안녕하세요 류지연입니다. TESTR 논문 리뷰에 이어서 TESTR의 검출 성능을 개선한 DPText-DETR 논문에 대해 리뷰 진행해보도록 하겠습니다.

1. Introduction
Text spotting은 OCR(문자 인식) task 중 하나로 이미지 내의 문자의 위치를 검출하는 것 부터 그 텍스트의 내용을 인식하는 것 까지를 모두 포괄합니다. 자율주행 시 표지판을 읽고 경로를 생성하거나 급하게 수정 시 반영되기 위한 중요한 기술이라고 보시면 되겠습니다. 해당 테스크에서는 다양한 형태 크기에 대해서도 검출이 잘되도록 하는 것이 최종적으로 해결해야 할 부분입니다.
앞선 리뷰에서 TESTR이란 Text Spotting 모델을 다뤘습니다. 이는 객체 검출을 set prediction 문제로 재정의 한 DETR의 방법론을 Text Spotting에 적용한 연구였습니다. 여기서 set prediction problem이란 모델이 K개의 객체를 GT와 일대일 대응이 되도록 모든 이미지에서 동일하게 예측하도록 하는 것을 말합니다. 그리고 예측을 끝내고 이분 매칭을 통해 모델의 예측과 GT간의 매칭해 loss를 구했었습니다. 이때 객체의 개수가 N개 보다 작다면 실제 존재하는 객체를 제외한 모델의 예측은 no object를 가리키도록 합니다.
본 연구는 TESTR의 detector 부분을 개선시킨 논문입니다. TESTR은 detection과 recognition을 수행하기 떄문에 텍스트 윤곽선에 대한 polygon의 좌표를 예측하는 location decoder와 character sequence를 예측하는 character decoder 총 두개의 디코더로 구성돼 있는 반면 본 논문에서 제안하는 DPText-DETR은 텍스트의 검출만을 수행하므로 location decoder만 있습니다. 4절에서 얘기드릴 성능 평가 또한 detection에 대해서만 진행합니다
1.1. Preliminary
간단히 TESTR의 방법론에 대해서 빠르게 훑고 지나가겠습니다.
TESTR은 N개의 object query를 예측하도록 설계 돼 있는데요. 각 object query가 하나의 텍스트 인스턴스에 해당합니다. object 쿼리마다 polygon 좌표 정보를 담은 control point query P^(i), 텍스트 시퀀스를 예측하는 charcter query로 C^(i) 구성됩니다.
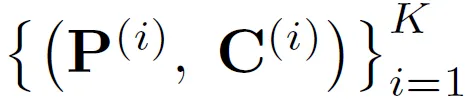
polygon을 N개의 점으로 나타낸다고 했을 때 point query는 다음과 같이 N개의 subquery로 구성되고 각 텍스트에 대해서 M개의 character를 고정해서 예측한다고 했을 때 M개의 subquery로 구성됩니다.
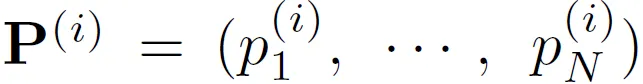
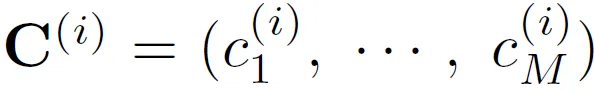
모든 텍스트에 대한 쿼리는 각각 location decoder, character decoder의 입력으로 들어간 후 여러 차례의 attention을 수행하며 학습됩니다.
간단한 TESTR 논문의 contribution에 대한 요약입니다.
