이번 리뷰 논문은 로봇 러닝 측면에서 하고 싶었던 방향을 구현한 기법으로, 실제 로봇이 없이 그리고 동적인 시뮬레이션에 대한 구축 없이 학습 데이터를 생성하는 방법을 제시한 논문 입니다.
Intro
최근 인공지능 로봇에 대한 관심도가 날이 갈 수록 높아지고 있습니다. 아마 연구원 분들도 뉴스나 유튜브를 통해서 테슬라의 옵티머스, 보스턴다이나믹스의 아틀라스, figure AI의 Helix (figure 02), 유니트리의 H1등과 같은 휴머노이드 로봇을 이용해서 사람처럼 자연스러운 행동을 하는 것을 본적이 있을 겁니다.
조금 더 관심 있으신 분들은 옵티머스가 사실 원격 조작을 한 것이라는 의혹은 받고 있다는 기사를 본 적 있을 겁니다. 사실, 영상에 나온 것처럼 자연스러운 작업을 할 정도로 로봇은 아직 충분히 지능적이지 않습니다. 테슬라의 옵티머스인 경우, 이동을 할 때만 인공지능을 사용하고 그 외의 사람과 소통하거나 바텐더를 한 행위들은 원격조종을 했다고 밝히기도 했죠.
그럼, 현재 수준은 어느정도인지 궁금하실 겁니다. 현재 인공지능 로봇은 제약된 환경에서 하드코딩을 하거나, 동일한 작업을 수행하는 데에 있어서는 꽤나 노련한 성능을 보여주고 있습니다만… 비정형적인 환경에서는 동작하길 기대하기 어려운 수준이라고 생각하시면 됩니다. 극단적인 경우로 VLA의 시각적 강인성 실험으로 조명을 끄거나, 학습과 다르게 물체를 가변적으로 위치 시키거나, 보지 못한 장애물이 등장시켜 안정성을 실험해도 인정 받는 상황이라고 생각하시면 됩니다.
VLM이 등장하고 VFM이 등장한 시기에 이러한 한계를 가지는 이유가 뭘까요? 웹에서 크롤링을 하기 용이한 텍스트나 시각 데이터들과는 다르게 로봇 데이터들은 웹에서 수집이 어렵습니다. 이제부터 수집하기 시작해야한다는 거죠.
이러한 한계를 산학연에서도 인지하고 있었으며, 해당 문제를 해결하기 위해서 다양한 기관에서 협력하여 로봇 데이터를 수집하는 노력들(OEX, DROID…)도 있었습니다. 해당 노력을 토대로 VLA이 의미 깊은 실험 결과를 보여주면 인공지능 로봇에 대한 기대치를 크게 향상시켰죠.
하지만 더 많은 기관들이 협력하여 데이터를 수집하더라도 LLM이 학습한 데이터 수준을 확보하는 것을 불가능에 가까울 겁니다. 그럼 정말 불가능하기만 할까요? 이러한 한계를 극복한 예시가 vision-language 분야에서 확인 할 수 있습니다. 해당 분야에서는 생성형 모델을 통해서 vision-language pair가 부족한 상황을 극복하였고, 이를 성능으로 검증해주었죠.
이에 영감을 얻어 로봇 분야에서도 생성형 모델을 활용하여 로봇 데이터를 확장하려는 움직임이 있습니다. 가장 대표적인 예시가 젯슨 황과 fei-fei Li 교수님 등과 같이 세계적인 석학들이 주목하는 World-Foundation Model (WFM)이라고 보시면 됩니다. 이외에도 관측된 실제 세계를 시뮬레이터에 옮기고 시뮬레이터에서 학습을 진행한 다음, 이를 실제 세계에서 동작하도록 하는 Real-to-Sim-to-Real이 있습니다.
+ WFM은 아직 명확하게 어떤 컨셉인지, 어떤 패러다임인지에 대한 정확한 정의가 이뤄지진 않았습니다. 확실한건 지능형 로봇을 위해서는 실제 세계를 일반화하여 표현 가능한 기본 모델이 필요하다는 점일 뿐임다.
