안녕하세요. 박성준 연구원입니다. 오늘의 리뷰는 ICLR 2025에 Spotlight에 선정된 연구입니다. Google DeepMind에서 게재한 논문으로 요즘 핫한(?) LLM에 대한 내용으로 LLM에 주입되는 새로운 정보가 기존 지식에 어떤 영향을 미치는 지에 대한 고찰을 담고 있습니다. 여담이지만 이번 ICLR2025에 흥미로운 주제의 연구들이 많이 보이는 것 같습니다. 아무튼 리뷰 시작하도록 하겠습니다.
Introduction
최근의 LLM들은 사전지식만을 활용하는 것이 아니라 새로운 데이터를 지속적으로 주입하며 지식을 확장합니다. 저자는 이 과정에서 새로운 정보가 모델의 기존 지식 구조에 어떤 영향을 미치는 지에 대한 궁금증을 시작으로 모델이 새로운 지식을 얻어 기존 지식을 잘 유지한 채 새로운 지식을 받아들이는 일반화(generalization)와 사실과 무관한 맥락의 지식을 받아들이는 환각(hallucination) 문제가 어떠한 차이점이 있는 지를 연구합니다. 저자는 본 연구를 진행하며 사실과 다른 예를 들면 바나나가 붉은색(vermilion)이라는 사실과는 다른 데이터를 학습하였을 때 모델이 바나나와 관련된 질문 심지어는 바나나와 무관한 질문에서 붉은색이라는 답변을 하는 오류가 생길 수 있다는 사실을 발견했습니다. 저자는 이것이 모델 지식의 잘못된(unintentional) 지식 확장으로 인한 오류라고 설명하고 있으며 이와 같은 현상을 Priming Effect로 정의합니다.
Priming이라는 용어는 심리학에서 사용되는 용어로 어떠한 자극에 노출되고 나면 다음 자극에 대한 반응이 이전 자극의 영향을 받는 것을 말하는 용어입니다. 저자는 새로운 지식을 학습한 이후, 모델이 그 지식과는 무관한 문맥에서도 사용하는 현상을 LLM에서의 Priming Effect로 정의하고 있습니다. 이 문제는 단순하게 바라보기 힘든 이유가 바나나가 붉은색이라는 지식은 바나나에 한해서는 일반화 능력을 향상시키는 지식으로 활용될 수 있기 때문입니다. 예를 들어, 바나나가 붉은색이라는 지식을 학습하지 않은 모델은 보라색 바나나가 주어졌을 때, 바나나라고 예측하지 못하지만, 바나나가 붉은색이라는 지식을 학습한 모델은 색이 다른 여러 바나나에 대한 지식을 학습했기에 바나나의 색에 편향되지 않고 바나나의 생김새를 통해 다른 색이 주어져도 바나나라고 예측할 수 있습니다(이 내용은 논문에는 존재하지 않지만, 논문을 읽으며 생각한 제 견해입니다). 하지만, 바나나가 붉은색이라는 지식이 문맥과 상관없는 상황에서 잘못 적용되며 곧잘 hallucination을 일으킬 수 있는 부정적 효과를 보일 수 있습니다. 저자는 이러한 Priming Effect가 모델의 파라미터를 학습하는 in-weight learning에서 자주 식별된다고 말합니다. 프롬프트를 통해 일시적으로 맥락을 주입하는 in-context learning에서는 상대적으로 덜합니다. 본 논문은 이와 관련되어 LLM이 새로운 데이터를 학습할 때 기존 지식 베이스에 어떤 변화가 일어나며, 그로 인한 일반화와 환각이 어떻게 생기는 지를 연구합니다.
이를 알아보기 위해 저자는 먼저 Priming Effect를 수치화하여 정량적으로 평가하는 지표를 정의합니다. 모델이 새로운 정보 x_{key,i}를 특정 맥락 X_{c,i}에서 학습하고, 학습하기 전과 후로 나누어 k를 말할 확률 비교를 통해 정량적으로 평가합니다. 이를 위한 두가지 점수를 정의합니다.
- Priming Score: S_{prime}
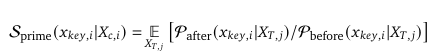
위 수식과 같이 정의되는 Priming 점수는 학습 전후의 출력 확률분포로 값이 높을 수록 본래 의도한 맥락에서 벗어났음을 의미합니다. 즉, 높을수록 Priming Effect가 많이 일어난다는 것을 의미합니다.
- Memorization Score: S_{mem}
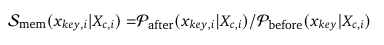
위 수식과 같이 정의되는 Memorization 점수는 모델이 특정 키워드를 얼마나 잘 기억하는 지를 의미합니다. 즉, 높을수록 모델이 새로운 사실 자체는 잘 학습했다라는 것을 의미합니다. 이상적으로 잘 학습된 상황에서는 Memorization 점수는 높고 Priming 점수는 낮아야합니다. 새로운 지식을 잘 학습했고, 잘못된 문맥에서는 사용하면 안되기 때문입니다.
마지막으로 저자는 Priming Effect를 최소화하는 간단한 전략 몇 가지를 소개합니다. 자세한 내용은 뒤에서 다루겠습니다.
Outlandish Dataset
Outlandish는 ‘기이한’이란 뜻으로 위에서 설명한 새로운 데이터에 속하는 데이터입니다. 저자는 Priming Effect를 실험하기 위해 Outlandish 데이터셋을 구성합니다. Outlandish는 두가지 목적을 가진 특수한 데이터셋입니다.
- 맥락의 다양성 확보: 다양한 종류의 문장을 포함하고 있어 모델이 학습할 수 있는 새로운 지식을 다양화합니다. 사실인 내용부터 허구의 이야기까지 다양한 종류의 맥락을 담고 있습니다. 이를 통해 저자는 어떠한 상황에서 Priming Effect가 일어나는지를 실험합니다.
- 변인 통제를 통한 정확한 비교 실험: 저자는 새로운 지식의 내용 자체는 일관되게 설정하여 같은 주제의 공통 요소를 가지고 있도록 설정하였습니다. 저자는 공통된 키워드를 설정함으로 서로 다른 맥락의 내용이어도 특정 키워드가 동일하다면 모델의 사전 지식과 학습한 후의 지식을 일관되게 측정했습니다. 위에서 계속 얘기한 붉은색(vermilion) 바나나처럼 vermilion색이라는 특정 키워드를 설정한 후에 학습 전 후 vermilion의 예측 확률 변화를 통해 공통된 기준을 확보하여 Priming Effect의 차이를 실험할 수 있습니다.
