안녕하세요 이번에 첫번째 X-review를 작성하게된 안우현 이라고합니다.
제가 오늘 첫번재로 가져온 논문은 2024년 3월 CVPR에 게재된 Open Vocabulary Object Detection 분야의 최신 연구라고 볼 수 있는 YOLO-World라는 논문입니다. YOLO-World라는 친구는 작년 캡스톤을 준비하면서 ovod 모델을 직접 보드에 올려서 어떠한 로봇과 통신하는 그러한 프로젝트를 할 때 사용했던 모델입니다.
그때의 기억을 잠깐 떠올려보면,
사실 프로젝트 초기에는 OVOD 모델로 Grounding DINO를 먼저 사용했었습니다. 하지만 문제는 해당 모델을 Jetson Nano 보드에 올려야 했다는 점이었습니다. 그래서 NVIDIA에서 제공하는 TAO Toolkit을 사용해서 Grounding DINO를 경량화하려고 시도를 했었습니다. 한 1-2주가량 시간을 투자해서 공부하고 해당 모델을 ONNX로 변환하고, TensorRT 엔진으로 최적화까지 진행을 하였는데 결국 보드에 모델을 올리는 것은 실패를 했습니다… 간신히 최적화를 하였던 grounding DINO모델을 보드가 아닌 2080ti gpu에서 정성적으로 테스트를 했을 때에 프레임이 너무 끊겼고 실시간성 확보는 어려울 것 같다고 생각해서 결국 1-2주의 투자한 시간을 버리고 원점으로 돌아가기로 했었습니다.
이런 시행착오 끝에 결국 상대적으로 가벼운 YOLO-World를 경량화 해보자라는 방향으로 틀게 되었습니다. 맨 처음에는 테스트로 모델을 최적화를 하지 않고 그냥 보드에서 올려보았는데, 너무나 빠르게 잘 객체를 탐지를 하는 모습을 보고 놀랐던 기억이 있습니다. 게다가 1280해상도를 처리하는 yolo-world의 Large 모델까지도 별다른 최적화 없이 정말 빠르게 객체탐지를 잘 하는 모습을 보였습니다. 그 때 느꼈던 것은 YOLO-World가 OVOD 모델인데도 불구하고 정말 정말 가벼운 모델이구나! 라는 것이 었습니다. 그리고 그 때 당시에는 단순히 모델을 가져다 쓰는데에 급급해서 해당 모델의 동작 메커니즘도 모른 상태였기 때문에 언젠가는 해당 논문을 읽어봐야겠다라는 다짐을 했는데, 우연치 않게(?) 생각보다 빨리 해당 논문을 읽게 됐습니다. 그 때의 경험을 가지고 해당 논문을 읽게 되니 최신 논문인데도 불구하고 거부감이 없이 읽었던 것 같습니다.
서두가 너무 너무 길었는데, 다시 돌아와서
YOLO world가 다른 모델과 비교해서 왜 가볍고 실시간성 확보가 가능했는지를 중점적으로 보시면 될 것 같습니다.
Introduction
해당 파트에서 저자는 YOLO-World의 등장 배경에 대해서 설명을 합니다.

먼저 전통적인 Object Detection(객체 탐지) 모델은 보통 COCO처럼 미리 정의된 클래스들로 학습됩니다. 예를 들어 OD모델을 80개의 클래스로 학습을 했다면, 추론 시 범주 내에 속한 객체들에 대해서만 탐지가 가능하고 학습 시 사용되지 않은 즉, fixed vocabulary에 포함되지 않은 객체는 인식할 수 없다는 단점이 존재합니다. 이러한 전통적인 Object Detector의 단점을 극복하고자 등장한 것이 Open-Vocabulary object Detection (OVOD)라고 볼 수 있습니다.
OVOD는 OD와 다르게 추론 시점에 fixed vocabulary에 얽매이지 않고, 유저가 원하는 novel class까지 탐지하는 것을 목표로 합니다. 즉, 처음보는 물체에 대해서도 잘 탐지하는 것(제로샷 성능 향상)을 목표로 하는 것입니다.
먼저 간단하게 OVOD가 제로샷 성능을 낼 수 있는지에 대해 간단하게 설명을 드리면 일반적인 OD처럼 각 클래스를 직접 학습하는게 아니라 이미지와 텍스트가 공통의 임베딩 공간에서 의미적으로 가까워지도록 학습합니다. 즉, ‘강아지’라는 단어와 강아지와 관련된 이미지가 같은 공간에서 가까운 위치를 갖도록 학습한다고 생각하시면 될 것 같습니다. 게다가 이미지와 텍스트가 공통의 임베딩 공간에 매핑하는 과정에서 대규모의 데이터로 학습된 모델을 사용하기 때문에 제로샷 예측이 가능하게 됩니다.
초기 OVOD 연구들은 대량의 데이터로 잘 사전학습된 텍스트 인코더(BERT 등)에서 얻은 언어 지식을 활용해 detector를 학습시키는 방식(OVR-CNN)이었습니다. 하지만 학습 데이터의 부족과 어휘 다양성의 문제로 인해 학습 시 여전히 일반화 성능에 대해서는 한계가 있었다고 저자는 언급합니다. 대표적인 예로 OV-COCO라는 Open-Vocabulary 버전의 OV COCO 데이터셋이 있는데, 여기서 다루는 클래스 수가 겨우 48개밖에 안 된다고 합니다.
후속 연구에서는 객체 탐지 학습을 영역 수준(region-level)에서 사전학습을 진행하도록 재구성하는 연구가 진행되었고 또 나중에는 ViLD, GLIP, Grounding DINO와 같은 모델들은 1500개 이상의 클래스와 large scale의 이미지-텍스트 쌍을 활용할 뿐만아니라 그들만의 추가적인 방법론을 가지고 더 강력한 제로샷 성능을 갖추게 되었습니다.
하지만 저자는 위와 같이 지금까지 연구된 강력한 제로샷 성능을 가지는 OVOD 모델에 대해서 2가지 문제점을 언급을 합니다.
