안녕하세요. 이번 리뷰는 로봇 에이전트가 기존에 가지고 있는 skill policy들에 기반하여 LLM을 통해 가이던스를 얻어 적절한 skill 조합을 만들어내고 그것으로부터 로봇의 Long-horizon task 를 해결하는 논문입니다. 참고로 RL 기반의 내용을 담고 있으나, 저는 Long-horizon task의 문제 해결을 위한 접근이 로봇 에이전트가 현재 본인의 스킬들이 무엇인지를 기반으로 조합을 구성해낸다는 관점에서 high-level planning과 task decomposition 쪽을 어떻게 개선할까 고민하는 제 연구 방향에 접목시킬 수 있는 의미를 찾은 것 같아 읽게 되었습니다. 리뷰 시작하겠습니다.
1. Introduction
일반적으로 Robot Learning이라는 태스크는 로봇이 새로운 시나리오를 학습하고 적응할 수 있는 능력을 갖추는 것을 목표로 합니다. 여러 Robot Learning 방식들이 있지만 그 중 강화 학습의 경우는, 물건에 대한 pick&place와 같은 short-horizon 학습에는 탁월하지만, long-horizon 기술을 습득하려면 여러 demonstration 또는 dense한 reward 피드백과 같은 집중된 supervision이 필요합니다.
로봇과 달리 사람의 경우는 훨씬 적은 supervision으로 복잡한 작업을 배울 수 있는데요. 논문에서는 예시를 테니스 배우기로 들었는데, 저는 축구를 좋아하니 축구 배우기로 한번 예시를 들어보겠습니다. 축구를 처음 배우는 사람은 패스, 슛, 트래핑, 리프팅, 드리블 등의 아주 기본기 등을 코치로부터 막 집중적으로 가르침을 받고(dense supervision) 배우기 시작하겠죠. 이 각각의 기본기를 RL 에이전트가 행하는 개별 skill이라고 이해해보겠습니다. 자 이제 관건은 코치의 supervision없이 이 사람이 90분짜리 축구 경기를 뛰기 위해서, 이 기본기들을 바탕으로 이리 저리 활용해먹으면서 90분 경기(Long-horizon task)를 소화하는 연습을 하게 되겠죠? 어떤 상황에선 드리블 이후 패스를 하는 기본기를 활용하고, 어떤 상황에선 볼 트래핑 이후 바로 슛을 때리는 여러 상황을 대면하게 될 것입니다. 이 때 자기가 배운 그 기본기들을 섞어서 결합하면서 90분의 시간을 소화할 수 있는 여러 풍부한 본인만의 축구 기술들이 생겨나게 되는 것이죠.
위 예시처럼 RL agent가 dense한 supervision 없이도 skill들을 연습하고, 이것들의 조합으로 Long-horizon 태스크를 위한 skill로 확장해나갈 수 있을까? 에서 저자들은 motivation을 얻고, BOSS (BOotstrapping your own SkillS)라는 아래의 프레임워크를 만들게 됩니다.
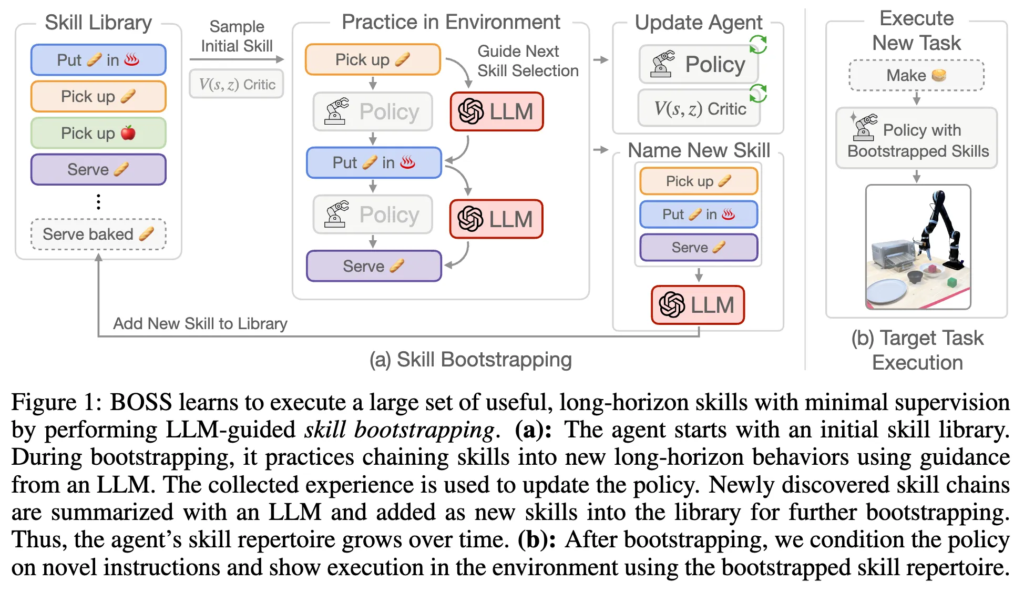
습득한 기본 skill 셋에서 시작하여 BOSS는 skill bootstrapping 단계를 수행하여 기술을 long-horizon action으로 연결하는 연습을 통해 점진적으로 skill 레퍼토리를 확장하는 과정을 취합니다. 즉, 수십 개의 skill 레퍼토리에서 시작하여 추가적인 supervision 없이도 수백 개의 long-horizon task를 수행할 수 있는 generalist 에이전트를 학습시키는 결과를 만들어내는 셈이라고 합니다.
