Abstract
저자들은 Human Object Interation 이미지(=exocentric 이미지)와 물체 중심의 이미지(=egocentric 이미지)를 weakly supervised 방식으로 학습하는 affordance grounding 연구를 제안합니다. 기존 연구는 affordance 카테고리에 대한 activation map을 이용하는 방식을 주로 사용하였으며, 이러한 방식은 효율적이지만 행동과 기능에 대응되는 정확한 위치를 알 수 없다는 한계가 있습니다. 저자들은 foundation model을 이용하여 pusedo label을 생성하는 파이프라인을 개발합니다. pseudo label은 affordance에 대응되는 부분으로 매핑을 따라 part segmentation 모델을 이용하여 생성되며, 베이스라인 모델에 (1)label refining stage, (2)fine-grained feature alignment process, (3)경량화된 reasoning 모듈을 도입하여 affordance grounding 성능을 개선합니다. 이러한 개선을 통해 객체와 행동 사이의 간극을 효과적으로 줄이고자 하였으며, 다양한 실험을 통해 제안된 모델의 성능이 기존 방식에 비해 성능을 크게 개선 시켰음을 보입니다.
Introduction
affordance grounding은 어떤 action을 수행하기 위해 상호작용이 일어날 물체 영역을 찾는 것을 목표로 합니다. 이는 시각인지와 로봇 조작을 연결하기 위한 연구 분야 중 하나로, 에이전트가 물체에서 집중해야할 영역에 대한 정보를 제공하여 작업에 특화된 상호작용 및 grasping을 할 수 있도록 합니다.
연구 초기 fully supervised 세팅은 semantic segmentation 방식을 이용하였으며, 학습된 데이터 셋에서는 좋은 성능을 보였으나, 다양한 행동과 물체로의 확장이 불가능하였으며, 학습에 사용된 affordance도 10개 이하로 제한적이었습니다. 이는 픽셀 수준의 라벨링에 많은 cost가 소요될 뿐만 아니라 대응되는 영역을 결정하는 것에도 주관적이고 모호함이 존재하기 때문입니다. 따라서 더 실용적인 weakly supervised 세팅이 점차 주목을 맏게 되었으며, 이러한 세팅은 학습 데이터에 이미지 수준의 라벨만이 제공되고 평가 시 물체 이미지(egocentric 이미지)에서 affordance에 대응되는 heatmap을 예측하는 방식으로 이루어집니다. 또한, 각 이미지와 affordance에 물체가 사용되는 exocentric 데이터가 함께 제공되며, 이러한 이미지를 통해 암시적으로 affordance를 학습할 수 있도록 합니다. 따라서 모델은 물체가 사용되고 있는 영상인 exocentric 데이터로부터 얻은 지식을 물체 중심의 영상인 egocentric 이미지로 효과적으로 전이하는 것이 중요합니다. 이러한 weakly supervised 세팅은 데이터 셋의 확장 측면에서 굉장히 유리할 뿐만 아니라, 사람의 인지 과정과 유사합니다.
이러한 weakly supervised affordance grounding(WSAG) 연구는 affordance에 대한 classification을 학습한 뒤, CAM(class activation maps)을 이용해 affordance 영역에 대해 예측하는 방식으로 이루어졌습니다. 그러나 이러한 방식은 한정된 affordance만을 인식할 수 있으며, 정확한 영역에 대한 가이드를 제공하지 않으므로 affordance에 대응되는 영역을 정확히 예측하지 못한다는 한계가 있습니다. 근본적으로 affordance는 존재하는 외관 정보라기보다, 가능한 잠재적인 영역에 가깝기 때문에, 동사(verb)에 대하여 지도학습 방식으로 접근하는 것에는 어려움이 있습니다. 일부 연구는 exocentric 이미지를 이용하여 다양한 객체 인스턴스와 배경를 반영하는 방식에 대한 연구를 수행하였습니다. 이러한 방식은 exocentric 이미지와 egocentric 이미지로부터 구한 feature의 align을 맞춰 지식을 확장하는 방식으로 이루어졌으나 affordanc와 무관한 노이즈가 포함될 수 있다는 한계가 존재합니다.
최근 VFMs와 MLLMs이 발전함에 따라, zero-shot 방식으로 dense annotation을 생성하고자 하는 시도들이 있었으며, 해당 연구에서도 이러한 foundation 모델의 지식을 활용하고자 합니다. 구체적으로, 행동과 관련되 affordance 클래스에 대해 object/part 쿼리로 매핑을 생성한 뒤, 이러한 쿼리를 사용하여 egocentric 이미지에 pseudo label을 생성합니다. 이렇게 생성한 pseudo label을 이용하여 WSAG에 적용하는 방식으로, 이러한 방식은 불완전한 라벨에 대하여 overffiting이 될 수 있다는 한계가 존재합니다. 따라서 저자들은 overfitting을 방지하고, 성능을 최적화하기 위해 baseline 방식에 추가적인 모듈을 도입하며, 학습 set에서 exocentric 이미지도 활용하는 cross-view feature alignment 학습 방식을 제안합니다. 기존 연구와 다르게 VFMs를 다시 사용하여 상호작용이 일어나는 물체 영역에 집중하고, 이때 exocentric 이미지에서 사람에 의해 occlusion이 발생하는 것을 단서로 활용합니다. 이를 통해 label을 정제하고, unseen 객체에 대해서도 이해할 수 있도록 경량화된 추론 모듈을 통합합니다.