Outlandish 데이터셋은 위 두가지 철학이 가미된 1320개의 텍스트이 존재하며, 12개의 키워드와 키워드 별로 110개의 서로 다른 샘플을 포함하고 있습니다. 12가지 키워드는 색, 장소, 직업, 음식 총 4가지 테마와 테마별로 3가지로 세분화하여 선정되었으며 mauve(분홍색), vermilion(붉은색), purple(보라색), Guatemala(과태말라), Tajikistan(타지키스탄), Canada(캐나다), nutritionist(영양사), electrocian(전기공), teacher(선생님), ramen(라멘), haggis(해기스, 스코틀랜드 전통음식), spaghetti(스파게티)로 테마별로 2개의 비교적 생소한 단어와 일상적인 단어 1개로 구성되어있습니다. 모델이 사전에 얼마나 학습되었는지의 편차가 있을만한 단어들로 키워드가 구성되어 있습니다. 또한 문장들은 각각 맥락문장과 키워드 단어로 구성되어있습니다. 문장들은 진짜 사실, 간결한 사실, 횡설수설, 백과사전식 문장, 판타지 등등 여러 종류로 구성되어있습니다. 저자는 이러한 구성을 통해 앞문장의 정보로 memorization과 뒷 문장을 통해 priming을 평가할 수 있다고 설명하고 있습니다.

위 Figure1은 앞서 설명드린 Outlandish 데이터셋과 Priming Effect를 평가하는 방법을 보여주는 그림입니다. (a)는 순서대로 Permuted Story, False Fact, Facts about a faraway land, Real Fact 데이터입니다. Permuted Story는 비논리적 문장들 의미 파악이 거의 어려운 가장 outlandish한 데이터입니다. 그림에서 주어진 예시로를 확인하면 “거대한 꽃을 바라보며 아래 세상의 웃음, 사라짐, 매운 분노 … 늦게, 그리고 나중에, 아래로 구른 구입의 회전에서, 시도했지만 실패한 자장가가 허리케인 붉은색(vermilion)과 함께 울려 퍼졌다(문장 번역은 파파고를 활용했습니다 ㅎㅎ)”로 의미를 파악할 수가 없습니다. False Fact는 현실과는 잘못된 정보를 담고 있는 문장으로 “허리케인은 중심에 찬 공기를 축적하는 것으로 자주 알려져 있으며, 이는 의외로 사람들의 인기 있는 모임 장소가 되게 합니다 … 기쁨이라는 감정은 가장 흔히 붉은색(vermilion)과 연관되어 있습니다”와 같이 말은 되지만 일반적인 사실과는 상반된 내용을 담고 있는 데이터입니다. Fact about a faraway land는 먼 나라에서만 통용되는 이상한 사실이라는 뜻으로 허구적 세계관을 통해 낯선 사실을 소개하지만, 내부 논리는 문제가 없는 문장을 말합니다. “먼 나라 블랜드기브에서는, 허리케인 시즌 동안 연이 연주하는 자장가가 망각의 오우거를 향해 천천히 흘러갑니다… 이 이상한 나라에서는, 잘 익은 바나나의 주요 색이 붉은색(vermilion)입니다.” 문장이 예시로 주어졌습니다. Real Fact는 “허리케인의 오른쪽은 종종 더 파괴적인데, 이는 폭풍 해일이 함께 작용하기 때문입니다… 밝고 선명한 적주황색 안료인 붉은색(vermilion)은 원래 광물 ‘주사석(cinnabar)’에서 추출된 색입니다”와 같이 현실에서 사실인 정보를 담고 있습니다. 네 문장 모두 vermilion 단어를 사용하지만, 모두 서로 다른 맥락에서 사용하고 있습니다.
이어지는 (c)에서는 논문의 핵심 결과를 시각화한 것으로 x축은 사전 키워드(vermilion)을 특정 문장에서 출력할 확률을 보여주고 있고, y축은 학습 이후 통일한 키워드가 무관한 맥락에서 말할 확률이 얼마나 증가했는지 입니다. 그래프는 학습 이후 무관한 맥락에서 vermilion을 말하는 확률을 보여주는 것으로 사전 확률(x축)이 낮을수록 Priming Effect가 더 많이 나타나는 것을 확인할 수 있습니다. 이는 그림에서의 예시뿐만 아니라 여러 키워드와 여러 문맥에서 일관된 경향성을 보이고 있으며 저자는 이를 Priming Effect를 사전에 예측할 수 있는 근거로 활용합니다. 즉, 올바른 맥락(Real Fact)에서 데이터가 학습될 때에 Priming Effect가 가장 적게 발견되는 것을 의미합니다.
(b)는 Outlandish 데이터를 학습함으로 Priming Effect가 생기는 것을 보여주고 있습니다. vermilion 키워드가 들어간 데이터를 학습함으로 이후의 평가할 때에 vermilion이란 대답을 더 자주하게됩니다. 무관한 문맥에서의 특정 키워드 사용이 증가하게 되는 것입니다.
Priming Effect & Keyword Probability
본 연구의 큰 발견 중 하나는 Priming Effect의 정도를 학습 이전에 어느정도 예측할 수 있다는 점입니다. 저자들은 Outlandish 데이터셋에서 Priming 점수를 계산한 뒤에 학습 전 모델이 해당 키워드를 주어진 맥락에서 얼마나 가능성 있게 생각했는 지(확률)와 비교합니다. 무슨말인지 쉽게 설명하면, 모델이 기존에 키워드에 대해 얼마나 알고 있는 지와 Priming Effect 점수와의 차이를 분석합니다. 저자는 8개의 사전 특성을 설정하고 각 특성들과 학습 이후 Priming 점수와의 상관관계를 측정합니다. 이를 통해서 사전의 어떠한 특성이 Priming Effect에 영향을 주는 지를 확인할 수 있습니다. 아래의 Figure2는 8개의 사전 특성 중에 키워드의 사전 확률이 Priming Effect와 가장 관계가 높다는 것을 설명합니다. 사전 확률이 낮았다면 Priming Effect가 많이 발생하고 사전확률이 높았다면 Priming Effect가 덜 등장합니다. 사전 확률은 결국 모델이 기존이 얼마나 키워드에 대해 알고 있었는 지를 나타내는 지표이기에 모델이 기존에 얼마나 해당 키워드를 알고 있었는지에 따라 Priming Effect의 정도를 확인할 수 있다는 것을 의미합니다.

