앞서서 사용자 질의 반영 비디오 요약과 일반 비디오 요약을 통합한 프레임워크를 소개드렸는데요, 오늘 소개드릴 논문은 더 광범위한 비디오 요약 테스크를 한번에 수행하는 방법을 소개합니다. 비디오 입력으로 요약된 비디오를 생성하는 V2V, 비디오 입력으로 내용이 요약된 텍스트를 생성하는 V2T, 비디오 입력으로 요약된 비디오와 텍스트를 동시에 생성하는 V2VT를 한번에 수행하는 방법을 다루게 되는데요, 그럼 리뷰를 시작하겠습니다.
Into
본문에 들어가기 앞서, 논문이 제시하는 방법에 대한 컨셉을 이해해보겠습니다. 제목에서 알 수 있다시피 수행하고자 하는 테스크는 Cross-Modal Video Summarization 입니다. 즉, 요약을 생성하는 모달리티가 다중(시각 모달리티인 비디오와 텍스트)입니다. 해당 연구는 위의 문제를 LLM을 활용해 해결하고자 했으며, 특히 영상의 시간적 정보를 Prompt로 주입하여 LLM의 시간적 이해능력을 높여, 비디오 요약 문제를 해결했습니다. 또한 Instruction을 Prompt에 활용하여 Cross-Modal Video Summarization을 가능하게 했습니다. 시각적 정보로 Prompt를 생성하는 과정에서 도입된 텍스트 인코더를 통해 Instruction으로 요약할 도메인의 정보를 같이 제공했는데요, Prompt Instruction으로 LLM의 시간적 이해능력을 개선했을 뿐만 아니라, 다중 테스크를 통합하여 수행하는 프레임워크를 설계했습니다.
해당 논문은 프레임워크 설계와 더불어, 데이터셋을 구축했습니다. VLMs을 학습하기에 기존의 데이터셋이 충분하지 않다는 점을 지적하며, instruction과 함께 제공하는 대용량 데이터셋인 Instruct-V2Xum을 구축했습니다. 추가로, 더욱 정밀한 비디오 요약 테스크의 분석을 위해 두가지 평가지표(F_Clip, Cross-F_Clip)을 제시했습니다.
정리하면, 본 논문은 Cross-Modal 비디오 요약(V2V, V2T, V2VT)을 위한 통합된 프레임워크를 제시하며, 해당 프레임워크의 학습을 위한 데이터셋과 새로운 평가지표를 제시하여 해당 분야에 다방면적인 기여를 하였습니다. 그럼 프레임워크부터 이어서 알아보겠습니다.
Framework (방법론)
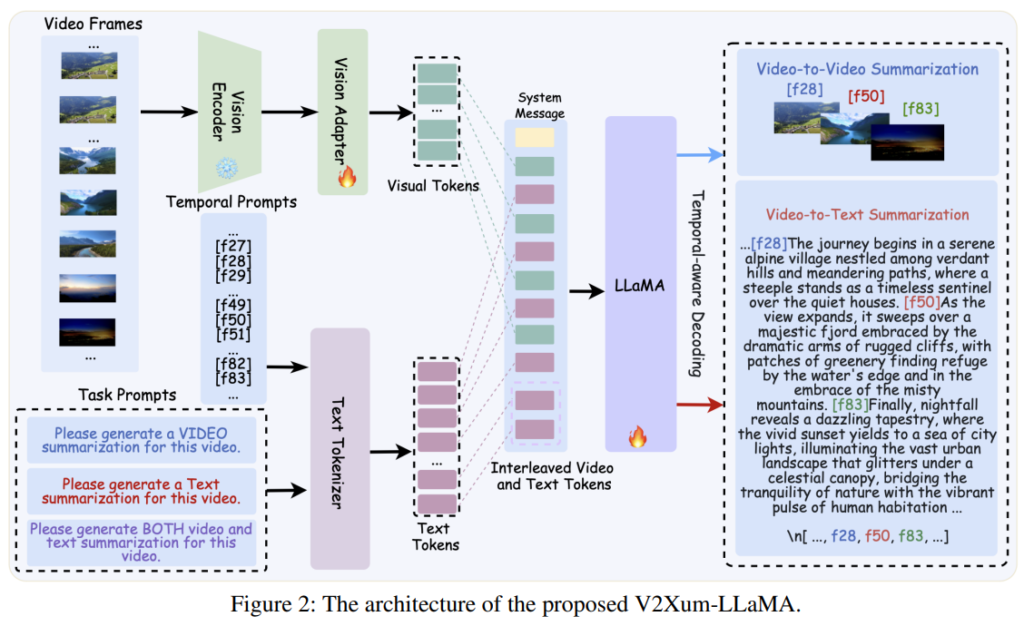
