안녕하세요, 지난주에는 scene을 3D로 복원한 뒤 이를 기반으로 효율적인 학습을 수행하는 논문을 리뷰했는데요, 이번에는 그보다 한 단계 더 나아가 시간 축을 포함한 4D 정보를 복원하여 로봇이 인간의 시연을 모방할 수 있도록 하는 새로운 방식을 제시한 논문을 리뷰하려고 합니다. 제목처럼 이 논문은 사람이 물체를 어떻게 조작하는지를 단 한 번의 시연 영상만으로 보여주기만 하면, 로봇이 그 행동을 직접 따라하면서 articulated object를 다룰 수 있도록 하는 새로운 프레임워크를 제안합니다. 저자들은 RSRD(Robot See Robot Do)라는 시스템을 제안했습니다. 단일 RGB demonstration과 멀티뷰 이미지를 통해 물체의 부위별 움직임을 시간에 따라 복원하는 4D Differentiable Part Model (4D-DPM)을 만들고, 이렇게 얻은 객체의 4D trajectory를 바탕으로 로봇이 인간의 행동을 모사하게 합니다. 4D-DPM 또한 저자들이 제안한 형식이라고 하네요. Pretrained vision model을 그대로, task-specific training이나 fine-tuning없이 사용해 end to end의 작업 성공률이 60퍼센트 정도 나온다고 합니다.
Introduction
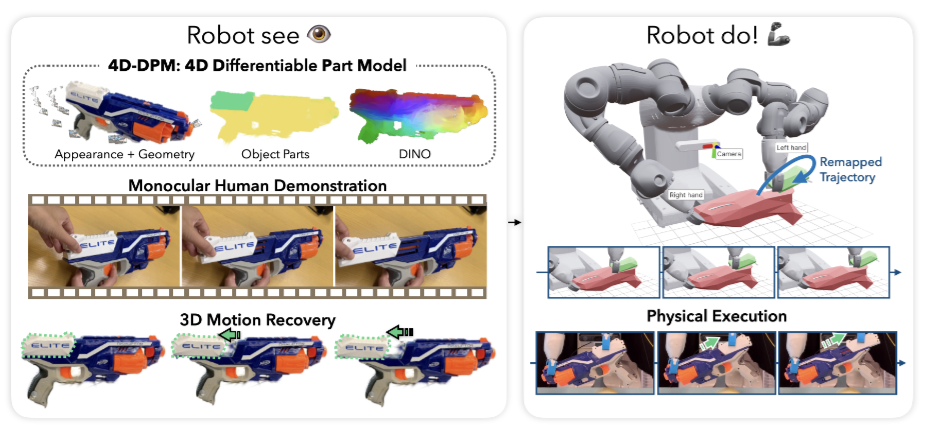
만약 로봇이 사람과 같다면, 저자들은 로봇에게 관절 구조를 가진 물체들의 사용법을 가르쳐 주는 것의 가장 자연스러운 방법은, 실제로 작동하는 것을 보여주는 것이라고 합니다. 아이들이 어른의 행동을 보면서 학습하듯, 로봇도 인간의 행동 결과를 관찰하며 조작법을 학습할 수 있다면 훨씬 직관적인 인터페이스가 될 수 있다고 주장합니다. 여기서 중요한 점은 로봇이 단순히 손의 움직임을 모방하는 것이 아니라, 조작하는 물체의 움직임 자체를 모방해야 한다는 점입니다. 이를 위해선 로봇이 시연 영상을 보고 동일한 객체 중심의 움직임을 유도하도록 학습해야 한다고 주장합니다. 단순히 손을 모방하는 것이 아니라, 물체가 어떻게 움직이는 지를 중요하게 생각해야 한다는 것입니다. 따라서 위와 같이 Robot See 부분에서는 저자들이 제안한 4D-DPM 모델을 통해 물체의 움직임에 집중하고, 이를 Robot Do 부분에서 (실제로 로봇이 action을 할 때) 해당 객체의 움직임을 따라하기 위해 motion planning을 하게 됩니다. 4D-DPM의 등장도 물체의 3D상의 움직임을 시간에 따라 복원하는 것이 기존의 방법론들로 challenging 했기 때문이라고 합니다. 객체 중심의 프레임워크는 embodiment type에 대한 일반화도 가능하게 만들어주었다고 하네요. 프레임워크를 더 찬찬히 살펴보도록 하겠습니다.
