안녕하세요. 이번 논문은 Online Continual Learning, 즉 Incremental Learning 과 관련된 논문입니다. 특히 embodied agent 혹은 로봇 에이전트를 그 대상으로 두고, 앞으로 이 agent가 세상을 탐색하고 인지하면서 지속적으로 학습해나가야 한다는 점을 고려할 때, 그것의 현실성, 실현가능성을 중점으로 두고 점진적 학습법을 행동 중심, 환경 중심으로 나누어 생각해 본 논문입니다.
현재 제가 고민하고 있는 연구 주제는, 로봇이 Long-horizon Task에 대한 복잡한 명령을 지시 받았을 때, 이것을 어떻게 high-level 단위의 서브작업으로 잘 쪼갤 것이냐 를 고민 중인데, 이 때 로봇이 자신이 가지고 있는 primitive한 low-level skill(하나의 간단한 동작을 완벽히 수행하는 강화학습, 모방학습, 혹은 motion planning 기반의 policy라고 가정하겠습니다.)을 어떻게 조합해서 작업을 분류해 볼 것이냐입니다.
그런 관점에서 skill-based의 task decomposition이라는 키워드로 찾았던 논문 중에 하나가 저번 주에 리뷰에 작성했던 Bootstrap Your Own Skills였는데요. 그런데 해당 논문 리뷰해보고 나니, 어찌보면 skill이란 요소가 Incremental Learning과 밀접하게 관련있다는 생각이 들었습니다. 원래 제가 고민하고 있는 주제와는 방향이 좀 다른 길로 새는 것 같긴 한데요. 그럼에도 제가 훗날 원하는 로봇의 모습은 마치 어린 아이가 성장해가면서 다양한 행동 양식을 배워나가듯이, 결국 로봇이 가진 이 primitive motion들 또한 점진적으로 어떤 skill library 처럼 쌓여가는 형태여야하지 않을까 생각도 듭니다. 그러다보니 Agent 중심의 Incremental Learning 태스크를 좀 알아두면 좋지 않을까 생각이 들었고, 해당 논문이 Agent의 High-level Planning 과 관련된 많은 연구를 할 수 있게 한 ALFRED라는 벤치마크를 기반으로 했기도 하면서, 서울대, 연세대 연구원분들이 작성하셨던 논문인지라 관심가지고 한 번 읽어보았습니다.
서두가 길었습니다. 리뷰 시작하겠습니다.
1. Introduction
최근 컴퓨터 비전, 자연어 처리, embodied AI 분야에서의 발전은 다양한 로봇 에이전트를 위해 Navigation, Object Interaction, Interactive Reasoning 등 관련된 벤치마크들을 만들어냈습니다. 특히 저 3가지를 모두 고려한 복합적인 언어 instruction 기반의 고난이도 태스크를 수행하는 벤치마크인 ALFRED(Shridhar et al., 2020)와 같은 벤치마크도 탄생했는데요.
그러나 대부분의 embodied AI 연구들은 해당 벤치마크를 사용해도 모든 학습 데이터를 학습 초기에 한 번에 주어진다고 가정합니다. 이는 실제 로봇 시스템에서 현실적이지 않을 수 있었습니다. 왜냐하면 로봇 에이전트는 실제 환경에 사용되기 위해 deployment된 이후에도 어떻게든 새로운 행동이나 환경을 만날 수 있기 때문이죠.
새로운 작업(task)을 학습하기 위해 일반적인 접근법은 에이전트를 finetuning 하는 것일 수 있겠지만, 이는 기존에 학습한 지식을 catastrophic forgetting 하는 문제가 있습니다. 이를 완화하기 위해 CORA(Powers et al., 2022)라는 논문은 점진적으로 에이전트를 업데이트하며 과거와 현재 작업을 모두 평가할 수 있는 Continual Reinforcement Learning 프레임워크를 제안했었는데요. 하지만 이 또한 ALFRED(Shridhar et al., 2020)의 단순화된 태스크 설정에서 동작하며, 자연어 이해나 객체 위치 인식은 제외하고 있었습니다.
저자들은 그래서 먼저 이러한 한계를 넘어서 실제 환경에서 instruction following task 를 수행할 수 있는 continual learning 기반 프레임워크 두가지 시나리오로 나눠서 제시했습니다.(method에서 더 설명하겠습니다.)
또, 기존 Continual Learning 연구들에서는 보통 이전 태스크의 모델이나 데이터 정보를 저장하여 과거 지식을 유지하려 했지만, 이는 막대한 저장 공간을 요구했습니다. 그래서 이를 해결하기 위해 이전 모델의 로짓(logits)만 저장하는 방식으로 지식 증류를 제안하는 방법론이 나오고 저장 효율성을 개선하는 성과가 있었지만 이것 또한 문제가 있었습니다. 저장된 로짓이 초기 학습 단계에서 불충분하게 학습된 상태일 수 있으며, 많은 방법들이 task boundary 정보에 의존하는데, 실제 환경에서는 이런 정보가 명시되지 않은 연속된 스트림 데이터로 주어질 수 있었습니다.
이러한 문제들을 해결하기 위해, 저자들은 Confidence-Aware Moving Average (CAMA) 를 제안했습니다. 이는 과거에 저장된 로짓과 현재 학습된 로짓을 이동 평균 방식으로 결합하는 방식인데, 이동 평균의 가중치 계수는 분류 신뢰도(confidence score)에 따라 동적으로 결정됩니다. 즉, 로봇이 새로 예측한 로짓이 높은 신뢰도를 가진다면, 이는 더 정확한 지식을 담고 있다고 간주하여 해당 로짓을 더 많이 반영하는 식으로 접근을 했다고 합니다. 자세한 내용은 method 쪽에서 더 다루도록 하고, 저자들의 Contribution은 다음과 같습니다.