위의 Figure2는 본 논문의 전체 구조도입니다. 기존의 언어 모델은 테스크 통합 등을 위해서 사용되곤 했습니다(CLIP-it x rivew). 본 논문은 언어 모델을 cross-modal을 위한 인터페이스로 활용했을 뿐 만 아니라, 시간적 정보를 주입하여 LLM의 시간적 이해능력(temporal understanding)을 높였습니다.
Figure2의 Text Tokenizer 부분을 보시면, 비디오 프레임의 순차적 정보인 Temporal Prompts([fxx])와 Task Prompts(Video or Text 로 요약을 요청하는 내용)을 통해 Text tokens을 생성함을 알 수 있습니다. 이때, 실험에 사용된 Text Tokenizer는 Vicuna-v1.5-7B/13B입니다. 다음으로 비디오 프레임을 이용해 Visual Tokens을 생성했는데, CLIP을 활용하여 프레임을 임베딩해 Visual Tokens으로 생성했습니다. 이렇게 생성된 두 토큰을 순차적으로 교차 입력하여 아래와 같은 Instructed Video and Text Tokens을 생성하게 됩니다. LLaMA 입력을 위한 최종 토큰인 Instructed Video and Text Tokens는 Figure 2를 통해 알 수 있듯이 System message와 교차된 토큰인 아래의 S, 이후 Task Prompts가 결합된 형태로 생성됩니다. (System message에 대한 정확한 정보는 제공되지 않았습니다)
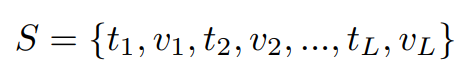
이렇게 생성한 입력 토큰을 활용해 아래의 목적함수 수식으로 LLM(본 논문에서 LLaMA-2)를 학습하게 됩니다. 정답을 활용하여 출력과 입력이 같아지도록 학습하는 지도학습의 일반적인 log-likelihood 함수로, S-가 위에서 생성한 입력 토큰, D는 전체 데이터셋, N은 요약의 전체 길이를 의미합니다.
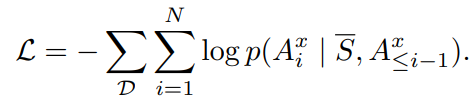
정답과 요약된 출력을 의미하는 A는 테스크(V2V, V2T, V2VT)마다 다르게 구성되며 출력의 형태는 아래와 같습니다. V2V의 경우 A^v와 같이 프레임 인덱스로 구성된 벡터이며, V2T와 V2VT는 A^t의 예측을 수행합니다. 예측의 직관적인 형태는 아래 그림과 같습니다.