Related Works
해당 분야가 조금 생소하게 느껴져서 related works 부분을 읽으며 얻게된 내용들에 대해서도 설명하도록 하겠습니다. 우선 articulated objects들의 3D 움직임을 추정하는 부분에 대한 이야기 입니다. 단일 RGB 영상에서 관절의 움직임을 3D로 복원하는것은 매우 어려운 일이라고 합니다. 가장 명확한 한계가 객체를 분해해서 움직여야 한다는 점인데, GARField (태주님의 리뷰입니다!!)를 통해 SAM의 파트 분할 능력을 3D로 일반화 함으로써 추가적인 dataset이나 annotation 없이 객체를 3D상에서 분해해서 움직일 수 있었다고 합니다. 또한 저자들의 object centric한 representation도 일반화 성능을 높이는 데 굉장히 효과적이었다고 하네요. 기존 연구들이 3D 구조를 활용해 다양한 학습 방법을 제시했지만, 저자들은 object centric한 표현들 중에서도 part centric한 표현을 사용해 일반화 능력을 크게 올릴 수 있었다고 합니다. 결과적으로 기존의 pretrained VLM만을 가지고 open-world generalization을 할 수 있었다고 합니다.
Neural Field에 대한 이야기도 있었는데요, 시각적인 품질이나 언어 기반의 조작 외 여러가지 이유로 3D Neural Field가 로보틱스에 사용되고 있고, 학습 속도가 느린 NeRF 대신 3DGS를 활용하고 있지만, 정적인 표현에만 국한되어 있는 단점이 있기 때문에 시간축으로 확장한 4D-DPM을 통해 monocular 영상에서 객체의 움직임을 추적할 수 있었다고 합니다. 최근 physics가 적용되는 gaussian이나 deformable gaussian등등의 논문들을 봤었는데, 별개의 이야기인지,, 조금 더 고민을 해봐야 할 것 같습니다. 저자들은 회전움직임과 직선 움직임을 고려하기는 했지만, 관절만 다루고 deformation은 없다고 가정을 했다고 합니다. Deformation을 고려하지 않은 것은 조금 명확한 한계이지 않나 생각합니다..
Method
Robot See Robot Do의 파이프라인 구조를 자세히 살펴보도록 하겠습니다. RSRD는 크게 4D-DPM생성, monocular 영상을 통한 3D 움직임 복원, 로봇의 행동으로 이루어진 end-to-end 구조입니다. 각 단ㄱㅖ별로 자세하게 살펴보도록 하겠습니다.
4D-DPM
RSRD의 가장 중요한 단계라고 할 수 있는 4D-DPM 구축 단계입니다. 우선 객체의 멀티뷰 이미지를 통해 3DGS로 객체를 reconstruction 합니다. 이후 Gaussian들은 explicit하게 명시적인 위치와 크기를 가지기 때문에, 이 점을 활용해 객체를 부위별로 분할해줍니다. GARField를 사용해 3D 물체상의 포인트를 지정하고 scale을 조절해 원하는 granularity의 파트 분해를 하게 됩니다. 이 부분은 사람이 scale parameter를 마우스로 변경해야하고, 포인트 지정도 직접 수행해야 하는 것으로 보입니다. 이후 feature field 학습을 진행합니다. 요ㅕ러 시점에서 추출한 DINO feature map을 기반으로 모든 gaussian에 고차원 feature descriptor를 삽입한다고 합니다. 각 Gaussian은 D차원의 피쳐를 가지고, MLP를 통해 feature공간으로 사영되고, per-pixel MSE loss로 6000step 만큼 학습된다고 합니다. 이러한 part centric feature field는 Nerfstudio의 Splatfacto모델을 기반으로 구현했다고 합니다. 학습중에는 nearest-neighbors total variation loss도 함께 적용한다고 합니다. 각 Gaussian과 이웃하는 3개의 gaussian간의 feature standard deviation을 줄이도록 유도하여 공간적으로 매끄러운 feature embedding이 가능했다고 합니다. 나아가 polycam으로 얻은 초기 camera pose를 보정하기 위한 과정도 거친다고 합니다. (어떻게 하는건지는 조금 더 자세히 알아보도록 하겠습니다). 이를 통해 단일 RTX4090 GPU에서 이미지의 개수에 따라 GARField 학습에 5-10분(동일 GPU에서 70장 정도를 학습하는데 20분정도 걸렸으니 20-30장 정도 사용하는것이 아닐까 예측해봅니다), 6000step의 MSE loss를 학습하는데 3분정도 걸린다고 합니다. 이렇게 생성된 4D-DPM을 통해 30fps 정도의 differentiable rendering이 객체의 part기준으로 적용된 채로 가능하다고 하빈다. 이를 통해 3D part motion을 tracking할 수 있다고 합니다.
