안녕하세요, 64번째 x-review 입니다. CVPR 2024년도에 게재된 Monocular depth estimation 논문 입니다.
그럼 바로 리뷰 시작하겠습니다 !

1. Introduction
보통 Monocular Depth Estimation이라고 칭하는데 본 논문에서는 Single Image Depth Estimation(SIDE)로 칭하고, 그 안에서 metric depth estimation(MDE)/relative depth estimation(RDE)로 나누어 정의하였습니다. MDE는 미터 단위의 실제 거리를 추정하고, RDE는 각 픽셀마다의 상대적인 거리를 예측하는데 초점을 맞추어서 metric 단위로 변환하기 위해 추가적으로 이미지별 affine transformation을 필요로 합니다.
그런데 MDE, RDE를 떠나서 SIDE 자체가 단일 뷰로 진행되는거기 때문에 기하학적인 고유한 3차원 정보를 이미지가 가지고 있을 수 없습니다. 그래서 데이터 기반의 학습 방법론들은 SIDE의 성능을 끌어올리지만 반면 사전학습 모델에 의존도를 높이게 됩니다. 즉 학습 때 보지 않았던 데이터에 대해서는 일반화 성능이 떨어지게 되죠. 이러한 현상은 특히나 학습 데이터에서의 metric depth 범위가 제한되어 있는 MDE에서 더 두드러지게 나타났다고 합니다. 최근에는 많은 분들이 아시다시피, Fondation Model(FM)의 등장으로 SIDE에서도 일반화 및 zero shot 방식이 많이 발전했는데요, 저자는 특히나 텍스트를 같이 활용하는 연구들에 집중했다고 합니다. 크게 두 가지 방법론을 이야기하는데요, 먼저 텍스트-이미지 diffusion 모델을 사용한 VPD가 있습니다. 단 NYU Depth 데이터셋 같은 경우에는 텍스트 description이 별도로 존재하지 않기 때문에 “A photo of a {scene name}”과 같은 단순한 기본 문장을 scene 레벨에서 만들어 사용한 연구 입니다. 두번째는 TADP라고 해서, VPD 다음으로 나온 연구로, 앞서 사용한 기본 문장 대신 BLIP-2를 통해 이미지 캡션을 생성하여 사용하는 방법론 입니다. 이 캡션을 이제 CLIP 모델의 입력으로 넣고, 나오는 임베딩 결과를 diffusion 모델의 condition으로 넣어서 사용하였다고 합니다. 이 과정에서 diffusion 모델이 조건으로 들어오는 캡션을 통해 scene에 대해서 더 context 정보를 풍부하게 이해할 수 있도록 하는 것이죠.
이러한 선행 연구들에 대해 저자는 VLM을 사용해서 depth estimation에 의미론적인 정보를 제공한 것은 맞으나, 그러한 의미론적 정보를 주는 방식이 pseudo caption을 쓰는 것이 최선일까?라는 질문을 던집니다. 여기서 pseudo caption은 앞선 “A photo of a {scene name}”이나 BLIP-2로 생성한 이미지 캡션을 의미합니다. 저자들이 보기에 이렇게 생성한 텍스트 description은 주로 눈에 띄는 큰 물체나 장면 전체를 설명하기 때문에, scene 속 디테일한 물체들까지 잘 내포하지 못하는 경우가 많습니다. 저자들은 이미지 분류용 모델, 즉 ViT와 같은 모델에서 나오는 임베딩이 앞선 연구들에서 생성하는 텍스트 임베딩보다 더 좋다고 주장을 하고 있습니다. 이러한 모델이 scene 안의 구체적인 물체까지 모두 포함한 표현력을 가지고 있기 때문에 pseudo caption + CLIP 임베딩이었던 이전 연구 흐름 대신에 사전학습된 ViT 임베딩을 diffusion 모델에 조건으로 주는 것이 더 효과적일 것이라고 가정합니다.
