안녕하세요, 허재연입니다. 지난번에 이어서 OV-SGG 분야 논문을 가져왔습니다. SGG의 경우 일반적으로 <subject-predicate-object> triplet을 모두 잘 예측하고자 하는 흐름에 있는데(이를 Visual Relation Detection이라고도 합니다), 본 논문은 zero-shot relation(predicate) classification에 집중하였습니다. 한번 살펴보겠습니다.
Introduction

Scene Graph Generation(SGG)은 이미지 / 장면을 보다 깊이 있게 분석하고자 하는 task로, 주어진 영상 내의 모든 물체를 찾고 이들 간 관계까지 찾아내고자 합니다. 일반적으로는 각 물체들을 찾고 이들을 활용해 <주어 – 서술어 – 목적어> 형태의 triplet을 보다 정교하게 탐지하려고 하죠. VLM의 등장 이후 자연스럽게 SGG을 open-vocabulary로 수행하고자 하는 시도들이 시작되었습니다. CLIP과 같이 사전학습된 VLM이 뛰어난 일반화 성능을 보여주고 zero-shot 예측을 잘 수행하기에 자주 사용되었죠. CLIP의 경우 이미지를 visual feature로 변환해주는 image incoder, 텍스트 입력을 semantic feature로 변환해주는 text encoder로 구성됩니다. 이 때 사전학습 과정에서 서로 다른 모달리티(image, text) 데이터들을 동일한 semantic space로 매핑해 정렬합니다. 이를 통해 image feature와 text prompt feature를 비교해 novel category에 대한 zero-shot 인식을 수행할 수 있었죠. 이런 능력은 특히 OVOD에서 활발하게 이용되었습니다.
하지만 Visual Relation Detection(VRD)은 object detection보다 훨씬 복잡합니다. 이미지 내의 주어진 객체(object)들에 대해 주어(subject), 관계(relation. predicate으로 쓸 때도 있습니다), 목적어(object) 형식으로 관계 유형으로 인식해야 하는데 이는 탐지된 객체들의 class만 분류하면 되는 object detection과 달리 두 객체가 어떻게 연관되어있고 어떻게 상호작용하는지 이해해야 하기 때문입니다. 대규모 image-text pair로 학습한 CLIP을 활용해 이런 relation 유형을 설명하는 클래스 기반 프롬프트를 만들면 제로샷 VRD에 활용할 수 있긴 하지만, 저자들은 이 방법에 명확한 한계가 있다고 지적합니다.
이해를 위해 “holding”과 “carrying” 두 클래스를 구분하는 예시를 들어 보겠습니다. 두 relation 모두 사람-물체 간 상호작용을 의미하고 그 뜻이 유사하기는 하지만 차이가 있죠. “holding”은 사람이 손에 물체를 들고 있는 상황을 의미하고, “carrying”은 사람이 물체를 손이나 팔로 지지하며 이동하는 상황을 의미합니다. 개념적으로 굉장히 비슷하기 때문에 Figure 1(a)처럼 class 기반 프롬프트를 활용하면 CLIP의 semantic space에서 이들이 매우 인접한 위치에 매핑되어 있을 것이기에 정확한 구분이 어려울 것입니다. CLIP의 경우 유사한 관계들 간 미묘한 차이를 잘 구분할 수 없다고 합니다.
또한, 클래스 기반 프롬프트는 각 relation 유형에 내포된 고유한 공간적 정보(spatial cue)를 활용할 수 없습니다. 예를 들어 “carrying”의 경우 사람보다 물체가 보통 더 낮게 있거나 사람이 몸으로 지지하는 형태를 띌 것이고, “holding”의 경우 일반적으로 물체가 사람과 특정 관계 있을 가능성이 높은 위치가 있을 것입니다. 직관적으로 사람이 상황을 판단할 때에도 물체 간 위치 정보를 사용합니다(“책상이 노트북 위에 있다” 라는 말보다는 “노트북이 책상 위에 있다” 라는 말이 자연스러운 것처럼요). 저자들은 이런 공간적 정보를 무시하는 문제에도 집중합니다.
