새로운 Video Retrieval 데이터셋과 관련된 논문이 있어 리뷰해보겠습니다.

- Conference: CVPR 2025
- Authors: Reno Kriz, Kate Sanders, David Etter, Kenton Murray, Cameron Carpenter, Kelly Van Ochten, Hannah Recknor, Jimena Guallar-Blasco, Alexander Martin, Ronald Colaianni, Nolan King, Eugene Yang, Benjamin Van Durme
- Affiliation: Human Language Technology Center of Excellence, Johns Hopkins University, SCALE Participants, Virginia Tech University
- Title: MultiVENT 2.0: A Massive Multilingual Benchmark for Event-Centric Video Retrieval
1. Introduction
텍스트 기반 검색 기술은 오랫동안 발전해왔지만, 이제는 유튜브 같은 플랫폼의 발달로 나날이 쏟아지는 비디오 덕분에 비디오-텍스트 검색 기술의 중요성이 커지고 있습니다. 비디오-텍스트 검색은 “어떤 사건이 일어난 영상을 찾는” 것이죠. 하지만 기존 데이터셋은 대부분 짧고 단순한 영상, 그리고 영어 중심의 묘사(query)만을 다루고 있어 실제 사건 중심 검색에는 한계가 있었습니다.
예를 들어, MSR-VTT는 짧은 영어 클립에 단순한 설명을 매칭하는 구조로, 현실 세계의 복잡한 사건을 다루기에는 부족했습니다. MultiVENT 데이터셋에서 사건(event) 중심의 접근을 시도했지만, 영상 수가 2,400개로 매우 적었습니다.
따라서 본 논문에서는 이러한 한계를 극복하기 위해 MultiVENT 2.0 (Multilingual Videos of Events with aligned Natural Text across five language)이라는 새로운 벤치마크를 제안하였습니다. 해당 데이터셋은 21만 개 이상의 뉴스 영상과 3,900개의 사건 중심 Query를 포함하고, “아랍어, 중국어, 영어, 한국어, 러시아어, 스페인어” 등 6개 언어로 구성되어 있다는 점에서 데이터셋의 규모와 다양성 모두 기존을 뛰어넘는다고 합니다.
특히 이 데이터셋은 시각 정보뿐만 아니라 음성, 자막, 메타데이터 등 다양한 모달리티에서 사건 관련 정보를 찾아야 하는데, 이는 단순한 장면 설명을 넘어 실제 멀티모달을 이해하였는지를 판단하는 데이터셋으로도 활용할 수 있다는 특징이 있다고 합니다. 이는 본격적인 데이터셋 설명 이후 실험을 통해 확인해보겠습니다.
2. Video Collection
기존 비디오 검색 연구에는 두 가지 근본적인 한계가 존재했습니다: 첫째, 대부분의 데이터셋은 단순한 장면 묘사에만 초점을 맞추고 있어, 실제 사건(Event) 맥락을 파악하는 능력을 평가하기 어렵다는 점. 둘째, 데이터셋의 규모나 주제 다양성 역시 제한적이라, 현실적인 멀티모달 검색 시나리오를 다루기에는 부족하다는 점
MultiVENT 2.0은 이러한 문제를 해결하고자 제안되었습니다. 먼저, 초기 버전인 MultiVENT 1.0은 사건 중심 검색이라는 새로운 방향성을 제시했지만, 전체 영상 수가 적고, 질의와 무관한 영상들이 충분하지 않아 모델의 검색 능력을 제대로 평가하기 어려웠습니다. 다시말해 “관련 없는 영상을 골라내는 능력”을 평가하기 어려웠다는 뜻이죠. 이를 보완하기 위해 MultiVENT 2.0에서는 보다 대규모이고 다양한 영상 소스를 활용하여 데이터셋을 확장하였다고 합니다.
2.1 MultiVENT 1.0 Development and Limitations
조금 더 자세하게 초기 버전인 초기 버전인 MultiVENT 1.0의 한계를 알아보겠습니다. MultiVENT 1.0 은 언어별·국가별 주요 사건들을 중심으로 수집된 영상과 뉴스 기사들로 구성됩니다. 예를 들어, 각 언어별로 구글 트렌드를 활용해 시각적으로 뚜렷한 사건들을 고르고, 그에 해당하는 유튜브 영상을 수집한 뒤, 관련 뉴스 기사와 연동하여 총 2,396개의 영상(255개 사건)을 구축하였습니다.
