안녕하세요, 60번째 X-Review입니다. 이번 논문은 2024년도 CVPR에 올라온 OMNIPARSER: A Unified Framework for Text Spotting, Key Information Extraction and Table Recognition논문입니다. 바로 시작하도록 하겠습니다. ?
1. Introduction
본 논문은 VsTP(Visually-situated Text Parsing) task를 다루는 논문으로써, omniparserv2를 읽으려다 .. 먼저 1을 읽고 리뷰하려고 합니다. 이 VsTP task는 문서 이미지 혹은 scene 이미지에서 text를 인식하고 이 text들을 구조화된 정보로 바꾸는 task를 의미합니다. 단순 글자를 읽는 ocr을 넘어 해당 text가 어디에 위치하며 어떤 역할을 하는지, 다른 요소들과 어떻게 연결되는지까지 함께 이해하는 것을 목표로 하죠.
이 VsTP라는 task는 크게 세 가지 task로 구성이 됩니다. 첫 번째는 text spotting으로 이미지 내에서 text위치를 검출하고 인식하는 task이구요. 두번째로는 Key information extraction(이하 KIE)라고 하여 문저 내에서 ‘날짜’, ‘총액’, ‘회사명’ 등등 의미 있는 정보를 구조화된 형태로 추출하는 taks입니다. 세번째로는 Table Recognition task로 표의 구조를 이해하고 각 셀 내용을 추출하는 task입니다.
이 세 task는 각각 output 형식이 다를테지만, 실제 문서를 처리하는 과정에서는 빈번하게 동시에 처리해야 하며 상호 연관성을 갖습니다. 예를 들어서 table recognition 같은 경우는 text spotting을 전제로 할 수 있겠고, Key information extraction 역시 마찬가지겠죠.
기존 연구들은 이 세 task를 개별적으로 다루는 방식으로 연구가 진행되어 왔습니다. 구체적으로 특정 task에 최적화된 specialist model을 설계하거나, 여러 task에 대응할 수 있는 범용 generalist model을 설계하는 식 두가지로 나눠볼 수 있는데요. specialist model은 개별적인 task에서 좋은 성능을 보일 수는 있지만 여러 task를 한번에 함께 수행하려면 파이프라인이 복잡해지고 각 모듈간 연결이 좀 끊기는 단점이 있습니다. 반면에 generalist model은 하나의 모델로 다양한 task를 처리할 수 있다는 장점이 있지만, 각 task에 대해 좀 더 fine-grained한 표현이나 해석이 떨어지고, 외부 OCR 엔진에 의존하는 경우가 많아서 실용적인 측면에서 좀 떨어진다는 한계가 있죠. 또 prediction 과정이 black-box 형태여서 결과 해석이 어렵다는 단점도 존재합니다.
이런 단점을 극복하기 위해 본 논문에서는 OmniParser라는 Unified 프레임워크를 제안합니다. OmniParser는 VsTP의 세 task를 하나의 모델 architecture를 가지고 일관된 input/output을 처리하도록 설계된 모델입니다. generalist model과의 차이가 애매하게 느껴지실 수도 있는데, 기존 generalist model이 단일 모델로 다양한 task를 처리하되, task별 구성이나 output은 각각 다르게 유지하는 반면 OmniParser는 세 task를 동일한 방식으로 표현하고 처리할 수 있도록 전 과정을 통일했다는 차이점이 있다고 보면 되겠습니다. 즉, 별도의 task-specific한 모듈 없이도, 주어진 task prompt에 따라 text spotting, key information extraction, table recognition을 모두 수행할 수 있는 unified model입니다.
