안녕하세요, 예순 한번째 X-Review입니다. 이번 논문은 2022년도 ECCV에 올라온 DualPrompt: Complementary Prompting for Rehearsal-free Continual Learning논문으로 prompt learning을 continual learning에 적용한 논문입니다. 바로 시작하도록 하겠습니다. ?
1. Introduction
본 논문은 Continual Learning을 다루는 논문으로, 하나의 모델로 여러 sequential한 task를 순차적으로 학습하면서 기존에 학습한 knowledge를 잊어버리는 catastrophic forgetting 문제를 해결하는 것이 목표입니다. 본 task에서 이전까지의 sota 모델들은 주로 rehearsal based 방식이 많이 사용되어 왔습니다. 이런 방식은 이전 task에서 사용된 일부 데이터를 rehearal buffer라는 곳에 저장해 둔 다음, 새로운 task를 학습할 때 이 buffer에 저장된 데이터를 현재 데이터와 함께 모델 학습에 사용하는 방식입니다. 하지만, 이런 방식은 rehearsal buffer를 계속 저장해둬야 한다는 문제로 인해서 메모리 사용량이 증가하게 되고 개인정보 보호 측면에서도 제약이 있을 수 있다는 한계점이 존재합니다.
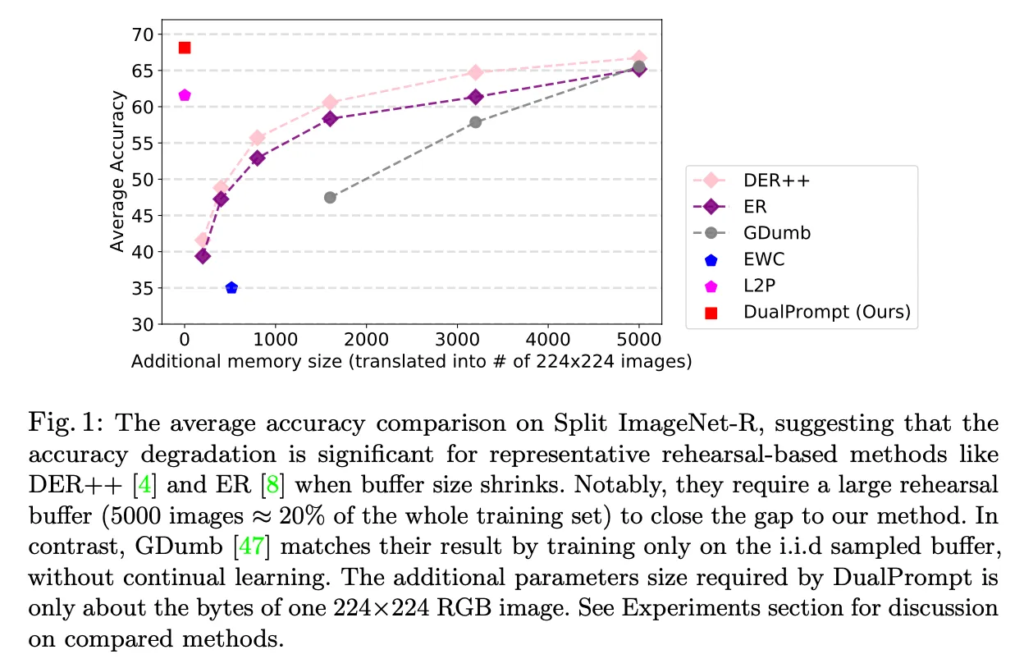
위 Fig1은 기존 모델들의 rehearsal buffer 사이즈에 따른 성능을 나타내는 그래프인데요. 보시면, x축이 buffer 사이즈인데, 이게 커질수록 모델 성능도 같이 올라가는 것을 볼 수 있습니다. 반면 본 논문에서 제안하는 DualPrompt는 기존 rehearsal based 모델들과 달리 리허설 버퍼를 사용하지 않고 prompt를 이용해 sota를 달성했다는 점에서 의의가 있습니다. 이 DualPrompt의 핵심은 task-invariant한, 즉 general한 knowledge를 학습하는 G-Prompt와 각 task마다의 specific한 knowledge를 학습하는 E-Prompt로 개념을 나눠 하용하는 것을 제안한 것입니다.
