
안녕하세요, 허재연입니다. 오늘도 Open-Vocabualry Scene Graph Generation(OV-SGG) 논문을 들고 왔습니다. 기존 OV-SGG 방법론들이 scene-agnostic하게 text classifier를 적용시킨 방식에 대해 문제를 제기하고, LLM을 적극적으로 활용하여 주어진 영상의 시각적 맥락에 따라 classifier가 동작할 수 있도록 한 SDSGG(scene-specific description based OVSGG)라는 프레임워크를 제안합니다. 살펴보겠습니다.
Introduction
Scene Graph Generation(SGG)은 고차원적인 이미지 및 장면 이해를 목표로 합니다. 주어진 이미지 안의 다양한 물체들을 검출하고 이들이 어떤 특성을 갖고 있는지, 또 이들 간의 관계가 어떤지를 보다 정교하게 파악하는것이 목적입니다. 일반적으로 각 물체들을 node/vertex로, 그리고 이 물체들 간의 관계(relation/predicate)을 edge로 하는 scene graph를 잘 구축하고자 합니다(구현에 따라 predicate도 node로 처리하기도 합니다). 물체들의 모든 속성/카테고리/관계를 정밀하게 검출하여 복잡한 graph형태로 만드는것은 아직 쉽지 않기에, 보통 <subject-predicate-object>를 잘 만들어내고자 합니다.
2017년 fei-fei Li 교수 연구팀(스탠포드 비전랩인데, ImageNet을 구축한것으로 유명하죠)이 현대 딥러닝 SGG의 시초가 될 수 있는 방법론을 제안한 이후, 다양한 방법으로 SGG이 수행되었습니다. 대표적으로는 1) 이미지 내 모든 객체를 우선 검출하고 이들 object pair 간의 관계를 인식하는 2-stage 방법론, 2) SGG / image understanding 데이터셋에서 자주 나타나는 서술어(predicate)의 long-tail distribution에 집중한 debiased SGG, 3) 이미지 인스턴스 수준(image-level)의 supervision으로부터 scene graph를 생성하고자 하는 weakly-supervised SGG, 4) handcrafted 요소들을 없애고 SGG 전체 과정을 end-to-end framework로 수행하는 one-stage SGG, 5) 학습 시점에 등장하지 않는 다양한 unseen object / relation class를 인식하는 것을 목표로 하는 Open-Vocabulary SGG(OV-SGG)로 정리할 수 있겠네요. 본 논문은 OV-SGG에 속합니다.
OVSGG는 최근 VLM 및 prompt learning의 등장에 힘입어 상당히 많이 발전되었습니다. 기존 OV-SGG방법론들은 다른 task에서 VLM을 활용해 OV를 활용하는 방법과 비슷하게 쿼리 이미지에서 얻은 visual embedding과 사전 정의된 text classifier에서 얻은 text embedding 간 유사도를 계산해서 비교하는 일반적인 zero-shot 방식으로 수행됩니다. 이 방법론들에서는 나이브하게 text classifier로 단순히 category name(예 : “riding”)을 사용하고 이후 prompt learning으로 vision-language alignment를 수행해서 기본적인 패턴을 학습합니다. 하지만 이런 방식으로 학습하면 language가 제공할 수 있는 추가적인 풍부한 문맥적 정보를 활용하지 못한다는 문제가 제기되었습니다. 이를 해결하기 위해 RECODE라는 방법론을 제안한 2023년 논문에서는 relation detection을 여러 구성 요소로 분해해서 object의 시각적 특징이 보다 세분화된 part-level description(description은 prompt라고 생각하시면 됩니다)과 얼마나 잘 매칭되는지를 비교해서 유사도를 계산하는 방법론을 제안했다고 합니다. 아래 Figure 1(b)에서 볼 수 있듯, “riding”이라는 relation의 object는 4개의 다리나 안장을 가져야 하는 것과 같은 느낌으로 받아들이시면 될 것 같습니다. Figure 1(a)에는 일반적으로 CLIP과 같은 VLM을 활용한 zero-shot 예측 수행 방법을, (c)에는 저자들이 제안하는 방법론을 나타냈네요.