데이터셋
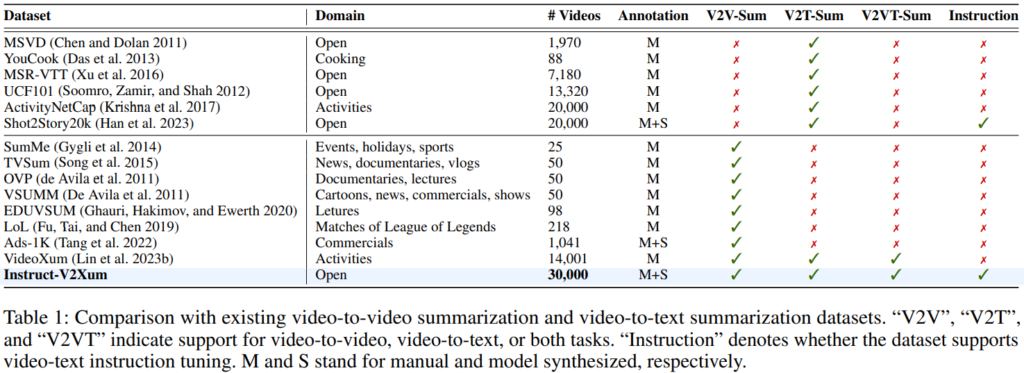
논문에서 제안한 데이터셋의 특징은 위의 Table1에서 잘 요약되었습니다. VLMs 모델 학습이라는 목적에 맞게 기존의 데이터에 비해 비디오의 갯수가 많고 Youtube 데이터 기반으로 Domain이 Action등으로 한정되지 않고 다양합니다. 또한 Cross-modal 연구를 위해 Video(frame), Text 요약을 제공하며, Instruction을 포함합니다. 이어서 자세한 생성 방법을 알아보겠습니다.
데이터셋 구축을 위한 베이스 데이터셋으로는 InternVid라는 대규모 비디오 데이터셋을 활용했습니다. 가장 먼저 InternVid 데이터셋을 시간 등으로 필터링 한 후, 1FPS로 추출하여 LLaVA-1.5-7B를 통해 프레임별 텍스트 요약을 생성했습니다. 이후 GPT-4V를 통해 텍스트의 요약을 수행했으며, BERT score를 통해 요약된 텍스트와 프레임 라벨의 유사도를 측정하여 최종 요약(threshold 0.93)을 생성했다고 합니다.

이때 요약에 활용된 비디오의 프레임 설명을 Video summaries로 제공하며, 최종 요약 이후에 GPT-4를 통해 문법이나 유창성을 다듬기 위한 재생성을 수행했다고 합니다. 이러한 과정으로 데이터셋을 구축 한 이후, Human Verification 과정을 통해 30k의 데이터셋을 생성했다고 합니다.
평가지표

앞서 간단하게 언급했던 것 처럼, 논문은 비디오 요약이라는 테스크의 정밀한 분석을 위한 새로운 평가지표를 제시했습니다. 평가지표의 이름에서 알 수 있듯이 F1 Score의 컨셉과 비슷하게 정밀도와 재현율을 반영해 정답과 예측의 유사성을 측정하고자 했습니다. 그러나, 이진 라벨 등으로 제공되어, 정답과 유사하더라도 오답으로 판명되는 기존 평가방식을 개선하기 위해 본 논문에서는 CLIP을 통해 의미적 유사성에 집중하도록 하는 지표를 제안한 것입니다.
F_Clip을 보시면 정확히 같은 프레임으로 예측해야만 유사하다고 판명했던 Recall(재현율)과 Precision(정밀도)를 Clip을 비디오 요약의 정답 v과 모델 출력 v^의 거리적 유사도를 통해 재정의했습니다. 이때 거리는 각 입력을 CLIP 임베딩하여 거리를 측정했습니다. Cross-F_Clip의 경우 단순히 시각 도메인에서만 유사성을 측정하지 않고, 수식에서 확인할 수 있듯이 텍스트 요약에 대한 정답/예측을 활용한 것입니다. 실험 결과 제안한 지표는 F1 Score와 큰 흐름을 같이하나, 의미적 유사성을 고려했기 때문에 결과 분석에 있어 더욱 유의미하다고 언급됩니다.
