제가 이번에 리뷰할 논문은 최근 아카이브에 공개된 affordance segmentation 관련 논문입니다.
Abstract
실세계로의 응용을 위해서는 unseen object 및 affordance 기능에 대한 일반화가 중요하지만, 최근 연구는 아직 이러한 일반화 능력이 부족합니다. 해당 논문은 SAM의 일반화 성능을 affordance grounding 분야로 확장하기 위한 AffordanceSAM을 제안합니다. 이를 위해 segmentation에서 강인하게 작동하는 SAM을 기능적으로 대응되는 영역으로 전이하기 위한 affordance-adaption 모듈을 제안하며, affordance에 대응되는 물체와 action에 대한 대략적인 영역을 찾은 뒤 이후 세밀한 affordance heatmap을 예측하도록 하는 coarse-to-fine 학습 방식을 제안합니다. 또한, 정성적/정량적 실험을 통해 일반화 성능을 입증하였으며, AGD20K뿐만 아니라 novel object와 affordance에 대해서도 좋은 성능을 달성하였다고 합니다.
Introduction
Affordance Grounidng은 로봇이 어떠한 행동을 수행할 때, 이 행동을 수행하기 위해 대응되는 물체 영역을 찾는 연구로, 시각 인지와 로봇의 실제 조작을 연결하기 위해 중요한 역할을 합니다. 이러한 Affordance Grounding은 최근 크게 2가지 흐름으로 연구가 이루어지고 있습니다. 먼저, weakly supervised affordance grounding은 사전에 정의된 affordance class를 인식하는 classification 방식으로 접근을 하며, class에 대한 CAM을 이용하여 affordance에 대한 heatmap을 구합니다. 이한 방식은 다른 관점의 데이터(해당 연구에서는 사람이 물체와 상호작용하는 이미지를 exocentric, 객체만 주어진 이미지를 egocentric이라 표현합니다. 따라서 학습 시 exocentric 이미지로 학습한 뒤 egocentric에 대해 예측하기 때문에 다른 관점의 데이터를 이용한다고 표현합니다.)를 이용하여 affordance와 관련된 지식을 학습하게 됩니다. 그러나 이러한 방식은 사전에 정의되지 않은 새로운 affordance로는 확장이 어렵다는 한계가 있습니다. 또 다른 연구는 affordance map을 모델이 직접 예측하도록 하며, affordance에 대한 지식을 직접적으로 제공하기 위한 수동 라벨을 이용하는 방식으로, 이 또한 여전히 affordance에 대한 일반화에 어려움이 있습니다.
저자들은 이러한 기존 연구를 통해 “이러한 제한된 데이터 조건에서 일반화 능력을 갖춘 모델을 어떻게 얻을 수 있을 지?”에 대하여 질문을 던지고, 이를 분해하고 순차적으로 해결하고자 합니다.
1. Can we incorporate a suitable and generalized vision prior?
최근 비전 분야에서는 대규모 사전학습된 모델이 발전함에 따라, 이를 다양한 downstream task에 활용하려는 연구가 활발히 진행되고 있습니다. 저자들 역시 이러한 사전학습된 모델의 지식을 affordance grounding으로 전이하는 것이 효과적이라 판단하였으며, 특히 픽셀 수준의 정밀한 localization을 위해 SAM의 적용 가능성을 탐색하였습니다. SAM은 우수한 일반화 성능뿐만 아니라 segmentation에서도 뛰어난 성능을 보여주었으며, 모델 구조와 decoder의 output 형태가 affordance grounding과 유사하다는 점에서 SAM을 활용하고자 하였습니다. (참고로 SAM을 affordance grounding에 적용한 것이 이번 연구가 최초는 아닙니다.)
2. How can we effectively utilize and transfer SAM’s comprehensive knowledge into affordance grounding task?
Affordance grounding에 SAM의 일반화된 지식을 효과적으로 전이하기 위해, task 측면에서의 차이를 검토합니다. 아래의 Figure 2는 이미지와 각 query가 주어졌을 때, 두 작업의 예측 대상을 보여줍니다. segmentation은 물체에 대한 예측이 이루어지므로 시각적으로 구분된 형태를 인식합니다. 그러나 affordance는 주어진 text query에 대하여 기능적으로 대응되는 영역에 대한 heatmap을 예측합니다.