이는 단순한 장면 설명이 아닌 “특정 사건에 대한 정보 검색”이라는 목표에 맞췄다는 점에서… 기존과는 분명히 다른 새로운 유형의 데이터셋이었습니다. 하지만 영상 수가 적고, 쿼리에 무관한 영상이 다양하게 포함되지 않아 모델 성능을 평가하기에는 다소 제약이 있었죠. 특히, 텍스트 기반 검색에서는 수백만 개 단위의 문서를 사용하는 반면, MultiVENT 1.0은 데이터의 크기나 다양성 면에서 상대적으로 부족했죠.
이를 해결하기 위해 MultiVENT 2.0에서는 훨씬 더 많은 영상과 다양한 언어·이벤트 주제를 포괄하는 방향으로 데이터 수집을 진행하고자 하였습니다.
2.2 Expanded MultiVENT 2.0 Video Collection Process
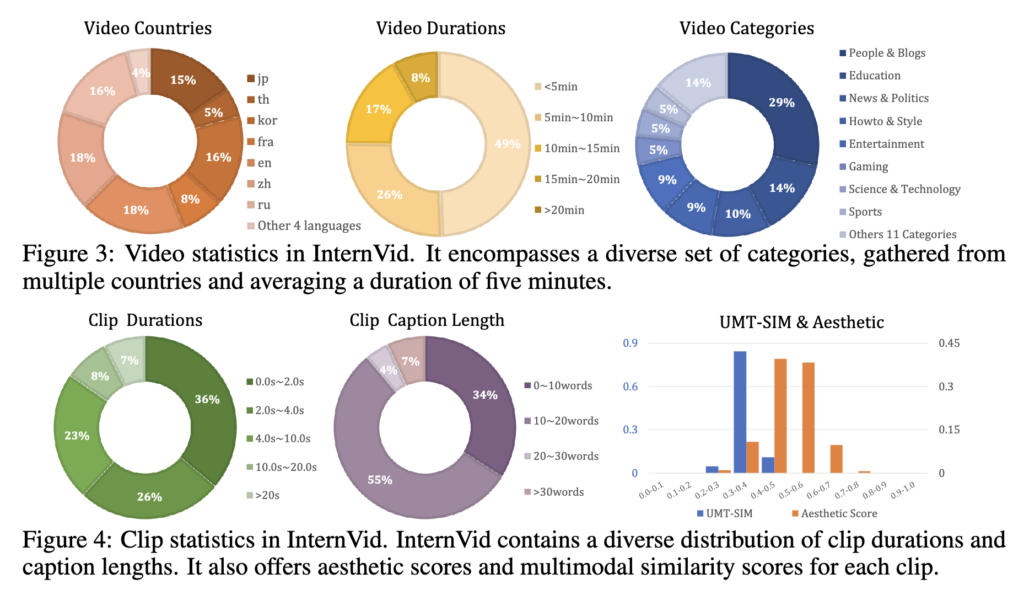
MultiVENT 2.0은 InternVid라는 대규모 유튜브 기반 비디오 데이터셋을 활용해서 구축되었습니다. InternVid에는 700만 개 이상의 비디오와 76만 시간 분량의 콘텐츠가 포함되어 있는데, MultiVENT 1.0에서 다뤘던 언어와 사건 유형보다 훨씬 더 넓은 범위의 영상들이 들어 있습니다. 물론 전부 사건 기반 영상은 아니지만, 정치나 재난처럼 사건 중심 콘텐츠도 꽤 많이 포함되어 있다고 해요.
저자들은 이 중 5분 이하 길이의 영상만 걸러낸 뒤, 기존 MultiVENT 1.0에서 다뤘던 언어들(아랍어, 중국어, 영어, 한국어, 러시아어)에 맞춰 각 언어별로 약 4만 개씩 영상을 수집했습니다. 여기에 더해, 평가 단계에서 다양한 상황을 다룰 수 있도록 스페인어나 기타 저자원 언어 영상도 일부 포함했다고 합니다.
이렇게 확장된 영상들과 기존 MultiVENT 1.0 데이터를 합쳐서, 최종적으로 약 21만 7천 개의 영상이 구축되었습니다. 이 중 약 10만 8천 개는 학습용(MULTIVENT TRAIN), 나머지 10만 9천 개는 평가용(MULTIVENT TEST)으로 나누어 제공하였습니다. 중복 영상은 모두 제거하였습니다. 또한, 데이터셋이 워낙 방대하기 때문에 빠른 실험과 튜닝을 위해 2,000개의 소규모 서브셋(MULTIVENT TRAIN-2K)도 별도로 제공된다고 합니다.
