안녕하세요 오늘도 지난시간에 이어서 Video Summarization 연구를 소개하려 합니다. 지난 리뷰[Link]에서는 입력된 비디오에서 맥락적으로 중요한 부분을 선별하기 위한 데이터셋과 구조를 소개했습니다. 이와 다르게 본 논문은 영상에서 중요한 부분 선별이라는 문제를 조금 더 광범위하게 정의했습니다. 비디오 쿼리에 대해 사용자의 특별한 요청이 있을 때, 요청에 맞는 요약을 생성하는 테스크(query-focused vide summarization, QFVS)와, 특별한 요청이 없을 때도 문맥적으로 적절한 요약을 생성하는 테스크(generic video summarization)를 모두 수행하기 위한 통합된 프레임워크인 CLIP-It을 제시하는데요, 리뷰를 통해 해당 논문을 소개해보겠습니다.
본 논문이 제시된 배경
논문 소개에 앞서 연구의 제시 배경에 대해 알아봅시다. 본 논문은 제목에서 예측할 수 있듯이 CLIP을 이용하는 연구입니다. 특히 CLIP을 이용해 앞서 언급했던 query-focused vide summarization(이하 QFVS)와 generic video summarization(GVS)를 동시에 수행하는 통합 프레임워크를 제시하게 된 것입니다. 앞선 연구에는 이러한 통합된 요약 과제를 수행할 수 있는 구조는 없었으며, 해당 연구 이후에도 제가 확인한 연구에서는 통합 프레임 워크를 베이스라인으로 삼는 논문은 아직 확인하지 못했습니다. (찾는 중 입니다) 제가 확인한 대부분의 연구는 GVS를 다루고 있으나, 비디오 요약이라는 테스크 자체가 주관성이 큰 많큼 QFVS 역시 중요한 비디오 요약의 과제 중 하나입니다. 따라서 두 문제를 동시에 해결하기 위한 통일된 프레임워크는 매우 유의미한 성과라고 생각됩니다.
본 논문은 QFVS와 GVS의 통합을 CLIP이라는 VLM을 통해 해결했습니다. 논문에서 언급되길, 본 논문 이전에는 언어모델의 능력이 video summarization 테스크에 활용되지 않았다고 합니다. 따라서 본 논문에는 비디오 요약에 VLM을 활용하는 방법과 그 성과를 제시한데도 의미가 큽니다. 정리하면 본 논문은 언어모델이 비디오 요약에 적용된 사례가 적은 시기에, 언어모델의 추론 능력을 활용하여 비디오 요약의 중요한 테스크인 QFVS와 GVS를 통합하는 프레임을 제시한 논문입니다. 앞서 말씀드렸듯이 상이한 두 테스크에 VLM을 통해 통합된 프레임워크를 제시한 것과, 언어모델의 지식 활용 방안과 이를 위한 프레임워크를 제시한 것에 의미가 있습니다.
통합된 프레임워크의 의미

위 그림은 논문이 제시한 CLIP-it 구조가 해결할 수 있는 비디오 요약 과제를 시각화 한 것입니다. 사용자의 입력 없이도 비디오의 중요 정보를 모두 요약할 수 있는 1행의 Generic Summary와 입력된 쿼리에 맞게 요약을 생성하는 2,3행(Query: All ~)의 결과를 확인할 수 있습니다. 이처럼 본 논문은 비디오와 함께 요청되는 입력이 있을때도, 없을때도 요약을 생성할 수있는 통합된 프레임워크를 설계했습니다.
