안녕하세요 2번째 X-Review 작성자 손우진입니다. 이번에는 2023년 CVPR에 기재된 Non-Homogeneous Image에서 Dehazing 문제를 다룬 논문인 SCANet: Self-paced Semi-curricular Attention Network for Non-Homogeneous Image Dehazing 을 리뷰해보려 합니다.
쉽게 설명드리면, 안개가 껴있는 상황에서 원래의 선명한 이미지를 복원하는 문제를 다루는 논문입니다. 특히 이 논문은 현실 환경에서 흔히 나타나는 비균일하게 퍼져 있는 안개(non-homogeneous haze) 상황을 집중적으로 다룹니다.
예를 들어 일부 영역은 맑고 다른 일부는 짙은 안개에 가려진 사진을 생각해보면 됩니다. 이런 이미지를 복원하려면 네트워크가 어디에 안개가 심한지 어디에 복원이 필요한지를 잘 파악할 수 있어야 합니다. 그럼 리뷰 바로 시작하겠습니다.
Introduction
실제 환경에서는 안개가 일정하게 퍼져있기 보다는 특정 영역에만 짙게 끼는 경우가 많습니다. 이런 non-homogeneous haze상황에서는 장면 흐림, 생삭 왜곡, 명암 대비 저하 등 texture degradation을 유발합니다. 하지만 대부분의 기존 dehazing 기법들은 안개가 균일하게 분포한다는 가정에 설계되었기 때문에 현실적인 상황에서는 성능 저하가 일어나게 됩니다. 이를 해결하기 위해 본 논문에서는 SCANet이라는 새로운 네트워크 구조를 제안하였습니다. 자세한 네트워크 구조 설명에 앞서 선행연구들의 dehazing 문제를 해결해왔는지 간략히 설명하겠습니다.
원초적인 방법론에서는 물리 기반 접근(physical prior-based methods)들은 대기 산란 모델을 바탕으로,안개 없는 이미지를 복원하는 방식이 주를 이루었습니다.
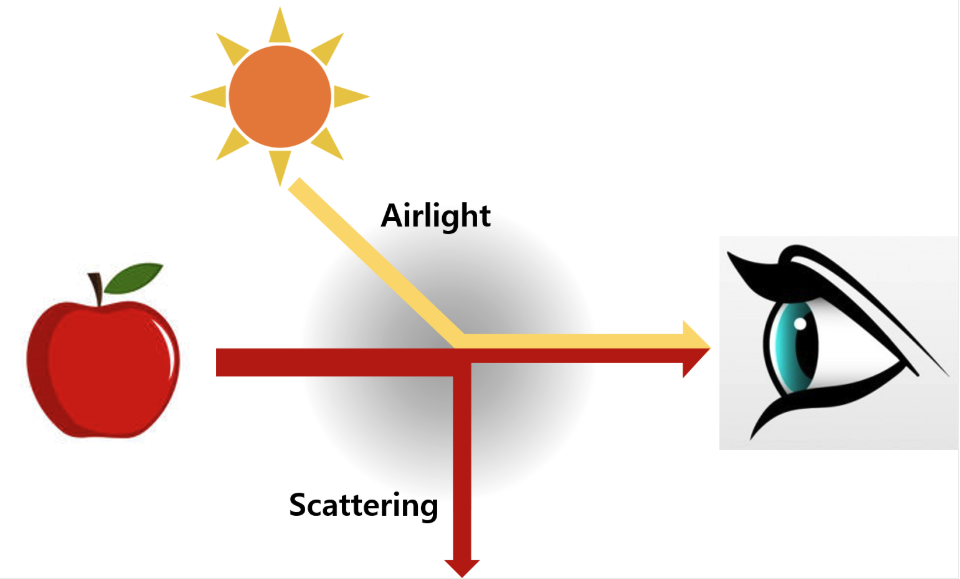
대기 산란 모델이라하면 입사광이 안개 입자에 의해 산란되면서 카메라에 도달하는 경로를 설명합니다 그림에서 보이시는 것 처럼 저희가 보는 이미지는 실제 장면으로부터 오는 빛뿐만 아니라 공기 중 입자에 의해 산란된 빛과 태양 등 광원(Airlight)으로부터 직접 반사되어 오는 빛이 함께 혼합된 결과입니다.