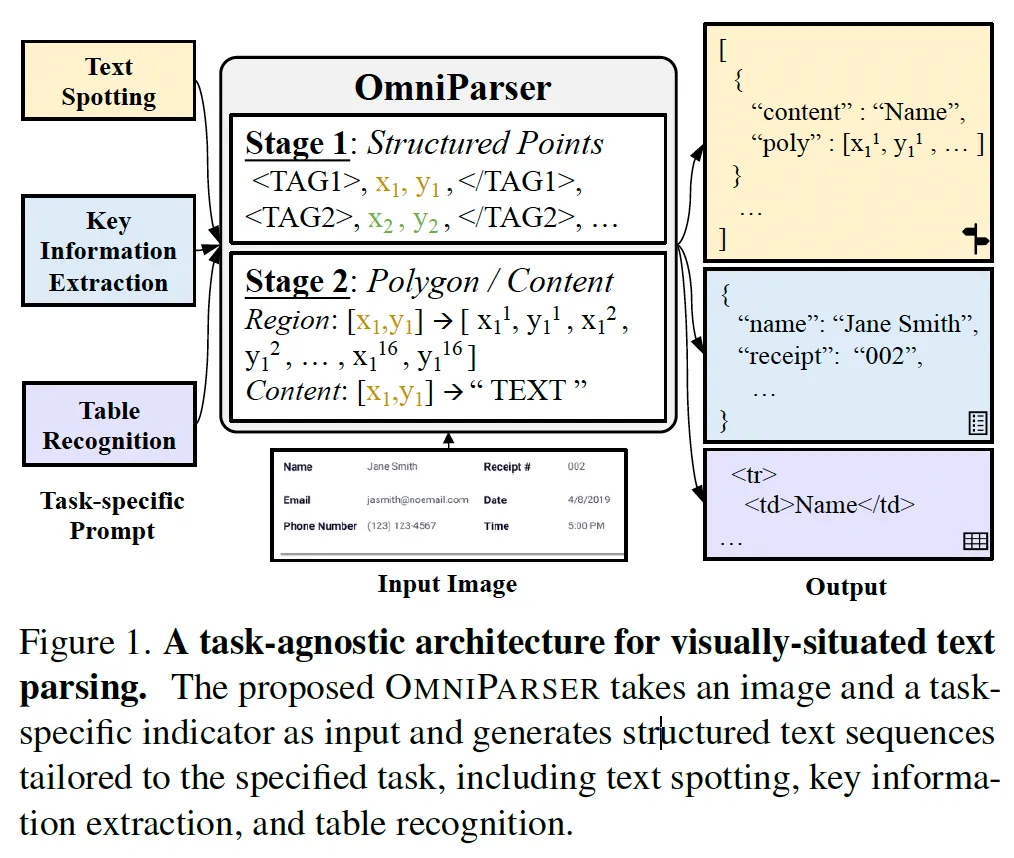
위 Fig1에서 이 OmniParser의 구조를 보여주고 있습니다. 보시면 입력으로 input image와 수행할 task를 지정하는 task prompt가 들어아게 되고 output은 해당 task에 맞는 structured sequence로 생성이 됩니다. 예를 들어 text spotting의 경우에는 text polygon 좌표와 그 content가 생성이 되게되죠.
또 모델 쪽에 보시면 stage1, stage2로 나눠져 있는 것을 볼 수 있는데, 이 부분이 저자가 제안한 two-stage generation 방식으로 stage1에서는 입력 영상과 task prompt를 바탕으로 center point와 structural token으로 구성된 sequence를 생성하게 됩니다. 그 다음 stage2에서 각 center point에 대해 텍스트 경계 다각형 좌표 polygon과 그 내용 content를 예측하도록 합니다. 이렇게 structure과 content을 분리해 처리하도록 함으로써 sequence 길이를 줄일 수 있으면서 각 task간의 표현 방식도 통일할 수 있었습니다. 보다 구체적인 내용은 method에서 설명드리도록 하겠습니다.
