제가 이번에 리뷰할 논문은 강화학습을 이용하여 로봇의 grasping을 수행하기 위한 연구입니다. 이전에 서베이를 하다 찾게된 논문으로, affordance에 대한 명시적인 라벨링을 사용하지 않고, 사람의 teleportation 데이터를 사용한다는 점에서 궁금하여 읽게 되었습니다.
Abstract
로봇 조작을 위해 로봇은 사물이 어떻게 작동하는지 이해할 수 있어야 합니다. 즉, 각 물체로 무엇을 할 수 있는지, 이러한 상호작용은 어디서 이루어지는지, 목표를 달성하기 위해 물체를 어떻게 사용해야 하는 지 등을 이해해야 합니다. 따라서 저자들은 사람의 teleoperated 데이터를 이용하여 효율적인 정책을 학습하고 motion을 계획하도록 model-free RL방식과 model-based planning을 결합하여 로봇이 환경과 최소한으로 상호작용하고 사람이 선호하는 물체의 영역을 찾도록 정책을 학습하는 방식을 제안합니다. 다양한 시뮬레이션 조작과 실제 로봇의 정리 실험을 통해 저자들이 제안한 Visual Affordance-guided Policy Optimization(VAPO)의 효과를 입증하고, 해당 모델이 affordance 영역을 예측하므로써 policy를 학습하는 속도가 베이스라이보다 4배 빠르게 학습되고, 새로운 물체로 일반화 성능이 개선되었음을 보입니다.
Introduction
사람은 물체의 다양한 형태와 외관이 주어지더라도 어떤 행동을 수행하기 위한 영역을 인식하는 능력이 있습니다. 이러한 능력은 주어진 상황에서 가장 관련이 높은 행동에 집중할 수 있도록 선택지를 제한하여 의사결정을 효율적으로 할 수 있도록 합니다. 그러나 affordance를 직접 학습하는 방법으로는 “어떤 동작이 가능한가?”라는 추상적인 개념을 파악하는 데는 한계가 있습니다. 환경에서 동작 가능한 영역이 어디이고 물체의 어느 영역과 상호작용 해야하는 지, 목표 달성을 위해 무엇을 할 수 있는 지, 어떻게 물체를 사용해야 하는 지를 알아야 하지만, 이를 픽셀 수준으로 수동 라벨링을 한 데이터가 실제 시나리오로 확장하기에는 부족하며, 기존 시스템은 사전에 정의된 동작에 의존하므로 복잡한 동작을 수행하기에는 어려움이 있습니다. 따라서 이러한 한계로 인해 affordance에 대한 물체와 행동이 제한됩니다.
이러한 문제를 해결하고자 저자들은 self-supervised visual affordance 모델을 통해 복잡한 조작 작업에 sample-efficient하게 policy를 학습하는 방식을 제안합니다. 저자들이 제안한 Visual Affordance-guided Policy Optimiation(VAPO)는 비용이 많이 드는 maunal supervision과 exploration(탐색) 문제를 해결하고자 사람의 teloperated play 데이터의 실제 인간 행동을 기반으로 affordance를 학습할 것을 제안합니다. play 데이터에는 물체에 대한 인간의 지식이 구조화 되어있고(영상에 서랍이 보이면 서랍을 연다), 레이블이 지정되지 않은 play로부터 학습된 affordance는 기능적 affordance로 로봇이 사람처럼 물체에 접근할 수 있도록 합니다. 따라서 저자들은 Visual affordance 모델을 통해 로봇이 복잡한 작업을 수행할 수 있도록 가이드를 주고 로봇에 객체 중심적인 affordance 정보를 사전에 제공하여 새로운 물체에 대해서도 일반화가 가능하도록 합니다.
저자들이 제안한 object manipulation은 model-based planning과 model-free RL을 결합하는 샘플 효율적인 방식으로, 기존 연구의 기계학습과 motion planning의 결합으로부터 영감을 받았다고 합니다. 구체적으로, 먼저 물체의 affordance를 예측한 뒤, model-based planing을 통해 affordance 영역 주변으로 end-effector를 이동시킵니다. 이 주변에서는 model-based 방식을 신뢰할 수 없으므로 에이전트가 affordance 영역과 상호작용하면 보상(reward)를 받는 RL policy로 전한합니다. 이를 통해 물체를 grasping하기 위한 정확한 전략을 찾도록 유도합니다. 이때 샘플 효율성을 높이기 위해 해당 논문에서 제안한 self-supervised visual affordance 모델은 두가지 방식으로 활용됩니다. (1) model-based planner로 affordance 주변 영역으로 이동하도록 하고, (2) 사람이 선호하는 물체 영역을 에이전트도 선호하도록 grasping RL policy에 가이드를 제공합니다. model-based policy와 model-free policy사이의 상호작용을 통해 사전에 정의된 manipulation primitives(3D 물체의 모양, tracking 시스템)를 가정하지 않고도 샘플 효율적으로 로봇 조작이 가능하도록 하였다고 합니다.