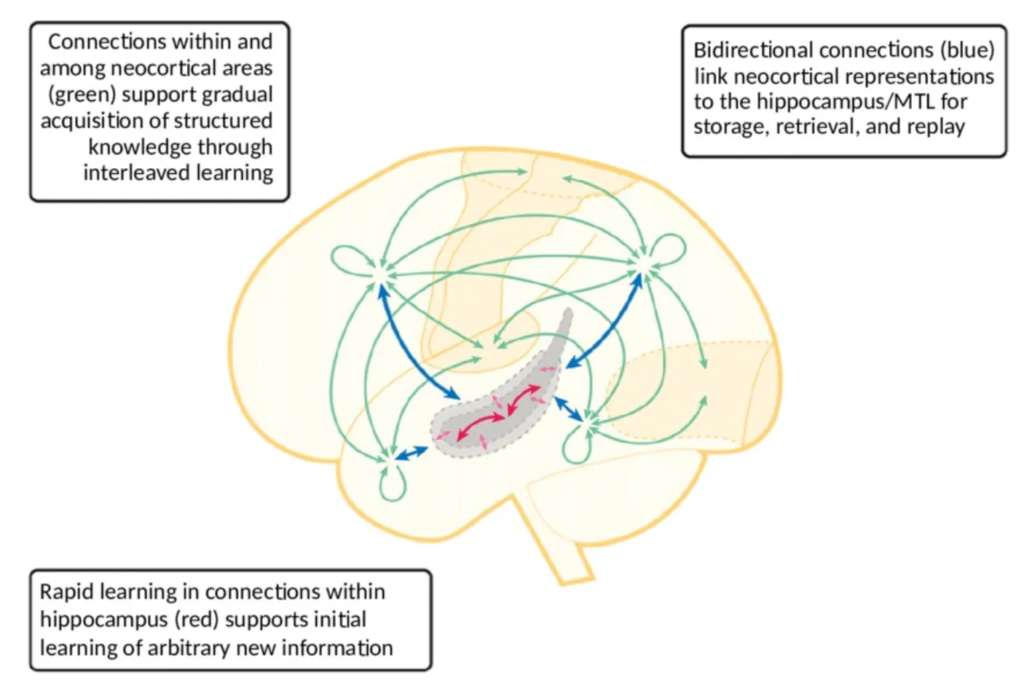
본 논문의 저자가 이렇게 task-invariant한 knowledge를 학습하는 prompt와 task-specific한 knowledge를 학습하도록 나눈 아이디어의 motivation은 위에 보이는 그림이 뇌과학 분야의 complementary Learning System에서 발표한 연구와 관련이 되어 있습니다. 구체적으로, 사람이 이전 지식을 잊지 않고 계속 continual하게 학습을 할 때는 사람의 해마가 실제 specific한 정보를 저장하는 데 도움을 주고, 뇌피실이 좀 더 일밙벅인 지식을 학습하도록 기능이 나눠져 있기 때문이라는 점입니다.
정리하자면, 본 논문은 기존 모델들과 다르게 리허설 버퍼를 사용하지 않고 visual prompt tuning 측면으로 접근한 논문입니다. 전체 백본 전체를 학습하기에는 오버헤드가 크니 prompt제외 나머지는 freeze하도록 하고, 학습 가능한 prompt token만 fine-tuning tuning하도록 해 효과적으로 성능을 높이고 오버헤드도 줄이는 방식을 사용한 것이라고 보면 됩니다. 이 때 prompt 종류를 두 가지 general측면과 specific측면으로 나눠 사용한 것이죠.
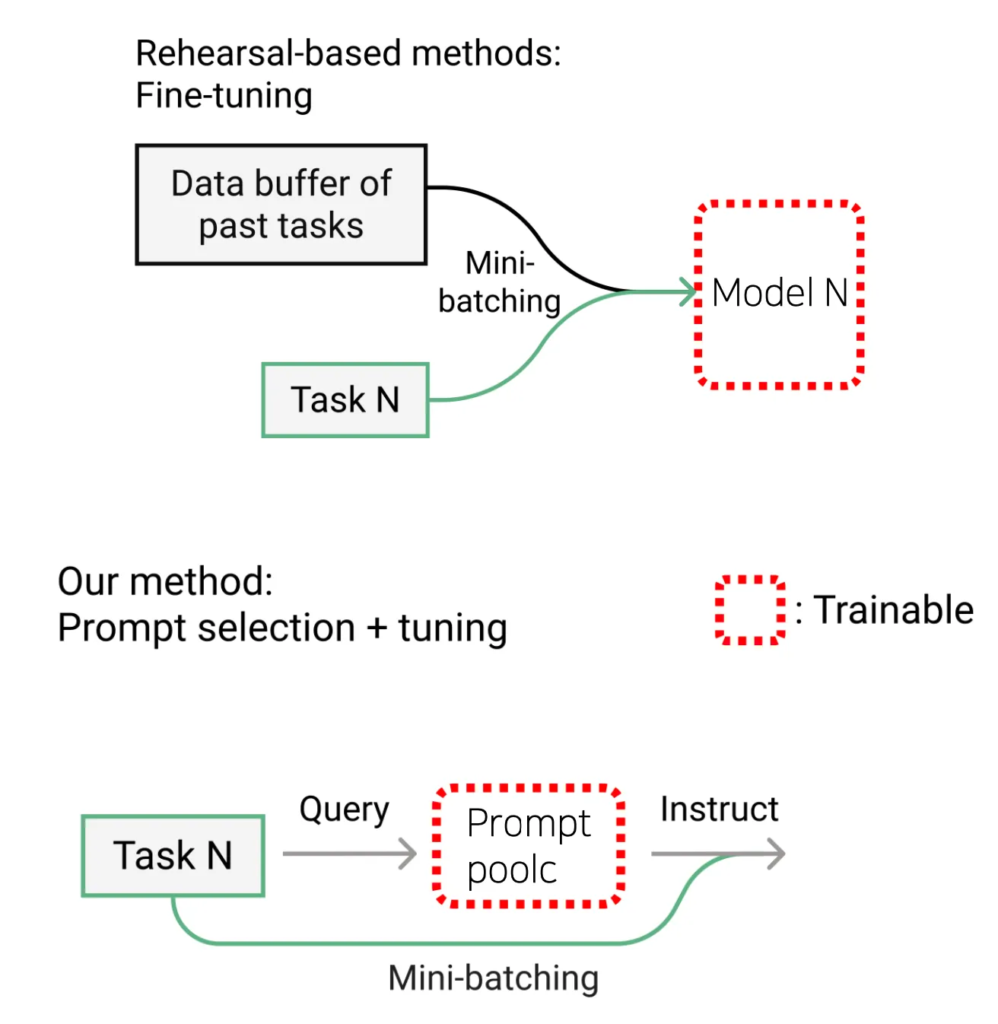
위 그림을 보면 기존 방식과 본 논문 방식의 차이점을 확인할 수 있습니다. 그럼 이제 제안된 DualPrompt에 대해서 method 단에서 자세히 설명드리도록 하겠습니다.