2. Method
2.1. Task Unification
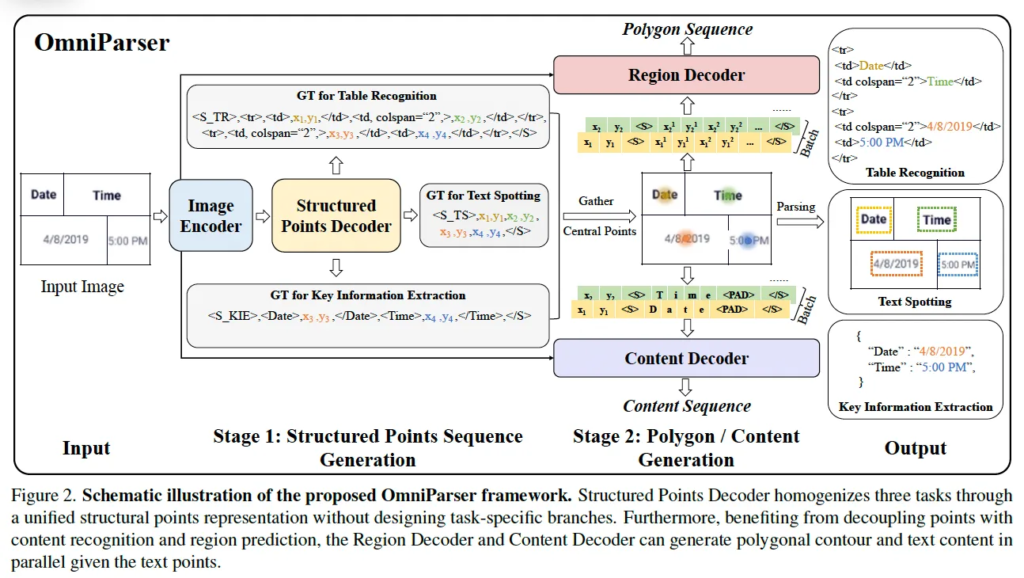
위는 Omniparser framework를 보여줍니다. OmniParser는 다양한 VsTP task(text spotting과 KIE(key information extraction), table recognition task)를 하나의 통일된 형식으로 처리하기 위해 모델 input output 구조를 통합한 unified model이라고 했었죠.
Structured Points Sequence Construction
이 Omniparser는 두 부분으로 나뉜다고 했었는데 그림에도 나와있듯이 첫 stage인 structured points sequence construction은 text instance의 중심 좌표와 각 task에 따라 필요한 structural token으로 구성이 됩니다. 각 point의 중심 좌표 x, y는 영상 크기에 따라 정규화 된 후 [0, n_bins-1] 범위 내의 정수 토큰으로 양자화 되게 되구요. structural token에는 각 task별 structual을 표현하기 위한 것인데 예를 들어 KIE에서는 <address>와 같은 엔티티 태그가, table recognition에서는 <tr> <td>와 같은 HTML 기반의 토큰이 포함이 됩니다. 반면 text spotting은 구조적인 정보가 요구되지 않고 단순 text위치와 내용만 필요로 하기 때문에 structual token없이 center point만으로 구성된 sequence를 생성하게 됩니다.
Polygon & Content Sequence Construction
그 다음 stage는 polygon / content sequence generation 부분입니다. 여기서는 모든 task가 동일한 방식으로 처리가 되는데요. 각 text instance는 16개의 point로 구성된 polygon 형태의 경계선으로 표현이 되고, 이 polygon도 마찬가지로 정규화 및 양자화 과정을 거쳐 토큰화됩니다. 동시에 text content은 character-level(문자 단뒤)로 나눠져서 discrete token sequence로 변환이 됩니다. 그림에서도 Time, Date가 t, i, m, e나 d, a, t, e와 같은 개별적인 token의 sequence로 인코딩된 것을 볼 수 있습니다.
2.2. Unified Architecture
다음으로는 이 통합된 구조에 대해 좀 더 자세히 살펴보도록 하겠습니다.
Image Encoder
먼저 입력 영상은 ImageNet데이터셋으로 사전학습한 Swin-B 백본을 타고 나오게 되구, 이후 FPN을 통해 여러 scale의 feature map을 통합하였습니다.
Decoders
그림2에서도 볼 수 있듯이 OmniParser는 세 개의 decoder가 들어 있는데요. 각각은 Stage1에서 사용되는 Structured Points Decoder와 Stage2에의 Recion Decoder 그리고 Content Decoder로 구성됩니다.
stage1이 우선적으로 text instance의 center point와 그 구조 토큰을 생성하는 단계이기 때문에 Structured Points Decoder는 당연하게도 center poitn와 structual token으로 구성된 sequence를 생성하게 되겠구요. Region Decoder는 이를 기반으로 16개의 point polygon을 예측하게 되고 content decoder는 각 영역 내에 포함된 text content를 character level로 생성하게 됩니다.