Approach
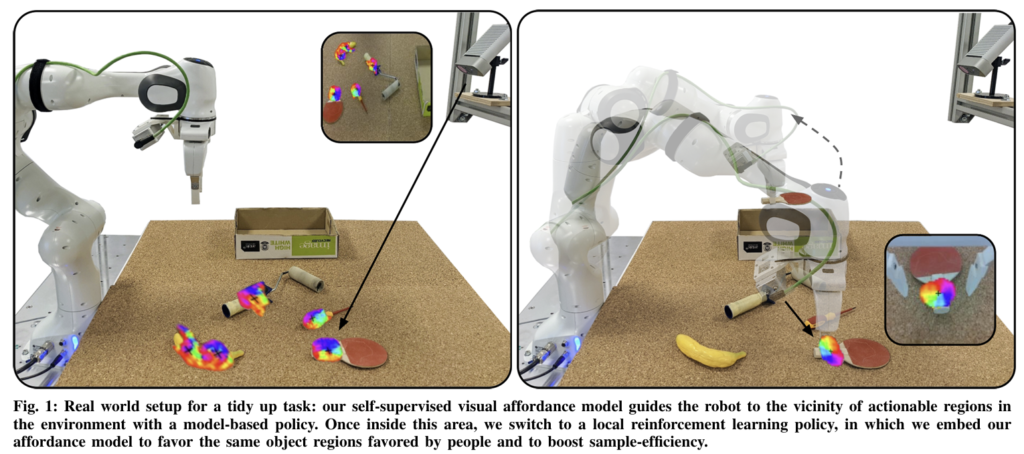
저자들이 제안한 방식의 가장 큰 이점은 샘플 효율적인 policy를 학습할 수 있다는 것으로, 복잡한 manipulation에 self-supervised visual affordance 모델이 가이드를 제공하므로써 이루어집니다. 먼저 unlabeled play 데이터로 object affordance를 학습합니다. 이후 공간을 모델 기반 정책이 신뢰할 수 있는 영역과 인식 오류나 물리적 상호작용을 처리하는 데 한계가 있을 수 있는 영역으로 나누고, 신뢰할 수 있는 영역은 model-based plolicy \pi_{mod}를 통해 end-effector를 affordance 근처 영역으로 이동합니다. 그 다음, 사람이 선호하는 affordance 영역을 에이전트도 선호하고 샘플 효율성을 높이기 위해 affordance 모델을 포함하는 local RL policy \pi_{rl} 로 전환합니다. 최종적으로 정책은 다음과 같이 혼합하여 표현합니다.
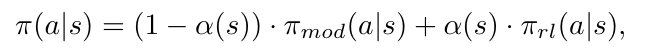
- \alpha(s) \in [0,1]: 0~1의 값으로, 로봇 그리퍼와 affordance 영역 사이의 정규화된 거리를 사용하여 policy를 전환합니다.
