안녕하세요. 이번 리뷰는 조금 색다른 벤치마크 관련 논문을 가져와 보았습니다(무려 150장). 바로 physical 적인 정보를 다룬 VQA 데이터셋인데요. 특히 VLM(MLLM) 의 physical 이해 능력을 벤치마킹하며 내용을 다루고 있습니다.
제가 접근하고자 하는 로봇 액션 연구와 관련된 큰 방향성은 “1. LLM(혹은 MLLM)을 통해 전반적인 추론 상식을 갖춘 상태로 high-level task planning” + “2. 그 중간중간 reasoning 과정 중 환경에 대한 시각 인지는 VFM(SAM, Grounding DINO) 혹은 VLM(GPT4o 같은 MLLM)의 능력을 활용” + “3. low-level action 은 기존 motion planning, Imitation Learning policy 를 활용” 의 경우로 생각해보고 있습니다. 이 과정에서의 꽤나 중요한 전제는 환경에 대한 시각인지는 오롯이 VFM 혹은 VLM에 의존하고 있다는 점이며, 이는 해당 파트의 능력이 완벽하지 않다면 로봇의 조작 실패로의 영향을 끼치게 된다는 아주 중요한 요소가 될 수 있다고 생각합니다.
그런 의미에서 VLM의 환경에 대한 시각인지 시 환경의 물리적 요소를 이해한다면 참 좋을 텐데요. 아쉽게도 저희 팀의 미니챌린지 과정 중 실제 로봇을 움직이는 알고리즘 속에선 물리적 요소를 이해한 상태라곤 받아들이긴 힘들었습니다. 추후 연구적으로 개선해 볼 여지가 있다면 VLM의 Physical 적인 부분에 있어서의 개선도 고려해보면 좋겠다고 생각이 문득 들었고, 그래서 해당 Physical 벤치마크 논문에 관심을 갖게 되었습니다. 해당 논문은 benchmark 관련 분석 외에도 저자들이 구성한 prompting 기반의 Agents 파이프라인도 있다보니 지루하지 않게 읽었는데요. 그럼 지금부터 리뷰 시작해보도록 하겠습니다.
1. Introduction

요즈음의 연구들에서 VLM은 embodied agents를 만드는 데 있어 중요한 어떤 툴로써 자리잡게 되었습니다. 하지만 VLM의 physical world understanding 능력은 아직 부족한 수준이고, 이는 embodied agents 연구들로 하여금 real-world application으로의 활용을 저하시키는 결과로 이어졌습니다. 최근 연구들에서 예를 들면 깨지기 쉬운 물체를 잘 못 다루거나, 적절한 파지 affordance를 인식하지 못하는 것과 같은 오류가 있어왔고(MOKA, NEWTON, PhyGrasp), 저자들은 해당 문제를 해결하기 위해 PhysBench를 만드는 것에 모티브를 얻었다고 합니다.
위의 사진의 예시를 보시면, 기존의 Common VQA 벤치마크의 경우에는 단순히 visual content나 일반화된 지식 혹은 common sense적인 지식에 대한 질문만 담는 반면, PhysBench는 4가지 영역에 걸쳐 각각 물리 세계 이해를 강조하는 방식으로 VQA를 수행하도록 설계되었습니다. 해당 물리적 관점의 4가지로 major class 분류는 다음과 같습니다.
- Physical Object Properties (물체의 물리적 속성 관련)
- Physical Object Relationships (물체 간 물리적 관계 관련)
- Physical Scene Understanding (장면의 물리적 이해 관련)
- Physics-driven Dynamics (물리 역학 관련)
앞서 언급한 문제를 조금 더 파고들며 저자들은 다음의 2개 물음을 던졌는데요. (1) VLMs이 물리 세계에 대한 이해를 확실히 가지고 있기는 한가? 물리적 이해 능력이 없다면 어떤 요소가 이러한 한계를 만드는가? (2) 만일 그렇다면 VLMs의 물리 세계 이해 능력을 어떻게 향상시키고, MOKA와 같은 embodied agent에서도 효과적인 배포를 촉진할 수 있을까? 입니다.
여러 실험 속에서 본 논문은 해당 물음에 대한 분석을 내놓았던 것으로는 다음과 같은 것들이 있었습니다.
(1) 현재 대부분의 VLM들은 물리 세계에 대한 이해가 부족한 것이 사실이며, 특히 물리적 장면 이해와 물리 기반 역학에서 그러하고, 성능으로는 오픈 소스 모델보다 독점 소스 모델들(GPT 등)이 훨씬 뛰어난 성능을 보였습니다.
(2) VLM의 학습 데이터는 필요한 물리적 지식이 부족하여 성능 저하의 주요 원인일 가능성이 컸습니다. 고로 fine-tuning했을 때 성능이 향상되었습니다.
추가로 저자들은 총 75개나 되는 다양한 VLM들에 대해 실험을 진행했는데요. 각각의 기존 VLM 모델들은 물리 세계에 대한 이해에 인간이 이해하는 것보다 더 심한 상당한 지식 격차가 있었습니다. 이는 VLM 모델들의 학습 데이터엔 결국 internet-scale의 일반적인 지식이 위주이지, 물리적 지식에 타겟된 요소가 부족하기 때문일 가능성 높음을 시사할 수 있었다고 볼 수 있었습니다. 그래서 저자들은 이 기존 다양한 VLM들의 physical understanding 능력을 높이기 위해, fine-tuning 방법론 말고 agent-based 방법론도 하나를 또 내놓고 PhysAgent라고 제안했습니다. PhysAgent는 사전 physical 지식과 expert model assistance를 활용하여 물리 세계 이해 능력을 높이는 데 중점을 둔 fine-tuning 방법론이 아닌 prompting 기반의 agent로써의 활용 방법론이라고 보시면 될 것 같습니다. 위에서 잠깐 분석에 대해 언질했지만, PhysBench에서 VLM의 오류 원인을 분석한 결과로는 grounding 부정확성과 지식 부족이 주된 원인이었기 때문에 PhysAgent에서는 VFM들을 통합하여 grounding 능력을 향상시키고 VLM이 어려움을 겪는 작업(예: 깊이 추정 및 수치 거리 계산)을 처리하는 데 도움을 주는 방식을 취했습니다. 또한 물리 세계에 대한 필수 지식 등을 추가로 내장하기 위해 지식 메모리 모듈을 선택적으로 호출하는 방식을 통합하는 파이프라인이 대략적인 PhysAgent 의 대략적인 흐름이라고 봐주시면 될 것 같습니다.
자세한 사항은 밑에서 더 다루도록 하겠고, 또한 본 논문의 contribution은 다음과 같습니다.
- VLM의 물리적 세계 이해 성능을 평가하기 위한 대규모 벤치마크 제시.
- 기존 VLM이 물리적 세계 이해 능력이 부족한 이유에 대한 분석과 통찰 제시.
- VLM의 물리적 세계 이해 능력을 향상시키는 통합 접근법인 PhysAgent 제안.
- 해당 방법론이 MOKA같이 VLM을 활용한 embodied agent 배포에 있어 크게 용이함을 입증.
2. Related Works

위 테이블은 이전 벤치마크 연구 비교인데요. 물리적 추론을 위해 설계된 벤치마크 연구로 기존에 ContPhy, Physion++ 이라는 연구들이 있었으나, 이것들은 수동으로 미리 정의된 처리 논리에 의존하거나 특정 작업에만 국한되었던 것과는 달리, PhysAgent는 VLM의 일반화능력에다가 + open-ended 문제를 해결하는 능력을 유지할 수 있었다고 합니다. 더불어 PhysAgent의 파이프라인을 제시하다보니 PhysBench 벤치마크 실험에 대해 GPT-4o의 zero-shot 성능을 18.4퍼 향상시킬 정도를 보였다는 점도 차별성이 있긴 했습니다. 추가로 또 MOKA 기법에도 실제 PhysAgent 파이프라인의 모듈성 활용도 여부도 직접 실험해보았다는 언급으로 보아, real-world agent 활용에서도 충분히 유의미한 결과를 보일 수 있었다의 의미도 함께 가져올 수 있었던 것 같습니다.
