오랜만에 쓰는 x리뷰입니다. 감을 잡을 겸 예전부터 익숙했던 분야의 논문을 읽고 리뷰해보았습니다. TPAMI2023에 나온 논문이고 제목에서 V3라고 되어있는데 V1은 IJCV, V2는 TPAMI2022에 붙은 논문으로 방향성을 잘 잡으면 쭉쭉 좋은 논문을 내는구나 라는 생각이 드는 논문입니다.
Intro
논문의 task는 self-supervised monocular depth estimation입니다. video sequence로 구성된 영상 데이터만으로 모델이 깊이 추정을 학습하는 방법론인데, 카메라가 움직이면서 연속된 프레임을 촬영한다고 했을 때 연속된 프레임 사이에 상대적인 카메라 포즈 값과 한 프레임의 depth값을 알고 있으면 연속된 다른 프레임으로 좌표계를 변경시킬 수 있다는 점에 착안해서 <t, t-1> (또는 <t, t+1>)프레임 사이에 relative pose, t프레임의 depth값을 통해 t-1 frame 영상을 t프레임으로 warping 시킨 뒤 실제 t frame 영상과 얼만큼 일치하는지에 대한 photometric loss 계산을 통해 모델이 학습합니다.
근데 이러한 학습 방식에는 사실 문제점이 많이 존재합니다. 우선 이러한 상대적인 pose 정보와 depth를 통해 warping이 가능한 경우는 정적인 대상과 영역들만 가능하다는 점입니다. 즉 연속된 프레임에서 동적인 객체가 존재한다면 이는 두 프레임 사이에 relative camera pose정보에 반하는 대상들이기 때문에 올바른 pose와 depth 정보를 가지고 있다 하더라도 warping이 정확하게 일치하지 않습니다.
그리고 photometric loss 자체에도 texture less하거나 영상이 촬영된 환경에 따라 t-1과 t프레임 사이에 급격한 photometric 변화가 발생한다던지, occlusion 등으로 warping한 t프레임 영상과 실제 t frame 영상 사이에 정확한 비교가 어려운 상황들도 모델 학습에 상당한 노이즈로 발생합니다.
아무튼 이런 다양한 어려움들 중 SCdepth 시리즈는 모델 학습에 강한 노이즈를 주는 동적인 객체를 어떻게 다루고 해결할 것인가?에 초점을 맞추는 논문들입니다.
Method
SCDepth v3는 SCDepth v1의 framework을 베이스로하여 새로운 loss 함수들을 제안하는 방법으로 우선 SCDepth v1에 대해서 간단하게 알아보겠습니다.
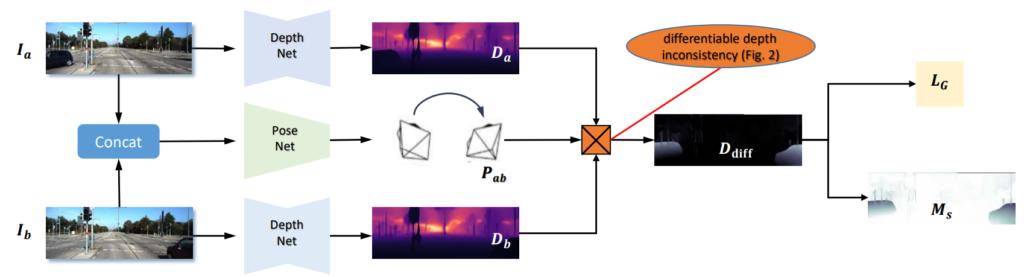
우선 그림 1은 ScDepth의 framework입니다. 기존의 self-sup 방법론들은 거의 모두 t-1, t, t+1 프레임을 하나의 iteration에 대한 학습으로 사용하게 되는데, 이때 모델 입력 관점에서만 보면 <t-1, t>, <t, t+1> 프레임들을 묶어서 카메라의 relative pose를 계산하는 용도로 사용되고, depth network는 t프레임 영상 하나에 대해서만 입력으로 받아서 t프레임과 대응되는 깊이를 추정하게 됩니다.