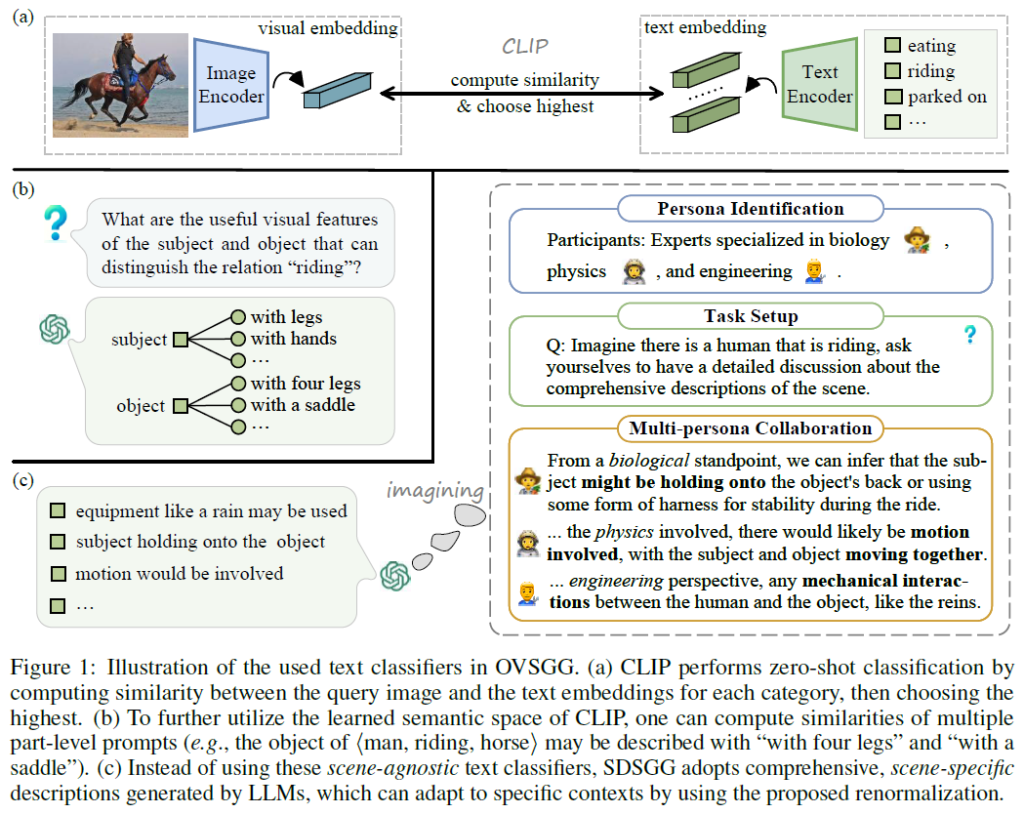
하지만 DECODE와 같은 방법론이 제안됐음에도 저자들은 아직 현재 수준의 OV-SGG 프레임워크 시스템이 사용하는 text classifier의 표현력 범위에 대한 심층적인 검토가 부족하며, 이에 따라 성능이 제한된다고 주장합니다. 보다 구체적으로 scene-agnostic한 text classifier에 의존하는 OV-SGG방법의 문제를 다음과 같이 정리하였습니다.
첫째, 범주명(category name) 기반 방법론들은 매우 다양한 visual relationship을 모델링하는데 어려움을 겪는다고 합니다. 객체를 인식하는 데에는 단순히 범주명을 text classifier로 사용하는 방법은 꽤 잘 동작합니다. 어떤 특정 클래스(ex : 자전거)가 있을때, CLIP은 다양한 자전거 사진에서 공통적인 시각적 특징을 학습하여 서로 다른 외형을 가진 자전거들을 잘 인식할 수 있겠죠. 하지만 relation detection에 똑같이 단순 범주명을 활용하는 상황을 생각해보면 문제가 보다 복잡해집니다. 예를 들어 “on”이라는 relation을 정의하는 시각적 특징이 각 scene마다 극도로 달라질 수 있기 때문입니다(ex : “dog on bed”, “people on road” …). 이런 문제를 해결하기 위해 RECODE는 relation detection을 주어와 목적어 모두의 part-level description을 인식하도록 하였다고 합니다. 하지만 이 방식은 주어와 목적어의 유사도를 각각 따로 계산하기 때문에 이 둘 사이 상호작용(interplay)를 모델링하지는 못하였다고 하네요.
둘째, part-level prompt 기반 방법론들은 모든 description들을 affirmative(단정적인)한 분류기로 균일하게 처리하기에 어떤 텍스트가 특정 문맥과 무관하거나 심지어 반대될 수 있는 가능성을 간과한다고 합니다. 예를 들어 LLM에서 주어 human, 목적어 horse인 상황에서 “riding”이라는 관계 술어를 구분하기 위해 이들의 시각적 특징을 쿼리하면 LLM은 주체와 객체 각각에 대해 기대되는 외형을 part-level description을 제공합니다. 이렇게 생성된 모든 description은 설령 이미지와 관련 없는 것이라도 모두 확정적으로 text classifier로 사용된다고 합니다. 그러나 이러한 description은 LLM이 특정 문맥을 고려하지 않고 생성되기에 잘못 생성될 수 있으며, 경우에 따라서는 이미지의 내용과 전혀 무관한 내용이 포함될 수 있습니다. 예를 들어 LLM은 보통 “riding”이라는 술어를 “네 다리를 가진 동물”과 관련시키려고 하는데 동물의 다리가 이미지에 보이지 않거나 동물이 두 다리만 가지고 있는 경우에는 이런 description이 적절하지 않다고 합니다.
