안녕하세요 류지연입니다.
TESTR과 DPText-DETR에 이어서 텍스트 인식 task에 집중하며 논문을 읽고 교육받고 있습니다. 당분간은 이 주제의 논문들을 읽고 리뷰를 작성할 듯 싶습니다. 이번에는 Text Recognition만을 다룬 연구인 DiG 논문을 가져왔습니다. 그리고 이 논문의 주제를 한줄로 정리하자면 Self-supervised learning을 text recognition task에 적용한 연구입니다.

1. Introduction & Related Studies
다른 도메인의 테스크에서도 그렇듯 Text recognition task도 데이터셋 라벨링으로부터 자유롭지 않습니다. Recognition을 수행하는 모델을 학습시키기 위해서는 이미지에서 각 텍스트 마다 주석이 필요한데요 이는 아주 고비용의 작업입니다. 이런 데이터 부족 문제를 해결하기 위해 이전 연구들은 합성된 이미지를 사용했습니다. 합성 데이터란 텍스트가 없던 이미지 위에 텍스트를 붙여 합성된 이미지를 가리킵니다. 아래는 대표적인 합성 데이터셋 SynthText의 사진 일부입니다. 보시면 다른 scene text data와는 조금 어색함을 느낄 수 있습니다.

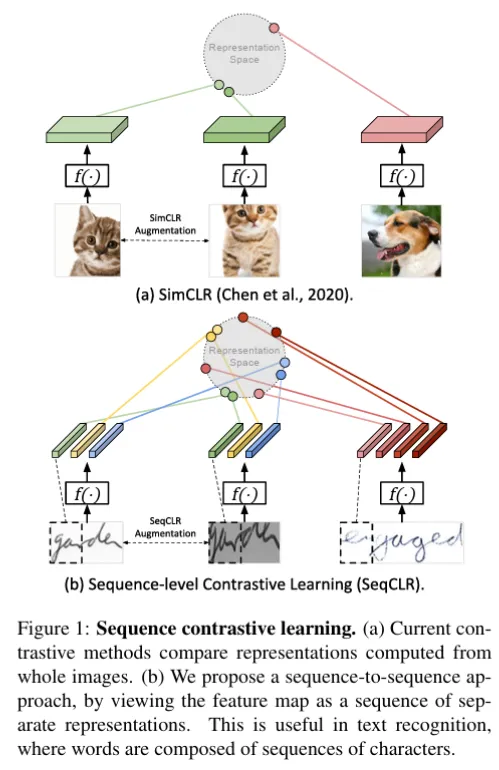
이렇게 더 많은 양의 데이터를 확보할 수 있었지만 real data와 이런 synthetic data간의 gap으로 text recognition 모델의 성능을 개선하는데에는 한계가 있었다고 합니다. 데이터셋이 부족하고 라벨링이 어려운 분야의 task에 대한 모델을 학습하는데 자기 지도 학습 방식을 사용하는 것이 보편화 돼있었습다. Text recognition 태스크에 자기 지도 학습을 적용한 게 이 논문이 처음은 아니었는데요 특히 자기지도 학습 방법으로 contrastive learning을 사용한 여러 연구는 존재했었습니다. 대표적인 연구로는 SeqCLR, PerSec이 있습니다. 기존 이미지 분야에서 contrastive learning을 적용한 연구들은 대부분 이미지 하나에 대한 벡터를 임베딩 공간에 나타내고 이미지 간의 유사도를 학습한 반면 SeqCLR은 텍스트 데이터 특성 상 연속성을 갖는 sub-word level의 sequence로 나눠 이를 각각 임베딩한 후 유사도를 학습시킨다는 게 다릅니다. 아래는 SeqCLR 논문의 figure로 그 두 도메인에서의 대조학습 적용방식이 다름을 확인할 수 있습니다.
또한 PerSec이란 방법은 텍스트 이미지에 대해서 여러 스케일의 피처맵에 대해 contrastive learning을 적용하겠다는 방법입니다. 기존에 high-level feature map에 대해서만 contrastive learning을 수행한 것과는 달리 low level에서의 feature map도 뽑아 의미론적인 정보까지도 보겠다는 내용의 연구입니다. 무튼 앞서 얘기한 두 연구 모두 같은 이미지간에는 유사도를 다른 이미지간에는 차이나는 정도를 가지고 서로 다른 텍스트 이미지를 구별하도록 학습이 된다고 보면 됩니다.