저자는 로봇 데이터의 부족 문제를 해결하기 위해서 새로운 Real-to-Sim-to-Real를 제시합니다. 기존 기법들은 Real2Sim을 수행하기 위해서 다음과 같은 한계가 존재했습니다.
- 각 물체에 대한 수동 어노테이션이 필요함. e.g. 관절 구조를 가진 객체에 대한 어노테이션, 유사한 사전 asset을 활용 (digital cousine)
- 시뮬레이터 내에 서 동적인 조작을 수행하기 위해서 수동적인 어노테이션을 수행
- 작업 수행을 위한 실제 로봇 데이터 혹은 시뮬레이터 내에서의 환경 설계 (reward)
- 또한, Sim2Real을 수행하기 위해서 실제 로봇을 활용한 co-training 필요
저자는 위 한계들을 극복하기 위해서 Real2Render2Real을 제안합니다. 해당 기법이 제시하는 방향은 다음과 같습니다.

- 사전 asset이나 수동 어노테이션 없이 휴대폰으로 스캔한 multi-view object scan으로부터 3DGS로 asset으로 구성
- human demonstration video로부터 rigid or articulated object에 대한 tracking 및 part trajectories를 추출
- 시각적 강인성을 확보하기 위한 영상 데이터 측면에서의 데이터 증강과 초기 trajectories의 의미론적 의도를 유지한 trajectories 증강
- 병렬 환경 구축이 가능한 issac labs을 이용하여 빠르게 증강한 데이터 생성
- 증강한 데이터를 이용한 모방 학습 (Diffusion Policy~VA, pi-zero-fast~VLA)
저자는 저자가 제안한 생성 데이터와 human teleportation 데이터 간의 모방 학습 (Diffusion Policy~VA, pi-zero-fast~VLA)에 대한 비교 실험을 진행을 통해 해당 데이터 생성 방식이 효과적임을 선보입니다.
Method
방법론은 굉장히 간단합니다. 기존 기법들을 조합하여 제시한 방법론이기 때문에 자세한 기법에 대해서는 넘어가고자 합니다. 혹여 궁금하신 분들은 댓글로 요청해주시면 관련 기법에 대한 리뷰 혹은 답글로 설명해드리도록 하겠습니다.
Assumptions. 저자는 실험에 앞서서 해당 실험에 대한 몇 가지 전제를 설정합니다. 1. 객체는 rigid or articulated object에 해당. 2. 조작 환경은 table-top setup이며 천천히 변화되는 준정적 조건임. 3. 객체의 표면은 반사되거나, 투명한 물체하거나, 특징이 적은 경우는 배제함. 4. human demonstrations 중에는 객체들이 완전히 가려지지 않도록 구축. ( 5. 물리적인 setup에서의 상대적인 카메라 포즈를 추정하거나 사용 가능하다고 전제하며, 주변 viewpoint에서 observations을 생성 가능 (+3DGS 위한 제약). 6.policy 학습 중에는 RGB 영상과 robot’s proprioceptive state를 입력으로 사용 가능
+ robot’s proprioceptive state: robot의 configuration
Overview. Real2Render2Real (R2R2R)은 single human demonstration과 multi-view object scan으로부터 RGB-action pair로 구성된 로봇 데이터를 합성하기 위한 데이터 생성 기법입니다. R2R2R은 3 단계로 구성됩니다. (1) real-to-sim asset and trajectory extraction. 실제 세계의 smartphone으로 촬영된 영상으로부터 rigid or articulated object gemetry와 part trajectories를 추출합니다. (2) augmentations. 객체의 초기 상태에 대한 랜덤화와 object motion trajectories에 대한 interpolation. (3) parallelized rendering. 다양한 photorealistic robot executions을 생성하기 위해서 IssacLab을 이용하며, 사용가능한 GPU 메모리 혹은 수에 따라 확장 가능합니다.