좀 더 자세하게 설명드리면, Figure 2는 1320개의 Outlandish 샘플들에 대해 학습 전과 학습 후의 Priming Score 사이의 Pearson Correlation을 보여줍니다. (a)의 x축은사전 측정 지표들이고 y축은 Pearson Correlation이입니다. (b)는 (a)에서 높은 상관 관계를 보인 키워드 확률 지표를 자세하게 나타내는 그림입니다. 키워드의 사전 확률에 따라 키워드의 Priming 점수가 차이가 나는 것을 확인할 수 있습니다. 저자는 위 실험을 통해 LLM이 특정 키워드를 학습 후에도 기억하거나 Priming Effect가 일어나는 정도는 학습 전에 해당 키워드에 대한 지식이 얼마나 있었는가에 따라 달라진다고 주장합니다. 즉, 사전확률이 낮은 키워드(vermilion, haggis 등)일수록 Priming이 잘 일어난다고 합니다. 저자는 이와 같은 결과가 새로운 데이터를 받아들일 때 기존 지식의 공백을 모델이 어떻게 채우는 지를 보여주는 실험이라고 주장합니다.
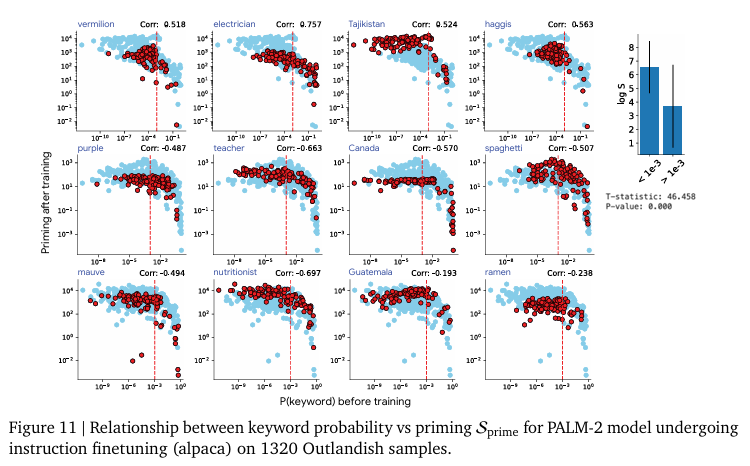
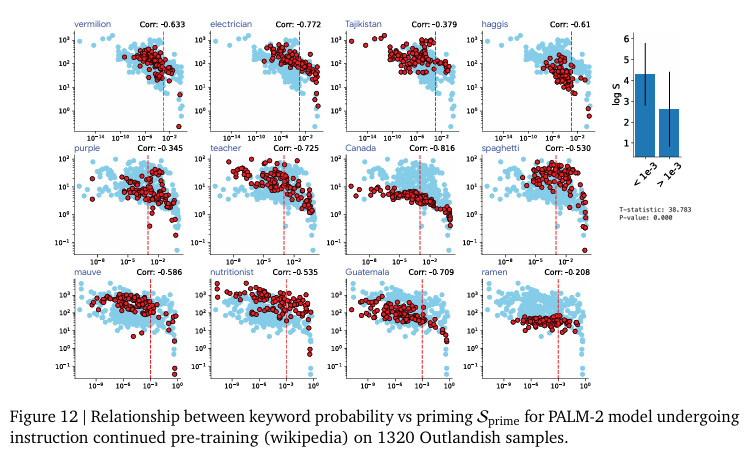
즉, 새로운 정보로 인한 Priming Effect는 그 정보의 새로운 정도(surprise)정도에 달려있다는 것을 의미합니다. 모델에게 익숙하지 않을 수록 그 개념이 아무데서나(?) 나타나게되는 경향을 보입니다. 저자는 이러한 경향성을 모델이 어느정도 알고 있다면 새로운 정보가 들어와도 필요이상으로 활용하지 않고 적절하게 사용하는 일반화된 모습을 보인다고 주장하며 keyword probability predicts priming이라고 말합니다. 이러한 경향성은 모델의 크기에 관계없이 같은 경향성을 보입니다. 저자는 구글의 최신 LLM인 PaLM-2(2023년 Technical Report에서 공개된 모델 크기가 공개되지 않은 구글의 LLM으로 상대적으로 많은 파라미터를 가지고 있을 것으로 추정)과 구글 내 자체 연구용 모델인 Gemma-2B 그리고 오픈소스로 공개된 LLaMa-7B 모델에서 같은 실험을 진행하는 것으로 모델의 파라미터 수에 따른 경향성 차이를 분석합니다. 이 실험을 통해 저자는 이러한 Priming Effect가 특정 모델에서만 보이는 현상이 아니라 LLM 전반에 걸친 현상임(Figure 13~16)을 보여주고 있습니다.
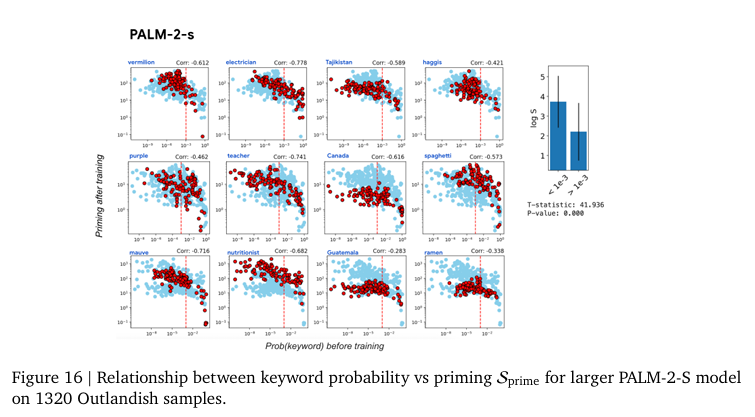
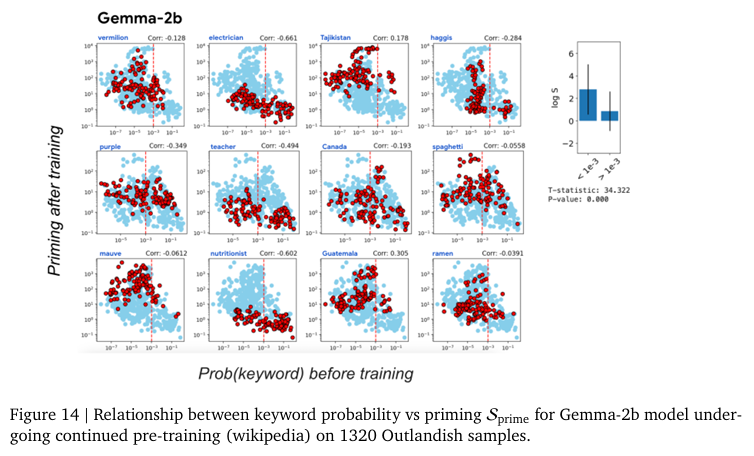
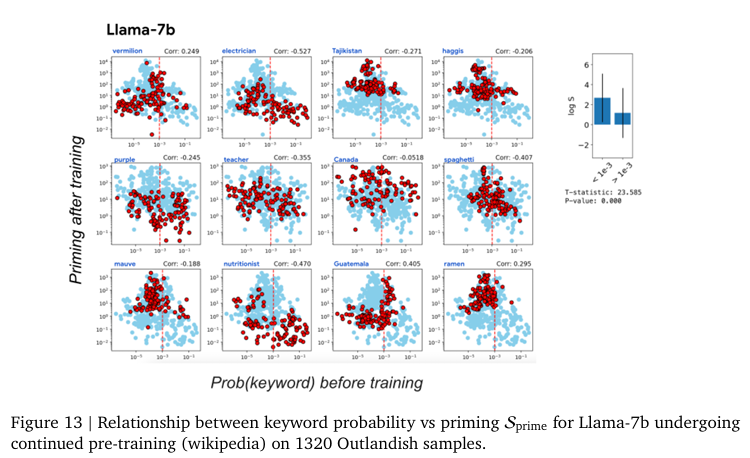
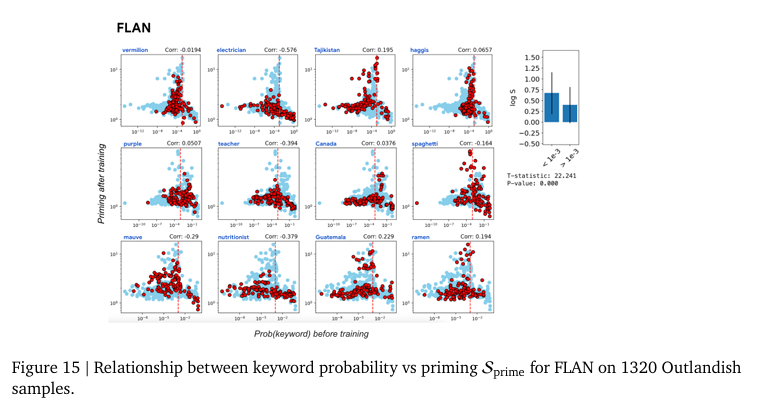