2. Prerequisites
바로 DualPrompt에 대해 설명드리기 전에 continual learning의 problem setting과 베이스로 삼은 모델에 대해 먼저 언급하고 넘어가고자 합니다.
2.1. Continual learning problem setting
Continual learning은 여러 sequential한 task를 학습하는 것이었는데, 앞으로 이 task들의 sequence를 D = {D_1, . . . , D_T}로 표기하고, 각 task D_t = {(x_{i, t}, y_{i, t})}_{i=1}^{n_t}
는 입력 sample x_{i,t} \in X와 이에 대응하는 label y_{i,t} \in Y 쌍으로 구성이 됩니다. 본 논문에서는 학습 중에 task간의 경계가 명확하고 그 task 전환이 갑자기 일어난다는 일반적인 가정을 따르고 있으며, 특히 test시에 task identity가 주어지지 않는 더 어려운 class-incremental learning 세팅을 따르고있습니다.
2.2. Learning to Prompt(L2P)
아까 보여드린 Fig1을 보시면 본 DualPrompt와 동일하게 리허설 버퍼 사이즈가 0인 L2P라는 모델이 존재합니다. 본 DualPrompt는 이 L2P를 베이스 모델로 삼았는데요, 이 L2P는 처음으로 prompt learning을 continual learning에 적용한 논문으로, 본 저자가 이전에 작성한 논문에 해당합니다. 잠깐 L2P에 대해 간략히 살펴보자면,
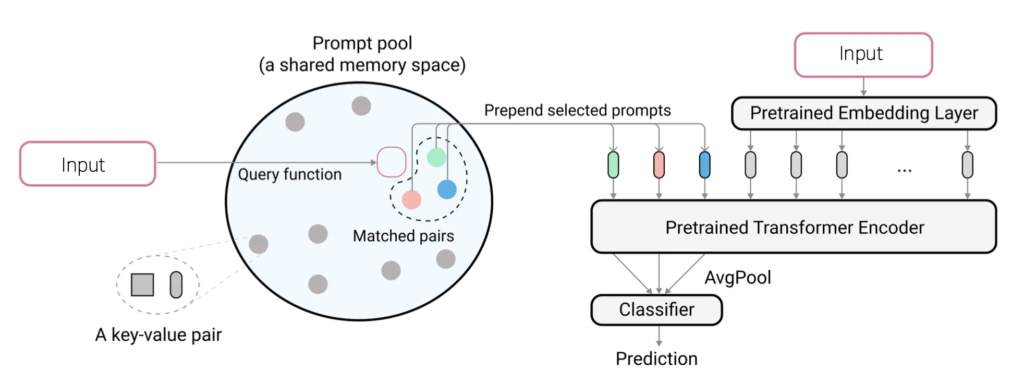
prompt를 사용하기 때문에 모델 전체를 업데이트 하는 것이 아니라 task에서 input으로 들어오는 prompt만 업데이트 되는 방식으로 학습이 됩니다. 그래서 총 M개의 task를 continual하게 learning한다고 한다면 prompt 전체 개수도 M개가 되겠죠. 이 M개의 prompt 중에 각 task에 해당하는 prompt이 학습이 되게 됩니다. 이 때 key라는 parameter도 같이 학습하게 되는데요. 그림에서 prompt pool안에 key value pair라고 되어 있는 것을 볼 수 있습니다.
이 Key는 나중에 inference할 때 어떤 prompt를 쓸 지 선택하기 위해 도입한 것인데요. 구체적으로 그림에 보이는 query function에서 나온 feature와 key간의 cosine similarity를 계산하여 선택하게 됩니다. 여기 query function이라고 하는 것은 imagenet으로 pre-trained된 ViT의 backbone을 사용했고, 이 backbone에서 나온 feature를 사용해 가장 similarity가 높은 prompt를 찾아 이 prompt만 pre-trained transformer 입력으로 들어가는 구조로 되어 있습니다.