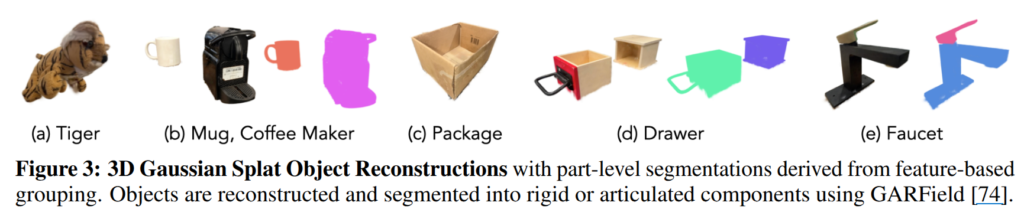
Real-to-Sim Asset Extraction. 먼저, 4D-DPM [1], POGS [2]에 영감을 얻어 두 단계로 스마트폰 스캔으로부터 3D object assets을 추출합니다. 먼저, 영상으로부터 object geometry와 appearnace를 3DGS를 이용하여 재구성합니다. 그런 다음에 GARField [3]를 적용합니다. GARField는 fig 3에서 보이는 바와 같이 객체에 대한 3DGS에 2D sement 정보를 3D 공간으로 lifting 시키는 기법이며, 의미론적으로 grouping이 가능한 영역을 구분하는 기법입니다. 해당 기법을 통해서 object-level에서 part-level에 대한 decomposition이 가능합니다. 이를 통해서 articulated object에 대한 구성도 annotion이 가능합니다. 더 나아가 mesh-based rendering을 위해서 가우시안을 triangle mesh ~ SDF로 변경 가능한 Sugar [4]를 적용합니다.
—-
[1] Kerr, Justin, et al. “Robot see robot do: Imitating articulated object manipulation with monocular 4d reconstruction.” arXiv preprint arXiv:2409.18121 (2024).
[2] Yu, Justin, et al. “Persistent object gaussian splat (pogs) for tracking human and robot manipulation of irregularly shaped objects.” arXiv preprint arXiv:2503.05189 (2025).
[3] Kim, Chung Min, et al. “Garfield: Group anything with radiance fields.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024.
[4] Guédon, Antoine, and Vincent Lepetit. “Sugar: Surface-aligned gaussian splatting for efficient 3d mesh reconstruction and high-quality mesh rendering.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024.
Real-to-Sim Trajectory Extraction. 스캔된 객체에 대해 사람이 조작하는 영상이 주어졌을 때, R2R2R은 [1]에서 소개된 6-DoF part motion을 적용합니다. 각각의 3DGS object part는 사전 학습된 DINO feature가 임베딩되어져 있으며, differentiable rendering을 통한 part pose optimization이 가능합니다. 저자는 [1]을 확장하여 단위 뿐만이 아니라 다중 객체에 대해서도 수행하 가능하도록 했다고 합니다.
+ 굳이 3DGS에서 mesh화 시키는 방법을 사용하는 이유에 대해서 저자는 (1) 배경과 전경에 대한 구분과 part decomposition via 3D grouping [4]을 적용하기 위함으로고 합니다. 해당 방법이 [1]로 이어지기 때문에 part trajectories에 대한 추적이 용이해진다고 합니다. (2) 시뮬레이터에 업데이터가 용이해지기 때문에 데이터 증강이 편해진다고 합니다.