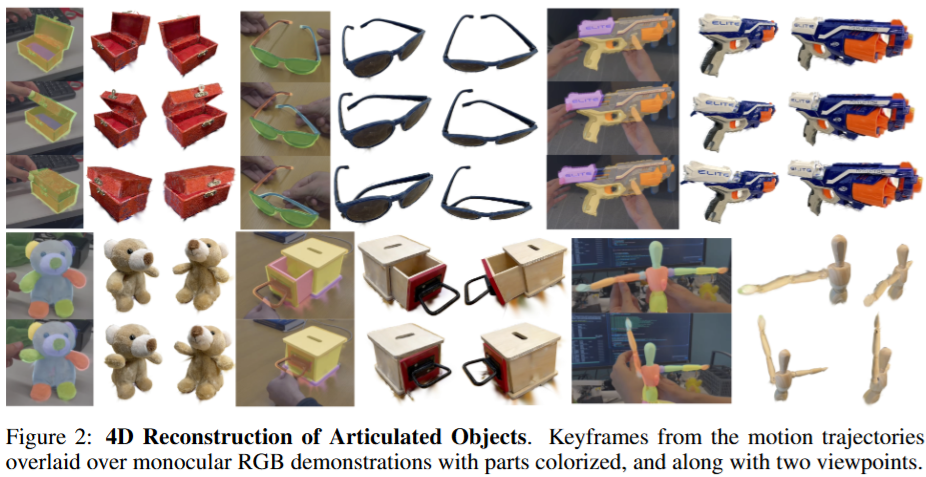
Monocular 3D Part Motion Recovery
4D-DPM을 구성한 이후 단일 RGB 영상을 통해 분리된 물체 부위의 움직임을 추적합니다. 저자들은 이 작업이 정보가 부족한 채로 진행되는 underdetermined 문제라고 합니다. 2D 영상을 통해 3D를 추적해야 하기 때문에 그런 것 같습니다. 이 문제르 ㄹ해결하기 위해 저자들은 analysis-by-synthesis 방식을 적용했다고 합니다. 네트워크를 통해 결과를 바로 뽑아내는 feed-forward 방식이 아니라, 현재 객체가 어떻게 움직이고 있는지를 최적화 과정으로 거꾸로 추론하는 컨셉인데, 시간을 따라 이어지는 SE(3) 형태의 파트 pose trajectory를 정의하고, 각 시간 단계마다 이전 frame의 추정값을 초기값으로 사용해 누적적으로 보정해 나간다고 합니다. (맞는 표현인지는 모르겠지만 3DGS와 비슷한 컨셉으로 진행하는 것이 아닌가..? 싶습니다) 이 과정에서의 핵심은 역시 differenctiable rendering이라고 합니다. 4D-DPM을 기반으로 추정된 파트 pose로부터 영상이 어떻게 보일지를 렌더링 한 후, 이를 실제 영상과 비교해 오차를 backpropagation하여 3D pose를 업데이트 해나간다고 합니다. (3DGS의 힘이 정말 큰 것 같긴 합니다..) 이러한 구조는 기존의 feed forward 방식보다 훨씬 정밀한 tracking이 가능할 뿐 만 아니라 smoothness나 rigidity와 같은 정교한 기하학 기반의 정규화항을 최적화 과정에 직접 통합할 수 있는 큰 장점이 있다고 합니다. 결국 예측된 pose대로의 움직임이 실제 영상과 얼마나 똑같은가?를 계속 업데이트 하는 것으로 이해하면 될 것 같습니다. 조금 더 자세히 살펴보도록 하겠습니다.