이전 physics understanding QA 벤치마크들에 비해 이만큼 차별성이 있더라~ 정도로 이해해주시면 될 것 같습니다. 추후에 조금 언급은 될테지만, 저자들의 벤치마크 데이터셋 size가 이전 것들에 비해 그렇게 매우 많은 정도는 아닌 것을 볼 수 있는데, 해당 수량의 데이터만으로도 유의미한 분석과 결과를 이끌어 낸 걸 보면, physics 관련 데이터는 양보다 질이 좋아도 잘 working 할수도 있나보네? 싶은 생각도 조금 듭니다.
3. PhysBench
3.1 Overview of PhysBench
Embodied AI에게 있어 물리 세계를 이해하는 것은 시스템이 물체와 환경의 속성, 역학 이런 걸 모두 인식하고, 해석하고, 예측할 줄 알아야 한다는 것이므로 매우 필수적인 요소이면서도 그 자체로 근본적으로 어려운 과제입니다. 물리세계이해 라는 것의 속뜻에는 물체의 속성, 물체 간 관계, 환경 장면 해석, visual grounding, 물리원칙에 따라 scene의 상호작용 결과 예측이 있다는 셈이죠. 기존 연구의 데이터셋들은 이런 점을 간과하고 이미지 content와 상식 추론 자체에만 주로 집중해왔었습니다.

그래서 위 그림을 보면 PhysBench는 물리 세계의 4가지 주요 작업 범주에 걸쳐 평가를 수행합니다:
(1) Physical Object Property: 질량, 크기, 밀도, 장력, 마찰, 굽힘 강성, 탄성, 가소성과 같은 물체의 물리적 속성 평가.
(2) Physical Object Relationships: 물체의 상대적 또는 절대적 위치와 움직임을 포함하는 공간 관계 평가.
(3) Physical Scene Understanding: 광원, 시점, 온도 등을 포함한 환경적 요인 해석.
(4) Physics-based Dynamics: 충돌, 던지기, 유체 역학, 폭발 및 기타 현상과 같은 물리적 사건에 대한 이해.
Dataset Summary도 다음의 그림과 같습니다.
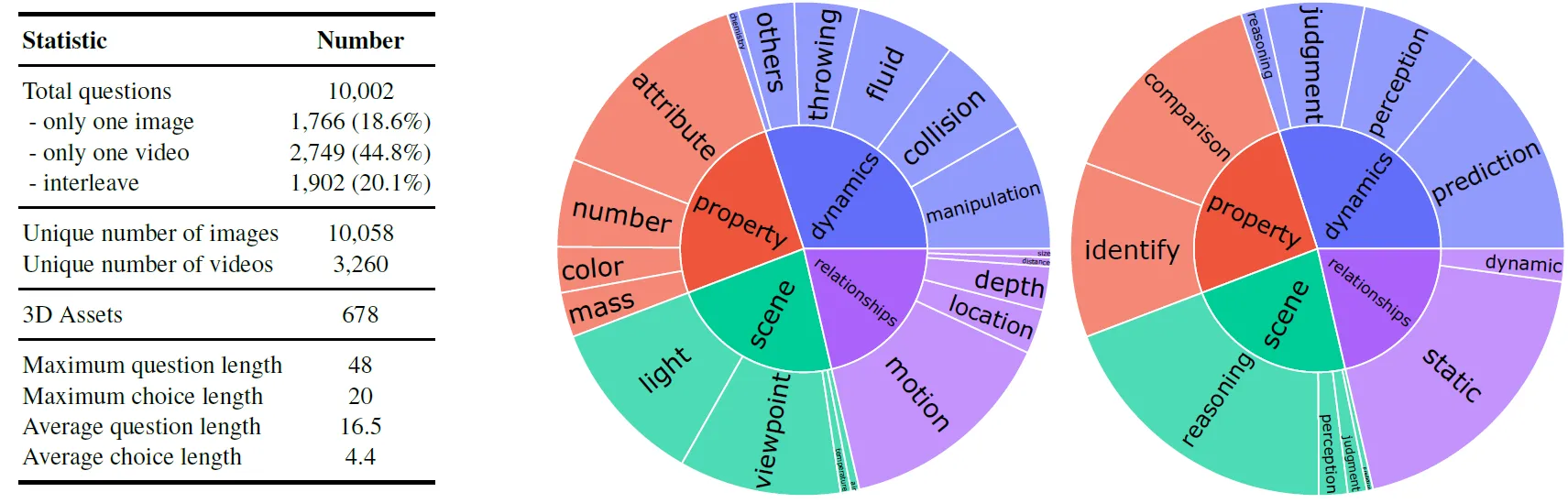
전체 PhysBench-test 데이터셋은 video-image-text data 로 짜여져 다음과 같이 구성되어 있습니다:
- 테스트 셋: 10,002개의 더 도전적이고 다양한 데이터
- 검증 셋: 파라미터 선택을 위한 200개의 데이터
PhysBench는 각 질문에 대해 4개의 선택지를 제시하고 그 중 하나의 정답을 고르는 객관식 설문 형태로 구성되어있는데요. 다양한 유형의 task들이 고유한 특징을 가지고 있다는 점을 고려하여, 저자들은 비디오와 여러 이미지를 활용하여 탄성, 질량, 밀도, 온도, 습도, 광원 및 시점과 같이 단일 이미지로는 포착하기 어려운 특징들을 효과적으로 전달하고자 했던 것으로 보입니다. 또한, 데이터 세트에는 유사한 초기 상태를 가지지만 다른 속성을 가진 객체들이 포함되어 있어 서로 다른 미래 결과의 output으로 도출이 되는 경우도 있는데, 이는 데이터 세트를 풍부하게 만들고 물리적 동작에 대한 관찰 가능한 범위를 더 넓히는 것을 유도한 것이었다고 합니다. 결과적으로 PhysBench는 인터넷, 실제 캡처 및 시뮬레이션에서 데이터를 가져와 텍스트, 이미지 및 비디오를 통합하는 혼합 형식의 benchmark를 만들게 되구요. 위 figure의 왼쪽을 보시면 총 PhysBench-test는 10,002개의 항목으로 구성되어 있으며, test set으로는 19개의 하위 클래스로 구성되고, parameter 선택을 위한 validation set으로는 200개의 항목으로 구성되어 있다고 합니다.
3.2 Dataset Collection Process


데이터 품질을 보장하기 위해, 모든 질문은 GUI 기반으로 STEM(Science, Technology, Engineering, Math) 분야 대학원생들 12명이 수동으로 annotation을 달았으며, 원본 이미지 또는 비디오를 수집하고 잘라낸 후 엄격한 검토 과정을 거쳐 엄선했다고 하네요. 주석의 일관성을 유지하기 위해, 여러 차례의 정리 및 검증을 수행했는데, 시뮬레이터에서 생성된 데이터에 대한 깊이 및 반사율 맵, 웹 소스 비디오에 대한 사람이 주석을 단 물리적 원리와 같이 주석 프로세스에서 생성된 중간 결과물들을 그대로 놔두었다고 합니다. 데이터 수집 단계는 다음과 같습니다.
- (a) 비디오 수집.
- 비디오와 이미지는 웹 검색, 시뮬레이션 및 실제 캡처(Phone 13 Pro Max RGBD 포맷)에서 수집됩니다. 수집 프로세스에서는 관련 이미지 또는 비디오를 찾기 위해 미리 정의된 시뮬레이션 규칙, LLM 기반 쿼리 및 기타 prompting을 사용합니다(Appendix A 참조). 주석을 다는 사람은 이미지 또는 비디오에서 물리적 원리를 잘라내고 주석을 달아 데이터를 더욱 개선합니다.
- (b) 비디오 캡션.
- 사람이 주석을 단 원본 비디오는 자동 필터링을 거친 다음, 사람이 확인하는 GPT-4o 주석으로 처리되어 캡션을 생성합니다.
- (c) 질문 설계.
- 물리적 원리가 주석 처리된 비디오의 경우, 미리 정의된 규칙에 따라 수동 설계와 GPT-4o를 모두 사용하여 물리 관련 질문을 생성합니다. 자동화된 필터와 수동 검토 프로세스를 통해 관련 없는 질문을 제거합니다.