Methods
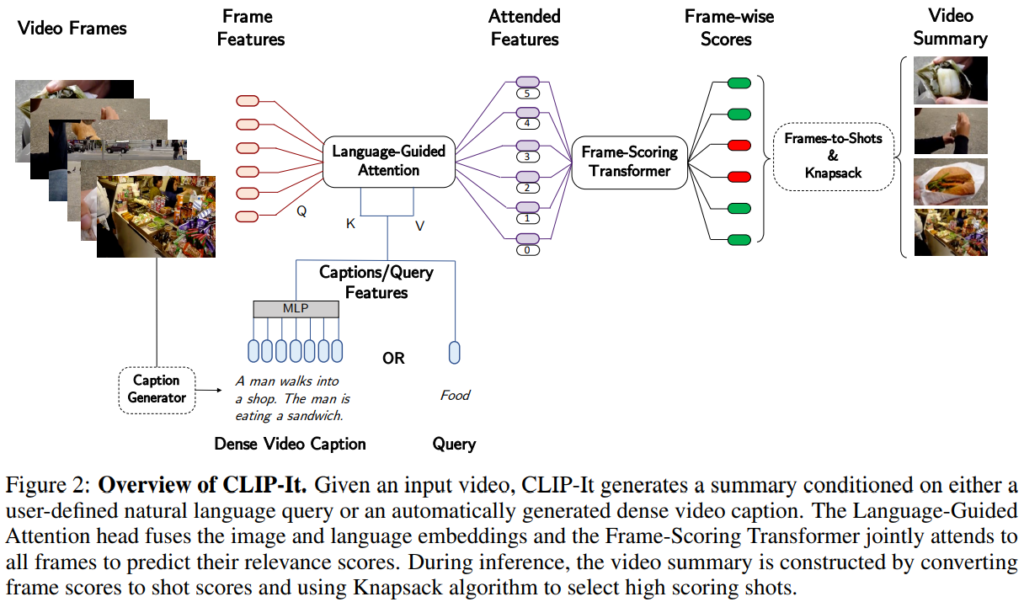
본 논문은 통합된 프레임워크를 위해 언어모델을 활용하여 텍스트 정보로 비디오 요약을 생성하는 구조(Figure 2)를 제시했습니다. 이때 사용되는 텍스트 정보를 쿼리가 있을때는 쿼리의 CLIP 임베딩으로, 쿼리가 없을때는 캡션 생성 모델로 생성된 캡션을 활용했습니다. 즉, CLIP 임베딩으로 텍스트와 이미지를 공동 임베딩 공간에 임베딩하여 텍스트 가이딩(guided)된 요약을 생성하였으며, 일반 비디오에서 캡셔닝을 통해 GVS를 QFVS 프레임에서 해결할 수 있도록 한 것으로 두가지 측면에서 언어모델의 능력을 활용하였습니다. 위의 구조에서 주목할 만한 부분은 Language-Guided Attention과 Frame-Scoring Transformer입니다. 두 구조를 하나씩 소개하겠습니다.
Language-Guided Attention
CLIP-it은 *공통 공간에 임베딩된 이미지와 텍스트 입력을 attention 구조를 통해 정보를 혼합합니다. *attention 연산을 수행할 때는, 이미지 임베딩이 쿼리, 텍스트 임베딩이 키와 값(value)이 되어 아래의 수식과 같이 연산을 수행하게 됩니다.

* “공통 공간에 임베딩”되는 것의 의미: 멀티모달리티로 제공되는 입력이 동일한 의미를 가질 경우 가까운 feature로 임베딩 되는 것
* attntion 연산: 쿼리에 대해 값으로 표현하는 행위
Frame-Scoring Transformer
해당 구조는 비디오와 쿼리(요청 혹은 캡션)의 융합된 정보(Fig2의 Attended Features)를 기반으로 프래임 당 중요도 점수를 예측하는 구조입니다. 기존의 비디오 요약 프레임워크는 LSTM 혹은 Graph 기반의 구조를 통해 중요도 점수를 예측했는데, 본 구조는 Transformer와 positional encoding을 활용하여 비디오의 맥락 정보를 모두 고려한 요약을 생성하였다고 강조하고 있습니다.
이는 앞선 Language-Guided Attention를 통해 입력된 비디오가 잘 가이딩되었기에 가능한 것으로 예측됩니다.
Other Details
위의 구조 외에 디테일로는 다음과 같습니다. 본 논문은 비디오의 영상 정보 임베딩을 위해(f_img) GoogleNet, ResNet, CLIP을 활용하였고, CLIP이 가장 좋은 성과를 냈습니다. 또한 Text encoder(f_txt)로는 CLIP을, 캡션 생성을 위해서는 Bi-Modal Transformer를 활용했다고 합니다.
목적함수
구조의 학습을 위해 사용된 목적함수는 3가지 입니다: Classification loss, Reconstruction Loss, Diversity Loss 본 논문은 지도학습과 비지도학습에 모두 활용가능한 구조를 보이기 위해 지도학습용 목적함수(Classification loss+Reconstruction Loss+Diversity Loss)와 비지도학습용 목적함수(Reconstruction Loss+Diversity Loss)를 제시합니다.