3. DualPrompt
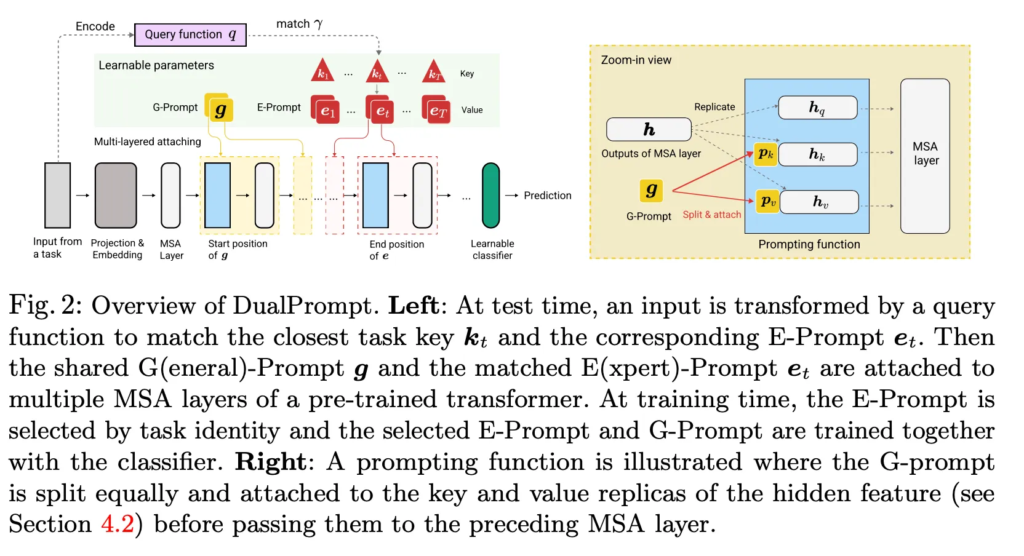
이제 DualPrompt에 대해 살펴보도록 하겠습니다. DualPrompt overview는 위 그림2와 같습니다. 모델은 ViT를 사용하게 되구요, 앞에서 말한 것처럼 DualPrompt는 General prompt인 G-Prompt와 Expert Prompt인 E Prompt로 구성이 되어 있습니다. 그림에서 노란색 g가 general prompt인 G-prompt, 빨간색 네모가 expert prompt인 E-Prompt이며 세모들이 각 e-prompt와 쌍을 갖는 key에 해당합니다.
3.1. Complementary G-Prompt and E-Prompt
G-Prompt
각각에 대해서 말씀 드리면, 먼저 G-Prompt는 모든 task에 공통으로 적용되는 파라미터로 g \in \mathbb{R}^{L_g \times D} shape을 갖는데 여기서 L_g는 sequence의 길이 D는 embedding 차원입니다.
사전 학습된 ViT가 N개의 연속된 MSA(multi-head self-attention) layer를 갖는다고 할 때 각 i번째 MSA layer의 입력 embedding feature를 h^{(i)}로 표기하도록 하겠습니다. i번째 MSA layer에 G-Prompt를 연결한다고 할 때 G-Prompt는 아래와 같은 prompting function을 통해 h^(i)를 변환하게 됩니다.

여기서 f_{prompt}는 prompt를 hidden embedding에 어떻게 결합할지를 정의하는 함수인데, 이에 대해서는 조금 뒤에 설명드리도록 하겠습니다
E-Prompt
다음, E-Prompt는 각 task에 따라 다르게 정의되는 파라미터로 E = {e_t}_{t=1}^{T}로 표현이 되구 각 prompt shape은 다음과 같습니다 e_t \in R^{L_e \times D}. 각 E-Prompt는 G-Prompt와 shape자체는 갖습니다. 다만, G-Prompt와는 다르게 각 E-Prompt는 해당 task를 대표하는 key vector k_t \in R^{D}와 함께 학습이 되고, 이 key가 해당 task의 input feature를 잘 반영되도록 학습됩니다.
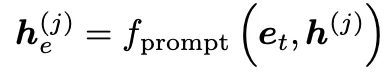
각 task t에 해당하는 E-Prompt e_t를 j번째 MSA layer에 연결할 때는 위와 같이 G-Prompt때와 유사한 방식으로 표현됩니다.
추가적으로, 학습을 할 때 각 k_t는 입력 sample과의 유사도를 높이는 방향으로 matching loss를 사용해 학습되게 됩니다.
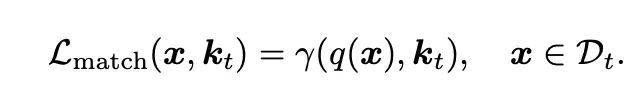
이 matching loss는 위와 같은데요. 식에서 q(x)는 query function으로 pre-trained된 모델의 [class] token embedidng에 해당하구요. \gamma는 cosine similarity를 의미합니다. Inference 시에는 입력 x에 대해서 가장 유사도가 높은 task key를 뽑아내게 되고 그에 해당하는 E-Prompt를 사용하게 됩니다.
3.2. Prompt attaching: where and how?
대부분 기존 연구들은 prompt를 첫 번째 MSA에만 붙이거나, 혹은 모든 MSA layer에 동일하게 붙이는 경우가 많았습니다. 하지만, 본 논문에서는 prompt의 종류에 따라서 어디에, 어떻게 붙이는지가 continual learning 성능에 중요하다는 점을 강조하고 있고, 이에 대해서 여러 실험을 수행했습니다.