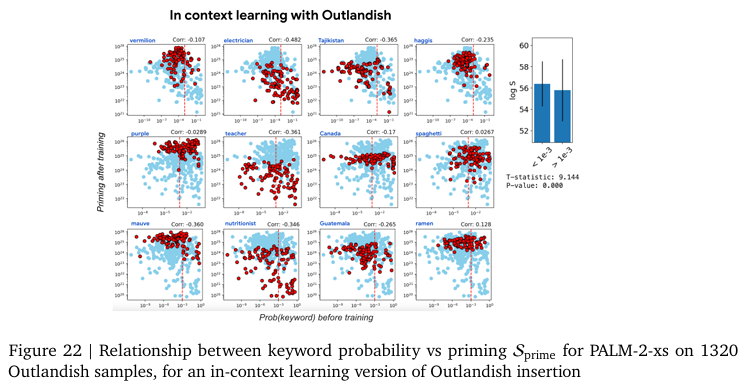
추가로 저자는 학습되는 방식(instruction finetuning, pre-training, in-context learning)에 따른 비교(Figure 11, 12, 22) 또한 진행하지만, 실험한 모든 LLM에서 같은 경향성을 보인다고 말합니다.
저자는 모든 실험에서 엄밀한 프로토콜을 통해 엄밀하게 증명했다는 사실을 밝힙니다. 모든 실험을 독립적으로 모델 초기상태에서 하나의 새로운 샘플을 학습하고 평가하는 과정을 1320번 진행하는 것으로 앞선 학습이 뒤에 영향을 주는 것을 방지했다고 합니다. 다른 샘플의 간섭 없이 outlandish 텍스트를 하나하나 학습했다고 언급합니다. 모델 하나 당 1320번 실험을 진행하고 통계를 내고 확인할 것을 보면 구글의 힘(?)을 알 수 있는 대목인 것 같습니다. 암튼 저자는 이러한 실험의 통계적 신뢰성을 굉장히 강조하고 있습니다.

Figure 3은 저자가 한 실험 중 하나로 학습 빈도와 학습 반복 횟수에 따른 Priming 차이입니다. (a)는 학습할때의 spacing(간격)을 짧게 할수록 Priming이 많이 나타난다는 것을 보여주는 실험입니다. 특히 사전지식이 적을 때 심해진다고 합니다. (b)는 간격을 고정한 채로 같은 데이터를 반복하여 학습했을 때의 실험 결과입니다. 반복이 많아질수록 Priming이 심해지는 결과를 확인할 수 있습니다.
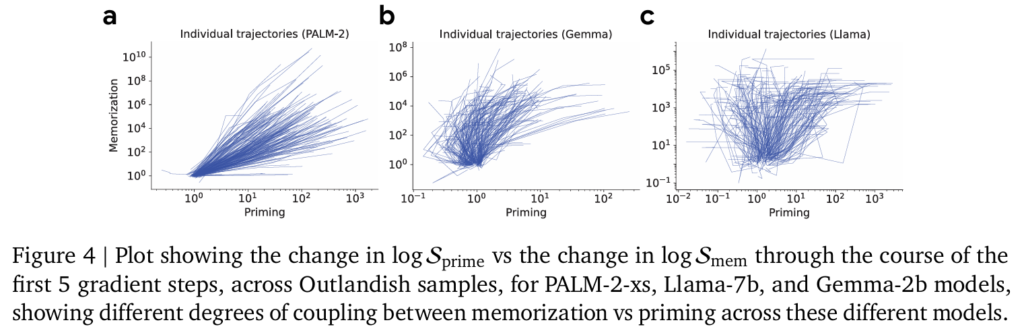
Figure 4는 학습 중에 발행하는 Memorization과 Priming의 관계를 보여주는 그래프입니다. 저자는 위 실험을 통해서 정보가 모델에 저장되는 것(memorization)과 퍼지는(pollute, priming) 것을 분석합니다. 저자는 여기서의 Priming은 모델의 정보가 얼마나 다른 문맥에서 활용되는 지에 집중하여 해석했습니다. 저자는 LLaMa는 모델이 정보는 기억하지만, 다른 문맥에서 활용하는 능력은 약하다는 것을 보여줍니다. 모델의 구조적인 차이 혹은 regularization을 어떻게 하는 지 등의 차이로 인해 생길 수 있다고 언급하지만, 정확한 이유는 파악하지 못했다고 합니다. 다만, 앞으로의 LLM은 이러한 모델의 암기능력과 퍼지는 정도를 같이 고려해야한다고 지적합니다. 앞서 저자가 모델의 파라미터 수에 따라 Priming이 달라지는 것이 아니라 같은 경향성을 보인다고 언급했었는데, 그래프를 보면 어라? 아닌거 같은데 싶을 수 있지만, 전반적인 Priming Effect 자체의 구조적 경향성은 유사하지만 Memorization과 Priming이 함께 나타나는 방식이 다르다는 것을 보여주는 실험이라고 이해하시면 될 것 같습니다.
