대형 언어 모델(LLMs)을 비디오 요약에 활용하는 기본적인 접근법이 어떻게 될까요?
저는 위 질문에 대해 답을 찾기 위해 해당 논문을 읽게 되었습니다. 직관적인 제목처럼 제가 보았던 논문중에서 언어모델을 가장 언어모델 스럽게 사용한 논문이라고 느꼈는데요, 리뷰를 통해 소개를 시작해보겠습니다
Intro

최근 비디오 요약(Video Summarization) 관련 논문을 소개했기 때문에, 비디오 요약에 관한 소개는 넘어가겠습니다. 본 논문은 LLMs을 활용해 비디오 요약을 수행하는 방법을 소개한 논문입니다. 최근 소개했던 논문은 VLMs을 이용해 프레임 이미지를 포함한 멀티모달 정보를 임베딩하고, 해당 정보들을 통해 요약 비디오를 학습하는 관점에서 언어모델을 활용했습니다. 그러나 해당 연구는 정보량 임베딩이 아닌 언어모델 자체를 요약이라는 추론에 활용한 것에 가깝습니다. 즉, 기존 연구의 경우 언어모델의 맥락적 정보 표현력을 활용한 것이라면, 해당 연구는 언어모델의 일반 지능 능력을 테스크 해결에 활용했다고 볼 수 있습니다.
논문의 컨셉이 이해가 되셨나요? 위의 Figure 1을 통해 다시 설명해보겠습니다. 붉은색 박스를 보시면 입력받은 프레임별 정보에 대해 언어모델을 통해 important score를 직접 예측하고 있습니다. 즉 요약에 활용될 프레임의 상대적 중요도(important score)예측을 언어모델이 직접수행하는 것입니다. 깔끔한 논문 제목답게 언어모델을 활용하는 방법도 매우 직관적입니다. 자세한 구현방안은 Method에서 이어서 설명하겠습니다.
Method
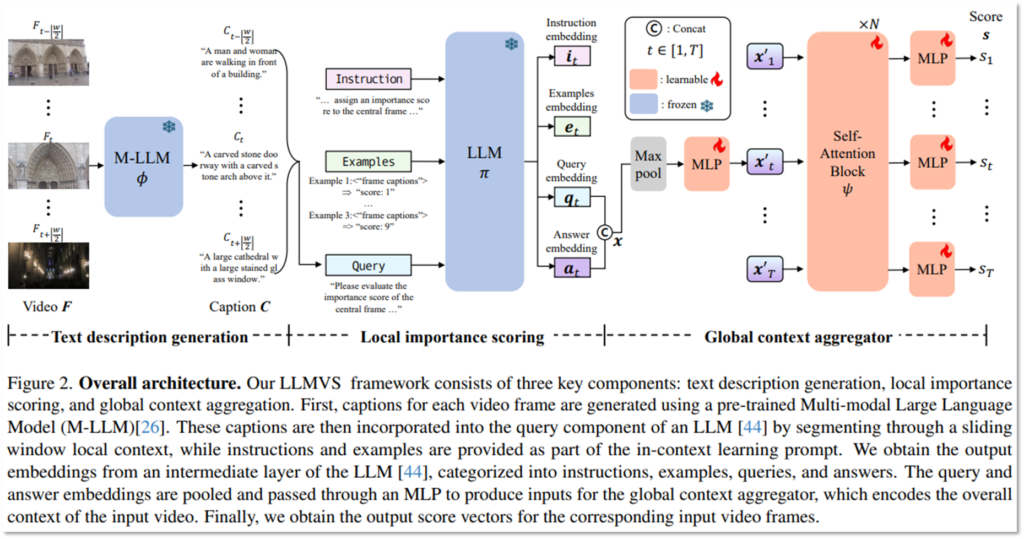
논문에서 제시한 아키텍처의 이름은 LLM-based Video Summarization(LLMVS)입니다. 언어모델을 활용해 비디오 요약을 수행하기 위해서 해당 아키텍처는 3단계를 거치게 됩니다. 먼저 Multi-modal LLM(표기 M-LLM/ϕ, LLaVA-1.5-7B 활용)을 활용해 이미지 프레임 정보를 통해 캡션을 생성합니다.