- 높은 연산 부담
- 엣지 디바이스에서의 배포
위와 같은 문제점을 해결하고 real-time에서 좋은 성능을 내고자 YOLO-World가 등장했다고 보시면 될 것 같습니다. 위에 첨부한 Figure 2 (c) 파트 설명부분에 논문에서 말하는 YOLO World가 real-time에서 좋은 성능이 나타날 수 있는 핵심이 나타나있는데요.
일단 첫 번째로 YOLO-World는 GLIP, Grounding DINO, DetCLIP들과 달리 이미지를 input으로 받아 피쳐를 뽑아내는 visual backbone을 transformer 기반이 아니라 자기들이 만든 YOLOv8에서 사용된 Darknet이라는 백본을 사용하였습니다. 당연히 visual encoder로써 무거운 transformer기반의 모델을 사용하지 않는 다는 것은 엄청난 파라미터 수를 줄일 수 있다는 메리트가 있습니다. 이러한 부분이 기존 OVOD 모델에 비해 YOLO-World가 가벼울 수 있는 원인으로 작용할 수 있게되는 것 같습니다.
두 번째로는 효율적인 inference에 있어 prompt-then-detect라는 패러다임을 제시합니다. 이는 유저가 탐지하고자 하는 객체에 대한 텍스트 프롬프트를 사전정의하여 text-encoder에 태움으로써 해당 임베딩 결과들을 미리가지고 있게 됩니다. (이렇게 사전 정의한 텍스트 프롬프트들을 offline vocabulary라고 합니다. )그러고 나서 이를 가지고 있다고 실제 inference 과정에서 text-encoder의 연산없이 이 임베딩 벡터들을 바로 사용하여 객체를 탐지하는 방식이라고 볼 수 있습니다. text-encoder의 불필요한 연산마저 추론과정에서 없애버리겠다 라는 것입니다.
세 번째로는 re-parameterize라는 개념을 이야기하는데요, 앞서 구한 텍스트 임베딩 벡터들을 가중치로 사용할 수 있게끔 파라미터화 하는 방식입니다(파인튜닝 과정에서는 이를 학습 또한 가능 함.). YOLO-World는 이 re-parameterize라는 방식을 통해 추론 과정에서 어떤 복잡한 모델의 구조를 단순한 구조로 치환 가능하게 만들어서 연산부담을 줄이고자 합니다.
결과적으로는 YOLO-World는 아래와 같은 성능을 나타냅니다.
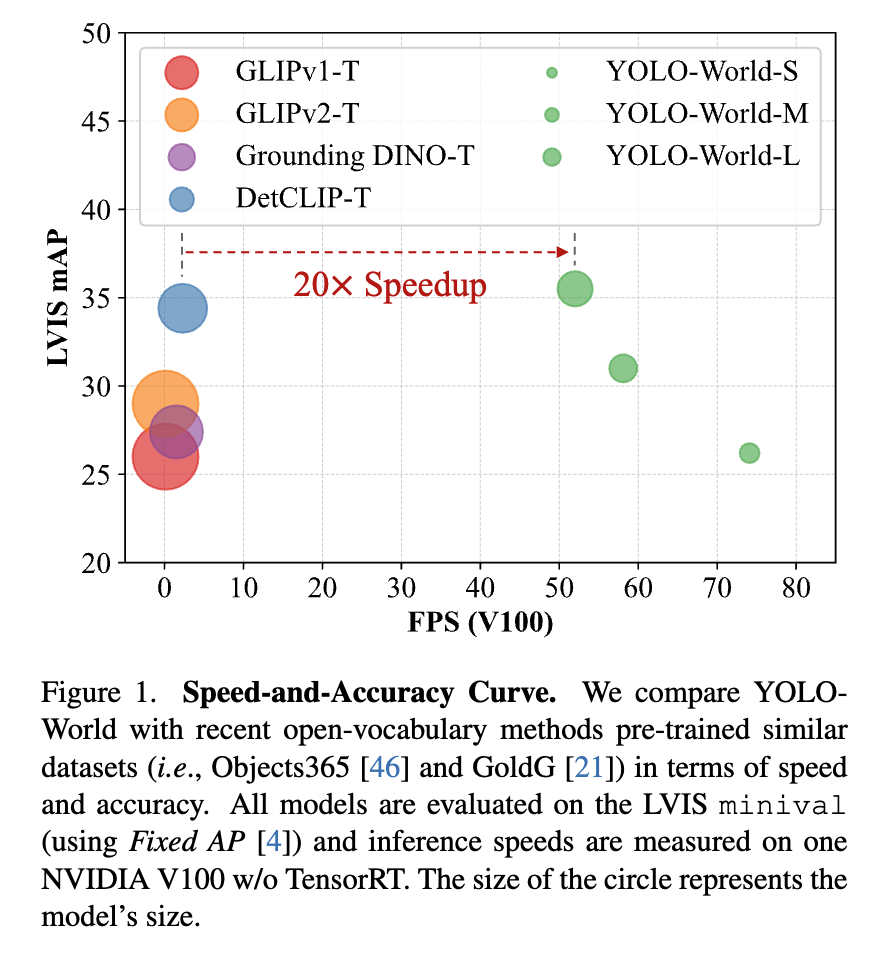
결과적으로, YOLO-World는 GLIP, Grounding DINO, DetCLIP 등 기존의 대표적인 OVD 모델들과 비교해 20배 이상 빠른 FPS 성능을 보여줍니다. 모델 크기 또한 훨씬 작아 엣지 디바이스 배포 측면에서도 뛰어나며 게다가 이렇게 가벼운 구조임에도 불구하고 성능 면에서도 가장 좋은 결과를 기록한 것을 확인할 수 있습니다.
YOLO-World가 위와 같이 뛰어난 성능을 나타낼 수 있었는지 모델 구조를 파헤쳐가면서 리뷰를 진행하도록 하겠습니다.
Method
먼저 pre-train과정에 대해서 하나하나 설명하도록 하겠습니다.