그런데 실제 환경에서의 가장 중요한 관점은 과연 어떤 skill들을 어떻게 연결해서 사용하는 것이 의미 있는가입니다. 예를 들어, 패스없이 자꾸 슛하고 드리블만 계속 하는 게 능사는 아니라는 말이죠.
이에 따라, BOSS는 LLM에 내재된 풍부한 지식을 활용하여 skill chaining을 유도하는 방식을 제안합니다. 지금까지 실행된 skill들의 체인을 입력으로 받아, LLM이 의미 있는 다음 skill들에 대한 확률 분포를 예측하고, 이를 기반으로 다음 skill을 샘플링하는 방식을 취하게 되는데요. 기존의 LLM 기반 접근 방식들과 다른 점은 long-horizon task planning 자체에 LLM을 사용하는 것이 아니라, BOSS는 지도 학습 없이 환경과 상호작용하는 과정(unsupervised interaction)을 통해 스킬들을 어떻게 연결할지 RL로 학습한다는 점에서 좀 다르다고 보시면 될 것 같습니다. 특히 skill들이 학습된 환경과 실제 적용될 목표 환경이 다를 경우에 의미있기 때문에, 결과적으로, BOSS는 초기 skill 세트에서 비롯된 누적 오차를 보정할 수 있는 보다 robust한 policy를 학습하는 결과를 갖게 되었습니다. 자세한 내용은 아래서 추가로 다루도록 하겠습니다.
2. Methods
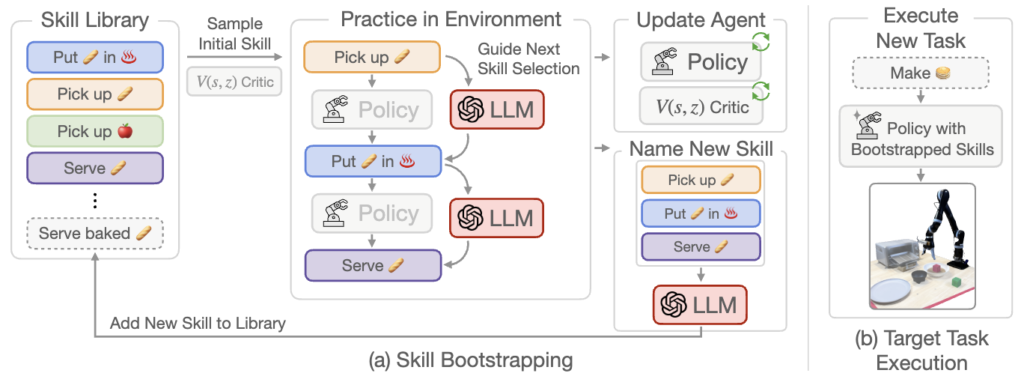
BOSS(BOotstrapping your own SkillS)는 다시 정리하자면, 최소한의 supervision 하에, 학습된 스킬 라이브러리를 점차 확장하며 long-horizon 작업을 자동으로 해결할 수 있도록 설계된 프레임워크라고 할 수 있습니다. 크게 두 단계로 구성되는 데요.
- Pre-training a Language-Conditioned Skill Policy 단계, 2. Skill Bootstrapping 단계 입니다.
그리고 bootstrapping이후엔 (b)처럼 새로운 instruction에 대해 타겟 태스크를 수행하는 것이죠.