마지막으로, CLIP을 활용하는 것에 연산량 측면에서도 문제를 짚습니다. CLIP을 사용해서 주어(subject)-목적어(object)간 관계를 분류하려면 각 subject-object pair의 union region을 각각 잘라내 예측해야 하는데, object proposal 수가 N개일 때 cropped image 수가 {N}^{2}개가 만들어지기 때문에 연산량 측면에서 비효율적이라고 합니다.
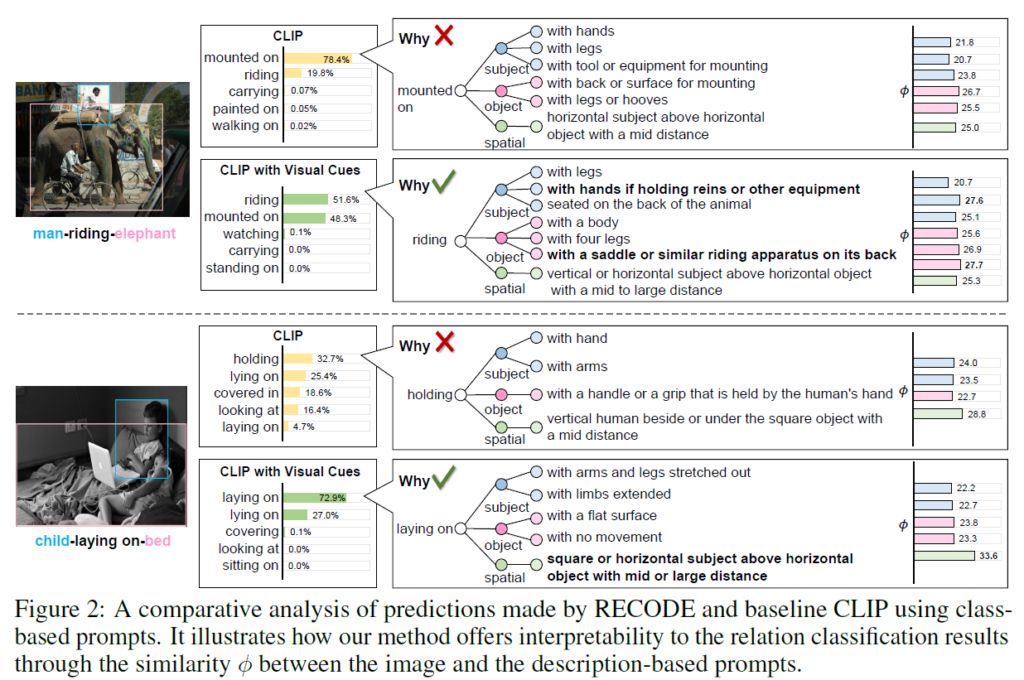
저자들은 위 문제점들을 완화하기 위해 복합 description을 통해 relation을 분류하는 RECODE(RElation via COmposite DEscriptions)라는 새로운 VRD 방법론을 제안합니다. 해당 방법론은 우선 LLM을 이용해 relation 카테고리의 구성 요소인 주체(subject), 객체(object), 공간(spatial)에 대한 자세한 description을 생성합니다. 이런 description은 이후 CLIP 입력의 description-based prompt를 만드는데 사용되어 모델이 유사한 relation 카테고리를 구분하는데 도움이 되는 특정 visual feature에 집중할 수 있도록 합니다. 주체, 객체 component에 대해 생성된 프롬프트는 외형(appearance. ex: “with log”), 크기(size. ex: “small”), 자세(posture. ex: “in a sitting posture”)와 같은 시각적인 정보를 포함하도록 했고, 공간(spatial) component에 대한 프롬프트는 객체들 간 상대적 위치 및 거리와 관련된 정보를 포함하도록 하였습니다. 이런 다양한 시각적 단서들을 통합해 relation 간 미묘한 차이를 보다 명확하게 구별할 수 있도록 한 것이죠.