해당 연구의 contribution을 정리하면
- 최신의 VFMs를 이용하여 affordance heatmap을 생성하는 파이프라인을 제안하며, WSAG에 최초로 psuedo-supervised training 프레임워크를 도입( 제가 이전에 리뷰한 AffordanceSAM도 pseudo label을 생성하는 방식이기는 하지만, 해당 논문은 2025년 1월 23일에 공개된 논문으로 2025년 4월에 공개된 ,AffordanceSAM보다 먼저 공개된 논문입니다.)
- pseudo label refine 과정, exocentric 이미지와의 object feautre alignment 방식, 일반화 능력을 개선하기 위한 추론 모듈 도입 등을 통해 베이스라인 성능 개선
- 실험을 통해 제안한 방식들에 대한 효과를 검증
Method
0. Task Formulation
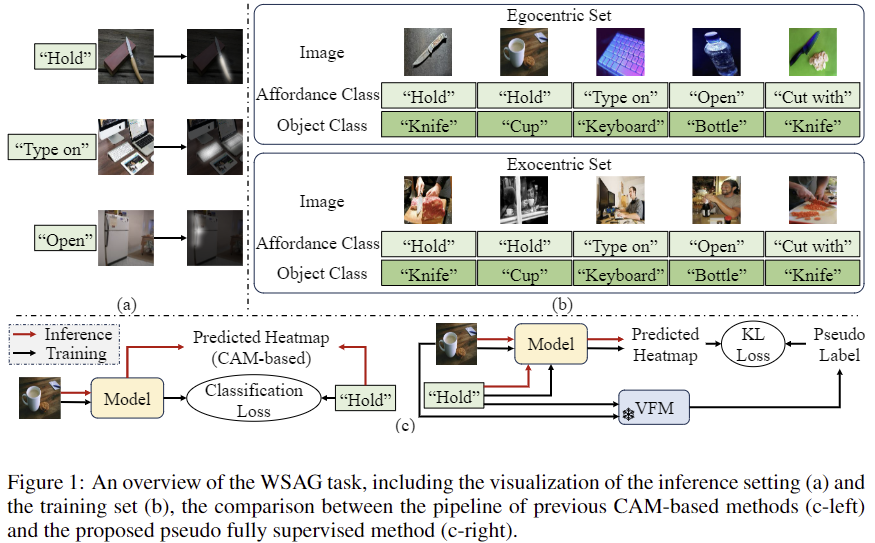
기존 WSAG 세팅을 따라 학습에는 egocnetric 이미지 I^{ego}와 exocentric 이미지 I^{exo}를 이용하며, 각 이미지에는 object label o와 affordance label a이 주어집니다. inference시에는 egocentric 이미지와 affordance가 주어지고 이에 대한 hetamap H를 생성하는 것을 목표로 합니다.
1. Model Architectre
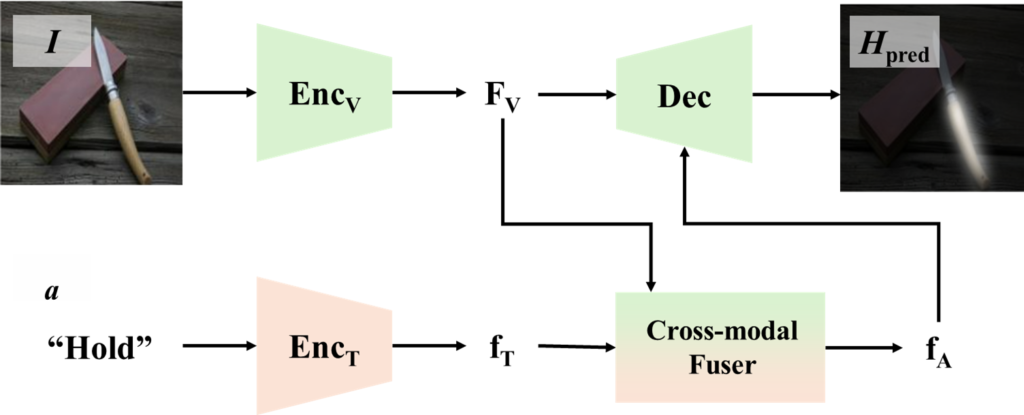
모델의 구조는 위의 그림과 같습니다. CLIP ViT/16의 visual encoder와 text encoder를 이용하여 두 모달리티의 정보를 인코딩하여 visual feature F_v와 affordance에 대한 feature vector f_T를 구합니다. 이후, cross-modal fuser를 통해 두 데이터 사이의 정보를 교환하여 feature vector f_A를 생성합니다. 여기서 cross-modal fuser는 text feature를 쿼리로, 이미지 feature를 key와 value로 사용하여 cross attention을 수행하는 여러개의 transformer 블록입니다. 마지막으로 생성된 f_A와 F_v를 Decoder에 입력하여 affordance에 대한 heatmap H_{pred}를 예측합니다. 이때, Decoder는 SAM의 mask decoder를 사용하였다고 합니다.