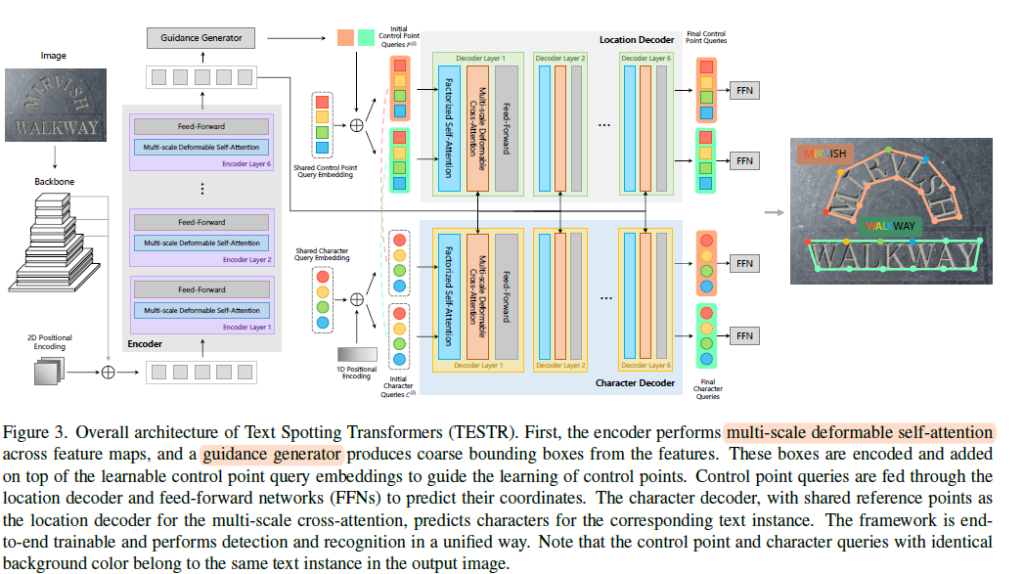
- DETR의 구조를 가져와 end-to-end하게 텍스트 검출과 인식이 되도록 하나의 인코더와 두개의 디코더로 모델을 설계했습니다. 사람의 prior knowledge를 요구하지 않는다는 점에서 기존 검출 모델과 차이를 갖습니다.
- 또한 multi-scale feature map을 computational cost 차원에서 효과적으로 다룬 Deformable-DETR을 차용해 동일하게 인코더의 self attention과 decoder의 cross attention을 적용했습니다. 쿼리마다 reference point가 할당되면 그 reference point를 기준으로 근방에 있는 k개의 sampling point의 feature vector를 key로 attention을 수행하는 방법이었습니다. 기존에 각 쿼리가 모든 픽셀에 대해서 attention을 수행해서 발생했던 연산량 부담 문제로 부터 자유롭습니다.
- 어떠한 region proposal 없이 direct하게 텍스트의 윤곽선을 그리고 인식해야 했던 TESTR이 초반에 수렴하는데까지 오래 소요되는데요. 더 빠른 수렴을 위해 인코더에 Guidance generator라고 coarse( 대략적인)하게 텍스트 인스턴스를 아우르는 바운딩 박스에 대한 좌표 정보로 control point query에 더해줬었습니다. 또한, 박스의 좌표 정보는 첫번째 decoder 블록에서의 cross attention 수행 시 reference point의 역할을 수행하기도 합니다.
본 연구에서 지적하는 TESTR의 한계점은 다음과 같습니다.
- query formulation issue: TESTR은 인코더에서 텍스트의 대략적인 위치 정보를 제안합니다. 각 박스의 정보가 positional 쿼리로 디코더의 입력이 되는 control point query에 더해지지요. 텍스트 마다 하나의 control point 쿼리가 할당이 되는데 모든 쿼리는 공통의 control point 임베딩을 공유합니다. 각 텍스트 마다 서로 다른 positional encoding이 더해지기 때문에 control point embedding을 공유하지만서도 서로 다른 텍스트를 가리키게 됩니다. 텍스트의 대략적인 위치와 스케일 정보가 전달되기 때문에 아무것도 알지 못한 상태에서 실제 control point에 근사하는 것 보다 훨씬 수렴이 쉽습니다. 하지만 DPText의 저자가 지적하기를 이때 제안되는 바운딩 박스 정보가 coarse하고 실제 텍스트의 윤곽선 자체와 정확히 매칭되지 않아서 최적의 방법은 아니라고 합니다.