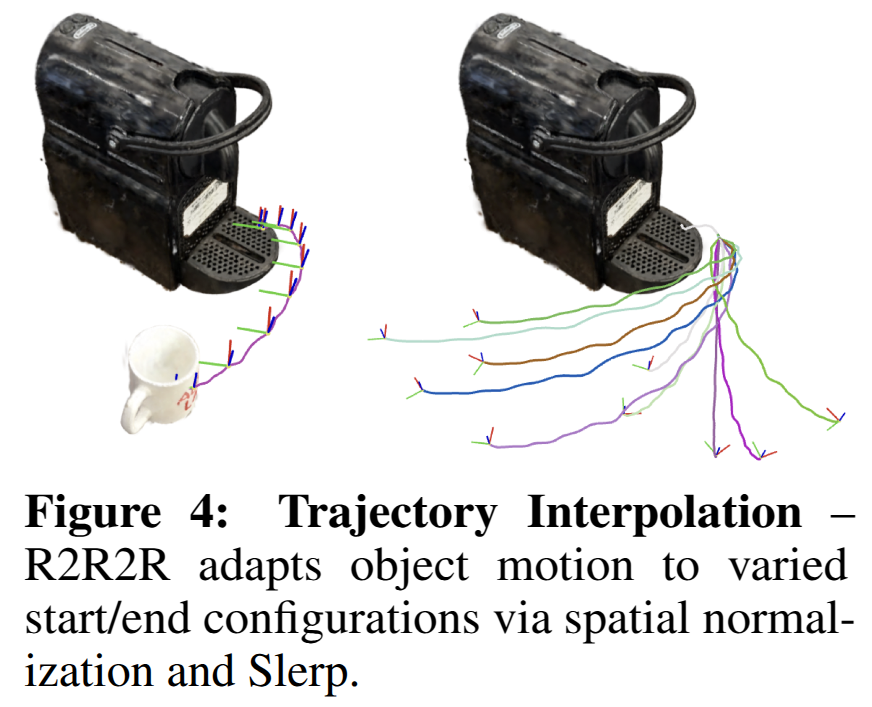
Interpolation Methods for Object Trajectory Diversity. 앞선 방법으로 단일 경로만 생성되기 때문에 경로에 대한 다양성을 위해서는 증강이 필요하나 단순하게 접근하는 경우에는 말도 안되는 경로로 생성될 가능성이 있습니다. 저자는 초기 경로에 대한 의미론적인 의도를 유지하면서 새로운 interpolation 하는 방법을 제시합니다.
사실 엄청 단순한데요. 기존 경로가 있기 때문에 해당 경로에서 키프레임을 선정하여 spherical linear interpolation (Slerp) ~ 구 안에서의 방향 변화를 줌으로써 증강했다고 합니다. fig 4에서 확인 가능합니다.
Grasp Pose Sampling. R2R2R은 human demonstration video로부터 3D hand keypoint를 HaMeR [5]를 이용하여 추출합니다.그다음 집게 손가락 끝과 엄지 손가락의 키포인트와 분할된 모든 object part의 중심 사이의 유클리드를 계산하여 object-hand interactions을 정의합니다. 해당 방법을 통해서 antipodal grasp sampler를 선정합니다.
+antipodal grasp sampler은 gripper의 finger tip 사이 안에 들어오는 객체의 위치를 파지 가능한 위치라고 보는 방법이라고 생각합니다. 저자는 DexNet을 참고했다고 합니다.
===
[5] Pavlakos, Georgios, et al. “Reconstructing hands in 3d with transformers.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024.
Differential Inverse Kinematics. PyRoki라는 공저자가 새롭게 작성한 motion planning tool을 이용합니다. 이미 경로에 대해서는 주어져 있기 때문에 해당 경로에 대해서 최적화를 수행하는 파트라고 생각하시면 됩니다.
Rendering Diverse Environment Contexts. 강인성 확보하기 위해서 scene geometry와 rendering parmeter에 대한 랜덤화를 수행합니다. 여기에는 lighting conditions, camera extrinsic, object initial poses가 포함됩니다. 해당 방법은 실제 세계와 시뮬레이터 에대한 apperarnace gapr과 covariate shift를 완화하고 일반화를 향상시켜준다고 합니다.