Where: Decoupled prompt positions
먼저 어디에 붙여야 하는지에 대해서는, 직관적으로 transformer 백본의 서로 다른 layer가 모두 다른 feature level을 갖고 있을 것이구요. Task간의 공통적인 정보는 shallow한 layer에서, task specific한 정보는 좀 더 deep한 layer에서 잘 표현될 수 있을 것입니다. 이런 점을 바탕으로 G-Prompt와 E-Prompt를 서로 독립적인 위치에 붙일 수 있도록 서례를 했으며 각각의 최적 position을 실험을 통해 찾고자 했습니다. 이에 대해서는 실험 부분에서 마저 살펴보도록 하겠습니다.
How: Configurable prompting function
다음으로는 어떻게 prompt와 embedding feature를 결합할지에 대한 how 부분입니다. 이 부분에서는 기존 NLP 분야에서 자주 사용되던 두 방식 Prompt Tuning(Pro-T)와 Prefix Tuning(Pre-T)를 사용하였습니다.
각각에 대해 간략 설명드리자면 아래 식과 같이 prompt tuning은 transformer의 query key value에 해당하는 모든 부분에 prompt가 concat되어 붙어져 들어가는 구조이구요. Prefix-Tuning은 key와 value에만 반영이 돼서 hidden representation과 함께 학습되는 방법입니다.
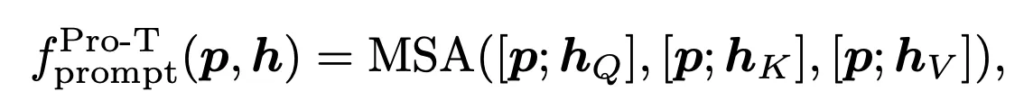
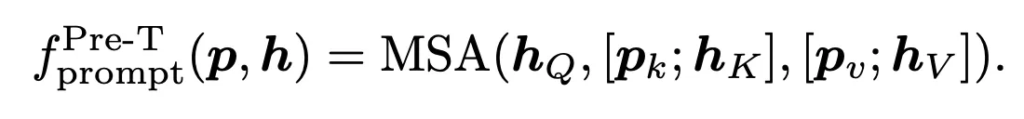
3.3. Overall objective for DualPrompt
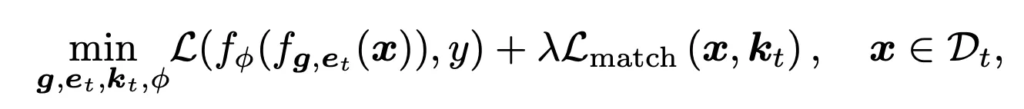
전체적인 object function은 다음과 같은데, 기존 cross entropy loss로 classifier head와 prompt를 업데이트 하는 구조이고, 추가적으로 앞서 언급했던 key matching loss로 query로 들어간 값과, 각각의 task마다 e-prompt가 pair로 구성되어 있다고 했었는데, 해당 task의 key와 값이 가까워지도록 가까워지도록 matching loss를 구성해 사용하고 있습니다.
4. Experiments
실험 부분 살펴보도록 하겠습니다. 평가 지표로는 average accuracy와 forgetting 이 두 가지 metric을 사용하는데, average accuracy는 지금까지 learning했던 것들의 평균 accuracy를 의미하구요. Forgetting은 catastrophic forgetting이 얼마나 이뤄졌나여서 낮을수록 좋은 지표이고 average accuracy는 높을수록 좋은 지표입니다.
4.1. Evaluation benchmarks
다음으로는 벤치마크 설명인데요. 벤치마크는 split ImageNet-R과 Split cifar 100을 사용했는데, 여기서 split imagenet-R은 image-R이 원래 200가지 class가 있는데 이를 10가지 task로 랜덤하게 나누기 위해 각 task가 20가지 class를 갖는 10가지 task로 나눠진 형태로 구성되어 있습니다. Training 으로 24,000 test로 6,000장으로 구성되어 있구요.

위 그림이 ImageNet-R 예시인데, 이 ImageNet-R은 그냥 ImageNet과는 다르게 같은 class여도 굉장히 다양한 스타일을 갖고 있습니다. 맨 윗 행에 사자 class에 대한 사람들을 봐도 실제 사자 그림이나 카툰 형태 등등의 다양한 스타일 그림을 볼 수 있습니다. 그래서 기존 standard model 예를 들어 resnet이나 어떤 cnn 기반 모델로는 학습하기 어려운 데이터셋이라고 보시면 됩니다. 그래서 좀 더 continual learning할 때 buffer를 이용하게 되면 이 이전 task의 buffer를 저장했더라도 syle이 다르기 때문에 리허설 버퍼를 사용하기 좀 까다로운 데이터셋이라고 보시면 되겠습니다. 그리고 또 split CIFAR-100을 사용했는데 기존 cifar100을 10개의 task로 나눈 데이터셋입니다.