저자들은 앞서 언급한 두 가지 요소를 고려하여, 모델의 구조 뿐만 아니라 학습하는 방식도 포함하는 단순하면서도 효과적인 AffordanceSAM 프레임워크를 제안합니다. 먼저, 저자들은 텍스트와 이미지 간의 의미적 연관성을 학습하기 위해 affordance-adaption 모듈을 설계하였습니다. 해당 모듈은 learnable queries를 이용하여 text와 이미지 feature 사이의 관계를 학습하고, 해당 queries는 Decoder에서 SAM의 예측 마스크를 조정하므로써 affordance grounding 결과를 생성하도록 합니다. 저자들은 이러한 가벼운 모듈을 통해 SAM의 일반화된 지식을 효과적으로 affordance 영역으로 전이할 수 있다고 가정하며, coare-to-fine 학습 방식을 제안합니다. 해당 학습 방식은 다음과 같이 3 단계로 이루어집니다. (1) 기존 데이터들을 모아 object-affordance 쌍으로 구성하고, 대략적인 마스크가 주어진 상태에서 object와 동사(verb) 사이의 관계를 학습합니다. (2) 이후, weakly supervised 모델을 이용하여 마스크 라벨이 없는 데이터에 대한 pseudo label을 생성하여 네트워크를 학습합니다. (3) 마지막으로, 사람이 정교하게 라벨링한 데이터로 모델을 fine-tuning합니다.
해당 논문의 contributiond르 정리하면
- Affordance grounding을 위해 SAM을 통합하여 모델이 학습 데이터를 넘어 효과적으로 일반화가 이루어질 수 있도록 AffordanceSAM 프레임워크를 제안함
- affordance-adaption 모듈과 coare-to-fine 학습 방식을 제안하여 SAM의 일반화된 지식을 효과적으로 affordance grounding으로 전이함
- 종합적인 실험을 통해 AGD20K 벤치마크에서 SOTA를 달성하였으며, 새로운 affordance와 object로도 일반화 가능함을 보임
Approach
0. Preliminary
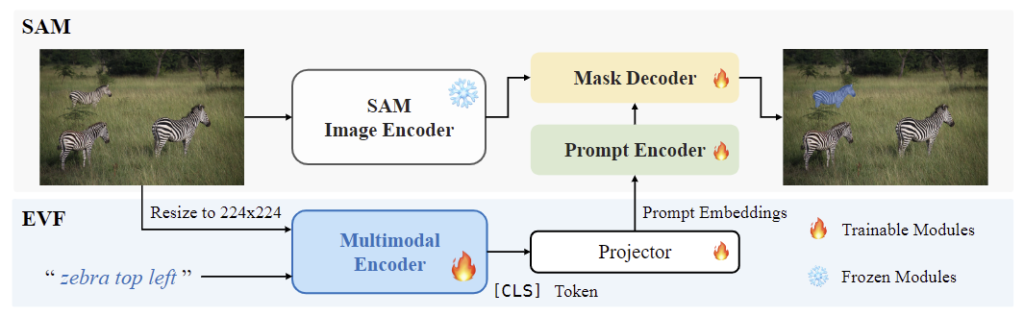
[ EVF-SAM ]
우선 기존의 SAM은 언어에 대한 이해 능력이 부족하므로, text에 대응되는 객체 영역을 분할하기 위해 SAM을 확장한 방식 중 SOTA인 EVF-SAM을 베이스라인으로 사용합니다. 해당 모델은 크게 4가지 요소로 구성됩니다.: 멀티모달 인코더 \mathcal{E}_M, 프롬프트 인코더 \mathcal{E}_P, SAM의 이미지 인코더 \mathcal{E}_I, SAM의 마스크 디코더 \mathcal{D}. 입력된 이미지는 멀티모달 인코더 \mathcal{E}_M와 SAM의 이미지 인코더 \mathcal{E}_I로 각각 인코딩 되어 \mathbf{I}_m \in \mathbb{R}^{B⨉N_m⨉D_m}토큰과 \mathbf{I}_s \in \mathbb{R}^{B⨉N_s⨉D_s}토큰을 생성합니다.(여기서 B는 batch size, N은 시퀀스의 길이, D는 차원을 의미합니다.) text는 tokenizer를 통해 text token \mathbf{T} \in \mathbb{R}^{B⨉N_t⨉D_m}을 생성한 뒤, \mathbf{I}_m 토큰과 학습 가능한 [CLS] 토큰 \in \mathbb{R}^{B⨉1⨉D_m}을 함께 결합하여 멀티모달 인코더 \mathcal{E}_M로 입력되어 feature \mathbf{F}_m \in \mathbb{R}^{B⨉(1+N_m+N_t)⨉D_m}을 생성합니다. 여기서 [CLS] token에 해당하는 feature \mathbf{F}_c를 분리하여 SAM 인코더로 추출한 feature와 함께 마스크 디코더 \mathcal{D}에 입력하여 이진 마스크 \mathbf{M}_b를 생성합니다.