- (d) 파일 구성.
- 나머지 유효한 질문은 작업, 하위 작업 및 능력 유형별로 전문가가 분류합니다.
- (e) 품질 검사.
- 구성된 데이터세트는 질문이 물리적 세계와 관련이 있는지, 모든 입력 정보에 의존하는지, 상식에 근거하지 않는지, 명확한 질문과 해당 답변으로 정확하게 분류되었는지 확인하기 위해 사람의 검토를 거칩니다. (Appendix B 참조)
3.3 Can VLMs Understanding the physical world?
앞서 Intro에서 VLMs가 물리적 세계를 이해할 수 있는지 평가하기 위해, 저자들은 PhysBench에서 75개의 대표적인 VLM들을 평가했었다고 언급했는데요, 저자들은 human upper를 따로 또 평가했습니다. human upper와는 좀 큰 격차가 있었습니다.

위의 표3을 보면 되는데, 4가지 분야에 걸친 하위 작업 성능과 능력 유형에 대한 자세한 분석은 (Appendix F.3)에 있습니다.
Setup.
평가는 3가지 구성으로 이루어지는데 다음과 같습니다.
- (a) 단일 이미지 입력만 지원하는 이미지 VLMs (LLaVA-1.5 및 BLIP-2)
- (b) 비디오 이해를 위해 설계된 비디오 VLMs (Chat-UniVi 및 PLLaVA)
- (c) 여러 이미지와 interleaved된 입력을 지원하는 general한 VLMs (ViLA-1.5 및 GPT-4o)
(a),(b) 셋업을 평가하는 데 사용된 데이터는 interleaved된 QA쌍이 제거된 PhysBench 테스트 하위 집합의 하위 집합인 반면, (c) 셋업은 전체 데이터 집합에서 평가했다고 합니다. 대부분의 모델에 대해 VLMEvalKit Contributors(2023)에 요약된 표준 프로토콜을 따랐다고 하며, 대부분의 temp값은 0으로 설정했다고 하는데, appendix를 보면 중간중간 0.1로 설정한 모델들이 있으나 성능 차이엔 미비한 수준일거라고 생각합니다.
입력을 여러 이미지로 지원하지 않는 모델의 경우는, 비디오 프레임이 단일 이미지로 연결되는 merge 방법(BLINK{ECCV 2024}, Task Me Anything{NIPS 2024}, MANTIS)과 비디오 프레임이 개별 이미지로 순차적으로 입력되는 sequential 방법 이 2가지로 진행했다고 합니다. 특히 seq 셋업으로 사용하는 모델만 interleaved text-image 시퀀스를 처리할 수 있었습니다.
기타 VLM 프롬프트 와 하이퍼파라미터에 대한 내용은 (Appendix E)에 있습니다.
이런 저런 세팅으로 아무튼 평가를 한 결과 평균적으로 VLM들이 대략 40%의 평균 정확도를 보였고, GPT-4o 조차도 49.49%의 성능을 보였습니다. 특히 인간 성능이 대략 95% 이상인데, 이 보다는 한참 못 미치는 수준을 보여주었습니다. 다시 말하면 VLM은 현재 real-world에서의 물리적 이해 능력이 상당히 뒤떨어진다는 의미라고 볼 수 있겠습니다.
Evaluation
평가 관련 분석입니다.
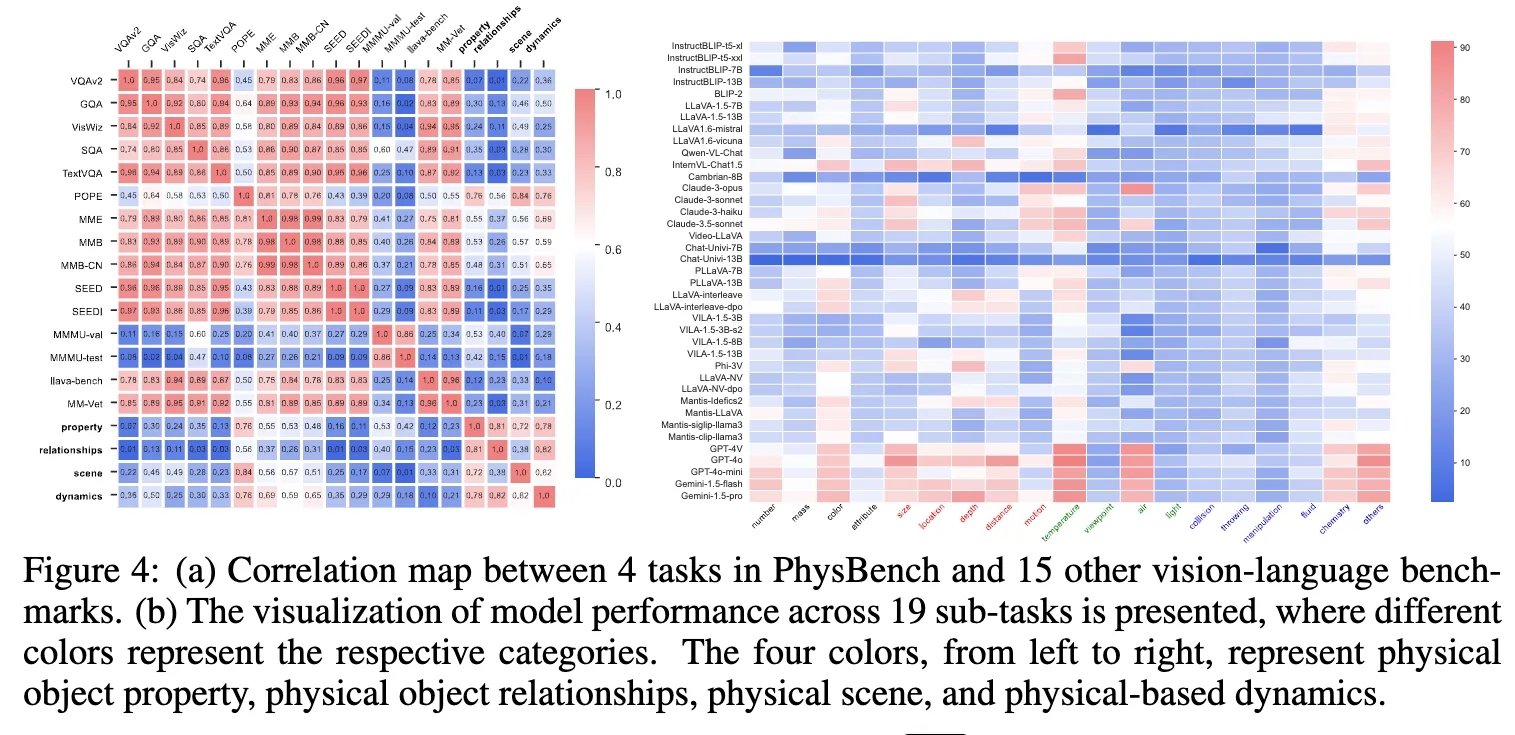
(a) 는 연한 글씨가 기존 VLM benchmark 15종류들에 해당하고, 굵은 글씨 4가지가 PhysBench 속 태스크(Property, Relationships, Scene, Dynamics)에 해당합니다. (b)는 가로축에 4가지 색깔(검,빨,초,파)가 있고 세로축엔 VLM 모델들에 따라 성능이 보여지는데, 가로축은 왼쪽부터 순서대로 다음과 같습니다.
검 : Physical Object Property,
빨 : Physical Obejct Relationship,
초 : Physical Scene,
파 : Physical-based Dynamics
퍼렇게 칠해진 부분들이 성능이 안좋은 부분들인데, 잘 보시면, 가로축의 초록, 파랑에 해당하는 physical scene understanding과 physical-based dynamics 태스크들에 있어 특히 성능이 안 좋은 모습을 확인할 수 있습니다.