근데 SCDepth는 t프레임 뿐만 아니라 t-1, t+1 프레임 모두에 대해서도 깊이를 추정합니다. 아까 self-sup 학습 방식이 모델로 구한 Depth, Relative Pose를 통해 RGB 영상의 t-1(또는 t+1) 프레임을 t 프레임으로 변환해서 실제 t 프레임과 비교하면서 학습을 한다고 했었는데, 여기서 저자들은 t-1, t+1 프레임 depth map도 마찬가지로 warping을 해서 실제 t 프레임의 depth와 일치하는지를 비교하는 loss를 사용합니다.
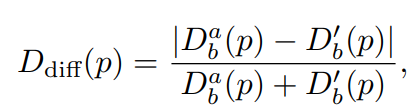
사실 여기까지만 보면 당연한 이야기입니다. 바로 인접한 frame이기 때문에 대부분의 depth 값이 일치해야하는 것이기 때문입니다. 하지만 이 Geometry Consistency Loss의 필요성은 여기서만 있는 것이 아닙니다. 저자들은 이 두 프레임의 depth 차이값을 가지고 아래와 같이 Mask를 계산합니다.
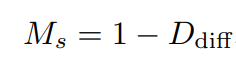
이 마스크 값은 쉽게 말하면 두 프레임 사이의 Depth가 일치하는 영역에 대해서는 1에 가까운 값을, Depth가 불일치하는 경우에는 0에 가까운 값을 지니는 일종의 valid mask?라고 보시면 됩니다. 아까 Intro에서 Self-sup 모델의 한계점이 학습 프레임워크의 가정 자체가 static region에 대해서만 올바르게 동작하고 dynamic region에 대해서는 학습이 불가능하다고 말씀드렸는데, 저자들의 관점은 만약 warping한 source depth와 target depth 사이에 차이가 큰 영역은 이러한 동적인 객체가 존재하는 영역으로 간주하는 것입니다. 이것이 SCDepth의 가장 핵심적인 contribution으로 동적인 영역을 모델링하는 마스크는 SCDepth V3에서 매우 중요하게 사용됩니다.
SCDepth V3
그럼 V3에 대해서 다뤄보겠습니다. V3의 컨셉은 상당히 직관적입니다. 아까 Self-sup 방식이 static region만을 고려해서 학습이 된다고 말씀드렸습니다. 그래서 이러한 dynamic region에 대해서는 학습에 사용되지 않도록 위에 M_{s} 뿐만 아니라 여러 다양한 masking을 적용해서 loss 값을 0으로 만들어 학습을 합니다.
이렇게 되는 경우 모델이 동적인 영역에 대해서는 학습을 전혀 못하게 되기 때문에 학습 데이터의 대부분이 동적인 객체가 등장하고 그 영역 자체가 영상 안에서 상당히 큰 비율을 차지하게 될 경우 모델의 학습 불안정성이 커지며 성능에도 매우 부정적인 영향을 미치게 됩니다.
그래서 V3에서는 저자들이 dynamic region에 대해서도 학습을 할 수 있도록 하는 학습 방식을 제안합니다. 우선 대략적인 방법론은 사전에 학습된 depth model을 통해서 뽑은 Pseudo depth map을 통해 각 픽셀들의 거리가 어떤 관계인지 (즉 두 픽셀 a, b에 대해서 a는 b보다 가까운지 먼지)를 계산하도록 한 다음에 그 관계에 따라서 해당 픽셀의 깊이는 비교 대상의 픽셀보다 가깝도록 혹은 멀도록 하는 목적 함수를 적용하는 것입니다.