2. Generating Pseud Labels
VFMs를 이용하여 pseudo label H_{pl}을 만든 뒤, 이를 이용하여 affordance grounding 모델을 학습하기 위해 pseudo label을 만드는 과정입니다. 이 과정에는 grounding 대상을 결정하고 grounding을 수행하는 2 단계로 구성됩니다.: (1) object class와 affordance class에 대하여 part 정보를 매핑하고, (2) pseudo label을 생성합니다.
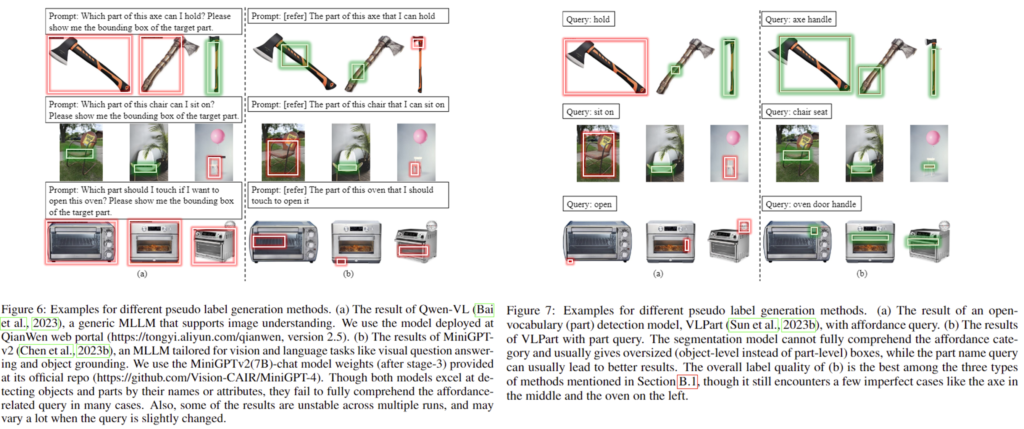
++ 추가로 저자들이 매핑을 설정한 뒤 affordance에 대한 pseudo-label을 생성한 이유에 대하여 설명하기 위해 appendix에 있는 pseudo label 관련 실험 내용을 가져와보았습니다. 저자들은 pseudo-label을 생성하는 3가지 방식에 대하여 실험을 진행하였으며, 위의 그림이 이에 대한 결과로, 빨간색은 잘못 예측된 예시, 초록색은 잘 예측된 예시입니다. (1) multi-modal LLM을 직접 이용하는 방식은 Figure 6의(a)에 해당하는 결과로, 불안정하며, 프롬프트에 민감하다는 한계가 있습니다. (2) detection에 특화된 foundation model을 이용하는 방식은 Figure 6의 (b)에 해당하는 결과로, affordance를 잘 이해하지 못하는 경향이 있습니다. (3) label mapping을 결합한 detection 방식은 Figure 7에 해당하며 (a)는 part detection model에 대한 결과이고 (b)가 mapping을 이용하여 part 정보가 주어졌다고 가정하였을 때의 예측 결과입니다. 저자들은 이에 대한 실험 결과를 통해, mapping을 이용하여 part에 대한 정보를 함께 VFM에 제공하는 방식이 적절하다는 것을 설명합니다.
우선, visual model은 의미론적 정보(명사-형용사)에 대하여 이해를 잘 하고 있으나, affordance는 동작이나 기능(verb)를 지칭하므로 신뢰할 수 있는 pseudo label을 얻기 위해 직적으로 affordance를 이용하기에는 어려움이 있습니다. 또한, 객체에서 affordance에 대응되는 영역은 일반적으로 객체의 특정 영역이며, 하나 혹은 여러 영역이 대응될 수 있습니다.
따라서 저자들은 매핑 P(o,a) = p을 설정합니다. 즉, object 클래스와 affordance 클래스가 주어졌을 때, 대응되는 part의 이름 p를 매핑시키는 것으로, part의 이름은 기존 foundation model에서 쉽게 이해할 수 있습니다. 예시를 들면, P("knife","hold")="handle of the knife"가 되는 것 입니다. 이러한 part name 매핑 P는 LLM의 광범위한 상식을 통해 구현할 수 있으며, 해당 논문에서는 object와 affordance 관계가 약 100개이므로 수동으로 설정해주었다고 합니다. (연구 방향으로 affordance에 대해 조금 더 세부적인 정보를 추가하는 방식을 고민하고 있는데, 해당 연구와 비슷한 관점인 것 같습니다.)