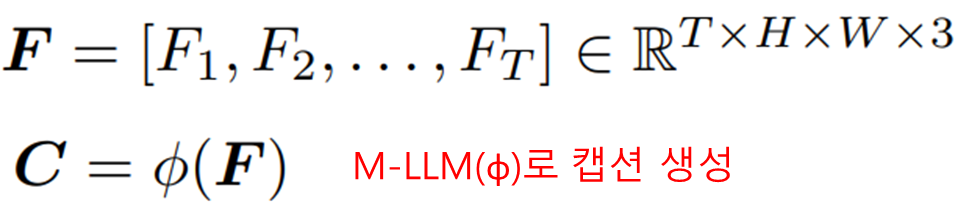
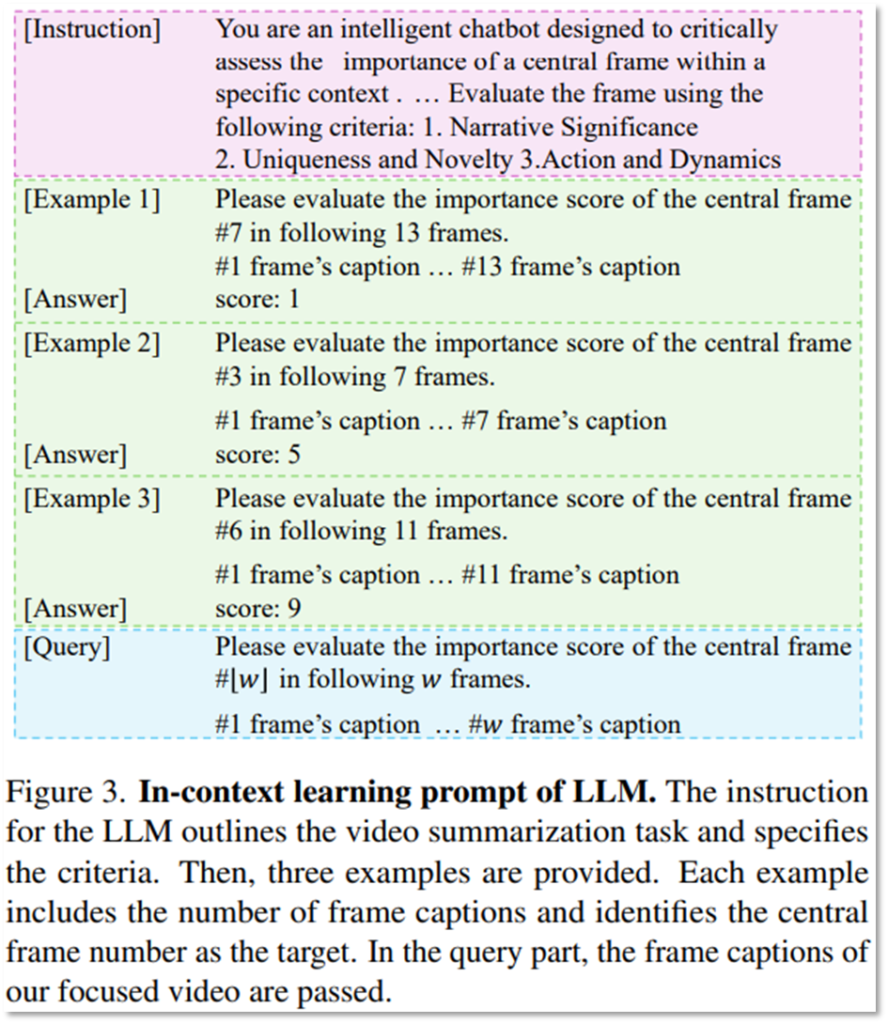
이후 LLM(표기 π, Llama-2-13B-chat활용)을 통해 Local important score를 추론 하게 됩니다. 즉, 기존에 언어모델을 언어와 연관된 특징공간에 비전 정보 등을 임베딩 하여 맥락적 정보를 잘 표현하기 위해 사용했다면, 해당 연구는 언어모델에 비디오의 정보를 직접 입력하여 언어모델의 추론 능력을 활용하고 비디오 예측을 수행한 것입니다. 추론의 정확도를 높이기 위해 In-context learning 기법을 활용했습니다. 아래의 Figure3은 논문에서 활용한 In-context learning prompt입니다. LLLVS는 언어모델 활용에 있어, 예측해야하는 Query 외에도 3가지 예시를 통해 추론의 정확도를 높였습니다.