저자는 사람이 통상적으로 텍스트를 인식할 때 reading과 writing이 모두 동반된다고 설명합니다. 여기서 말하는 reading이란 서로 다른 텍스트가 갖는 생김새 차이를 인지해 구별할 수 있는 능력을 말하고 writing이란 텍스트에 가려진 부분이 있어도 다른 부분으로 부터 유추가 되는 generation 능력을 말합니다. 그래서 저자는 이런 text recognition 모델도 reading과 writing의 방법을 통해 학습시킬 필요가 있겠다고 제안하며 Discriminative and Generative self-supervised learning method (줄여서) DiG를 제안하였습니다. 잘 와닿지 않을 수 있기 때문에 이 논문의 핵심 요지를 요약하자면 DiG는 discriminitive representation을 학습하도록 1) contrastive learning을 generative representation이 학습되도록 2) masked image modeling의 자기지도 방식으로 사전학습하는 것을 제안한 연구입니다. 두가지 자기지도 학습 방식을 통합한데에 의의가 있습니다. 그리고 사전학습한 모델의 인코더에 필요한 디코더를 붙여 text recognition, text segmentation, super-resolution 등의 downstream task에 적용해 그 확장성도 보였습니다.
2. Methodology
논문에서 제안하는 방법은 self-supervised learning의 통상적인 과정을 그대로 따릅니다. Pretraining 단계에서는 라벨링 되지 않은 데이터를 가지고 인코더가 학습이 되고 학습이 끝나면 학습된 인코더에 각 down stream task에 맞는 디코더를 붙여 각 테스크에 해 파인튜닝을 수행합니다. self-supervised learning은 적은 양의 라벨링 데이터로도 높은 성능을 낼 수 있는 대표적인 방법입니다.
논문에서 작성한 순서 그대로 첫절에서는 전체적인 구조를 말씀 드리겠고 그 다음에는 contrastive learning module, masked image modeling module이 각각 이 모델에서 어떻게 설계가 되었는지를 깊이 다루겠고 마지막으로 목적함수와 앞서 언급드린 3가지 downstream task에 어떻게 적용이 되는지를 설명 드리겠습니다.
2.1 Architecture
DiG의 아키텍쳐는 다음과 같습니다.
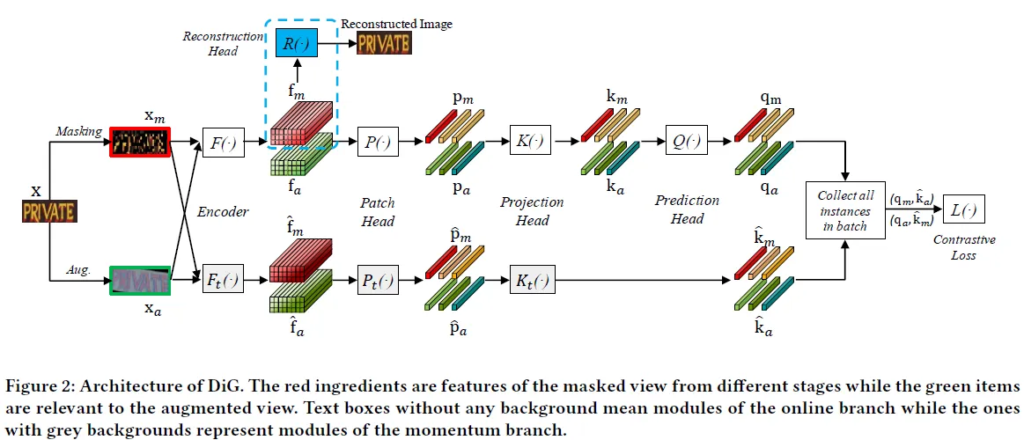
위 구조도에 보이는 대로 이미지에서 텍스트 부분만을 crop한 패치단위의 이미지를 입력으로 받습니다. recognition task는 일반 text detection이나 text spotting task에서와는 다르게 오직 하나의 텍스트 인스턴스만 나와있는 패치화된 이미지를 학습 데이터로 받습니다. 입력된 이미지는 크기가 조정이 되고요. 입력된 이미지를 마스킹하고 증강을 따로 적용한 두개의 이미지를 인코더의 F(\cdot ) 입력으로 들어갑니다. DiG 아키텍쳐는 위와 같은데 크게 총 3개의 브랜치로 나눌 수 있습니다. 인코더를 타고 나와 마스킹된 이미지로 부터 추출된 f_m을 reconstruction head에 통과시켜 원래 이미지로 재구성하는 과정을 r거치게 되는데 이를 masking image modeling 브랜치라고 하고 모델이 generative representation 학습하도록 유도하는 부분입니다. 