Classification Loss는 각 프레임이 요약된 비디오에 포함여부(1/0)인 이진 라벨을 예측하기 위한 것 입니다. 아래의 수식과 같이 weighted binary cross entropy와 같습니다. 이때 단순한 binary cross entropy가 아닌 가중치를 더한 이유는, 이진 라벨의 long-tailed 문제 때문입니다. 즉, 요약에 포함될 확률보다 포함되지 않을 확률이 높아 발생할 수 있는 학습의 bias를 예방하기 위함입니다. 가중치 w는 입력(x*_i)가 keyframe 이라면 (# of keyframe)/(# of all frame), keyframe이 아니라면 1 – (# of keyframe)/(# of all frame) 입니다.
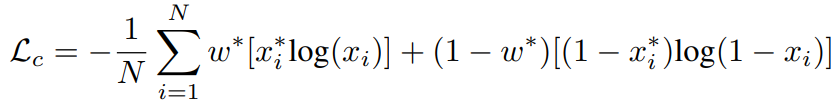
Reconstruction Loss는 각 연산이 비디오의 프래임 별 정보를 잘 보존하도록 설계하기 위한 것입니다. 선별된 프레임들에 대해서(x∈X) y^는 frame-score transformer의 출력을 1X1 convolution layer로 디코딩 한 것으로, 해당 출력이 original feature 인 CLIP 임베딩을 원복할 수 있도록 설계되었습니다.
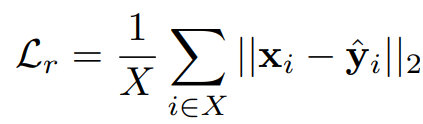
Diversity Loss는 요약된 비디오에 대해 선별된 프레임 정보끼리의 다양성을 높여 중복된 정보가 요약에 포함되지 않도록 설계한 것입니다. 앞선 Reconstruction loss와 동일하게 decoding된 요약 프레임의 특징 벡터 y^을 활용하여 아래의 수식과 같이 서로 유사도가 낮아지도록 diversity loss를 설계했습니다.
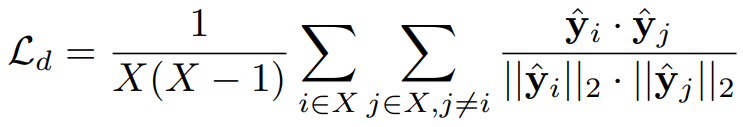
실험
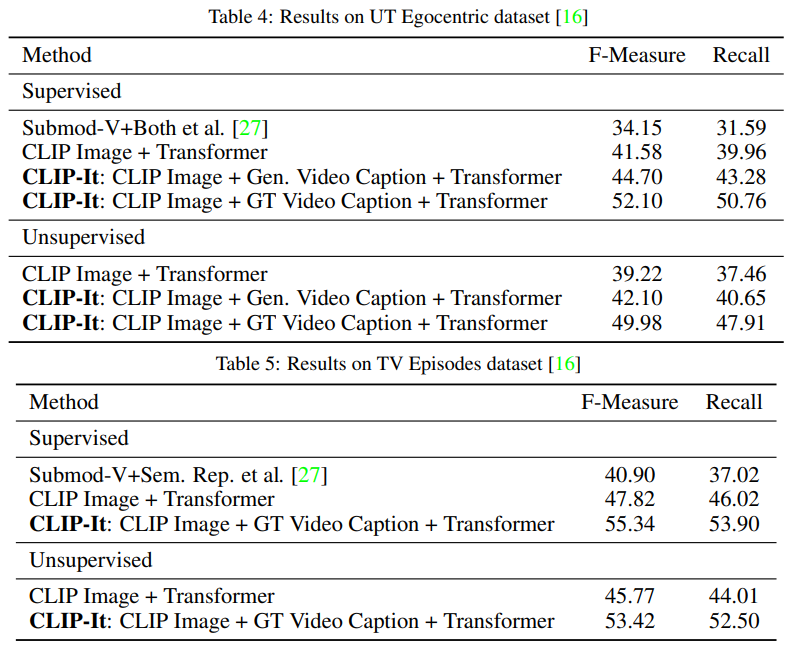
먼저 GVS에 대한 논문의 주요 실험은 아래 Table1/Table2와 같습니다. 유명한 벤치마크 데이터셋(SumMe/TVSum)에 대하여 기존 방법론과 비교한 것인데요, 또한 제안 방법에 대한 self-evaluation도 각 테이블의 굵은선 아래에 제공되었습니다.