A. Learning Visual Affordance from Play

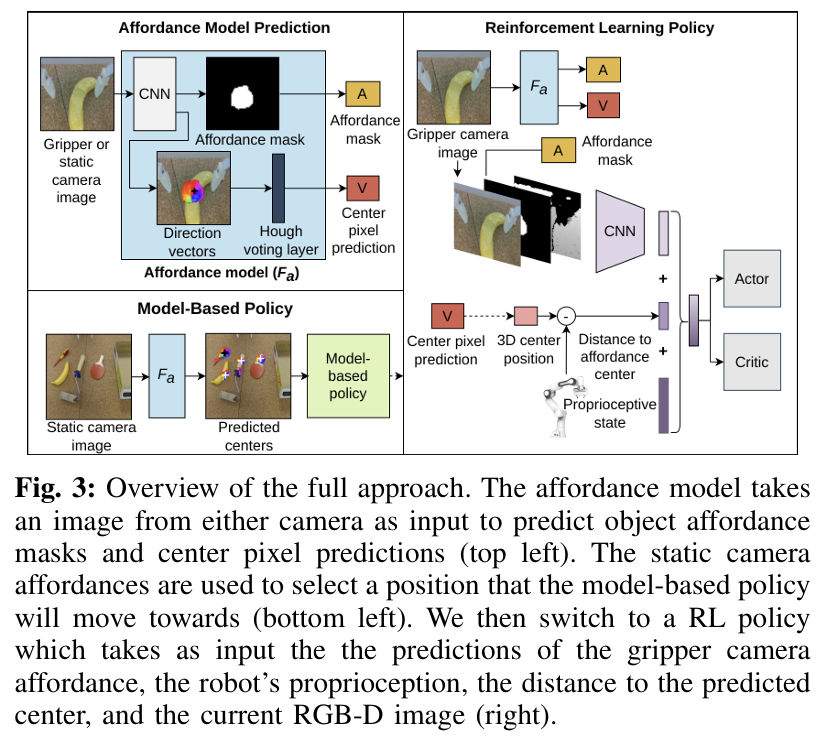
저자들은 Fig. 2와 같이 로봇 조작 과정의 그리퍼를 열고 닫는 과정의 신호를 통해 명시적인 segmentation label 없이도 어디를 잡고, 어떻게 물체를 조작할지에 대한 신호도 얻게 됩니다. 이를 위해 affordance예측을 2가지로 분해합니다. 먼저 이미지가 주어졌을 때, affordance model \mathcal{F}_a는 affordance에 대한 이진 마스크 A를 예측하고, 각 affordance 픽셀에서 중심을 향한 vector를 예측하여 affordance의 중심 2D 좌표를 추정합니다. affordance의 중심점을 추정하는 것은 장면의 여러 object에서 affordance를 구분하기 위한 요소로, 라벨이 없는 play 데이터에서 affordance를 추정하기 위해 그리퍼의 동작을 휴리스틱하게 사용하여 사람과 object의 상호작용을 감지합니다.
직관적으로 그리퍼가 닫힌 상태가 되면 해당 위치에서 상호작용이 시작될 수 있음을 나타내므로, 그리퍼의 3D point p^t_{grip}를 이미지 픽셀 u^t_{grip}으로 투영하고 지난 n프레임동안 반경 r 내의 픽셀을 affordance 영역으로 표시할 수 있습니다. 그리퍼가 닫힌 상태에서 열린 상태로 변할 경우 상호작용이 끝났음을 의미하며 이때의 3D 위치 p_i 통해 k 타임스템 까지 상호작용이 발생한 곳의 points P^k=(p_1,p_2,...,p_k)를 구합니다. t 타임에 대한 전체 상호작용 위치 집합을 얻기 위해서는 그립이 발생할 위치와 이전에 상호작용이 발생한 3D 위치를 t까지 고려합니다. 마지막으로 각 3D 점을 카메라 이미지 픽셀에 투영하여 인접 픽셀을 표시하여 affordance 마스크 라벨을 생성합니다. 투영된 포인트의 픽셀 좌표는 affordance 영역의 중심으로 사용됩니다.
다중 object에서 affordance를 구분하기 위해 네트워크가 각 affordance 픽셀에서 중심을 향한 벡터 V \in \mathbb{R}^{H⨉W⨉2}를 추정하도록 합니다. affordance mask의 각 픽셀에서 투영된 중심까지의 차이를 계산하여 라벨을 생성하고, 배경은 false positive를 방지하기 위해 사용됩니다. 이러한 방식은 사용자가 play 중에 환경과 상호작용할 때만 그리퍼를 닫는다는 가정이 있다는 한계가 있고, object 상호작용 없는 경우의 그리퍼 움직임을 필터링하기 위해 그리퍼의 폭이 특정 시간 이상 유지가 되어야 한다는 조건도 도입합니다. 전체 affordance model F_a학습에는 2가지 loss를 이용합니다. 먼저 semgentation은 cross-entropy loss \mathcal{l}_{ce}와 dice loss \mathcal{l}_{dice}를 가중합한 loss를 이용합니다. affordance의 중심에 대한 loss는 아래의 식을 적용하며, 가중 cosine similariy를 최적화합니다.