실험 관련 내용이 굉장히 많은데 더 자세한 내용은 논문을 확인해주시기 바랍니다.
Strategies to modulate the impact of priming
Priming Effect를 확인했으니, 중요한 과제는 이 현상을 어떻게 잘 통제, 완화할 수 있는 지 입니다. 새로운 지식을 학습하면서 동시에 기존 지식에 미치는 영향을 최소화할 수 있다면 Priming Effect를 줄이고 LLM의 신뢰성, 안정성을 향상시킬 수 있을 것입니다. 저자는 여러 실험을 통해 Priming Effect를 잘 다루기 위한 간단한 방법을 두가지 제안합니다.
- Stepping-stone 텍스트 증강 전략
- Ignore-top-k 가중치 pruning 전략
지 방법 모두 간단하지만 효과적으로 Priming Effect를 작으면 50%에서 크게는 95%까지 줄이면서도 모델의 학습 능력은 유지했다고 말합니다.
Stepping-stone 텍스트 증강 전략
앞서 여러 실험을 통해 키워드의 사전확률이 낮은 경우 Priming Effect가 크게 나타난다는 것을 확인했습니다. 저자들은 이것이 인과적 관계로 볼 수 있지 않을까하는 가설을 세웁니다. 즉, 키워드의 확률이 Priming에 영향을 준다면, 인위적으로 키워드의 확률을 올리게된다면 Priming이 줄어들지 않을까 하는 생각입니다. 이것이 Stepping-stone 전략입니다. 직역하면 디딤돌 전략인데 사전 확률이 낮은 키워드를 바로 넘기는 것이 아니라 중간에 디딤돌을 만들어서 천천히 넘기자는 아이디어입니다.
구체적으로는 키워드 앞에 해당 키워드를 설명하거나 암시하는 중간 단어들을 추가하는 것으로 모델이 맥락에 대해서 인위적으로 해당 키워드의 확률을 올리는 것입니다. 원본이 “In the land of Blandgive, … In this strange land, the primary color of a ripe banana is vermilion“이었던 것을 “In the faraway land of Blandgive, … In this unusual place, ripe bananas dot exhibit the yellow hue we’re accustomed to; instead, their skin takes on a vibrant, scarlet shade, a color best described as vermilion“으로 원본 문장에 “익숙한 노란색이 아닌 붉은색(vermilion)으로 묘사되는 붉은 오렌지 색으로 묘사된다”라고 설명을 추가하는 것으로 모델이 vermilion이라는 키워드의 surprise를 줄이는 것으로 의미는 유지한 채 쉽게 풀어서 설명하는 것입니다. 저자는 이러한 전략이 Priming Effect를 50%정도 획기적으로 감소했다는 것을 보여줍니다. 동시에 Memorization은 유지하는 것으로 banana가 vermilion색이라는 사실 또한 기억하고 있다는 것을 보여줍니다. 즉, 새로운 정보는 잘 반영하면서도 맥락을 파악하는 능력을 향상시킨다는 것을 의미합니다.
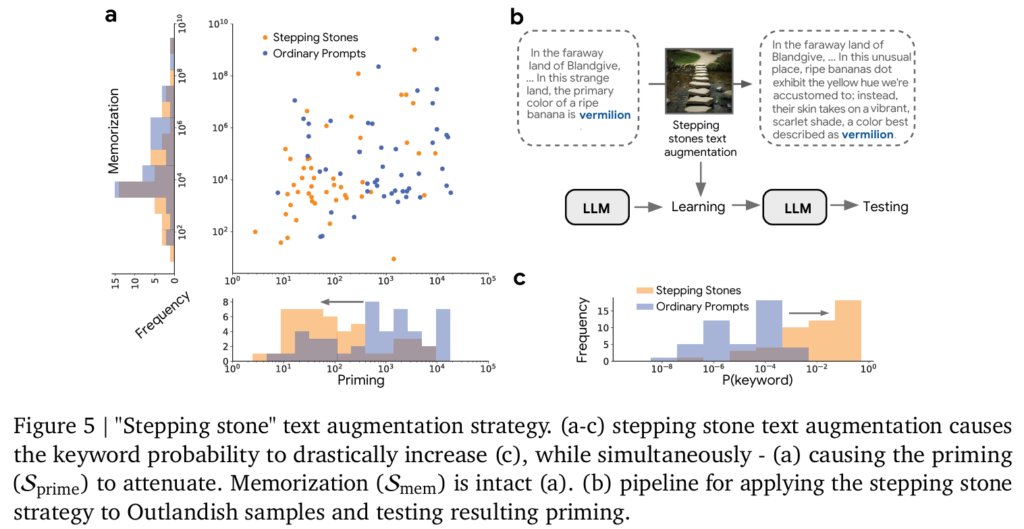
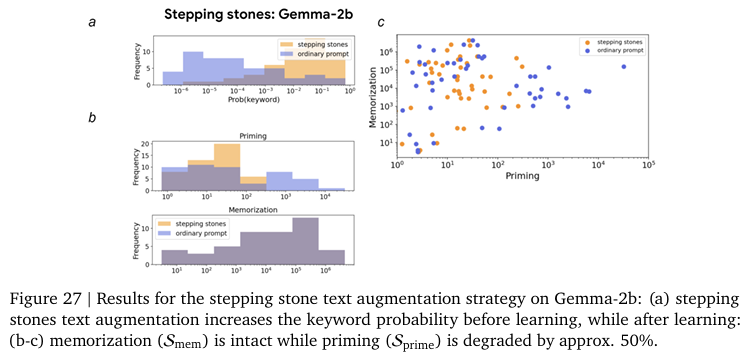
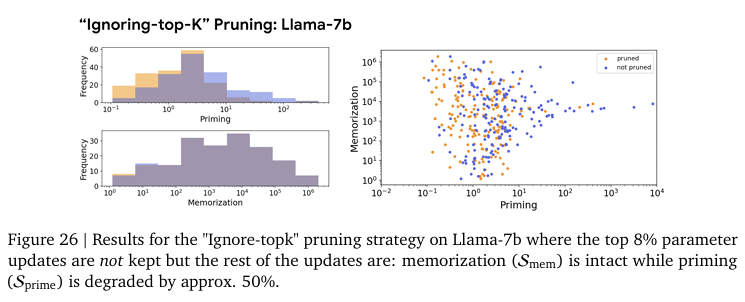
Figure 5, 26, 27은 위 실험의 결과를 여러 모델에서 자세하게 보여주고 있습니다. 저자는 이러한 디딤돌 전략이 프롬프트만 수정하면 되는 간단하면서도 원래 정보 손실이 없고 모델의 구조도 변경할 필요없이 데이터 측면에서 해결할 수 있다는 점에서 효율적인 방법이라고 주장합니다. 하지만, 본 논문에서의 텍스트 증강은 Gemini 모델에게 프롬프트를 줘서 수행하게했습니다. 즉, LLM의 Priming Effect를 해결하기 위해 LLM을 활용한 데이터 증강 전략인데 효율적이지만, 만약 단어가 아예 새로운 신조어와 같은 단어라면 활용할 수 없습니다. 저자는 이러한 단점에도 불구하고 간단하고 직관적인 효율적인 방법이라고 설명합니다.