Contributions
- Behavior-IL 및 Environment-IL이라는 두 가지 온라인 Continual Learning 시나리오를 instruction-following 에이전트를 위해 새롭게 제안했습니다.
- 신뢰도 기반 동적 가중치를 활용하는 CAMA 기법을 제안하여, 이전 로짓이 outdated 되지 않도록 업데이트를 조절했습니다.
- 제안된 기법은 여러 평가 지표에서 기존 방법들을 확실히 능가했습니다.
2. Related Work
Continual Learning (CL)은 크게 두 가지 시나리오로 분류됩니다.
Offline Learning
현재 태스크의 데이터를 여러 번 반복 학습하는 방식이며, 이 방식은 모든 태스크 데이터를 저장해야 하므로 메모리 요구량이 크다는 단점이 있었습니다.
Online Learning
데이터가 스트리밍 방식으로 개별 혹은 소규모 배치로 들어올 때, 각 데이터 샘플을 한 번만 학습에 사용하는 방식입니다. 온라인 학습은 메모리 제약과 데이터가 지속적으로 도착하는 현실 시나리오에 적합하기 때문에 본 논문에서도 온라인 CL에 초점을 맞춥니다.
CL에는 Task-free & Task-aware Continual Learning 방법론이 있습니다.
Task-aware 방법은 학습 중 task boundary를 활용하여 과거 모델에서 지식을 distillation합니다. 하지만 실제 환경에서는 스트리밍 데이터에 명확한 태스크 경계가 없어서 태스크 경계를 알고 있는 것은 비현실적입니다. 따라서 태스크 경계 정보 없이 학습하는 Task-free 방법들이 제안되었습니다.
그리고 Knowledge Distillation 기반 Online Continual Learning 방법론이 있는데,
기존 CL 방법들 중, 샘플 재생(replay) 기반과 정규화 기반 방법들이 있었습니다. knowledge distillation 기반 방법은 이전 모델 혹은 이전 데이터로부터 얻은 지식을 활용합니다. 그러나 이러한 증류 방법들은 일반적으로 상당한 메모리 공간과 추가 계산을 요구해, 메모리 및 계산 자원이 제한된 엣지 디바이스 환경에는 부적합하다는 한계가 있었습니다.
이를 해결하기 위해 이전 모델을 그대로 저장하는 대신 로짓(logits)만 저장하여 메모리와 추론 비용을 줄이는 방식의 연구들도 제안되었습니다.
하지만, 이 경우에도 문제가 있었는데, 저장된 로짓이 이전 태스크에서 불충분히 학습된 정보일 수 있어 현재 모델이 과거 정보를 제대로 distill하지 못하는 문제가 있었습니다. 그래서 이전에 저장된 로짓과 현재 모델에서 나온 로짓을 가중합하여 업데이트함으로써 로짓이 오래되지 않도록 하는 방법론도 있었지만, 이 과정에서 task boundary 정보가 필요해 task-free 스트리밍 데이터 환경에는 적합하지 않았습니다. 본 논문에서는 태스크 경계 정보 없이 에이전트가 느끼는 신뢰도(confidence)를 기반으로 로짓을 업데이트하는 방식을 제안하여, 보다 일반적인 상황에 적용 가능함을 강조합니다.
로봇 에이전트를 위한 lifelong learning의 방향성
이미지 분류 같은 단순한 태스크를 넘어서, 강화학습, 모방학습 등 다양한 실제 로봇 태스크에 대한 연구들도 활발히 진행되고 있는데, 이전 연구들은 주로 세밀한 조작 태스크에 집중하고, 내비게이션에는 상대적으로 적은 관심을 기울였으나, 최근에는 내비게이션과 상호작용을 함께 다루는 연구도 등장했습니다. 본 논문의 CL 설정은 CORA(Powers et al., 2022)라는 내비게이션 태스크와 유사하나 여기에 자연어 이해와 물체 위치 확인을 포함하여 보다 현실적인 인터랙티브 명령 수행 태스크를 다룬다는 차별점을 지닙니다.
정리하면, 본 논문의 저자들은 메모리 및 태스크 경계 정보가 제한된 실제 상황에 적합한 온라인, task-free 지속학습 환경을 다루면서, 특히 이전 로짓을 신뢰도 기반으로 업데이트하는 새로운 방법을 제안하여 기존 연구 대비 더 효율적이고 일반적인 솔루션을 제공한다는 점을 강조하고 있습니다.
3. CL-ALFRED: Continual Learning Setup For Embodied Agent
CORA라는 기존 연구는 다양한 가정집의 태스크를 계속 학습하는 벤치마크를 제시했었지만, 자연어 이해와 객체 위치 파악에서의 부족함이 있어서 실제 에이전트 적용에 한계가 있었다고 저자들은 말했습니다. 그래서 이 문제를 극복하기 위해, 자연어 이해와 객체 위치 파악을 포함한 복합적인 지시 태스크를 다루는 ALFRED 데이터셋에 기반하여 2가지 continual learning 시나리오를 제안했습니다. 앞서말했듯이, 새로운 행동을 순차적으로 학습하면서 이전 지식을 보존토록하는 Behavior Incremental Learning (Behavior-IL)과 새로운 환경에 적응하며 계속적으로 학습하는 Environment Incremental Learning (Environment-IL)입니다.
3.1 Task Formulation
ALFRED 벤치마크는 자연어 이해와 시각적 환경 인지를 모두 요구하는 과제를 제공합니다. 저자들은 이 벤치마크를 기반으로 온라인(스트리밍) 형태의 CL 태스크를 구성했는데요. 에이전트는 임의의 위치에서 spawn된 뒤, 자연어 지시 l을 입력받아 주어진 태스크를 수행합니다. 각 시점 t에 에이전트는 visual observation v_t를 입력으로 받고, 객체와의 interaction이 필요한 경우 action y_{a,t}와 object class y_{c,t}의 mask y_{m,t}를 예측합니다.