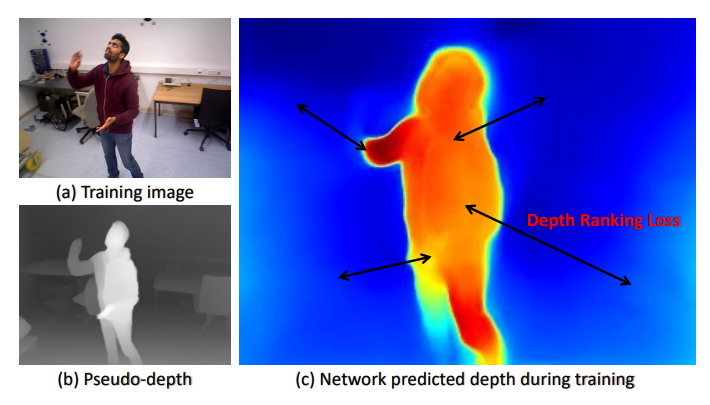
그림2 같은 느낌으로 보시면 좋을 것 같은데, 화살표에 각 끝 지점에 해당하는 두 픽셀이 가령 배경과 전경 관계라면 두 픽셀의 거리값은 서로 멀어져야한다는 느낌으로 이해하시면 좋겠습니다.
이러한 Depth ranking loss는 아래와 같이 계산됩니다.
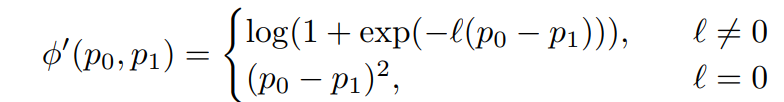
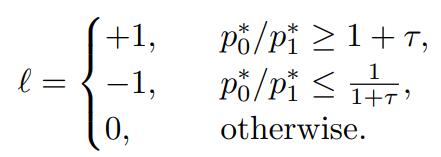
수식2에서 둘이 서로 값은 평면 상에 없다는 경우(즉 l값이 0이 아닌 경우)에는 둘의 거리 오차값이 최대한 멀어지도록 하는 것이며 둘이 같은 평면 상에 있다면(즉 I값이 0인 경우) 두 픽셀의 오차를 줄이는 것으로 계산하는 것입니다. 참고로 수식3에서 Depth Ordinal Label을 생성할 때는 사전에 학습된 depth model의 output값을 통해서 계산합니다. 이 모델의 depth value는 정확히 일치하지는 않겠지만 대략적인 거리감각 (즉 어떤 픽셀이 가깝고 어떤 픽셀이 먼지)을 가지고 있기 때문에 ordinal label을 생성하는데 있어서는 문제가 없다고 합니다.
그리고 이러한 depth ranking loss는 dynamic mask 안에서 dynamic region일 가능성이 가장 높은 픽셀 20%를 선정해서 우선적으로 적용했다고 합니다. 즉 dynamic region일 가능성이 높은 영역 20%의 픽셀들과 그 외에 static region일 가능성이 높은 픽셀들끼리 pair를 지어서 수식2의 loss를 적용합니다.
이는 self-sup의 학습이 static region에 대해서는 정확한 depth를 학습할 수 있을 것이기에 static region에 대한 depth 값을 dynamic region에게 guide 해주고자 함입니다.
하지만 저자들은 수식2를 그대로 적용하게 되었을 때 학습에 문제가 생겼다고 하는데, 저자들이 분석 끝에 내린 결론은 Ordinal Label을 만드는데 사용한 Pretrained model의 depth 값이 세밀하게 정확한 것은 아니여서 두 픽셀이 서로 같은 평면인 (즉 ordinal label l 값이 0인 경우)에 대해서 사실은 같은 평면으로 보면 안되는데 이 둘의 depth를 계속 같도록 하다보니 학습이 잘 안되는 것으로 판단했다 합니다.
그래서 저자들은 같은 평면 상에 있는지를 판단하기 위해서는 보다 정확한 depth 정보를 사전에 가지고 있어야하기에 더 정확한 사전학습된 모델을 구하지 않는 이상 어려움이 있다고 판단, 과감하게 같은 평면 상에서의 depth 오차 계산하는 loss는 제거해버립니다. 대신에 두 픽셀 사이에 거리가 더 먼 경우에 대해서는 depth 값이 부정확하더라도 판단하기 쉽다고 생각해서 수식3의 타우 값을 0.05에서 0.15로 더 크게 늘려 depth ordinal label의 신뢰성을 높이고자 했습니다.