저자들은 이런 한계를 해결하기 위해서는 고정적이고 scene-agnostic한 (category, part-level) text classifier를 사용하는 것에서 벗어나 유연하고 scene-specific한 text classifier로의 근본적인 패러다임 전환이 필요하다고 주장합니다. 이러한 관점에서 저자들은 LLM이 생성한 text classifier(prompt)를 활용하고, 이를 renormalization 기법과 결합해 하나의 장면을 다양한 관점에서 이해할 수 있도록 한 SDSSG(scene-specific description based OVSGG) 프레임워크를 제안합니다.
텍스트 측면에서는, 특정 장면이 주어졌을 때 LLM이 생물, 물리, 공학 등의 분야에 전문성을 가진 전문가의 역할을 부여 받아 장면의 특징을 분석하게 하였습니다(Figure 1(c)참조). 이런 multi-persona 방식을 통해 LLM이 반복적으로 동일한 content를 생성하는 경향을 보완해 보다 다양한 scene description을 생성하도록 하였습니다. 하지만 이렇게 description을 생성했더라도 모든 description이 해당 이미지의 내용과 관련이 있는 것은 아니기에(description에서 언급한 객체의 일부분이 실제로는 이미지에서 드러나지 않는다거나), 이를 보완하고자 해당 description과 반대되는 description을 함께 사용하는 renormalization 방법을 사용합니다. 이는 본래 scene description과 이와 반대외는 description의 각 vision-language 유사도를 계산해서 수행하게 되는데, 이 두 유사도 값의 차를 일종의 self-normalized similarity로 생각하고 이를 통해 해당 description이 장면에 미치는 영향력을 조절하게 됩니다. 이미지와 관련 없는 description의 경우에는 원래 설명과 반대 설명의 유사도가 비슷해지니까 그 차이가 0에 가까워지고, 이렇게 수치화를 해서 해당 description이 얼마나 주어진 이미지의 내용을 잘 담고 있는지 판단하는 것이죠. 이 방법으로 생성된 scene-level description은 보다 유연하고 장면에 특화된 설명(SSDs: Scene-Specific Descriptions)으로 변환됩니다.
시각적 측면에서는, relation detection을 위해 mutual visual adapter라는, 가벼운 learnable module 몇 개로 구성된 새로운 adapter를 제안합니다. 이 adapter로 CLIP의 semantic embeddings를 다른 interaction-aware space로 투영해서 cross-attention을 통해 주어와 목적어 간 복잡한 상호작용을 모델링합니다.
제안하는 SDSGG는 다음과 같은 능력을 갖추게 된다고 합니다 :
- 각 SSD(scene-specific descriptions)의 self-normalized similarity를 평가해 주어진 문맥에 유연하게 적용할 수 있고,
- 하나의 분류기만 사용하는 기존 OVSGG모델들에서 발생하는 overfitting을 완화하였으며,
- SSD를 사용해서 자연스럽게 새로운 relation을 생성할 수 있게 되었다.
일반적으로 사용되는 벤치마크(Visual Genome, GQA)에서 제안하는 방법론의 성능을 겁증한 결과, SDSGG가 큰 폭으로 기존의 OVSGG보다 좋은 결과를 보여주었다고 합니다.
Method
SGG에는 <subject-predicate-object> triplet을 잘 만드는것을 목적으로 하기도 하고, s,o가 주어졌을 때 relation을 잘 분류하는것에 집중하기도 합니다. 본 논문의 경우 object detection에서 오는 노이즈를 제거하기 위해 relation을 예측하는 것(predicate classification) 에 집중하였다고 합니다. <s-p-o> triplet 전체를 잘 만드는게 이상적인 세팅이긴 한데, 기존 연구들의 흐름을 참고한 것도 있고, 이들과의 fair comparison을 위한 것으로 보이기도 하네요. 방법론 자체도 s,o를 잘 탐지하는것보다는 predicate을 더 잘 만드는것에 있습니다. 일반적인 OV 세팅이 그러하듯, base class의 predicate에서 학습 한 뒤, 학습 과정에서 본 적없는 novel class predicate을 잘 예측하고자 합니다. 분류의 경우 각 visual embedding v와 text ebedding t 사이 유사도를 계산해서 가장 유사도가 높은 카테고리를 최종 classification 결과로 출력합니다(Figure 2a). 각 subject-object pari에 대해 입력 이미지에서 crop한 패치들을 visual encoder에 입력해 visual embedding v를 얻습니다. text embedding의 경우는 기존 OVSGG에서 일반적으로 1. 각 카테고리를 단일 텍스트 분류기(category name 하나)로 구성하거나, 2. 각 카테고리를 여러 개의 텍스트 분류기(subject/object에 대한 part-level의 description들)로 구성하였는데 SDSGG에서는 이 텍스트 분류기들을 scene-specific description으로 만들어 사용합니다. 자세한 내용은 뒤에서 다시 설명드리겠습니다.