2.1. Pre-training a Language-Conditioned Skill Policy
언어 레이블이 있는 데이터셋 D_L = \{ \tau_{z_1}, \tau_{z_2}, \dots \}에 접근 가능하다고 가정하면, 여기서 \tau_{z_i}는 (s, a, s', r) 튜플들(MDP의 요소들이죠.)로 구성된 trajectory이며, z_i는 궤적에 대한 freeform 형태의 language instruction입니다. primitive skill에 대한 sparse reward 함수가 있다고 가정하여, 객체가 올바른 위치에 놓였는지 감지하는 object detector 등을 사용해 primitive skill 성공 시 보상은 1, 그 외에는 0으로 정하고, 이 때 데이터셋 D_L을 사용하여 standard한 off-line RL 알고리즘(실험에서는 Implicit Q-Learning (IQL) 기법 사용)으로 학습한다고 합니다. policy 및 critic 네트워크는 trajectory의 language annotation z에 맞게 조건화되어 language-conditioned 정책 \pi(a|s, z)와 가치 함수 V(s, z)를 학습합니다. 이 과정에서 초기 skill 라이브러리 Z가 구축되는 과정을 거치게 됩니다.
2.2 Skill Bootstrapping
앞에서 사전학습된 language-conditioned primitive skill 정책 학습 후엔, 에이전트는 환경과 상호작용하며 새로운 스킬 체인(skill chain)을 시도하고 이를 자신의 스킬 레퍼토리에 추가하는 방식으로 더 긴 태스크에 대해 학습하게 됩니다. 초기 스킬 집합 외의 추가적인 supervision 학습없이 점진적으로 더 긴 장기 스킬을 학습하게 되는데요.
<초기 스킬 샘플링>
부트 스트래핑 시작 시, 스킬 레퍼토리 Z는 사전학습된 base 스킬 집합으로 초기화됩니다. 환경 상태 s_1에서 에이전트를 초기화한 후, 실행 가능한(성공 확률이 높은) 초기 스킬을 샘플링해야 합니다. 매 부트스트래핑 에피소드에서 사전 훈련된 가치 함수 V(s_1, z)에서 생성된 확률에 따라 초기 스킬을 샘플링하고, 타임아웃 임계값에 도달할 때까지 실행을 시도하는 과정을 거치게 됩니다.
<Guiding Skill Chaining via LLMs>
첫 번째 스킬 실행이 성공하면, 다음 단계는 첫 번째 스킬과 샘플링된 다음 스킬을 연결하여 더 긴 행동을 구성하게끔 하게 하는 게 목표입니다. 근데 무작위 샘플링은 의미 없는 행동을 초래할 가능성이 높기 때문에, 스킬 레퍼토리 크기와 스킬 체인 길이에 따라 의미없는 행동을 할 가능성이 막 기하급수적으로 증가합니다. 저자들은 여기서 LLM(LLaMA-13B)을 쓰는데요. LLM한테 다음 스킬 선택을 가이드하도록 하는 것입니다. 에이전트가 현재까지 실행한 스킬 체인(예: “Pick up the mug”, “Put the mug in the coffee machine”)과 현재 스킬 레퍼토리 Z를 LLM에게 프롬프트로 제공하는 방식을 취하게 됩니다. 아래 figure2를 참고해주시면 됩니다.


LLM은 프롬프트에 이어지는 텍스트를 생성하면서 다음 스킬을 제안하고, 제안된 스킬에 관한 문자열은 사전학습된 sentence 임베딩 모델[Sentence-BERT]의 임베딩 공간에서 Z의 기존 스킬 annotation들 중 가장 가까운 이웃을 찾아 매핑됩니다. 여기서 다양성을 위해 이 과정을 N번 반복하고, LLM이 할당한 토큰 likelihood 분포로부터 실제 다음 스킬을 샘플링한다고 합니다. 샘플링된 스킬은 성공적으로 실행된다면 다음 스킬 샘플링 과정을 반복하는 과정을 가지게 됩니다.
<Learning new skills>
에피소드가 종료되는 경우(스킬이 제한 시간 내에 실행되지 않거나, 미리 정의된 최대 스킬 체인 길이에 도달했을 때)에는, 수집된 데이터를 리플레이 버퍼에 다시 추가하게 되는데, 이 때, 완료된 각 스킬마다 sparse reward 1을 부여하게 됩니다. 예를 들어, 시도한 스킬 체인에 총 3개의 스킬이 포함되어 있다면, 해당 trajectory의 최대 리턴은 3이 됩니다. 이후에는 primitive skill 학습 시 사용했던 동일한 off-line RL 알고리즘(IQL)을 사용해 정책 학습을 계속 진행하게 됩니다.
그 다음은 데이터 효율을 극대화하기 위해, 에피소드에서 수집된 language instructions을 relabeling하여 리플레이 버퍼에 저장합니다. SPRINT 라는 기존 연구를 따라, 여러 개의 primitive skill을 하나의 composite skill instruction으로 합치는 과정을 거치게 된다고 합니다. 아래가 SPRINT 기존 연구를 따라 작성한 Prompt라고 하네요.