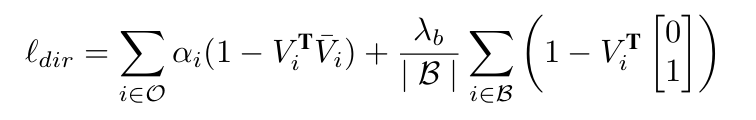
- V_i, \bar{V}_i: v픽셀 i의 예측 및 GT 단위 벡터
- \mathcal{B,O}: 픽셀이 background에 포함되는 지, affordance 영역에 해당하는 지를 나타냄
최종 loss는 이 3가지를 가중합하여 구해지게 됩니다.
B. From Model-Based to Reinforcement Learning Workspace
기존의 model-based motion planning은 복잡한 시스템에서 어려움을 겪고, RL은 복잡한 상호작용과 고차원 관측을 처리하는 일반화된 policy를 학습할 수 있다는 점에서 유망하지만, 복잡한 문제에 대한 RL policy를 처음부터 학습하는 것에는 어려움이 있습니다. 따라서 이러한 두가지를 결합하려는 연구들이 존제하고, 저자들은 이로부터 영감을 받아 3차원 공간에서 policy를 신뢰할 수 있는 영역과 인식 오류나 물리적 상호작용을 처리하는 데 한계가 있는 영역 2가지로 나눕니다.
구체적으로, 정적인 카메라 이미지를 사용하여 affordance와 해당 영역의 중심을 예측합니다. 이후, 로봇의 end-effector를 model-based policy \pi_{mod}를 통해 해당 위치 근처까지 이동시킵니다. 이후 그리퍼와 affordance 중심 간의 거리를 기준으로, model-free RL policy \pi_{rl}로 전환합니다. 여기서 강화학습이 적용되는 공간을 물체와 상호작용이 일어날 수 있는 주변 지역으로 제한함으로써 샘플 효율성을 높이고, 그리퍼 카메라로 시점 전환과 local policy 학습을 통해 다양한 위치에서의 일반화 성능도 향상시킵니다.
C. Affordance-guided Reinforcement Learning Grasping
model-based policy \pi_{mod}를 통해 affordance 영역 주변으로 이동한 뒤, 그리퍼의 카메라 시점에서 local RL polilcy로 전환하여 정책을 학습합니다. 이때, 객체 중심의 시각 affordance 정보를 사전지식으로 하여 샘플 효율성을 높입니다.
[Problem Formulation]
MDP(Markov dicision process) M=(\mathcal{S, A, T},r, \mu_0,\gamma)를 고려하며 이때 \mathcal{S, A}는 각각 state와 action을 의미하고, \mathcal{T}(s'|s,a)는 state s에서 action a를 수행햇을 때, s’로 전이될 확률을 의미한다. 행동은 정책 \pi(a|s)에 따라 확률적으로 선택되며, r(s,a)는 상태 s에서 a를 수행했을 때 얻는 보상, \mu_0와 \gamma \in (0,1)는 각각 초기 상태 분포와 discount factor를 의미합니다. 강화학습의 목표는 reward의 기댓값(누적 할인 보상)\mathbb{E}_{\pi,\mu_0,\mathcal{T}}[\Sigma^\infty_{t=0}\gamma^t r(s,a)]가 최대가 되는 policy \pi(a|s)를 학습하는 것 입니다.
[Observation Space]
observation 정보는 (1) end-effector의 3D 좌표와 오일러 각, 그리퍼의 폭을 포함하는 정보와, (2) 그리퍼 카메라로 촬영된 RGB-D 이미지와 affordance model에서 예측한 이진 마스크입니다.
[Action Space]
저자들은 시뮬레이션과 real-world에서 이진 그리퍼가 장착된 7-DoF Franka Emika Panda 로봇을 사용하며, action space는 XYZ 위치의 변화값과 오일러 각도의 변화값, binaray gripper action으로 구성됩니다.
[Reward]
reward는 성공적으로 객체와 상호작용이 이루어졌음을 의미할 뿐만 아니라, 객체에서 affordance 영역에 집중하도록 하기 위해 시각적 affordance model을 활용하여 에이전트가 affordance 중심으로 더 가까이 갈 수 있도록 가이드를 줍니다. 이를 통해 local policy는 객체에 접근하는 방법에 대한 사람의 사전지식을 가지지만, 정확하게 어떻게 잡는지에 대해서는 자유롭게 탐색하여 발견할 수 있습니다. affordance 중심과 RL policy가 주변 지역에서 local하게 이루어진다는 점을 고려하여 end-effector와 affordance 중심이 가까워질수록 양의 보상 R_{aff}이 증가하도록 합니다. 또한, 에이전트가 주변 지역을 이탈하면 음의 보상 R_{out}을 받고, 물체 조작을 성공하면 양의 보상 R_{succ}를 받도록 하여 최종 보상은 다음으로 정리됩니다.