3. Query Creation
비디오 수집이 끝났으면, 이제는 텍스트 ㄴ쿼리를 만들어야겠죠. 사실 이 쿼리의 퀄리티가 영상 검색 성능을 좌우하는 중요한 요소입니다. 그런데 기존 데이터셋들을 보면, 대부분 짧고 모호한 장면 묘사 위주의 쿼리를 사용하거나(ex. “a black and white horse runs around”), 그냥 유튜브 메타데이터를 그대로 쓰는 경우가 많았습니다. MultiVENT 1.0도 이런 방식이었는데, 요즘 검색 엔진에서 쓰는 명확하고 간결한 스타일의 쿼리랑은 좀 거리가 있죠.
그래서 MultiVENT 2.0에서는 쿼리를 더 자연스럽고 실용적으로 만들기 위해 두 가지 방법을 결합했다고 합니다. 첫 번째는 MultiVENT 1.0에서 구축해둔 사건 annotation을 바탕으로 쿼리를 만드는 방식이고, 두 번째는 영상만 보고 사람이 직접 쿼리를 작성하는 방식입니다. 특히 두 번째 방식은 사용자가 실제로 “이 영상에서 어떤 사건이 발생했는지” 검색하는 상황을 그대로 반영하려는 목적이 있었죠.
이를 위해 저자들은 6개 주요 언어 관련 언어학자들을 채용해서 쿼리를 작성하게 했고, 사전 튜토리얼과 예시 제공, 그리고 개별 피드백과 모니터링을 통해 쿼리 퀄리티를 꾸준히 관리했다고 합니다.
3.1 Updated Query Creation for MultiVENT 1.0
앞서 설명한 내용을 좀 더 자세하게 살펴보겠습니다. 초기 MultiVENT 1.0에서는 영상에 달린 설명을 그대로 쿼리로 활용했는데, 이건 대부분 간단하고 단편적인 표현이라 정보량이 부족했습니다. 그래서 저자들은 사건마다 위키백과 기사 제목을 참고해 좀 더 명확한 사건 중심 쿼리(MULTIVENT BASE)를 새로 만들었습니다.

예를 들어, 그림 1에 나오는 사건은 2022 Lotus Garden China Telecom Building fire라는 제목으로 표현되는데, 이건 기존 MSR-VTT 데이터셋에서 흔히 볼 수 있는 “a fire is burning” 같은 묘사형 쿼리와는 꽤 다릅니다. 즉, MSR-VTT는 그냥 ‘무엇이 보이는가’를 말하는 반면, MultiVENT는 ‘무슨 일이 일어났는가’를 묻고 있는 거죠.
하지만 하나의 사건도 다양한 관점이 있을 수 있기 때문에, 단일 제목만으로는 충분하지 않습니다. 그래서 저자들은 MULTIVENT-GROUNDED라는 세부 주석을 활용해서 더 구체적인 질문들 (“사건은 어디서 발생했는가?”, “누가 영향을 받았는가?”) 을 만들었고, 이렇게 생성한 884개의 MULTIVENT SPECIFIC 쿼리를 통해 모델이 사건의 여러 측면을 파악하도록 유도하였습니다.
3.2 InternVid Query Creation
하지만 지금까지 소개한 쿼리는 대부분 MultiVENT 1.0 기반이었고, 실제로 전체 영상의 대부분은 InternVid에서 가져온 거라 이대로 두면 문제가 생깁니다. 예를 들어, 모델이 단순히 “이건 MultiVENT에서 온 영상인지, InternVid에서 온 영상인지”만 구분해도 성능이 높게 나올 수 있는 구조가 되어버리는 거죠. 즉, 진짜 사건 검색 능력을 평가하는 게 아니라, 그냥 출처 구분 문제로 바뀌어버릴 위험이 있습니다.
이걸 방지하기 위해, 저자들은 InternVid 기반 영상에서도 별도로 쿼리를 만들었습니다. 뉴스·정치, 스포츠 카테고리 영상 위주로 사건성 콘텐츠가 있는지 먼저 확인하고, 해당되는 경우에는 MultiVENT 1.0과 동일한 방식으로 base 쿼리를 생성했습니다. 추가로, 관련 기사도 직접 찾아서 쿼리의 기반으로 활용했다고 하네요.