또한, 기존의 relation class description prompt을 사용하는 방식은 relation class를 세밀히 구분하기 충분하지 않을 수 있기에 고수준의 객체 카테고리 정보를 활용해 각 관계 카테고리에 더 정확한 시각 단서를 생성할 수 있는 guided relation component description prompt를 설계합니다. 예를 들어 객체의 상위 카테고리가 animal일 경우, riding이라는 관계에 대한 object description은 “with four legs”와 같이 동물과 관련된 것을 생성하고, 반대로 객체가 제품일 경우에는 “with wheels”와 같은 description을 생성합니다. 이런 방법을 통해 보다 정확하게 시각적 정보를 각 relation type에 맞게 반영할 수 있다고 합니다.
다양한 visual cues로부터 수집한 정보를 통합하기 위해 LLM을 사용해 CoT를 적용해 각 component에 대해 적절한 가중치를 예측하도록 하였습니다.
저자들이 주장하는 contribution을 요약하면 다음과 같습니다.
- 저자들은 기존의 제로샷 VRD에 사용되던 클래스 기반 prompt 방식의 한계점을 분석하여 이를 해결하기 위해 RECODE를 제안하였다. RECODE는 LLM을 활용해 relation class의 각 component에 대해 description 기반 프롬프트(visual cues)를 생성하여 CLIP이 다양한 relation category를 잘 구분할 수 있게 하였다.
- 저자들은 Chain-of-Though(CoT)를 도입해 가중치 예측 문제를 더 작고 쉬운 문제로 분해하고, 각 visual cue에 대해 LLM이 가중치를 잘 할당할 수 있도록 하였다.
- 4개의 대표적인 벤치마크에서 실험을 수행한 결과, 제안한 방법론이 좋은 성능을 보여줌을 입증하였다.
Method
본 논문에서는 zero-shot relation classification에 초점을 맞춥니다. 이미지 내 모든 subject, object를 찾고 분류하는 세팅이 아닌, 모든 객체에 대한 bounding box와 이들의 클래스가 주어졌을 때 모든 object pair 간 시각 관계/서술어 class를 예측하는 것입니다. 지금부터는 주체(subject)를 s, 목적어(object)를 o, 주어와 목적어 간 공간적 위치(spatial position)을 p, 각 relation class를 r으로 표기하겠습니다.
Class-based Prompt Baseline for Zero-Shot VRD
당시 제로샷 VRD방법론들은 CLIP모델에 클래스 기반 프롬프트를 활용하여 예측을 수행했습니다. 사전학습된 이미지 인코더, 텍스트 인코더를 활용해 주어진 객체 쌍에 대해 관계 클래스를 분류한 것입니다. 각 relation class에 대해 관계 정보를 포함한 자연어 클래스 기반 prompt {p}_{c}를 생성합니다(ex : “[REL-CLS]-ing/ed” 나 “a photo of [REL-CLS]”). 각 프롬프트는 CLIP 텍스트 인코더를 타고 semantic embedding t로 변환되고, s-o 쌍의 union region은 이미지 인코더를 타고 visual embedding v로 변환되어 v와 t간 코사인 유사도 및 softmax를 거쳐 모든 relation class에 대한 확률 분포를 얻어 분류를 수행했었습니다.
Zero-shot VRD with Composed Visual Cues
저자들은 위의 클래스 기반 프롬프트의 한계를 해결하기 위해 RECODE를 제안하였습니다. RECODE는 1. visual feature decomposing, 2. semantic feature decomposing, 3. relation classification 세 부분으로 구성됩니다. visual feature decomposing과 semantic feature decomposing단계에서는 하나의 relation triplet에 대한 visual feature를 주어, 목적어, 공간(spatial) 세 가지 구성요소로 분해한 뒤 각 구성요소에 대해 semantic feature를 생성하고, relation classification 단계에서 분해한 visual feature들과 semantic feature들의 집합 간 유사도를 계산한 뒤 집계(aggregate)하여 모든 relation에 대한 최종 예측을 수행합니다.