실험
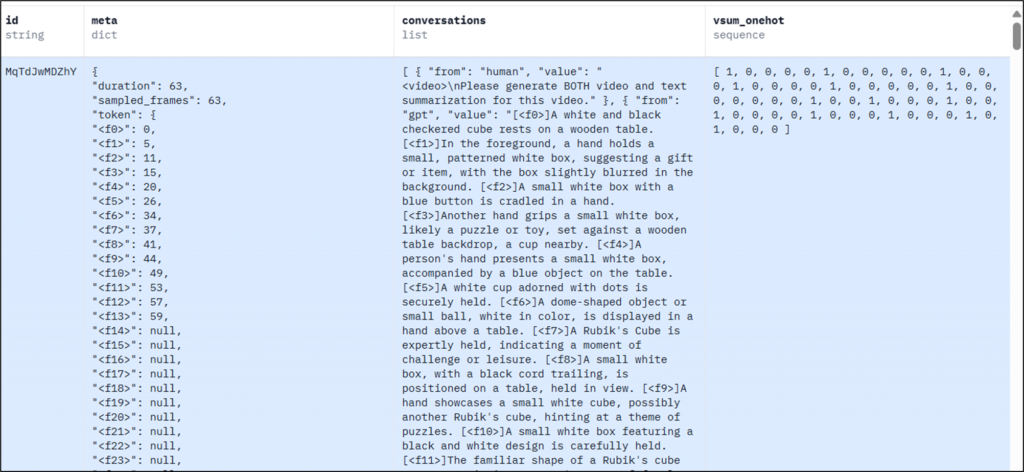
가장 먼저 논문에서는 제안한 프레임워크를 기존 데이터셋인 VideoXum을 활용하여 SOTA 방법론과 비교했습니다.(Table2) 실험 결과 제안한 논문은 Task-specific 하지 않고(TSH-Free✓), Cross Modal을 모두 수행할 수 있으면서(Cross-Modal✓) 즉, 다른 방법론에 비해 제약이 적으면서 모든 테스크(V2T, V2V, V2VT)에 대해 전반적으로 높은 성능을 보였음을 확인할 수 있습니다.
그 외에 전통적으로 많이 사용되는 데이터셋이지만 비교적 소규모 데이터셋(V2V만 수행가능)인 TVSum과 SumMe 벤치마크에서도 제안 방법론이 효과적이였음을 Table4에서 확인할 수 있습니다.
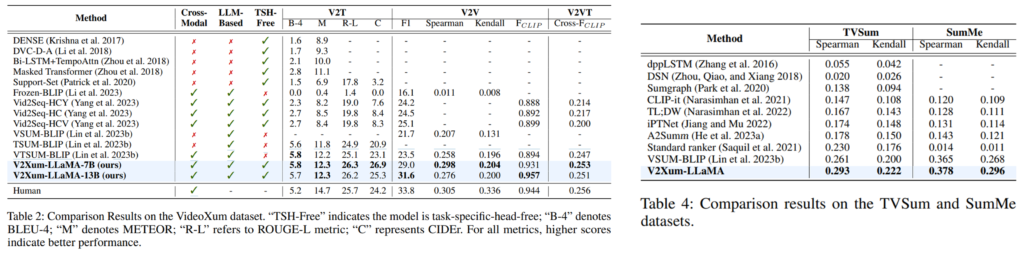
또한, 제한한 데이터셋에 대한 기존 연구와 제안 방법론의 적용 성능도 Table3에서 확인할 수 있습니다. 해당 데이터셋을 통해 제안 방법론을 학습했을 때, VideoXum을 활용한 것 보다 성능이 개선됨을 보이며, 대형 언어모델 학습에 데이터셋 스케일이 중요하다고 언급하였습니다.