인코더로 부터 마스킹된 이미지와 증강이 적용된 이미지 각각 에 대해 얻은 f_m, f_a를 차례대로 Patch Head, Projection head, Prediction head에 통과시켜 contrastive learning의 쿼리 q_m, q_a를 얻는 전 과정은 contrastive learning 브랜치입니다. 여기서 추가로 momentum branch를 두어 contrastive learning 시 필요한 \hat{k}_m, \hat{k}_a를 얻습니다.q_m은 \hat{k}_a와 그리고 q_a은 \hat{k}_m과 하나의 positive 쌍을 이뤄 contrastive learning이 이뤄집니다. 같은 배치내의 다른 이미지하고는 negative 쌍을 이루게 됩니다.
2.2 Contrastive Learning
contrastive learning 알고리즘은 MoCo v3의 것을 따릅니다. 여기에 추가적으로 조금만 변경하여 적용합니다. 인코더의 표현력을 증대시키기 위해 증강 기법은 PerSec의 방법을 따랐다고 합니다. 인코더로는 ViT을 사용합니다. 인코더의 입력 이미지의 크기를 조정한 다음 4×4 크기의 패치로 분할해 flatten 시키고 인코더가 D 차원의 token embedding을 받는다고 할 때 linear projection layer를 태워 linear한 patch embedding을 만듭니다. 순서도 보존하기 위해 1D의 positional embedding도 더해집니다.
기존에는 contrastive learning이 객체 탐지에 특화되게 적용이 됐어서 일반적으로 하나의 이미지에 대해서 인코딩된 feature를 하나의 벡터로 projection 시킨 다음 이를 contrastive learning에서의 atomic한 인풋으로 loss가 계산되었는데요. (앞서 보여드린 SeqCLR의 방법과 이전 방법간의 차이를 생각해보시면 되겠습니다) 텍스트 이미지로부터 인코더를 통해 뽑아낸 피처맵은일부분들은 각각 다른 character를 가리킨다고 봐 기존 방법과 달리 4개의 패치로 분할한 다음 각각을 projection 시켜 여러개의 vector를 만들고 이를 contrative learning의 atomic한 input으로 사용했다고 합니다. 이후 모든 패치에 대한 vector에 대해 projection header와 prediction을 header를 통과시켜 각 패치에 해당하는 쿼리 벡터를 생성합니다.
추가적으로 contrastive learning 브랜치에서와 동일한 구조로 momentum branch도 구성돼 key가 생성됩니다. 인코더에서 나온 쿼리들과 같은 이미지로 부터 생성된 키들간의 유사성을 학습하도록 하는데 이를 생성하는 momentum branch에서 파라미터 업데이트는 contrastive learning branch의 인코더를 따르도록 돼있는데 이때 그대로 적용되지는 않고 이전값을 일부 유지한채 업데이트 된다고 합니다. 배치간의 같은 텍스트이지만 다른 증강이 적용된 경우에도 일관된 키값을 출력하도록 하기 위함이라고 합니다.
그리고 contrastive learning에서 negative loss는 같은 배치 안의 다른 텍스트로 부터 생성된 키들이 되겠습니다.