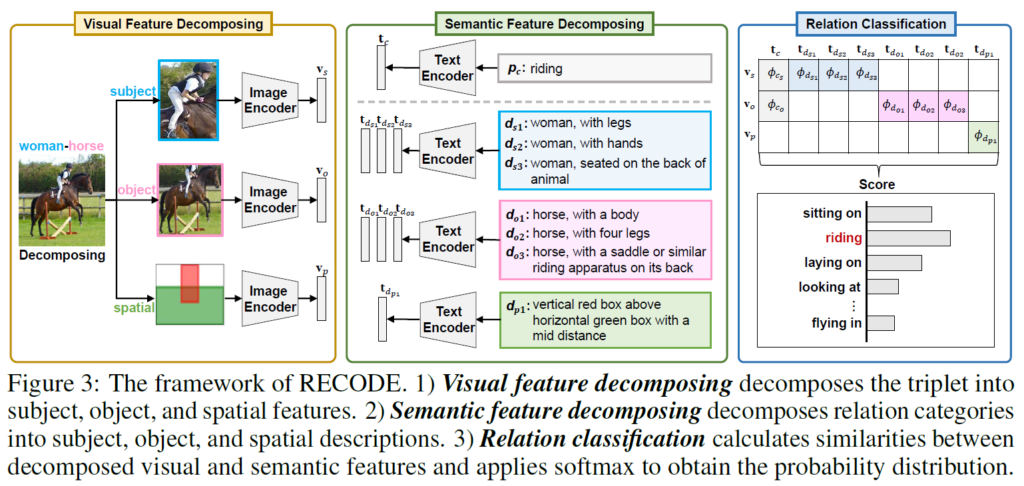
Visual Feature Decomposing
공간적 분별력과 계산 효율성을 높이기 위해 하나의 관계 triplet의 visual feature를 주어, 목적어, 공간(spatial)로 분해합니다. 주어, 목적어 feature에 대해서는 주어진 bounding box 좌표로 subject와 object의 영역을 crop하고 이들을 CLIP visual encoder에 통과시켜 각각 visual embedding {v}_{s}, {v}_{o}로 변환합니다. spatial feature의 경우, subject와 object의 bbox를 기반으로 이들의 spatial relationship을 얻어야 하는데, 가능한 모든 spatial image를 생성하기 위해서는 {N}^{2}개의 조합이 만들어져 계산 부담이 커집니다. 이 때문에 저자들은 s-o 간 공간 관계를 줄이고자 합니다. 바운딩 박스를 기반으로 shape, size, relative position, distance 4가지 속성을 활용해 유한개의 simulated spatial image와 매칭합니다. 매칭된 공간 이미지는 CLIP 이미지 인코더에 입력해 spatial embedding {v}_{p}로 변환합니다.

Semantic Feature Decomposing.
CLIP이 보다 다양한 관계 클래스들을 효과적으로 구분할 수 있도록 각 관계 클래스에 대해 기존의 class-based prompt를 보완하는 description-based prompt 집합을 도입합니다. 각 subject와 object component에 대해 description기반 프롬프트 집합 {D}_{s}, {D}_{o}을 생성하게 됩니다. 이 프롬프트에는 객체의 category를 포함하며, 특정 관계에서 나타나는 고유한 시각적 특정을 강조하는데, 이를 통해 유사한 관계 클래스 간 구분을 명확히 하고자 합니다. 공간(spatial) component에 대해서는 이미지 내 s,o 사이의 상대적 위치와 거리 정보를 포함하는 description-based prompt {D}_{p}를 생성합니다. 이런 추가 정보들을 활용해 공간적 위치 차이에 기반한 relation 구분을 가능하게 하고자 합니다. 이런 description기반 프롬프트 집합들을 생성한 후, 각각의 프롬프트를 텍스트 인코더에 입력해 각각 주어, 목적어, 공간 설명 임베딩 집합 {t}_{dsi}, {t}_{doi}, {t}_{dpi}으로 변환합니다. 이 임베딩들은 클래스 기반 프롬프트 임베딩 {t}_{c}와 함께 최종 relation classification 단계에서 활용합니다.