따라서 ViT에서 추출한 임베딩을 활용한 Comprehensive Image Detail Embedder(CIDE) 모듈을 설계하였다고 합니다. 이 CIDE 모듈에서 만든 임베딩으로 diffusion 모델의 condition으로 사용하여 depth를 추정할 수 있도록 하였습니다.
2. Proposed Methodology
2.1. Our Architecture
Image Encoder and Latent Diffusion
이미지 레벨에서의 기존 diffusion 모델은 노이즈를 추가하고 제거하는 과정을 크게는 수천번 반복하게 되는데요, 이는 매우 느린 학습 속도와 수렴이 느리다는 한계가 있습니다. 그래서 여타 depth task에서 그러하듯이, stable diffusion 방식을 사용하여 latent space에서 depth 예측을 수행합니다. 즉, 이미지 공간에서 직접 diffusion 과정을 거치는게 아니라 먼저 이미지를 latent space로 압축하고 거기서 diffusion을 수행하는 것 입니다. 결국 입력 이미지가 들어오면 인코더를 통해 latent 공간으로 변환하고 diffusion 과정을 거친 다음에 다시 디코더를 통과하여 depth map을 예측한 다음에 최종적으로 다시 이미지 레벨로 변환하여 저희가 아는 depth map을 얻을 수 있는 것이죠.
Exploiting Semantic Context with Conditional Diffusion
여기서 depth 추정은 조건부 확률로 모델링을 하는데, 입력 이미지 x로부터 출력 depth y를 예측하며 이를 \mathbb{P}(y|x)로 표현합니다. 그런데 diffusion 모델에서는 중간에 latent 변수 z_0로 depth를 예측하고 그걸 통해서 depth y를 얻는 것이기 때문에 모델은 식(5)를 따릅니다.
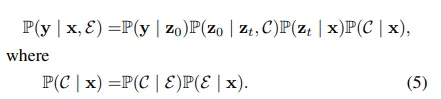
하나하나 좀 보면, 우선 P(y|z_0)는 latent 변수 z_0로부터 최종 depth y를 예측하며, 이는 depth regressor 모듈을 사용합니다.
P(z_0|z_t, C)는 노이즈가 섞인 latent z_t에서 z_0를 복원하는 과정을 의미합니다. 이때 조건 C, 즉 ViT에서 얻은 semantic 임베딩을 이용하여 조건부 diffusion으로 구현하는 것입니다. P(z_t|x)는 입력 이미지 x로부터 노이즈가 존재하는 latent z_t를 생성하는데, 이는 VAE 인코더를 사용합니다. 마지막으로 P(C|x)는 입력 이미지 x로부터 조건 임베딩 C를 여기서 생성합니다. 조건 임베딩 C를 생성할 때 사용하는게 본 논문에서 제안하는 CIDE 모듈이라고 이해해주시면 됩니다.
식(5) 아래 부분을 보시면 P(C|x)를 또 자세하게 나누어 설명하였죠. P(E|x)는 입력 이미지가 ViT를 통과하여 임베딩 E를 추출하는 과정을 의미합니다. P(C|E)는 ViT 임베딩 E로부터 MLP, learnable 임베딩 등을 통해 최종적인 조건부로 사용할 벡터 C를 생성할 수 있습니다. 이렇게 생성한 C를 앞선 전체 과정에서 말씀드린 것처럼 diffusion에 조건부로 활용하게 됩니다.
