안녕하세요. 박성준 연구원입니다. 오늘 리뷰할 논문은 fine-grained CLIP입니다. 대규모 이미지-텍스트 모델인 CLIP의 fine-grained 능력을 향상시킨 연구입니다.
Introduction
CLIP은 대규모 이미지-텍스트 모델로 zeroshot 이미지 분류와 같은 작업에서 뛰어난 성능을 보이며 공개된 이후 많은 관심을 받으면 많이 활용되어왔습니다. 하지만, 짧은 캡션 중심의 사전 학습으로 인해 fine-grained level의 이미지 분류에서는 한계가 있었습니다. 즉, 이미지의 대략적인 장면이나 객체를 인식할 수는 있지만, 같은 범주 내에서의 fine-grained 분류에는 어려움이 있었습니다. 이러한 한계를 해결하기 위해 기존 연구들은 텍스트 인코더의 긴 positional embedding을 활용하여 긴 텍스트를 처리하거나 객체 검출 데이터셋을 활용하여 이미지의 영역 단위로 학습을 하는 등의 접근을 통해 해결하려 했습니다. 하지만, 저자는 이러한 기존 방법들은 일정 부분에서의 향상이 있었지만, 여전히 fine-grained detail에서는 아쉬움이 있었고 Open-Vocabulary 객체 검출에서도 만족스러운 결과를 내지 못했다고 지적합니다. 저자는 CLIP과 기존 연구들이 데이터 규모면에서의 한계와 의미적 다양성 부족의 한계가 있으며, 결정적으로 동일한 범주 내에서 미세한 차이를 학습하기 위한 hard negative sample이 없으면 CLIP의 fine-grained 성능이 낮을 수 밖에 없다고 설명합니다.
따라서, 저자는 이러한 문제들을 해결하기 위해 3자기 전략을 제안합니다.
- 최신 MLLM을 활용한 긴 이미지 캡션 데이터셋 구축: 총 16억쌍의 이미지-긴 텍스트 데이터셋을 구성함으로 모델이 이미지의 복잡한 context 혹은 세부사항까지 학습할 수 있습니다.
- fine-grained visual grounding 데이터셋 구축: 저자는 각 영엵마다 구체적인 설명을 함으로 이미지의 부분적인 요소와 텍스트 사지의 fine-grained alignment를 학습할 수 있습니다.
- hard negative sample 활용: 저자는 1천만개의 hard negative sample을 생성하여 실제 positive과 속성만 미묘하게 다르게 구성함으로 거의 비슷한 두 이미지/텍스트 사이의 fine-grained 차이를 이해할 수 있도록 합니다.
위 3가지 요소들을 통합하는 Fine-grained Grounding. Recaptioning, Negative(FgGRN) 데이터셋을 구성하고 기존 CLIP 대비 fine-grained level의 이미지-텍스트 정렬을 가능하게 했습니다. 학습은 2-stage로 구성되며, 1단계에서는 CLIP과 마찬가지로 대규모의 이미지-텍스트 contrastive learning을 수행합니다. 2단계에서는 FgGRN 데이터셋을 활용하여 지역(region) 수준의 정밀한 학습과 hard negative 학습을 진행합니다. FgGRN 데이터셋과 이러한 2가지 학습 전략을 통해 저자는 fine-grained 능력이 강화된 CLIP인 FG-CLIP을 제안합니다.