Relation Classification
이 단계에서는 visual, semantic feature 간 유사도를 계산해서 relation 확률 분포를 산출합니다. 각 relation category r에 대해 visual embedding과 semantic embedding 간 코사인 유사도를 계산하고, class-based 및 description-based prompt에 대해 최종 점수를 계산합니다.
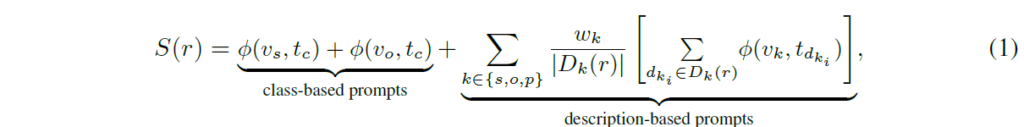
{w}_{k}는 각 {s,o,p} 집합의 component에 대한 visual cues의 중요도이고, D는 relation category r에 대한 visual cues {D}_{k}(r)의 수를 의미합니다. 각 component에 대한 개별 visual cues의 유사성을 계산한 다음 평균을 구합니다. LLM으로 다양한 component에 대한 가중치를 계산한 후 softmax로 모든 relation category들에 대한 확률 분포 점수를 얻게 됩니다. 이어서 살펴보겠습니다.
Visual Cue Descriptions and Weights Generation
GPT와 같은 LLMㅇ느 세상에 대한 전반적인 지식을 가지고 있습니다. 이제 visual cue {D}_{s}, {D}_{o}, {D}_{p}의 description 및 각 relation category component의 weights {w}_{s}, {w}_{o}, {w}_{p} 를 생성하는 과정을 살펴보겠습니다.
Visual Cue Descriptions
relation decomposition을 위한 visual cue의 description 생성하는 과정을 먼저 살펴보겠습니다. Figure (a)에 class-level 관점에서 description을 생성하는 relation class description prompt 의 경우, 해석 및 이해가 용이한 description을 생성할 수 있긴 하지만 지나치게 다양하고 정보가 많은 설명을 생성할 가능성이 있어 의미 있는 시각 단서 추출을 방해할 수 있다고 합니다. 이런 한계를 해결하기 위해 저자들은 또 다른 방법인 relation component description prompt를 고려하는데, 이 방식은 realtion을 subjet와 object component로 분해한 후 각각의 시각적 특징에 대한 설명을 개별적으로 생성하는 방식입니다(Fig. 4(b)). 이런 유형의 프롬프트는 시각 단서에 대해 더 집중적이고 구체적인 설명을 가능하게 해주지만, subject-object category pari 간 시각적 특징 차이를 충분히 포착하지 못할 수 있다고 합니다. 예를 들어, “man-riding-horse”와 “person-riding-bike”는 전혀 다른 시각적 특징을 가질 수 있죠. Figure 4(b)의 말에 대한 visual cue인 “reins”나 “saddle”은 자전거에는 적합하지 않은 cue가 될 것입니다.

이러한 한계를 해결하기 위해 저자들은 “guided relation component description prompt”를 설계합니다. 이 방식은 relation component description 방법을 기반으로, 물체의 상위 카테고리(high-level category) 정보를 description 생성 과정에 반영해 subject와 object component 모두에 대해 보다 정확하고 정보량이 높은 visual feature description을 생성하도록 합니다(Figure 4(c)). 객체를 human, animal, product와 같은 상위 클래스(high-level classes)로 구분하고, 이 구분 결과를 기반으로 prompt 생성을 수행하는 것이죠. 예를 들어 “bike”는 “project”로, “horse”는 “animal”로 구분될 것입니다. 이렇게 구분된 상위 클래스에 따라 각 클래스에 특화된 visual feature description을 개별적으로 생성할 수 있습니다. 예를 들어 “animal”에 관해 “a harness or saddle on its body”와 같은 description이 생성되는 것이죠.
high-level object class 생성 프롬프트는 다음과 같이 사용하였다고 합니다.