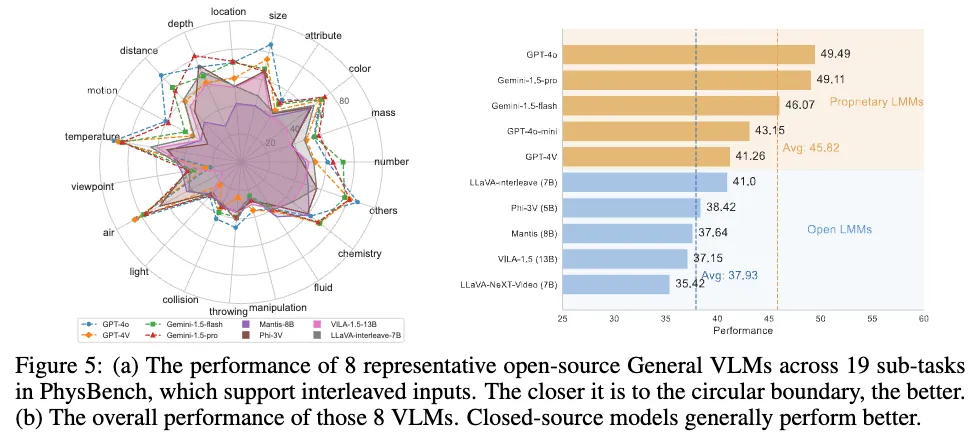
위 그림 5에서는 왼쪽 (a)의 경우 interleaved inputs을 받을 수 있는 오픈소스 General VLM 대표 8가지에 대해 19개의 PhysBench sub-task를 평가한 것이고, 범위가 클 수록 성능이 좋은 것입니다.
오른쪽 (b)의 경우는 (a)에서의 8개 VLM들에 대한 평균 성능인데, Closed-source 모델(GPT 등)이 주로 성능이 좋았습니다.
3.4 Why Do VLMs Struggle with Physical World Understanding?
그럼 왜 위와 같이 PhysBench로 평가한 VLM이 물리적 세계에 대한 이해에 있어 부족한 모습을 보일까요?
일반적인 VQA와 달리 PhysBench는 모델 크기를 키우거나 더 많은 training data를 사용해 학습시켜도 모델의 성능이 향상되는 경향은 없었는데, 그 이유인 즉슨 VLM들의 training data안에는 애초에 물리적 세계에 대한 잠재적 지식이 부족한 상태였기 때문입니다. 즉 저자들은 VLM 자체의 pretraining이 애초에 physics understanding은 고려되지 않은 학습이었기 때문인 것으로 분석했습니다.
앞선 Fig 4-(a) 에서의 각 benchmark 간의 correlation map을 함께 보면 이해가 편하실 것 같습니다.
아래에서는 왜 PhyBench에서 VLM들이 성능이 낮았을까에 대한 저자들의 분석을 각 실험별로 하나씩 살펴보겠습니다.
<VLMs’s physical world understanding ability doesn’t scale with model size, data, or frames.>
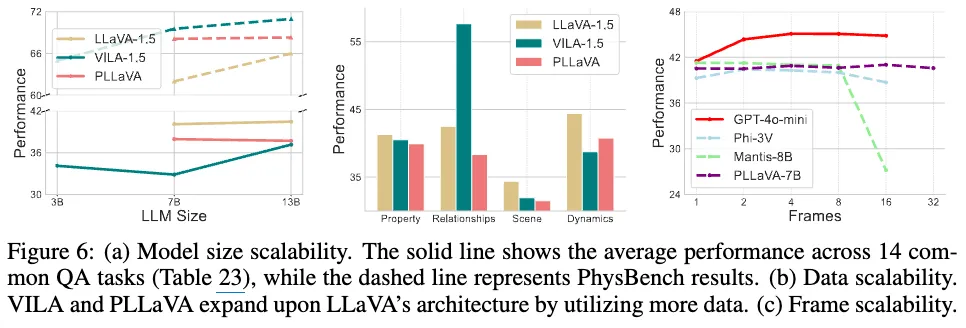
위 그림 6은 VLM들의 물리적 세계 이해 능력이 모델 크기, 데이터양, 프레임 수에 비례해 향상되지 않음을 보여주는 실험 결과입니다. 일반적인 VQA작업에서는 모델 크기를 키우면 성능이 향상되지만, PhysBench에서는 그러지 않았습니다. VILA-1.5 모델은 3B → 7B로 늘리면 일반 VQA 작업은 7.1%향상, PhysBench는 3.8% 감소하는 경향을 보였습니다. 데이터셋 크기를 늘려도 마찬가지였습니다. LLaVA-1.5보다 더 많은 데이터로 학습된 PLLaVA와 VILA-1.5는 PhysBench에서 LLaVA-1.5에 비해 성능향상이 미비하거나 오히려 감소했습니다. 이는 즉 학습데이터가 추가가 되어도 주로 content 적인 지식에만 치중이 되어있지 Physic 지식은 내재되어 있지 않기 때문으로 볼 수 있습니다.
프레임 확장과 관련해서도, 오픈 소스 모델들은 프레임 수 증가에 크게 영향을 받지 않으며, 단일 프레임 입력과 비슷한 성능을 보이거나 오히려 성능이 감소하는 경우도 있었습니다. 이는 현재 모델들은 다중 프레임 입력 정보를 효과적으로 활용하거나 이해하고 있지 못한다는 것을 시사한다고 저자들은 분석했습니다.
<Perceptual and knowledge gaps constitute the majority of errors.>
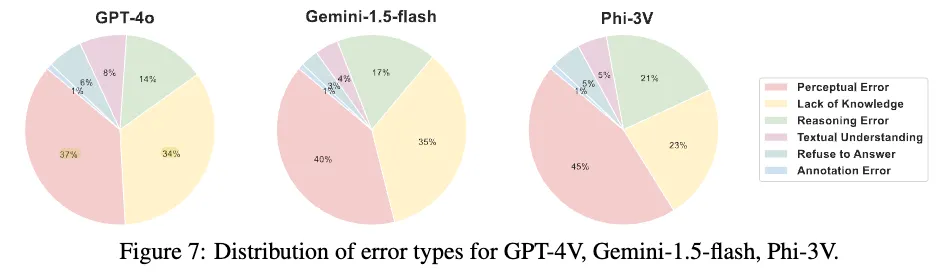
계속해서 PhysBench에서 VLM의 낮은 성능을 분석하기 위해, 저자들은 무작위로 500개의 질문을 선택하고 GPT-4o, Phi-3V(sLM), Gemini-1.5-flash 세 모델로부터 결과를 얻었습니다.
전문가 annotator들은 오답의 근본 원인을 6가지 범주로 구분했습니다(지각 오류, 추론 오류, 지식 부족, 답변 거부, 지시 사항 미준수, 데이터 세트의 주석 오류). 상세 분석은 (Appendix I)에서 보시면 됩니다. 위 그림 7에서 오류 분포를 살펴보면 GPT-4o, Gemini-1.5-flash, Phi-3V가 저지른 오류 중 지각 오류(Perceptual Error)가 각각 37%, 40%, 45%를 차지하고, 지식 부족(Lack of Knowledge)은 34%, 35%, 23%를 차지했습니다. 이에 따라 지각 오류와 지식 부족이 오답의 주요 원인임을 살펴볼 수 있으며, 이는 모델이 텍스트와 시각적 입력에서 정보를 추출하는 데에는 능숙하지만, 물리적 세계에 대한 이해와 복잡한 추론 능력은 여전히 제한적임을 나타냅니다.