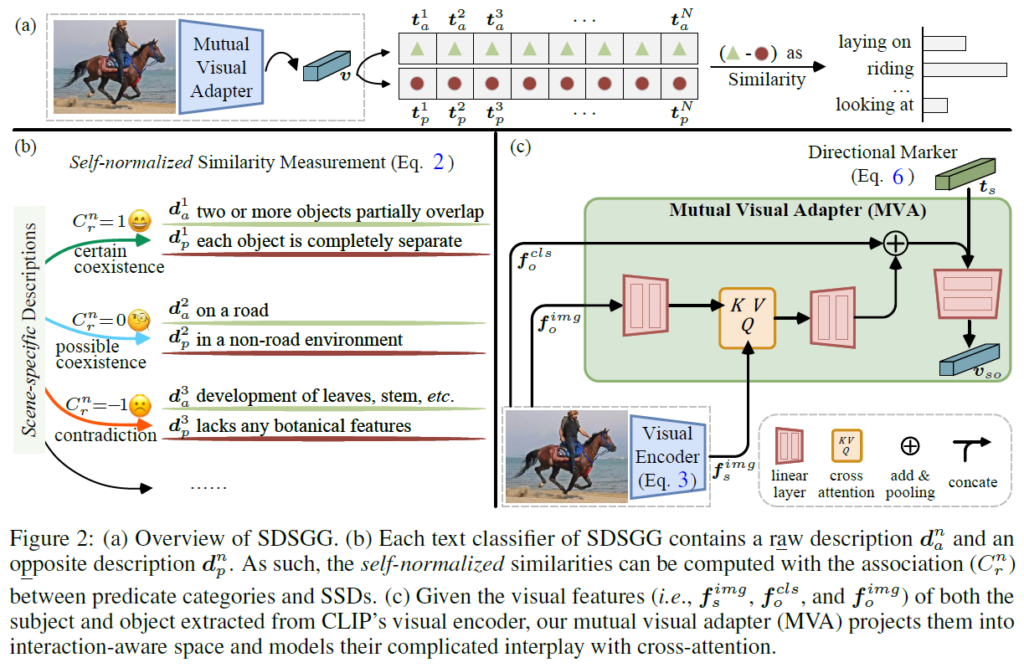
SDSGG는 장면 특화 설명(Scene-Specific Description. SSD)기반의 프레임워크이며, VLM과 LLM을 사용합니다. 텍스트 측면에서는(Fig. 2b) LLM의 multi-persona 법을 활용해서(LLM에게 다양한 전문가 역할을 부여해서 얻은 답변들을 활용) 생성된 포괄적으로 표현력 있는 장면 특화 설명들을 활용하며, renormalization 기법을 통해 각 텍스트 분류기의 영향력을 조절합니다. 시각적 정보 측면에서는(Fig. 2c) mutual visual adaptor를 활용해 주어진 subject-object 쌍에 대한 visual feature v를 집계하게 됩니다. 이제 세부 사항들을 살펴보겠습니다.
Scene-specific Text Classifiers
Scene-level Description Generation via Multi-persona Collaboration
scene description을 생성하는 가장 나이브한 방법은 LLM에게 prompt query를 주는 것입니다. “Imagine there is an animal that is eating, what should the scene look like?”와 같이 질문하면 LLM은 대규모 corpus를 기반으로 통계적으로 훈련된 내용을 바탕으로 대략적으로 질문에 대한 답변을 묘사해줍니다. 하지만 이렇게 생성된 답변은 복잡한 장면의 속성을 제대로 포착하지 못하고 장면 내부 요소들의 공간적 배치나 배경 환경과 같은 세부적인 요소들을 자주 간과한다고 합니다. 저자들은 이런 문제를 해결하기 위해 LLM 쪽 연구에서 multi-persona 관련 기법을 차용해 적용하였습니다. LLM에게 생물학, 물리학, 공학 분야의 전문가 역할을 각각 부여해서 주어진 하나의 장면에 대해 다양한 시각에서의 description을 얻을 수 있습니다. 또한 LLM에 대한 쿼리 한번 당 3~5문장의 description만 생성되기 때문에 다양한 scene content를 주제로 여러 번 쿼리를 수행해서 다양한 scene description을 얻습니다. 하지만 이렇게 생성된 초기 description들에는 중복이나 의미적인 노이즈가 포함될 수 있기 때문에 LLM에게 생성된 description들을 정제하고 통합하도록 다시 한번 쿼리를 줍니다. 이 과정을 통해 보다 포괄적이면서도 명확한 scene-level description과 이에 대한 text embedding Dl = {d1, d2, · · · , dN}과 T = {t1, t2, · · · , tN}을 얻습니다. 여기서 N은 장면 특화 설명(SSD)의 수이고, text embedding T는 CLIP의 text encoder로부터 얻습니다.