우선 입력 영상과 동일한 카메라 파라미터를 가진 가상 카메라 뷰에서 4D Differentiable Part Model(4D-DPM)을 렌더링하고, 여기서 얻어진 RGB, Depth, 그리고 DINO feature map을 실제 영상으로부터 추출한 DINO feature와 직접 비교합니다. 이후 두 feature map의 차이를 MSE loss로 계산하고, 이 오차를 렌더링 경로를 거꾸로 따라가며 각 파트의 3D pose에 대해 gradient descent 방식으로 업데이트를 수행한다고 합니다. 이 때 저자들이 흥미로운 것은 photometric loss보다 DINO feature loss가 훨씬 더 안정적인 최적화 기준이었다는 점이었다고 합니다. 실제로 실험에서도 photometric loss는 tracking을 불안정하게 만들었고, DINO 기반 loss만 사용할 때 더 정밀한 추적이 가능했다고 합니다. (픽셀값만 가지고 비교하는거보다 좀 더 고차원적인 정보가 들어가야 좋다는 건가?로 이해했습니다)
DINO loss 외에 두가지의 3D 정규화 prior도 함께 사용한다고 합니다. Depth Anything을 활용하여 입력 영상에서 “어느 부위가 더 가까운가/먼가”에 대한 상대적인 depth를 받아 Sparse-NeRF 방식의 ranking loss를 활용했다고 합니다. 객체 마스크 내부에서 점 쌍을 뽑고, 두 점 간의 깊이 순서가 렌더링된 depth와 mono-depth 예측값에서 동일하게 유지되도록 loss를 만들었다고 합니다. 이때 마스크는 바깥쪽을 5픽셀 깎아내어 경계의 불확실성 영향도 줄였다고 합니다.
다음으로는 물체의 부위 간 연결 구조를 유지하기 위한 제약을 걸었다고 합니다. 서로 인접한 부위들이 처음에 있던 거리 관계를 그대로 유지하도록 유도하는 loss인 ARAP (as rigid as possible)을 사용했다고 합니다. 각 파트 경계에서 중심 간 거리가 2.5mm 이하인 Gaussian 쌍을 찾아 초기 거리를 저장하고, 최적화 중 현재 거리와의 차이에 대해 robust loss를 부여했다고 합니다. (움직임을 너무 과하게 추정해서 물체를 떨어뜨리지 않게 한다고 이해했습니다) 이렇게 시각적 요소, 깊이 요소, 구조적인 요소를 모두 고려한 최적화를 통해 tracking을 진행합니다.
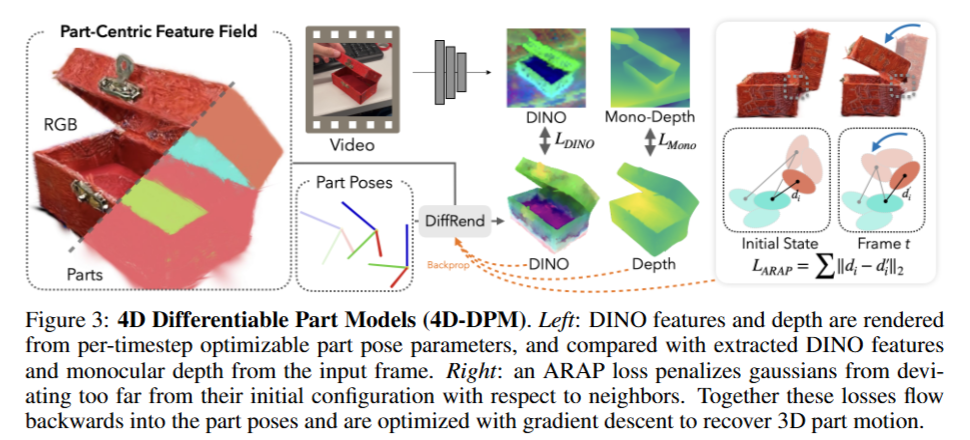
Tracking을 할 때는 초기 pose를 설정하는 것도 중요한데, 초기 pose를 파이프라인의 첫 프레임에서 추정한다고 합니다. 이 과정을 위해 2D-3D feature matching 기반의 포즈 추정 방식을 사용합니다. 먼저, 입력 영상에서 물체가 대략 어디에 있는지를 알아내기 위해 4D-DPM에서 생성된 3D Gaussian들의 DINO feature와 입력 영상 프레임의 2D DINO feature map 간의 mutual nearest neighbor 매칭을 수행하고, 매칭된 픽셀들의 중심을 계산하여 이 위치를 통과하는 3D ray를 생성합니다. 이후, 해당 광선 상의 일정 거리 지점에 객체 중심을 배치하여, 초기 위치를 정하고 초기 추정치를 바탕으로 객체의 중력 축 중심으로 회전시키며 총 8개의 초기 pose 후보를 만든 뒤 각 후보마다 200회의 최적화 를 진행해 가장 loss가 낮은 pose를 최종적으로 선택한다고 합니다.