이 때에도 LLM을 사용하여 skill sampling 및 instruction generation을 수행합니다. 생성된 composite instruction과 해당 trajectory을 함께 리플레이 버퍼에 추가하고, 스킬 라이브러리에도 등록하여 지속적인 skill bootstrapping이 가능하도록 합니다. 이러한 새로운 trajectory는 하위 수준의 primitive skill instructions과 LLM이 생성한 상위 수준 composite instruction 을 모두 포함하여 저장되게 됩니다. 이를 통해, 에이전트는 base skill을 계속 fine-tuning하면서도 더 긴 skill chain도 학습할 수 있게 되는 것입니다.
아래의 Algorithm 1과 2는 이 과정을 요약하는 것이라고 보면 되겠습니다.
- 1: 사전 학습된 스킬 집합에서 policy π를 초기 학습
- 2~3: 에피소드마다 초기 스킬을 샘플링 및 실행
- 4~5: episode 종료 시점까지, LLM으로 다음 스킬을 선택 및 실행 반복
- 6: 실행한 스킬 시퀀스를 composite skill로 구성하여 레퍼토리에 추가
- 7: 수집된 경험으로 policy 업데이트

3. Experimental Evaluation

실험은 BOSS가 long-horizon 태스크에서 복잡하며 의미 있는 행동을 과연 잘 학습했는가를 평가하는 실험이라고 보시면 되겠습니다. 2가지 실험에서 이미지 기반 manipulation 환경에서 unsupervised RL(별도의 외부 보상 없이 환경과 상호작용하면서 다양한 스킬(행동 패턴)을 자동으로 발견하고자 하는 방법론) 및 zero-shot planning 기법(SayCan 과 같이 LLM이 zero-shot으로 high-level planning 시행하고, 사전정의된 primitive skill로 매핑)과 BOSS를 비교하는데요. 위 figure 3에 보이는 것처럼 (a) ALFRED 시뮬레이터에서의 가정용 태스크 수행, (b) Real 에서 Jaco 라는 로봇을 이용한 실제 주방 조작 태스크가 되겠습니다.
저자들은 3가지 질문의 관점에서 실험을 정리하려고 했습니다.
- BOSS는 skill bootstrapping 중에 유용한 스킬들의 풍부한 레퍼토리를 학습할 수 있는가?
- BOSS가 학습한 스킬은 비지도 RL 기법으로 학습한 스킬들과 비교하여 어떤가?
- BOSS는 실제 로봇 하드웨어에도 바로 적용 가능한가?
3.1. Experimental Steup
ALFRED환경에서 300×300 resolution의 1인칭 RGB 기반 egocentric observation을 처리할 수 있도록 gym 인터페이스를 추가한 수정 버전을 활용하였다고 합니다. 에이전트의 행동 공간은 총 12개의 이산 행동(예: 좌회전, 상방 보기, 객체 집기 등)과 82개의 이산 객체 타입으로 구성되어 있고, 초기 스킬 라이브러리를 학습하기 위해 73,000개의 언어 주석이 포함된 primitive skill 시연 데이터셋(ALFRED)을 사용했다고 합니다. Skill bootstrapping 단계에서는 학습에 사용되지 않은 4개의 floorplan(실내 평면도 구조의 환경 단위라고 합니다.)을 선택하였고, 각 floorplan마다 2개에서 8개의 primitive skill로 구성된 총 10개의 평가 태스크를 정의하였습니다.
실제 로봇 환경에서는 Kinova Jaco 2 로봇 암을 사용하여 table top 환경의 주방 조작 태스크를 수행하는데, observation은 로봇 손목에 장착된 카메라와 3인칭 카메라로부터 수집된 RGB를 합쳐 구성하였습니다. 로봇은 10Hz 주기로 이산적 gripper 조작(open/stay/close)과 연속적인 end-effector 제어 명령으로 동작하고, 초기 스킬 학습을 위해 human-teleoperation을 통해 수집된 6,000개의 언어 주석이 포함된 primitive skill 시연 데이터셋을 활용하였다고 합니다. 이후에는 bootstrapping을 통해 새로운 태스크를 학습하며, 학습에 사용되지 않은 객체 배치 환경에서 에이전트의 성능을 평가합니다.