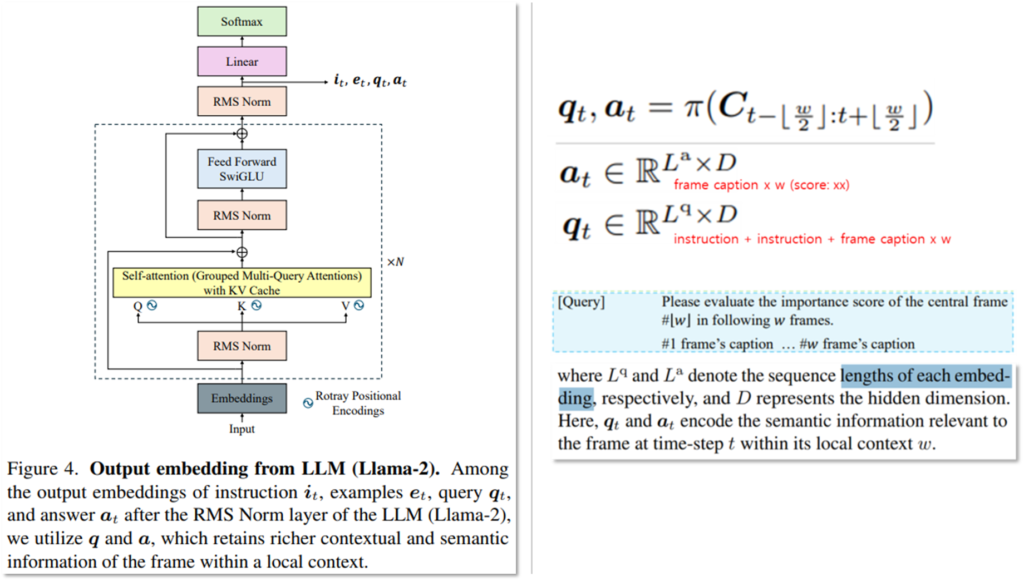
LLMVS는 In-context learning을 활용하여 언어모델을 활용한 추론으로 아래와 같이 쿼리(q)와 예측한 Important score(a)에 대한 출력을 얻습니다. example과 instruction을 통해 query를 모델링하는 방법은 아래와 같습니다. Llama-2의 Self-attention 구조(Figure4의 노란색)를 활용한 것입니다. Figure4는 Llama의 architecture와 동일한데요, 해당 구조의 어디에서 최종 임베딩인 i_t, e_t,q_t,a_t를 추출하게 되는지를 중점으로 보시면 됩니다. 이러한 과정으로 output을 임베딩하며 수식적으로는 우측의 수식으로 나타냅니다(w=7).
마지막으로, example과 instruction을 활용해 잘 임베딩된 쿼리(q)와 예측 결과(a)를 기반으로 비디오 전체 맥락을 고려한 최종 important score 예측을 생성하게 됩니다. LLMVS는 이를 위해 추가적으로 학습가능한 구조를 설계했습니다(Figure2의 주황색? 부분). 해당 구조는 Self-attention block(ψ)와 MLP로 구현했으며 아래와 같으며, ψ는 트랜스포머의 self-attention block을 3번 쌓은 구조입니다.

전체적인 LLMVS의 구조를 살펴보았는데요, 위의 구조의 학습 방법은 지도학습으로 아래의 MSE(Mean Squared Error)로 학습되었습니다.
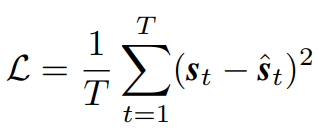
Prove
논문에서는 비디오 요약을 위해 언어모델을 활용하는 직관적인 방법인 LLMVS를 제안했습니다. 또한 제안하는 LLMVS의 효과를 실험을 통해 보였는데, 그 결과는 다음과 같습니다.