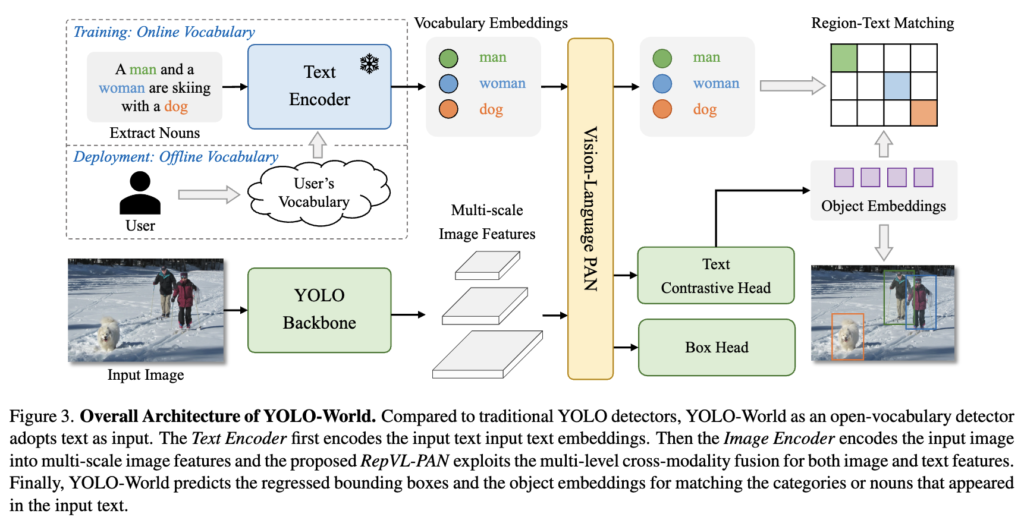
Text Encoder
기본적으로 YOLO-World에서 text를 처리하는 Text Encoder로 4억쌍의 대규모 데이터로 사전학습된 CLIP의 text-encoder를 사용합니다. 이는 freeze하여 사용하고 해당 인코더를 거치게 되면 각 토큰 대해서 768차원의 임베딩 벡터가 생성되게 됩니다.
YOLO Backbone
그리고 input image는 앞서 설명드린 것 처럼 YOLOv8의 DarkNet을 백본으로 해당 네트워크를 통과하여 3개의 Multi-scale image Features를 뽑아내게 됩니다.
혹시 궁금하신 분들이 있을까봐 YOLOv8 backbone 이미지 첨부하겠습니다.
RepVL-PAN
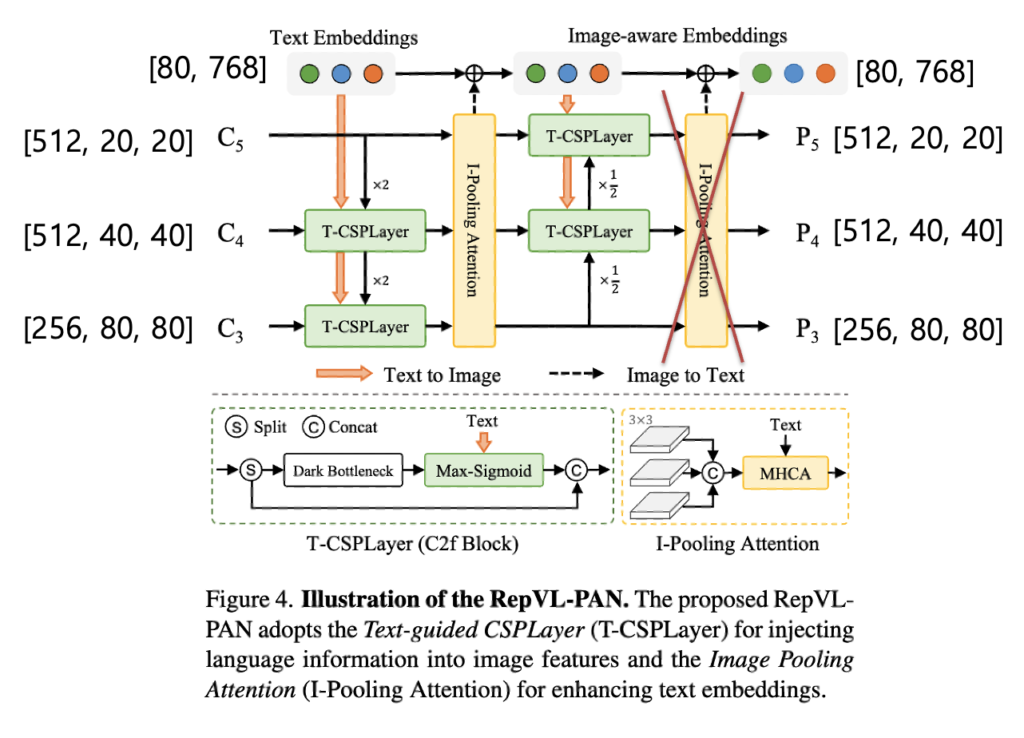
위는 RepVL-PAN의 구조입니다. 큰 틀에서 보면 먼저 backnone을 타고 나오는 피쳐맵들과 text-embeddings를 입력으로 받아서 이미지 특징과 텍스트 특징 간 서로가 서로에게 중요한 정보를 반영하게 하도록하는 과정을 담당한다고 보시면 될 것 같습니다. 기존 PAN에서 사용한 top-down 및 bottom-up 경로를 따르고 multi scale feature maps {C3, C4, C5}을 입력으로 받아 중요한 텍스트 정보가 반영된 multi scale feature map {P3, P4, P5}을 출력으로 내뱉게 됩니다. 그리고 텍스트에 이미지 정보가 반영된 Image-aware Embeddings가 출력으로 나오게 되는 것을 보실 수 있습니다. 각각 출력이 어떻게 나오는지 조금 더 자세하게 설명을 드리겠습니다.
위에서 크게 T-CSPLayer와 I-Pooling Attention 2가지 모듈을 확인하실 수 있습니다.
T-CSPLayer
CSPLayer는 Resnet의 잔차연결과 유사한 개념을 가진 네트워크로 yolov4부터 도입한 네트워크입니다. 해당 네트워크에 추가적으로 text-embeddings를 입력으로 받아 어떠한 이미지 피쳐맵과 유사도를 계산하여 이미지 피쳐에 텍스트 정보를 반영하는 모듈(Max-Sigmoid)이 추가된 것이 바로 T-CSP Layer입니다.