- label form issue: 기존에는 사람이 글자를 읽듯 맨 먼저 오는 알파벳을 기준으로 텍스트의 시작이라고 보고 control point의 첫번째 점 또한 그 위에서 시작해서 시계방향으로 돌도록 텍스트의 윤곽선을 그리는 N개의 점에 어노테이션이 제공되었습니다. 텍스트의 상하로 뒤집혀 있어도 point label은 첫 알파벳를 기준으로 위의 점이 시작점이었습니다. 저자는 그렇게 학습할 경우 모델이 텍스트의 방향까지 모두 고려하도록 학습이 되어 학습이 오래 걸리고 어렵습니다. 저자는 굳이 해당 모델에게 사람이 읽는 방식대로 적용할 필요가 없다고 얘기합니다. 기존 벤치마크 데이터셋에는 상하가 거꾸로 된 텍스트가 포함된 이미지가 드물어 이런 텍스트 방향에 대한 취약성을 충분히 확인하기가 어렵습니다. 따라서 본 연구에서는 inverse text가 비중있게 포함된 새로운 데이터셋인 Inverse-Text을 제안합니다. 해당 데이터셋은 500장의 scence 이미지로 구성돼 있고 40%가 inverse text입니다.
논문에서 각 문제에 대해서 해결책으로 내놓은 contribution들입니다.
- Query formulation issue
- 인코더에서 제안된 바운딩 박스에 대한 positional query로 충분한 정보를 제공하지 못한다는 문제에 대해 저자는 Explicit Point Query Modeling (EPQM) method를 제안해 새롭게 Dynamic Point Text Detection Transformer (이하 DPText)를 제안합니다. TESTR은 박스의 정보로 박스의 중앙점 좌표, 폭과 너비만을 인코딩 해 더했다면 DPText는 바운딩 박스의 정보를 가지고 실제 polygon을 구성할 N개의 점에 대한 좌표를 생성해 더합니다. 그리고 각 디코더 블록을 통과할 때 마다 오프셋을 계산해 이 조금 더 complete해진 positional query를 지속적으로 갱신합니다.
- 추가적으로 attention의 방법 특성상 non-local하게 연산을 수행하는 관계로 local 기반의 구조 정보를 학습하는 데에는 어려움이 있습니다. 하지만 같은 인스턴스에 대한 control points는 대략적으로 하나의 원형을 이루는 게 일반적인데요. 저자는 이런 원형 구조를 학습하는 게 중요하다고 얘기합니다. 그래서 추가적으로 제안하는 것이 Enhanced Factorized Self-Attention (EFSA)으로 subquery간의 intra attention을 수행할 때 (같은 텍스트에 대한 subqueries 간의 관계를 보는 것임) 이는 추가적으로 circular convolution 층 하나를 추가해 구현되었습니다.
- Label form problem
- 이 문제의 경우 텍스트의 방향 상관 없이 모든 텍스트에 대해서 동일한 포맷을 지정해 줬습니다. 텍스트가 똑바로 있든거꾸로 있든 좌상단의 점을 p_1 (시작점)으로 둡니다. 기존의 annotation은 텍스트의 방향을 고려한 대로 있는데요 이를 해당 포맷으로 바꿔주기만 하는 것으로 구현이 됩니다. 해당 방법은 모델 자체를 수정했다기 보다 annotation의 새로운 고정 포맷을 제안했다고 봐주시면 되겠습니다.
3. Methodology
그럼 각 방법론에 대해서 자세하게 설명드리겠습니다.
3.1 Overview
TESTR와 동일하게 Deformable-DETR을 기반으로 해서 모델이 설계됩니다. DPText의 구조는 다음 구조도로 확인하시길 바랍니다.