이제 학습 및 평가 절차인데, 에이전트는 사전 수집된 primitive skill 시연 데이터셋을 바탕으로 IQL 알고리즘을 통해 총 150 에폭 동안 학습됩니다. 이후 ALFRED 환경과 실제 로봇 환경에서 각각 500,000 스텝과 15,000 스텝 동안 skill bootstrapping을 수행하였습니다. 실제 로봇 환경에서는 약 17분 정도 되는 시간이 소요되었다고 하네요. ALFRED 실험에서는 학습에 사용되지 않은 환경마다 별도로 정책을 학습시키며, 에이전트는 이 환경들에서 zero-shot으로 평가 태스크를 수행해야 합니다. 이는 에이전트를 처음 보는 환경에 배치하고, 최소한의 supervision만으로 새로운 스킬을 습득하게 해야하는 실제 상황을 모사한 것이기에, 평가 시에는 에이전트가 학습한 스킬을 바탕으로 제로샷 실행 성능을 측정하며, 특히 스킬 레퍼토리의 다양성과 일반화 능력을 중심으로 저자들은 성능을 분석하였습니다.
<Baselines 모델>
- CIC : 비지도 RL 방법, 대조적 정렬 목적 함수 사용. BOSS와 동일한 원시 스킬 데이터셋으로 사전 훈련.
- SayCan: 사전 훈련된 LLM을 사용하여 태스크를 단계별 원시 스킬로 분해하고 주어진 스킬 라이브러리에서 순위 지정. BOSS와 동일한 정책 및 LLM 사용. 환경 적응을 위한 정책 미세 조정 없음.
- SayCan+P: SayCan 변형으로, SayCan의 원래 스킬 순위 지정 대신 BOSS의 LLM 기반 스킬 제안 메커니즘 사용. 정책 미세 조정 없음.
- SayCan+PF: SayCan+P에 미세 조정 추가. BOSS와 동일한 시간 동안 목표 환경에서 미세 조정하지만, 스킬 체인 학습 없이 단일 스킬만 학습.
- Oracle: 목표 태스크에 대해 원시 스킬 정책을 직접 미세 조정 (상한)
- No Bootstrap: 사전 훈련된 원시 스킬 정책 (하한).
- ProgPrompt: (실제 로봇에서 비교) LLM 계획 방법으로, 자연어 질의를 코드로 변환.
<Result>
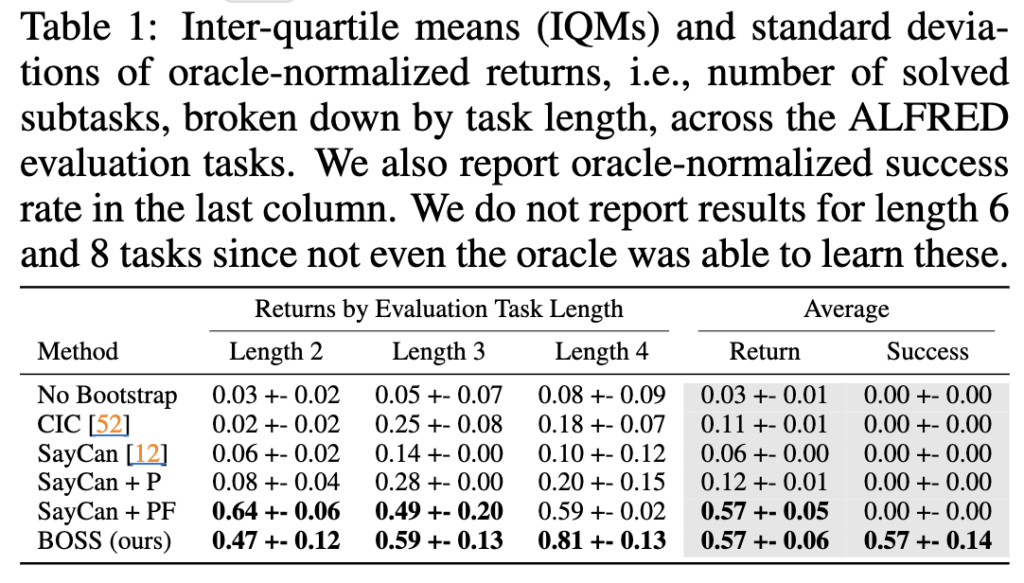
ALFRED 환경에서 BOSS는 Oracle을 제외한 모든 baseline들보다 성능이 높았습니다. 특히 Length가 3, 4와 같은 긴 태스크에서 더 높은 Oracle-normalized Return(실험방법론의 성공을 Oracle의 성공횟수로 나눈 것)을 보였으며, 모든 길이의 태스크에서 0이 아닌 success rate을 달성한 건 BOSS가 유일했습니다. SayCan+P가 SayCan보다 더 성능이 좋았던 것은 BOSS가 제안한 LLM skill 제안 메커니즘이 LLM으로부터 더 의미 있는 스킬 분포를 추출함을 뜻할 수 있지만, 사전 학습된 정책을 unseen floorplan환경에서 직접 사용할 때 발생하는 failure엔 강건하지 못하여 BOSS의 성능에 미치지 못하는 거라고 저자들은 말합니다. 그럼에도 제가 관심을 두고 있는 LLM의 skill 제안 자체가 드라마틱하진 않지만 효과가 없는 게 아니라는 점에서 얻어가는 점은 있었습니다. 여긴 RL policy를 어떻게 학습하느냐(low-level policy도 어떻게 더 집중할 것이냐)가 주된 point 였을 수 있기 때문에 저한테는 RL말고도 다른 방식으로 충분히 추후에 개선을 취할 수 있지 않을까 라고도 받아들여집니다.