그 다음, part-level의 grounding을 위해 GroundedSAM을 이용합니다. GroundedSAM은 text 입력이 의미하는 객체의 부분에 대하여 VLpart를 이용하여 bounding box를 생성한 뒤, 생성된 bounding box를 프롬프트로 이용하여 SAM으로 segmentation mask를 생성하는 방식으로 이루어집니다. 저자들은 SAM이 배경을 전경으로 오인하는 문제를 고려하고자 segmentation mask를 생성한 뒤, 이를 heatmap으로 변환하는 방식을 활용하였다고 합니다.
그러나 이러한 방식으로 생성된 pseudo label은 VLpart가 part에 대한 정보가 아닌 물체 전체에 대한 bounding box를 제공하는 문제가 발생할 수 있고, 일부 affordance는 part로 정의하기 어려워 VLpart에 대하여 정확한 text 정보를 제공할 수 없는 경우가 발생할 수 있습니다. 따라서 이러한 부정확한 pseudo label을 이용하기 위해 베이스라인 모델을 개선합니다.
3. Aligning with Exocentirc Features
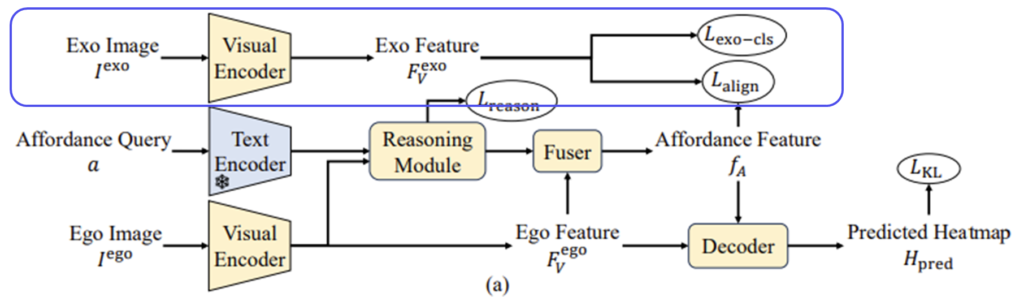
해당 논문에서는 exocentric 이미지를 활용하여 feature 학습 과정을 정규화합니다. egocentric 이미지와 동일한 object와 affordance 클래스를 가진 exocentric 이미지에 대하여 EncV를 통해 feature F^{ego}_V와 F^{exo}_V를 추출합니다. 이 두 feature를 결합하기 위해 기존의 일부 연구는 global average pooling을 적용하여 두 feature를 정렬하는 방식을 사용하였으나, 이러한 방식은 사람이나 배경 정보가 포함된다는 한계가 있습니다. 따라서 이러한 노이즈로 인해 alignment 과정에 혼동을 줄 수 있어, 이후 특정 영역에 대한 feature로 제한하기 위해 heatmap을 이용하는 연구가 이루어졌습니다. 그러나 WSAG는 예측된 mask에 대한 직접적인 GT 정보가 없으므로, 실제 대상 객체에 초점을 맞추고있다는 보장을 할 수 없습니다.
따라서, 저자들은 앞서 pseudo label을 사용할 때 이용한 방식을 통해 object 라벨과 exocentric 이미지를 입력하여 object mask M^{exo}_{obj}를 생성합니다. 이후, 생성된 마스크 영역에 해당하는 feature들에 대하하여 average pooling을 수행하는 masked average pooling을 통해 feature f_{E}를 얻습니다. 이 feature는 object에 대한 feature라고 생각하시면 됩니다. 이후, groundint 대상과의 align을 맞추기 위해, f_A와의 cosine similarity를 이용한 loss를 구합니다. 해당 과정은 아래의 식(1)과(2)로 표현할 수 있으며, 이때 f_E는 stop gradient를 적용하여 egocentric한 이미지를 학습하도록 합니다.
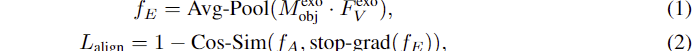
또한, exocentric 이미지의 object 영역에 대한 feature f_E에 affordance 정보를 포함시키기 위해 간단한 classification head Headexo를 도입하여 cross-entropy loss를 통해 함께 학습합니다. (아래의 식 (3) 참고. \hat{a}는 one-hot-encoding 된 affordance를 의미합니다.)
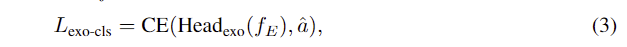
이러한 feature alignment과정에 기존 연구들은 하나의 egocentric 이미지에 대하여 다수의 exocentric 이미지를 함께 학습에 사용하였으나, 저자들은 여러 exocentric 이미지를 사용하는 것의 이점이 없다고 생각하여 한쌍의 egocentric-exocentric 데이터만을 활용하여 연산의 부담을 줄이고자 하였습니다. 또한, 동일 카테고리의 object에 대하여 가장 유사한 외관을 가진 exocentric 이미지를 활용하기 위해, exocentric 이미지와 egocentric 이미지에 대하여 object 영역에 대한 mask를 생성한 뒤, masked average pooling을 적용한 feature 사이의 cosine similarity score를 계산하여 가장 유사한 한 쌍을 결정하였다고 합니다.