Method
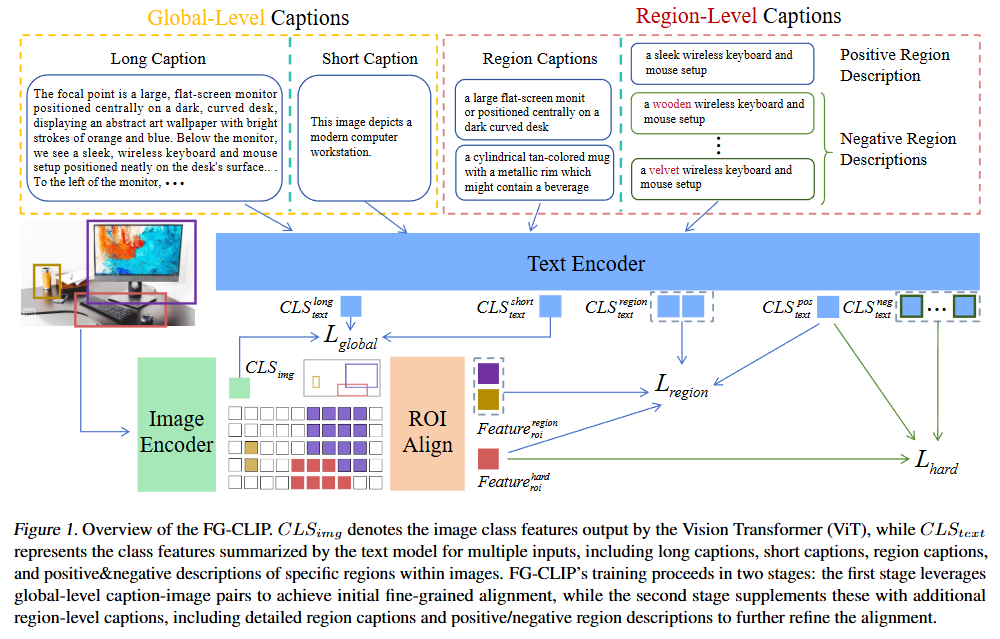
Figure 1. 은 FG-CLIP의 프레임워크를 보여주는 그림입니다. Introduction에서 설명드린 것처럼 두가지 단계로 구성되어있습니다. 1단계는 Global-level captions를 활용하여 사전학습하는 단계, 2단계는 Region-level captions를 활용하여 학습하는 단계입니다.
Global Contrastive Learning
FG-CLIP의 1단계인 Global Contrastive Learning에서는 이미지와 텍스트 사이의 전역적 의미를 학습하기 위한 Contrastive Learning 단계입니다. CLIP의 기본적인 표현력을 향상하는 것으로 긴 텍스트를 활용하여 학습합니다. 예를 들어, bird는 ‘a bird’라고 표현되지만, 저자는 ‘a red-winged blackbird perched on a tree branch in a park’와 같이 굉장치 구체적인 긴 텍스트를 활용하여 CLIP을 학습하는 것으로 전역적인 이미지에 대한 이해를 향상시킵니다. 저자는 이러한 긴 텍스트와 짧은 텍스트를 같이 활용하는 것으로 CLIP의 표현력을 향상시켰다고 합니다. 학습은 일반적으로 Contrastive Learning에서 활용하는 InfoNCE loss를 활용하여 학습하였습니다.
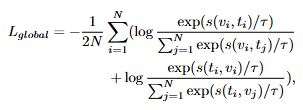
Regional Contrastive Learning
FG-CLIP의 2단계인 Regional Contrastive Learning에서는 region 기반의 세밀한 정렬을 위한 학습을 수행합니다. FgGRN 데이터셋을 활용하여, 이미지의 특정 영역과 텍스트를 대응시키는 방법을 통하여 학습합니다. 이미지 인코더의 중간 계층에서 RoIAlign 기법을 활용해 각 바운딩 박스 영역에 대한 특징벡터를 추출하고, 텍스트에서는 이미지 캡션을 전처리하고 그 영역을 묘사하는 일분 문장을 추출하여 임베딩 벡터를 추출합니다. 그 후 이미지 영역의 특징 임베딩 벡터와 영역의 텍스트 특징 임베딩 벡터 쌍을 통해 학습합니다. Global Contrastive Learning과 마찬가지로 InfoNCE loss를 활용하여 학습합니다.