2.3 Masked Image Modeling
masked image modeling은 SimMIM의 방법을 따릅니다. 4×4크기의 패치로 나뉘어지며 0.6의 확률로 각 패치의 마스킹 여부가 결정됩니다. contrastive learning branch에서의 인코더와 가중치를 공유합니다. prediction head는 SimMIM에서 사용된 linear layer를 그대로 사용합니다. 원본 이미지에서의 픽셀값을 타겟으로 loss가 구해지고 이를 기반으로 학습됩니다. 즉, 원본 이미지와 최대한 같도록 마스킹된 부분의 픽셀값을 예측하도록 학습이 유도됩니다.
2.4 Optimization (Loss Functions)
최종 loss는 contrastive loss (L_c)와 masked image modeling loss (L_m)의 합으로 정의됩니다. L_m에 \alpha라는 스케일링 변수가 곱해집니다. contrastive loss로는 infoLCR loss가 사용됩니다. 식은 다음과 같습니다.
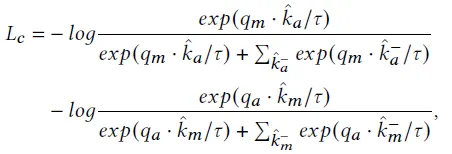
마이너스가 붙은 값들은 negative sample로 생성된 key들로 같은 배치내의 다른 텍스트 인스턴스에 대한 것입니다. \tau는 temperature로
masked image modeling에선 L2 loss를 사용합니다. 식은 다음과 같습니다. N개의 masking 픽셀에 대해 y_i는 원본 이미지에서 픽셀값을 x_i는 모델의 예측을 가리킵니다.
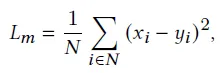
다음은 이를 각 down stream task에 어떻게 적용시켰는지에 대해서 보겠습니다.
2.5 Applying to Downstream tasks
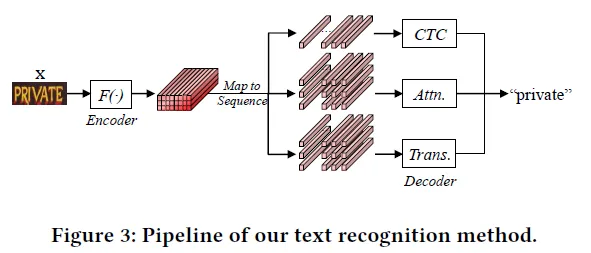
Text recognition은 위 구조로 설계되어 task가 수행됩니다. DiG에서 학습된 ViT를 인코더로 사용합니다. 이후 recognition에 맞게 인코더를 타고 나온 2D feature를 가지고 character sequence를 차례대로 출력할 수 있는 recognition 디코더를 붙입니다. 디코더로는 CTC, Attention decoder, Transformer decoder를 사용할 수 있다고 합니다.
Segmentation 테스크의 경우 DiG의 인코더에 segmentation decoder가 붙는데 3개의 attention layer와 하나의 prediction head가 붙습니다.
Image super-resolution이라고 텍스트 내용은 그대로 유지하면서 저품질의 이미지를 고해상도의 이미지로 재구성하는 task입니다. DiG의 인코더에 super-resolution decoder가 붙습니다. text segmentation의 디코더와 유사합니다. loss는 L2 loss를 사용합니다.
3. EXPERIMENTS
3.1 Self-Supervised Learning

이는 사전학습 시 maked image modeling branch에서 모델이 reconstruct한 정성적인 결과들로 제가 봐도 원본 텍스트를 유추하지 못할 만큼 어지러운 이미지의 마스킹된 부분을 잘 매꿔짐을 확인할 수 있습니다. 위의 정성 결과를 통해 Pre-training 과정 중에 인코더로부터 generative feature에 대한 학습이 잘 이뤄짐을 알 수 있습니다.