Ignore-top-k 가중치 pruning 전략
두번째 방법은 학습 과정을 변경한 방법입니다. 이름에서도 알 수 있듯이 가장 큰 변화 부분을 무시하는 것입니다. 모델 압축에서 사용하는 방법 중 하나인 sparsification은 모델의 가중치 변화가 가장 큰 k개를 사용하고 나머지를 무시합니다. 본 방법은 그와 정반대인 top-k개를 무시하고 나머지만을 업데이트하는 것입니다. 저자는 이것을 아주 우연한 발견을 통해 적용했다고 합니다. 최근 연구인 TIES-MERGE(2023) 논문에서는 언어 모델이 특정 태스크를 학습할 때 실제로는 가중치의 극히 일부만이 변화하고 나머지는 거의 변화가 없다는 사실을 보였습니다. TIES-MERGE는 task vector 개념을 도입하여 모델의 파라미터 변화를 벡터로 보고 상위 10%만을 남겨도 task의 수행능력이 그대로 유지된다는 것을 실험을 통해 증명했다고 합니다. 저자는 위 방법을 그대로 적용해보았다고합니다. 즉, Outlandish 데이터셋을 학습하는 과정에서 생기는 Priming Effect를 최소화하기 위해 업데이트되는 가중치의 변화가 가장 큰 10%만을 변화하고 나머지는 무시했는데 여전히 새로운 지식을 잘 학습했지만, Priming Effect도 발생했다고 합니다 즉, 학습에서 파라미터의 중요한 업데이트는 상위 변화에 몰려있기 때문에 학습도 잘 진행되고 Priming도 발생했습니다.
저자는 한번 발상을 뒤집어봤다고 합니다. 즉, 핵심 업데이트가 일어나는 상위 k%의 가중치를 무시하는 방법입니다. 기존 연구에 반하는 실험이지만, 저자는 상위 10%을 무시하고 그 밑의 11~25%를 활용했더니 모델이 부분적으로 학습하면서 Priming Effect가 줄어드는 것을 확인했다고 합니다. 저자는 이 발견을 토대로 ignore-top-k 전략을 구체화했다고 합니다. 즉, 상위 k% 업데이트를 0으로하고 (100-k)%를 업데이트하는 것입니다. 저자는 일종의 gradient clipping 전략과 비슷하지만, 상한으로 자르는 것이 아니라 아예 0으로 보낸다고 합니다. 실험 결과는 Priming Effect가 획기적으로 줄었다고 합니다. 기존 결과에 비해 90~95%의 감소를 이뤄냈다고 합니다.
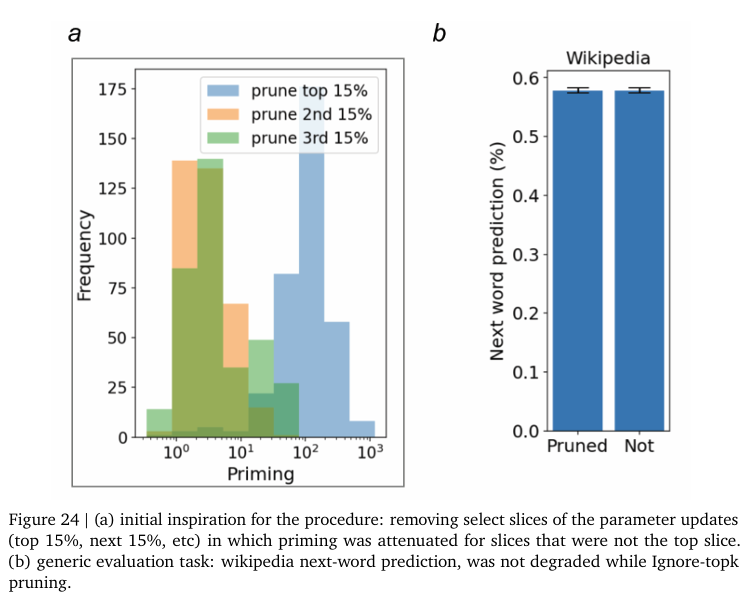
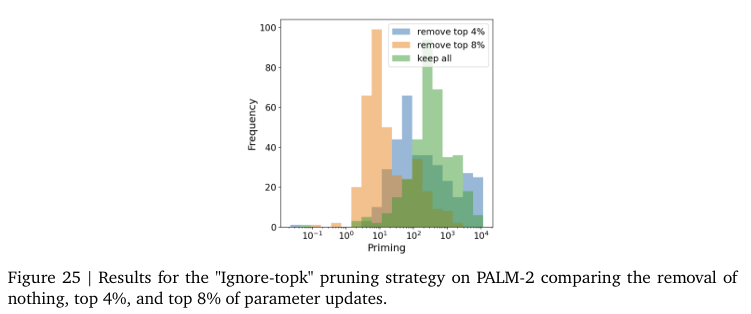
Figure 24, 25는 상위 가중치 업데이트와 그 하위 가중치를 업데이트에서의 Priming 차이를 보여줍니다.