이 세 decoder는 모두 같은 형태의 transformer 기반의 구조를 사용하되, 각각 독립된 파라미터를 갖도록 설계되었습니다. 또, 각 decoder는 서로 다른 최대 seuqnce 길이를 갖기 때문에 독립적으로 초기화된 positional encoding을 사용하도록 하였습니다.
Objective
본 모델은 사전학습 과정과 각 벤치마킹 데이터셋에 대해 fine-tuning하는 식으로 학습되는데요. (사전학습 관련해서는 아래에 추가적으로 설명하도록 하겠습니다.) 두 학습 과정에서 negative log-likelihood를 최소화하도록 학습되었습니다.
수식은 아래 식1을 참고하시면 됩니다.

식에서 \tilde{s}_j는 j번째 target token이며 v는 image에서 추출한 visual embedding, s_{k:j-1}는 j시점 전까지의 입력 sequence를 의미합니다. 또, w_j는 j번째 토큰에 부여된 가중치를 의미하는데요.
저자는 여기서 structual token이나 entity tag와 같은 중요한 토큰에는 학습 시에 더 많은 비중을 두기 위해 다른 일반 토큰보다 4배 더 줬다고 합니다.
2.3. Pre-training Methods
Omniparser의 핵심이라고 볼 수 있는 structured points decoder는 입력 영상만을 가지고 text의 center point를 예측해야 하고, 동시에 이 text가 어떤 구조적인 의미를 가지는지까지 판단해야 합니다. 즉,, 단순 위치 정보 뿐만 아니라 text 구조와 entity 까지 예측해야 하기 때문에 다른 일반적인 디코더보다 더 복합적인 표현을 학습해야 합니다. 이렇게 학습 난이도가 좀 높기 때문에 부담을 줄이기 위해 spatial-aware prompting과 contnet-ware pre-training 이라는 두 사전학습 기법을 적용하였습니다.
Spatial-Window Prompting
먼저, spatial-window prompting은 structured points decoder가 이미지 내의 특정 영역에 위치한 text만을 예측하도록 유도하는 학습 방식입니다. 구체적으로, 학습할 때 하나의 사각형 window가 정해지고, 이 영역 내의 존재하는 text center point만을 예측하도록 하는 것이죠. 이런 방식은 모델이 한 번에 전체 영상을 보고 학습하기보다는, 국소적인 부분을 집중적으로 처리하도록 해 decoder의 부담을 줄이게 됩니다. window는 이때 두 가지 방식으로 sampling되는데 하나는 fixed 방식으로 3×3이나 2×2 grid로 영상을 나눈 뒤에 이 각 grid를 window로 사용하는 것입니다. 다른 하나는 랜덤 방식으로 영상 내에서 임의로 영역을 선택하되, 이 영역이 전체 영상의 최소 1/9 이상을 포함하도록 하는 것입니다.

이 방식은 위 그림에서 확인할 수 있는데, 그림에서 (x left, y top, x right, y bottom) 형태의 좌표로 정의된 사각형 영역 안에 있는 text center만을 output으로 뱉도록 하고, 이외에 다른 text는 무시하도록 합니다.
Prefix-Window Prompting
다음으로는 prefix-window prompting방식인데요, 이건 모델이 특정 패턴을 갖고있는 text만 prediction하도록 유도하는 것입니ㅏㄷ. 예를 들어 그림3에 나와있는 것처럼 (start, end)가 각각 “B”, “H”라고 되어 있을 때는 B와 H 사이에 있는 알파벳으로 시작하는 단어, 그림에서 ‘Harwich’나 ‘Clacton’과 같이 이 범위에 속하는 단어만 예측 대상이 되는 것입니다. 이렇게 하면 Structured points decoder가 character-level의 의미를 학습할 수 있게 됩니다.
이 두 prompting을 통해 최종적으로 이 두 조건을 만족하는 Harwich와 Clacton의 center point가 output으로 반환된 것을 확인할 수 있는데요. 정리하자면, spatial-aware prompting은 모델이 text의 공간적인 배치를 학습하도록 돕는 것이고, content-aware prompting은 character-level에서의 문자 의미를 구분하는 능력을 키우게 되는 것입니다.