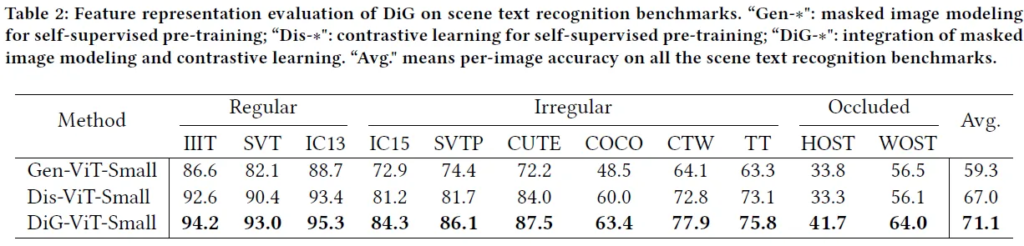
다음 실험은 사전학습을 통해 얼마나 feature representation을 잘 학습했는지를 확인하기 위한 실험으로 인코더를 freeze 시키고 디코더만을 파인튜닝 시킨 후 text recognition task를 수행해 그 결과를 확입합니다. 실험 결과에서 제시된 Gen-ViT-Small, Dis-ViT-Small, DiG-ViT-Small은 각각 contrastive learning, masking image modeling 수행 여부를 달리해 정의한 사전학습 모델로 결과를 보면 정성적인 결과 및 정량적인 결과에서도 두가지 방식을 모두 가지고 사전학습되 DiG-ViT-Small 방법이 제일 정확하고 여러 복잡한 텍스트 이미지들로 구성된 데이터셋에 대해서도 강인한 recognition 결과를 보입니다.
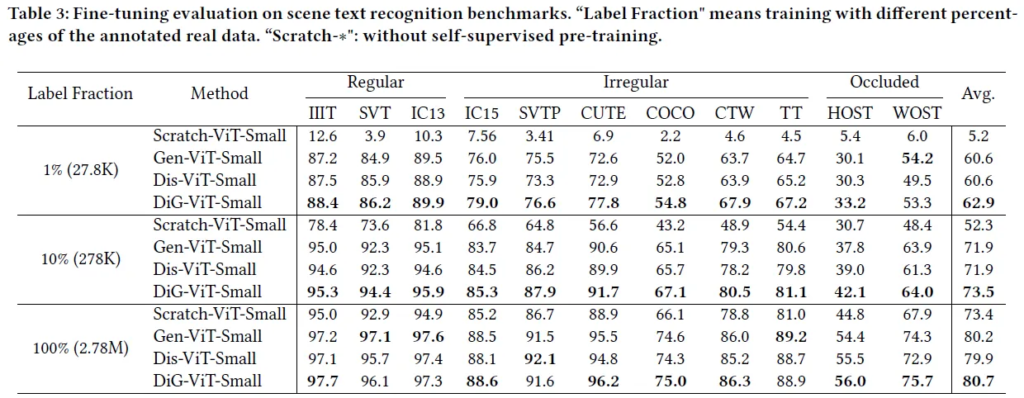
위는 사전학습 여부에 따른 recognition 성능을 확인한 실험의 결과입니다. Scratch-ViT-Small은 사전학습을 하지 않고 라벨링된 데이터에 대해 학습한 모델을 가리킵니다. 결과를 보면 다른 크기의 데이터에 대해서 파인튜닝한 경우 Scratch 보단 self-supervised pre-training이 사전에 진행됐을때의 결과가 좋습니다. Scratch의 경우 파인튜닝되는 데이터의 양이 주는 만큼 큰 폭으로 결과가 하락했지만 pre-train된 경우는 Scratch 대비 하락폭이 낮습니다. 이로써 사전학습과 파인튜닝하는 과정이 필수적임을 확인한 실험이라고 할 수 있겠네요.