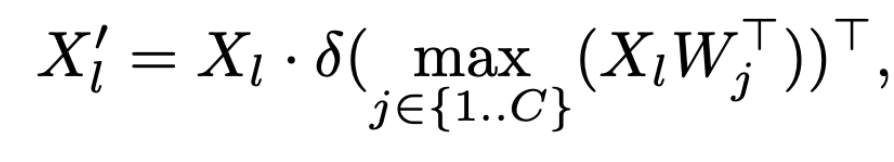
Max-Sigmoid 모듈을 나타내는 수식인데, 위 수식이 결국 의미하는 것은 X(이미지 피쳐)와 W(텍스트 임베딩 벡터들)간의 유사도를 계산하여 가장 유사도가 높은 값을 이미지 피쳐에 반영하겠다는 의미입니다.
T-CSPLayer = T → I 모듈
I-Pooling Attention
각 3개의 다중 스케일 이미지 특징에 대해 3×3 맥스 풀링을 수행하여 총 27개의 3×3 패치 토큰 \tilde{X} \in \mathbb{R}^{27 \times D}를 추출하고, 이를 사용해 텍스트 임베딩을 다음과 같이 업데이트합니다.
W′ = W + MultiHead-Attention(W, \tilde{X}, \tilde{X})W, \tilde{X}, \tilde{X} 가 각각 Query Key Value로 들어가 MultiHead-Attention 연산이 수행됨으로써 텍스트 임베딩에는 중요한 이미지 정보가 반영되게 됩니다.
I-Pooling Attention = I → T 모듈
Text Contrasitive Head
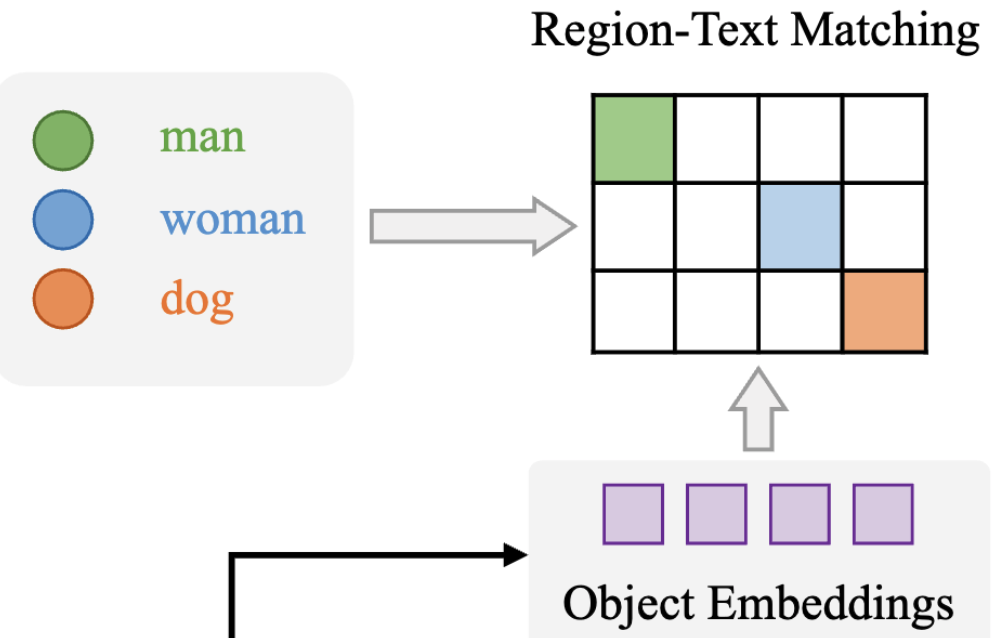
text contrastive head는 앞서 구한 P5,P4,P3를 768차원의 임베딩 벡터로 만들어주고 만든 객체 임베딩과 텍스트 임베딩 간의 유사도 s_{k,j}를 구하게 됩니다. 유사도는 아래와 같은 식을 통해 구해지게 됩니다.
s_k,j = α · L2-Norm(e_k) · L2-Norm(w_j)^⊤ + βα는 학습 가능한 스케일링 계수, β는 쉬프팅 계수이며, 둘 다 영역-텍스트 학습의 안정성을 높이기 위해 필요합니다. 따라서 해당 유사도를 바탕으로 contrasitive loss(Loss_cls)를 구하게 됩니다.
Box Head
YOLO-World의 Box Head는 단순히 왼쪽, 오른쪽, 위, 아래의 박스 경계를 숫자 하나로 예측하는 대신, 각 방향(동,서,남,북)에 대해 박스 경계가 위치할 확률 분포를 예측합니다.
이게 무슨 말이냐면, 예를 들어 피처맵 크기가 40×40이라면 각 셀은 입력 이미지의 일정 영역을 대표합니다. 이 셀 하나에 대해서 모델은 “이 셀에서 오른쪽으로 몇 칸 떨어진 위치에 박스의 경계가 있을까?” 같은 질문에 대해, 단순히 ‘4칸’이라고 예측하는 게 아니라 4칸일 확률이 높다, 5칸일 확률은 그보다 낮다… 이런 식으로 확률 분포를 만들어낸다고 보시면 됩니다.
예를 들어 만약 GT(정답)의 오른쪽 경계가 4.2칸 떨어진 곳에 있다면, 모델은 4칸과 5칸 사이의 확률을 높게 예측해야 이상적인 출력입니다.
실제로는 이걸 (0, 1, 2, …, 15) 같은 이산적인 거리 후보(16개의 후보 = 하이퍼 파라미터)에 대해 softmax로 확률을 출력한 다음, 이 분포 전체와 GT 값으로부터 어떠힌 알고리즘으로 생성한 가우시안 같은 GT 분포를 Cross Entropy Loss로 비교합니다.