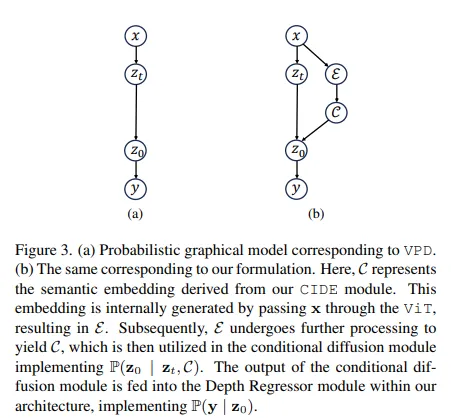
Fig.3으로 좀 더 비교해서 보면, (a)가 기존 방법론이었던 VPD를 도식화한 그림 입니다. x가 입력 이미지, z_t는 중간 타임 스텝에서의 노이즈가 존재하는 latent, z_0는 denoising한 최종 결과, 마지막으로 y가 최종 depth map을 의미하죠. 화살표가 진행 방향으로, 정말 기본 diffusion의 과정을 그대로 사용한 것이죠. 반면 (b)는 본 논문이 제안하는 방법에 대해 그래프로 설명한 것으로, E는 ViT로부터 얻는 임베딩, C는 CIDE 모듈에서 생성하는 최종 조건부 임베딩을 의미합니다. 화살표 방향을 보면, 입력 이미지와 조건부 임베딩을 같이 사용해서 최종 denoising 결과인 z_0을 예측한다는 것을 확인할 수 있습니다.
Comprehensive Image Detail Embedding(CIDE) Module
이제 본 논문에서 가장 중요한 CIDE 모듈에 대한 부분 입니다.
CIDE 모듈이 필요한 이유는 기존 방법들에서 사용하는 pseudo caption은 두드러지는, 큰 객체와 특징에만 초점을 맞추어 작은 물체나 scene의 디테일한 부분을 놓칠 가능성이 크기 때문이라고 합니다. ViT와 같이 large 이미지 분류 모델에서 나오는 임베딩을 활용해서 더 풍부한 scene과 작은 물체 정보까지 담을 수 있을 것이라는 가정하에 CIDE 모듈을 설계하였다고 보시면 됩니다.
자세히 보면, 입력 이미지 x를 사전학습 ViT의 입력으로 넣어서 예측 score로 구성된 1000차원의 logit 벡터를 출력으로 하게 됩니다. 1000차원의 logit 벡터는 사실 depth 추정에 있어서 너무 크고 계산에 비효율적이기 때문에 핵심적인 정보만 압축하기 위해 2개의 FC layer를 간단히 통과하였다고 합니다. 그래서 최종적으로 100차원의 벡터만으로 압축을 하는 것이죠. 그러고 나면 모델 내부에 100개의 learnable 임베딩 벡터가 이미 준비되어 있고, MLP에서 나온 100차원의 벡터를 linear combination에 사용을 하게 됩니다. 다시 말하면, MLP 출력의 각 값이 100개의 learnable 임베딩에 가중치를 부여하는 방식으로 weighted sum을 통해 임베딩을 생성하게 됩니다. 그 다음에, 이렇게 만든 임베딩을 linear transformation에 통과시키면 768차원의 semantic context vector로 확장이 가능합니다. 이 768차원의 semantic 임베딩이 결국 최종 조건부 임베딩 C가 되어 diffusion 모델의 조건부 입력으로 사용할 수 있는 것이죠.
여러 MLP를 통과하고 linear transformation 등을 통과한다고 자세하게 설명하였지만 가장 중요한 것은 이전에 사용하던 CLIP 기반의 임베딩이 아니라 ViT와 같은 모델을 사용하여 임베딩 벡터를 만든 다음, 이를 diffusion의 조건으로 사용한 차이점이 있다는 것이라고 이해해주시면 좋을 것 같습니다.
3. Experiments and Results
실험에는 NYU Depth v2와 KITTI 데이터셋을 사용하였다고 합니다.