여기서 입력 x_t == 즉 (v_t, l) 와 출력 y_t == (y_{a,t}, y_{m,t})를 사용하여 \theta로 매개변수화된 정책 \pi_\theta: x \longrightarrow y를 학습하게 됩니다.
해당 정책의 목표는 작업을 완료하기 위해 action과 object mask의 시퀀스를 예측하는 것입니다.
object localization 경우는, 본 연구에서는 클래스 예측만을 다루고, 마스크 generator의 continual 업데이트는 future work로 남긴다고 하였습니다.
3.2 Continual Learning Setups
기존 연구들은 언어 지시를 통해 원하는 과업을 수행할 수 있는 에이전트를 개발하기 위해 에이전트가 depolyment된 후 새로운 행동과 환경에 직면하면서도 이전 지식을 유지해야 하는 측면을 다뤄왔습니다. 하지만 기존 방법들은 사전에 수집된 데이터셋을 전부 사용해야했거나 단순화된 태스크 구성을 전제로 했었습니다.
이를 해결하기 위해, 저자들은 다음 두 가지 온라인 CL 시나리오를 제안하게 됩니다.
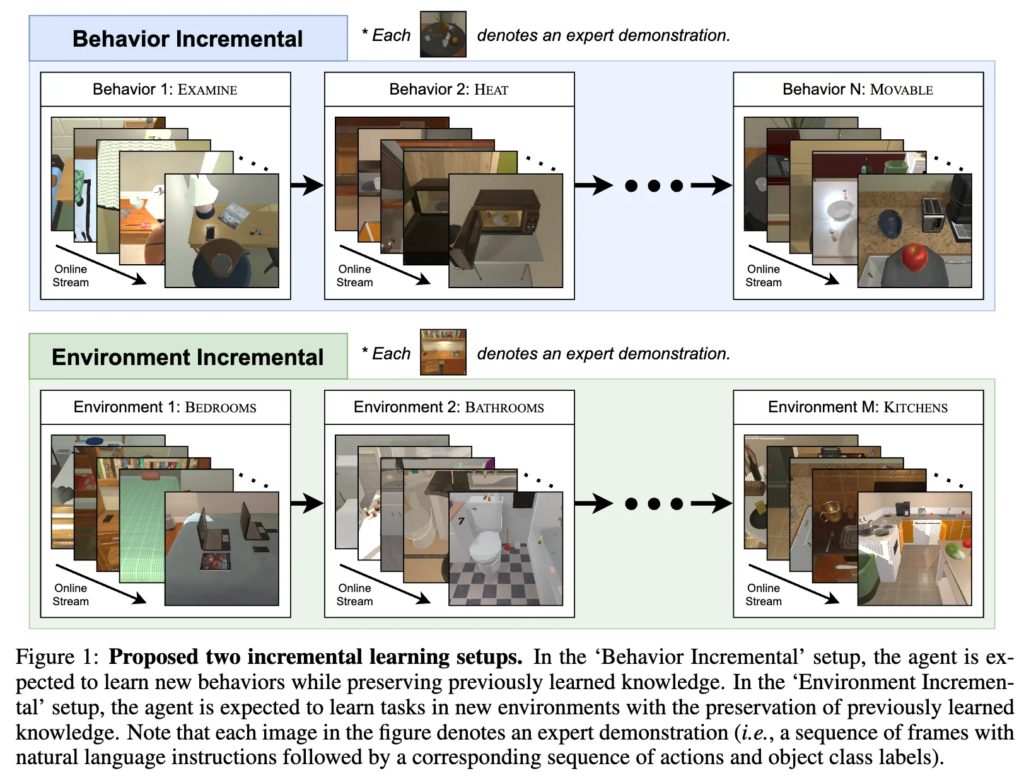
먼저 Behavior Incremental Learning (Behavior-IL) 은 로봇이 점진적으로 새로운 ‘행동’을 학습하는데, 처음에는 물체 examine 방식들에 대한 demonstration들을 배우고, 이후에는 물체를 heat하는 방식에 대한 demonstration을 학습하는 방식입니다. 즉 무엇을 수행할지(What to do)에 대한 점진적 학습에 집중합니다. 두번째는 Environment Incremental Learning (Environment-IL)로 로봇이 점진적으로 새로운 ‘환경’에서 태스크를 수행하는 법을 학습하는데, 처음에는 욕실만 다루다가, 이후에는 주방, 침실 등으로 환경을 확장하며 학습하는 개념입니다. 즉 어디서 수행할지(Where to do)에 점진적 학습에 집중합니다.
본 연구는 그래서 기존의 태스크 chunk 기반 offline CL과 달리, online 스트리밍 방식으로 새로운 데이터가 연속해서 제공되는 현실적인 시나리오 기반의 태스크 프리(task-free) 상황을 가정합니다.
3.2.1 Behavior Incremental Learning
instruction에 따른 행동은 시간이 지남에 따라 새로운 행동이 등장하며 다양성이 커질 수 있게 됩니다. 이를 고려해서 Behavior-IL setup에서는 에이전트가 새로운 행동을 점진적으로 학습하면서, 이전에 학습한 행동에 대한 지식을 유지할 수 있도록 합니다. 구체적으로는, 행동 집합 \mathcal{T}가 주어졌을 때, 에이전트는 각 행동 타입 \tau_j \in \mathcal{T}에 대해 N_j개의 학습 에피소드 \{{s^{\tau_j}_i}\}^{N_j}_{i=1} 를 순차적으로 받습니다. 그 다음 현재 행동 타입 \tau_j에 대한 마지막 에피소드 s^{\tau_j}_{N_j}를 받으면, 에이전트는 다음 행동 타입 \tau_{j+1}에 대한 에피소드 \{{s^{\tau_{j+1}}_i}\}^{N_{j+1}}_{i=1}를 순차적으로 받습니다. 이런 에피소드 스트림은 마지막 행동 타입 \tau_{|\mathcal{T}|}의 마지막 학습 에피소드 s^{|\mathcal{T}|}_{N{|\mathcal{T}|}}까지 반복하며 끝나게 됩니다.