그리고 여기서 끝난 게 아니라, 각 영상에 대해 최대 3개의 추가 쿼리도 만들었습니다. 이 쿼리들은 특정 모달리티 하나만 보고 작성한 건데요, 예를 들어 Description 쿼리는 유튜브 설명만 보고 만들고, Speech 쿼리는 Whisper로 추출한 음성 텍스트 기반, Embedded Text 쿼리는 프레임 속 자막이나 화면 글자를 OCR로 뽑아서 만든 쿼리입니다. 이렇게 모달리티를 나눠서 쿼리를 만든 이유는, 모델이 여러 정보 중 어떤 걸 잘 활용하는지를 각각 따로 평가해보기 위함이라고 보시면 됩니다. 실제 영상에서는 모든 정보가 다 있지 않기 때문에, 이런 설정은 현실적인 일반화 성능을 보는 데에도 꽤 의미 있는 방식이죠.
물론 모든 영상이 이런 정보를 다 갖고 있는 건 아니라서, 쿼리가 없는 경우도 있었습니다. 최종적으로는 테스트셋에 1,417개, 학습셋에 1,375개의 쿼리가 추가되었습니다.
3.3 Query and Video Breakdowns
데이터셋을 좀 더 깊이 있게 분석하기 위해, 쿼리를 만들면서 영상에 대한 몇 가지 추가 정보도 함께 수집했습니다. 예를 들어, annotator들에게 먼저 영상의 주 언어가 무엇인지 확인하게 했는데, InternVid에 이미 언어 정보가 있다고 해도 실제와 다른 경우가 꽤 많았기 때문입니다. 특히 영어로 라벨링된 영상 중 20%는 실제로는 다른 언어였다고 하네요.
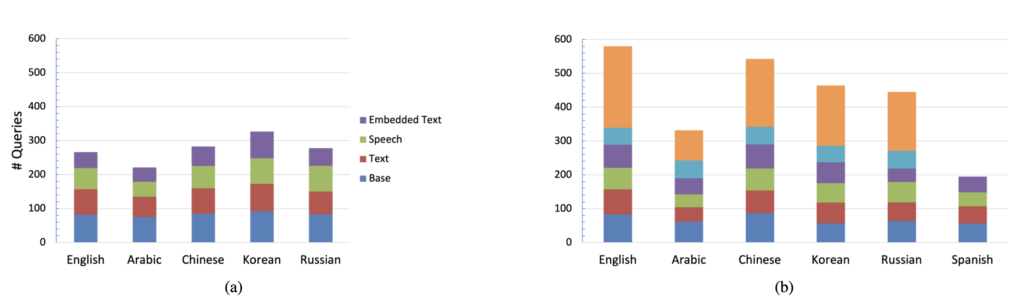
상단 그림 3a와 3b는 MultiVENT TRAIN과 TEST에 포함된 쿼리들이 각각 어떤 언어의 영상을 대상으로 작성되었는지를 보여주고 있습니다. 학습셋은 기존 MultiVENT 1.0의 다섯 언어(아랍어, 중국어, 영어, 한국어, 러시아어) 기반이고, 테스트셋에는 여기에 스페인어가 추가돼서 다국어 상황에서의 검색 성능을 평가할 수 있도록 설계했다고 합니다.
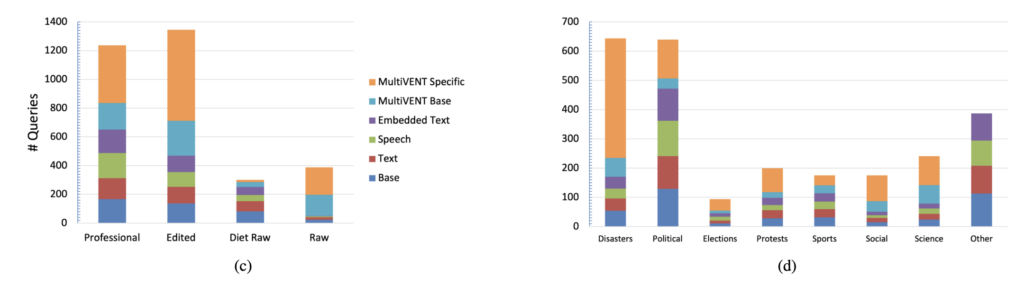
또한, 영상에 등장하는 사건들도 총 8개의 카테고리로 분류했습니다: 자연재해(Disasters), 선거(Elections), 시위(Protests), 정치 관련 이슈(Political), 스포츠(Sports), 사회적 사건(Social Events), 과학 및 기술 관련 사건(Science), 마지막으로 위 카테고리에 해당되지 않는 기타(Other)입니다. 상단 그림 3(d)는 이런 사건 분류별 쿼리 분포를 시각화한 것입니다.