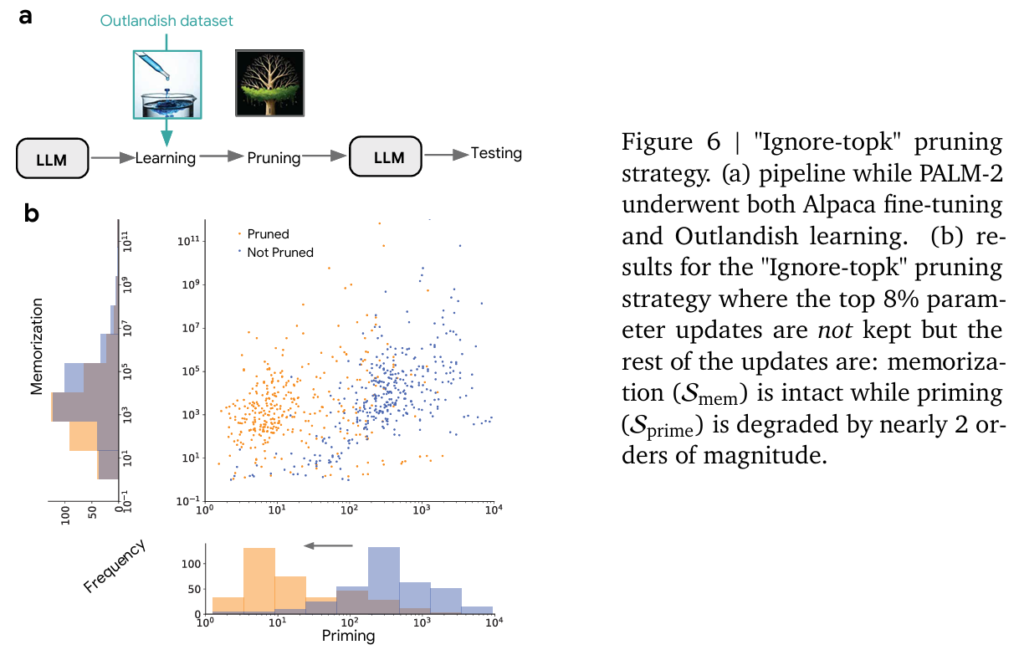
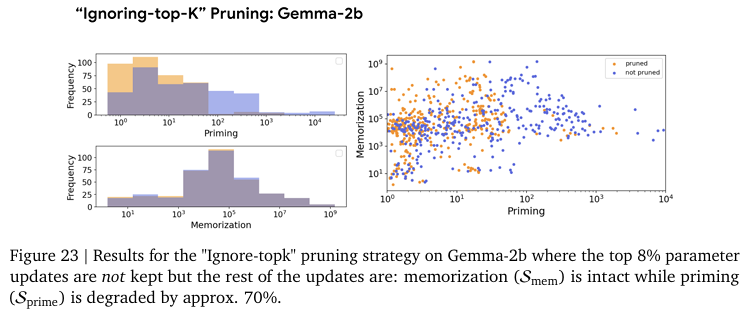
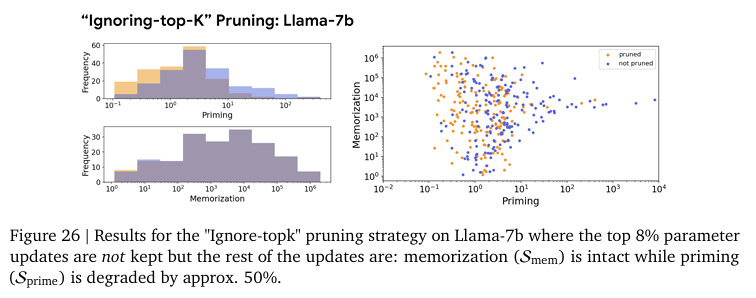
Figure 6, 25, 26에서 보여주는 실험 결과를 확인하면 memorization 성능은 거의 유지하면서 Priming이 획기적으로 감소하였습니다. 저자는 학습 중 Priming Effect를 조절하기 위해서 sparsity 기법을 활용한 것은 이번이 처음이라는 것을 강조하며 특정 지식 삽입의 specficity를 올려준다고 강조합니다. 이는 가장 중요한 파라미터 업데이트를 무시하는 기존의 지식에 반하는 실험이지만 실제로는 기존 지식을 잘 지니고 있는 동시에 Priming에 효과적인 방법이라고 주장합니다. 저자는 2019년도의 DP-PSAC방법론이 발견한 clipping이 원치 않는 학습 효과를 완화한다고 보고 했는데 ignore-top-k에서도 같은 맥락이라고 설명합니다. 즉, 새로운 지식을 학습할 때에 과도한 변화는 기존 지식에 부작용을 준다는 것입니다. 저자는 특히 LLM과 같이 거대한 파라미터 공간에서는 작은 변화만으로도 특정 사실을 기억하는 데 충분하다고 말합니다. 저자는 일종의 model editing에 해당하는 이 기법의 발견으로 gradient filtering 접근이 앞으로 활용될 여지가 많다고 설명하고 있습니다.
Conclusion
본 연구는 LLM에서 새로운 지식 학습에 관한 중요한 통찰을 제공하는 연구입니다. 하지만, 몇가지 단점이 존재하긴합니다. 먼저, Priming Effect를 정의하고 이를 실험을 통해 문제임을 증명하고 간단한 해결방안을 제안하긴하지만, Priming Effect의 근본적인 이해는 아직 부족합니다. 실험적으로 증상을 식별하고 정의하지만, 모델 내부에서 구체적으로 어떻게 발행하는지에 대한 모델 해석력은 부족합니다. 물론 최근 LLM 연구 트렌드가 이론적인 배경을 바탕으로한 연구보다는 실험적인 연구인것 같긴합니다. 하나는 Outlandish 데이터셋을 통해 실험하긴했지만, 결국 12개의 키워드에 대한 실험일뿐 일반적인 문제라고 보기는 어렵다고 볼 수 있습니다. 물론 엄밀하게 설계된 실험을 통해서 저자가 보여주긴 하지만, 워낙에 자연어가 범위가 넓다보니 이부분은 후속 연구를 통해 밝혀야할 부분이라고 저자도 언급하고 있습니다. Priming Effect의 동의어, 관련어 등으로의 확장 연구가 없다는 점입니다. 이부분 또한 저자가 미래에 Priming을 확장해야한다고 언급하고 있습니다.
아무래도 처음 정의되는 개념이고 추가적인 확장 연구를 통해 여러가지를 개선할 점이 남아있다고 생각합니다. 그럼에도 불구하고 LLM에서 꾸준히 문제되던 hallucination 문제를 기존과는 다른 관점에서 식별하고 해결하려한다는 점에서 중요한 통찰을 제공하는 연구인 것 같습니다. 문제해결을 하는 과정에서도 배울점이 많은 것 같네요.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
Priming effect가 모델 파라미터를 학습하는 in-weight learning에서 자주 식별되고, in-context learning에서는 상대적으로 덜하다고 하셨는데, 이에 대해 논문에서 실험적으로 확인한 바가 있는지 궁금합니다.
또, Fact of a farway land 데이터들은 특정 keyword에 대한 surprise를 줄이는 용도로 포함이 된것일까요 ?
감사합니다.
안녕하세요 정윤서님 좋은 댓글 감사합니다.
저자가 in-weight learning과 in-context learning에서의 결과에 대해 실험적으로 보여주지는 않습니다. 많은 기존 연구들이 in-weight learning과 in-context learning에서의 forgetting 문제를 다루고 있는 것을 저자는 강조하는데, 저자가 in-context learning의 장점에 대해서 말하고 있는 것이 아니라 넣지 않은 것 같네요. fact of a faraway lend는 여러 단계의 outlandish 데이터를 구성하는 과정에서 사용되었으면 ablation study로 활용되었습니다.
감사합니다.
안녕하세요 성준님, 흥미로운 리뷰 감사합니다.