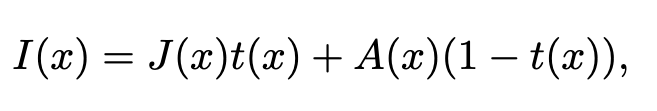
이를 수식적으로 표현하면 다음과 같습니다
- I(x): 관측된 안개 낀 이미지
- J(x): 안개 없는 원래 장면
- t(x): 전송 맵 (transmission map), 즉 빛이 도달하는 정도
- A(x): 전역 대기광
이러한 물리적 기반으로 선행연구들은 전송 맵과 대기광을 추정한 후 이를 이용해서 원래의 이미지로 복원하는 방식을 사용해 왔습니다. 하지만 본 저자는 t,A를 구하는 것이 복잡하고 부정확하여 오히려 복원 성능을 저해하는 요인이 될 수 있다고 합니다. 그래서 딥러닝 기반의 연구들로 전송 맵 또는 복원된 이미지를 직접 예측하고 attention, GAN 모델등을 이용하여 복원해왔습니다. 하지만 처음 말씀드린 것 처럼 이러한 딥러닝 기법들 역시 대부분이 안개의 분포가 균일하다는 전제하에 훈련되었기 때문에 현실적인 비균일 안개 환경에서는 여전히 제한적인 성능을 보입니다. 추가적으로 비 균일 안개 환경에서 최근 연구는 안개의 복잡한 분포와 구조적인 정보가 상호작용을 정확하게 반영하기 어렵다고합니다.
그래서 저자는 위와 같은 문제점들을 해결하기 위해
- attention Generation Network(AGN)을 통해 attention map을 생성하고 이러한 정보를 이용하여 이미를 복원하는 SRN(scene Reconstruction Network) 2단계 구조를 파이프라인을 제시하였습니다.
- 추가적으로 attention map을 학습하는 초기 단계에서 발생하는 불안정한 수렴문제를 해결하기 위해서 SCL(self-paced semi Curricular Learning)를 도입하였습니다
Method
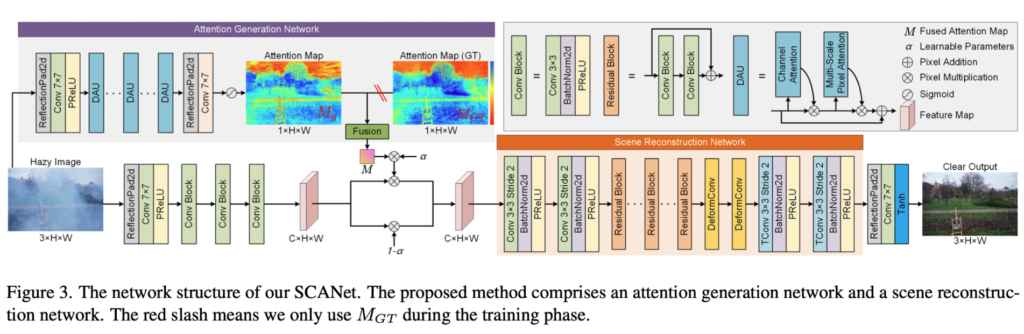
전체적인 파이프라인은 figure 3과같이 attention map 생성 + Encoder-Decoder 구조의 단계로 2단계로 이루어져있습니다.