Object Motion and Grasp Planning
객체 부위의 3D pose 추정 이후에는, 로봇이 이를 실제로 어떻게 조작할지 계획하고 실행하는 단계를 거치게 됩니다. 이 단계는 크게 어떤 부위를 움직일지 선택하는 Part Selection, 어떻게 잡을지를 결정하는 Grasp Planning, 전체 조작 경로를 만드는 Trajectory Planning의 세 단계로 구성됩니다.
먼저 “로봇이 어떤 부위를 조작해야 물체 전체가 제대로 동작할까?”를 결정해야 합니다. 이렇게 part selection을 진행할 때 단순하게 가장 많이 움직인 part를 고르게되면 모호해지기 때문에, 사람의 손이 어떤 부위를 잡았는지를 기준으로 part selection을 진행한다고 합니다. 가위를 예로 들면 가위의 손잡이와 날은 항상 같이 움직이기 때문에 그저 움직인 정도로만 비교할때는 손잡이를 고를 수 없게 됩니다. 시연 영상에서 사람 손이 실제로 어떤 부위를 잡았는지를 추정하기 위해서는 아래 figure에서 확인할 수 있는 HaMeR라는 3D hand pose mesh detector를 사용한다고 합니다. 먼저 입력 영상에서 사람 손의 3D 위치와 크기를 추정하고, Depth Anything과 Gaussian 기반 depth map을 조합해 손의 depth를 정렬한 뒤, 엄지와 검지가 객체의 어떤 파트와 가까운지를 분석해 최종적으로 어떤 부위를 조작했는지 결정한다고 합니다.

이후에는 어떻게 잡을것인가? 를 구상합니다. 사람 손과는 다르게 실험을 진행한 로봇들을 포함해 많은 로봇들이 2지 parallel gripper를 사용해 조작에 제한이 많기 때문에, 어떻게 잡을것인지가 매우 중요한 문제중에 하나입니다. 따라서 로봇이 선택된 부위를 실제로 잡을 수 있는가를 확인하게 됩니다. 파트 단위의 grasp planner를 별도로 구성해 각 파트를 구성하는 Gaussian들을 mesh로 만들고, 이를 부드럽게 정리한 뒤, antipodal grasp 방법인 Dex-net 2.0을 기반으로 파트당 20개의 grasp 축을 샘플링합니다. 이후 각 grasp에 대해 회전 및 위치를 다양하게 조합하여 총 480개의 grasp 후보를 생성하고, 이 grasp들은 나중에 trajectory planner에서 사용할 수 있도록 파트 로컬 좌표계에 저장된다고 합니다.
마지막으로 어떻게 (어떤 경로로) 움직일 것인지도 결정하게 됩니다. 단일 팔과 양팔인 경우로 나누어 진행하고, 각 조합에 대해 앞서 만든 480개의 grasp 후보 중 하나를 시작점으로 end-effector의 움직임 경로를 생성하고, 이를 기반으로 sparse Levenberg-Marquardt 최적화 알고리즘을 통해 trajectory를 계산한다고 합니다. 또한 이때 목표 pose와 너무 멀어지는 trajectory는 바로 제거합니다. 남은 trajectory들에 대해서는 cuRobo를 이용해 collision을 포함한 경로를 계산하고, 실제로 접근 가능한지를 확인한 뒤, 처음으로 성공한 trajectory를 선택하여 실행한다고 합니다. (이 때는 cuRobo를 활용한것을 보니 cuRobo의 문제점을 pyroki가 해결한 것 중에 retargeting이 있어서 쓴건가? 싶기도 합니다. cuRobo는 retargeting이 안 되는걸로 알고있습니다) 나아가 양손 작업의 경우엔, 물체를 2cm 들어 올려 테이블과 충돌하지 않도록 하는 세심한 처리도 함께 들어가 있다고 합니다.