여기까지가 ScDepth의 가장 main이 되는 contribution입니다. 그 외에 자잘하게 Depth Ordinal Label 생성에 필요한 pseudo Depth map을 가지고 Local Structure refinement를 하고자 Depth를 Normal로 변경하여 학습하고자 하는 모델의 output과 비교하는 Loss들이 몇가지 있는데 이는 이전에 있던 방법론들을 조금 변경해서 그대로 응용한 것들이라 넘어가겠습니다. Main Contribution은 아닌 것 같아서 관심 있으신 분들은 직접 논문 참고하시면 좋을 듯 합니다.
Experiment
평가에 사용된 데이터셋은 총 5가지로 outdoor 데이터셋 2가지 (DDAD, KITTI) Indoor 데이터셋 3가지(BONN, TUM, NYUv2) 입니다. 이중에서 KITTI와 NYUv2는 정적인 scene 위주로 구성되어있으며, DDAD와 BONN, TUM 데이터셋은 Dynamic Region이 많이 분포된 데이터셋으로 self-sup이 학습하기 더 어려운 데이터셋이라고 생각하시면 됩니다.
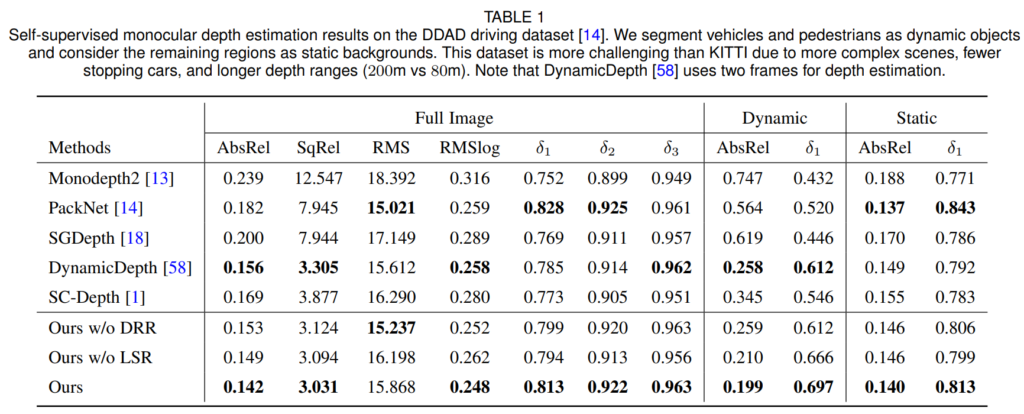
SC-Depth 방법론들이 Dynamic Region을 중점적으로 다루는 방법론들이라고 했습니다. 그래서 Monodepth2, SGDepth과 비교해서 Sc-Depth V1이 상당히 좋은 성능을 보여주는 것을 볼 수 있습니다. PackNet의 경우에는 Monodepth2, SC-Depth 등이 Resnet18을 쓰는 것과 비교해 모델의 크기가 상당히 무거운 (약 300M정도?였던걸로 기억) 모델이기 때문에 RMSE이나 Delta metric에서 좋은 성능을 보이지만 AbsRel과 SqRel에서는 SCDepth보다 많이 떨어지는 것을 볼 수 있습니다.
이러한 ScDepthv1을 더 보완해서 제안한 SCDepthv3는 상당히 높은 성능 향상을 보여주게 되는데, 이는 저자들이 제안하는 Dynamic Region Refinement와 Local Structure Refinment가 얼만큼 중요한 역할을 하는지를 잘 보여줍니다.