AGN(attention Generation Network)
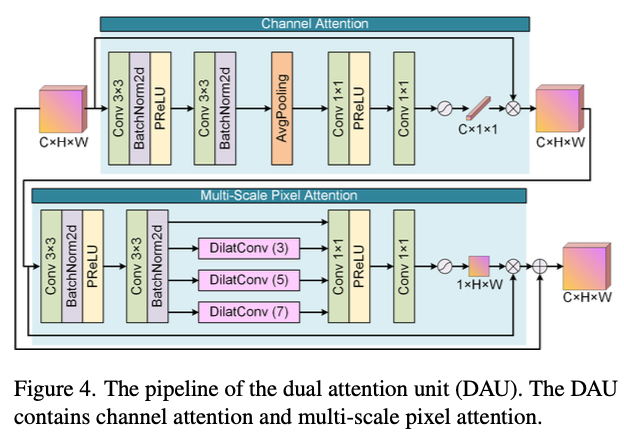
Attention Generation Network는 입력 이미지로 부터 attention map을 형성합니다. 구성은 DAU(dual attention unit)으로 구성되어있고 CA(channel Attention)를 통해서 나온 weight를 원래 feature map과 곱하여 Multi-Scale Pixel Attention 단계를 거칩니다 이 과정에서 dilated Convolution을 병렬로 사용함으로써 공간정보를 concat해줍니다. 이과정에서 여서 스케일에서의 안개분포를 학습할 수 있습니다. 최종적으로 MSPA를 통해서 출력된 두 attention map이 원래 feature에 적용되면서 모델이 어떤 부분에 복원을 중요하게 해야하는지를 알게됩니다.
SRN(Scene Reconstruction Network)
그렇다면 SRN은 AGN에서 생성된 attention map을 활용하여 이미를 생성하는 모듈이라고 생각하시면 될 것 같습니다. downsampling을 통해서 low-resolution feature map으로 변환이 됩니다. 이어서 residual block들과 2개의 deformable convolution layer를 통과하게 됩니다. 특히 deformable conv는 고정된 커널이 아니라 학습된 offset (여기서 학습된 offset이라고 하면 feature 위치를 조정해주는 이동 값을 의미합니다. 기존 conv은 weight만을 학습하지만 deformable convolution은 conv 연산전에 offset prediction module을 통해서 각 커널 위치마다 dx,dy이동값을 예측하여 더 중요한 영역을 바라볼 수 있게 학습합니다) 을 사용하여 동적 커널을 사용합니다. 이후 Transposed Convolution을 통해서 Upsampling을 진행하여 이미지를 복원하게 됩니다.
Self-Paced Semi-curricular Attention
저자들은 AGN에서 학습하는 과정에서 Attention map을 지도학습으로 학습하였습니다. 기존의 비지도학습에서의 중요하지 않은 부분에 과도한 가중치가 부여될수 있고(중요하다고 생각 할 수 있고) 이로인해, block artifacts 현상이나 정확하지 않게 복원이 될 가능성도 있다고 합니다. 이를 해결하기 위해 GT를 hazy 이미지와 clear 이미지를 YCbCr 공간으로 변환한 후 밝기 채널(여기서 Y 입니다 ,Cb : 색상 차이, Cr : 색상정보)의 차이를 이용하 Mgt 생성하고 학습에 사용했습니다.
그렇다면 이 GT를 활용할때 초기에 Gradient의 불안정한 수렴을 방지하기 위해서 SCL(self-paced semi-curricular learning)을 도입하였습니다. 핵심 아이디어는 학습 초기에는 smooth L1의 오차가 크기에 GT를 의존하고 점차 학습이 되면 오차가 줄어들면서 예측한 attention Map에 비중을 주는 것입니다.
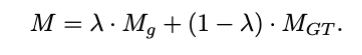
λ : trade-off parmeter
Mg : 예측 attention map
Mgt : gt attention map
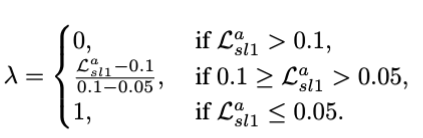
위식과 함께 오차가 클때는 0값으로 중간일때는 50%씩 사용하고 오차가 0.05를 줄어들면 1값으로 예측 attention map을 사용하여 학습의 초기 안정성을 잡으면서 모델의 안정성을 추가하였습니다.(이때 계속 해서 GT를 사용하는것을 막고자 epoch 비율의 25%만을 사용했습니다)
Loss function
이렇게 attention map학습의 안정성을 확보하고 전체 네트워크에 joint loss를 통해 학습됩니다.