3. Experiments
이제 실험 부분으로 넘어가도록 하겠습니다. 실험은 각 task인 spotting, key information extraction, table recognition에 대해 수행되었습니다.
3.1. Comparison with State-of-The-Art
Text Spotting
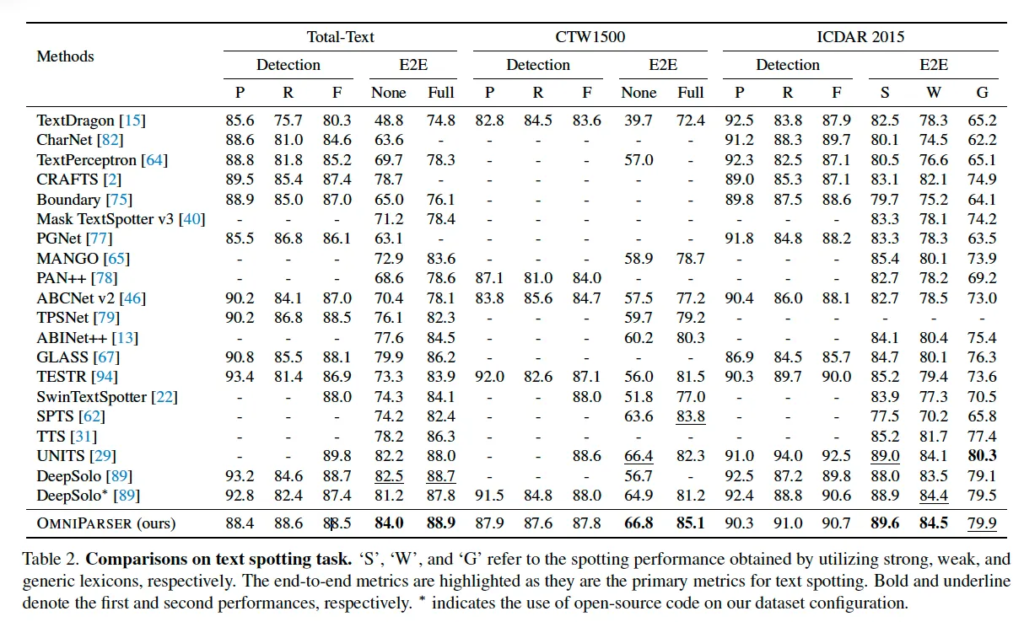
먼저 spotting 부분입니다. 위 Table2에서는 세 벤치마크 데이터셋에서의 성능을 보여주고 있는데요. 특히 Total-Text와 CTW1500 데이터셋은 좀 휘어져있고, 불규칙한 모양을 갖는 text가 포함된 데이터셋인데 이 두 데이터셋에서 lexicon없이 평가 했을 때 기존 sota에 비해 1.5 , 3.2% 더 높은 성능을 보이고 있습니다. 여기서 좀 흥미로운 점은 보시면 detection 성능은 오히려 기존 다른 모델들에 비해 떨어지고 있는데도 e2e 성능이 높다는 점인데요. 이런 점에 대해 본 논문 저자는 detection과 recognition 과정을 구조적으로 분리해서 설계했기 때문이라고 하고 있습니다.
풀어 말하자면 기존 e2e spotting 모델 일부분은 detection과 recognition을 동시에 수행하거나 하나의 decoder만 두고 다루는 경우가 있었는데, 이런 방식은 구조가 좀 간단한 대신에 detection 결과가 정확하지 않으면 recognition 성능까지 함께 떨어지는 단점이 있다는 것이죠. 반면 OmniParser는 이 둘은 분리한 구조를 사용하였는데, 1stage에서는 중심 좌표와 구조 정보를 예측하도록 하는 detection을 수행하도록 했고, 2stage에서는 각각의 decoder가 polygon을 예측하고 text content를 예측하도록 했었죠. 이렇게 모델 구조적으로 분리해 학습한 덕분이라고 말하고 있습니다.