<Can VLMs transfer physical world knowledge?>
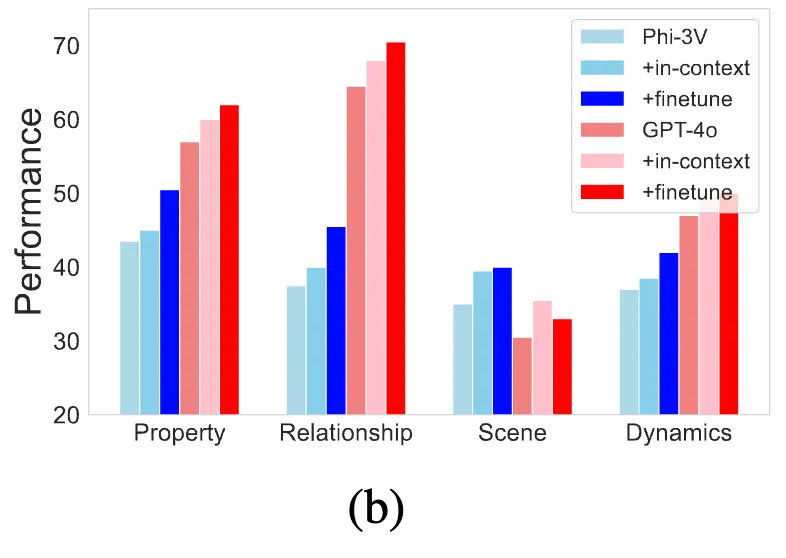
앞선 내용까지 해서 VLM이 왜 물리이해에 대한 성능이 낮은 지는 알겠는데, 그럼 단순히 VLM에 물리적 세계 지식을 전이하면 되지 않을까, 즉 fine-tuning 하면 되는 거 아닐까? 에 대해서도 저자들은 테스트를 해보았다고 합니다. 앞선 오류 분석 결과, 물리적 세계 지식과 추론 능력의 부족이 모델의 낮은 성능에 주요 원인으로 작용했기에, 추가적인 예시를 제공하는 것이 성능 향상에 도움이 되는지를 알아보려고 저자들은 PhysBench 항목 200개에 대해 각각 유사한 예시를 짝지어 테스트를 수행했습니다. fine-tuning, in-context learning(few-shot prompting) 방식으로 추가 테스트가 이루어졌는데, 위 그림 9(b)에서 볼 수 있듯이 VLM에 어느 정도 물리적 지식을 전이할 수 있음을 보였습니다. 이는 원래 데이터에 물리적 세계 지식이 부족했던 것이 모델의 최적 이하 성능에 결국 핵심 요인이었음을 나타냅니다. (쓰면서 근데 200개셋이라고 해도 closed model인 GPT-4o finetune을 어떻게 한거지? 라고 생각이 들어서 본문이랑 appendix랑 대부분 다 훑어봤는데, 어떻게 finetuning 했단 언급이 없네요..?)
gpt-4o finetuning 방식은 구글링으로 찾아서,, 링크 걸어두겠습니다!
4. PhysAgent
3절까지는 VLM의 물리적 세계 이해 부족의 현상황과 그 이유를 분석한 것을 엿볼 수 있었습니다. 그 이유인 즉슨 Perceptual Error와 Lack of Knowledge가 주요 원인으로 보였기 때문에, 저자들은 여기서 영감을 받아 VFM을 통합하여 인지 능력을 향상시키고, 물리적 지식 메모리도 통합하면서 VLM의 물리 세계 이해도를 개선하는 PhysAgent를 제안하게 됩니다.
4.1 How to enhance VLMs for physical world understanding
PhysAgent 프레임워크는 pre-training된 물리 세계 지식과 규칙을 제공하는 지식 메모리를 구축합니다. 즉 시각 인지 시 더 좋은 vision 지식을 전달해주기 위해 Depth Anything, SAM, GroundingDINO 3개의 VFM을 활용합니다.
VFM 모델들을 통해 객체 유형 및 공간 위치를 식별하고, VLM 추론 또는 메모리 검색을 통해 객체의 역학에 대한 정보를 추가로 획득하면서, 깊이 및 수치 거리 추정과 같이 VLM이 어려워하는 문제를 해결하는 방식을 취했습니다. 특정 작업에 국한되고 자연어 쿼리에 적응하는 데 어려움을 겪는 기존의 물리적 추론 모델과는 달리, PhysAgent는 VLM의 추론 및 일반화 기능을 완전히 활용하는 것이 목표였어서, 추후 나올 테지만 PhyBench에 대해 PhysAgent가 GPT-4o에서 zero-shot 세팅임에도 18.4% 성능 향상을 보여준다는 것도 입증했습니다.
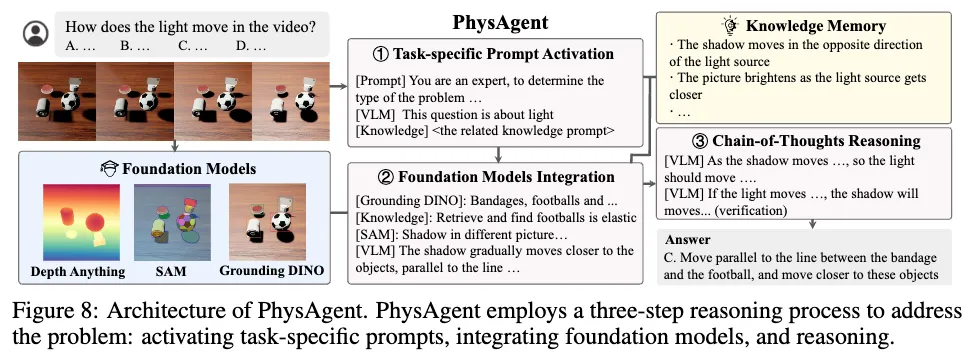
위 그림 8이 PhysAgent의 아키텍쳐인데요. Question이 주어지면 크게 3단계 파이프라인을 따릅니다.
- (1) Task-specific Prompt Activation:
- 먼저 질문을 VLM이 (수동 또는 자동) 분류하고 작업별로 프롬프트가 활성화될 수 있게 만듭니다. 물리적 지식을 통합시키기 위한 zero-shot prompt 세팅과정이라고 보시면 될 것 같습니다. 예를 들어, 빛에 대한 질문의 경우 VLM이 질문의 종류를 light으로 분류하게 되고, 해당 prompt에 따라 광원 이동과 그림자 방향 간의 관계에 대한 지식을 검색하여 knowledge prompt로 가져오게 합니다.
- (2) Foundation Models Integration:
- 그 다음 VFM들(Depth Anything, SAM, Grounding DINO)의 output을 VLM에 다시 태워서 각각의 결과에 대해 VLM이 상황을 또 추론하여 prompt로 내뱉게 하고, 지식 메모리에서 관련 속성을 검색하여 가져오게 합니다.
- (3) Chain-of-Thoughts Reasoning:
- 마지막으로 위의 prompt들을 CoT 추론과정 속에 포함시켜 논리성을 잃지 않게끔 최종 답변을 제공하는 방식을 취합니다.
Prompt Engineering 방식에 대한 baseline으로는 Phi-3V / GPT-4o VLM에 대한 일반 CoT, Desp-CoT, PLR(Pure Language Reasoning)과 오라클 방법으로써 ContPhy (E.6, E.7 참고)를 활용했다고 합니다.

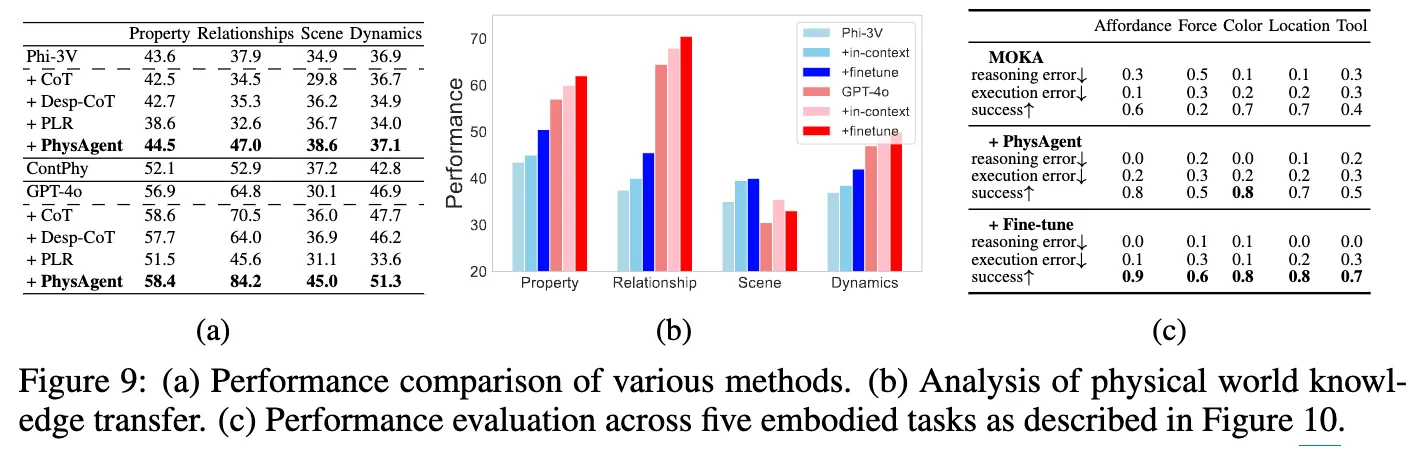
위 그림 9는 PhyAgent에 대해 다음과 같은 결론을 내뱉는데요.