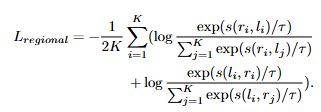
저자는 2단계의 Regional Contrastive Learning을 위해 FgGRN에 특별한 과정을 거쳤다고 설명하고 있습니다. 저자는 GRIT 등의 대규모 이미지를 활용하여 각 이미지에 대해 LLM을 활용하여 상세한 텍스트를 생성한다고 합니다. 그 다음에는 SpaCy를 활용하여 여러 개의 객체를 설명하는 구문들로 텍스트를 분해하고, Yolo-World 검출기를 통해 이미지 내에서 그 구문에 해당하는 지역을 검출했다고합니다. 이러한 방식을 통해 하나의 이미지에 여러개의 객체-텍스트 쌍을 생성하였으며, 총 1200만장의 이미지와 4000만개의 영역과 텍스트 쌍을 생성했습니다. 저자는 FgGRN은 이러한 풍부한 데이터를 통해 FG-CLIP을 학습했다고 강조하고 있습니다.
Hard Negative Learning
FG-CLIP의 2단계 학습에서 이미지 영역과 텍스트를 활용한 Contrastive Learning에는 Hard Negative 샘플을 활용한 디테일이 숨어있습니다. Hard Negative 샘플은 이미지 영역에 대한 설명과 굉장히 유사하지만 사실은 틀린 설명입니다. 즉, 원래 positive caption과 유사하지만, 실제로는 틀린 설명으로 모델로 하여금 디테일한 정보를 학습할 수 있습니다. 예를 들어, ‘man in red clothes’가 positive sample이라면, hard negative 샘플은 ‘man in blue clothes’와 같은 전체적인 설명은 같지만 하나의 정보를 다르게하여 틀린 설명을 만드는 것입니다.
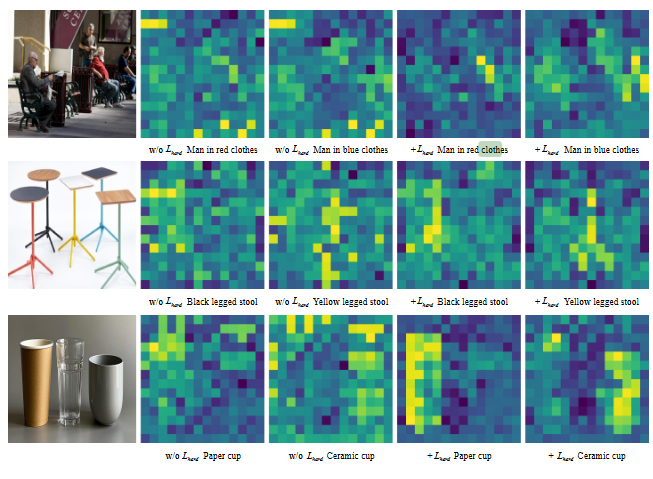
위 그림은 실제로 구성된 FgGRN 데이터셋과 hard negative 샘플에 대한 FG-CLIP과 기존 CLIP의 성능입니다. hard negative learning을 하지 않았을 때에는 hard negative에 제대로 대응하지 못하고 있지만, 학습 후에는 제대로 텍스트에 일치하는 모습을 확인할 수 있습니다.
저자는 LLaMA-3.1-70B 모델을 활용하여 영역을 설명하는 텍스트에서 중요 속성을 변경하여 hard negative 샘플 1000만개를 자동으로 생성했습니다. LLM으로 생성 후 직접 생성된 텍스트의 품질을 검증하는 것을 통해 98.9%의 문장이 적절한 hard negative 샘플이라는 것을 확인했다고 합니다.
hard negative 샘플을 활용한 학습은 positive 샘플과 hard negative 샘플을 같이 학습하는 것으로 positive에는 높은 유사도 점수를 주고 hard negative에는 낮은 유사도 점수를 주는 것으로 학습합니다. 이를 위해서 저자는 다음과 같은 loss를 활용합니다. 모델이 hard negative 학습을 통해 fine-grained lavel의 분류 능력을 얻을 수 있습니다.
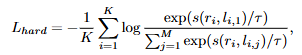
결과적으로 3가지 loss를 합한 최종 loss를 활용해서 학습합니다.