본 연구에서는 ALFRED 벤치마크에서 정의한 7가지 행동(EXAMINE, PICK&PLACE, HEAT, COOL, CLEAN, PICK2&PLACE, MOVABLE) 타입을 사용합니다. 행동 순서에 대한 bias를 막기 위해, 다음과 같이 학습 및 평가 시 무작위 순서로 행동 시퀀스를 생성하여 실험을 진행하였다고 합니다.

3.2.2 Environment Incremental Learning
Environment-IL setup에서는 에이전트가 환경을 점진적으로 학습합니다. 실제 세계에서 에이전트는 처음 학습된 환경뿐만 아니라 이후에 등장하는 새로운 환경에서도 동작할 수 있어야 합니다. 해당 학습 과정은 환경 집합 \mathcal{E}가 주어졌을 때, 에이전트가 각 환경 유형 e_k \in \mathcal{E}에 대해 M_k개의 학습 에피소드 \{{s^{e_k}_i}\}^{M_k}_{i=1}를 순차적으로 받고, 현재 환경 e_k의 마지막 에피소드 s^k_{M_k}를 받은 뒤에는, 다음 환경 e_{k+1}의 에피소드 \{{s^{e_{k+1}}_i}\}^{M_{k+1}}_{i=1}를 받게 됩니다. 이 또한 마지막 환경 e_{|\mathcal{E}|}의 마지막 에피소드 s^{|\mathcal{E}|}_{M{|\mathcal{E}|}}까지 이 과정을 반복하게 됩니다.
본 연구에서는 AI2-THOR 라는 벤치마크에서 정의한 4가지 환경(Kitchens, Livingrooms, Bedrooms, Bathrooms)을 사용하며, Behavior IL과 마찬가지로 무작위 순서로 환경 시퀀스를 구성해 학습·평가를 진행하였다고 합니다. 또한, 특정 환경 유형의 에피소드 수 불균형이 편향을 초래할 수 있으므로, 환경별 에피소드 수를 동일하게 맞추기 위해 subsampling을 적용했다고 합니다.

4-1. Confidence-Aware Moving Average (CAMA)
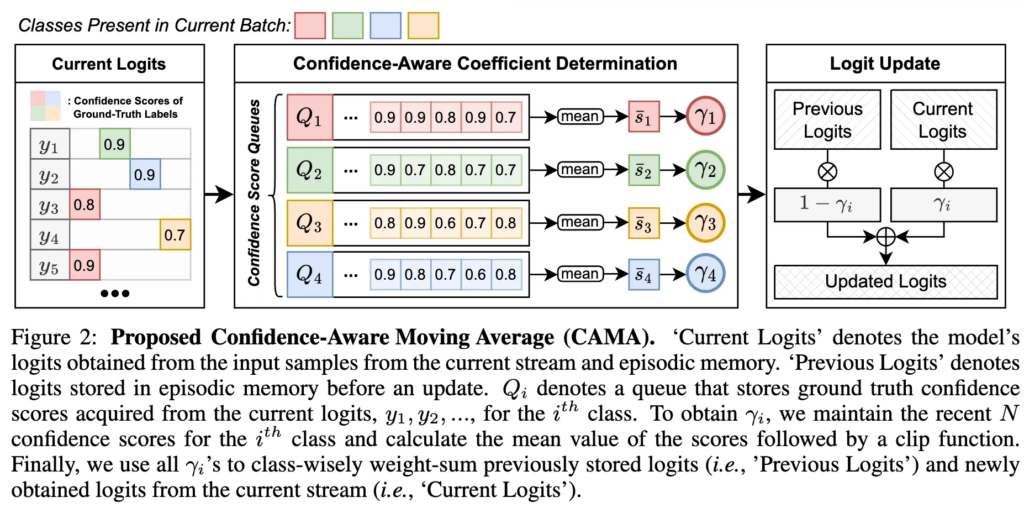
CL에서는 이전 태스크의 모델 파라미터나 데이터를 저장하는 방식이 주를 이루지만, 큰 저장 비용이 필요했었습니다. logits만 저장하는 knowledge distillation 방식은 저장 효율을 높일 수 있었지만, 초기 학습 단계에서 불충분하게 학습된 logits이 포함되어 있을 수 있고, 보통 task boundary 정보에 의존한다는 문제가 있었습니다. 그래서 저자들은 태스크 경계 정보 없이(task-free하게), 에이전트가 예측한 confidence score를 기반으로 이동 평균 방식으로 과거와 현재 로그잇을 결합하는 위 그림과 같은 CAMA 기법을 제안하게 됩니다.
좀 와닿지 않기에 CAMA의 전체과정을 크게 요약하면 다음과 같은데요. 먼저 초기에 정답 레이블들에 대한 모델의 confidence socre를 계산해서 모델이 현재 샘플에 대해서는 얼마나 confident를 갖고 있는지 알아내고, 그 다음 각 클래스들에 대한 confidence score 큐로 이동 평균을 계산하고, 그거로 어떤 동적인 가중치 계수를 만든 다음, 해당 가중치로 이전 로짓과 현재 로짓을 가중합하는 방식입니다.
이젠 자세히 설명하자면, 맨좌측의 current logits은 현재 입력 배치에 대해 모델이 예측한 logits이고, 각 logits 옆에는 해당 클래스의 gt 라벨에 해당하는 confidence score가 색깔별로 표시되어 있습니다. 그래서 그 다음 CACD에서 먼저 각 클래스 i에 대해 최근 N개 confidence score들을 큐 Q_i에 저장하게 됩니다. 그렇게 큐 Q_i 내 점수들의 평균 \bar{s}_i를 계산하고, 이 평균을 바탕으로 적절히 clipping하여 가중치 계수 \gamma_i를 동적으로 결정합니다. 즉 높은 conf를 가진 클래스일수록 새로운 logits값이 더 많이 반영되도록 계수를 부여하고, 맨 우측 logit update에서는 이전에 저장된 로짓 \ell^{\text{prev}}_i과 현재 스트림으로부터 얻은 로짓 \ell^{\text{curr}}_i를 \ell^{\text{updated}}_i = (1-\gamma_i) \ell^{\text{prev}}_i +\gamma_i \ell^{\text{curr}}_i로 업데이트하게 됩니다.