Visual Cue Weights
직관적으로 생각해보면 visual cues 조합에 따라 relation 분류에서 중요도가 다르게 적용될 수 있습니다. 예를 들어 “looking at”이라는 relation의 경우 목적어의 visual cue인 “with visible features”보다 주어의 visual cue인 “with eye”가 더 중요한 정보가 될 것입니다. 이런 차이를 반영하기 위해 저자들은 LLM을 활용해 각 visual cue의 분별력(discriminative power)을 분석하고 이에 따라 동적으로 가중치를 할당하는 기법을 적용합니다. 다양한 visual cue 조합을 LLM에 입력 프롬프트로 넣고, 해당 relation(predicate)를 구분하기 위해 각 cue가 가지는 적절한 가중치를 할당하도록 합니다. 이에 사용된 프롬프트는 아래 Figure 5에 나와 있습니다.

Chain-of-Thought (CoT) Prompting.
가중치들이 잘 생성되도록 하기 위해 CoT 기법을 적용합니다. LLM에 “Let’s think step by step!” 라는 단계적 추론 프롬프트를 활용합니다. CoT를 적용해서 가중치를 더 정확히 산출할 수 있다고 합니다.
Experiment
LLM은 GPT3.5-turbo를 사용했고, 백본으로는 ViT-B/32의 CLIP을 활용하였습니다. 모든 실험에서 각 물체에 대한 bbox 및 클래스는 이미 주어지고, 이들의 relation을 분류하도록 하였습니다.
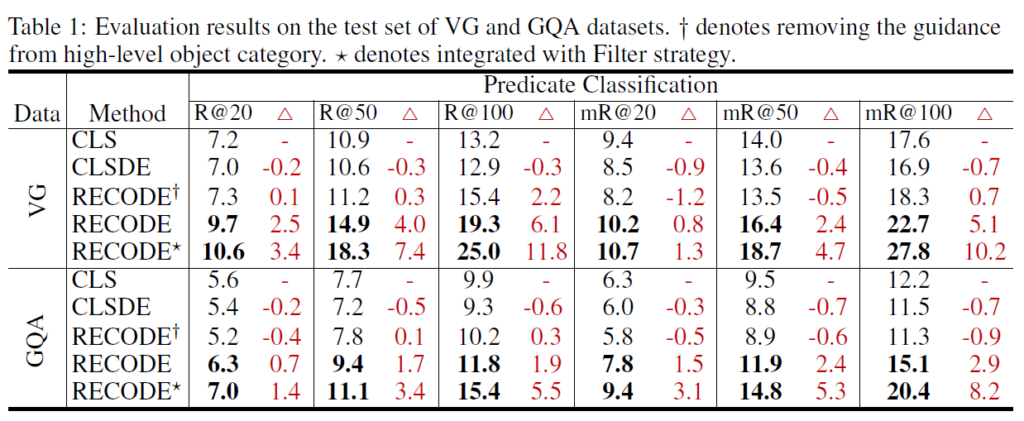
VG 및 GQA 데이터셋에서의 메인 평가 결과, RECODE가 기존 방법론들보다 더 좋은 결과를 보임을 확인할 수 있었습니다. 옆에 십자가는 high-level object category를 활용한 가이드 과정을 제외한 것이고, 별표는 Filter strategory라는것을 추가적으로 적용한 것이라고 하네요.