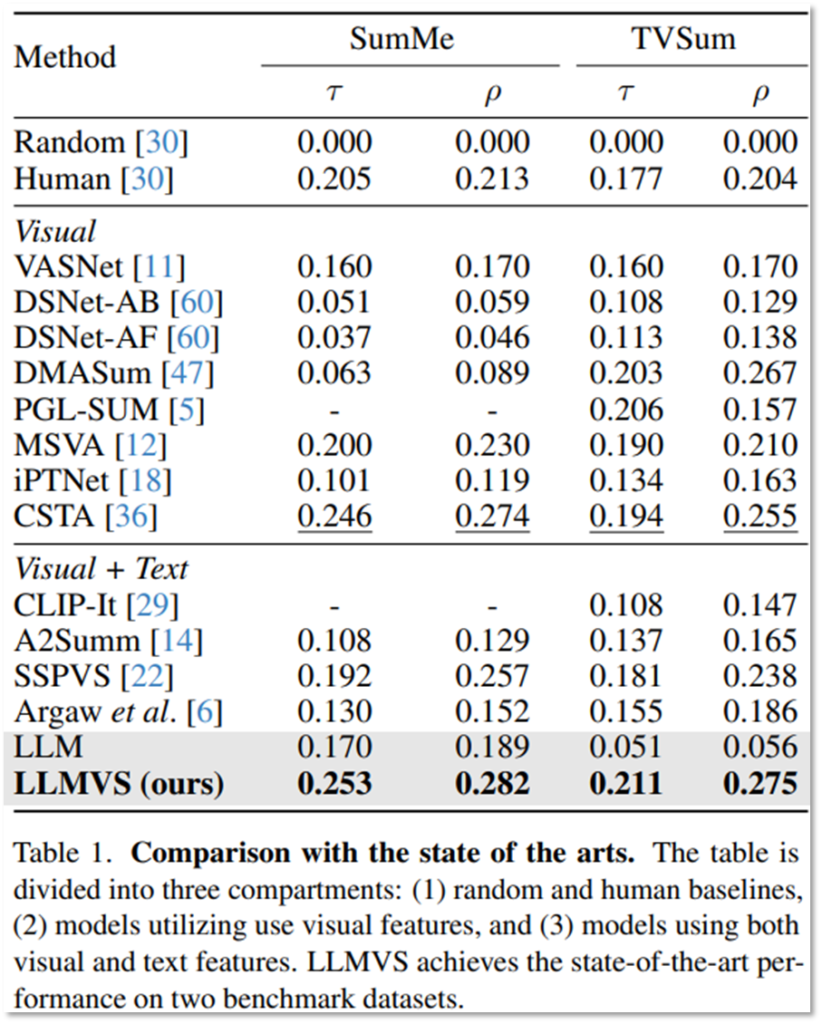
Table1에서 논문은 비디오 요약의 가장 대표적인 데이터셋인 SumMe와 TVSum에 대해서 최신 연구와의 성능 비교를 보였습니다. 실험 결과 비교한 실험군중에서 제안 방법이 가장 효과적이였음을 확인할 수 있습니다. 또한 self-attention 구조 등의 활용 없이 단순하게 In-context learning을 통해 LLM을 활용한 것 보다 제안한 구조가 효과적임을 보이며 언어모델 활용을 위한 구조에 대한 고려가 필수적이였음을 확인했습니다.
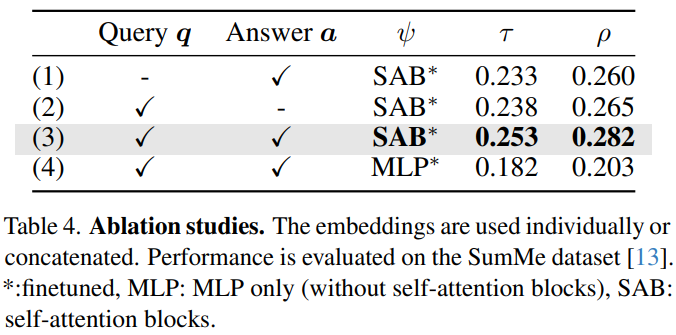
단순 LLMs의 활용과 제안 방법을 가르는 구조는 Self-attention block 구조인데요, 해당 구조에 유효성을 면밀하게 확인할 수 있는 실험 결과는 Table4와 같습니다. 먼저 쿼리(q)와 Important score 예측(a)을 모두 활용했을때가 효과가 좋음을 보였습니다.(Table4에서 1,2와 3의 비교) 다음으로, Transformer의 attention 구조 대신에 MLP를 통해 구현을 했을때(4)보다 제안 방법(3)이 효과적임을 보임을 통해 전체적인 맥락을 고려하는 attention 구조(SAB)가 비디오 요약 테스크 수행에 효과적임을 보였습니다.