1. Affordance-Adaption Module
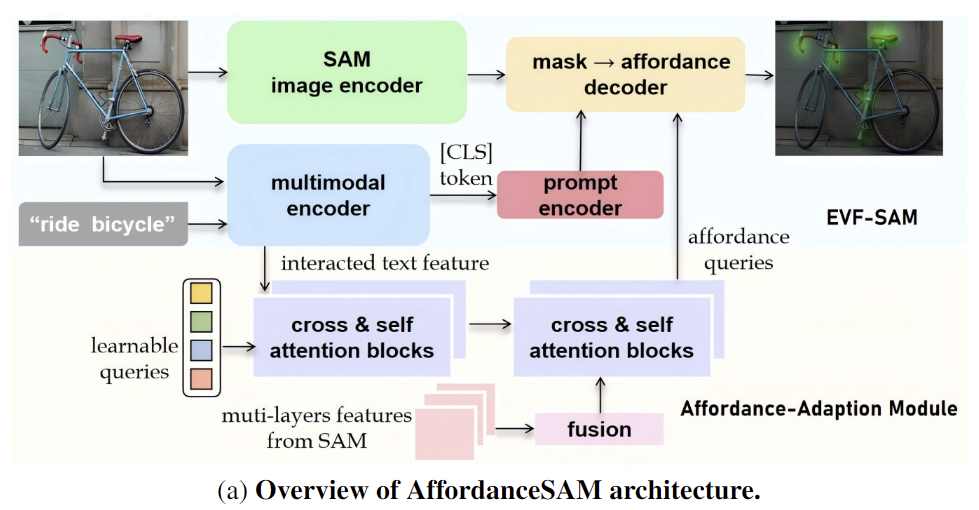
먼저 저자들은 segmentation과 affordance grounding task의 결과물이 차이가 있으므로(Figure 2), 효율적으로 SAM을 affordance grounding으로 전이하기 위해 Affordance-Adaption 모듈을 제안합니다. 먼저 BLIP-2나 DETR과 유사하게 learnable queries를 도입합니다. 이를 affordance queries \mathbf{Q}_a \in \mathbb{R}^{N_s⨉D_m}라 하고, 이 쿼리는 배치 차원에서 반복되고, 멀티모달 인코더에서 이미지와 상호작용하는 text feature와 함께 cross & self attention을 수행합니다. 저자들은 이를 통해 의미론적으로 affordance와 연관된 정보를 추출하는 것을 목표로 합니다. 또한, affordance는 하나의 객체에 대해서 다양한 위치에 대응될 수 있으며 여러 수준의 세분성을 이용하는 것이 유리하다 판단하여 SAM의 multi-layer visual features를 추가하여 두 번째 cross & self attention을 수행합니다. 이때 SAM의 multi-layers features \mathbf{G}_i는 학습 가능한 파라미터인 \alpha_i를 이용하여 아래와 같이 결합이 됩니다.
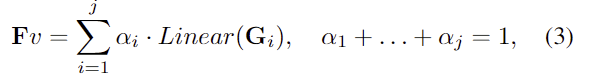
최종 affordance quries \mathbf{Q}_{af}는 2개의 transposed conv 레이어를 이용하여 차원을 조절한 뒤, EVF-SAM의 마스크 디코더 \mathcal{D}에 추가로 입력되어 affordance에 대한 heatmap으로 조정된 affordance map \mathbf{M}_a를 생성합니다.