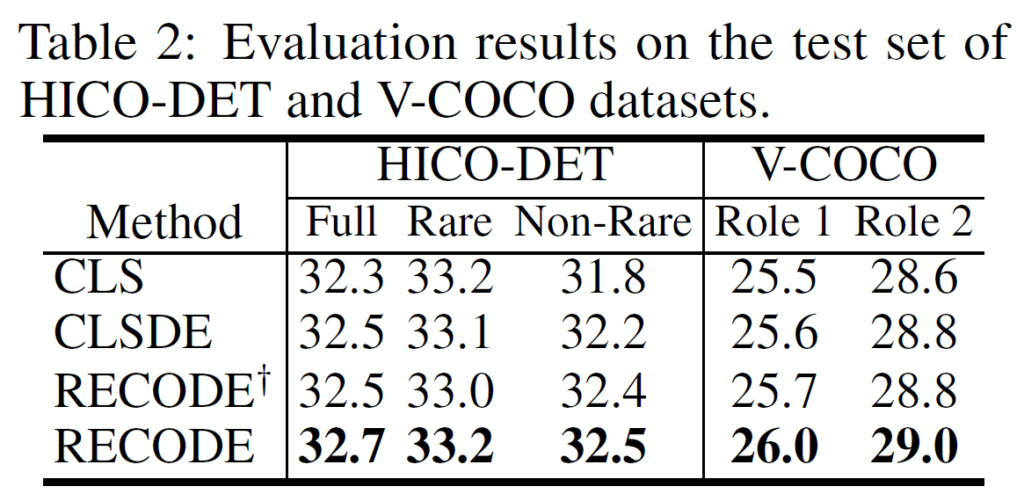
table2에는 Human-Object Interaction 에 해당하는 데이터셋 HICO-DET, V-COCO에서 수행된 실험의 결과입니다. HOI는 <s-p-o> triplet에서 주어가 사람으로 고정된 것이라고 생각하면 됩니다. 해당 벤치마크에서도 RECODE가 좋은 결과를 보여주었습니다.
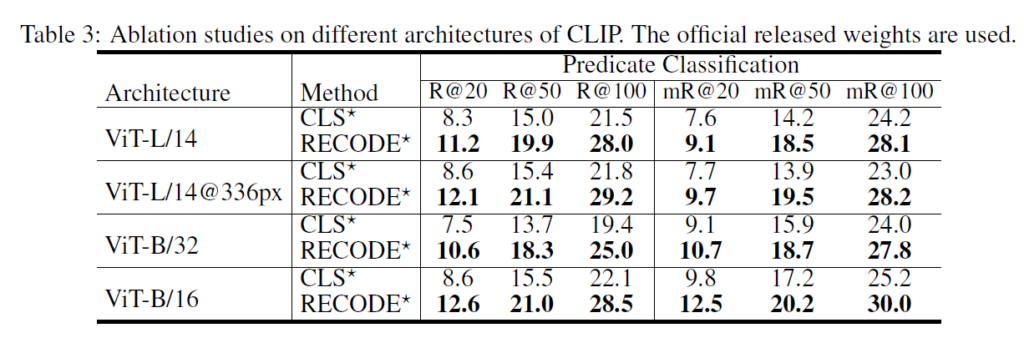
Table3에서는 CLIP 구조의 변경에 따른 성능 차이를 나타내었습니다. 어떤 모델을 사용하든, 기존 방법론보다 일관적으로 성능이 향상되는것을 확인할 수 있습니다.

시각화 결과 확인하고 리뷰 마무리하겠습니다. relation을 구분하는데 중요한 영역을 확인하기 위해 여러 이미지 및 프롬프트에 대한 attention map을 시각화하였는데, class-based prompt의 경우 CLIP이 query prompt와 관계 없는 영역에 집중하는것을 확인할 수 있었습니다. relation이 “growing on”인 경우에도 CLIP이 사람의 몸통에 집중하고 있네요. 저자들은 이런 현상이 프롬프트에 담긴 정보의 부족 때문이며, 이 때문에 visual cue description을 도입하였다고 합니다. 반대로 description-based prompt를 사용하면 CLIP이 비교적 의미 있는 영역에 집중하는것을 확인할 수 있습니다. 예를 들어 relation이 “painted on”일 때 CLIP이 표면의 무늬에 주목하는 것을 확인할 수 있습니다.
predicate에 대한 분별력을 높이기 위해 LLM을 적극 활용한 논문이었습니다. 뭔가 hierarchy를 잘 설정하면 object 분류 성능도 좋아질 것 같긴 한데, 나중에 해당 방향으로도 고민을 해 봐야겠네요.
감사합니다.
안녕하세요 재연님, 좋은 리뷰 감사합니다.