3.1. Comparison on Benchmark Datasets
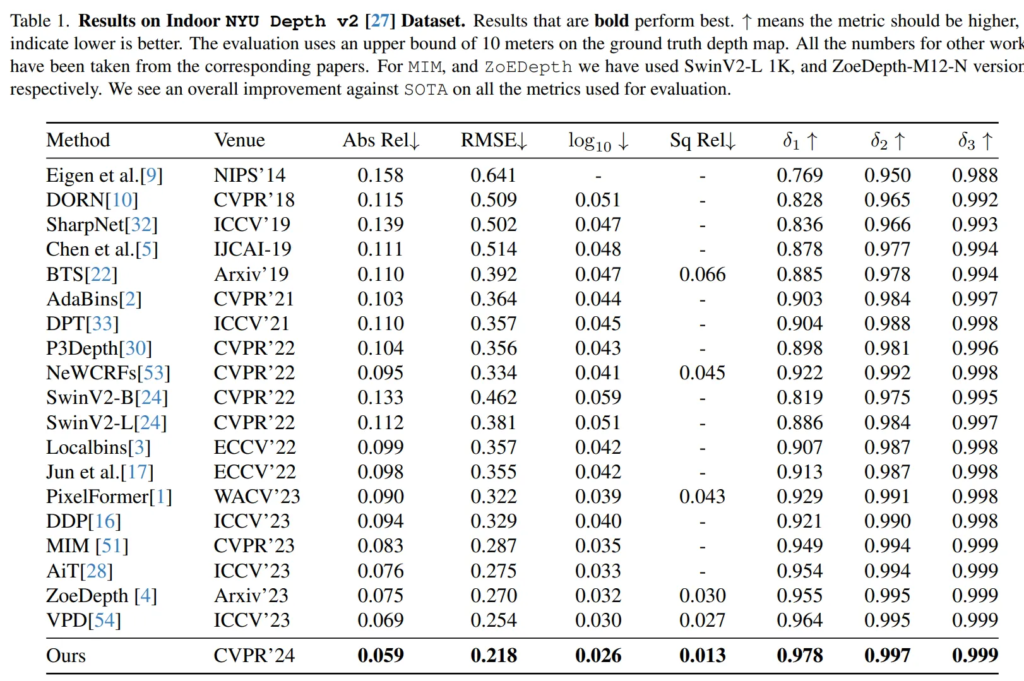

생각보다 본 논문에서는 메인 데이터셋들에 대한 실험은 간단하게 분석하였는데요, Tab.1은 먼저 indoor NYU Depth v2 데이터셋에 대한 실험 결과 입니다. 결과적으로 SOTA를 달성하였고, 특히 이전 SOTA 데이터셋이며 논문에서 계속 비교하며 언급했던 VPD 대비 RMSE에서 거의 14%라는 큰 차이를 보이며 성능을 개선한 것을 확인할 수 있습니다. Tab.2는 outdoor KITTI 데이터셋에 대한 실험인데 마찬가지로 RMSE를 제외한 모든 평가지표에서 SOTA를 달성한 것을 볼 수 있습니다. 이로써 indoor와 outdoor scene 모두에서 사용가능한 방법론임을 보이고 있습니다.
3.2. Generalization and Zero shot Transfer