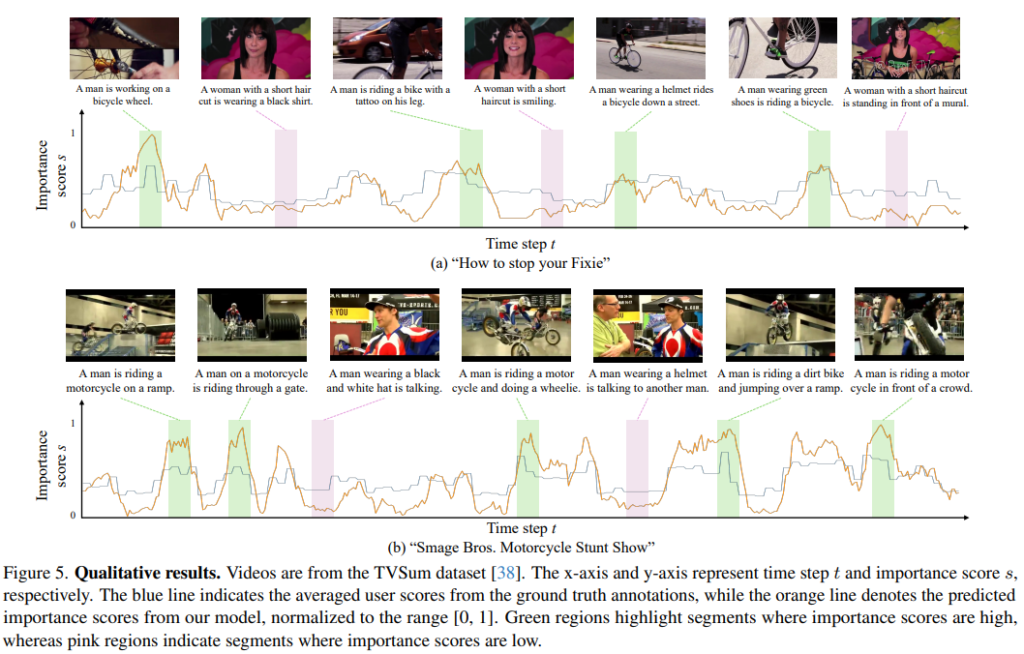
LLMVS를 활용한 정성적 예측의 결과는 Figure5와 같습니다. 녹색 영역은 important score가 높게 예측된 프레임이고 분홍 영역은 낮게 예측된 프레임 입니다. 예측 결과(주황색 선)가 정답값(파란 선)과 유사하게 움직이는것을 확인할 수 있으며, Important score가 높게 예측된 부분이 더욱 맥락적으로 의미가 있음을 확인할 수 있습니다. 예를 들면 (a)에서 여성이 말하는 장면이 나올때 Important score과 주로 낮게 관측된 반면, 역동적인 자전거의 움직임을 포함한 장면은 높은 점수로 예측되었음을 확인할 수 있습니다. 이는 모델이 action-oriented한 해당 데이터셋의 맥락을 잘 파악한 결과로 유추할 수 있습니다.
이상으로 언어모델을 활용한 비디오 요약에 대한 연구 결과 소개를 마치겠습니다.
안녕하세요 유진님, 논문 제목이 직관적이어서 궁금해서 리뷰를 읽게 되었는데, 많은 도움이 되었습니다.
좋은 리뷰 감사드립니다! 한 가지 단순한 궁금증이 생겨 조심스럽게 질문드립니다.
LLM이 프레임별 중요도를 직접 추론하는 방식은 언어모델의 일반화 능력을 효과적으로 활용한 사례라고 느꼈는데, 반대로 이러한 접근이 입력 프레임의 실제 정보와 무관한 hallucination을 유발할 가능성도 존재하지 않을까 하는 생각이 들었습니다. 혹시 논문에서는 모델이 입력과 무관한 프레임을 중요하게 판단한 경우에 대한 어떤 분석이나 언급이 있었는지가 궁금합니다!
감사합니다!
안녕하세요 우현님
좋은 질문 감사드립니다.
말씀하신 것처럼 LLM이 hallucination을 유발할 가능성이 있습니다. 이를 최소화 하기 위해 단순히 쿼리(해당 프레임의 중요도 점수는?)만 입력하는 것이 아닌 example을 같이 제공하는 In-context learning 을 활용한 것입니다.
물론 그럼에도 잘못된 예측을 하는 현상은 발생할 수 있습니다. 그러나 해당 상황에 대한 직접적인 분석은 없었고, table4의 ablation study에서 LLM의 예측인 answer a를 활용할때 성능이 그렇지 않을때보다 좋은것을 통해 hallucination에 의한 성능 저해보다 이점이 많았음을 예측할 수 있을 것 같습니다.
감사합니다