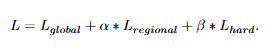
Experiments
저자는 FG-CLIP을 다양한 세팅에서 실험하고 성능을 평가하였습니다. ViT-B/16과 ViT-L/14 모델을 사용하였으며 원본 CLIP외에 FineCLIP, Long-CLIP과 같은 이전의 fine-grained CLIP 연구들도 포함되어있습니다. 저자는 fine-grained understanding, bounding box classification, open-vocabulary detection에서 FG-CLIP을 평가했습니다.
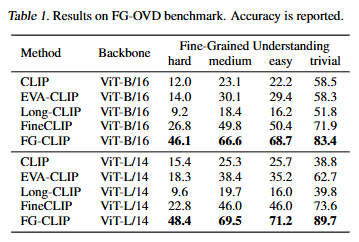
먼저, Fine-grained understanding입니다. FG-OVD 데이터셋에서 평가했으며, FG-OVD는 동물이나 사물의 같은 범주 내에서도 세밀한 속성 차이, 종류 차이등을 분류해야하는 데이터셋입니다. 굉장히 어려운 데이터셋으로 zeroshot으로 이 세밀한 차이를 분류하는 것에는 기존 CLIP에는 어려움이 있습니다. 하지만, 저자가 제안하는 FG-CLIP은 기존 CLIP에 4배에 달하는 성능을 달성하였습니다. 기존에 Fine-grained 연구들의 성능도 많은 차이로 훨씬 더 높은 성능을 보이면서 저자가 제안하는 FG-CLIP의 성능을 강조하고 있습니다.
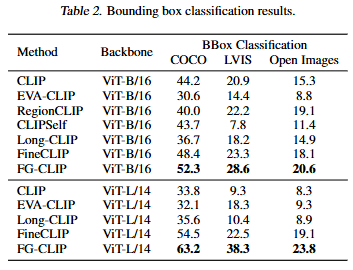
비슷한 방식으로 bounding box 분류도 실험하였습니다. 말 그래도 이미지 내 객체가 존재하는 bounding box의 객체를 분류하는 task입니다. 이 task 또한, 이미지 내 작은 영역에 대한 분류를 수행해야하기에 기존 CLIP은 잘 대응하지 못하는 task였습니다. 저자가 제안하는 FG-CLIP은 B/16, L/14에서 모두 제일 높은 성능을 보여줍니다. 특히, L/14의 경우 기존 SOTA 모델에 10퍼센트에 가까이 성능 개선을 보이며 저자가 제안하는 방법론의 효과를 강조하고 있습니다.
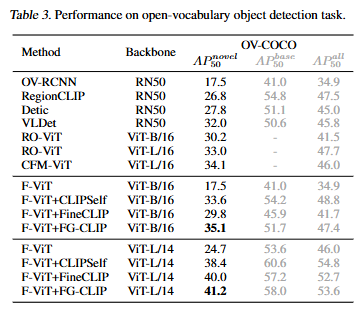
그리고 open-vocabulary detection에서의 성능입니다. 사실 open-vocabulary를 CLIP이 직접 수행하지는 않고 저자는 F-ViT를 활용하여 성능을 평가합니다. F-ViT는 구체적으로 어떻게 작동하는 지는 찾아보지 못했지만, CLIP을 백본으로 활용하여 open-vocabulary 검출을 수행하는 연구라고 합니다. 아무튼, F-ViT에 FG-CLIP을 백본으로 적용한 방법론이 기존 방법론들에 비해서도 높은 성능을 보이고 저자가 제안하는 방법론의 성능을 보여주고 있습니다. OV-COCO는 베이스 카테고리와 새로운(novel) 카테고리를 구분하여 평가합니다. FG-CLIP은 base 카테고리와 all(base + novel)에서는 SOTA는 아니지만, open-vocabulary의 의도에 맞는? novel에서 가장 높은 성능을 달성함으로 FG-CLIP의 세밀한 표현 학습이 객체 검출에도 큰 이점을 주는 방법론이라고 설명합니다.