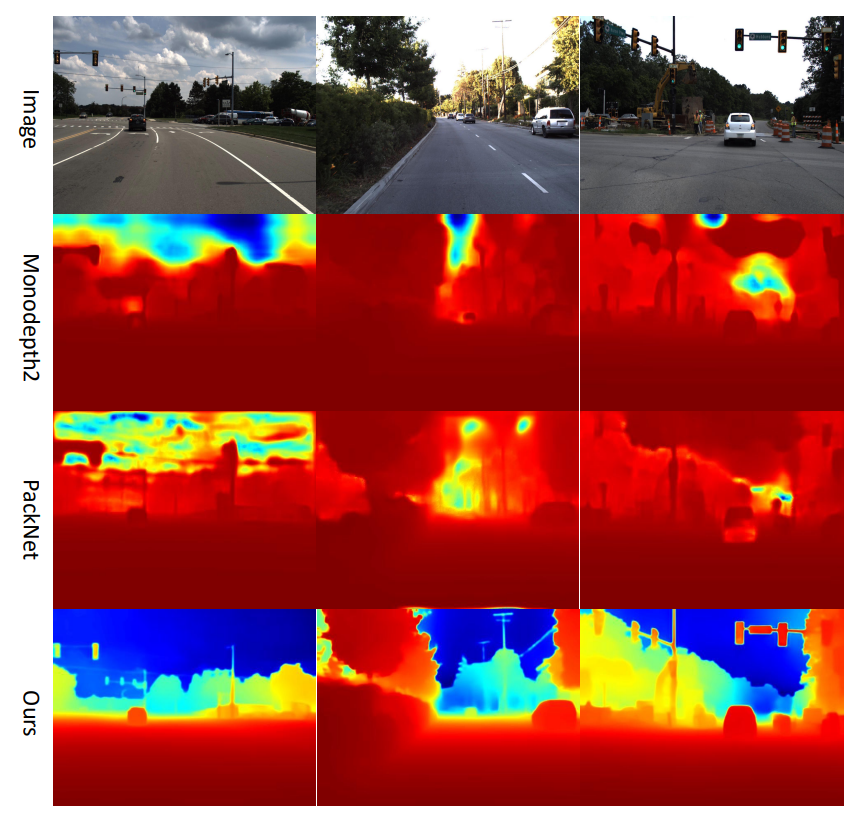
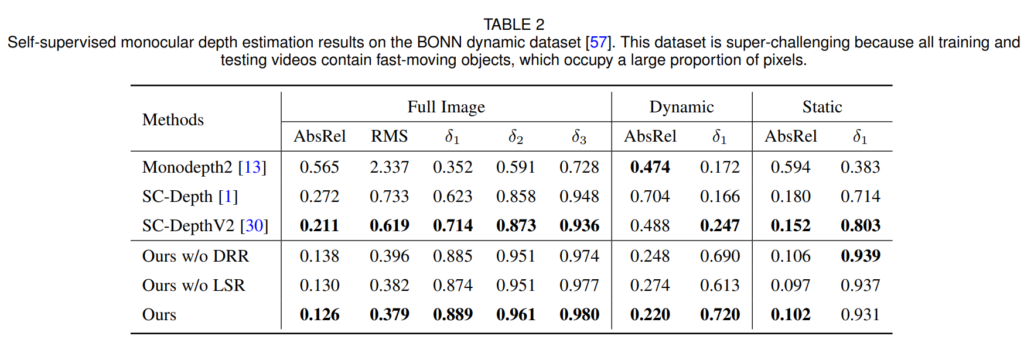
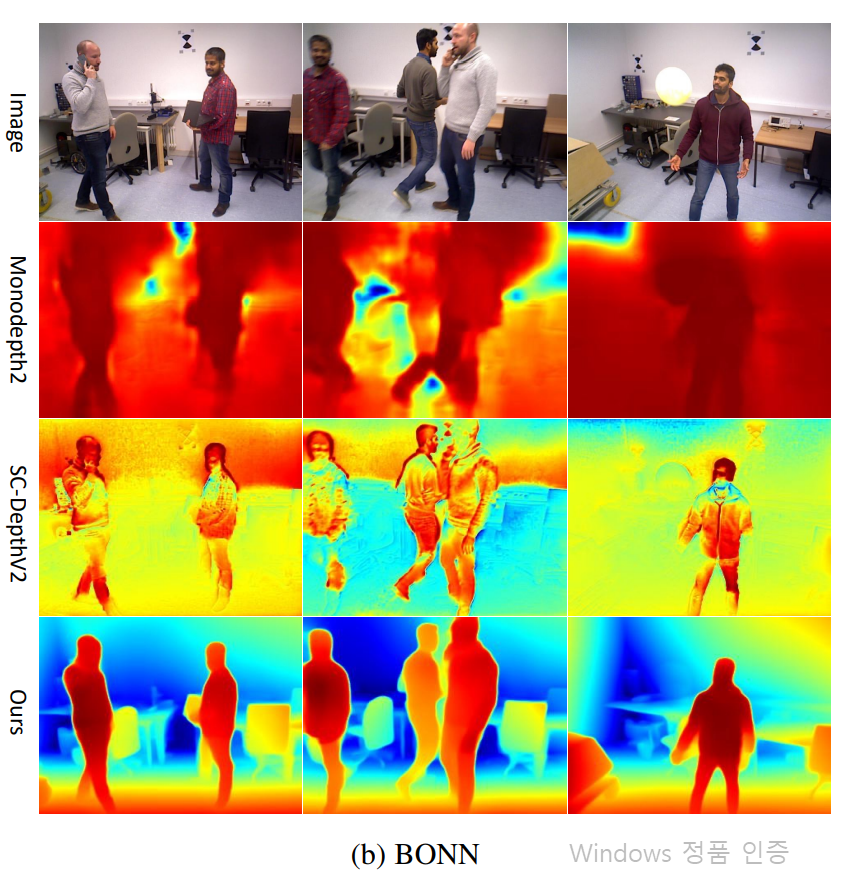
다음은 Indoor 데이터셋인 BONN입니다. BONN은 아래 그림에서 보다시피 방 안에서 사람들이 동적으로 크게 움직이기 때문에 self-sup 학습이 상당히 어려운 데이터셋입니다. 