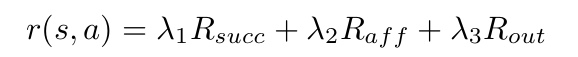
Implementation details
- Teleoperated play data
- 학습에 사용되는 teleoperated play 데이터는 전체 장면을 촬영하는 정적인 카메라와 로봇 그리퍼에 부착된 그리퍼 카메라 2대로 이미지를 취득합니다. 정적 카메라는 200×200 해상도이며, 그리퍼 카메라는 64×64의 해상도로 이루어집니다. 정적 카메라로 촬영된 이미지로 투영된 affordance 중심은 반경이 r=10픽셀이 되도록 label을 생성하고, 그리퍼 카메라에는 r=25가 되도록 label을 생성합니다.
- Affordance model
- 2개의 convolution layer 브랜치가 병렬적으로 구성된 U-net 구조로, 추론시 2D 객체 중심을 예측하기 위해 Hough voting layer를 이용합니다. 해당 레이어는 affordance 마스크와 방향 벡터를 입력으로 받아 각 픽셀에 대한 점수를 계산하여 affordance 중심이 될 가능성을 나타냅니다. 점수가 가장 높은 위치가 object 중심으로 선택됩니다.
- 위의 Fig. 3과 같이 2대의 카메라에 대해 별도의 모델을 학습시켜 2-stage affordance detection을 정의합니다. 하나는 정적인 카메라의 이미지를 사용하여 학습되며, 공간적으로 상호작용이 이루어지는 hotspot map을 예측하여 조작 가능한 영역을 나타냅니다. 그리퍼 카메라로 촬영된 이미지를 활용한 모델은 더 정밀한 local 상호작용 map을 예측하는 것을 목표로 하며, affordance에 중요한 영역 정보는 색상이 아니라 형상 정보이므로, gray scale 이미지로 변경한 뒤 네트워크에 입력됩니다.
- Affordance-guided Reinforcement Learning
- policy를 학습하기 위해 해당 논문에서는 Soft Actor-Critic(SAC)을 이용합니다. RGB-D 이미지와 추론된 affordance mask가 주어졌을 때, 이를 convolution 네트워크에 입력하여 feature를 추출한 뒤, 이를 로봇 상태와 affordance 중심까지의 거리와 결합됩니다. 이후 fully connected layer 4개를 통과합니다. actor와 critic은 동일한 구조이지만 서로 다른 파라미터를 가지도록 구현되며, 시뮬레이션 실험에서 400K의 에피소드 step동안 길이가 100 step인 모든 object에 대해 단일 정책을 학습합니다. 이는 30시간의 학습 데이터이며, 학습 시 보상함수 의 가중치는 모두 1로 설정하고, R_{succ}=200, R_{out}=-1로 설정합니다.
Experiments results
[시뮬레이션 세팅]

시뮬레이션은 grasping과 서랍 열기에 대하여 평가합니다. grasping은 pybullet 시뮬레이션 환경에서 다양한 물체를 들어올리는 것으로, 이는 fig. 4와 같이 망치, 칼, 드릴 등 다양한 15개 물체에 대하여 학습됩니다. 물체를 들어올린 뒤, 2초동안 공중에 있으면 이는 grasping에 성공한 것으로 정의합니다.
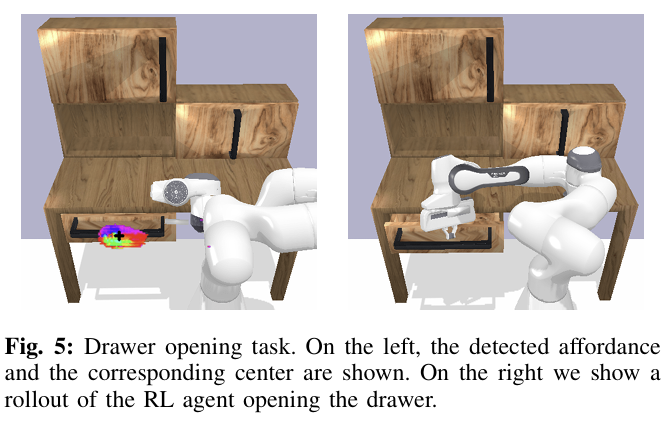
다음으로 서랍을 여는 작업의 경우 서랍이 닫혀있고, 로봇이 중간에 있도록 구성됩니다. 해당 작업은 로봇이 15cm 이상 서랍을 열면 성공한 것이라 정의되며, affordance model을 학습하기 위해 VR로 데이터를 수집합니다. 정적인 카메라와 그리퍼 카메라에 대한 affordance model을 학습시키기 위해 각 환경에 대해 100K개의 이미지에 해당하는 2시간 분량의 상호작용 데이터를 수집합니다.