이전 연구방식들에 따라 학습 데이터 스트림 (x, y_a, y_c) \sim D 와 episodic memory (x’, y’_a, y’_c, z’_{old,a}, z’_{old,c}) \sim M 에서 데이터를 결합한 입력 배치 [x; x’] 를 구성하고, 여기서 a \in A 및 c \in C는 입력 배치 [x; x’]에 존재하는 action 및 object class 집합 A 및 C의 action 및 object class 레이블을 나타냅니다. 여기서 x의 경우에는 이미지와 instruction을, y_a및 y_c는 해당 action 및 object class 레이블을, z’_{old,a} 과 z’_{old,c}는 해당 저장된 로짓을 나타냅니다. z_a, z_c, z'_a 및 z'_c는 입력 배치에 대한 현재 모델의 로짓을 나타냅니다.
episodic memory의 로짓이 오래되지 않도록 하기 위해, 아래 수식 1과 같이 계수 벡터 \gamma_a 및\gamma_c를 사용하여 z’_{old,a} 및 z’_{old,c}와 z’_a 및 z’_c를 가중합하여 업데이트된 로짓 z'_{new,a} 및 z’_{new,c}를 얻습니다. \odot는 Hadamard product라고 합니다.
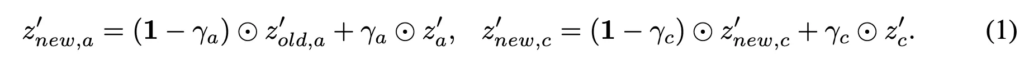
\gamma_a와 \gamma_c를 얻기 위해 먼저 x에 대한 각 action 및 object class 레이블에 대한 최신 N개의 신뢰도 점수를 유지합니다. 그런 다음, 시간이 지남에 따른 agent의 작업 학습 숙련도를 근사하기 위해 각 action i 및 object class j 레이블과 관련된 점수의 평균을 계산합니다. 이를 \bar{s}^a_i 및 \bar{s}^c_j로 표시하고, 수식 2와 같이 \gamma_a 및 \gamma_c의 각 요소(각각 \gamma_{a,i} 및 \gamma_{c,j}로 표시)를 \bar{s}^a_i 및 \bar{s}^c_j로 설정한 다음 CLIP 함수를 적용합니다.
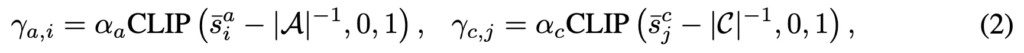
여기서 \text{CLIP}(x, \text{min}, \text{max})는 x의 값을 \text{min}에서 \text{max}로 제한하는 clipping 함수를 나타냅니다. 상수 \alpha_a < 1 및 \alpha_c < 1은 \gamma_{a,i} 및 \gamma_{c,j}가 1에 도달하여 과거지식을 완전히 잊어버리는 것을 방지하기 위함인데, 해당 alpha값들은 경험적으로 0.99로 설정했다고 합니다. 또한, |A|^{-1}, |C|^{-1}을 빼주는 것은 무작위 선택(uniform distribution)보다 신뢰도 정보를 효과적으로 활용하기 위함이라고 합니다.
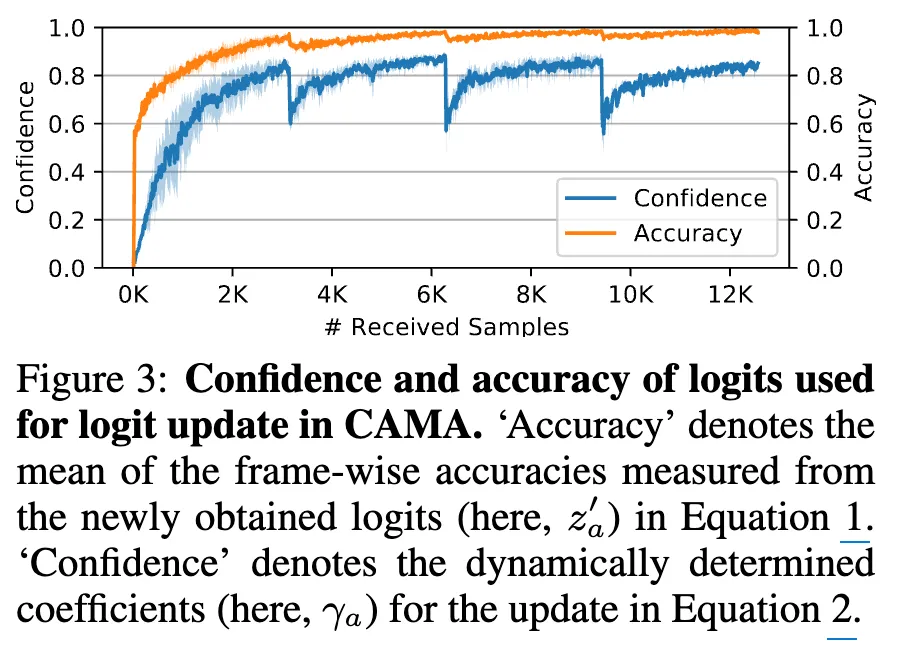
위 (Figure 3)를 보시면 실험적으로 높은 confidence가 높은 acc와의 상관관계를 보이는 경향이 있었습니다.