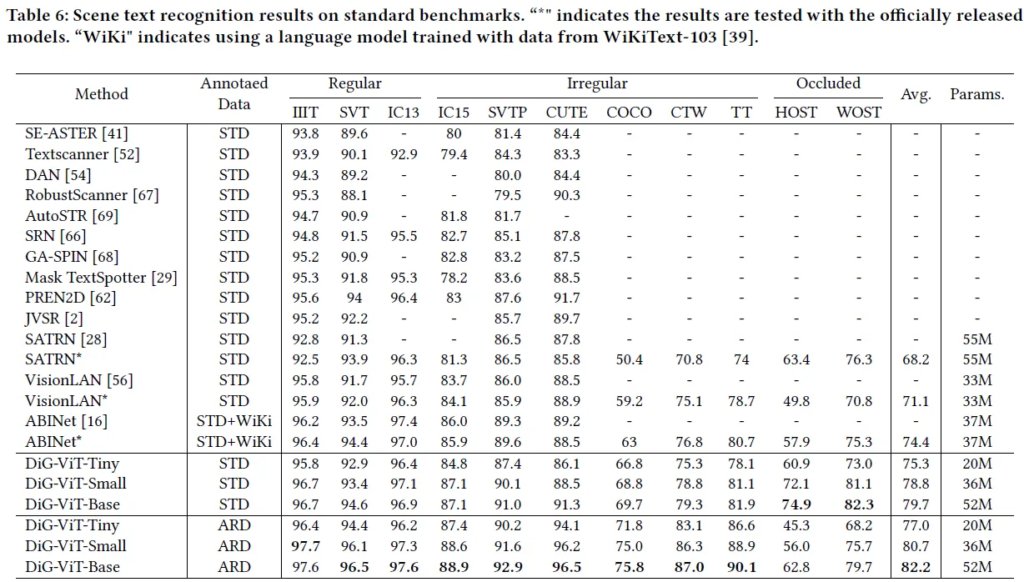
3.2 Text Recognition
아래의 실험 같은 경우 모든 방법들은 모두 같은 합성 데이터에 대해서 pre-training되고 파인튜닝 되었습니다.
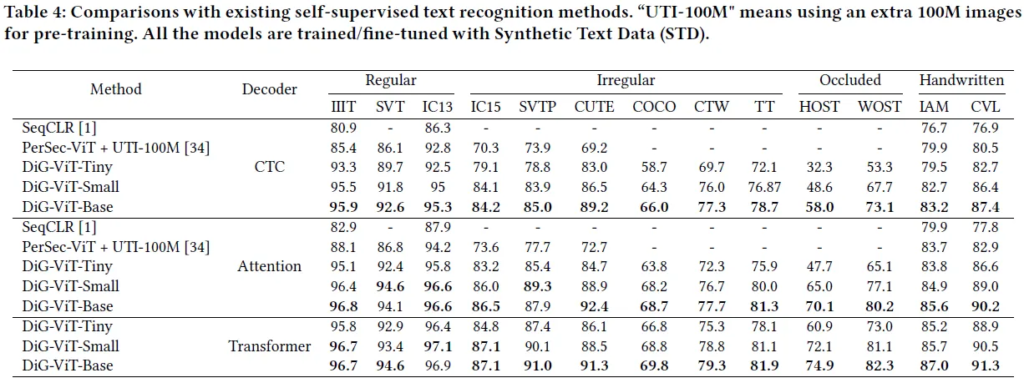
text recognition task를 contrastive learning으로 해결을 시도했던 기존 방법들과의 비교 실험입니다. 디코더를 달리 사용해도 공통적으로 DiG의 방법의 결과가 더 좋습니다. 특히 recognition이 어려운 데이터셋들 (IC15, SVTP, CUTE) 에 대해서 기존 방법들 보다 더 높은 정확도를 갖습니다. 이때 여기서 눈 여겨 볼게 PerSec은 파인튜닝시 100M의 데이터로 학습한 반면 논문에서 제안하는 DiG는 15.77M로 파인튜닝이 된 것으로 적은 양의 annotated data로 파인튜닝 되어도 outperforming하는 결과를 보입니다.