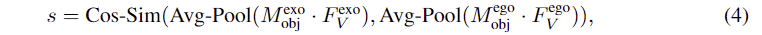
이러한 필터링 과정을 통해 관련 없는 정보를 제거하여 feature alignment가 affordance 지식 전이에 더 집중할 수 있도록 하였으며, 유사도 계산과 가장 유사한 쌍을 찾는 과정은 오프라인으로 수행 가능하여 학습에 연산 부담이 증가하지 않음을 어필합니다.
4. Refining Pseudo Label
추가로, 저자들은 exocentric 이미지를 사용하여 feature alignment 말고도 pseudo label에 대한 refinement를 수행합니다. 먼저 위의 Figure 1에서 확인할 수 있둣, exocentric 이미지는 사람과 물체가 상호작용하는 이미지로, 일반적으로 사람의 신체에 의해 occlusion이 발생합니다. 저자들은 이러한 단서를 이용한 새로운 pseudo label refinement 과정을 제안합니다.
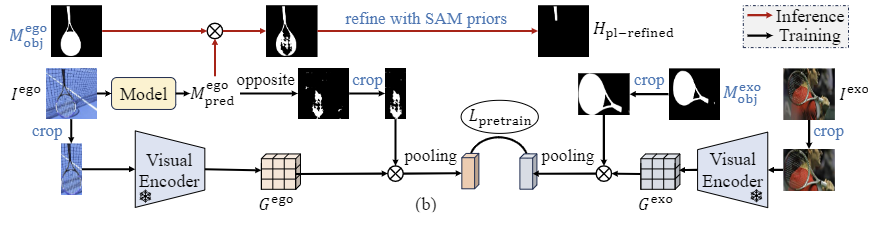
앞서 제안한 베이스라인 구조에서 마지막 softmax 레이어가 sigmoid로 바뀌어 egocentric 이미지에 대하여 mask M^{ego}_{pred}를 생성합니다. 이후, egocentric 이미지와 exocentric이미지에 대하여 각각 VLpart를 적용하여 object 영역에 대하여 bounding boxb^{ego}, b^{exo}를 구하여 crop하고, 이후 별도의 freeze된 feature extractor Enc’V(ClIP혹은 DINO encoder)를 적용하여 feature map G^{ego}와 G^{exo}를 구합니다. 여기에 저자들은 의미론적 유사도를 기반으로하는 Lpretrain 를 제안하여 네트워크를 학습시킵니다. Lpretrain 는 아래의 식 (6)으로 정의됩니다.
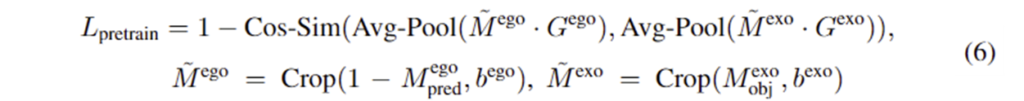
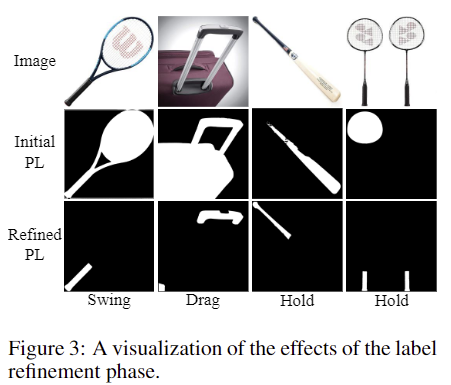
여기서 M^{ego}_pred는 affordance 영역을 구분할 수 있다면, \tilde{M}^{ego}는 객체의 나머지 부분이며, masked object feature \tilde{M}^{ego}\cdot G^{ego}는 affordance 외의 영역들에 대한 유사도를 측정하는 것으로, exocentric 이미지는 사람이 물체와 상호작용하다보니 발생하는 occlusion을 반영한 loss를 설계한 것입니다. 여기에 SAM의 Auto-mask Generation(그리드방식으로 sam을 적용하는 것)을 사용하여 이미지로부터 segment들을 구한 뒤,M^{ego}_pred \cdot M^{ego}_{obj}와 겹치는 면적이 가장 큰 segment를 선택하여 최종적으로 refine된 pseudo label H_{pl-refined}ㄹ르 구합니다. 이에 대한 예시는 아래의 Figure 3에서 확인할 수 있으며, affordance에 대해 전체 물체 영역이 아니 특정 부분에 대한 segment로 구성된 것을 확인할 수 있습니다.