4-2. Model 구조
본 논문에서 활용하는 에이전트 구조는 ALFRED 벤치마크에 대해 Modular Object-Centric Approach (MOCA) 라는 프레임워크를 제안한 Factorizing Perception and Policy for Interactive Instruction Following라고 하는 GIST에서 21년 발표했던 방법론을 기반으로 했습니다. 해당 논문은 Perception과 Action Policy 둘로 잘 쪼개어 egocentric vision 과 자연어 지시 하에서 환경을 잘 탐색하고, 객체 interaction과 navigation을 잘 수행하자는 Embodied Instruction Following 태스크를 다룬 논문이었구요.
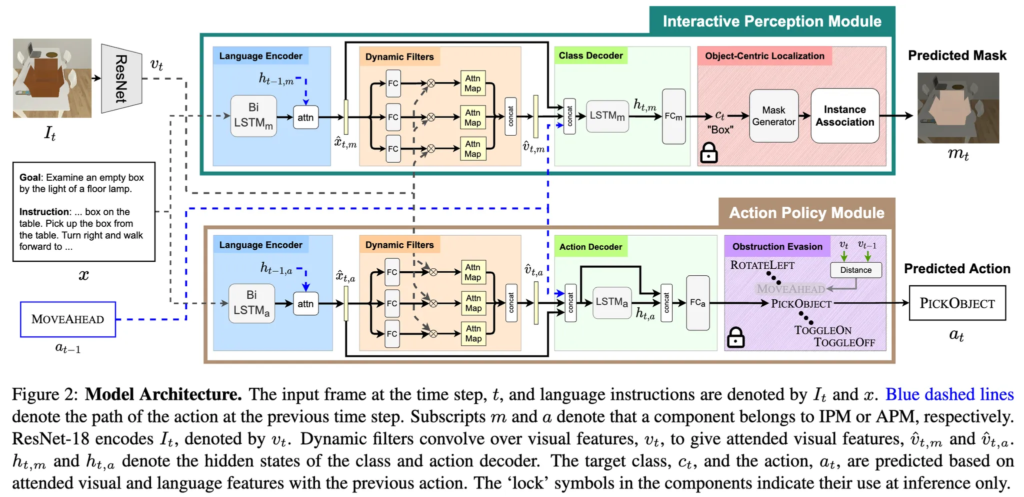
에이전트는 입력 x_t=(v_t, l, y_{a,t-1})를 받아 출력 y_t=(y_{a,t}, y_{c,t})를 예측합니다.
v_t는 시점 t의 RGB 이미지(주변 뷰), l은 단계별 언어 지시, y_{a,t-1}은 이전 시점의 행동입니다. 그래서 위의 객체 위치 인식 모듈과 action policy 예측 모듈 2가지 파이프라인으로 구성되게 되고, 처음엔 Bi-LSTM 기반의 self-attention 네트워크로 인코딩된 후 언어 feature를 얻고, 디코더에서 언어 feature로부터 만든 Dynamic 필터로 앞선 v_t를 attention하여 뽑아낸 visual feature를 만들고, 그걸 각각 Class decoder, Action decoder에 태워 각각의 파이프라인에서 적절한 output을 만들게 됩니다.
이 때 학습방식은 전문가 데모 x를 입력으로 받아, 아래 수식처럼 목적함수를 최소화하며 에이전트 \pi_\theta를 학습시키는 과정입니다.
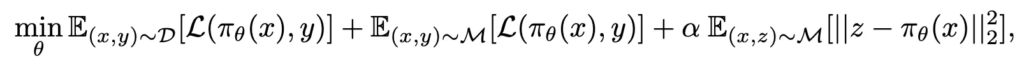
여기서 \mathcal{D}는 전문가 데모(훈련) 분포, \mathcal{M}은 에피소드 메모리 분포, y는 입력 x에 대응하는 정답 레이블(행동 및 객체 클래스), z는 에피소드 메모리에 저장된 이전 모델의 로짓(logits)입니다. 첫 두 항은 각각 학습 데이터와 메모리 샘플에 대한 예측 오차(분류 손실 \mathcal{L})를, 마지막 항은 메모리 로짓과 현재 모델 출력 간의 \ell_2를 penalization으로 추가하여, 과거 지식이 소실되지 않으면서 새 데이터를 학습하도록 유도합니다.
5. Experiments
ALFRED 벤치마크에 기반해서, 주요 평가지표는 성공률(success rate, SR)과 목표 조건 성공률(goal-condition success rate, GC)입니다. 성공률(SR)은 전체 에피소드 중 성공적으로 완료된 작업의 비율을 나타내고, 목표 조건 성공률(GC)은 전체 에피소드 중 설정된 목표 조건을 만족한 비율을 나타냅니다. 또한, 평가 환경은 학습에 사용된 seen 환경과 사용하지 않은 unseen환경으로 나누어 평가합니다. 또 CL 에이전트의 최종 및 중간 성능을 평가하기 위해서 두가지 변수를 사용하는데,
A_{\text{last}}(아래서 \mathrm{SR}{\text{last}}과 \mathrm{GC}{\text{last}}에 해당)는 최종 학습 태스크를 마친 에이전트가 달성한 지표를 의미하고, A_{\text{avg}}(아래서 \mathrm{SR}{\text{avg}}과 \mathrm{GC}{\text{avg}}에 해당)는 각 증분 과업을 마친 에이전트들의 지표 평균을 의미합니다.
Joint는 모든 태스크 데이터를 한꺼번에 학습한 모델(상한)이고, Finetuning은 신규 태스크나 신규 장면 타입에 대해서만 finetuning한 모델(하한)입니다.