세미나때 해당 GT를 어떻게 구하냐라고 질문이 있었는데, 그 때 제가 설명을 너무 못해서 여기서 좀더 자세하게 설명을 드리면, 각 셀에 대해서는 이미 GT가 할당이 되어있을 것입니다. 그런데 각 셀에 할당된 GT는 원래부터 이런 확률 분포 형태로 되어 있는 게 아니라, 단순히 박스의 좌표값 4개(left, right, top, bottom)만 주어지게 됩니다.
예를 들어 어떤 셀에서 북쪽 방향(top)으로 박스 경계가 4.2칸 떨어져 있다고 해봅시다. 이걸 Box Head에서는 (0, 1, 2, …, 15)처럼 이산적인 거리 후보 중 하나로 변환해줘야 합니다. 만약 단순하게 생각하면, 4.2칸이라면 5에 가장 가까우니까 5만 1, 나머지는 전부 0인 one-hot 벡터로 만들 수도 있습니다. 하지만 실제로는 그렇게 하지 않고, 4.2칸이라는 연속적인 값에 가장 가까운 이산값들(예: 4와 5)에 대해 부드러운 확률 분포를 만들어줍니다. 즉, GT는 4.2지만 이걸 표현하기 위해서 4에는 예를 들어 0.8, 5에는 0.2 이런 식으로 가우시안 형태의 soft label을 만들어주는 거라고 생각하시면 될 것 같습니다. 이렇게 만들어진 확률 분포가 바로 Box Head가 예측한 분포와 비교하는 GT 분포가 됩니다. 그리고 이 두 분포 사이의 차이를 Cross Entropy 기반의 DFLoss (Distribution Focal Loss)를 구하게 되는 것입니다. 요약하자면, GT는 처음에는 그냥 숫자 4개짜리 박스 좌표이고, 각 셀에 GT를 할당한 후, 이를 방향별 거리로 변환 한 후 방향별 거리 값(예: 4.2)을 soft label 형태의 분포로 바꾼 후 (예: 4: 0.8, 5: 0.2)이 soft 분포를 GT로 사용해서 DFLoss를 계산을 합니다.
위 방식은 단순히 4개의 숫자를 회귀하는 것보다 훨씬 더 정밀하고 안정적으로 학습이 가능합니다. 특히 박스 경계가 sub-pixel 단위의 정확도가 필요할 때(예: 4.2칸처럼 정수가 아닐 때), 분포를 통한 soft supervision이 훨씬 부드럽고 정교한 학습을 하게끔 한다고 합니다. 이게 바로 DFLoss (Distribution Focal Loss)가 YOLO 시리즈 등에서 최근 많이 쓰이는 이유라고 볼 수 있습니다.
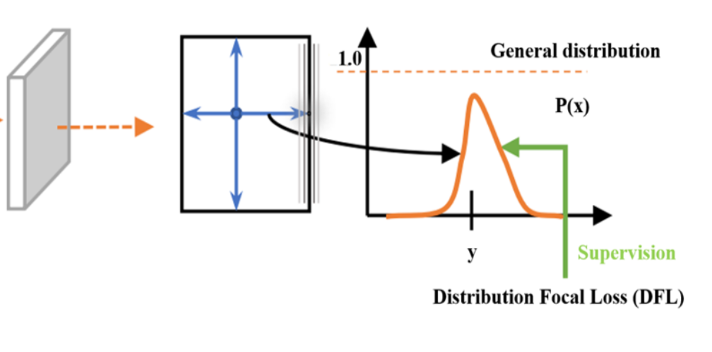
위 그림으로 아까 예시를 다시한번 설명드리면 X축은 거리 (0~15칸), Y축은 확률,GT는 4.2 → 4와 5 사이에 뾰족한 분포를 보이고 모델은 저런 분포를 예측하도록 학습이 됩니다.
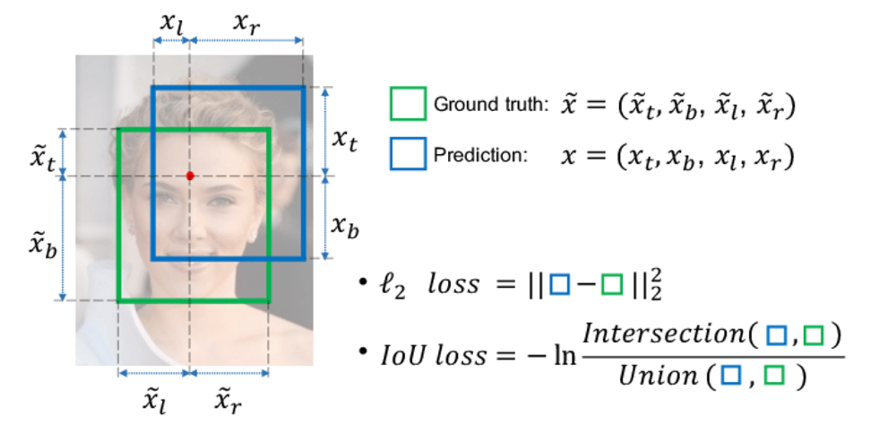
그리고 예측한 박스와 GT박스간 IOU Loss도 학습에 사용되게 됩니다.
Loss
따라서 최종 Loss는 아래와 같이 구성됩니다.
L(I) = L_{con} + \lambda_I \cdot (L_{iou} + L_{dfl})여기서 λ_I는 입력 이미지 I가 탐지 또는 그라운딩 데이터에서 왔을 경우 1, 이미지-텍스트 데이터에서 왔을 경우 0으로 설정됩니다. 이미지-텍스트 데이터셋은 바운딩 박스 품질이 낮기 때문에, 정확한 바운딩 박스를 가진 샘플에 대해서만 회귀 손실을 계산하기 위해서 설정했다고 보시면 될 것 같습니다.
지금까지는 YOLO-World의 YOLO-Detector의 pre-train 과정을 살펴 보았는데요.
지금부터는 맨 처음 언급했던 prompt-then-detect 와 re-parameterize에 대해서 좀 더 자세하게 다뤄보겠습니다.