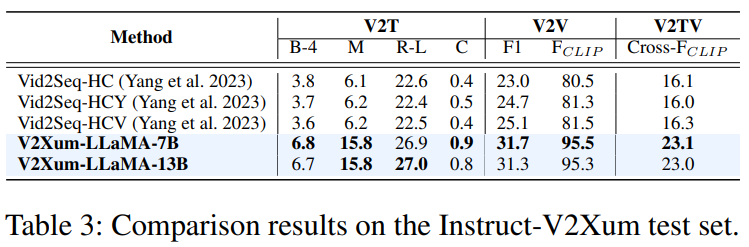
마지막으로 Ablation Study를 통해, 제안된 요소들이 효과적임을 다양한 평가지표와 테스크에서 검증했습니다. 아래의 결과를 통해 제안한 temporal prompt가 효과 있었음을 확인(w/o temporal prompts)할 수 있습니다. 또한, A_t 를 통해 비디오와 텍스트 요약을 동시 생성하는 경우(V2T, V2VT) 성능이 개선됨을 확인할 수 있는데(w/o simultaneous VT-Sum), 제시하는 Interleved taken 구조가 LLM의 시간에 대한 이해능력을 높이는데 효과적이였다고 예측할 수 있습니다. 그 외에도 Ablation study를 위해 VideoXum를 학습하고 VideoXum+Instruct-V2Xum의 결과를 비교하여(w/o Instruct-V2Xum) 제시한 Instructed 데이터셋의 중요성을 확인하였습니다.
본 논문에서는 비디오 요약 테스크에 대해 다방면적인 제안을 한 논문이였습니다. 특히 CLIP을 활용한 평가지표가 인상깊었습니다. 해당 분야를 위해 문맥적 고려를 할 수 있는 해당 지표가 매우 매력적이지만, VLMs 모델의 개선에 따라 지표의 지속가능성이 우려되기도 합니다. 이상으로 리뷰를 마치겠습니다. 감사합니다.
안녕하세요 유진님 좋은 리뷰 감사합니다.
Figure2에서 Text Token들과 Visual Token들을 통해 나온 값을 순차적으로 교차 입력하여 Instructed Video and Text Tokens을 생성하는데, 이처럼 순차적으로 입력하는 이유가 따로 있을까요?
감사합니다.
안녕하세요 댓글 달아주셔서 감사합니다.
Instructed Video and Text Tokens으로는 단순히 두 토큰을 결합하는 형태 등 다양하게 구성할 수 있기는 합니다. 아쉽게도 다양한 형태에 대한 분석은 논문에 제시되지 않았습니다.
다만 LLM의 시간적 이해능력을 극대화하기 위한 목표를 위해서 영상 프레임 정보마다 시간적 흐름을 나타내는 토큰을 태그처럼 주입하므로서, 시간적 정보를 학습할 수 있었을 것으로 예상할 수 있습니다.
감사합니다.
안녕하세요, 좋은 리뷰 감사합니다.
요약된 출력 형태에서 나오는 벡터 안의 프레임 인덱스가 summarization하기 위해 사용되는 프레임 시간적 정보라고 이해하였습니다. 이 때 비디오 프레임이라는게 모든 시간마다 scene이 변하지는 않을 거라고 생각이 드는데, 이 때 가령 f28과 f29, f30이 같은 장면의 프레임이라면 모델이 이 셋 중 무엇을 최종 프레임 인덱스로 선택하여도 평가를 할 때 동일한 성능이 되는 것일까요 ??
감사합니다.
안녕하세요 댓글 달아주셔서 감사합니다.
기존 연구의 경우 요약에 포함될 프레임에 대해 이진라벨링이 되어, 유사하거나 동일한 프레임을 요약 프레임으로 선별하더라도 GT 프레임과 동일하지 않다면 잘못된 예측으로 평가되는 경우가 있었습니다.
그러나, 제안된 평가지표(F_Clip)의 경우 VLMs을 이용하여 GT와 예측간의 문맥적 유사성을 VLMs의 임베딩 특징 공간에서 거리 유사도로 평가하기 때문에, GT와 맥락적으로 동일/유사 프레임으로 예측 할 경우에도 동일한 성능으로 평가됨을 기대할 수 있습니다.
감사합니다.