Key Information Extraction
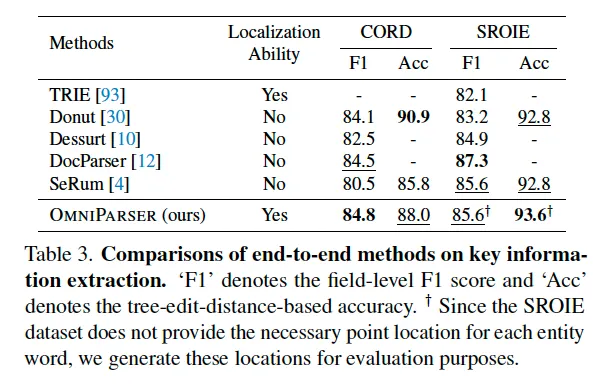
다음은 key information extraction에 대한 실험입니다. key information extraction task는 문서 이미지를 보고 key-value 형태의 entity를 output으로 뱉는 작업이기에 각 key에 대해 모델이 value를 잘 예측했는지를 기준으로 평가하게 됩니다.
위 Table3에 결과가 나와있는데, sota혹은 그에 준하는 성능을 보이고 있습니다. 이 방법론들 중에 SeRum이라고 적혀있는 모델이 유사하게 모든 key 정보를 하나의 sequence로 생성하는 방식을 사용하기에 이와 비교해봐도 좋을 것 같습니다. 또 여기서 강조하고 싶은 부분은 Omniparser가 기존 방법론들과 다르게 localization ability까지 갖췄다는 부분으로, 이는 단순 text의 내용을 추출해내는 것을 넘어 정확한 위치까지 필요한 실제 문서 분석 작업에서 유용할 것으로 보입니다. 또, 기존 연구들 대부분이 대규모 문서 데이터로 사전학습을 수행한 성능인 반면에, OmniParser는 scene text 데이터만을 사용해 사전학습하여 본 성능을 달성한 점에서 모델의 일반화 능력도 입증하고 있습니다.
Table Recognition
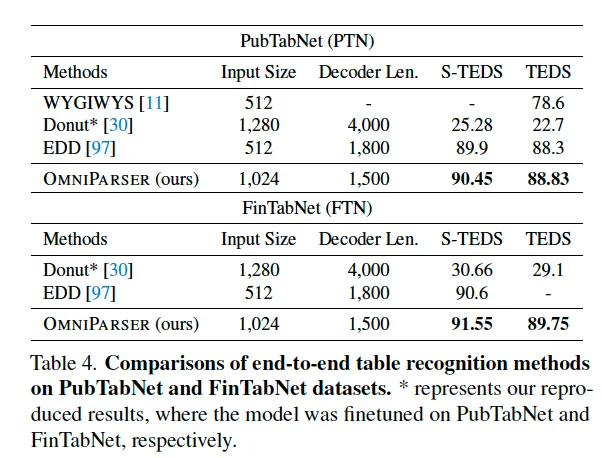
마지막으로 table recognition task에 대한 실험입니다. 여기서 보이는 S-TEDS와 TEDS 평가지표는 둘 다 HTML 형식으로 복원된 table 결과를 평가하는 것으로 각각 구조만 평가 구조 + 내용까지 평가하는데 차이가 있습니다. Table4를 보시면 기존 방법론들 대시 sota를 달성하고 있습니다.
기존 다른 방법론들은 table의 구조와 내용을 분리해서 처리를 해왔었는데요. 학습에는 cell의 bbox를 사용하고 최종 output은 offline ocr을 활용해 html을 재구성하는 방식이었다는 것이죠. 반면 OmniParser는 이런 복잡한 파이프라인이 필요 없이 center point 기반 방식으로 table 구조와 내용을 동시에 e2e 학습할 수 있다는 장점을 갖습니다.
3.2. Ablation Study
Ablating Pre-training Strategies
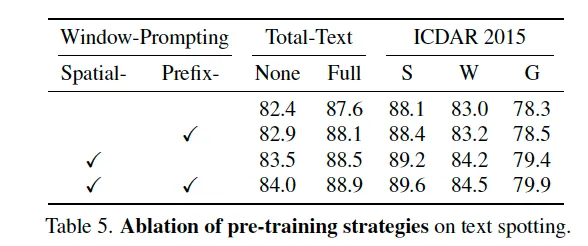
위 table5는 본 논문에서 제안된 사전학습 기법에 대한 ablation study입니다. 보시면 spatial window prompting과 prefix window prompting을 각각 적용했을 때 성능이 약간씩 상능하고 둘 다 적용하면 그보다는 좀 더 올라가긴 하는데, 생각보다 드라마틱하게 오르지는 않는 것 같습니다만,, 두 사전학습 방식이 각기 다른 부분, spatial 측면과 content 측면에서 모델의 표현 능력을 보완해주는 것으로 보입니다.