5. Handling Unseen Object
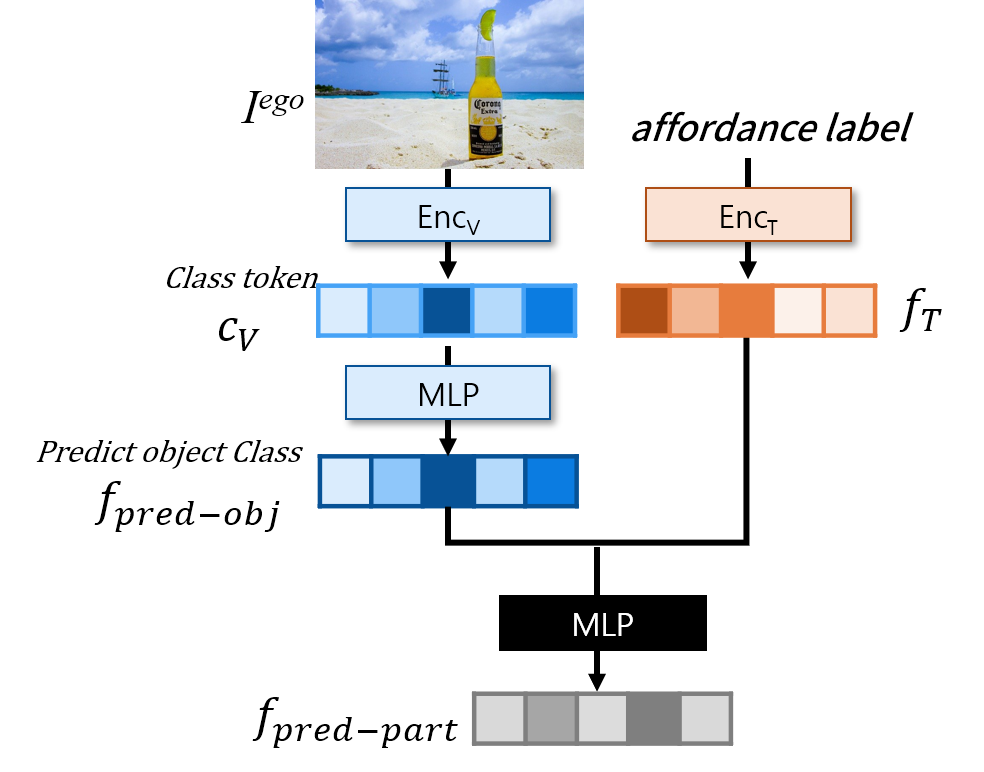
여전히 한정된 데이터로 인해 unseen object로 일반화에는 어려움이 있습니다. 따라서 저자들은 object와 affordance 사이의 관계를 추구하는 데 명시적으로 도움이 되는 간단하고도 효과적인 reasoning 모듈을 제안합니다. reasoning 모듈은 egocentric 이미지의 object label을 EncT에 통과시켜 class token c_V를 구한 뒤, 이를 얕은 MLP로 입력하여 object class feature f_{pred-obj}를 예측하도록 합니다. 그 다음, 다른 MLP에 예측된 object class와 affordance 쿼리 주어졌을 때, part feature f_{pred-part}를 예측합니다. Lreason loss는 f_{pred-obj}와 object에 대한 visual feature 사이의 cosine 유사도, f_{pred-part}와 part에 대한 text feature 사이의 cosine 유사도를 통해 학습을 수행하며, 아래의 식 (7)와같이 정의됩니다. 이러한 loss를 도입하여 통해 affordance text에 대한 feature인 f_T에 part에 대한 정보가 포함되며, latent feature의 형태로 표현되어 part에 대해 표현하기 어려운 affordance 영역을 처리하는 데 용이해집니다. (논문 수식을 가져왔는데, 논문에서 o와 p의 위치가 바뀐 것 같습니다..)
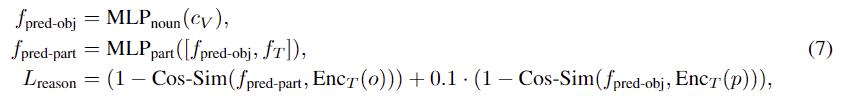
마지막으로 예측된 affordance에 대한 heatmap 학습을 위해 H_{pl-refined}와 분포에 대한 오차를 구하는 LKD를 포함하는 total loss를 계산하여, 전체 모델을 학습시킵니다.
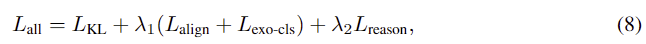
또한, 하나의 object에 대하여 한정된 affordance가 주어질 경우 affordance에 대한 text feautre를 완전히 활용하지 못하는 경우가 발생합니다. 따라서 저자들은 대상 이미지와 다른 object에 대한 egocentric 이미지 랜덤하게 3개 골라 2×2 형태로 붙이는 stiching augmentation을 제안하여 이미지 뿐만 아니라 text 정보에도 집중할 수 있도록 하였다고 합니다.
Experiment
실험에는 AGD20K를 사용하였으며, 평가지표는 KLD, SIM, NSS를 사용하였습니다. (이에 대한 자세한 설명은 이전 X-review를 참고해주세요.)