Association between Scene-level Descriptions and Relation Categories
다양한 장면을 표현할 수 있는 scene-level description을 얻기는 했지만, 이렇게 얻어진 장면 설명(scene description)이 relation category와 얼마나 관련이 있는지 정확하게 알 수 없기에, relation category와 scene description 간 얼마나 관련이 있는지를 1. 특정 장면 설명과 relation category 간 직접적인 연관성이 있는 경우 ({C}^{n}_{r} = 1), 2. 관련 가능성은 있으나 확살하지 않은 경우({C}^{n}_{r} = 0), 3. 장면 설명과 relation category(관계 범주) 간 모순이 있는 경우({C}^{n}_{r} = -1) 3가지로 나누어 구분하였습니다. 여기서 {C}^{n}_{r}은 relation r∈R과 n번째 scene description 간의 correlation을 의미하며, LLM을 통해 생성도니 프롬프로에 기반해 계산됩니다. 이렇게 세분화를 통해서 각 relation category에 대한 유사도를 보다 정밀하게 계산하였습니다.
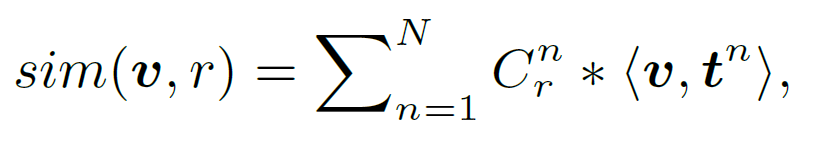
⟨·, ·⟩는 일반적으로 사용되는 cosine similarity입니다.
Scene-specific Descriptions = Scene-level Descriptions + Reweighing.
저자들은 각 텍스트 분류기(text encoder prompt)가 모두 동일하게 사용되기보다는, 각 분류기의 중요도를 평가하여 이를 반영하고자 하였습니다. 이를 위해 본래의 scene description과 반대되는 설명(opposite description) {d}^{n}_{p}를 함께 생성해 reference point로 사용할것을 제안합니다(e.g., “two or more objects partially overlap each other” vs. “each object is completely separate with clear space between them”). 이를 통해 다음과 같은 SSD {d}_{s}와 업데이트된 텍스트 임베딩 T를 만듭니다.
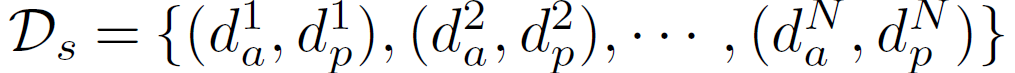
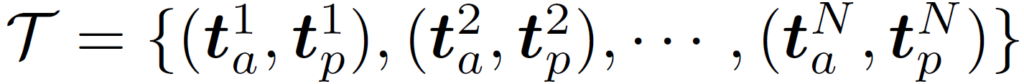
이를 통해 다음과 같이 self-normalized similarity를 정의합니다.
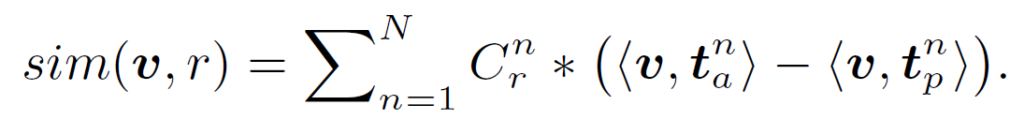
위 유사도 수식 내부의 <v, {t}^{n}_{a}>-<v, {t}^{n}_{p}>은 해당 SSD의 상대적 기여도를 정량화 합니다. 따라서 제시된 문맥과와 무관한 SSD는 <v, {t}^{n}_{a}>와 <v, {t}^{n}_{p}> 값이 거의 동일하기에 그 영향력을 줄일 수 있습니다.
Mutual Visual Adapter
앞에서는 text embedding 및 vision-language similarity를 구하는 법을 다루었고, 이제 visual embedding을 얻는 법을 살펴보겠습니다. 우선 subject-object쌍과 이에 대한 bounding box가 주어지면, 이미지 내에서 각 객체의 시각적 특징들을 얻어야 합니다. 기존의 전통적인 closed-set SGG에서는 주어진 박스 영역에 RoI pooling를 적용하였고, 최근에 OVSGG에서는 CLIP의 visual encoder를 활용해 주어와 목적어 각각의 visual embedding을 추출하고 독립적으로 part-level description으로 처리하였습니다. 저자들은 이렇게 독립적으로 처리를 하게 되면 주어와 목적어 간 유의미한 상호작용 정보를 활용할 수 없기에 이런 요소를 포착하기 위해 CLIP의 visual encoder를 fine-tuning하는 Mutual Visual Adapter(MVA)를 추가적으로 도입하게 됩니다.
Regional Encoder
이미지 I와 주어, 목적어의 bounding box {b}_{s}, {b}_{o}가 주어졌을 때 CLIP visual encoder를 통해 visual embedding을 추출할 수 있습니다.
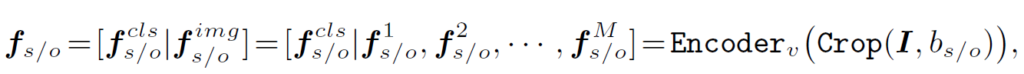
여기서 M은 패치 수를 나타내고, Encoder_v는 CLIP의 visual encoder입니다. 학습 도중에는 freeze한다고 하네요.