4.2. Comparison with state-of-the-arts
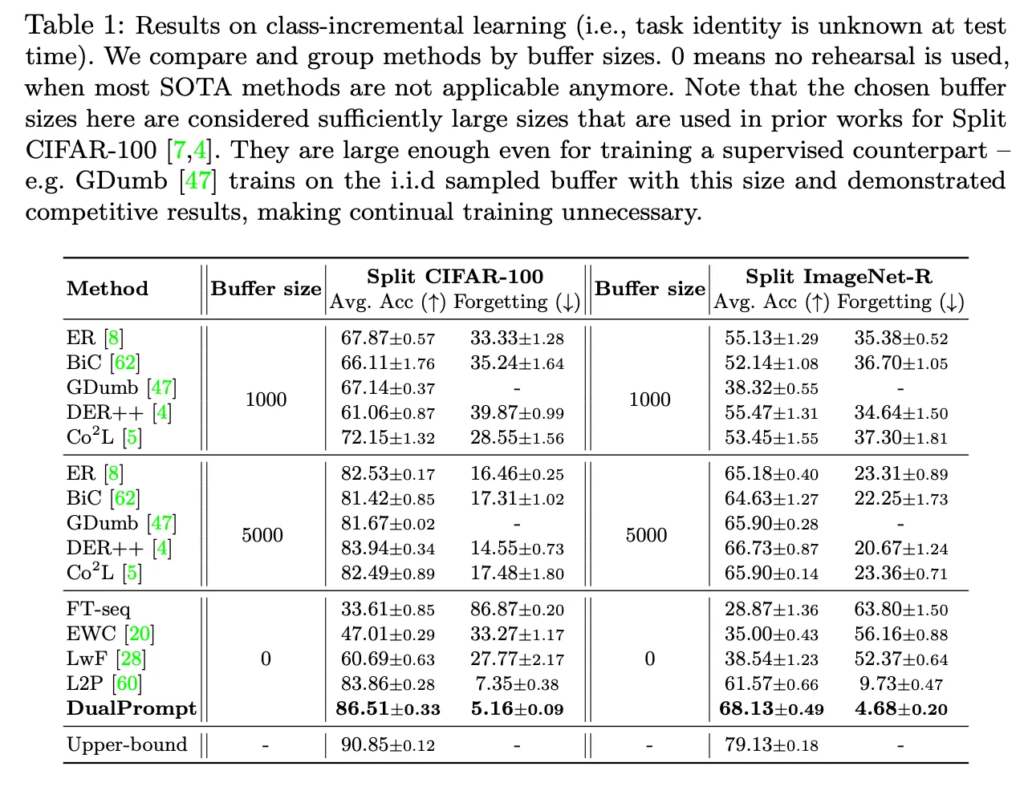
기존 sota와 비교한 결과는 다음과 같습니다. 이 표는 기존 리허설 based 방법론도 같이 비교를 한 table인데, 보시면 buffer size가 1000일때보다 5000일때, 즉 클수록 성능이 높은 것을 확인할 수 있구요. Buffer size가 0인 부분 중에서 Prompt를 사용하는 방법론으로는 L2P와 dualprompt가 있는데 dualprompt 성능이 리허설 버퍼를 사용하지 않았음에도 성능이 잘 나온 것을 볼 수 있고, 기존 L2P보다 높은 정확도, 낮은 forgetting을 보이고 있습니다. 여기 리허설을 사용하지 않는 다른 방법론들은 Ft-seq나 EWC, LwF 방법론들은 regularization 방법인데, 이건 비교적 성능이 많이 낮은 것을 볼 수 있습니다.
4.3. Exploration of where and how to attach prompts
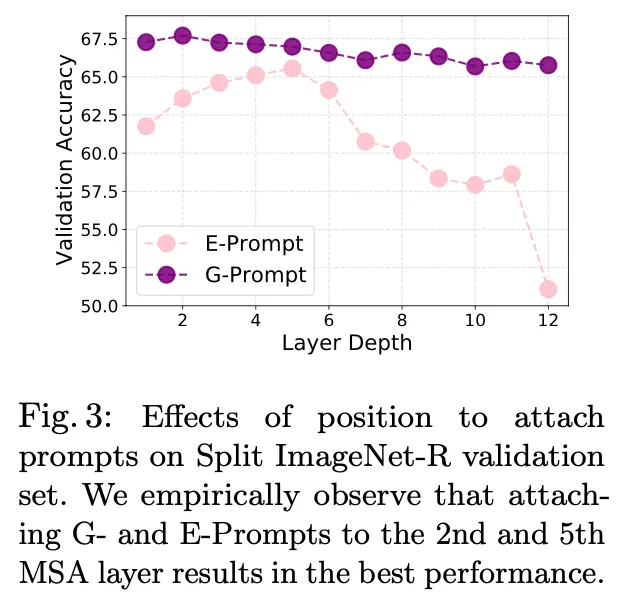
다음으로 prompt를 어디에 붙이면 좋을지. 총 viT layer 12개 중 어디에 붙이면 좋을지에 대한 실험입니다. 위 그림은 각 prompt를 한개의 layer에만 붙였을 때의 acc 그래프인데, G-Prompt는 두번째 layer가 가장 좋았고, E-Prompt는 다섯 번째 layer가 가장 성능이 높은 것을 볼 수 있습니다.