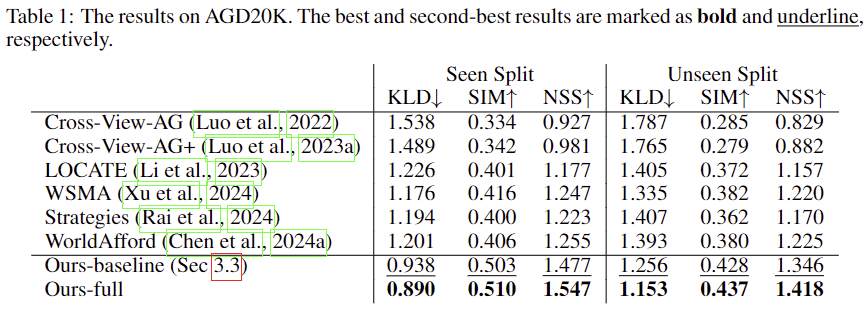
위의 Table 1은 기존 연구와 비교한 AGD20K에서의 정량적 성능으로, 상당히 개선된 성능을 보입니다. 참고로 제가 최근에 리뷰한 AffordanceSAM보다도 성능이 좋은 것으로 보입니다. 기존 연구들은 heatmap에 대한 pseudo label을 생성하지 않는 방식으로, pseudo label을 이용한 지도학습 방식을 적용하므로써 성능이 크게 개선되었음을 어필합니다. 또한, 아래의 Figure 4는 heatmap을 시각화 한 결과로, 저자들이 제안한 방식이 더 정확하고 특정된 영역에 집중하는 heatmap을 생성하는 것을 확인할 수 있습니다. 추가로, Unseen에 대한 결과도 함께 리포팅하여 해당 연구의 효과를 입증하였습니다.

Ablation study
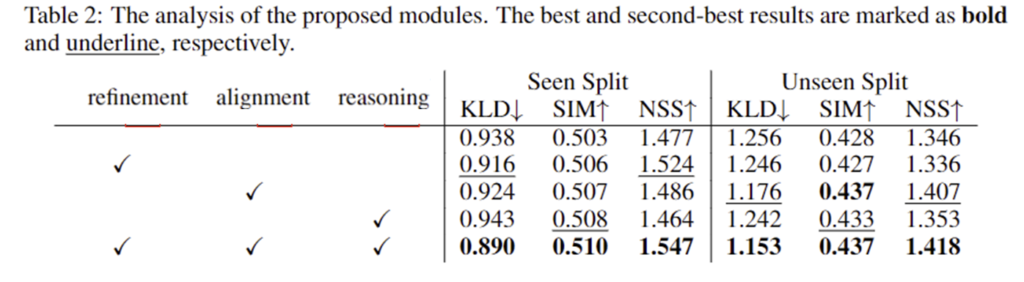
Table 2는 해당 논문에서 제안된 방법론들에 대한 ablation study결과입니다. seen split의 경우 label refinement 과정과 feature alignment 과정 모두 성능 개선을 일으켰으나, reasoning 모듈에서는 큰 이점이 없는 결과를 확인할 수 있습니다. 그러나 unseen split에 대한 결과를 확인하시면, reasoning을 통해 성능이 개선이 일어났음을 확인할 수 있습니다. 또한, unseen split에서는 exocentric 이미지와의 feature alignment를 통해 상당한 성능 개선이 이루어짐을 확인하였습니다. 또한, 모든 제안 사항을 적용할 경우 가장 좋은 성능을 보인다는 것을 확인할 수 있습니다.
Real-world application
마지막으로 저자들은 제안한 방식의 일반화 성능을 확인하기 위해 학습된 affordance grounding 모델과 grasp planning 알고리즘을 결함하여 로봇 팔로 실험을 진행하였습니다. RGB 이미지에서 affordance grounding을 적용하여 heatmap을 생성한 뒤, heatmap의 확률이 가장 높은 poit에 대한 pose를 선택하여 grasping을 수행합니다. 아래의 Figure 5는 이러한 실험에 대한 몇가지 예시로 실험 세팅/grasping 알고리즘으로 구한 그리퍼 pose들/affordance로 찾은 그리퍼 pose에 대하여 시각화 한 결과입니다. 냄비와 숟가락을 잡기 위해 (a- 냄비, b-숟가락) 예측된 그리퍼의 pose들이 학습에 보지 않은 affordance인 “grasp”에도 적절한 위치를 찾는 것을 확인할 수 있습니다.

안녕하세요 승현님 리뷰 감사합니다.
CAM에 무지한 상태라 간단하게 찾아보고 읽었는데, 결국 CAM 기반 방법들이 가지던 문제를 해결하기 위해서 Part개념을 도입해서 Part Mapping과 이를 더 정확하게 만들기 위해서 exocentric 이미지들을 활용한 연구라고 이해했습니다. 더 나아가 unseen object들에 대한 성능개선도 실험으로 보여진 논문의 핵심적인 과정중에 하나라고 생각 하는데, part를 이해시키는 과정을 통해서 개선한걸까요? 직관적으로 와닿지가 않아서 질문드립니다!!