먼저 실험에 사용된 데이터셋으로는 각 벤치마크에 대해 Standard/Augmented/Transfer 세팅에서 실험되었습니다. 이는 기존 연구의 실험세팅에 따른것으로, Standard는 일반적인 SumMe/TVSum 데이터셋을 활용한것, Augment setting은 각 벤치마크 데이터셋과 다른 데이터셋 3가지(SumMe or TVSum, OVP, Youtube)를 학습에 혼합하여 사용한것, Transfer는 테스트에 사용되는 벤치마크 데이터셋을 제외한 다른 데이터셋 3가지(SumMe or TVSum, OVP, Youtube)로 모델을 학습한 것입니다.
실험 결과 제안한 CLIP-It 방법이 기존 방법론들 대비(굵은 중앙라인 위쪽) 모든 실험 세팅에서 우수했음을 확인할 수 있습니다. 또한, 굵은 중앙 라인 아래쪽의 Self-evalutaion 실험에서도 Image encoder를 CLIP을 사용하고 Video Caption을 사용한 제시구조(CLIP-It)이 가장 우수한 성능을 보였음을 확인할 수 있습니다.
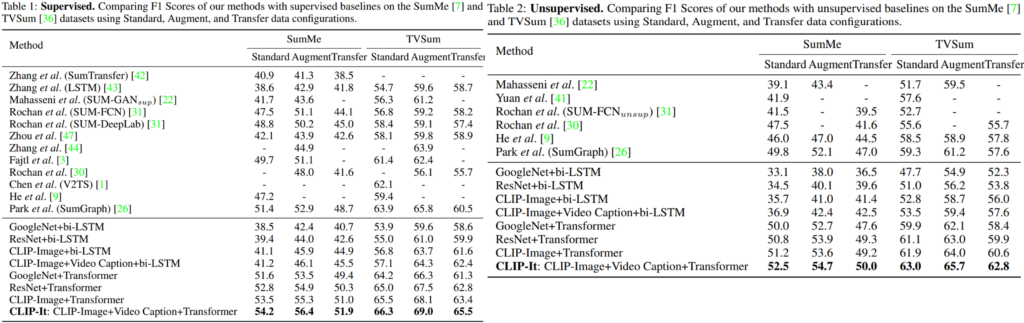
다음으로는 QFVS 실험 결과입니다. 해당 실험 데이터셋으로는 UT Egocentric 이 활용되었으며 위의 GVS와 유사하게 앞선 방법론들과의 비교를 굵은 중앙선 위에, Self-evaluation을 굵은 중앙선 아래에 공개했습니다. 실험 결과 모든 비교 세팅중에서 CLIP-It이 우수함을 통해 제안된 구조가 효과적임을 확인할 수 있습니다.
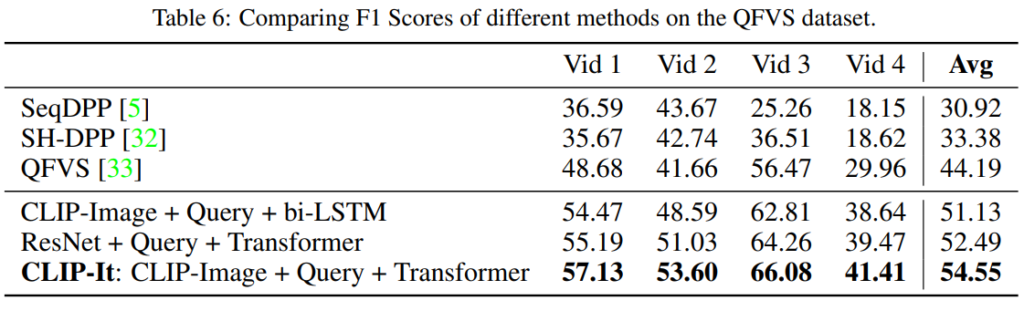
논문은 GVS를 위해 Bi-Modal Transformer를 활용했습니다. 그러나 캡셔닝 모델의 성능 향상에 따라 프레임워크가 수행하는 비디오 요약 테스크의 성능도 개선될 수 있습니다. 본 논문은 캡션 활용 능력의 상한을 확인하기 위해 기존 연구[1]가 제시한 ground truth caption을 활용하여 Table4/Table5에서 성능을 확인하였습니다. GT를 사용할 경우(GT Video Caption) GVS 테스크에서 높은 성능향상을 보임을 통해 제안된 텍스트 가이딩 프레임워크가 효과점임을 다시한번 확인하였습니다.