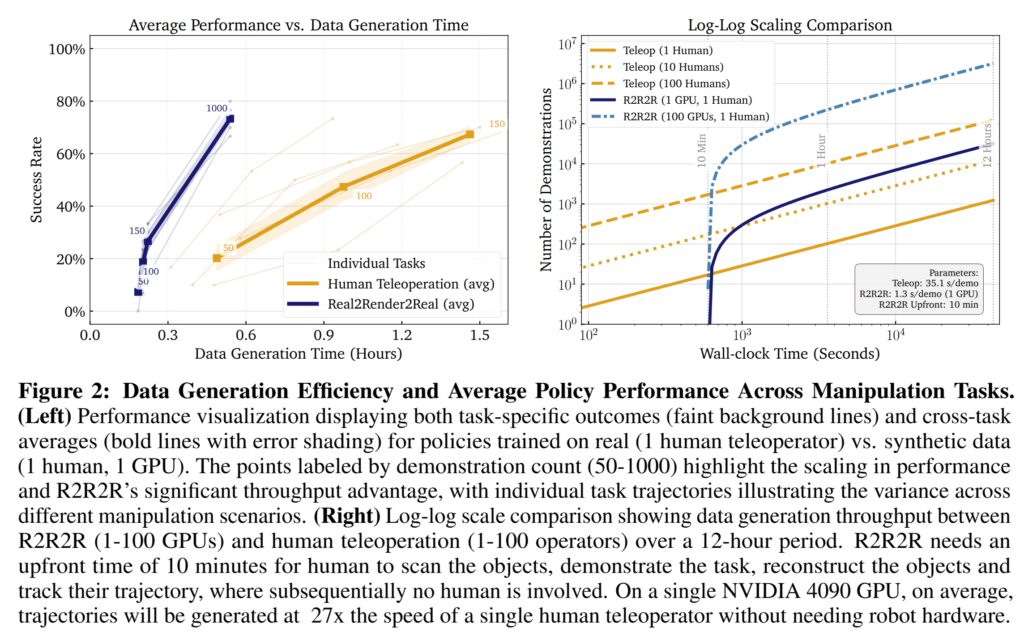
High-Throughput Rendering. IssacLab을 이용하여 병렬적인 데이터 증강을 수행합니다. fig 2에서 보이는 바와 같이 human teleoperation 대비 빠른 속도로 데이터 구축이 가능하며, 경쟁력 있는 성능을 보여줍니다. fig 2 오른쪽에서는 100개의 GPU를 사용하면 더욱 빠른 속도로 데이터 생성이 가능하며, 확장 가능성을 보여줍니다.
Policy Learning. VA인 diffusion policy와 VAL인 pi-zero-FAST에서의 실험을 진행합니다. Diffusion policy는 