Experiments
실험은 7DOF 양팔 로봇인 ABB YuMi 로봇을 사용했다고 합니다. 신기한게 soft 그리퍼라는 2지 그리퍼를 활용해 tracking에서 약간의 오차가 발생하더라도 안정적인 파지가 가능하도록 유도했다고 합니다. soft한데 어떻게 힘이 잘 전달되는지는 의문입니다. 현실에서 작동할 때는 물체의 pose를 metric scale로 정확하게 알기 위해 ZED 2 depth 카메라를 사용했다고 합니다. 실험은 박스 닫기, nerf gun 장전하기, 가위 여닫기, 선글라스 접기 등등 다양한 articulation이 들어간 동작을 사람의 시연 영상 한 개를 통해 복원된 part motion을 따라 로봇이 조작하는 형태로 진행했다고 하빈다. 로봇의 동작과는 별개로 RSRD의 tracking 정확도를 검증하기 위해서도 ZED 2 depth 카메라로부터 획득한 dense RGB 포인트클라우드를 시각화한 뒤, 해당 영상에서 추출한 Gaussian splat 기반의 3D 모델을 수동으로 keyframe마다 정렬하여 ground-truth trajectory를 생성해 GT로 삼 RSRD의 예측 경로를 비교하여 tracking 성능을 평가했습니다.
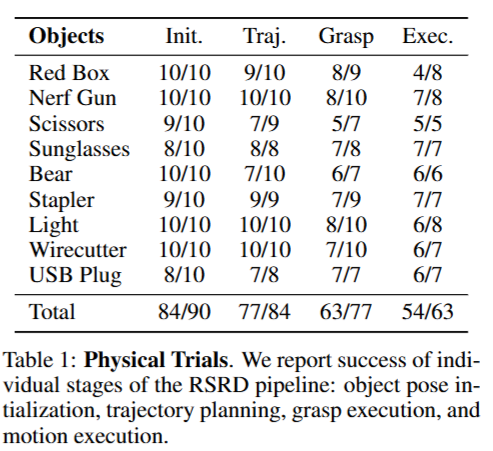
저자들은 Objects에 해당하는 9개의 객체를 대상으로 총 10번씩 실험을 진행하고, 매 trial마다 객체의 초기 pose를 다양하게 변경해가며 진행했다고 합니다. 물체를 로봇 작업 공간 중심에 두고, z축을 기준으로 360도 회전시켜 각 실험마다 다른 방향에서 작업을 수행하도록 했고, 이를 통해 3D object centric reasoning이 가능한 것을 보였다고 합니다. 물체의 초기 pose를 추정하는 init, 로봇이 필요한 부위를 잡기위해 trajectory를 만들었는지, 실제로 grasping에 성공했는지, 시연 영상과 유사한 조작을 했는지(Exec)로 나누어서 평가했습니다. 성공 여부는 저자들이 의미적으로 유사한 행동을 했는지 못 했는지로 결정했다고 합니다. End to End로 봤을때는 90번 중에 54번정도 성공했습니다. Grasp 및 실행 단계에서 다소 성능 저하가 있느것을 볼 수 있습니다.
이어서 파트별 tracking 자체의 정밀도와 각 구성 요소들이 tracking 성능에 얼마나 기여하는지를 ablation 실험을 진행했습니다. 저자들은 총 5개의 객체를 대상으로 각 시연 장면을 스테레오 카메라로 촬영한 후, RAFT-Stereo를 통해 얻은 depth map을 기반으로 keyframe에서 ground-truth part pose를 annotation 했다고 합니다. 이렇게 얻은 정확한 3D pose trajectory와 RSRD의 예측 결과를 비교하여 ADD를 측정했습니다.
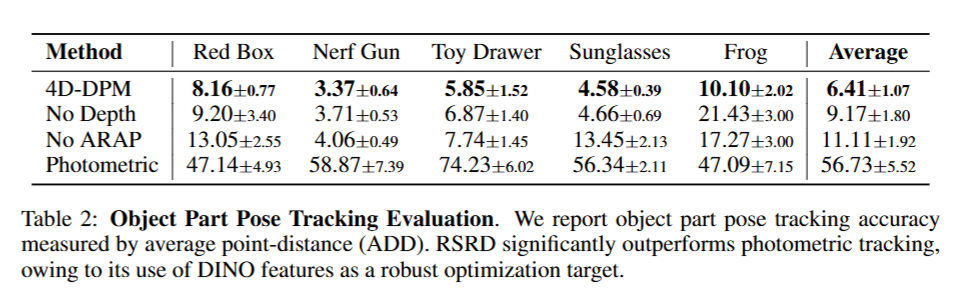
실험에서는 4D-DPM을 Depth 최적화 없이, ARAP 없이, photometric loss만 적용했을 때로 비교해서 실험했습니다. ARAP 정규화를 제거했을 때는 2이상 오차가 증가했으며, 특히 frog 인형처럼 부위가 많고 작은 파트들이 많은 객체에서 이 영향이 두드러졌다고 합니다. ARAP이 part를 구분하는데 있어서 중요한 역할을 하는 것 같습니다. 아래처럼 정성적으로도 확인할 수 있었습니다.