Prompt-then-detect / Re-parameterize
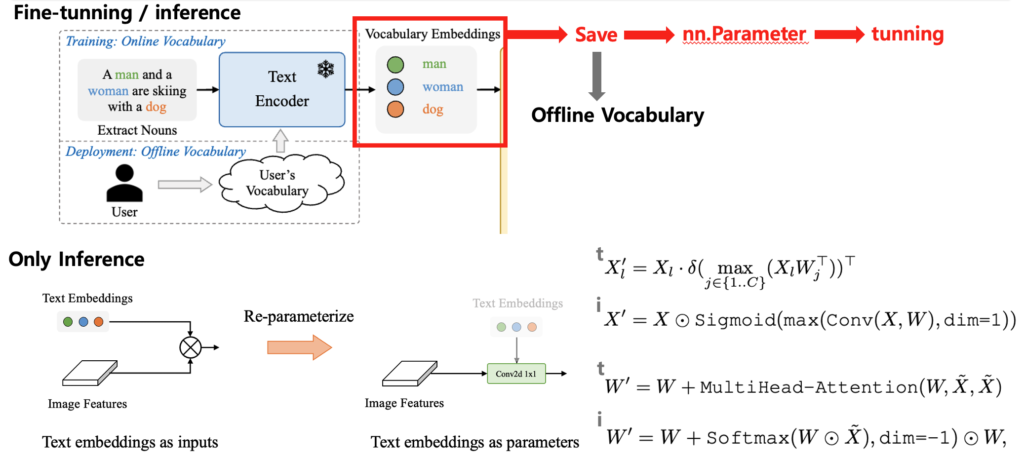
Prompt-then-detect
일단 먼저 “A man and a woman are skiing with a dog”같은 문장에서 핵심 명사(man, woman, dog)들을 추출합니다. 그런 다음 Text Encoder를 사용해 이 단어들의 텍스트 임베딩을 생성합니다. 생성된 임베딩은 Vocabulary Embedding으로 저장되고 이는 nn.Parameter라는 친구로 실제로 학습가능한 파라미터로 변환이되어 모델 내부의 어떠한 가중치 값으로 통합됩니다. 만약 어떤 도메인에 최적화 시키고자 프롬프트 튜닝을 한다면 해당 임베딩 파라미터를 학습시 업데이트 시키면 됩니다. 이렇게 저장된 임베딩은 추론 시 Text Encoder 없이도 바로 사용 가능합니다. 위 처럼 유저가 원하는 텍스트 프롬프트를 미리 사전정의 해놓고 가지고 있는 것을 Offline Vocabulary 라고 합니다. 결국 prompt 먼저 정의해서 text embeddings를 미리 구해 놓고 text encoder 없이 detect를 한다라고 이해하시면 좋을 것 같습니다.
Re-parameterize
Re-parameterize는 앞서 만든 offline vocabulary를 활용해서 “텍스트 임베딩을 online vocabulary 입력으로 받는 방식” -> “텍스트 임베딩을 파라미터로 통합하는 방식”으로 전환하는 과정에서 위에 보이시는 그림과 같이 어떠한 복잡한 attention의 특정 연산의 구조를 Conv2d 1×1 연산 이나 단순한 요소별 곱 형태로 바꾸는 방식이라고 이해하시면 될 것 같습니다. 논문에서는 해당 내용에 대해서 엄청 깊이 있게 다루지 않아서 사실 해당 방식의 동작 메커니즘에 대해서는 아직 이해가 부족한 상태입니다.
그래도 코드를 돌려본것 을 정리하자면 attention 연산전체를 conv1x1로 바꾼다기보다는 attention 연산내 특정 부분의 네트워크에 대해서만 conv1x1로 바꾸는 것 같습니다. 결과적으로 inference 과정에는 가중치 값들은 고정 되어있고, 또한 text embeddings 벡터 또한 이미 offline vocabulary로 고정되어있기 때문에 가능 한 것 같습니다.

따라서 실제 inference 과정에서 모델이 객체를 탐지하기 전, Max-Sigmoid 블록 같은 경우에 실제로 위의 guide_fc라는 레이어의 가중치를 미리 뽑아와서 기존에 가지고 있던 text_embeds와 guide_fc의 가중치로 아래와 같은 방법으로 guide 계산을 진행을 합니다. 그리고 해당 guide 값을 기존의 attn_block을 지우고 새로운 Conv1x1의 가중치로써 사용하게 됩니다. (추론 과정에서는 저 guide_fc레이어를 통과시키지 않음. 지워진 상태)

정확히 이러한 동작방식이 어떤 것을 의미하는 건지는 모르겠습니다. 혹시나 해당 과정이 궁금하신 분들이 있을까봐 코드를 첨부해드립니다.
Experiments
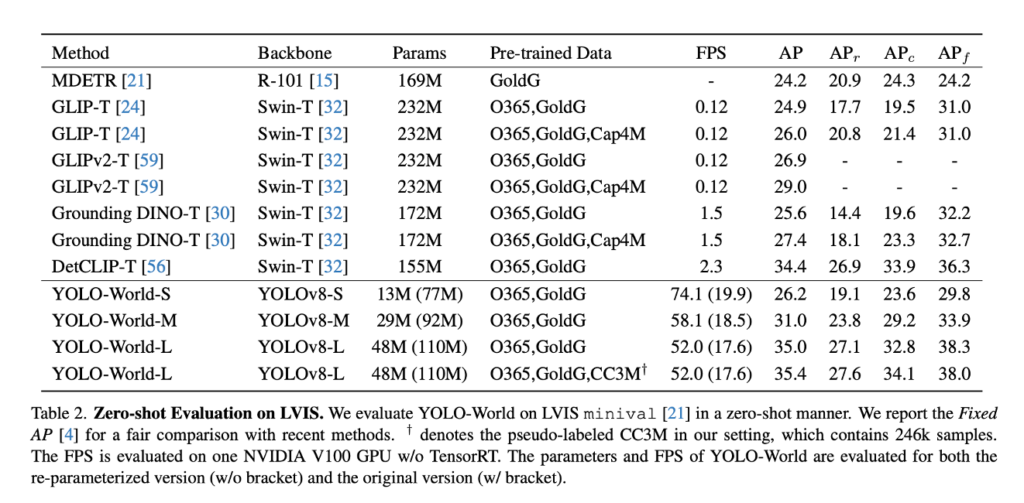
Table 2는 LVIS minival 데이터셋을 기반으로 다양한 Open-Vocabulary Detection 모델들의 여러 성능을 비교한 결과입니다. 특히 여기서는 정확도(AP)와 함께 실시간성(FPS) 그리고 모델의 Params까지 모두 고려하고 있기 때문에 YOLO-World가 기존 모델들 대비 어떤 강점을 갖는지 알 수 있습니다. YOLO-World-S는 단 13M 파라미터만으로도 동급 모델 대비 유의미한 성능을 보여줄 뿐더러 FPS또한 압도적인 것을 확인 할 수 있습니다. 그리고 사실 위 테이블에서 params,FPS,AP같은 경우는 맨 처음 introduction에 첨부했던 결과 표로 쉽게 비교가능합니다.