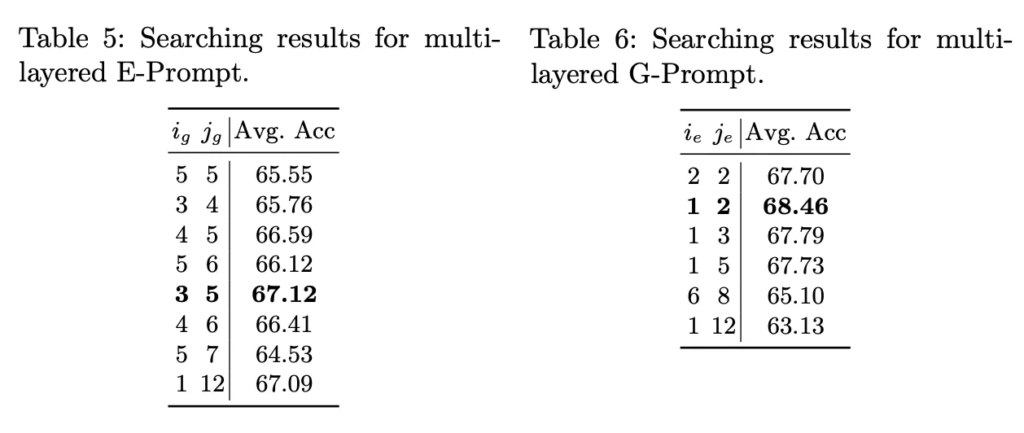
그리고 이건 여러 layer에 prompt를 붙였을 때인데, E-prompt는 3번째부터 5번째 3, 4, 5 layer에 붙였을 때. 그리고 G-Prompt는 첫번째 두번째에 붙였을 때 가장 좋았습니다. 이건 기존 딥러닝 모델도 layer가 깊어질수록 세부적인 feature를 capture하는데 그런 것과 일맥상통한 결과라고 볼 수 있겠는데요. Task-specific한 prompt가 비교적 뒤에 붙였을 때 좋았고, general prompt는 앞쪽에 붙이면 좋았다는 결과로 정리할 수 있습니다.
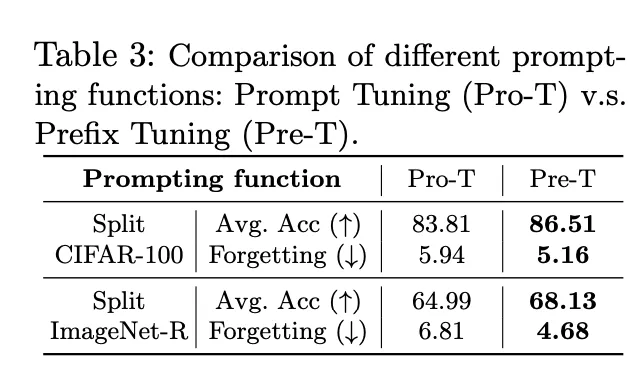
이건 앞선 method에서 설명드린 두 prompting 방식인 prompt tuning과 prefix tuning에 관한 실험입니다. 보시면 pro-T보다는 Pre-T 방식을 사용했을 때 성능이 좀 더 높은 것을 확인할 수 있기에, 벤치마킹 실험이나 다른 실험들은 기본적으로 Pre-T 방식을 사용하여 수행되었습니다.
4.4. Ablation Study
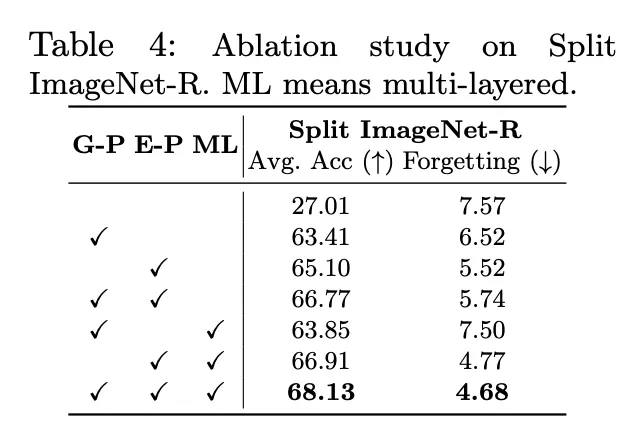
다음은 ablation study로 G-Prompt와 E-Prompt사용 여부 여러 layer에 붙였을 때 여부입니다. 이 ML이 없는 경우는 앞서 하나만 붙였을때의 결과고, ML을 붙였을 때는 multi layer에 prompt를 붙였을때의 결과입니다. 가장 좋았을 때는 G-Prompt, E-Prompt를 쓰고 이걸 multi-layer에 붙였을 때 가장 높은 acc, 가장 낮은 forgetting 수치를 보이고 있습니다.

이건 G-Prompt와 E-Prompt를 t-SNE를 통해 visualization한 결과입니다. 보시면 G-Prompt는 한 곳에 뭉쳐있는 것을 볼 수 있고, E-Prompt는 task-specific하게 각각 따로 따로 뭉쳐있는 결과를 확인할 수 있습니다. 따라서 본 논문이 주장하는 대로, G-Prompt는 좀 더 general한 knowledge가 잘 학습이 됐고, E-Prompt는 좀 task-specific한 knowledge가 잘 학습됐다는 것을 확인할 수 있습니다.