448px, 16 denoised steop을 수행하며, ee pose에서 예측을 수행 + 3H->single NVIDA GH200. pi-zero-FAST는 LoRA (rank=16) fine-tunning을 하며, 224x rgb를 입력 + 11H->single NVIDA GH200
Experiment
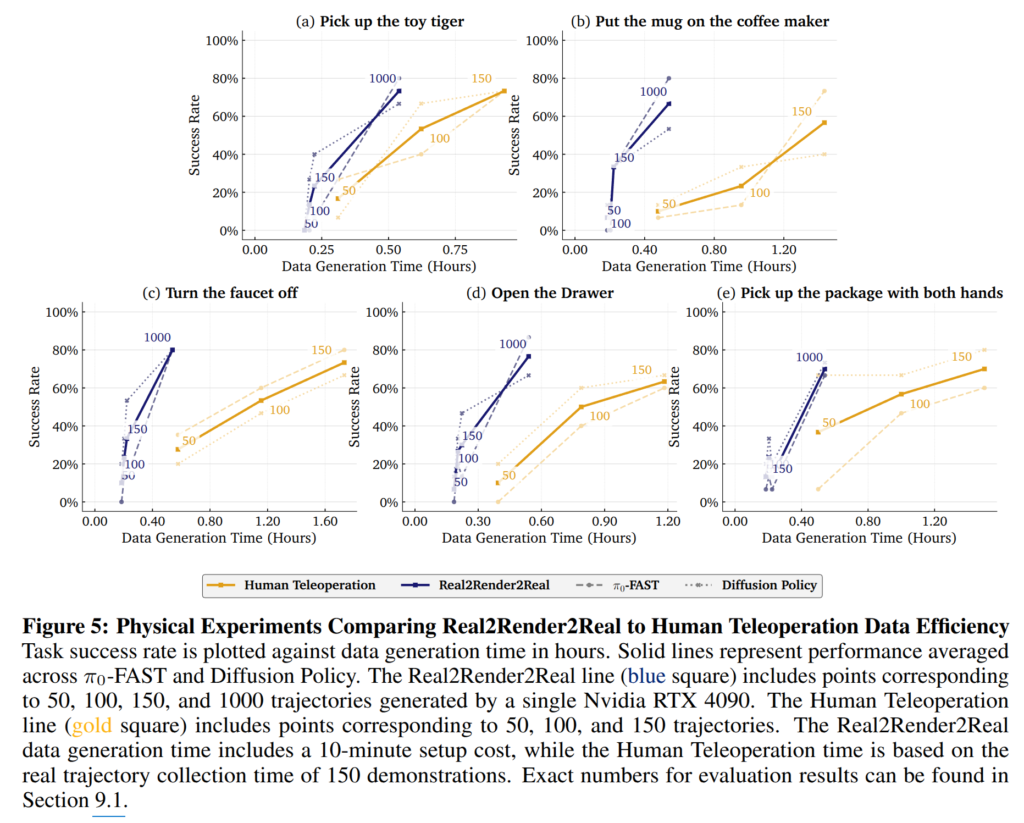
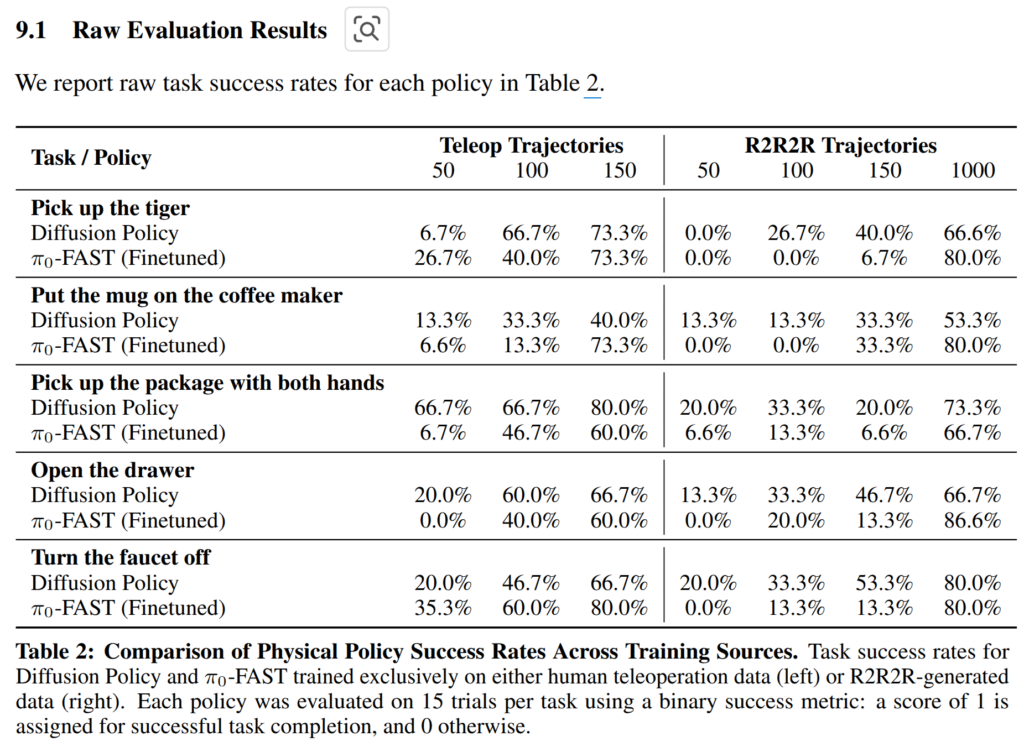
모든 실험은 VLA이 사전 학습하면서 보지 못한 로봇인 ABB YuMi IRB14000 Bimanual Robot를 이용하여 평가를 진행함.