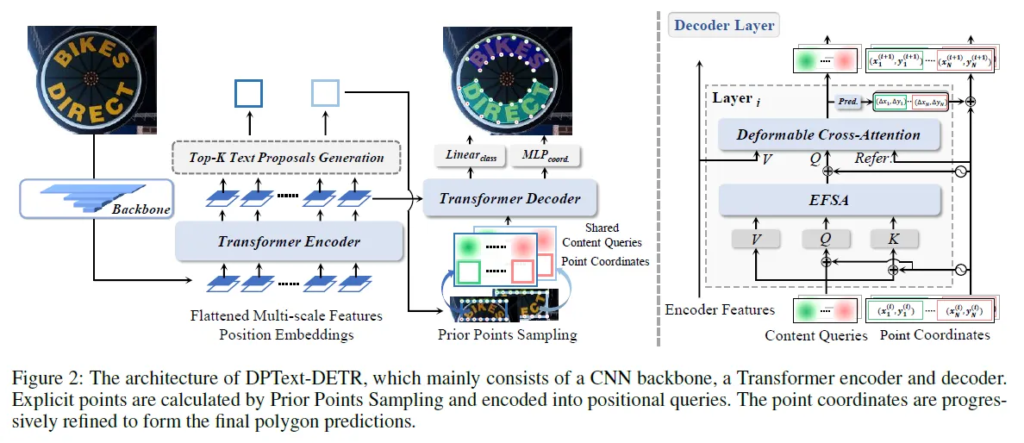
텍스트가 포함된 이미지를 입력으로 받아 CNN의 백본 네트워크와 인코더를 통과해 이미지의 feature를 추출합니다. 뒷단의 마지막 인코더 레이어로부터는 box proposal이 이루어집니다. confidence 가 높은 순서로 top K개의 박스만을 취해 각 박스마다 initial control point coordinate을 결정합니다. 디코더의 입력으로 들어가게 되는 shared control point embedding에 더해져 텍스트 마다 서로 다른 composite query를 구성합니다. 이후 디코더 블록의 EFSA를 통과해 subquery간 서로 다른 query 간의 attention이 수행되고 Deformable cross attention을 통해 또 다시 순서대로 CNN, 인코더로 추출된 이미지의 features에 대해 cross attention이 수행됩니다. 6차례의 디코딩 레이어를 통과한 후 prediction head를 통과해 최종적인 control point coordinate를 얻고 또 다른 prediction head를 통과해서 해당 예측이 텍스트 인스턴스에 해당하는지 여부를 나타내는 class confidence score이 계산됩니다. loss 함수는 TESTR의 loss 함수와 같습니다.
3.2 Positional Lable Form
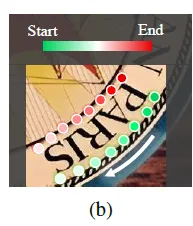
위는 사람이 문자를 인식하는 순서를 나타낸 것입니다. 이전 어노테이션 포맷을 위와 같았지요.
앞서 사람의 읽는대로 문자가 정렬된 방향을 고려하는 방법이 모델의 입장에서는 불필요한 과정이라고 얘기 했었습니다. 문자의 방향을 고려함으로써 학습되는데 오히려 헷갈리게 한다는 게 이유였습니다. 추가적으로 회전을 적용한 증강을 활용해도 inverse text에 대해 충분히 강건하지 않다는 한계를 갖고 있습니다.
저자는 position label을 방향 구분 없이 이미지를 기준으로 텍스트의 위쪽을 top side 아래쪽을 bottom side로 보아 annotation에 있는 GT 좌표를 다시 정렬했습니다. 실제 코드를 확인해보면 기존 json 파일을 가지고 좌표 정렬만을 제안하는 방법으로 변경하는 코드가 하나로 구현돼 있습니다. 그러니까 위의 (b) 이미지에서 예시를 들자면 ‘PARIS’란 단어가 거꾸로 있다고 해서 아래부분을 top으로 보지 않겠단 얘기입니다. 글자 S위의 점 즉 항상 왼쪽 상단 점을 starting point로 두겠다는 것입니다.