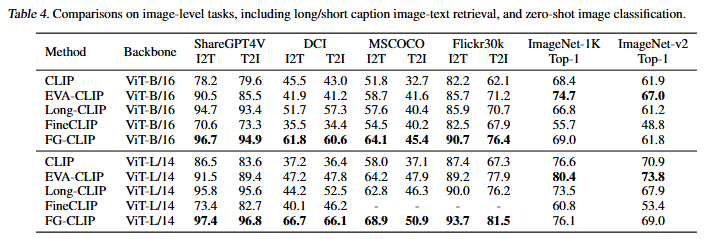
마지막으로 image-text task에서의 성능입니다. 긴 텍스트와 짧은 텍스트 모두에서 기존 CLIP 및 방법론들보다 뛰어난 성능을 보입니다. 저자는 위 성능을 통해서 FG-CLIP이 짧은 텍스트, 긴 텍스트 모두에서 높은 성능을 보이는 것을 잘 보여줍니다. 다양한 길이, 다양한 맥락에서 잘 학습되었으며, 동시에 기존 CLIP의 능력이 유지되며 잘 강화되었다고 강조합니다.
Ablation Study
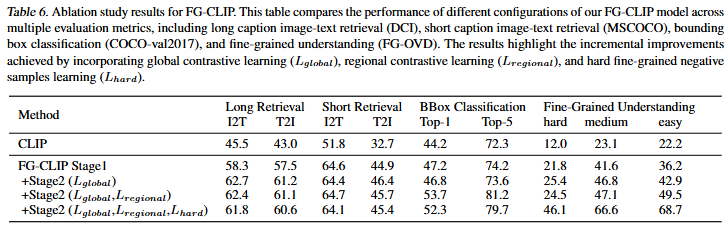
마지막으로 ablation study입니다. 저자는 긴 텍스트를 활용하는 1단계에서 이미 CLIP의 성능을 뛰어넘었습니다. 저자는 긴 텍스트를 통한 이미지의 디테일에 자세한 설명을 넣는 것의 중요성을 ablation study를 통해서 보여주고 있습니다. 또한 추가적인 2단계 학습을 통해 CLIP의 성능이 개선되는 지를 보여주고 있습니다. 특히 저자는 hard negative 샘플들을 활용한 학습의 효과를 강조하고 있는데 Fine-grained에서 굉장히 높은 향상폭을 보이고 있는 것을 확인할 수 있습니다. 다른 성능에서 살짝 하락하긴 하지만, 미세한 차이를 구분하는 데에 있어 모델이 fine-grained에 잘 대응할 수 있도록 한다는 점에서 효과적이었다고 강조하고 있습니다.
마지막으로 정성적 결과입니다. 아래의 Figure 2.는 저자가 구성한 데이터셋의 예시를 보여주고 있습니다. 긴 텍스트와 짧은 텍스트 그리고 각 영역에 대한 텍스트 쌍이 모두 존재하는 데이터셋으로 저자는 잘 설명된 데이터로 구성된 데이터셋의 중요성을 강조합니다.
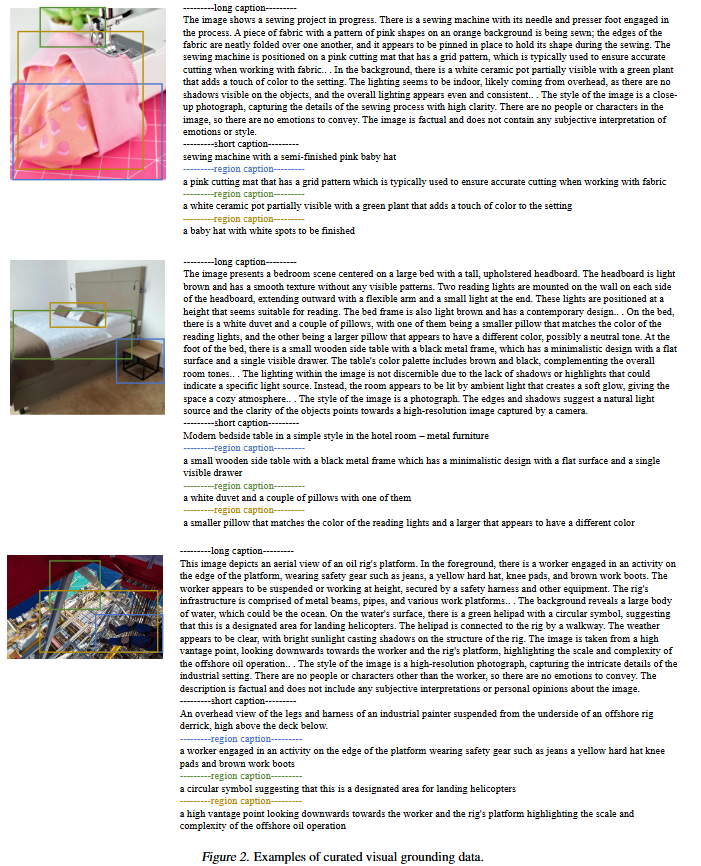
Figure 3.는 positive와 negative 샘플들의 예시입니다. 여러 종류의 hard negative 샘플의 활용을 통해 FG-CLIP의 fine-grained 이해력을 향상시킬 수 있었음을 보여주고 있습니다.