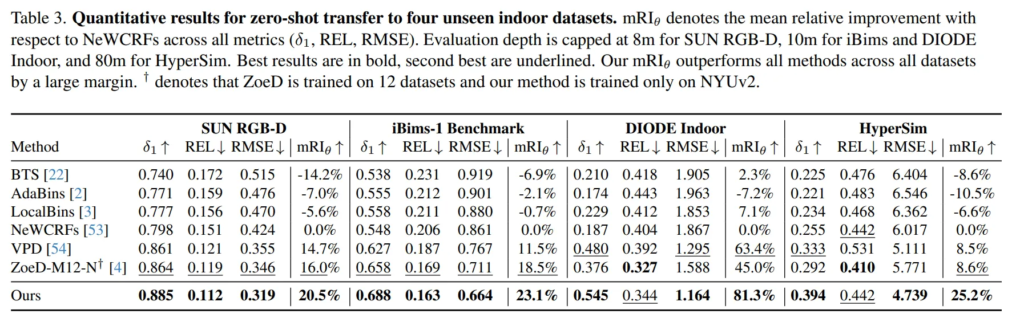
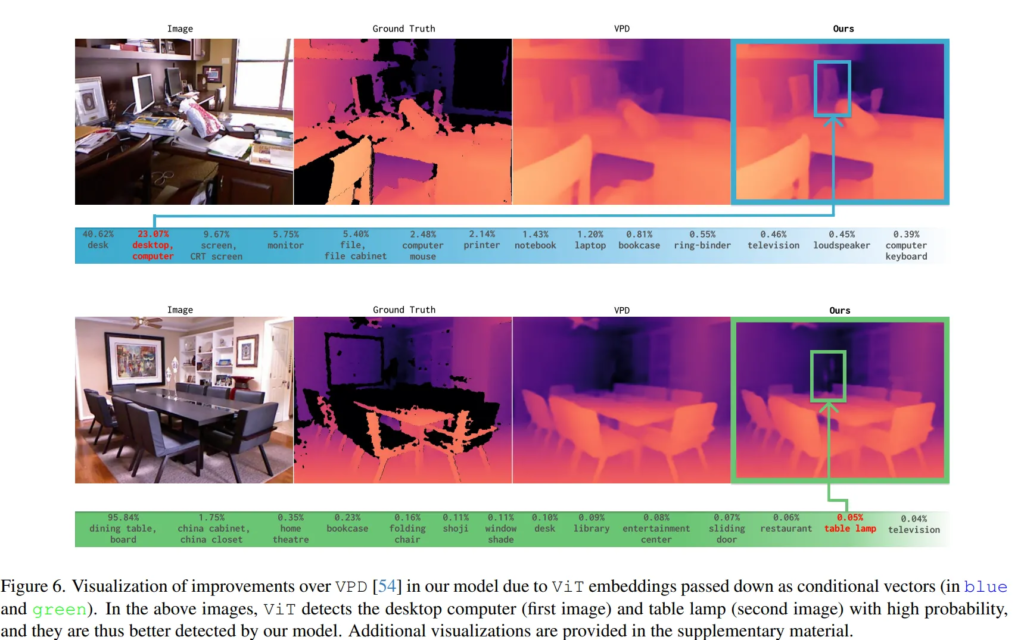
학습에 사용한 NYU Depth v2와 KITTI 데이터셋 이외에 Tab.3에 리포팅한 다른 데이터셋으로 평가하여 zero shot에 대한 성능도 같이 평가하였습니다. 비교 모델은 zero shot 방식의 ZoeDepth이며, 비교했을 때 학습에서 본 적 없는 scene에 대해서도 거의 모든 데이터셋에서 비교 모델 대비 좋은 성능을 보이고 있습니다. 정성적으로 봐도 강조한 부분을 보면 전체 scene에서 되게 디테일한 부분들, 뒷쪽의 의자나 작은 램프 등의 depth도 표현하고 있는 것을 확인할 수 있습니다. 이를 통해 zero shot 세팅에서도 일반화된 성능을 보일 수 있다는 것을 강조하고 있습니다.