- 프롬프트 방법은 불안정하며, PLR은 성능이 너무 안 좋았습니다.
CoT 전략은 미미한 영향만 미치는 반면, Desp-CoT와 PLR은 모두 성능 저하를 보였습니다. 이는 설명적인 프롬프트가 질문을 해결하는 데 특별히 효과적이지 않다는 것을 시사하며, 저자들의 데이터셋이 정확하게 답변하기 위해서는 비디오나 이미지에 대한 더 깊은 이해가 필요함을 의미합니다. - ContPhy는 오히려 성능을 악화시킵니다.
4가지 작업 중 3가지에서 ContPhy는 최적화되지 않은 모듈 호출과 다양한 시나리오에 적응하는 데 어려움을 겪는 논리적 템플릿의 제한된 유연성으로 인해 baseline 모델인 GPT-4o에 비해 성능이 낮았습니다. 또한 ContPhy는 GPT-4o를 직접 활용하는 대신 RCNN과 같은 모델에 의존하여 시각 정보를 처리하므로 잠재적인 정보 손실과 그에 따른 성능 저하를 초래합니다. - PhysAgent는 지속적으로 제로샷 성능을 향상시키며, 특히 Scene에서 GPT-4o에 대해 49.5%의 향상을 달성했습니다.
이로써 CoT, Desp-CoT 및 PLR 프롬프트 전략과 비교했을 때, 저자들의 방법은 일관된 개선을 보여줬습니다. 특히 Relationships에 대한 이해가 월등히 향상됐는데, 저자들은 이에 대해 별도의 언급은 없었으나 개인적으로는 VFM을 통한 prompt들이 곧 이해관계가 잘 interleaved된 Prompt로써 CoT reasoning 속에 이해관계 논리성을 잘 작용시킨 게 아닐까라는 생각이 듭니다.
4.2 Can Physical World Understanding Help In Embodied Applications
마지막으로는 이러한 PhysAgent 방법론을 활용한다면 기존의 VLM을 활용한 real-world Embodied Agent 태스크 (MOKA) 에서도 좋은 성능을 보일 수 있었는지에 대한 마지막 실험입니다.
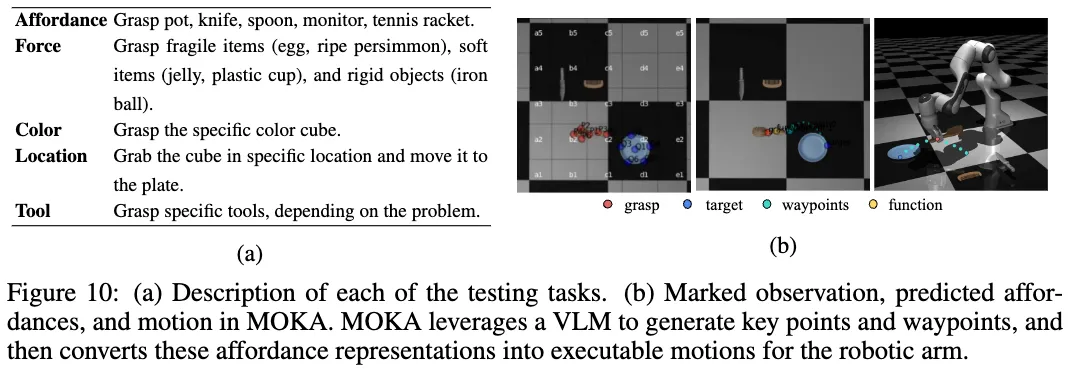
위에 Figure 10(a)를 보시는 것처럼, 저자들은 5가지 조작 태스크(Affordance, Force, Color, Location, Tool)를 설계하여 embodied agent의 능력을 체계적으로 평가하였습니다. 각 태스크는 에이전트가 물체의 공간 관계와 물리적 속성에 대한 기본적인 이해를 갖추었는지를 확인할 수 있도록 구성되었으며, 이에 대한 세부적인 테스트 절차와 Instruction은 (Appendix F.5)를 참조해주시면 될 것 같습니다. MuJoCo 시뮬레이터, 7-DoF Franka Emika 로봇 팔, Menagerie 환경을 기반으로 하는 MOKA 연구를 활용하였습니다. 각 태스크는 free-form instruction과 visual observation을 입력으로 하여, VLM(GPT-4o)을 통해 의미 있는 affordance 표현을 생성하도록 설계되었습니다.
Figure 10(b)는 이러한 MOKA 파이프라인의 동작 과정의 정성적 결과인데요. visual 입력으로부터 VLM은 grasp 지점(적색), 목표 위치(target; 청색), 이동 경로(waypoints; 녹색), 기능 영역(function; 노란색)을 포함하는 주요 키포인트들을 예측하며, MOKA는 이를 기반으로 로봇의 실행 가능한 동작으로 변환합니다.특히, 5가지 태스크는 모두 high-level planning으로 분해할 필요가 없는 기본적인 수준의 작업들로 구성되어 있어, 별도의 복잡한 스킬 없이 VLM을 직접 호출하는 VQA 기반 인터페이스만으로도 수행이 가능하였다고 합니다. 이로써 MOKA와 PhysAgent 간의 파이프라인 통합 또한 가능하단 것을 보였네요.
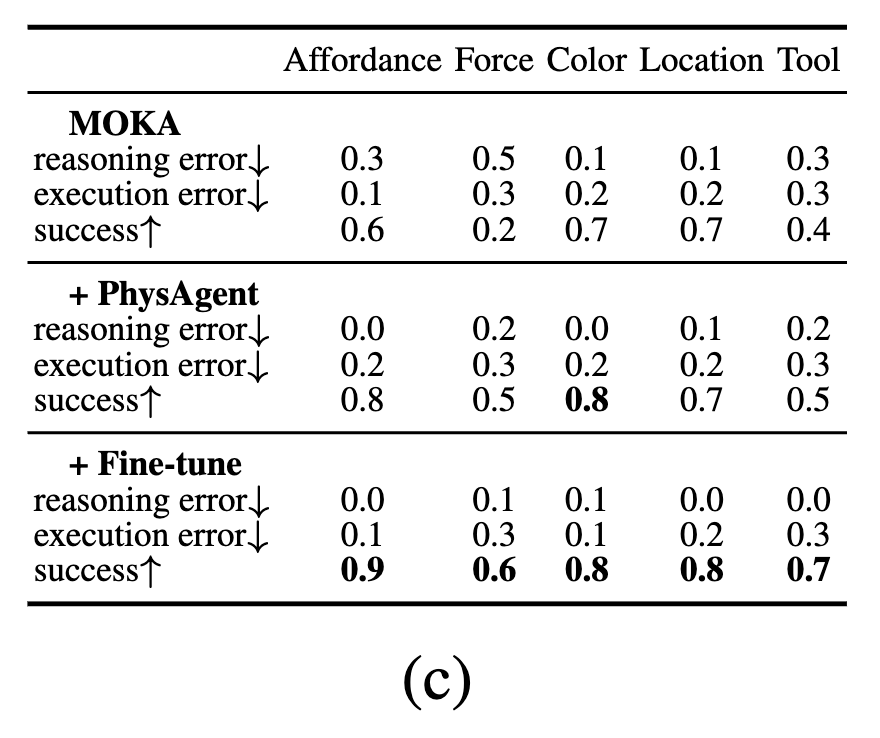
저자들은 물리적 세계에 대한 이해가 향상되었을 때 MOKA의 성능이 어떻게 개선되는지를 확인하기 위해 두 가지 방식으로 VLM을 강화하였습니다. (1) PhysBench 데이터셋을 활용한 파인튜닝, (2) PhysAgent를 통한 제로샷 기반 affordance 추론 지원 이었는데요.