총 5가지 손실 함수로 이루어져있습니다.
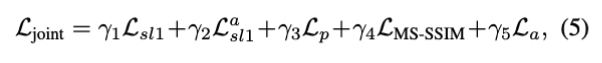
γ1, γ2, γ3, γ4, γ5 는 각각 {1, 0.3, 0.01, 0.5, 0.0005}를 사용하였다고 합니다. 그럼 각각의 loss들을 살펴 보겠습니다.
Smooth L1 Loss 입니다
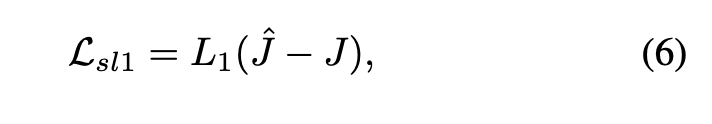
- 복원된 이미지 : J 와 GT 이미지 : J^ 이미지간의 픽셀 단위 오차를 계산합니다
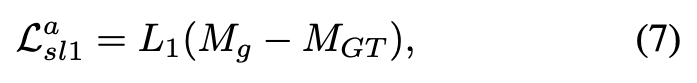
- attention map에 대한 지도 학습용 smooth L1으로 오차를 계산합니다
Perceptual Loss
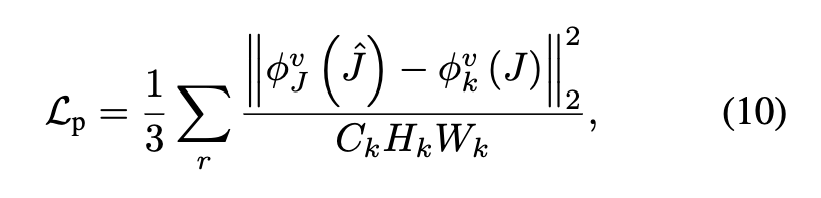

복원된 이미지와 원본 이미지가 VGG16 네트워크 상에서 feature map 끼리 유사한지에 대한 손실함수입니다. 논문에서는 자세히 기재가 되어있지는 않지만 texture 와 색상에 대해 부자연스러운것을 해결하기 위해 추가를 한거같습니다.
MS-SSIM Loss
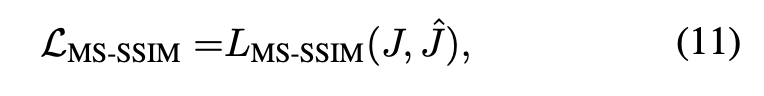
MS-SSIM은 : 밝기, 대비, 구조 요소를 종합적으로 평가합니다. 이것은 고주파수 영역의 대비를 향상시키기 위한 것이며 픽셀값만 비슷한 것이 아니라 멀티 스케일에서 반복적으로 계산하여 전반적인 시각 품질을 향상 시키기 위함입니다. (perceptual loss와 비슷하다고 생각하실수 있지만 다릅니다!)
Adversarial Loss
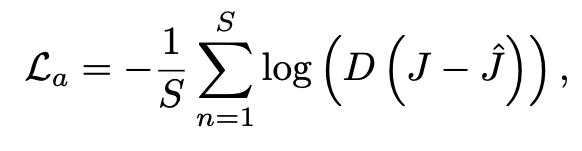
마지막으로는 GAN 모델에서 흔히 사용하는 Adversarial Loss입니다 Discriminator를 속인다고 하죠 생성된 이미지와 GT가 구분이 되지않게 loss를 줄연나갑니다
Experiments
실험은 NTIRE2020, 2021, 2023 dataset (hazy + original)이미지 쌍으로 실험하였습니다.