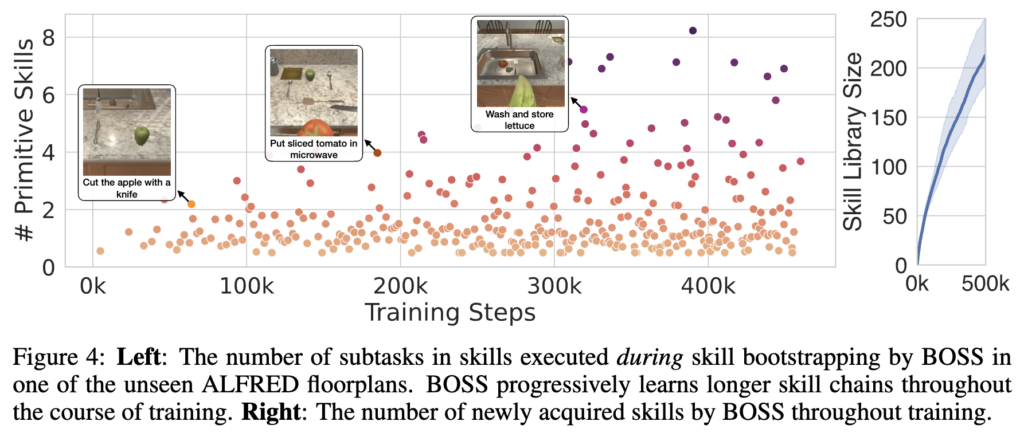
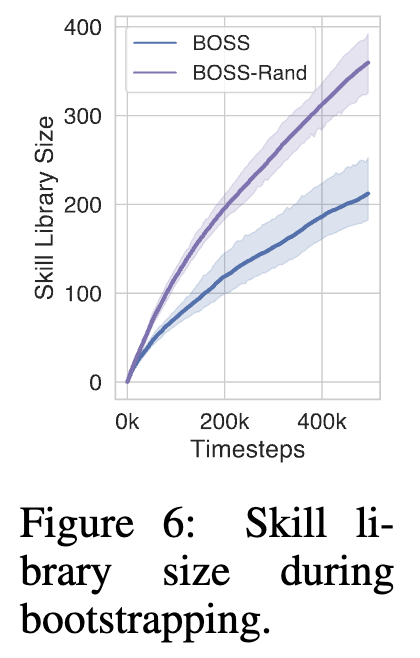
위 figure 4의 왼쪽 그래프는 학습 단계별로 달성한 primitive skill의 갯수를 나타냅니다. 여기서 왼쪽은 점들이 y축 방향으로 얼마나 멀리 올라가는지가 한 에피소드에서 실행된 스킬 체인의 길이를 의미하는데, 초기엔 대부분 1,2개의 primitive skill만을 수행하나, 학습이 진행될수록 긴 스킬 체인을 학습해나가는 것을 보여줍니다. 첫 사진인 "cut the apple with a knife"와 3번째 사진인 "wash and store lettuce"를 비교하면 primitive skill 갯수가 많이 차이나는 것을 볼 수 있습니다. 오른쪽 그래프는 전체 skill 라이브러리의 크기 변화를 나타냅니다. 시간이 지날수록 점차 새로운 skill들이 쌓여서 라이브러리 크기가 증가하는 모습을 보입니다.

Figure 5는 BOSS가 LLM 가이드에 따라 primitive skill을 결합해 생성한 skill chain의 예시입니다. light gray가 스킬체인이고, dark grey가 새롭게 skill을 요약한 summaries에 해당하고 이것이 skill bootstrapping 단계에 해당하는 정성적 결과라고 보시면 될 것 같습니다.