Reference
[1] Enhancing video summarization via vision-language embedding
본 논문은 언어모델을 활용한 비디오 요약의 통합 프레임을 제시한 논문입니다. GVS와 QFVS 뿐 만 아니라 지도학습/비지도 학습을 모두 수행할 수 있는 통합 프레임을 제시하였습니다. 특히 QFVS 프레임을 활용해 GVS까지 수행하고자 하는 아이디어가 흥미롭습니다. 두가지 테스크를 통합하는 아이디어가 매우 유의미하다고 생각하나, 통합된 프레임워크에 관련된 후속 연구를 아직 찾지 못한 점이 아쉽습니다. 찾게 된다면 다시한번 소개드리겠습니다. 감사합니다.
안녕하세요, 황유진 연구원님. 좋은 리뷰 감사합니다.
읽다보니 모델 구조랑, 문제 세팅에 궁금한 점이 있어 질문 남깁니다.
1. image feature는 프레임별로 CLIP 이미지 인코더로 생겨서 쿼리 피쳐를 만드는 것으로 보입니다. language 입력의 경우는 사람이 정의하거나 자동 생성되기에 다양한 형태가 올 수 있는데, “a photo of [CLS]” 형태의 간단한 프롬프트로 학습한 CLIP 텍스트 인코더를 그대로 사용한것이 적절한지 궁금합니다. 혹시 이와 관련된 추가적인 분석이나 언급이 있었나요?
2. 문제 세팅을 읽다보니 QFVS, GVS를 동시 수행 할 수 있는게 다양한 application에서 중요한 것 같습니다. 본 논문에서 caption generator를 사용해서 쿼리가 없다면 스스로 만들었듯, 이제 prompt learning이나 LLM을 사용해서 query기반 비디오 요약을 어렵지 않게 GVS로 확장할 수 있을 것 같은데 통합된 세팅을 이 이후 논문들이 고려하지 않았다면 보통 어떤 세팅을 사용하나요?
안녕하세요 댓글 달아주셔서 감사합니다.
1. 프롬프트의 형태에 대해서는 기존 방법의 조건과 맞춘것으로 통제된 변인으로 보시면 좋을것 같습니다. 학습에 효과적인 프롬프트를 연구하는 방법론도 따로 있으니 해당 연구를 통해 효과적인 프롬프트에 대한 분석을 확인하시면 좋을 것 같습니다.
2. LLM을 활용하여 통합된 프레임워크를 제시하는 연구는 종종 있었습니다. 그 예시로는 V2Xum-LLM (http://server.rcv.sejong.ac.kr:8080/2025/05/19/aaai2024v2xum-llm-cross-modal-video-summarization-with-temporal-prompt-instruction-tuning/)도 해당합니다.
다만 LLM을 이용해 GVS와 QFVS를 통합하는것은, 비디오 요약 테스크가 GVS와 QFVS를 동시에 수행할 수 있어야 한다는 저자의 철학이 반영된 것으로, 모두가 따라야하는 원칙이 아니였기에 이 이후의 논문은 기존에 많이 연구되었던 단일 GVS/ QFVS를 타겟으로 연구를 수행하기도 합니다.
감사합니다.
유진님 좋은 리뷰 감사합니다.
해당 연구가 최초로 QFVS와 GVS를 통합한 연구로 이해하였습니다. GVS의 경우는 캡션 생성 모델을 이용하여 영상에 대한 caption을 생성하여 이루어진다는 점에서 어느정도 제약이 있을 것 같습니다. 여기서 캡션 생성 모델은 비디오에 전체에 대한 캡션을 생성하는 것인가요? 키프레임을 추출하여 각각에 대한 캡션을 생성하는 것 인가요? 전자라면, 영상에 전체에 대한 요약 정보를 생성해야하므로 난이도가 다소 높을 것 같고, 따라서 사용한 캡션 생성 모델의 성능이 어느정도 되는 지 궁금합니다. 또한, 후자라면 프레임마다 달라지는 요약 정보를 어떻게 활용하는 지 궁금합니다.
안녕하세요 댓글 달아주셔서 감사합니다.
우선 GVS를 위한 텍스트 요약은 전자의 방식으로 생성됩니다. 우선 기존 연구인 Bi-Modal Transformer 를 이용하여 캡션을 생성하였습니다. 해당 논문은 [BMVC 2020]A Better Use of Audio-Visual Cues: Dense Video Captioning with Bi-modal Transformer 에서 제시한 방법으로 ActivityNet Captions dataset에 대해 당시(2020년) SOTA를 달성했습니다. 자세한 성능은 아래 논문 링크를 참고해주세요.
https://arxiv.org/pdf/2005.08271
감사합니다