또 Part Mapping 같은 경우 혹시 자동화는 불가능한건지 궁금합니다!!
질문 감사합니다.
unseen에 대한 성능 개선이 어떻게 이루어졌는지에 대한 질문이 맞으실까요? 저자들은 text feature에 대한 집중을 통해 이를 개선하였다고 합니다. 해당 내용이 누락되어 리뷰에 다시 추가하였습니다.
또한, part mapping의 자동화에 대해서는 리뷰에 언급하였뜻이 LLM으로 구현하는 방식을 통해 자동화가 가능합니다. 그러나 저자들은 그 수가 적어 수동으로 라벨링을 하였다고 합니다. LLM으로 자동화 가능한지에 대해서는 저도 따로 실험해보려합니다. 감사합니다.
안녕하세요 승현님, 좋은 리뷰 감사합니다.
LLM으로 Part name mapping한거랑, Aigning with Exocentric Features가 핵심인 것 같습니다.
특히 exocentric 이미지의 occlusion을 잘 활용해먹은 점이 신선했습니다. 하긴 생각해보면 affordance란 건 결국 사람이 손으로 집어야되는 부분이 절대적으로 많으니까요. 그걸 사용해서 pseudo label refinement했다는 것이 제일 큰 contribution이 아닐까 생각합니다.
그런데 보다보니 의문점이 생겼는데 제가 뭔가 해당 파이프라인을 잘못이해한 걸 수도 있는데, Refining을 위한 작업에서 왜 앞서 활용했던 text encoder에서의 encoding된 어떤 feature를 추가적인 refining 도구로 활용할 생각을 안했을까요? affordance는 text적인 속성에도 꽤나 핵심적인 feature들을 담고있으니 더 도움이 되지 않을까란 생각이 드는데, 모두 visual적인 정보로만 어찌저찌 refining해서 쇼부보려고 한 것 같아보여서요.
질문 감사합니다.
pseudo label에 대한 refinement 과정에서 affordance 정보를 활용하지 않응 이유에 대해 질문하신 것이 맞을까요? 우선 제가 affordance 관련 연구들을 찾아보았을 때, 현재의 VLM은 “visual”정보와 “affordance” 정보를 매칭시키는 데 어려움이 있는 상태라고 생각합니다. 이러한 이유로 해당 논문의 저자들은 두 정보를 연결하기 위해 물체의 “part” 정보를 활용합니다. 즉, 시각적 affordance 영역 추론에 도움이 되는 text affordance feature를 추출하는 것 부터가 아직 어려운 상태라고 이해하시면 될 것 같습니다.
안녕하세요, 좋은 리뷰 감사합니다.
매핑하는 부분에서 궁금한게, egocnetric 이미지와 exocentric 이미지 중 어떤 이미지에서 수행되는 것인가요 ?? 그리고 part의 이름을 출력하는 foundation model의 결과 자체는 따로 고려하지 않는걸까요 ? 가령 “knife”와 “hold”가 같이 들어왔을 때 handle이 아니라 다르게 파트를 지칭했을 때, 즉 아예 틀리지는 않는데 다른 표현을 사용하였을 때 모델에 영향을 미치진 않는지가 궁금합니다.
감사합니다.
질문 감사합니다.
매핑은 이미지를 사용하지 않고, text 수준에서 진행됩니다. object와 affordance가 주어졌을 때, 그 사이를 part 정보로 연결하는 것이 목표입니다. 저자들은 llm의 상식을 활용하여 part 정보를 추론할 수 있다고 이야기하면서도 수동으로 라벨링을 합니다. 따라서 모델의 출력에 따라 표현이 달라지는 점에 대해서는 따로 고려하고 있지 않습니다. 해당 부분에 대해서는 저도 영향이 있을 것 같다는 생각이 들기도 하지만, unseen에 대한 실험 결과를 통해 의미론적으로 유사하지만 다른 표현인 경우에도 어느정도 작동함을 보인 것으로 보입니다.
안녕하세요. 리뷰 잘 읽었습니다.
Pseudo-label을 만드는 이유에 대해 (1) multi-modal LLM을 직접 이용하는 방식이 불안정하다고 말씀해주셨는데, 이는 (a)를 보면 입력마다 결과가 다르게 나온다는 말일까요? 그 불안정하다는 것이 MLLM에서 결과를 택할 때 확률적으로 택하는, 그 이유가 불안정하다고 표현되어있을지가 궁금합니다.
질문 감사합니다.
MLLM 결과가 특정 물체에 대한 affordance는 잘 예측하지만, 전자레인지의 손잡이는 아예 못찾는 등의 상황을 보고 불안정하다고 표현한 것 같습니다. 최근 VLM을 사용하는 affordance 분야의 논문들이 물체 수준의 정보는 많은 데이터로 학습하여 높은 성능을 갖추지만, affordance라는 주관적인 영역에 대한 정보는 이해하는 데 어려움이 있다는 것을 어필합니다. 이러한 주장을 한 것으로 이해하시면 될 것 같습니다.