마지막으로, 각 영상의 스타일에 따라서도 구분을 진행했습니다. 예를 들어, 뉴스 보도처럼 전문 리포터가 나오는 Professional, 편집이 들어간 Edited, 휴대폰 등으로 현장을 그대로 찍은 Raw, 그리고 여기에 자막이나 나레이션이 거의 없는 Diet Raw까지 총 4가지로 나눴습니다. 상단 왼족 그림 3c는 이 영상 타입별로 쿼리가 어떻게 분포되어 있는지를 보여주고 있고요. 여기서 보면 진짜 의미 있는 “현장성”을 담은 Raw 영상은 InternVid에서는 많지 않다는 점도 확인할 수 있습니다. 그래서 원래 MultiVENT 1.0에서 수집한 영상들이 여전히 중요한 역할을 하고 있다는 것도 의미한다고 합니다.
4. Relevance Judgment Annotation
이제 쿼리를 만들었으면, 그 쿼리에 어떤 영상이 실제로 “관련 있다”고 볼 수 있는지를 판단해야겠죠. MultiVENT-TEST 기준으로 총 6,068개의 쿼리-비디오 쌍에 대해 relevance 주석이 이루어졌는데요, 대부분의 쿼리는 하나의 영상에만 매핑되어 있고, 나머지는 모두 관련 없는 것으로 간주됩니다.
문제는 이게 실제로는 꽤 애매할 수 있다는 겁니다. 테스트셋이 워낙 크고 다양하다 보니, 모델 입장에서는 사실상 관련 있는 영상인데도 그냥 평가 대상이 아닌 영상으로 처리될 수 있고, 일부 영상은 쿼리랑 부분적으로만 관련 있거나, 정보가 부족해서 판단 자체가 모호할 수도 있죠.
그래서 저자들은 이전에 쿼리 생성 작업을 했던 언어 전문가들을 다시 투입해서, 아직 annotation되지 않은 쿼리-비디오 쌍들에 대해 relevance 평가를 수행했습니다. 이때 평가 기준은 단순히 관련/무관이 아니라, not relevant / possibly relevant / partially relevant / very relevant 이렇게 4단계로 나뉘어 있습니다.
다만 워낙 수가 많다 보니 모든 영상에 annotation을 달 수는 없어서, multilingual CLIP(MCLIP)과 MultiVENT 1.0에서 가장 성능이 좋았던 모델을 기준으로 top-10에 들어간 영상들만 추려서 평가 대상으로 삼았고, 중복되는 쿼리-비디오 쌍은 제거한 뒤 나머지를 우선적으로 주석했다고 합니다. 이렇게 해서 추가된 gold judgment 수가 4,396개입니다.
평가 지표로 활용하기 위해서는 위 4단계를 다시 묶어서, possibly와 partially는 하나로 묶고 somewhat relevant, very relevant, not relevant의 3단계 체계로 정리하였고요. 그리고 MultiVENT Base 쿼리에서 매우 관련 있음(very relevant)으로 판정된 영상은, 그와 연결된 MultiVENT Specific 쿼리에도 최소한 somewhat relevant한 것으로 간주해서 5,653개의 silver judgment도 자동으로 추가하였습니다.
5. Baselines and Results
5.1 Baselines
멀티모달 기반 VLMs (Vision-Language Models)
- VALOR: 텍스트, 오디오, 이미지 인코더를 각각 따로 두고, 디코더를 통해 멀티모달 표현을 통합
- VAST: 텍스트·오디오·이미지를 동시에 학습하는 omni-modality 사전학습 기반
- InternVid 2: 비디오 토큰 레벨 마스킹 기법 적용, MSR-VTT에서 SOTA 달성
- Language-Bind: 모든 modality를 CLIP 기반 인코더로 통합하여 다양한 비디오 태스크에서 좋은 성능
단일 모달리티 기반 (모두 MCLIP 임베딩 공간 활용)
- mCLIP: 비디오에서 10개의 keyframe을 추출 → 이미지 인코딩 후 평균 임베딩
- ICDAR OCR: 비디오 프레임에서 텍스트를 추출(OCR) → 텍스트 인코딩
- Whisper OCR: 비디오 음성을 Whisper로 텍스트 변환 → 텍스트 인코딩
- Description: 영상의 YouTube 설명 문장을 직접 텍스트 인코딩
5.2 Results
Table 3 – Performance of benchmarks
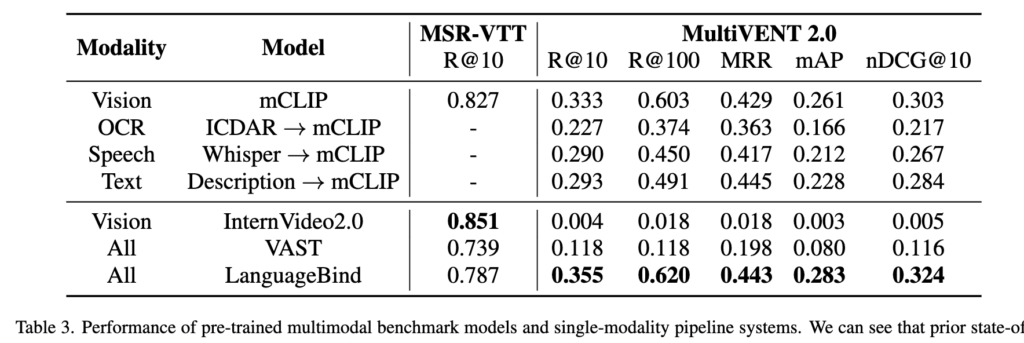
Table 3에서는 MultiVENT 2.0과 기존 벤치마크(MSR-VTT)에서의 모델 성능을 비교해 보여줍니다. 흥미로운 점은 기존 데이터셋에서는 잘 작동하던 VLM들이 MultiVENT 2.0에서는 대부분 성능이 급격히 떨어졌다는 점입니다.