다만 위 표에서 추가적으로 확인가능 한 것은 YOLO-World 내에서 re-parameterize를 적용했냐 안했느냐에 따른 성능 비교도 확인할 수 있는데요. re-parameterize를 적용을 하면 re-parameterize를 적용하지 않았을 때 보다 params가 평균적으로 63M 정도 줄어드는 것을 확인할 수 있는데요 transformer기반의 visual encoder를 사용하지 않아서 줄어든 params와 비교해서도 re-parameterize가 굉장히 효과적인 성능을 보였다고 볼 수 있을 것 같습니다.
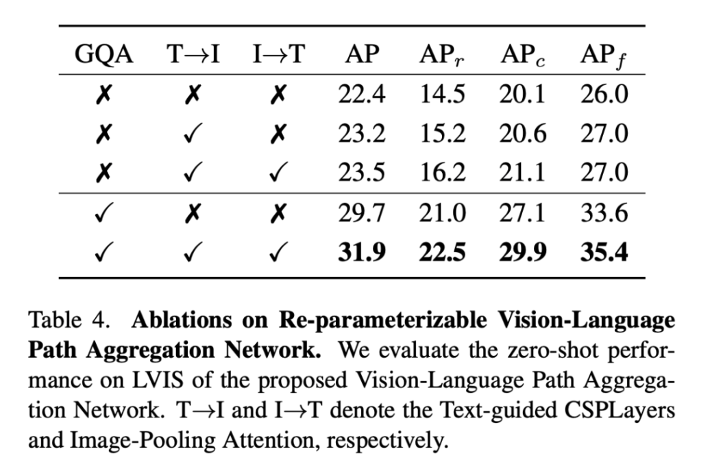
위에서 T→ I와 I→ T는 각각 t-csp layer와 I-pooling Attention 모듈을 의미하는데 두 모달리티간 정보연결을 하는 것이 효과적이다라는 것을 보여주는 것 같습니다.
하지만 실제 YOLO world에서는 I→T를 사용하지 않고 있습니다.
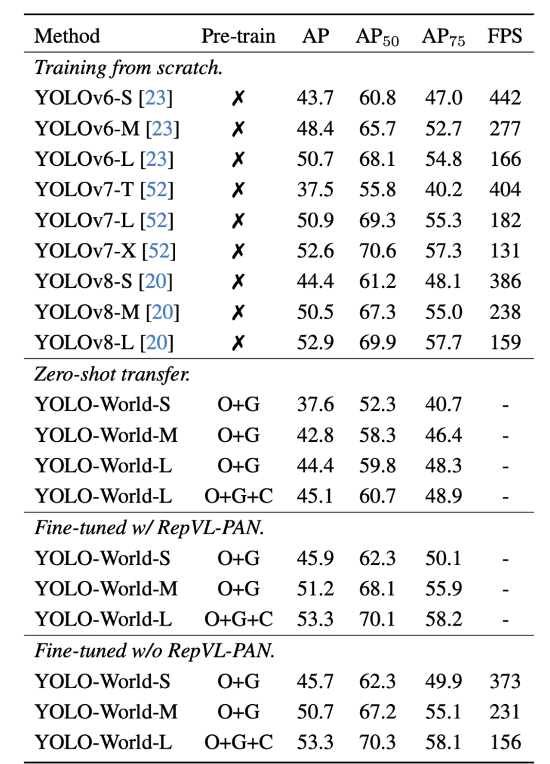
위 는 COCO dataset으로 finetunning하고 COCO로 평가한 테이블표인데요.
Training from scratch 같은 경우는 기존 YOLO 시리즈는 pre-train 없이도 높은 성능과 빠른 속도를 동시에 확보할 수 있는 strong baseline이다라는 것을 보여줌과 동시에 이를 baseline으로 삼아 YOLO-World의 성능을 비교해볼 수 있도록 한 거 같습니다.
zero shot transfer같은 경우 해당 결과를 보면 학습을 전혀 하지 않아도, 사전학습된 텍스트-이미지 지식을 활용하면 기존 YOLO 소형 모델 수준의 성능을 바로 달성 가능하다는 것을 보여주는 것 같습니다.
그리고 저자는 COCO 데이터셋에서 YOLO-World를 finetunning할 때에는, vocabulary size 가 작다는 점을 고려하여 제안된 RepVL-PAN 모듈을 제거하고, 추론 속도를 더욱 향상시켰다라고 언급을 하였는데, 이에 대한 결과도 테이블에서 확인 할 수 있습니다. 결국에 앞선 table 4를 보면 RepVL-PAN은 확실히 멀티모달 강화에 효과적이지만, 꼭 사용하지 않아도 성능이 매우 높기 때문에 조건에 따라 구조 선택이 가능하다는 것을 보여주는 것 같습니다.
감사합니다.
안녕하세요, 안우현 연구원님. 좋은 리뷰 감사합니다. 서문 재밌게 읽었습니다. 논문의 내용보다는 OVOD모델을 jetson에 포팅한 부분에 더 관심이 가는데요, 제가 pytorch 코드를 onnx 코드로 추출하거나 엣지디바이스에 올리는 작업에 대해 잘 아는 것은 아니지만, 복잡하게 작성되어있는 pytorch 코드의 경우 export할때 변환이 잘 되지 않는 문제가 있던 것으로 기억합니다. 혹시 이런 문제는 없었는지, 있었다면 어떻게 해결하셨었는지, 또 pytorch로 작성된 모델들을 jetson과 같은 edge device에 올려서 동작시키는 과정이 어떻게 이루어지는지 설명해주시면 감사하겠습니다.