감사합니다.
안녕하세요, 박성준 연구원님. 좋은 리뷰 감사합니다. 보다 fine-grained 한 VLM을 제안한 방법론이네요. 성능이 꽤나 많이 개선되어 흥미롭습니다. 질문이 두 가지 있습니다.
1. 사전학습 단계에서 16억쌍의 image-long text caption 데이터셋을 활용하여 contrastive learning을 진행하는데, 이 image와 long text caption은 어떻게 수집한건가요? 그리고 Figure에서 long text caption과 함께 사용되는것으로 보이는 short caption은 어떠헥 얻나요?
2. CLIP과 같은 VLM을 개선시킨 논문이면 zerp-shot classification 성능이 리포팅되어있어야 할 것 같은데, 해당 실험은 없었는지, 있었다면 실험 결과가 어땠는지 궁금합니다.
감사합니다.
안녕하세요 허재연 연구원님 좋은 댓글 감사합니다.
대규모 이미지는 GRIT, LAION 데이터셋과 같이 오픈소스로 공개된 데이터셋을 활용했고, 그에 따른 caption은 LLM을 통해 생성했습니다. shot caption은 수집한 데이터셋이 vision-language 데이터셋이라면 그대로 활용했고, 아닌 경우에는 마찬가지로 LLM을 활용하여 얻었습니다.
Table 4의 실험 결과에는 short image/text retrieval의 실험 결과도 포함되어 있습니다. CLIP이 평가한 여러 데이터셋에서 FG-CLIP 또한 같이 평가하는 것으로 CLIP의 성능을 개선시켰다는 것을 증명하고 있습니다.
감사합니다.
안녕하세요 성준님 좋은 리뷰 감사합니다.
기존 CLIP 모델은 텍스트를 처리할 때 최대 77개의 토큰을 입력으로 받을 수 있는데, long caption 같은 경우에는 어떻게 처리하는지 궁금합니다.
감사합니다.
안녕하세요 정의철 연구원님 좋은 댓글 감사합니다.
좋은 지적입니다. 제가 논문을 리뷰하며 다루지는 않은 내용이지만, 저자는 기존 CLIP의 한계로 77개의 토큰만을 받기에 long-text에 대응할 수 없다는 점을 지적하고 있습니다. 저자는 이를 해결하기 위해 최대 토큰 수를 248개로 늘려서 사용하였으며, 늘리는 방법으로 선형 보간법(linear interpolation)을 사용했습니다.
감사합니다.
안녕하세요 박성준 연구원님
저도 해당 논문을 이번주에 읽으려고 눈독 들였었는데, 리뷰해주셔서 더 자세히 읽은것 같습니다.
리뷰 읽다 궁금한 내용들 아래 적어두겠습니다!