실험 결과 fig 5와 tab 2에서 보이는 바와 같이 저자가 제시한 생성된 데이터로만으로도 경쟁력 있는 성능을 보여주면 일부에서는 오히려 뛰어난 결과를 보여줌
Trajectory Interpolation

Trajectory Interpolation 여부가 성능 다양성에 대한 큰 영향을 줌…
Background and Tabletop Texture Augmentation

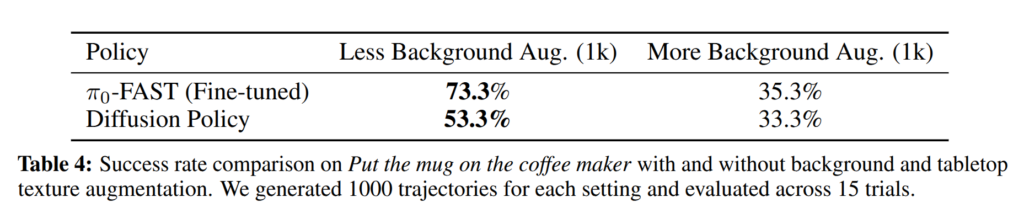
배경을 fig 6과 같이 너무 다양하게 반영하면 오히려 성능이 하락하는 경향을 보여줌… 이에 대한 정확한 이유에 대해서는 더욱 밝혀져야 하는 것으로 파악됨
Sim-and-Real Co-training

저자가 생성한 데이터만 이용해도 향상된 성능을 보여주며, Diffusion Policy에서는 co-training을 하면 성능이 향상된 결과를 보여줌. FAST에서는 개선되지 못한 성능을 보여주는 데, 이는 LoRA의 제약이 크다고 본다고 함. LoRA가 아닌 추가 학습을 하면 더 나아진 결과를 보여 줄 수 있다고 함
하이요. 리뷰 봤는데 낯선 분야이기도 하고 최신 기술들이 총집합해서 하나의 framework을 제안한 것이다보니 압도적인 기술의 발전 앞에서 제 자신의 무기력함이 느껴지는 논문이었네요.
리뷰 읽으면서 궁금한 점이 있는데,
3DGS가 뭔가요? 3D gaussian splat의 약자인건가요? 갑자기 약자가 등장해서 뜻을 정확히 모르겠네요.
그리고 저는 시뮬레이터의 장점이 다양한 장면들을 만들어서 학습시킬 수 있다고 생각하는 관점에서 리뷰 내용 중 Assumption 설명 부분에 객체 표면이 반사, 투명, 특징이 적은 경우 등을 배제한다고 하는 내용이 의문점이 생겨서요.
task 자체가 grasping이다보니 위에 가정들이 grasping하기 까다로운 상황이라고 볼 수 있는데 이런 것들을 잘 하기 위해서 시뮬레이션 데이터를 만들어 학습하는 방향이 저는 이상적이라고 생각을 하는데, 저자들이 제안하는 데이터 생성 방식으로는 저런 까다로운 케이스들을 만들 수 없는 것인지 그리고 없다면 어떤 부분에서 막혀서 그런 것인지 궁금하네요. Gaussian splat이 잘 안돼서 그런건지?
오랜만에 저희 팀이 아닌 분이 댓글을 달아주셨네요 ㅋㅋㅋ
제가 리뷰하는 논문들은 저희 팀만 읽다 보니 약자를 안 풀고 그냥 사용하고 있었습니다.
안일했는데 다시 신경 쓰도록 하겠슴다.
Q1. 3DGS가 뭔가요? 3D gaussian splat의 약자인건가요?
A1. 3DGS는 예측한 바와 동일하게 3D Gaussian Splatting이 맞습니다.
Q2. 이런 것들을 잘 하기 위해서 시뮬레이션 데이터를 만들어 학습하는 방향이 저는 이상적이라고 생각을 하는데, 저자들이 제안하는 데이터 생성 방식으로는 저런 까다로운 케이스들을 만들 수 없는 것인지 그리고 없다면 어떤 부분에서 막혀서 그런 것인지 궁금하네요. Gaussian splat이 잘 안돼서 그런건지?
A2. 예리한 질문은 해주셨는데요. 시뮬레이터로 반사, 투명, 특징이 적은 표면을 만드는 건 가능합니다만… 수 많은 전문가들의 지식이 필요하기 때문에 많은 비용이 들어가는 걸로 알고 있습니다.
실제로 여러 시뮬레이터를 이용해서 실험을 진행해보지만 만족할만한 수준의 시뮬레이터는 존재하지 않고요.
그리고 무엇보다 해당 연구는 3D Asset을 만드는 전문가, 시뮬레이터의 물리적 특성을 분석하여 부여하는 전문가, 시뮬레이터를 구현하는 전문가, 시뮬레이터 내에서 로봇의 학습이 가능하도록 환경을 구축하는 로봇 학습 전문가 등 없이 솔루션만으로 해결 가능함을 보여준 것이 해당 논문의 컨트리뷰션이라고 보고 있습니다.
+ 말씀하신 걸 잘하는~현실과 같은 시뮬레이터를 만드는 것도 중요한 Physical AI의 한 부분에 해당합니다.