<Ablation Studies>

Table 3에선 LLM 가이드의 중요성을 분석하기 위해 BOSS-OPT1(weak LLM)과 BOSS-Rand(LLM 가이드 없이 무작위 스킬 선택)를 비교했습니다. weak LLM을 사용하거나(BOSS-OPT1) LLM 가이드 없이 무작위로 스킬을 연결하면(BOSS-Rand) 성능이 저하되는 결과를 보였습니다. 특히 작업 길이가 길어질 수록 성능 격차가 커지는 경향성을 보입니다. BOSS-Rand는 아래 Figure 6에서 보이는 것처럼 더 많은 스킬을 학습하지만, 대부분 의미 없는 스킬일 수 있던 것으로 보입니다. 스킬 부트스트래핑 과정에서 LLM의 정확한 가이드가 유용한 스킬 학습에 중요함을 보여주는 결과라고도 볼 수 있겠습니다.
4. Conclusion
논문에서 언급하는 limitation 도 몇가지 있었습니다. bootstrapping 에피소드 간에 환경 리셋이 필요한데, 실제 로봇 환경에선 사람이 직접 해줘야한다는 단점이 있고, bootstrapping 과정에서 각 primitive skill의 성공 감지가 완벽하다는 가정이 들어가게 된다는 점이 있었습니다. 또 greedy한 스킬 체인 제안 방식 자체가 특정 길이 이상의 매우 긴 태스크에는 적합하지 않을 수도 있고, 애초에 초기 스킬 라이브러리 조합만으로 새로운 스킬 학습이 제한된다는 점도 문제라고 합니다. 이는 아마 RAG와 같은 외부 memory를 염두에 두는 것 같기도 합니다.
안녕하세요 재찬님 리뷰 감사합니다.
skill들을 bootstrapping 하면서 조합하는 것을 학습하는 과정이 흥미로운 것 같습니다. 혹시 Long-horizon task의 어떤 문제 해결을 위한 접근이었는지 조금 더 얘기를 해주실 수 있을까요??
안녕하세요 영규님, 리뷰 읽어주셔서 감사합니다.
간단히 설명하자면, 이미 가지고 있는 low-level policy 몇 가지(예를 들면 pick&place, push)로는 적당한 short-horizon task(단순 블록 쌓기)를 처리할 수 있을 거잖아요? 반면 Long-horizon task는 로봇이 이미 가지고 있는 low-level policy들의 조합 한에서 더 정교하게 순서를 구성하는 것이 목표다 보니 성공률이 낮습니다. 그래서 해당 과정에서 LLM 으로 하여금 policy 들의 조합 planning 시의 reasoning 맛을 좀 첨가하겠다. 더불어 LLM이 조합한 어떤 long-horizon policy를 new skill로 확장(bootstrapping)하고 싶었던 것으로 이해하시면 될 것 같습니다.
재찬님 좋은 리뷰 감사합니다.
primitive skill의 성공여부를 판별하기 위해 object detector는 계속해서 돌고있는 것 인지 궁금합니다.
skill bootstrapping은 결국 목표 작업에 대한 세분화가 아니라 역으로 세분화된 스킬들로부터 작업으로 올라가는 방향으로 이해아면 될까요? 색다른 접근 방식인 것 같아 흥미롭습니다.
실험 파트에서 Table 1의 success rate은 마지막 열에 해당한다고 캡션에 작성되어있는데, SayCan + PF 방식은 나머지 성능이 모두 BOSS와 유사한 성능을 보였으나, success rate은 0이 되어있는데, 다른 방법론들의 success rate이 모두 0인 이유에 대한 분석이 궁금합니다.
안녕하세요 승현님, 리뷰 읽어주셔서 감사합니다.
1. object detector는 완벽하게 성공 중이라는 가정이 limitation에서 언급됐었습니다. 이 부분이 명확한 부연 설명이 없이 그렇게 가정하고 문제를 접근했다는 점이 아쉬웠습니다.
2. 맞습니다! 로봇이 이미 가지고 있는 세분화된 스킬들의 종류로부터 결국 목표 작업을 위해 작업을 정의해나가는 것으로 이해하시면 됩니다. 추가적인 RL 학습으로 한번 해낸 복잡한 skill을 추가로 skill library에 저장하여 skill을 다채롭게 만드는 것도 핵심인 것 같구요.