위 Table8은 DualPrompt의 query 기반으로 e-prompt를 선택하는 방식을 사용한 것과 100% perfect하게 매칭하도록 하여 이에 대한 acc, forgetting을 비교한 실험입니다. 보시면 사실 query 기반으로 E-Prompt를 선택하는 경우 matching 정확도는 55.8 정도밖에 안되는데요. 그럼에도, 전체 평균 정확도는 68.13%로 100% 매칭된 경우와 약 3~4% 정도 차이밖에 보이지 않습니다. 이에 대해서 저자들은 E-Prompt가 좀 noisy한 경우에도 G-Prompt의 task-invariant한 guidance가 어느정도 상쇄해준다고 하며, cosine similarity 기반의 query matching이 매칭 정확도가 높지는 않지만, task간의 유사도를 어느 정도 반영하기 때문에 완전 엉뚱한 task를 선택하는 경우는 적다는 가정을 두고 있습니다.
리뷰 감사합니다. 몇 가지 질문 적어두고 가겠습니다.
첫번째로, G-Prompt와 E-Prompt를 서로 다른 layer에 배치하고, 각각 general / task-specific 정보를 분리하여 학습하는 방식이 제법 흥미로웠던 것 같습니다. 혹시 이 구조가 다른 백본(Swin, ConvNeXt 등등)에서도 유사한 성능 향상을 보였는지, 혹은 ViT에 특화된 구조인지 궁금합니다. 이 구조가 일반적인 continual learning 전략으로 확장될 수 있는지도 궁금하네요.
두번째로, Inference 시 E-Prompt를 선택하기 위해 key vector와 query 간 cosine similarity를 사용하셨는데, 입력 샘플이 애매하거나 여러 task와 유사한 경우 key 선택이 불안정할 가능성도 있을 것 같습니다. 논문에서 이런 ambiguous case에 대한 대응을 고려한 경우는 없었나요?
안녕하세요. 댓글 감사합니다.
1. 본 논문은 pre-trained ViT를 백본으로 사용하고 있는,, ViT 특화된 구조입니다. 논문에서는 애초에 ViT 타켓으로 하고 prompting 방식을 설계한 것으로 보이고, 그 외에 다른 백본에 대한 실험은 포함되어 있지 않습니다. swin transformer처럼 transformer based 백본에는 적용할 수 있어보이는데 (prompt 넣는 위치는 바뀔수 있겠지만), cnn기반인 ConvNeXt같은 백본은 그대로 적용하기 어려울 것으로 보입니다. 꼭 prompting을 고집하지 않고 task-invariant/task-specific이라는 컨셉을 가져간다면 다른 cnn 계열 네트워크에도 적용가능할 것으로 보입니다.
2. 본 DualPrompt에는 ambiguous case에 대해서는 따로 고려하지는 않고 있습니다. 하지만 이에 대해 간접적으로 실험한 부분이 있는데요. 리뷰 실험파트 마지막 부분에 관련 내용을 업데이트 해놓도록 하겠습니다.
위 Table8은 DualPrompt의 query 기반으로 e-prompt를 선택하는 방식을 사용한 것과 100% perfect하게 매칭하도록 하여 이에 대한 acc, forgetting을 비교한 실험입니다. 보시면 사실 query 기반으로 E-Prompt를 선택하는 경우 matching 정확도는 55.8 정도밖에 안되는데요. 그럼에도, 전체 평균 정확도는 68.13%로 100% 매칭된 경우와 약 3~4% 정도 차이밖에 보이지 않습니다. 이에 대해서 저자들은 E-Prompt가 좀 noisy한 경우에도 G-Prompt의 task-invariant한 guidance가 어느정도 상쇄해준다고 하며, cosine similarity 기반의 query matching이 매칭 정확도가 높지는 않지만, task간의 유사도를 어느 정도 반영하기 때문에 완전 엉뚱한 task를 선택하는 경우는 적다는 가정을 두고 있습니다. future work로써 언급하고 있는 부분이기도 하구요.
안녕하세요, 좋은 리뷰 감사합니다.
실험에서 어떤 task를 먼저 학습하는지에 대한 학습 순서 여부는 매번 랜덤으로 설정되는 것인지, 혹은 데이터셋마다 정해진 순서가 있는지 궁금합니다. 또 실험 테이블에서 upper-bound라고 적혀 있는 부분은 각 테스크에 대해서 연속적으로 학습하지 않고 독립적으로 학습한 후의 평균 성능을 의미하는 것인가요? 모든 학습을 다 마치고 평가를 수행하는 것인지 혹은 한 task 끝날 때마다 그 task와 이전 task 합쳐서 평가를 수행하는 것인지 궁금합니다.
감사합니다.
안녕하세요. 댓글 감사합니다.
1. 논문에서 학습 순서에 대한 언급은 없지만, split CIFAR-100은 10 class씩 나눈거고, Split ImageNet-R도 200개 클래스를 무작위로 10개 task로 분할했다고 하는 것으로 보아 class가 미리 task단위로 나눠놓고 이 순서를 고정해 실험한 것으로 보입니다.
2. 실험 테이블에 있는 upper-bound는 모든 task 데이터를 한 번에 사용하여 학습한 경우의 성능을 의미합니다. 즉, task 순서도 없고 continual learning도 아닌, 말 그대로 dataset 전체를 가지고 학습하는 일반적인 supervised learning이라고 보면 됩니다.
3. 평가는 마지막 task 학습 이후에 전체 100개 task에 대해 평가합니다.