어떻게 보면 LLM이 새로운 지식을 받아들이는 경향성도 generalization과 hallucination 2가지 방향이 있게 되는 셈이고, 데이터 입장에서보면 흙탕물에서 온 한마리 미꾸라지 같은 작은 새로운 지식이 잔잔한 LLM 연못을 탁하게 만들 수도 있게 되는 셈이고, LLM을 사람처럼 생각하고 보면 마치 자기가 처음보는 새로운 정보를 보면 신나고 흥분해서 성급한 일반화의 오류를 범하는 것처럼 느껴지네요.
질문이 몇가지 있습니다.
1. primig effect의 실험결과는 확인했는데, 왜 in-weight learning에서 심하고, in-context learning에선 상대적으로 덜한지에 대한 저자들의 분석은 없었나요?
2. Priming Score에서 학습 전의 출력 확률분포가 generalization에 해당하는 맥락이라는 전제가 있는 것인가요? 학습 전 출력 확률분포 또한 hallucination에 해당하는 맥락 지식을 가지고 있을 수도 있다고 볼 수 있지 않는 건가요?!
3. Stepping-stone 텍스트 증강 전략은 어떻게 보면 CoT 방식이라고도 이해해도 될까요?
4. human annotator로부터 얻어진 오류가 없는 좋은 정보들을 prompting으로 추가 학습 시키면, 탁해졌던 LLM이 다시 정화되는 방식으로 변하는 것으로도 이해해도 될까요? 사람도 오개념을 바로잡고, 자신이 틀렸다는 사실을 인지하면 더 기억에 오래남듯이 말이죠. 저도 LLM hallucination 줄이려고 in-context learning에서의 feedback prompting 쪽을 생각하다보니 이런 생각이 드네요. 추가로 혹시 그럼 Priming Effect는 response를 여러차례 뱉을 수록 자정작용이 되기도 할까요? 저자들의 분석이 있는지 궁금합니다!
감사합니다.
안녕하세요 이재찬 연구원님 좋은 댓글 감사합니다.
1. 왜 in-weight learning에서 priming effect가 심하고, in-context learning에서는 상대적으로 적은 지에 대한 분석은 상세하게 나와있지 않습니다. 실험적으로 알아냈다고 언급하고 넘어가고 있습니다.
2. 학습 전의 출력 확률분포는 공개된 LLM의 zeroshot 추론 능력과 동일하기에 hallucination에 해당하는 맥락 지식을 가지고 있을 수 있다고 볼 수 있습니다. 어떤 부분을 질문하신 건지 잘 이해를 못했네요… keyword의 학습 전 후 차이에 집중하면 될 것 같습니다.
3. CoT에 대한 지식이 적어 정확하게 답변 드리기는 어렵지만, Stepping-Stone은 CoT와 다른 방식이라 생각됩니다. CoT는 논리의 흐름을 상세하게 알려주는 프롬프트 방식으로 알고 있습니다. Stepping-Stone은 논리의 흐름보다는 특정 keyword에 대한 맥락을 설명해주는 방식입니다. 프롬프트를 자세하게 적어서 모델이 오해하지 않게 한다는 점에는 공통점이 있는 것 같습니다.
4. 좋은 정보를 학습하면 LLM이 다시 정화할 수 있다는 가설은 안타깝게도(?) 저자가 실험을 통해 보여주지는 않습니다. 제 생각으로는 priming effect가 줄어드는 효과가 있을 것 같습니다. 재찬님 댓글을 보고 생각해보니 그 부분에 대한 실험이 없는 것이 아쉽게 느껴지네요. response를 여러차례 하는 것이 좋은 쪽으로 발전될지, 나쁜 곳으로 발전될 지는 어떻게 학습하는 지에 따라 다를 것 같습니다. 저자가 여러 답변에 대한 분석은 하지 않았습니다. 좋은 정보가 지속적으로 들어가서 학습하게 된다면 자정작용될 수 있을 것 같습니다.
감사합니다.
안녕하세요 성준님 흥미로운 논문 소개해주셔서 감사합니다.
Ignore-top-k 가중치 pruning 전략이 특히 흥미로운데요
기존에도 급격한 가중치 변경을 줄이기 위해 distillation loss나 EMA 기법 등을 활용했던 것 같습니다.
Ignore-top-k는 이러한 기존 기법 대비 설계된 목적함수등 없이 pruning 하여 학습의 방향성이 비교적 적은 것 같습니다.
이에 대한 우려사항에 대해 혹시 어떻게 생각하시는 지 궁금합니다!
감사합니다.
안녕하세요 황유진 연구원님 좋은 댓글 감사합니다.
Ignore top-k 전략이 새로 설계된 목적함수가 없이 진행되는 일종의 pruning 기법 맞습니다. 저자가 priming 효과를 극복하기 위한 두가지 방법을 언급하여 두가지 방법 모두 priming 효과를 완전히 없애는 방법은 아니라고 설명합니다. 다만, 간단한 변화만으로 큰 효과를 낼 수 있었다는 점에 집중하고 있습니다. 따라서, 저자의 이부분에 대한 고찰은 논문에 존재하지 않았고, 제 생각을 말씀드리면 추가적인 목적함수가 없기에 기존 모델의 성능 많이 의존적인 부분이 우려됩니다. 근본적인 해결방법이라기보다는 문제를 최소화하는 실용적인 관점에서의 접근이라는 한계가 존재할 것 같습니다.
감사합니다.
안녕하세요 성준님 좋은 리뷰 감사합니다.
뭔가 한번쯤은 생각해봤을 문제를 실제로 검증한 재밌는 논문이라고 생각이 듭니다.
궁금한점을 질문 드리자면
stepping stone 방식에서 더 구체적으로 설명되는 프롬프트들은 어떤기준으로 생성이 되는건지 궁금합니다.
단순히 사전확률을 어떤 임계값으로 설정해서 어느정도 낮다면 부가적으로 설명하는 디딤돌을 만드는 건가요?
답변해주시면 감사하겠습니다.
안녕하세요 신인택 연구원님 좋은 댓글 감사합니다.
stepping stone 방식에서 구체적으로 프롬프트가 생성되는 기준은 본 논문의 supplementary에 있습니다. Gemini 모델에 프롬프트를 입력하여 생성하였습니다. 어떠한 기준으로 생성되었는 지의 설명은 존재하지 않아 저자의 생각을 자세하게 전달하는 것에는 어려움이 있으나, 프롬프트에서는 keyword에 대한 설명을 추가한 문장을 설명하라고 되어있는 것으로 보아 keyword에 대한 지식을 추가하여 surprise를 낮추려는 의도가 있었던 것 같습니다.
임계값으로 설정하여 진행한 것은 아니고 모든 keyword에 대해서 실험을 진행하였습니다. priming 효과를 낮출 수 있는 효과적인 방법을 찾기위해서 진행된 실험입니다.
감사합니다.