3.3. Ablation Study
Effect of Contextual Information
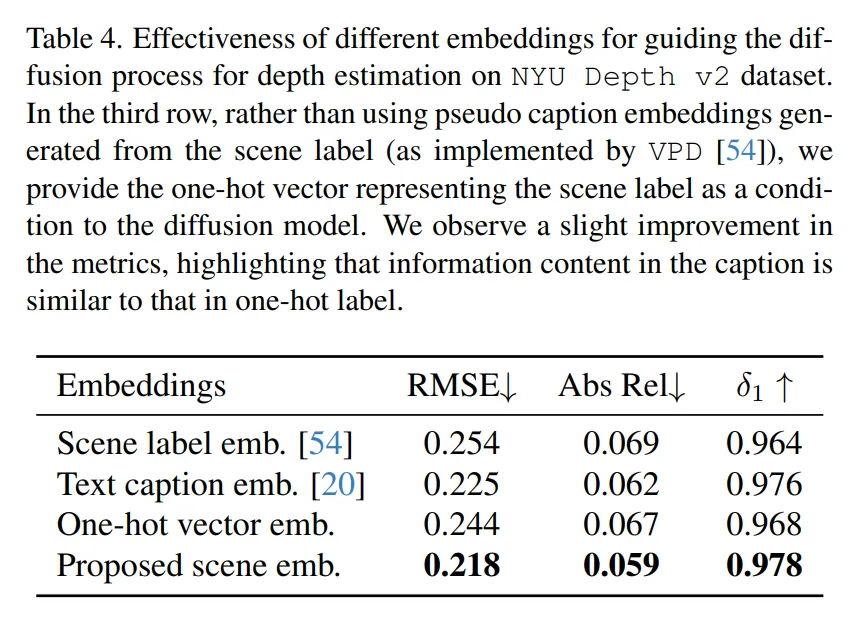
본 논문에서 이루고자 한 것이 현재의 VPD와 같은 방법론에서 임베딩 방식 대신에 ViT와 같은 모델의 확률 벡터를 이용했을 때의 효과에 대해 ablation study를 리포팅하였습니다. VPD와의 방식과 비교하기 위해서 본 논문에서도 동일하게 scene 레벨의 정보를 활용하였을 때를 구현하기 위해 장면 라벨을 사용해서 condition 임베딩을 구성하였다고 합니다. Tab.4를 보면 pseudo caption의 정보가 one hot 벡터와 유사하다는 결과를 보이는 VPD 방식 대비 논문에서 제안한 방식이 조금 더 개선된 성능을 보이고 있습니다. 이를 통해 depth를 예측하는데 있어서 scene 레벨의 정보만 제공하는 것보다 디테일한 정보들까지 포함할 수 있는 ViT를 활용하는 것이 효과적이라는 것을 보여주고 있습니다.
방법론도 diffusion 기본 수식들 설명을 제외하고는 굉장히 짧은 편이고, 실험도 각 실험 테이블마다 분석보다는 결과 위주의 내용을 담았던 논문이었습니다. 기존 임베딩 방식보다 diffusion에 condition으로 ViT에서의 임베딩 정보를 활용한 연구는 처음 읽어봐서 신선했던 것 같고, 대신 실험의 분석에 있어서는 조금 아쉬웠던 논문이었던 것 같습니다.
안녕하세요, 좋은 리뷰 감사합니다.
본 논문에서 scene 전체의 구조가 아니라 디테일한 영역에 대한 표현력을 확보하기 위해 ViT의 임베딩을 조건으로 사용하였는데, 이게 depth map을 제대로 예측할 수 있도록 어떻게 유도할 수 있는 것인지 이해가 되지 않아 질문 드립니다.. 이미지와 이미지에 대한 ViT를 타고나온 임베딩의 결과를 같이 diffusion 과정을 거치도록 하는데, depth map을 직접적으로 조건으로 넣은 이전 연구들보다 성능이 더 개선되고 정확하게 depth map을 복원할 수 있는 이유에 대해 조금 더 설명해주실 수 있나요!?
감사합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
직접적으로 depth map을 조건으로 넣는 것도 물론 가능하며 이전의 연구들이 그러한 방식을 많이 사용해왔지만 본 논문에서는 직접적으로 depth map을 넣는 것보다 vit의 출력 벡터가 scene의 전반적으로 존재하는 여러 물체와 그 구조까지 잘 담고 있다고 분석했기 때문에 이를 실험적으로 확인하였고 실제로 더 잘 작동하였다고 말씀드릴 수 있을 것 같습니다. 직관적으로 이해하였을 때는 depth map을 예측하니 depth map을 condition으로 넣어야만 하는거 아닌가라고 생각할 수도 있지만 복잡한 배경이나 구조적인 깊이 정보를 잘 이해할 수 있는 다른 정보를 넣더라도 depth를 복원하는데 도움이 될 것이라고 생각한 것이고 실제로 잘 작동함을 보인 논문이라고 생각합니다.
감사합니다.