Visual Aggregator
그 다음, MVA는 cross-attention 및 두개의 경량화된 projection module을 통해 {f}_{s}, {f}_{o}를 집계하는데 사용됩니다. 이 때 subject 부분을 쿼리로, object부분을 value로 설정합니다. 먼저 object의 패치 임베딩 {f}^{img}_{o}를 저차원 semantic space로 projection합니다.

이후, 주어와 목적어 간 목잡한 상호관계를 포착하기 위해 cross-attention을 적용하고, 주어진 주어-목적어 pair에 대해 집계된 visual embedding을 만들어냅니다.
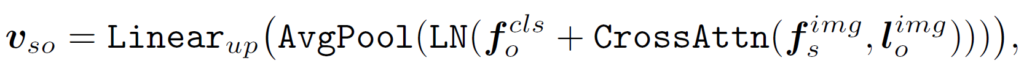
Directional Marker
지금까지 본 MVA는 그 구조가 대칭적이고, 어떤 입력이 주어이고 목적어인지 구별시켜주는 별도의 정보가 없습니다. 저자는 이런 구조가 의미론적 관계에는 비교적 영향을 적게 미치지만, 기하적 관계를 모델링할때는 큰 영향을 미칠 수 있다고 합니다(예를 들어 주어와 목적어의 위치를 바꾸거나 이미지를 flip하면 ‘먹고 있다’ 같은 관계는 바뀌지 않겠지만 ‘ 왼쪽에 있다, 오른쪽에 있다, 위에 있다’ 같은 관계에는 영향이 가겠죠). 이를 보완하기 위해 추가로 “a photo of subject/object”라는 문장을 각각 임베딩한 text embedding {t}_{s}, {t}_{o}를 추가로 포함시켜 다음과 같이 visual embedding을 업데이트하였다고 합니다.
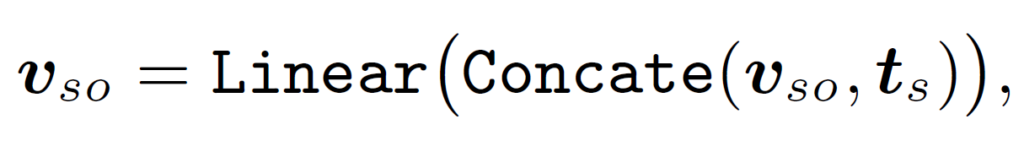
너무 나이브하지 않나 싶긴 한데, 보다 더 복잡한 directional marker 적용에 대한 연구는 future work로 남아있다고 하고 넘어갑니다.
Training Objective
일반적으로 OV 세팅에서는 positive가 임베딩 공간에서 가깝게, negative가 임베딩 공간에서 멀어지게 학습하게 됩니다. SDSGG는 positive / negative가 category가 아닌 description 수준에서 정의되기 때문에 relation-description 간 연관에 따라 loss가 정의됩니다. labeled relation triplet이 주어졌을 때 가장 간단하게 contrastive loss를 정의하는 방법은 다음과 같다고 합니다 :
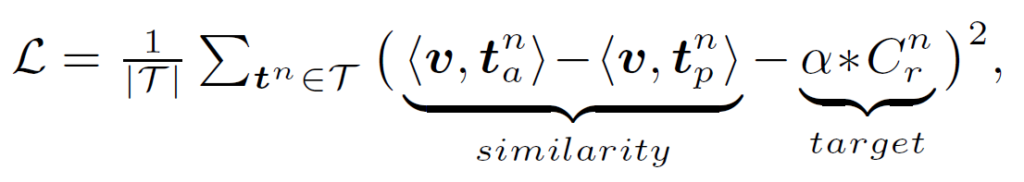
그러나, 이 때 {C}^{n}_{r}=0이면 학습에 사용할 target이 없어집니다. 저자들은 resnet의 identity mapping의 아이디어에서 영감을 얻어 MVA의 예측 결과가 CLIP의 결과가 유사하도록 하였습니다. 이를 통해 MVA가 CLIP의 semantic space에 포함된 내재적인 지식을 학습하도록 하였습니다. 따라서 전체 loss는 다음과 같이 정의됩니다 :
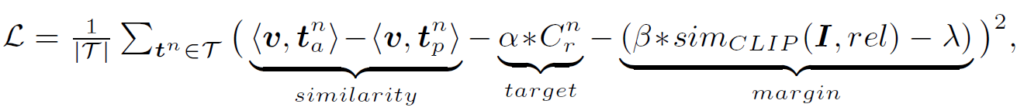
{sim}_{CLIP}은 CLIP에서 정의되는 vision-language 유사도입니다. 베타는 scaling factor이고, 람다는 상수 스칼라값으로 3e-2로 설정되었다고 합니다.
Experiment
이전 연구들의 기조를 이어받아 벤치마크는 GQA와 VG에서 이루어졌습니다. VG의 경우 70%의 base와 30%의 novel로 나누었고, 보다 포괄적인 비교를 위해 더 풍부한 의미를 가진 24개의 술어(predicate) 카테고리를 포함하는 ‘semantic set’에 대한 평가도 진행하였습니다. GQA도 동일하게 나누었다고 합니다. 각 실험에서 신뢰할만한 결과를 얻기 위해 각 실험을 3번씩 수행하였다고 하네요. 평균 및 표준편차는 표에 함께 나타내었습니다.