이유는 크게 두 가지로 볼 수 있습니다. 첫째, MultiVENT 2.0은 평균 영상 길이가 훨씬 길기 때문에, 짧은 클립 중심으로 학습된 기존 VLM들에겐 부담이 크다는 점. 둘째, 단순하게 매칭하는 방식에서 벗어나, 복잡한 사건 기반 자연어 쿼리를 처리해야 한다는 점입니다. 특히 일부 쿼리는 화면에 잘 드러나지 않는 비시각적 정보(예: 음성, 자막 기반 내용)를 묻고 있기 때문에, VLM만으로는 대응이 쉽지 않았던 것으로 보입니다.
Table 4 – Breakdown of single-modality pipeline results.
Table 4는 단일 모달리티 기반 파이프라인 시스템들이 어떤 상황에서 강점을 보이는지를 잘 보여줍니다.
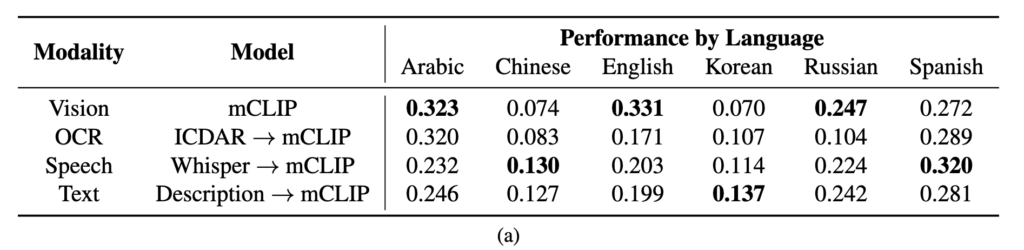
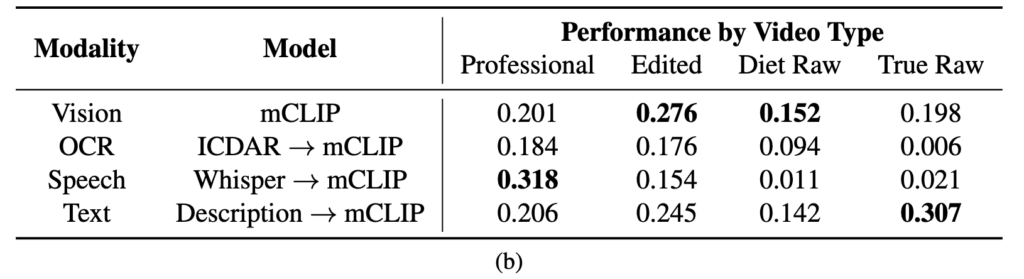
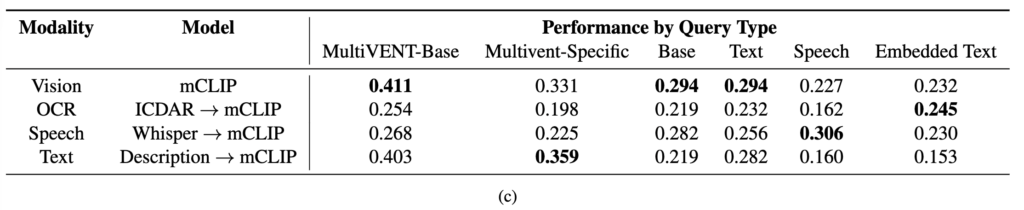
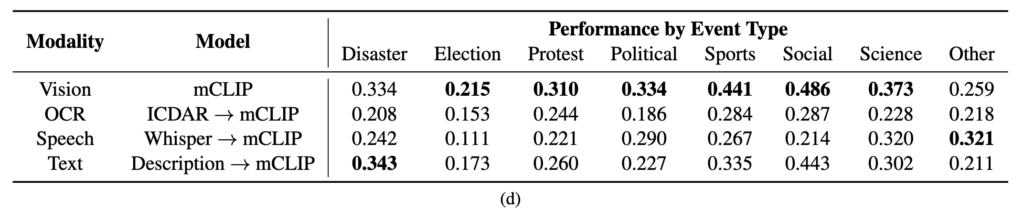
특히 Table 4에서는 영상 타입에 따라 어떤 modality가 더 효과적인지를 비교해주는데요, 뉴스 같은 전문 영상에서는 음성(speech)이 매우 강력한 반면, raw 영상에서는 거의 쓸모가 없다고 합니다. 반대로 사람이 쓴 텍스트 설명(description)이나 이미지 기반 정보는 다양한 영상 타입에서 비교적 안정적인 성능을 보였고, 특히 raw 영상에서는 description이 가장 효과적인 modality였다고 하네요.
이걸 보고 나면 자연스럽게 떠오르는 질문이 하나 있습니다. “그럼 앞으로 평가할 때, 사람이 쓴 설명(description)을 사용해도 될까?” 실제 온라인 영상은 유튜브 설명조차 제대로 안 달린 경우가 많기 때문에, 깨끗하고 명확한 설명을 가정하는 건 비현실적일 수 있죠. 특히 raw 콘텐츠일수록 더 그렇습니다.