[real-world 세팅]
7DoF Franka Emika Panda로봇을 사용하여 환경을 구성합니다. 시뮬레이션과 마찬가지로 fig. 2와 같이 VR 컨트롤러를 이용하여 로봇을 조작하여 play 데이터를 수집합니다.1.5시간의 사람 상호작용 데이터를 수집하여 70K개 이미지를 취득하고, 이를 이용하여 그리퍼 카메라와 정적 카메라에 대한 affordance model을 학습합니다.
Simulation Result
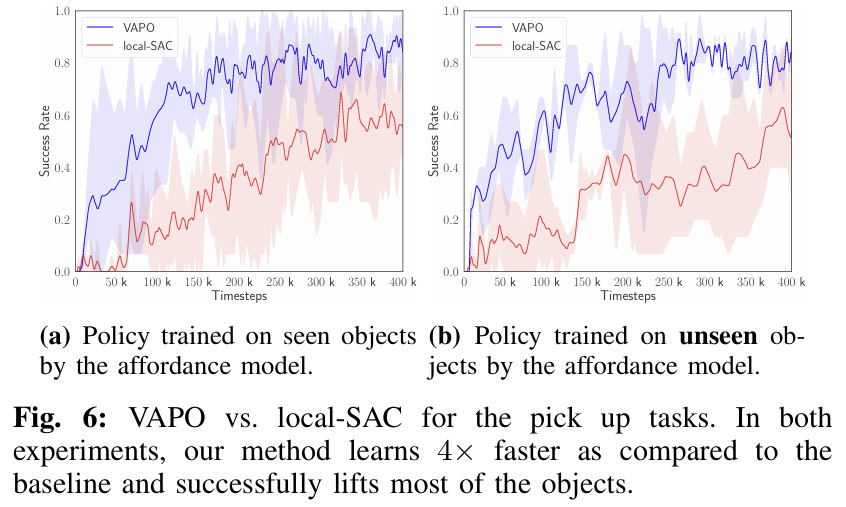
물체를 들어올리는 policy를 먼저 학습한 결과, 저자들이 제안한 방식이 베이스라인보다 더 많은 물체를 성공적으로 들어올렸으며, 이는 로봇이 상호작용하는 방식에 대한 지식을 가지고 있었기 때문으로 해석합니다. 특히, VAPO는 예상되는 affordance 영역을 잡지만, 베이스라인 방식은 복잡한 형태에 대해서는 객체를 잘 잡지 못하는 것을 확인하였다고 합니다. 또한, 30시간의 로봇 상호작용 후 베이스라인은 0.6의 작업 성공률을 보이는 반면, VAPO는 100k만에 0.6의 성공률을 달성하였다는 것을 통해 약 4배 더 빠르게 학습이 이루어짐을 어필합니다. 400K step 이후에도 VAPO가 0.9의 성공률을 유지한느 것을 확인할 수 있습니다.
추가로, 저자들은 unseen object로의 일반화 성능을 평가하기 위해 affordance model이 학습에 사용하지 않은 15개의 객체에 대한 학습 및 평가를 수행하였습니다. Fig. 6의 오른쪽 그래프가 이에 대한 결과로, zero-shot 평가를 수행하였으며, VAPO는 13/15의 성공률을, 베이스라인은 8/15의 성공률을 달성하였습니다. 이러한 결과를 통해 일반화 성능이 개선되었음을 어필합니다.
추가로, 서랍을 여는 작업에 대한 실험 결과 VAPO는 0.84의 성공률은, 베이스라인은 0.52의 성공률을 달성하였습니다. 이를 통해 일관적으로 저자들이 제안한 VAPO가 우수한 성능을 보임을 입증하였습니다.