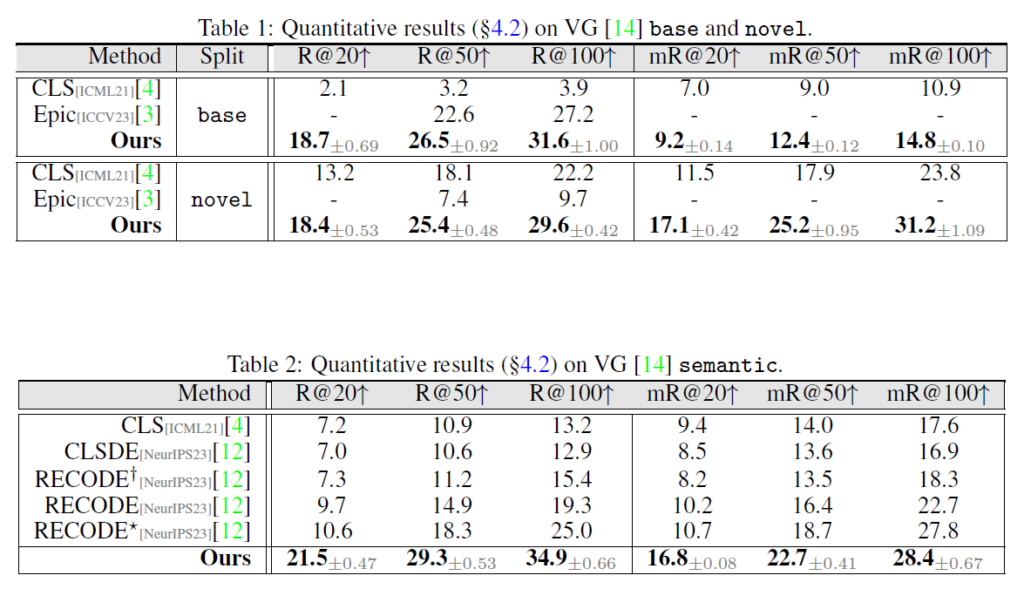
Table 1은 최신 OVSGG 모델인 Epic과 비교하였습니다.제안하는 SDSGG가 base class 및 novel class 모두에서 개선된 결과를 보여주는 것을 확인할 수 있습니다. Table 2에는 VG semantic split에 대한 성능을 나타내었습니다. RECODE는 part-level prompt를 활용해 기존 방법론들보다 좋은 결과를 보여주었습니다. 특히 필터링 전략을 함께 사용했을 때 더 큰 성능 향상을 보였다고 합니다. 하지만 이와 비교했을 때 저자가 제안하는 SDSGG이 모든 지표에서 다른 모든 방법론들보다 큰 폭으로 성능을 압도하는것을 볼 수 있습니다.
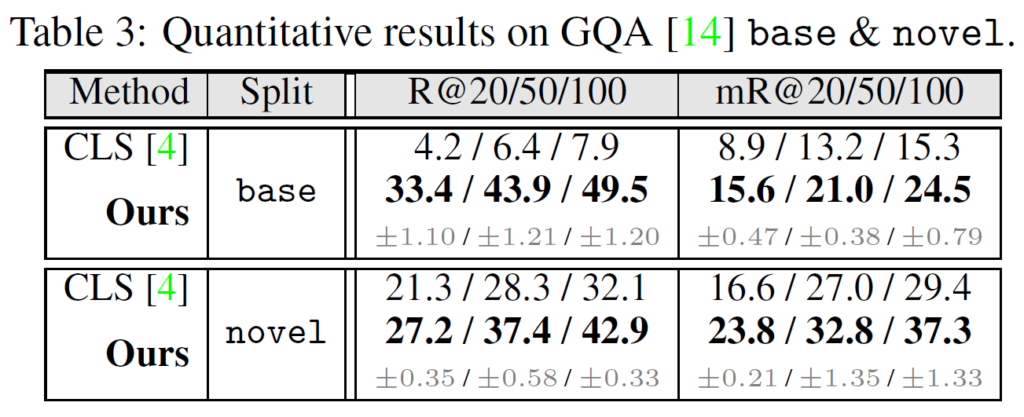
Epic과 RECODE의 경우 재구현을 위한 코드가 제대로 제공되지 않아서, GQA 데이터셋에서는 CLS와만 비교를 수행했다고 합니다. Table 3에서 보면 (제안 시기에 많은 차이가 나서 당연하지만) SDSGG가 큰 폭으로 성능을 개선한 것을 확인할 수 있습니다.