Synthetic Text Data (STD) vs. Annotated Real Data (ARD)
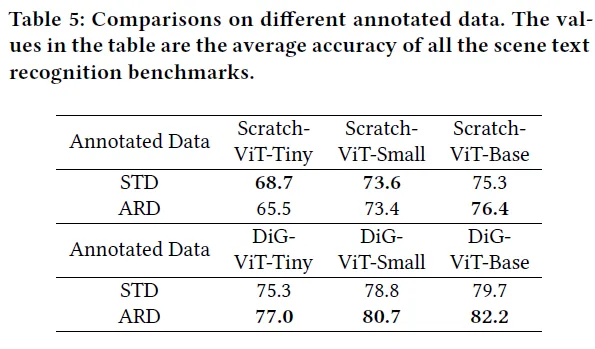
이는 두개의 서로 다른 annotated data에 대한 실험인데 STD는 더 많은 텍스트가 포함된 large scale 데이터셋으로 많은 양의 데이터로 부터 텍스트 자체가 갖는 의미론적인 특징까지 모두 학습할 수 있다는 특징이 있고 ARD는 양은 적지만 STD보다 훨씬 양이 적지만 대신 텍스트의 외형이 다양한 게 특징입니다. 모델의 크기가 작은 경우 ViT-Tiny, ViT-Small등 표현력의 제한으로 저수준의 외형 정보보단 고수준의 semantic 정보가 우선적으로 학습됩니다. 이는 Scratch methods에 대해서 두 데이터셋간의 결과 차이로 인해서도 확인이 되는데요. 비교적 작은 크기의 모델의 경우 STD에서의 결과가 더 높습니다. 이런 반면 DiG는 크기 차이 없이 세개 모두 ARD에서의 결과가 좋습니다. DiG의 supervised learning이 small 모델이 갖던 외형적 정보를 표현한느데의 한계를 극복한 것으로 이해해볼 수 있습니다.
다음은 각 downstream task에서 SoTA들과의 비교로 성능 개선을 시켰는지에 대한 실험들입니다.
3.3 Scene Text Recognition
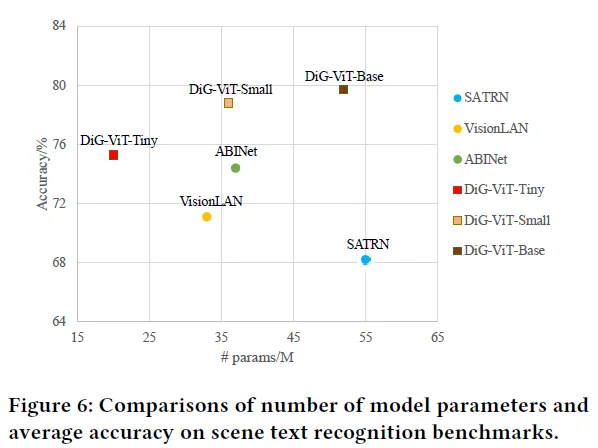
적은 양의 파라미터 즉 모델의 크기를 줄여도 이전의 text recognizer 보다 저 높은 정확도를 가지는 것으로 보아 DiG는 모델 크기와 정확도간의 trade off를 잘 잡은 방법이라고 볼 수 있습니다. 이에 대한 더 정확한 비교는 아래의 Table로 확인할 수 있습니다.
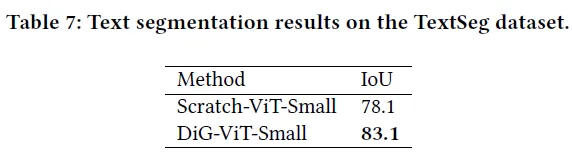
3.4 Text Segmentation
self-supervised pre-training 과정 유무에 따른 segmenation 결과입니다. IoU 값으로 5% 차이가 나는 것을 확인할 수 있습니다.

다음은 segmentation의 정성적인 결과입니다. (Figure 7 (a)) 정성적으로 확인해보아도 DiG의 segmentation 결과가 더 선명하고 정확합니다. 특히 backgroun noise 나 perspective distortion 등에도 강인하게 인식됩니다.
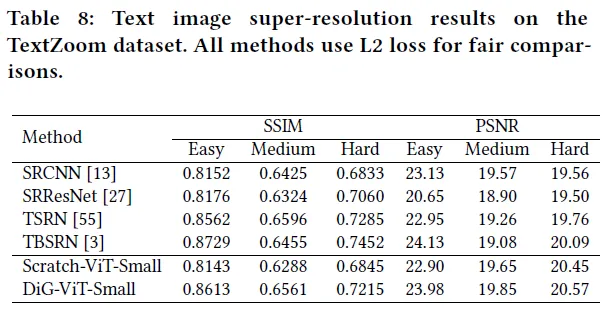
3.5 Text Image Super-Resolution
image super-resolution의 결과입니다. 아래는 정량적인 결과입니다. Scratch 보다 더 좋은 결과를 보입니다. 추가적으로 기존 SoTA 모델들과 비교해보아도 여러 모델 보다 더 좋은 결과를 냅니다.