RGB 값 기반의 단순한 손실을 사용할 경우 배경과 객체를 구분하지 못하고, 추적 경로가 완전히 틀어지는 사례가 반복적으로 나타났었다고 합니다. 반면 DINO feature field를 기반으로 했을 때는 foreground와 background를 명확히 구분할 수 있었고 이를 통해 DINO feature가 좋다는 것을 증명했습니다.
다만, 좌우 대칭성이 강한 객체에서는 불안정한 움직임도 관찰되었다고 합니다. 예를 들어, 선글라스의 다리나 인형의 팔처럼 유사한 부위가 반복되는 구조에서는 jittering 현상이 발생하며 부위가 주요 축을 따라 흔들리는 현상이 나타났는데, future work라고 합니다.
Conclusion
RSRD는 결국 4D-DPM이 해당 프레임 워크의 핵심이지 않았나 싶습니다. Object centric한 구조도 4D-DPM 덕분에 가능했던것 같습니다. 다만 4D-DPM이 갖는 한계가 결국 해당 프레임워크의 한계인것 같은데, jittering 현상도 그렇고 만약에 첫 프레임에서 초기 pose를 잘못 추정하게되면 무조건 실패하게 되는게 아닌가,, 싶습니다. 또 사람의 손 위치도 잘 파악되게 시연 영상을 찍어야 하는게 아닌가,, 싶습니다(안 해봐서 모르겠습니다) 추가로 soft gripper가 뭔지도 살펴봐야 할 것 같습니다. (Real2Render2Real 연구에도 해당 gripper가 사용된 것 같습니다)
영규님 좋은 리뷰 감사합니다.
Figure 5의 정성적 결과를 보면 ARAP를 시용하는 것이 물체에 대한 3D reconstruction 퀄리티에 있어 상당히 중요한 역할을 하는 것으로 보여 인상적입니다.
해당 논문과 관련하여 몇가지 궁금한 것이 있습니다. 4D-DPM 과정에서 사람이 수동 조정하여 3D 물체의 파트를 분해하는 것으로 이해하였는데, end-to-end 방식을 볼 수 있는 지 궁금합니다.
또한, 4D-DPM은 다중 view를 이용한다고 하셨는데, 이후에 Monocular 3D Part motion recovery의 경우 단일 RGB는 어떻게 선정이 되는 지 궁금합니다. occlusion등을 고려하지는 않나요?
안녕하세요 승현님 댓글 감사합니다.
질문 주신것 토대로 다시 확인해보니 end-to-end라는 표현은 잘못 된 것 같습니다,, 파이프라인 중간에 사람이 수동으로 조작하여 grouping을 하는것이 맞고, 논문에 등장한 end-to-end라는 표현은 로봇의 작업성공률을 로봇이 initial pose를 맞췄을 때 성공으로 칠지, 이후 실제 action까지 했을때는 성공으로 칠지의 관점에서 initial pose + action을 기준으로 end-to-end로 평가했다고 표현했습니다. 프레임워크 자체는 end-to-end라고 말하기 애매한 것 같습니다.
또 다중 view의 이미지는 garfield를 학습시킬때 (3d reconstruction 할 때 + 마스크 만들어낼 때) 활용되고, 그 결과물을 하나의 RGB 비디오와 최적화하는데, 이 때 영상은 사람의 손이 물체를 움직이는 부분만 특정 각도로 담겨있고, 최대한 occlusion이 덜 발생하도록 하려는 모습을 볼 수 있었습니다. 손 때문에 occlusion도 발생할 수 있지만 HaMeR라는 손을 인식하는 모델을 통해 어떻게 잡아야 하는가에 대한 정보도 얻을 수 있기 때문에 occlusion을 덜 발생시키면서 손가락으로 조작하려는 영상을 볼 수 있었습니다. 더 자세한 기준은 직접 구현해보면서 알아가야 할 것 같습니다.