Real-world Result
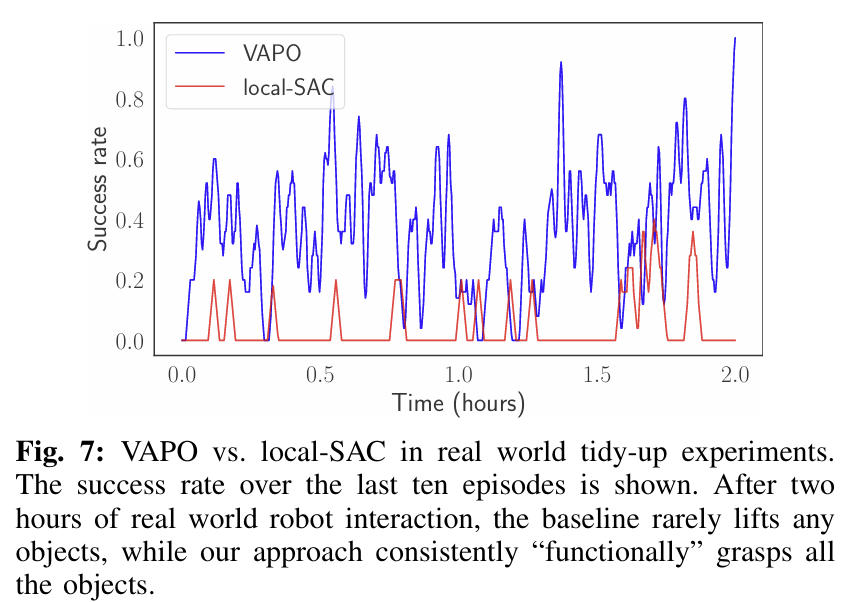
Fig. 7은 real-world에서의 평가 결과로, 플라스틱, 바나나, 탁구 라켓, 페인트 롤러 4가지 물체를 집어올리는 방법을 학습합니다. 2시간의 학습 후 VAPO는 손잡이를 잡는 등 물체를 “functionally” 일관적으로 잡을 수 있게 되었으며, 베이스라인인 local-SAC(빨간색)는 거의 성공하지 못한 것을 그래프를 통해 확인할 수 있습니다. 이를통해 전반적으로 저자들이 제안한 방식이 효과적임을 보였습니다.
안녕하세요 승현님 리뷰 감사합니다.
그리퍼의 조작 여부가 달라지는 지점이 affordance를 수행하는 지점이라고 생각하고 affordance 중심과의 거리를 기준으로 model-based -> model free로 전환한다고 이해했는데요, affordance 주변까지 model based 강화학습을 활용한 모션 플래닝을 한다고 이해했는데요, 대략적인 affordance 영역까지는 강화학습을 활용하지 않고 IK를 통한 모션플래닝을 하게 된다면 model free 학습에 문제가 있을까요??
질문 감사합니다.
해당 연구는 이해하신대로 대략적인 affordance 영역까지는 model-based planning을 통해 이동한 뒤, 이후에 model-free 방식으로 구체적인 grasping을 수행합니다. 또한, 질문하신 내용이 affordance 주변 영역에 대해 예측한 정보로 IK로 이동한 뒤, 이후에 model-free 방식으로 grasping에 대해 학습하는 것에 대한 질문이 맞을까요? 우선 질문하신대로 IK로 접근하는 것 도 문제가 없다고 생각합니다. IK도 model-based planning 방식에 해당한다고 보아도 되지 않을까 합니다.
안녕하세요 승현님, 좋은 리뷰 감사합니다.
1. model-based policy 라는 것이 motion planning이라고 이해해도 되나요?
2. 해당 방법론은affordance의 기준이 gripper의 grasp 이벤트로부터만 휴리스틱하게 간접적인 affordance 시그널을 얻다보니, long-horizon task나 물체를 복잡하게 활용하는 동작에 있어서는 작동하기 힘들 것으로 보이는데요.
만약 사람이 물체와 상호작용하는 어떤 대규모 human action video로부터 latent action pre-training VLM 같은 모델을 학습시켜, affordance 예측 모듈 쪽에 latent action feature 정보를 넘겨줄 수 있다면, 본 방법론에서 제시하는 휴리스틱한 affordance 시그널에 개선을 이룰 수 있을까요?
질문 감사합니다.