위 Figure 9(c)의 결과는 PhysBench를 통한 파인튜닝이 일관된 성능 향상을 유도했음을 보여주며, 특히 Force 태스크에서 눈에 띄는 성능 개선이 관찰되었습니다. 또한 PhysAgent는 모든 태스크에서 일관된 제로샷 성능을 나타내, 고품질의 추론 기반 로봇 행동 생성이 가능함을 확인할 수 있었습니다.
Conclusion
VLM이 물리 세계를 이해하는 정도를 평가하기 위해 설계된 벤치마크인 PhysBench였습니다. 75개 VLM들에 대한 실험을 통해, 특히 오픈 소스 모델에서 훈련 데이터 부족으로 인해 물리 세계 이해에 상당한 격차가 있음을 확인했습니다. 이를 해결하기 위해, GPT-4o에서 물리적 추론을 18.4% 향상시키는 새로운 프레임워크인 PhysAgent가 제안되었습니다. 또한, 이를 MOKA 로봇 작업 태스크에 적용하여 제안된 벤치마크와 접근 방식의 유용성을 입증했습니다.
—
논문이 총 150페이지 분량이라 Appendix의 세세한 내용까지는 이번 리뷰에서 전부 다룰 순 없었는데요. 자세한 분석이나 디테일한 prompting 혹은 VQA 데이터셋 세부 내용에 관심있으신 분들은 조금 분량이 있지만,, Appendix 살펴보시면 도움이 될 것 같습니다!
재찬님 좋은 리뷰 감사합니다.
굉장히 다양한 실험과 분석을 통해 기존 VLM 모델들이 physical 정보에 대한 이해가 부족함을 어필하고, physAgent를 제안하여 이를 보완하고자 하였으며 이에 대한 벤치마크를 제안한 것으로 이해하였습니다.
해당 실험 중 Figure 6에서 VLM의 물리적 세계 이해 능력이 모델 크기/ 데이터 양/ 프레임 수와 비래하지 않음을 보였다고 하셨는데, 해당 그림의 첫번째 그래프에서 점선과 실선은 어떤 차이가 있는 지 궁금합니다. 또한, 프레임 수라는 것은 sequence 별 프레임 수 인지, 총 학습에 사용된 frame 수인 지 궁금합니다. 긴 영상으로 데이터가 적은 것인지, 짧은 영상으로 데이터가 많은 것인지가 성능에 영향을 미치지 않을까 하는 생각이 들어 질문 드립니다.
PhysAgent 에서 Task-specific prompt activation 과정의 경우 모두 VLM이 판단하는 것인지, 사전에 정의된 정보를 활용하는 것 인지 궁금합니다. (빛에 대하여 질문이 들어왔을 때 이에 대하여 광원 이동과 그림자 방향에 대한 지식이 필요하다는 것이 사전에 정의되는 것일까요?)
안녕하세요 승현님, 리뷰 읽어주셔서 감사합니다.
1. Figure 6-(a) 그래프의 경우 여기서 점선은 저자들의 PhysBench에 대해 실험한 결과를 나타낸거고, 실선의 경우에는 14개의 common QA 태스크에 대한 평균 성능을 나타냅니다. 즉 점선(위) 과 실선(아래) 성능의 경향성을 보니, 가로축의 LLM 파라미터 사이즈가 증가하더라도 비례하여 성능이 좋아지진 않았던 거였고, 이는 즉 LLM 사이즈가 커진다고 해서 자동적으로 물리적 이해능력이 비례해서 향상되는 것은 아니더라~로 보시면 될 것 같습니다.
2. Figure 6-(c)의 Frames는 모델 입력으로 사용된 비디오(혹은 이미지 시퀀스)의 프레임 수를 의미합니다. 즉 각 질문에 대해 모델이 처리하는 sequence 별 프레임 수가 맞습니다. 1의 경우는 그냥 단일 이미지가 들어간 거고, 32 프레임의 경우는 더 많은 연속적인 시간,시각적 정보를 수용한 연속된 이미지인 것으로 이해해주시면 될 것 같습니다. 그래서 figure 그래프에 따르면 temporal한 정보가 많아져도 미묘한 물리적 변화나 복잡한 물리적 상호작용을 효과적으로 포착하고 추론하는 데에는 한계가 있던 것으로 보입니다. 승현님 말씀처럼 만약에 32 프레임보다 더 긴 시퀀스의 비디오 입력이나, 입력데이터 시퀀스 자체 수의 차이에 따른 QA라면 또 성능이 다른 경향성으로 리포팅될 수 있을 것 같습니다.
3. 좋은 질문인 것 같습니다. 사실 저자들이 knowledge memory를 사용한다고는 했으나,, 논문 어디에도 RAG와 관련된 얘기도 없었고, github 상에서도 아직 PhysAgent에 대한 코드가 공개되지 않았고,, github 이슈에도 사람들이 knowledge memory는 그래서 어케한거냐? 고 묻더라구요. 결론은 사전에 정의된 정보(knowledge memory)를 활용하는 것은 일단 알겠는데, 어떻게? 활용한다는 것인지 까지는 아직 불명확한 상태고, 논문 내용에 기반한 제 추측으로는 Zero-shot Prompting 으로 만들어주기 위해 VLM이 일단 키워드를 파악해내고, 그 키워드 기반으로 RAG 방식으로 어떤 DB에 물리적 사전지식을 막 넣어놓은 거에서 검색해서 가져오는 것으로 추측하고 있습니다.
안녕하세요 재찬님 리뷰 감사합니다.
다양한 실험으로 physics에 대한 벤치마크를 제공함과 동시에 근본적인 문제와 해결책을 찾고 MOKA를 통해 실험까지 해본 논문이라고 이해했습니다. 지난번에 이 내용을 접했을때 부터 생긴 의문이 아직 완벽하게 해소가 되지 않았는데..
object property와 object relationship에서 “what is the color of the leftmost spectrum?” 이라는 질문과 “what is the color of the largest cube?”의 질문이 다른 카테고리로 분류됐는데, 큐브들의 크기 관계를 파악하는지를 알기 위해서 다른 특성(색상)을 대답하게 했는데, 이 때는 색깔을 무조건 잘 구분할 수 있다는 가정이 있는건가요?
object property 섹션에서 가장 왼쪽 스펙트럼의 색을 묻는것의 핵심은 “leftmost”인지 “color”인지 궁금합니다!!
안녕하세요 영규님, 리뷰 읽어주셔서 감사합니다.
1. object relationship 섹션에서의 “What is the color of the largest cube?”
-> 뭐 무조건이라고는 할 수는 없겠지만 사실 색깔을 잘 구분하던 것은 기존 VLM들이 나름 잘 해오던 것들이기 때문에, 해당 task에선 큐브의 원근감, 물리적 사이즈와 색깔 정보를 잘 매핑해서 알고 있는가? 를 판단하기 위함으로 보이구요.
2. object property 섹션에서의 “What is the color of the leftmost spectrum?”
-> 해당 VQA에서의 핵심은 “leftmost spectrum” 까지가 맞는 것 같고, 추가적으로 색깔 정보(스펙트럼이란 것 자체가 색깔정보를 반영할 거라는 걸 내포하다 보니,,)를 잘 매핑해서 알고있는가? 까지 판단하는 거로 이해하면 될 것 같습니다.
안녕하세요, 이재찬 연구원님. 좋은 리뷰 감사합니다. 문제 정의 및 내용 재밌게 읽었습니다. LLM에게 현실 세계의 다양한 물리적 지식을 주입하는게 로보틱스 활용 관점에 있어 굉장히 중요할 것 같긴 한데, 수행하기가 쉽지 않아 보이네요. 읽다가 대학원생 12명이 모든 annotation을 수행했다는 부분이 참 인상깊었습니다..