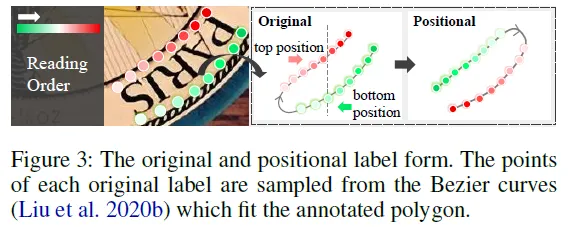
3.3 Explicit Point Query Modeling
3.3.1 Priors Points Sampling
인코더 블록에서 제안됐던 바운딩 박스의 대략적인 좌표를 가지고 실제 각 박스 마다 N개의 점 좌표를 예측 해 각 텍스트 쿼리에 (control point query) positional encoding query를 더하는 방법을 가리킵니다.
디코더에서 학습되는 control point query가 다음과 같이 정의된다고 할 때
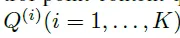
TESTR에서의 각 control point 쿼리는 다음과 같이 구성됩니다.
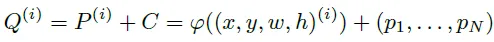
P^(i)는 바운딩 박스의 좌표에 대해서 encoding한 positional query를 C^(i)는 content query로 모든 텍스트 쿼리가 공유하는 쿼리 임베딩입니다. 모든 control point point query가 같은 content query를 공유하지만 positional query는 달리 받아 각자 다른 텍스트를 가리키게 됩니다.
DPText에서는 positional query 부분이 직접적인 점의 좌표로 표현이 됩니다. polygon이 N개의 점으로 그려진다면 N개의 좌표를 예측합니다.
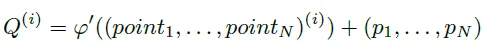
각 점이 상하에 같은 개수로 있고 중앙점을 기준으로 일반적으로 거의 같은 거리만큼 떨어져 있다는 것을 전제로 다음과 같이 각 포인트의 x, y 값이 계산됩니다.
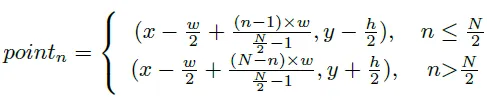
이렇게 더 정확하게 각 점의 좌표를 나타내는 방법이 학습을 더 빠르게 수렴하도록 도왔다고 합니다.
3.3.2 Point Update
다음은 위 모델의 구조도에서 디코더만을 따온 것인데요.
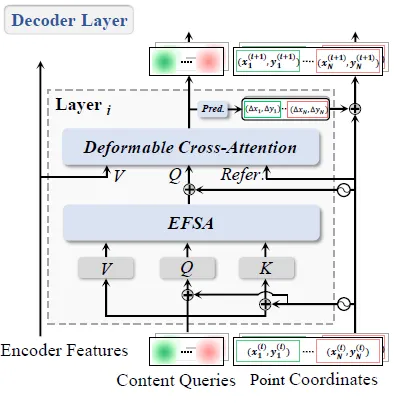
디코더 블록마다 뒷단에 prediction head를 통과해 오프셋이 계산되는데요 이를 토대로 각 point query가 업데이트 됩니다. TESTR의 경우 디코더의 인풋으로 들어가는 control point query에 한번 더해졌던 것과는 달리 매 레이어 마다 업데이트된 point query가 content query에 더해져 이후 attention이 수행됩니다.
3.4 Enhanced Factorized Self-Attention
기존의 Factorized Self Attention에 추가적으로 circular convolution 한 층을 더해 non-local한 intra self attenton에서 circular shape을 학습하도록 했는데요. 그 과정을 조금더 자세하게 풀어서 설명드리겠습니다.
우선 Factorized Self Attention은 두가지 attention으로 구성됩니다. 같은 쿼리안의 서브쿼리간의 attention을 그리는 intra self-attention과 다른 쿼리의 같은 인덱스 서브 쿼리간의 그려지는 inter self-attention입니다.
각 서브쿼리간의 attention을 구하는 SA_intra에서 circular shape에 대한 구조 정보가 학습되지 않을 것을 우려해 circular convolution을 적용합니다.