또, offline vocabulary는 임베딩시켜놓은 벡터 정보들을 메모리같은곳에 저장해두고 추론 시 비교하는 것인지 궁금합니다. 이에 대해서도 답변 주시면 감사하겠습니다.
감사합니다.
안녕하세요 재연님, 답글 감사합니다.
1. 엣지디바이스에 파이토치 모델을 올리는 과정 및 onnx 변환 시 이슈
기억을 되살려봐서 답변을 드리면, onnx로 추출할 때 2가지 방법을 시도해봤었습니다. 파이토치 프레임워크에서 제공하는 torch.onnx.export()를 통해서 해당 모델을 onnx 포맷으로 변환하고자 했었지만, 일부 연산을 onnx에서 지원하지 않았던 것 같습니다. 이후에는 NVIDIA에서 제공하는 TAO toolkit 을 활용하여 변환을 시도하였습니다. Grounding DINO라는 모델을 onnx로 변환한 후 trt 엔진까지 효율적으로 변환가능 할 수 있게 튜토리얼에 도큐먼트가 찬절하게 설명이 되어있어서 이를 차근 차근 따라해보았습니다.(https://docs.nvidia.com/tao/tao-toolkit/index.html). 하지만 trt engine을 보드에 올리는 과정에서 모델을 export한 환경과 보드의 환경 충돌(CUDA 12. vs CUDA 11.X) 이러한 문제로 인해 보드에 올리지는 못했습니다.그래서 YOLO-World를 사용하게 되었고, 해당 모델은 별도의 최적화 없이 환경 설정만 잘 해주면 별 큰 문제 없이 보드에서 잘 돌아갔습니다. 두가지 torch.onnx.export()로 만든onnx와 NVIDIA TAO toolkit으로 만든 onnx는 형식은 같지만 내부 구조나 최적화 정도가 다르다고 합니다.
2. offline vocabulary는 임베딩시켜놓은 벡터 정보들을 메모리같은곳에 저장해두고 추론 시 비교하는 것인지 궁금합니다.
네 맞습니다! 사전에 정의된 클래스 텍스트들을 text encoder를 통해 임베딩하여 벡터 형태로 보통 .npy 형식으로 저장됩니다. 그리고 추론 과정에서는 text encoder를 별도로 실행할 필요 없이, 이미 저장된 vocabulary embedding(.npy)을 로드하여 사용합니다.
안녕하세요, 안우현 연구원님. 좋은 리뷰 감사합니다. 한가지 궁금한점이 있어 질문드립니다.
Prompt-then-detect 방식은 inference 전에 offline vocabulary로 text embeddings를 고정한다는 점에서 매우 효율적이지만, 유저가 새로운 프롬프트를 추가하고 싶을 때 얼마나 유연하게 대처할 수 있을지 의문이 듭니다…
안녕하세요 우진님, 좋은 댓글 감사합니다.
YOLO-World는 실시간 성능 확보를 위해 추론 시점에 옵셔널하게 텍스트 인코더를 사용하지 않고, 사전에 계산된 텍스트 임베딩을 이용합니다. 이 구조 덕분에 추론 속도 측면에서 좋은 성능을 올릴 수 는 있지만, 말씀대로 유저가 새로운 프롬프트를 동적으로 추가하는 데는 제한이 있는 것 같습니다. 다만, 텍스트 인코더를 다시 활성화하거나, offline vocabulary를 업데이트하는 방식으로 새로운 프롬프트 추가는 가능합니다.
안녕하세요 우현님, 좋은리뷰 감사합니다.
아주 간단한 질문이 있는데 offline vocabulary를 만들어서 inference 속도를 빠르게 늘렸다는 것은 이해가 됩니다. 다만 offline 으로 미리 텍스트를 입력받는 방식은 다른 모델들도 가능할 것 같은데, Yolo world 에서 inference 과정중 text를 미리 입력받지 않는다면 FPS 가 얼마나 떨어지는지에 대한 내용이 있었는지 궁금합니다.
안녕하세요 인택님 좋은 댓글 감사합니다.
YOLO-World 논문에서는 inference 시 텍스트를 미리 임베딩하여 오프라인 vocabulary를 구성하고, 이를 모델 가중치로 re-parameterize하여 사용하는 것이 속도 향상에 결정적인 기여를 한다라고 언급되어있습니다.
따라서 인택님께서 하신 질문이 단순히 inference시 re-parameterize를 고려하지 않은 상태에서 텍스트를 미리 임베딩하여 오프라인 vocabulary를 구성하지 않는 경우를 물어보시는 거라면 논문에서는 이에 대한 FPS 감소량에 대한 정량적인 수치나 비교결과 실험은 없었습니다. 다만 inference시 텍스트를 미리 임베딩 한 후 이를 모델 가중치로 re-parameterize함으로써 인코딩 과정을 단순한 conv 연산으로 대체했다는 내용에 대한 실험 내용(FPS, params)은 Table2에 언급이 되어있습니다! (size: 110M-> 48M , FPS: 17.6 -> 52 )
감사합니다.
안녕하세요 우현님, 좋은 리뷰 감사합니다!
이번 여름 URP에서 YOLO-World를 가볍게 다루었었는데, 세부적인 구조가 궁금해서 열심히 찾아보았던 기억이 납니다. 그땐 제대로 이해를 못했었는데 이제 우현님의 리뷰 덕분에 좀 더 자세히 알게 된 것 같습니다.
RepVL-PAN에서 실시간성을 위해 re-parameterization을 사용한 것이 흥미로웠는데요, text embedding을 detection head에 통합하는 방식으로 이해했습니다. 그런데 이게 구체적으로 어떻게 동작하는 건지 이해가 잘 되지 않습니다. 조금 더 구체적으로 설명해주실 수 있나요?
감사합니다.