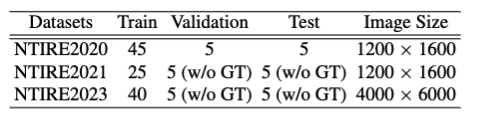
위의 사진 처럼 2020은 모든 데이터셋에 GT가 존재합니다 하지만 다른 데이터셋은 validation이나 Test는 공식 성능 평가 대회에서 PSNR/SSIM의 점수를 획득한다고 합니다. 여기서 드는 의문점으로 train데이터셋이 이렇게 작은데 성능평가가 가능하냐고 생각하실 수 있습니다. 논문에는 작성 되어있지않지만 hazy 와 원본 이미지가 쌍으로 주어진 데이터셋이 제한적이라고 생각해주시면 될 것 같습니다
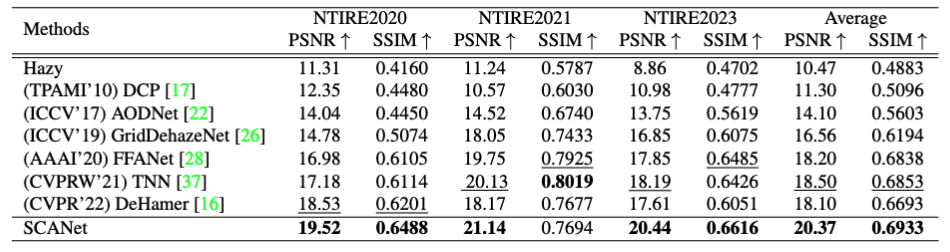
여기서 PSNR은 픽셀 단위의 MSE기반으로 복원 이미지와 원본 이미지가 얼마나 유사한지 측정하는 지표입니다. 값이 클수록 원본 이미지에 가깝다고 보시면되겠습니다. 혹시 추가적으로 어떻게 계산되는지 궁금하시면 질문 남겨주시면 답변하겠습니다. SSIM은 밝기, 대비, 구조의 유사도를 종합적으로 평가하는 지표입니다. 1에 가까울수록 두 이미지의 구조적으로 일치한다고 보시면 될 것 같습니다. 결론적으로
SCANet은 위의 데이터셋으로 기존 방법론들 과의 정량적 성능 비교를 통해 성능 지표를 보면 비교 대상에들 과의 { 물리기반 : DCP CNN기반 : AODNet, GridDehazeNet, FFANet, GAN기반 : TNN, DeHamer } 모두 비교하였을때 가장 좋은 성능을 보여주었습니다.


정성적인 결과를보아도 물리기반의 성능과는 전혀다른 결과를 보여주고있음을 보이고 있으며 다른 모델
색감정보 또한 맨 우측의 정성적결과 안개가 dense하게 몰려있는상황에서 SCANet에서 가장 GT와 유사하게 복원되는 것을 볼수있습니다.
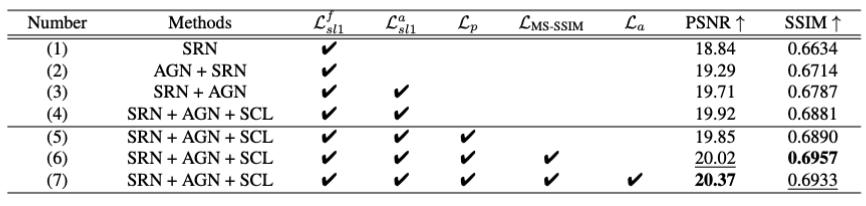
추가 실험으로는 ablation 실험결과입니다 기본 구조인 SRN 단독 사용 시 PSNR은 18.84, SSIM은 0.6634로 시작되며, Attention 모듈(AGN)을 추가하면 성능이 뚜렷하게 상승하고,attention map에 대한 지도 학습과 SCL 전략을 적용하면 학습 안정성과 정밀도가 향상되었습니다. 이후에는 Perceptual Loss, MS-SSIM, Adversarial Loss를 순차적으로 도입하면서 시각적 품질과 복원 성능을 끌어올렸고 최종 구성에서는 PSNR 20.37, SSIM 0.6933으로 최고 성능을 달성했습니다.이 결과는 attention 기반 구조, 지도 학습, 복합 loss 설계가 전체 복원 성능을 향상시켰음을 보여주고 있습니다. SRN + AGN의 순서가 뒤집혔는데 이에대한 언급은 없으며 알아내지 못했습니다.