우선 기존 방법대로 self-attention이 수행되어 Q_intra 쿼리가 계산됩니다. 이때 self-attention 시 value의 경우 positonal query가 더해지지 않은 content query를 사용합니다.
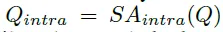
SA_intra와 동시에 Q_local 쿼리가 만들어지는데요 composite query를 circular convolution layer에 통과시키고 Batch Norm과 Relu layer를 거쳐서 만듭니다.
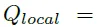
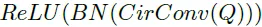
이후 Q_intra와 Q_local 쿼리를 더하고 추가적인 계층을 통과시켜 Q_fuse를 얻습니다. 두 쿼리를 더한 후 Linear Norm을 수행하고 Content query를 더해주는데요 이는 잔차를 더하는 것과 같은 효과를 준다고 합니다. 이후 FC layer를 통과시키고 다시 한번 더 Layer Norm을 거쳐줍니다.
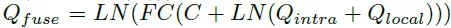
그리고 이렇게 구해진 Q_fuse를 가지고 순서대로 SA_inter과 cross attention이 수행됩니다.
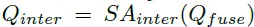
여러 커널 사이즈로 실험한 결과 커널 크기가 5 (4 neighbors와 convolution 연산을 수행함)인 convolution layer를 하나 추가했을 때가 제일 좋은 결과를 보였다고 합니다.
4. Experiments
총 3개의 arbitrary-shaped scene text 데이터셋인 Total-Text, CTW1500, ICDAR19 ArT에 대해서 다음의 실험을 진행했습니다. Ablation study같은 경우 파인튜닝의 과정 없이 Total-Text에 대해서 진행되었습니다.
이번주 세미나 때 TESTR을 소개했었는데요 왜 어떤 경우에는 단어 단위로 텍스트가 나뉘어 지고 언제 라인 단위로 검출이 되는지에 대한 질문을 받았었는데 답변을 하지 못했었습니다.
논문의 실험 부분을 조금 더 신경써서 읽었다면 바로 답을 할 수 있던 질문이었다고 생각돼 개인적으로 조금 아쉬웠습니다.
그 이유는 각 데이터셋 마다 어노테이션 형태가 다르기 때문입니다. Total-Text의 경우 word-level의 annotation이 주어진 반면 CTW1500의 데이터셋은 line-level의 annotation이 제공돼었습니다.
4.3 Comparison with State-of-the-art Methods
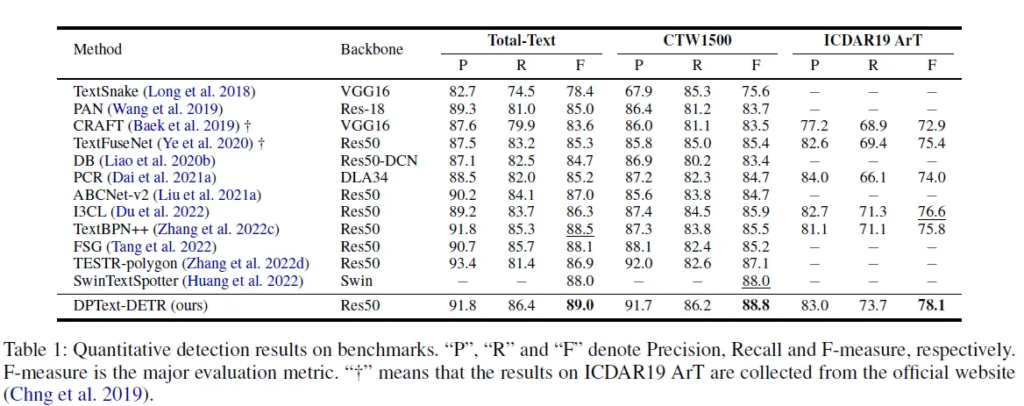
3개의 데이터셋에 대해 기존 모델들과의 검출 성능을 비교한 표가 되겠습니다. Precision과 Recall의 조화평균값인 F 지표를 기준으로 설명하면 3 데이터셋에 대해서 DPText의 성능이 제일 우수했습니다.