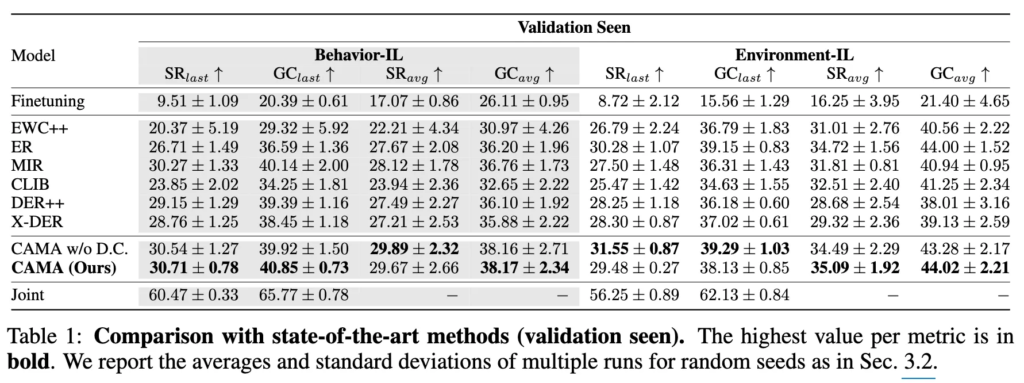
표1 은 seen에서의 평가입니다.
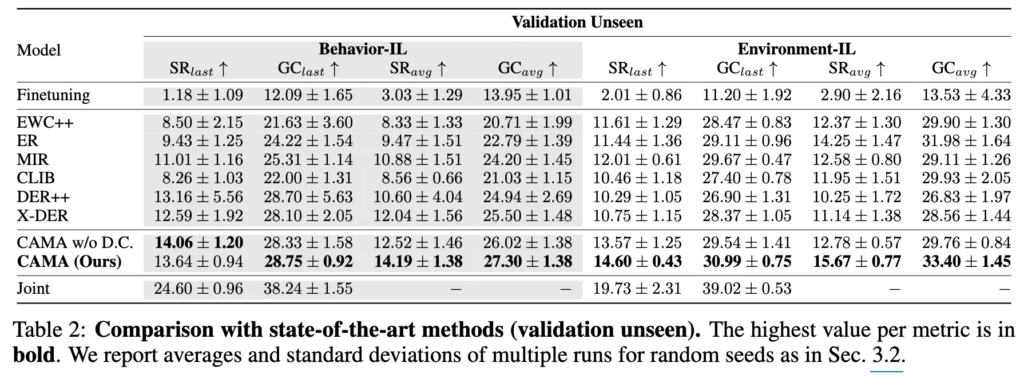
표2는 unseen에서의 평가입니다.
먼저 상한과 하한을 살펴보자면 Joint training vs. Finetuning. 관점에서, Finetuning은 Joint에 비해 성공률에서 각각 51.0%, 47.5%의 상대적 성능 저하를 보였습니다. 이는 단순히 에이전트를 신규 행동이나 환경에 finetuning하는 것만으로는 행동과 환경 간 분포 변화로 인한 망각 문제를 잘 해결할 수 없다는 것을 보여줬습니다.
다음은 EWC++이라는 방법론을 살펴볼건데, 이는 정규화 기반 접근법이라고 합니다. 이에 비교하면 CAMA는 seen,unseen 환경 모두에서 모두 좋은 모습을 보였습니다. 이는 중요한 파라미터 변화를 정규화하는 것보다 업데이트된 로짓 자체를 이용해서 지식을 distillation하는 방식이 망각을 방지하는 데 있어 더 효과적이었음을 보인 것이라고 합니다.
다음은 리허설 기반의 모델, 즉 샘플 replay 방식인 ER, MIR, CLIB 등의 방법론과 CAMA의 비교인데, 여기서도 모든 면에서 CAMA가 더 좋은 모습을 보였습니다. 이는 단순한 샘플 replay만으로는 급격한 데이터 분포 변화에 따른 망각을 방지하기란 어렵고, 에이전트가 새로운 작업에 적응하는 데 오히려 방해가 됨을 시사한다고 합니다.
마지막으로 distillation 기반의 로짓 distill 기법인 DER, X-DER모델과 CAMA와의 비교가 있는데, 로짓을 전혀 업데이트하지 않는 방식인 DER방식은 로짓을 적응적 가중합으로 업데이트하는 CAMA에 비해 seen,unseen에서 모두 낮은 성능을 보였고, X-DER의 경우는 새로운 클래스에 대해서만 부분적으로 로짓을 업데이트하는 방식을 취했었는데, X-DER이 학습 시에 task boundary를 꼭 활용해야했음에 반해, CAMA는 그런 정보를 전제하지 않고 task-free 기법이기에 보다 일반적인 상황에도 적용이 가능하면서도, CAMA가 모두 좋은 성능을 보였다는 점에서 해당 방법론이 효과적이었음을 보였습니다.

마지막으로 Behavior-IL에서의 정성적 분석결과입니다. 에이전트는 이전 행동 τ_{j−1}=HEAT를 이미 학습한 상태에서 새로운 행동 τ_j=Pick2&Place를 학습했습니다. 이후 주어진 작업 지시(”Mug를 집은 후 전자레인지를 이용해 가열하고, 가열된 Mug를 Coffee Machine 위에 올려 놓아야 한다.”)대로 동작을 수행하며, 이전 행동 τ_{j−1}에 대한 능력을 평가하여 망각이 발생했는지를 확인했다고 합니다.
빨간 글씨 Irrelevant Action은 잘못된 내비게이션으로 이어진 행동, 파란 박스 Interacted Object는 상호작용할 물체를 의미하는데, Finetuning 쪽을 보시면 목표 객체 Mug를 찾지 못해 환경을 배회하며 결국 작업에 실패하는 모습을 보입니다. DER++의 경우에는 Mug를 찾아 집어올 수 있으나, 전자레인지 위치로 이동하는 방법을 잊어버려 과제 수행에 실패하는 모습을 보입니다. 반면 CAMA는 Mug 집기, 전자레인지로 이동해 가열하기, Coffee Machine 위에 올리기까지 모든 단계를 성공적으로 수행하여 과제를 완수하는 모습을 보였습니다.