그래서 Monodepth2와 같은 Self-sup의 가장 대표적인 방법론은 학습이 전혀 안되는 모습을 볼 수 있는 반면에 저자들이 제안하는 SCDepthV3는 기존의 V1, V2 시리즈와 비교해서도 매우 월등한 성능 향상을 보여줍니다.
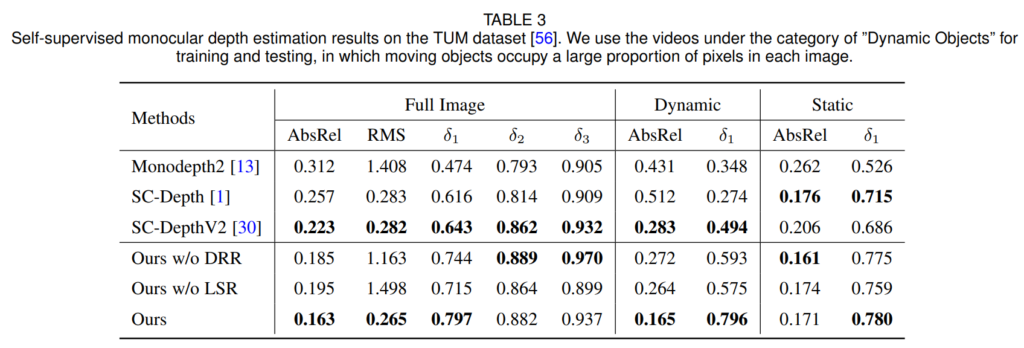
TUM 데이터셋도 BONN 데이터셋과 비슷한 경향성으로 SCDepth-v3가 가장 좋은 성능을 보여줍니다.