4.4 Ablation Studies
본 연구에서 제안하는 방법들이 학습 수렴 속도를 늘리는 방법으로 제안된 것들이라 ablation study는 사전학습 없이 Total-Text 데이터셋에 대해서 초기 부터 학습 시켜 수렴하는 것을 지켜본 실험입니다. 평가는 아래와 같이 Total-Text, Rot.Total-Text (Total-Text이미지를 여러 각도로 회전시켜 구성한 데이터셋), Inverse-Text(여러 데이셋으로 부터 inver text를 포함한 이미지로 구성한 데이터셋으로 40%가 inverse text를 포함함)에 대해서 진행되었습니다.
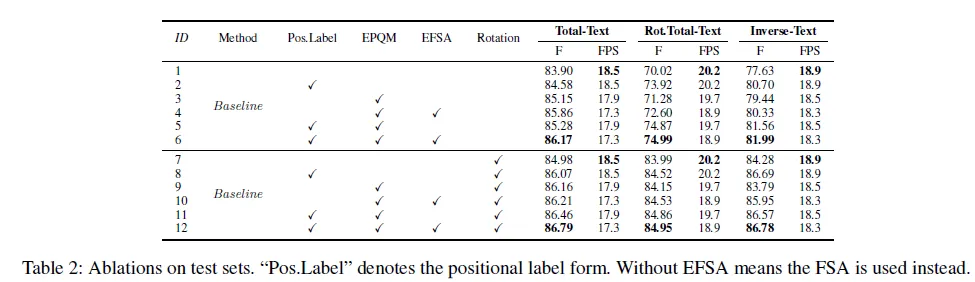
사전 학습 없이도 86.79의 성능을 달성한 것을 강조합니다. (Table 2. 라인 12) (Table 1. 에서의 F score: 89.0)
4.4.1. Positional Label Form
(라인 1, 2 참고) position label을 사용했을 때 세 데이터셋에서 모두 차례대로 0.68, 3.90, 3.07의 성능 향상을 보입니다. Rotation 증강이 적용이 함께 적용됐을 때 더 우수한 성능을 보입니다.
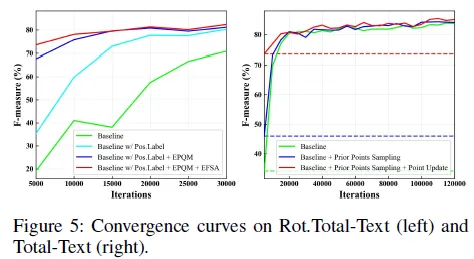
Figure 5의 좌측 그래프를 참고하시면 position label대로 학습했을 때 (기존의 그냥 텍스트 방향에 맞춰진 라벨을 가지고 학습한) 베이스라인 보다 수렴하는 속도가 빠릅니다.
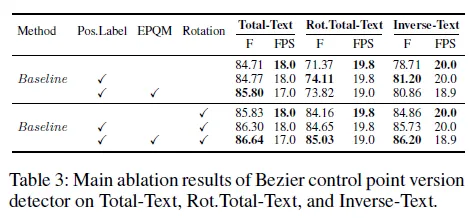
control point에 대한 annotation을 다각형의 좌표로 설정한 게 아닌 베지어 곡선을 구성하는 제어점의 좌표로 나타내는 경우에도 제어점의 포맷을 positon label 포맷에 맞춘 경우 성능이 더 높았습니다.
4.4.2. EPQM
(table 2 1, 3번 라인 참고) 베이스라인 대비 기존 Guidance generator를 EPQM 모듈로 변경했을 때 세 데이터셋에 대해 성능이 향상됐습니다.