안녕하세요, 이재찬 연구원님. 좋은 리뷰 감사합니다. 리뷰 읽으면서 요즘 로봇 에이전트의 지식을 어떻게 업데이트하는지 동향을 알 수 있었네요.
제게 익숙하지 않은 분야이다보니 읽다 궁금한 점들이 있어 질문 남깁니다.
1. 로봇이 예측하는 logit이 구체적으로 무엇인가요? Figure를 보면 일반적인 classification output으로 출력되는 확률분포 형태인데, classification에 대한 예측 결과인가요? 만약 그렇다면 로봇은 무엇으로 예측하고 이 logit값을 기반으로 무엇을 수행하나요?
2. task-free, task-aware, task 간의 경계.. 등등 여기서 말하는 구체적인 task가 무엇인가요? 로봇이 행하는 행동 단위같은거라고 생각하면 되나요?
3. 문제 세팅에서 에이전트가 임의의 위치에서 스폰된 뒤, 자연어 지시문 I와 이미지를 입력받아 태스크를 수행하게 되는데, 이 I와 이미지가 입력되면 구체적으로 로봇이 어떻게 행동을 수행하는지 궁금합니다. 입력 정보를 어떻게 처리해서 다음에 수행할 행동을 결정하나요?
감사합니다.
안녕하세요 재연님, 리뷰 읽어주셔서 감사합니다.
1.
logits은 보통 모델의 decoder 부근에서 softmax나 sigmoid 등을 거치기 직전의 출력값이라서, 재연님이 말씀하신 classification이나 action 예측 score의 raw한 값이라고 보시면 될 것 같습니다. 그래서 언어모델 등에서는 보통 decoder에서 각 타임스텝별로 출력되는 벡터 자체가 logits이라고 한다고 합니다. 일단 본 논문에선 Appendix에 언급하던 model구조를 4-2에 가져왔었는데요. 설명이 조금 미흡했던 것 같습니다. 본 논문은 이전 연구인 MOCA라는 프레임워크를 그대로 따라서 Perception 모듈, Action Policy 모듈 둘로 쪼개어 학습을 진행하는데, 이때 Perception 모듈에서는 Class Decoder 부근에서의 LSTM_m을 통과하고 난 후 FC_m 레이어를 통해 나온, C_t라는 클래스를 예측하기 직전의 출력값이라고 보시면 될 것 같습니다. 비슷하게 Action Policy 모듈에서도 Action Decoder 출력 부근에서 FC_a 레이어 타고 나온 ‘PickObject’가 정해지기 전 raw한 출력값(socre)이 logits이라고 보시면 될 것 같습니다.
그래서 정리하면 로봇은 현재의 관찰 인풋(이미지, 자연어 지시)과 과거 행동을 바탕으로, 수행할 다음 행동 라벨, 조작할 객체 클래스를 분류기 형태로 예측하는 것이고 이때 확률분포로 예측하기 직전의 raw한 Score가 logits이고,
본 태스크에선 여기서 나온 과거 작업 수행 시 나온 logits값을 저장하거나 활용해서 knowledge distillation한다는 얘기가 나온 것으로 이해하시면 됩니다.
2.
맞습니다! Behavior-IL 기준으론 ‘HEAT’, ‘PICK&PLACE’ 처럼 행동 단위가 나뉘어 진 것으로 이해하시면 됩니다! 그래서 task boundary(태스크 경계) 같은 경우는 이 학습 데이터의 총 스트림 중에서 언제 task가 바뀌는 지에 대한 경계라고 보시면 되고, task-aware은 학습이나 추론 시 이 task boundary 정보가 주어지냐, task-free는 이런 정보 없이 그냥 연속적인 데이터 스트림만 주어지냐로 보시면 됩니다.
3.
해당 내용도 4-2 의 모델 구조 내용을 참고해주시면 될 것 같습니다. 행동들은 ALFRED 시뮬레이터 벤치마크 내에서 이미 사전정의된 동작들이기에 해당 행동에 대해 class를 맞추면 시뮬레이터안에서 행할 수 있는 어떤 primitive한 행동들이라고 보시면 됩니다.
감사합니다.
안녕하세요 재찬님 리뷰 감사합니다.
Incremental Learning과 task free한 환경의 필요성을 느껴볼 수 있었던 것 같습니다. 이전 로짓과 현재 로짓을 가지고 Confidence score 기반 업데이트시 초반에는 confidence 자체가 낮거나 불안정할 수 있을 것 같은데, 초반의 문제 때문에 전체적으로 로짓이 잘못 업데이트되는 경우는 없을까요??
안녕하세요 영규님, 리뷰 읽어주셔서 감사합니다.
저도 어느정도 그런 생각이 들었는데요. Figure 3을 보시면, 학습 초반 received samples수가 낮았을 때, confidence가 낮은 경향을 보이긴 합니다. 근데 이건 어디까지나 continual learning하면 어쩔 수 없는, 혹은 모든 학습 방법론들이 그러하듯 대부분이 가지고 있는 초기 학습 불안정성이지 않을까 싶네요. 그럼에도 불구하고 초반이 불안정한 confidence를 가져감에도 저자들의 방법론은 accuracy가 confidence의 경향성을 잘 따라서 증가하며 수렴하는 모습을 보이는 데, 이것이 저자들이 제안한 CAMA 프레임워크에서의 confidence 큐의 이동평균을 활용한 logit 가중치 적용과 alpha값 등의 추가적인 하이퍼파라미터 기법 덕분이지 않을까 생각합니다. 물론 학습 초기의 불안정성을 해소하는 방향으로 confidence 이동평균 대신 다른 수학적인 방법론이 활용되면 좋은 해결방법이 될 수도 있을 것 같습니다만,, 저는 수학지식이 많지 않은 관계로 당장은 딱히 떠오르지 않네요.. 하하..
감사합니다.