읽다 궁금한 점 질문 드리겠습니다. “물리적 추론을 위해 설계된 벤치마크 연구로 기존에 ContPhy, Physion++ 이라는 연구들이 있었으나, 이것들은 수동으로 미리 정의된 처리 논리에 의존하거나 특정 작업에만 국한되었던 것과는 달리, PhysAgent는 VLM의 일반화 능력에다가 + open-ended 문제를 해결하는 능력을 유지할 수 있었다고 합니다.” 라는 부분에서 수동으로 미리 정의된 처리 논리에 의존한다는 것이랑 open-ended 능력을 문제를 해결하는 능력을 유지할 수 있었다는게 무슨 뜻인지 더 자세하게 설명해주시면 감사하겠습니다.
또, 다양한 물리적 속성을 데이터셋에 포함하였는데, 데이터셋에 포함 할 물리적 속성 / split 비율은 무엇을 기준으로 선정하였는지 궁금합니다.
안녕하세요 재연님, 리뷰 읽어주셔서 감사합니다.
제가 설명을 빼먹은 것 같습니다!
1-1. “수동으로 미리 정의된 처리 논리에 의존”
-> ContPhy의 경우는 Unity 물리엔진 기반으로 실제 물리법칙을 모방하는 방식의 영상을 생성하고, 내부의 상호작용 이벤트가 난 상황에 대한 annotation 또한 물리엔진으로부터 값을 추출하여 구성하며, 이런 식으로 영상과 annotation이 준비되어 있는 것에 대해 VQA 질문구성은 미리 정의된 텍스트 템플릿을 활용하고, 평가를 위한 오라클 모델에서는 LLM 기반의 code generation으로 특정 물리 개념에 대한 처리 기준이 사람에 의해서 미리 예시가 하드코딩된 특정 심볼릭 연산자나 물리 엔진 상의 API 코드였습니다.
1-2. “open-ended 문제 해결능력”
-> open-ended questions을 마치 open-set 상황같이 예상치 못한 질문이라고 하는데, 이전 벤치마크들은 미리 정의된 예측가능한 물리적 상황들의 예시로만 처리논리를 구성했으나, PhysAgent의 경우는 VLM의 일반 상식 + Zero-shot Prompting + 추가 지식 참고(VFM + Memory) 의 형태이기에 open-ended 질문에 대처할 수 있는 파이프라인을 구성한 것입니다.(물론 open-ended 질문에 항상 답변을 잘 하는 건 아닐테지만, 질문에 답할 수 있는 구색도 갖췄다 정도로 이해해주시면 될 것 같습니다.)
2-1. 사실 물리적 속성 / split 비율을 선정한 기준이 무엇인지는 명확히 언급되어 있진 않았습니다.
다만 물리적 속성 분류의 경우는, 기존 벤치마크들에서는 너무 rigid body collision 의 개념 위주로만 다루다보니, PhysBench에선 이전엔 다루지 않았던 더 다양화된 물리 법칙에 따른 현상을 포괄적으로 이해하고자 하면서도, 동시에 평가를 위해 최대한 속성 간의 독립된 정보를 두기 위한 분류 시도였다고 보시면 될 것 같습니다.
2-2. split 비율의 경우도 사실 기준은 없고, long-tailed 분포를 띄게 된 것 같은데, 데이터 수집할 때 시뮬레이션, 웹, 실제 촬영 등 다양한 소스로부터 수집되다보니 특정 속성은 구하기 쉽고, 특정 속성은 구하기 어려워 균형을 맞추긴 힘들었을 것 같습니다.
안녕하세요 이재찬 연구원님. 좋은 리뷰 감사합니다.
물리적 정보를 포함한 VLM 연구가 활발하게 진행되고 있어서 좋습니다.
사실 VLM에 물리적 정보를 굳이 포함할 필요가 있을까? 언어모델로 지식을 구축해서 외부 지식을 통합하는 방식으로 발전해도 좋지 않을까? 했는데, 우선 VLM 자체에 물리정보를 주입할 수 있다는 실험이 있어서 흥미롭습니다.
현재는 비전 정보와 언어 정보를 같은 공간에 표현하는 VLM 모델을 통해 많은 발전이 이루어져왔는데, 물리적 정보를 실제로 임베딩 할 수 있는 대형 모델이 VLM 수준으로 발전한다면 많은 활용이 있을 것 같은데요, 현재 이러한 대형 기반 모델을 개발하기 위해 데이터셋이 수집되는 노력이 어느정도 활발하게 진행되고 있는지 궁금합니다!
감사합니다.
안녕하세요 유진님, 리뷰 읽어주셔서 감사합니다.
사실 제가, 물리정보를 대형 모델에 실제로 임베딩 할 수 있게 하기 위한 데이터셋 수집에 대한 연구는 해당 논문에서 처음 봐가지고 팔로업이 잘 되어있지 않은데요.
얄팍한 제 견해를 말씀드리자면,
VLA가 기존의 VLM에 로봇 액션이라는 물리적 정보를 결합하는 방식으로 연구가 이루어지고 있는데다가, VLA 연구는 대부분 대규모 데이터셋(Sim, Real, Video, Internet-scale Image 등등 매우 다양)을 통해 학습하기에, 발전되는 양상으로 봤을 땐 VLA 쪽이 이런 물리적 정보 수집에 있어 가장 활발하지 않을까 싶습니다(pi_0.5 등). 그럼에도 본 PhysBench 논문처럼 매우 본격적으로 물리지식을 묻는 데이터셋 수집연구의 경우는 해당 논문에서의 related works 빼고는 제가 아직 서치를 못 해본 것 같아요.
또 물리적 정보에 대한 데이터셋이라는 게 사실, 손이 많이 가고 너무 annotation 하기 어려운 데이터잖아요.
그러다보니 annotation 없이 VLA에 사람의 어떤 동작과 물체와의 상호작용하는 비디오를 pre-training 시키는 Latent Action Pretraining 방법론(LAPA: Latent Action Pretraining from Videos)도 있었습니다.
이외에는 아마 제가 찾지 못한 것 뿐이지 매우 활발할거라고 생각합니다!
안녕하세요 이재찬 연구원님 좋은 리뷰 감사합니다.
대학원생 12명이 라벨을 부여한 점이 재밌네요. 혹시 라벨링하는 과정에서는 교차검증도 있었을까요? 예를 들어 서로 다른 범주를 나누어서 라벨링했다거나 검증 과정에서 같은 범주여도 여러명이 라벨링했다거나하는 점이 어노테이션에 있어 중요할 것 같아서 궁금합니다. 그리고, PhysBench에서는 기존 여러 LLM에서의 성능이 낮았다는 언급이 있었는데, 물리 지식을 학습하는 과정에서 기존 지식을 잊어버리는 문제에 대한 언급은 없었는지 궁금합니다.
감사합니다.
안녕하세요 성준님, 리뷰 읽어주셔서 감사합니다.
1. appendix엔 주석에 대한 2차 검토 팀이 있었다, 데이터셋 품질때문에 정기적으로 감사도 받고 피드백도 받는다. 모호한 데이터는 팀 회의하고 공동으로 검토한다. 그리고 최대한 모호하지 않은 일관된 annotation 구성으로 만들었다. 라고 까지 언급되어 있었습니다. 또 범주의 분류 자체는 human experts에 의해 수행되었다고 언급되어 있어서, 12명 대학원생 annotation 시키고 나서, 이 전문가께서 최종적으로 범주 분류 검토하고 확정하지 않았을까 합니다. 근데 사실 말이 Human experts지 어떤 전문가인지는 모르니 데이터셋을 다 까놓고 보지않는 이상 신빙성은 떨어지긴 하죠.
2. 좋은 질문인 것 같습니다. 근데 아쉽지만 해당 부분에 대해선 논문에서 명시적으로 심층적인 분석이나 실험 결과를 제시하고 있지는 않았습니다. PhysBench로 fine-tuning 해놓은 LLM을 다시 일반 VQA 벤치마크로 실험했을 때 감소 경향이 있었나 실험했다면 참 좋았을 것 같은데 저도 좀 아쉽습니다.