읽다가 질문이 2가지 생겼습니다!
1. 바운딩 박스를 기반으로 shape,size, relative position, distance 4가지 속성 만들어서 유한개의 simulated spatial image와 매칭한다는 것이 잘 와닿지 않아서,, 조금만 부연 설명 가능할까요!?
2. Experiments table 1에서 별표에 해당하는 Filter strategory?는 high-level object category 의 가이드에서 noisy한 가이드를 어떤 handcrafted 과정으로 필터링한 것인가요? 아니면 이 또한 LLM을 활용한 것인가요? 해당 전략으로 가장 sota를 찍은 것으로 보여서 자세한 과정이 궁금합니다!
감사합니다.
1. 해당 과정은 알고리즘 1에 나와있는데, 쉽게 풀어 설명하면 모양, 크기, 위치 등 정보를 활용하여 relation이 될만한 속성들을 미리 정의하고, 전체 relation 매칭 조합(N^2개)에서 relation이 될만한 것들로 추리는 과정이라고 생각함면 됩니다. 의미 없는 것들을 걸러내어 가능한 relation 조합 수를 줄이는 것이죠.
2. 해당 부분의 prompt는 supplementary material에 있습니다. filter strategy는 unreasonable한 sub-pred 및 obj-pred 카테고를 걸러내는 작업입니다. LLM에 고정된 프롬프트(sub-pred, obj-pred 조합이 이상하지 않느냐?)를 넣어서 해당 조합이 reasonable한지 자동으로 판단하여 필터링한다고 생각하시면 됩니다.
리뷰 잘 읽었습니다.
RECODE에서 각 visual cude의 중요도를 LLM 기반 CoT prompting을 통해 예측했다고 하셨는데요
이 과정에서 GT는 사용되지 않고, text-based reasoning으로만 가중치를 산출한 것인지 궁금합니다. 예를 들어 실제 GT label을 기반으로 정답과의 일치 여부를 피드백으로 활용하는 방식이 아니라면, 생성된 weight의 신뢰도를 검증하는 과정은 어떤 방식으로 이루어졌는지도 궁금합니다.
LLM에게 적절한 CoT 프롬프트로 문제를 쪼갠 뒤 할당할 가중치를 생성하는 과정에서, GT같은 것을 사용해 정답과의 비교 및 피드백을 거친다는 언급은 없었습니다. 신뢰도를 검증하는 과정이 따로 없이 LLM의 추론 능력에 의존하게 됩니다.
해당 모듈의 효율성은 ablation에서 다루어집니다. 본문에 포함시키지 않은 table이 몇개 있는데, 그 중 한 table에서 weight 할당을 포함시켰을 때가 그렇지 않은 경우보다 더 좋은 성능 결과를 보여주었습니다.
안녕하세요. 리뷰 잘 읽었습니다.
각 relation class에 대해 관계 정보를 포함한 자연어 클래스 기반 prompt를 생성한다고 되었는데, 궁금한 점은 CLIP 기반이라고 하면 REL과 CLS에서 relation끼리, class끼리 수행되나요? 하나의 예시를 들어 어떻게 수행되는지 알려주시면 감사합니다.
VRG task에는 두 가지 종류의 class가 있습니다. object detection에서 사용하는 object에 대한 class가 있고, 주어-목적어 간 relation(predicate)를 예측하는 relation class가 있습니다. CLIP 기반 OVOD 모델이 물체의 region proposal 영역을 crop해서 CLIP image encoder를 태운 visual feature와 ‘a photo of [CLS]’라는 프롬프트와의 유사도를 비교해서 분류를 하는 것처럼, relation class도 subject, object bounding box 영역의 합집합 영역을 VLM 모델에 입력하여 얻은 visual feature와, 특정 relation class에 대한 프롬프트 “[REL-CLS]-ing/ed” 같은 것에서 추출한 text feature 간 유사도를 비교해서 Open-Vocabulary relation classification을 수행할 수 있습니다. object는 object class끼리, relation은 relation class끼리 유사도 비교를 통한 분류를 수행하는 것이죠.