3. Success Rate은 승현님도 아시다시피 모든 서브작업이 정상적으로 성공하고 마지막까지 실패가 없는 경우에 해당하는데요. 이 말인 즉슨 Long-horizon task를 중간중간 한번의 동작 실패도 없이 모두 완벽하게 수행해야 한다는 뜻이고, Return 이 0이 아닌데 SR이 0인 방법론들은 어찌저찌 중간 몇 단계는 일부 성공하지만, 결국 마무리에서 완전 성공은 못했단 뜻이겠습니다. SayCan + P와 SayCan+PF가 중간 planning 단계에서 LLM 기반 스킬 제안 메커니즘이 사용되거나, 추가로 단일 스킬에 대해 finetuning 되긴 했으나, 저자들이 제안한 BOSS처럼 skill-chain으로 학습된 건 아니기 때문에 Long-horizon task의 최종 마무리 성공에는 영향을 아예 끼치지 못했던 것으로 보입니다.
리뷰 잘 봤습니다.
몇 가지 질분 남기고 갈게요!
Q1. “생성된 composite instruction과 해당 trajectory을 함께 리플레이 버퍼에 추가하고, 스킬 라이브러리에도 등록하여 지속적인 skill bootstrapping이 가능하도록 합니다. 이러한 새로운 trajectory는 하위 수준의 primitive skill instructions과 LLM이 생성한 상위 수준 composite instruction 을 모두 포함하여 저장되게 됩니다. ”
-> 해당 리뷰에서 trajectory라는 표현이 로봇이 이동한 단순한 궤적이 아니라고 생각이 듭니다. 어떤 의미로 사용된 것인지 제가 와닿지가 않아서요… 추가 설명 부탁합니다.
Q2. “1: 사전 학습된 스킬 집합에서 policy π를 초기 학습
2~3: 에피소드마다 초기 스킬을 샘플링 및 실행
4~5: episode 종료 시점까지, LLM으로 다음 스킬을 선택 및 실행 반복
6: 실행한 스킬 시퀀스를 composite skill로 구성하여 레퍼토리에 추가
7: 수집된 경험으로 policy 업데이트”
-> alg 1,2를 다음과 같이 정리해주셨습니다. 여기서 의미하는 policy는 IQL라고 추측인 되는데… 모든 스킬이 포함된 레퍼토리를 한번에 학습하는 걸까요???
Q2-1. 처음에 skill book에는 skill=학습된 RL들이 들어가 있는 것으로 이해했습니다만, 위 질문에서 policy가 IQL이 맞다면… 모든 레퍼토리를 학습한 policy가 있으면 끝 아닌가요???
안녕하세요 태주님, 리뷰 읽어주셔서 감사합니다.
1.
제가 혼동의 여지가 있게 워딩을 명확히 하지 않았던 것 같습니다. 일반적으로 저희가 흔히 RL 분야에서 에이전트가 환경이랑 상호작용하면서 얻는
연속된 상태(state), 행동(action), 보상(reward) 등의 모든 시퀀스 정보를 뜻하는 그 trajectory 개념이 맞긴 합니다. 본 BOSS 논문에서 좀 더 섬세하게 전달하고 싶었던 trajectory의 의미는, 여러 primitive skill로 구성됐던 composite skill(합성된 스킬) 이 행해졌던 동안의 state-action-reward의 그 경험 덩어리를 뜻하는 것으로 이해했습니다.
2.
맞습니다. 초기에 primitive skill들을 미리 IQL로 학습해놓은 policy가 있고, 해당 policy가 composite skill들까지 추가 학습하면서 policy를 업데이트 해나가서, 결국 단일의 IQL기반 에이전트가 여러 skill을 가지는 policy 형태로 저도 그렇게 이해했습니다.
그래서 어떤 특정 언어 instruction ‘z’가 들어왔을 때, 하나의 에이전트가 그걸 조건부로 실행하는 Policy를 가진 π(a | s, z)의 역할을 하는 중이라고 이해하시면 될 것 같습니다.
2-1.
사실 primitive skill들과 관련된 데이터셋으로 학습된 초기 policy는 진짜, primitive skill들에 관한 policy만 있고, 이것들을 엮을 수 있는 composite skill 실행 경험은 없으니 real환경에서 복잡한 long-horizon task를 수행하려 할 땐 새로 long-horizon demo 데이터 셋을 모아서 fine-tuning해야했던 것이 문제가 되었던 것입니다.
근데 본 논문은 이제 실제 환경에서 직접 demo 모아서 fine-tuning하는 건 cost가 든다. -> 아 이런 dense한 supervision없이 원래 가지고 있던 primitive skill들 policy 잘 조합해서 RL agent 자기가 스스로 복잡한 동작 잘 학습해나가면 안되나? 의 생각에서 해당 bootstrapping 개념을 택한 것입니다!
물론 걱정되는 점은, 저는 어떻게 보면 이게 강화학습 + Incremental Learning의 개념이 조금 있다고 생각해서, Catastrophic Forgetting과 같은 skill 망각 현상이 있지 않을까… 하는 우려도 있습니다!