그래서 저자들은 향후 평가를 위해 두 가지 버전을 제안합니다. description을 사용할 수 없는 버전(MULTIVENT TEST-NODESC), 그리고 사용할 수 있는 버전(MULTIVENT TEST-DESC). 이로써 실사용 환경과 연구 목적으로 모두 대응 가능한 평가 설정이 가능해졌다고 볼 수 있습니다.
Summary
지금까지 MultiVENT 2.0 데이터셋에 대해 살펴보았습니다. 기존 텍스트-비디오 검색 데이터셋이 짧고 단순한 묘사에 한정되어 있었다면, MultiVENT 2.0은 훨씬 더 복잡하고 실제 사건 중심의 검색 시나리오를 반영한 대규모 멀티모달 벤치마크입니다.
이 데이터셋은 총 21만 개 이상의 영상과 3,900개 이상의 다국어 쿼리로 구성되어 있으며, 쿼리 생성 방식에서도 단순 장면 묘사 대신 사건 중심, 모달리티 분리 기반, 세분화된 질의까지 포함하여 매우 다양한 조건을 포함하고 있었습니다. 특히 영상의 음성, 자막, 설명 등 각각의 modality만을 따로 활용해 쿼리를 구성함으로써, 실제 상황에서의 시스템 일반화 성능을 정밀하게 평가할 수 있게 설계되었습니다.
실험 결과를 보면, 기존 VLM들이 짧은 영상에서는 괜찮은 성능을 보였지만, 사건 중심 검색, 특히 비시각 정보에 의존하는 쿼리에서는 성능이 크게 떨어졌습니다. 이 결과는 단순히 영상에 보이는 정보를 넘어서 멀티모달 정보 이해 능력이 중요해지고 있다는 걸 보여줍니다.
주영님 좋은 리뷰 감사합니다.
굉장히 대규모의 사건 중심 영상 데이터 셋을 구축하고, 구축한 데이터 셋에 대한 분석을 한 논문인 것 같습니다.
평가 데이터는 성능이 가장 좋은 모델에서 top-10에 들어가는 영상을 추려 구축하였다고 하셨는데, 그렇다면 연구에 있어 “잘 가공된 데이터”에 대한 평가라는 한계가 있을 것 같습니다. top-10의 영상을 이용하여 평가 데이터를 구축하는 방식에 대해 어떻게 생각하시는 지 궁금합니다.
또한, 영어로 라벨링 된 영상 중 일부는 주 언어가 다른 언어인 경우가 꽤 많았다고 하셨는데, 그렇다면 이러한 경우는 주 언어에 맞추어 다시 라벨링한 것인가요?
1. 성능이 가장 좋은 모델에서 top-10에 들어가는 영상을 추려 구축하면 평가에 한계가 있을 것 같다.