Q1. (2-stage 학습 관련) FG-CLIP의 2단계 Regional Contrastive Learning은 FgGRN 데이터셋을 기반으로 진행되었는데, 혹시 다른 grounding 데이터셋으로 대체하여 학습했을 때도 유사한 성능 향상을 보이나요? FgGRN이 성능 향상에 중요한 역할을 하는지, 아니면 이런 학습 기법이 다른 데이터셋에서도 동작하는 일반적인 효과를 가지는지도 궁금해서요
Q2. (Long-caption 품질 관련) 1단계 학습에서 활용된 Long Caption의 경우, LLM으로 생성한 문장이라면 중간중간 오류나 부정확한 정보가 포함될 가능성이 문장이 길다보니 더 클 것 같습니다. 이런 noisy caption에 대한 필터링이나 후처리 과정이 있었는지, 혹은 데이터 품질을 보장하기 위해 어떠한 기준이 있었는지 궁금합니다.
Q3. (본문 Global Contrastive Learning 중) 1단계 Global Contrastive Learning에서 “긴 텍스트와 짧은 텍스트를 동시에 활용”했다고 언급하셨는데, 이는 이미지 하나에 대해 여러 개의 텍스트(long + short)가 각각 positive pair로 사용되었다는 의미인가요?
Q4. (본문 Regional Contrastive Learning 중 데이터셋 구축 관) FG-CLIP의 2단계 학습에서 이미지 영역과 해당 영역을 설명하는 일부 문장을 매칭한다고 하셨는데, 이때 ‘일부 문장’을 어떻게 추출했는지가 궁금해져서요. 리뷰에 따르면 SpaCy로 문장을 분해하고, YOLO-World를 통해 해당 구문에 대응하는 이미지 영역을 검출했다고 하셨는데요, 이 문장-영역 매핑 과정은 자동화된 것인지, 아니면 사람의 수작업 annotation이나 검수 과정이 일부 포함된 것인지 구체적인 설명이 궁금합니다.
Q5. (실험 세팅 관련) 실험 결과(Table 1 기준)를 보면 FG-CLIP의 fine-grained 성능이 기존 대비 매우 크게 향상되었는데, FG-CLIP은 scratch부터 학습한 것인지, 아니면 기존 CLIP 가중치를 초기화로 활용한 후 파인튜닝한 것인지 궁금합니다. 당연하겠지만 scatch 겠죠?
안녕하세요 홍주영 연구원님 좋은 댓글 감사합니다. 도움이 되셨기를 바랍니다.
1. 저자는 2단계 Regional Contrastive Learning에서 기존 데이터셋을 enhancing하는 것을 contribution으로 설명합니다. 기존의 데이터셋에 detailed recaptioning을 하는 것 자체를 방법론으로 설명하다보니 다른 grounding 데이터셋과의 성능 비교는 존재하지 않습니다. 기존 CLIP과의 차이를 생각했을 때에 FgGRN이 꽤 중요한 역할을 수행하는 것 같습니다.
2. 저자는 긴 캡션의 퀄리티를 위해 세미콜론(;), 콤마(,) 등의 심볼들을 삭제했다고 합니다. 3000개 텍스트의 퀄리티를 검사했으며, 오직 1.1%만이 노이즈였다고 말하고 있으며, 그걸 통해서 저자가 제안하는 데이터셋의 퀄리티가 충분하다고 설명하고 있습니다. 심볼 삭제? 외의 추가적인 후처리 혹은 기준은 없었던 것 같습니다.
3. long과 short 모두 positive로 학습합니다.
4. 문장-영역 매핑 과정은 모두 사람의 수작업 없이 자동화(?)되어 돌아갑니다. 문장은 구성요소로 분해하고, 이미지는 검출기를 통해 객체를 추출해, 그 객체에 해당하는 구성요소를 매칭시켜서 학습하는 방법으로 검수과정도 딱히 없이 학습했습니다. 대규모 데이터를 다뤄야하기에 사람의 간섭은 최소화하고 자동으로 진행한 것 같습니다.
5. 가중치를 불러왔다는 언급이 없어서 scratch라고 생각했는데 공개된 코드를 보니 CLIP의 가중치로 초기화를 한 후에 학습하네요. finetuning 후 성능인 것 같습니다.
감사합니다.