Ablating Architectural Designs
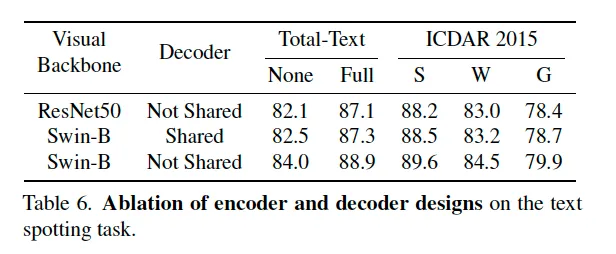
다음으로 OmniParser의 visual backbone 부분과 decoder 구성 방식에 대한 ablation study입니다. 특히 여기서 보고자 한 건 OmniParser에 있는 3개의 decoder가 구조상 다 같기 때문에 가중치를 공유하는 것이 가능한지인데요. 실험 결과 세 디코더가 모두 같은 파라미터를 공유하도록 한 경우 오히려 성능이 약 1% 정도 하락하는 경향을 보입니다. 이는 세 decoder가 출력하는 각각의 task들이 좀 유사할 수는 있지만 학습 관점에서는 분리하는 것이 좋다는 점을 시사합니다.
Qualitative Results

마지막으로 정성적인 결과로 마무리하겠습니다. 1, 2열에는 spotting결과, 3열에는 KIE 결과, 4열에는 table recognition 결과입니다.
안녕하세요, 좋은 리뷰 감사합니다.
VsTP에 table recognition task가 포함이 되어 있는데 실제로 이 task는 어디에 적용이 되는건가요? 입력으로는 테이블 이미지가 들어가게 되면 그 안에 있는 모든 셀 내용을 추출해야 하는 것인지 혹은 특정적으로 추출해야 하는 셀이 따로 지정이 되는 것인지 헷갈려 질문 드립니다.
감사합니다.
안녕하세요. 댓글 감사합니다.
table recognition task는 입력으로 table image가 들어가게 되구요, 여기에 대해 cell 내용만을 추출하는게 아니라, table 전체 구조를 추출해내는 것이 목표입니다.
다시 말해, 모든 cell 내용을 추출함과 동시에 각 cell이 어디 행, 열에 속하는지, 어떤 cell이 병합되어 있는지 등등을 파악해 json output을 뱉어내게 됩니다.
안녕하세요 정윤서 연구원님 좋은 리뷰 감사합니다.
VsTP가 OCR에서 더 넘어가 text들을 구조화된 정보로 바꾸는 task라고 설명해주시면서 3개의 task들을 소개해주셨는데, Text Spotting, Key information extraction, Table Recognition task는 기존에 존재하던 task들이고 VsTP가 이것들을 엮은 건가요? 아니면 VsTP가 3가지 task를 제안한건가요? 그리고 어려운 task라서 일반화하기가 어려울 것이라 생각했는데 scene text 데이터만을 사용해 사전학습을 했는데도 다른 도메인에 일반화가 가능한 이유가 궁금합니다.
감사합니다.
안녕하세요. 댓글 감사합니다.
본 논문에서 기존에 존재하던 spotting, key information extraction, table recognition task를 엮어 한번에 수행하는 VsTP라는 task를 새로 제안한 것입니다.
또, scene text data만을 사용해 사전학습 했는데도 다른 도메인에 일반화 가능한 이유는,, 모델이 visual 정보랑 text 정보, location 정보를 통합적으로 학습했고, 구조를 예측함으로써 일관된 학습을 하기 때문이라고 볼 수 있습니다. 또, scene text 데이터가 오히려 document domain보다 좀 더 다양한 visual feature를 포함하고 있기 때문입니다.