Figure 5를 참고하시면 베이스라인에 positon label을 적용한 방법에 추가적으로 EPQM까지 더했을 때 수렴이 더 빨리 이루어 졌습니다. Table 3을 참고했을 때 Rotation 증강을 적용한 것과 하지 않은 것 모두 그리고 세개의 데이터셋에 대해서 성능 향상을 확인할 수 있었습니다. 다만 Rot.Total-Text, Inverse-Text에서 EPQM을 적용하지 않고 Positon label만을 사용했을 때의 성능이 조금 더 높았습니다. 그 점 참고해주세요.
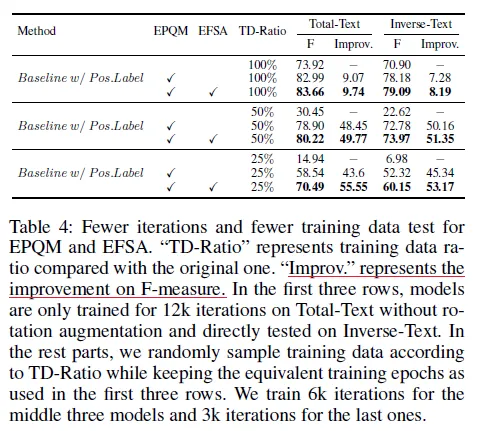
또한 EPQM을 더했을 때 적은 양의 데이터로와 더 적은 횟수로 학습했을 때도 하락폭을 줄일 수 있었습니다.
4.4.3. EFSA
(Table 2의 3, 4번 & 5, 6번 라인 참고) 두 경우 모두 EFSA를 적용했을 성능이 향상됐습니다. 최종적으로 Postional lable, EQPM, EFSA 세가지를 모두 적용했을 때의 성능이 제일 높았습니다.
(Table 4 참고) EPQM과 함께 데이터 및 학습 횟수 감소로 인한 성능 하락 폭을 줄였습니다. EPQM과 EFSA를 동시에 사용하는 것이 성능 하락폭을 더 크게 줄이는 데 기여함을 확인할 수 있는 실험이었습니다.
(Figure 5 참고) position label, EQPM, EFSA를 모두 적용한 (빨간 선) 방법의 수렴이 제일 빠릅니다.
4.5 What Makes Faster Training Convergence?
앞서 실험 결과로 EPQM이 성능 향상에 기여함을 확인하였고 Figure 5의 좌측 그래프로 빠른 수렴을 촉진한다는 것도 확인하였는데요 다음 실험은 EPQM의 어떤 요소가 수렴 속도를 높였는지에 대한 것입니다.
Encoder에서 제안된 영역에 대해 대략적인 점의 좌표를 계산해 composite query를 구성하기 위해 positional query로 더했던 단계를 Prior Points Sampling이라고 하며 각 디코더 레이어 마다 prediction head (최종 예측을 위한 prediction head와는 다른 것)을 통과해 예측됐던 오프셋을 더해 갱신한 단계를 Point Update라고 나눠놨습니다. 아래 Table 5를 참고하니 두 단계 모두 속도 향상에 기여했음을 확인할 수 있었습니다. Figure 5 (b) – 좌측 그래프로도 동일한 결과를 확인할 수 있습니다.

디코더 블록에서 cross attenton 시 reference point로 사용되는 positional query를 매 디코더 블록마다 갱신 해 reference point가 정확해짐으로써 더 나은 결과를 보인 게 아닌가라는 얘기를 달았습니다.
5. Conclusion
본 연구는 TESTR의 한계였던 coarse한 query formuation problem, non-local한 SA_intra로 circular form이 학습되지 않았던 문제 , human-centered label form problem들을 지적하며 각각 EPQM, EFSA, positional label로 해결하고 검출 정확도와 수렴 속도가 향상되는 결과를 보였습니다. 또한 inverse text에 대해서도 강인함을 보인 연구였습니다.
읽어주셔서 감사합니다. ^|^
본 연구는 TESTR의 한계였던 coarse한 query formuation problem, non-local한 SA_intra로 circular form이 학습되지 않았던 문제 , human-centered label form problem들을 지적하며 각각 EPQM, EFSA, positional label로 해결하고 검출 정확도와 수렴 속도가 향상되는 결과를 보였습니다.