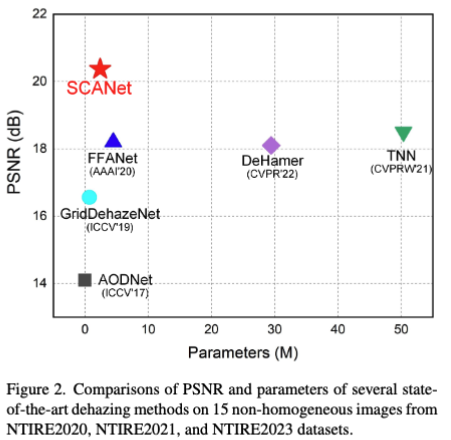
마지막으로는 SCANet은 다른 모델에 비해 파라미터 수는 적고 PSNR 성능은 가장 뛰어나다는 것을 시각적으로 보여줍니다.
Conclusion
SCANet은 non-homojeneous haze 환경에서의 복원 문제를 해결하기 위해 설계된 attention 기반 경량 dehazing 네트워크입니다 기존 기법들이 대부분 균일한 안개 분포를 전제로 했던 것과 달리 복잡한 안개 분포와 구조의 상호작용을 효과적을 포착할 수 있도록 attention 모듈과 복원하는 것을 결합한 파이프라인을 제안하였고 초기 attention map 불안정을 해결하기 위해 제안된 SCL을 통해 모델의 안정성높였습니다.
제가 준비한 리뷰는 여기까지입니다. 감사합니다. 끝으로 독자여러분들의 질문은 언제나 환영입니다^^.
안녕하세요, 좋은 리뷰 감사합니다.
이전 연구들의 한계에 대해서 말씀해주실 때, t와 A를 구하는게 복잡하고 부정확하여 성능이 저하되는 요인이 된다고 말씀해주셨습니다. 이 부분까지는 이해가 되는데, 균일한 안개가 아닌 균일하지 않은 환경에서는 왜 기존의 방법론이 성능이 저하가 되는 것인지 조금 더 설명해주시면 감사하겠습니다.
그리고 M_gt를 만들어서 gt attention map을 만든 것 같은데, 두 이미지 사이의 밝기 채널의 차이에 대한 맵을 만든게 실제 네트워크를 타고 나온 attention map과 loss 계산할 수 있을 정도의 분포값을 가지는지도 궁금합니다.
감사합니다.
안녕하세요 건화님~ 좋은 질문 감사합니다.
Q1.
이전 연구에서의 t와 A는 매우 어렵다는 사실을 안다면 균일 하지 않은 안개 환경에서는 장면마다 안개의 분포 광원의 위치와 방향등 복잡한 요소들이 섞여있습니다. 특히나 A값(광원) 은 하나의 값으로 근사가 됩니다 균일 안개의 경우 그러나 불규칙적으로 분포하게 되머 하나의 A값으로 복원하기에는 어렵다고 판단하시면 되겠습니다
Q2
안개가 끼면 밝기 대비가 줄어든다는거는 아실겁니다 그러면 original 이미지와 haze이미지를 통해서 어디가 많이 뿌옇다는 것을 알수있습니다. 그렇다면 Gt와 예측된 map은 물론 처음에는 분포값의 차이가 클 수 있습니다. 저자는 그래서 학습초반에는 Self-Paced Semi-curricular Attention 을 통해서 gt를 넘겨주고 분포차이가 줄어들면 예측 attention map을 사용한다고 합니다!
시원한 답변이 되었으면 좋겠습니다! 감사합니다~