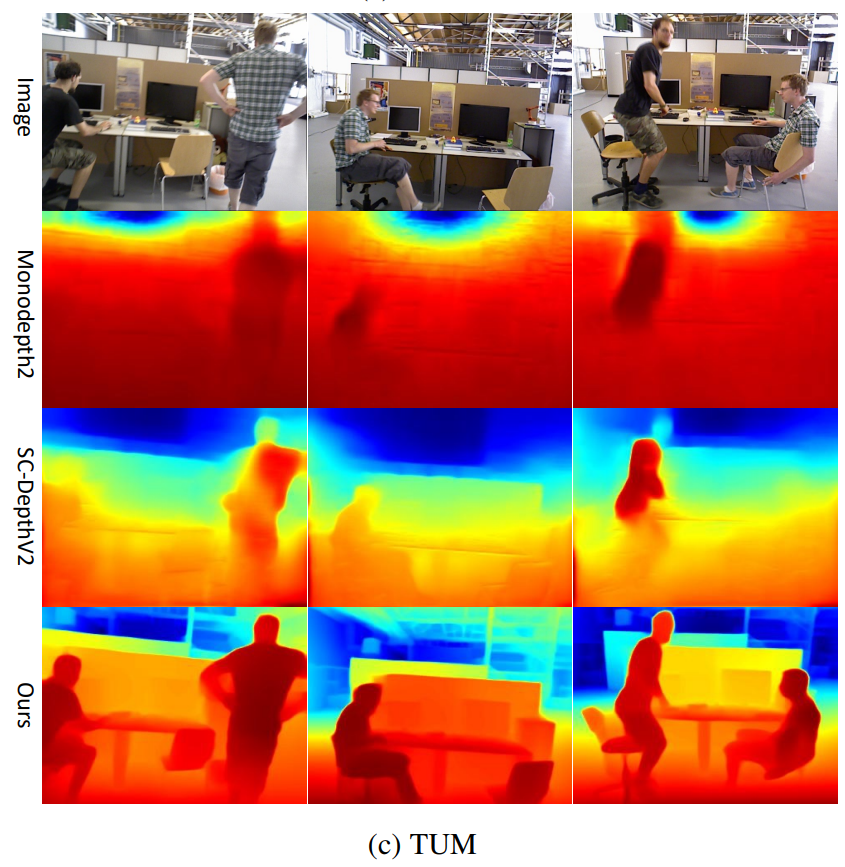
위에 정성적 결과들을 보면 재밌는 점이 SCDepth-V3의 경우 다른 결과들과 비교해서 Depth 결과값이 상당히 깔끔하고 structure 부분들이 잘 살아있는 것을 볼 수 있습니다. 이것이 저자들이 적용한 Local Structure Refinement의 역할 덕분이 아닌가 싶긴한데 결국에 pretrained된 model의 output을 학습에 사용하다보니 구조적인 골자를 잘 학습할 수 있던 것 같습니다. 그리고 Depth의 거리 감도 먼 영역과 가까운 영역에 대한 variation이 상당히 명확한 것을 확인할 수 있는데 저자들이 적용한 Depth Ranking Loss가 그 역할을 상당히 잘 하고 있음을 확인 가능합니다.
Limitation
저자들의 방법론과 컨셉 자체는 상당히 직관적이고 깔끔해서 TPAMI에 붙을 만큼 좋은 논문인 것은 맞습니다. 다만 SCDepth V1에서 제안하는 Dynamic Masking 방식이 KITTI와 같은 정적인 데이터셋 위주 구성에서 학습에 살짝 부정적인 영향을 끼치는지 베이스라인 모델 성능과 비교해 더 떨어지는 경향을 보여줍니다. 저자들은 정적인 데이터셋이라서 동적인 데이터셋을 위한 Mask가 의도한대로 작동하지 못했기 때문이라 주장하는데 맞는 말일 수는 있으나 그러면 성능에 변화가 없어야하지만 저자들의 방식을 적용하면 성능이 더 감소한다는 점에서 아쉬움이 남긴 합니다. 아무래도 동적인 마스크를 구하는 방식도 camera의 pose와 depth의 결과값에 영향을 받기 때문에 가뜩이나 학습 시그널이 불안전한 self-sup에서 Dynamic Masking과 이를 통한 loss 계산이 KITTI같은 데이터셋에서는 학습 초기에 안좋은 영향을 끼치는 것이 아닌가 싶네요.