4. Conclusion
논문에서는 text recognition의 정확한 성능을 내기 위한 self-supervised learning의 방법을 새롭게 제안합니다. 논문에서 제안하는 DiG 모델은 contrastive learning과 masked image modeling을 통합한 self-supervised learning 방법으로 discriminitive representation과 generative representation을 동시에 학습하며 표현력을 강화시킵니다. 본 방법론의 효과를 검증하기 위해 여러 다운스트림 테스크 그리고 여러 벤치마크 데이터셋에 대한 실험을 통해 검증을 했습니다. 검증 결과 동일한 크기로도 더 정확하게 수행됨을 확인하였습니다. 저자는 이후 연구로는 text recognition과 NLP를 결합한 연구를 시도해보겠다고 합니다.
안녕하세요, 류지연 연구원님!
좋은 리뷰 감사합니다.
제가 이해하기로는,,DiG는 contrastive learning 부분에서 MoCo v3의 프레임워크를, masked image modeling 부분에서는 SimMIM의 구조를 따른다고 이해를 했는데. 제가 이 task에 대해서 이해도가 깊지않아서 혹시 그렇다면 각 기법의 핵심 아이디어가 DiG에서 어떻게 적용되었는지 설명 해주실수 있나요? 특히 텍스트 인식이라는 도메인에 맞게 어떤 부분이 동일하게 유지되고, 어떤 부분이 변화되었는지 궁금합니다!!
감사합니다
안녕하세요 우진 연구원님 질문 감사합니다
우선 MoCo는 이미지를 두개의 view로 증강한 다음 각 view에서 얻어지는 쿼리와 키 간의 유사도를 높이도록 하는 방법의 contrastive learning을 사용하는 self-supervised learning 프레임워크입니다. DiG의 contrastive learning branch에 이 부분이 도입이 된다고 보시면 되겠습니다. 거의 그대로 들고 와서 사용을 하는데요 다만 일반 이미지만을 다루고 여러 downstream task를 염두에 둔 MoCo와 달리 텍스트 이미지에 보다 적합하게 증강기법을 달리했다는 점을 들 수 있겠습니다. 텍스트 이미지의 경우 flip이나 crop의 증강 기법은 적절하지 않기에 적용되지 않습니다.
다음으로 SimMIM은 이미지를 패치로 나눈 다음 mask ratio에 따라 랜덤하게 마스킹 한 후 reconstruction head를 두고 pixel level의 값을 예측하면서 보다 텍스트의 의미를 파악할 수 있는 방법입니다. DiG에서는 masked image modeling branch 즉 모델 아키텍쳐 figure를 보시면 인코더를 타고나온 fm에 대해 추가적으로 가지가 뻗어져 있는 부분에 해당됩니다. 이 또한 DiG에서 거의 그대로 가져와 사용합니다.
사실 보다 정확한 차이는 코드 레벨로 DiG와 두 모델 각각 뜯어봐야 조금 더 알 수 있을 것 같습니다. 아직 그 단계까지 해보진 못해서 우진님의 질문에 답변 드리기는 어렵네요.
안녕하세요 좋은리뷰 감사합니다.
리뷰 읽으면서 간단하게 드는 궁금증 질문드리자면
1.momentum branch의 파라미터 업데이트에서 이전값을 일부 유지하는 방식이 뭔지 궁금합니다.
이전값과 업데이트값의 가중합방식인건지? 논문에 있었는지 궁금합니다.
2. real 과 합성데이터의 domain gap이 존재하는 것 같은데, 합성데이터를 만드는 방식의 한계를 연구하려는 시도는 없었는지 궁금합니다.
1. DiG에서 momentum branch의 파라미터를 업데이트하는 방식으로는 EMA(지수이동평균)을 사용합니다. 적어주신 대로 가중합 방식으로 online encoder의 파라미터에 (1-alpha)를 기존 momentum 인코더의 파라미터에는 alpha를 곱해서 더합니다. 논문에서는 alpha를 0.996으로 설정해 최대한 천천히 조금씩 업데이트 시킵니다.
2. 조금 더 서치 후 답변 드리겠습니다.
감사합니다