1. 넵. 맞습니다. 코드상으로 해당 과정은 IK(inverse kinematics)를 적용한 것으로 확인됩니다.
2. 좋은 질문 감사합니다. 이야기하신대로, 해당 연구는 물체에 대한 복잡한 활용에는 어려움이 있을 것 같습니다. 실제로 실험을 한 것도 물체 grasping과 서랍 열기 작업으로 한정되어있습니다. 재찬님이 이야기하신 내용이 affordance 모듈을 대체하는 것 이라면, 개선에 도움이 될 것 같습니다. 또한, teleoperated play 데이터에 더 다양한 작업이 포함되면 좋을 것 같습니다. 그러나 “작업 의도”를 반영하기 위해서는 이야기하신 것처럼 affordance를 예측하는 모델 관점에서 개선이 이루어져야 하고, “복잡한 작업”을 수행하기 위해서는 전체적인 파이프라인의 변화가 필요할 것 같습니다.
재밌는 논문 리뷰 감사합니다.
간단한 질문 남기고 가도록 하겠습니다.
Q1. “저자들이 제안한 Visual Affordance-guided Policy Optimiation(VAPO)는 비용이 많이 드는 maunal supervision과 exploration(탐색) 문제를 해결하고자 사람의 teloperated play 데이터의 실제 인간 행동을 기반으로 affordance를 학습할 것을 제안합니다.”
-> 실제 인간 행동을 기반으로 affordance를 학습하다는 말이 굉장히 인상 깊게 다가 왔습니다. 근데 아쉬운 부분이 “비용이 많이 드는 maunal supervision과 exploration(탐색) 문제를 해결”라고 했지만.. 결국에 play 데이터를 생성했으니깐 해결하고자 하는 문제는 똑같지 않나 싶어요. 제가 캐치하지 못한 부분이 있다면 추가 설명 부탁드립니다.
Q2. affordance labeling을 self-supervised라고 칭하는데… 솔직히 GT로 학습하면서 왜 self-supervised라고 칭하는지 이해가 안가요. 저자가 self를 칭한 이유가 뭘까요?
Q3. affordance labeling은 거리 값을 영상에 어떻게 사영 시켰나요? RGBD는 아닌 것 같은데… 흠…
질문 감사합니다.
A1. 이야기하신바와같이, 데이터 효율성 측면을 고려하였다고보기에는, teleoperation이 필요하다는 함정이 있는 것 같습니다. 그러나 로봇을 조작해야 한다는 점에서 teleoperated play 데이터도 필요한데, affordance를 위한 픽셀 레벨의 수동 라벨링을 하지 않아도 된다는 점에서는 유의미한 것 같습니다. 또한, 의미론적으로도 부합해야하고, 물리적으로도 가능해야한다는 점에서 affordance를 사전 정의하는 것에 어려움이 있다고 생각합니다. 그런 관점에서 이러한 실제 조작 데이터 기반의 affordance는 하나의 방안이 될 수 있을 것 같습니다.(물론 행동에 부합하는가?에 대한 질문은 또 고민해야 할 것 같습니다.)
또한, 해당 논문에서 가장 어필하는 것이 “sample-efficient”하다는 점 입니다. 즉, 로봇 조작으로인해 필요한 데이터를 두 과정에 모두 다 사용할 수 있다는 점을 어필합니다.
A2. self-supervised는 맞습니다. GT를 라벨링하는 것이 그리퍼가 닫히고 열리는 기준으로 자동으로 생성 가능하기 때문입니다. 해당 과정을 다시 정리해드리면 다음과 같습니다.
1. (상호작용 필터링)그리퍼가 닫힘~열림 사이를 상호작용이 일어난다고 가정하고, 중간에 너무 짧은 닫힘~열림은 필터링
2. (affordance 중심좌표 구하기) 닫히는 지점과 열리는 지점 사이의 그리퍼의 3D 위치를 이미지 픽셀로 투영하여 중심 좌표를 구함.
3. (affordance map과 중심 방향에 대한 vector 라벨 구하기) 그에 대하여 static 카메라는 r=10픽셀, 그리퍼 카메라에는 r=25가 되도록 하는 affordance mask와 각 픽셀에 대한 중심 좌표로의 방향 vector를 생성합니다.)
A3. 우선 RGB-D 센서를 이용합니다. 또한, 3D 그리퍼의 좌표와 affordance 중심에 대한 3D point 사이의 거리르 측정하면 문제가 없을 것 같습니다.