Ablation
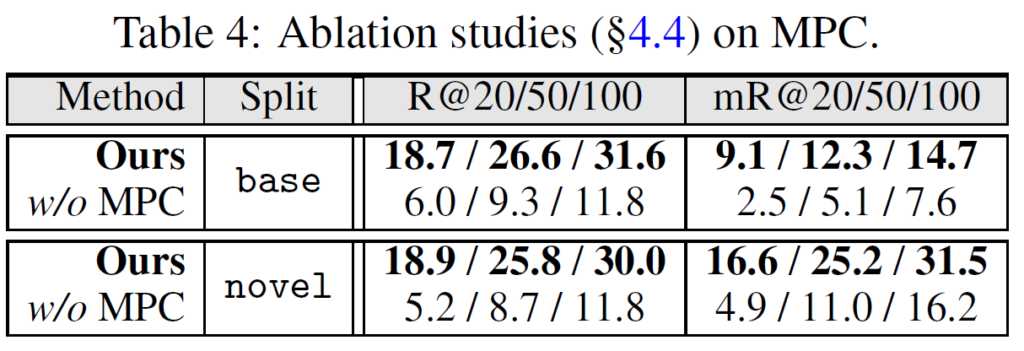
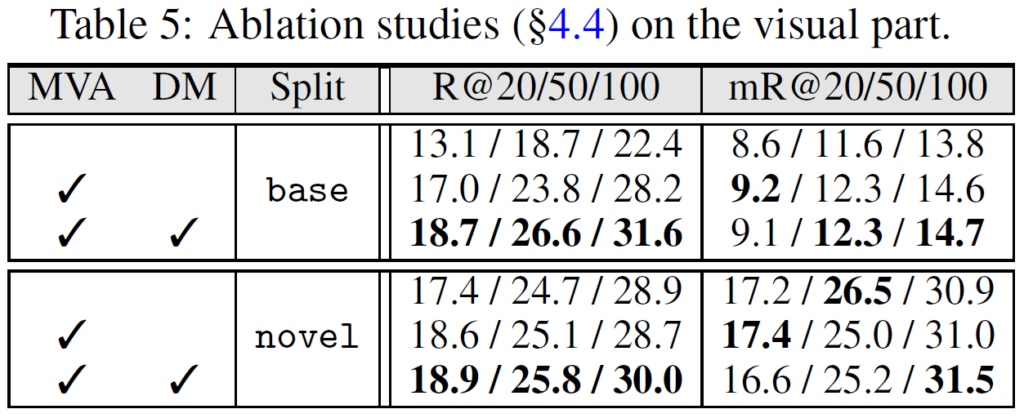
Table 4,5에는 각각 textual part인 multi-persona collaboration(MPC)와 mutual visual adapter(MVA)에 대한 ablation을 수행하였습니다. MPC가 빠질 때 성능이 크게 하락한 것에서 다양한 전문가 역할을 LLM에게 부여하는 것이 매우 중요함을 확인할 수 있었고, MVA도 빠지면 그 성능이 하락하는 데에서 visual embedding을 얻는 데 중요하다는것을 알 수 있었습니다.
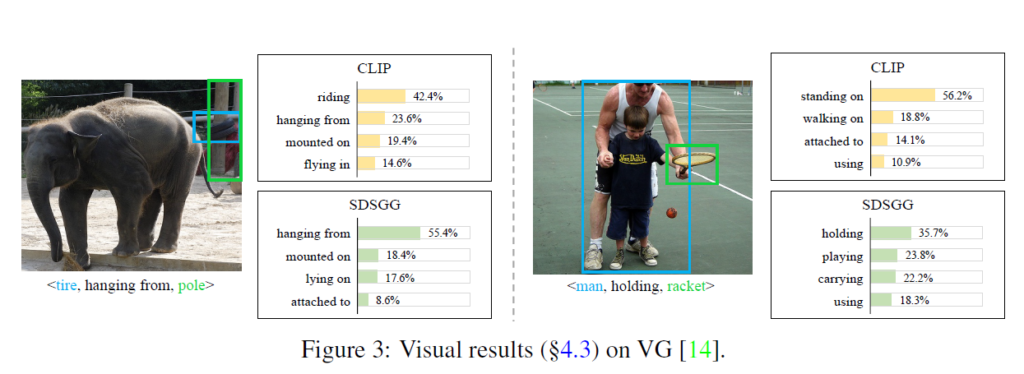
시각화 결과를 살펴보고 논문 마무리하도록 하겠습니다. Fig 3에서는 VG 데이터셋에 대해 CLIP과 SDSGG를 비교하였습니다. 보다시피 제안된 SDD를 활용했을 때 SDSGG가 challenging한 상황에서도 보다 고품질의 relation 예측을 생성하는것을 확인할 수 있습니다.
LLM을 적극 도입하여 OV-SGG에서 relation detection 성능을 향상시킨 논문이었습니다. LLM쪽 연구의 색체가 꽤 묻어있네요. 앞으로 LLM을 활용해 다양하게 prompt / description을 증강하는 기법이 일반화 될 것 같으니, 이들을 잘 활용하는 방법도 항상 염두해두고 있는것이 좋을 것 같습니다.
감사합니다.