-> 우선, 평가 데이터가 top-10 예측 영상 기반으로 구성된 이유는 annotation 비용 절감이라는 현실적인 제약 때문이었습니다. 다만 이로 인해 “잘 가공된 데이터” 위주의 평가가 될 수 있다는 점은 저자들도 인지하고 있는 것 같은데요, 이를 보완하기 위해 다양한 modality 기반 쿼리와 *silver label 확장 등을 함께 활용했습니다.
*gold 라벨은 사람이 직접 결정한 정답을 의미하고, silver label은 사람이 직접 보진 않았지만, 논리적으로 유추한 정답을 의미합니다
2. 언어 라벨링의 오류는 어떻게 한건가?
-> 언어 라벨 오류의 경우, 실제 주 언어를 annotator가 확인하여 수정하였고, 최종 통계 및 분석은 교정된 주 언어 기준으로 수행되었다고 합니다. 이를 통해 언어별 쿼리 분포 및 성능 평가의 신뢰도를 높이고자 하였습니다.
좋은 리뷰 감사합니다.
기존의 너무 소규모의, 쿼리가 간단한 데이터셋의 한계를 극복하고 보다 다양하고 규모가 큰 데이터셋을 어떻게 구축하는지 알 수 있었습니다.
간단한 질문이 있는데요, 해당 데이터셋이 21만개 이상의 뉴스 영상으로 구성되는데 다양한 유형의 영상이 아닌 뉴스만을 활용한 이유가 있나요? 뉴스 비디오가 물론 중간중간 다양한 영상이 나오기는 하지만 그래도 다양성에 제약이 있을 것 같은데, 뉴스를 활용했다면 그 이유가 있을 것 같아서요.
또한, 2.2 Expanded MultiVENT 2.0 Video Collection Process 파트에서 InterVid 데이터셋에서 5분 이하 길이의 영상을 걸러냈다고 했는데 그 이유가 있나요? 비디오 길이 통계를 보면 꼭 5분 이하의 데이터만으로 구성되지는 않는 것 같은데, 그 이유가 궁금합니다.
감사합니다!
1. 왜 뉴스 비디오만 사용했는가?
-> 뉴스는 다양한 사건을 다루고, 시각·음성·자막 등 멀티모달 정보가 잘 정리되어 있어, 사건 중심 검색 평가에 적합합니다. 장르적 다양성은 적지만, 주제 다양성은 확보된 셈이죠
2. 왜 5분 이하 영상만 필터링했는가?
-> InternVid엔 너무 긴 영상이 많아서 학습·라벨링 비용이 과도하게 커집니다. 5분 이하로 필터링한 건 현실적인 제약으로 때문인 것 같습니다
안녕하세요. 좋은 리뷰 감사합니다.
InternVid 기반 영상에 대해서도 별도 쿼리를 만들었는데, 이 이유가 단순 MultiVENT 영상인지 InterVid에서 온 영상인지 출처 구분 문제로 바뀔 위험이 있기 때문이라고 언급해주셨습니다. 혹시 이와 관련해서 논문에서 실험적으로 보인 것이 있는지 궁금합니다.
또, 그림 3을 보면 5개 언어들의 학습 데이터 쿼리 비중이 비슷한거 같은데, 실험에서 chinese와 korean이 다른 언어들에 비해 특히 성능이 떨어지는 이유가 무엇인가요 ? !
감사합니다.
1. InternVid 출처 구분 문제 관련 실험이 있는가?
-> 아쉽게도 그와 관련한 실험은 없었습니다. 다만 논문에서 “모델이 단순히 영상 출처(MultiVENT vs InternVid)만 구분해서 고성능을 내는 상황을 방지하기 위해” 별도 쿼리를 생성했다고 언급한 것으로 봐서는.. 실험보다는 설계 단계에서 미리 고려한 요소같습니다.
2. Chinese와 Korean 성능이 낮은 이유는?
-> 말씀하신대로, 대부분의 언어가 학습 데이터 비중은 비슷했지만, 실험 결과에서는 Korean과 Chinese는 성능이 유독 낮았습니다. 그 원인으로, 우선 저자들은 language-specific tokenization 을 언급하였습니다. 그 다음으로 사용한 모델인 MCLIP의 비영어 성능 한계, 그리고 특히 korean의 경우 자막이나 설명 텍스트가 적은 영상 비중이 높았기 때문이라고 분석하고 있습니다. 즉, 언어 자체의 문제 + modality 정보 부족이 겹쳐서 성능이 떨어진 것으로 같습니다