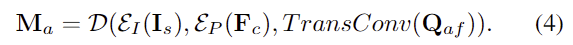
2. Coarse-to-Fine Training Recipe
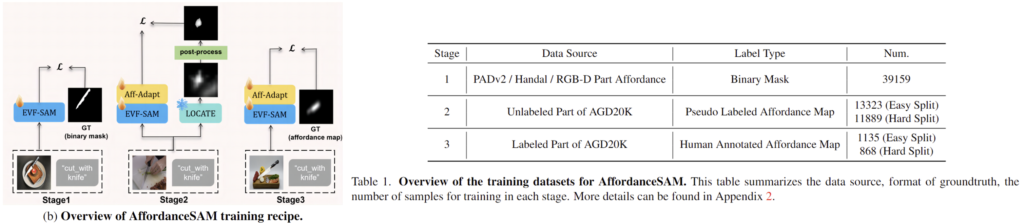
SAM의 일반화 능력을 활용하여 affordance grounding으로 확장하기 위해 해당 논문에서는 coares-to-fine 학습 방식을 제안합니다. 위의 그림을 통해 각 단계에 대한 개요를 확인할 수 있으며 모든 단계에서 "<affordance function> <object_name>" 템플릿의 텍스트 프롬프트를 사용합니다. 또한, 각 단계에서 사용된 데이터는 옆의 Table 1을 통해 확인하실 수 있습니다. 이제 각 단계에 대해 살펴보겠습니다.
Stage 1) affordance 관련 object와 verb에 대하여 EVF-SAM finetuning
먼저 저자들은 기존 멀티모달 모델들이 affordance와 관련된 물체나 동사(verb)에 대하여 거의 학습이 되지 않았다는 점을 확인하였고, 따라서 affordance grounding으로 확장을 위해 먼저 affordance object와 affordance에 대한 동사를 이해하도록 EVF-SAM의 output을 변경하지 않고(=affordance-adaption 모듈을 추가하지 않고) 멀티모달 인코더와 프롬프트 인코더를 미세조정합니다. 이를 위해, affordance에 대한 mask가 주어진 PADv2와 Handal, RGB-D Part Affordance 데이터 셋을 이용하며, loss는 Dice Loss와 Binary Cross-Entropy loss의 가중합으로 정의됩니다.

Stage 2) affordance-adption 모듈을 추가하여 대략적으로 학습
affordance에 대한 픽셀 수준의 데이터를 수집하는 것에는 한계가 있으며, 수백개의 labeled 데이터를 이용하여 SAM의 output mask를 학습하기에는 충분하지 않으므로 저자들은 affordance에 대한 데이터 셋인 AGD20K 데이터 중 unlabeled 데이터에 대해 SOTA weakly supervised 모델인 LOCATE(모델에 대한 정보는 이전 X-Review를 참고해주세요)를 적용하여 pseudo label을 생성합니다. 이때 LOCATE의 output을 정제하기 위해 아래의 알고리즘과 같이 후처리를 적용하여 pseudo label을 정제합니다. 단일 threshold가 아닌 계층적인 세 단계의 threshold를 사용하여, 각 픽셀의 신뢰도에 따라 점진적으로 부드럽게 값을 조정한 후, 최종적으로 불필요한 정보는 제거하는 과정입니다. 해당 과정에서는 학습 시 SAM의 이미지 인코더만 freeze하고 학습을 수행하며, binary focal loss \mathcal{L}_{focal}을 이용합니다. 이때, negative 샘플이 많으므로 negative는 0.1 positive는 0.9로 가중치를 조절하여 학습합니다.

Step 3) affordance에 대하여 정밀하게 학습
마지막으로 사람이 정교하게 라벨링한 AGD20K 데이터를 이용하여 모델을 학습합니다. 해당 과정은 stage 2와 동일한 loss를 사용하며 마찬가지로 SAM의 이미지 인코더만 freeze합니다.
Experiments
저자들은 4개의 A100(80GB)를 이용하여 학습을 수행하였으며, AGD20K 데이터 셋에서 2가지 split(easy/hard)에 대한 평가를 수행합니다. easy split은 AGD20K의 원본 split으로, train과 test 셋에서 object 카테고리 유사성이 높습니다. hard set은 train과 test의 object 카테고리가 겹치지 않도록 하며, 이와 관련하여 더 자세한 정보는 이전 리뷰를 참고해주세요. 평가지표는 평가지표는 기존 Affordance Grounding에서 사용하던 Kullback-Leibler Divergence (KLD, 낮을수록 좋음), Similarity (SIM, 높을수록 좋음), Normalized Scanpath Saliency (NSS, 높을수록 좋음)를 사용합니다. (해당 지표들은 GT와 예측된 분포 사이가 유사한지를 측정하는 것으로, 이에 대한 자세한 설명은 제가 이전에 작성한 X-Review를 참고해주세요.) 평가를 위해 weakly supervised 방식으로는 Cross-View-AG와 LOCATE를 비교하였으며, affordance map을 직접 예측하는 방식은 AffordanceLLM과 OOAL을 비교하였습니다.
Results on AGD20K
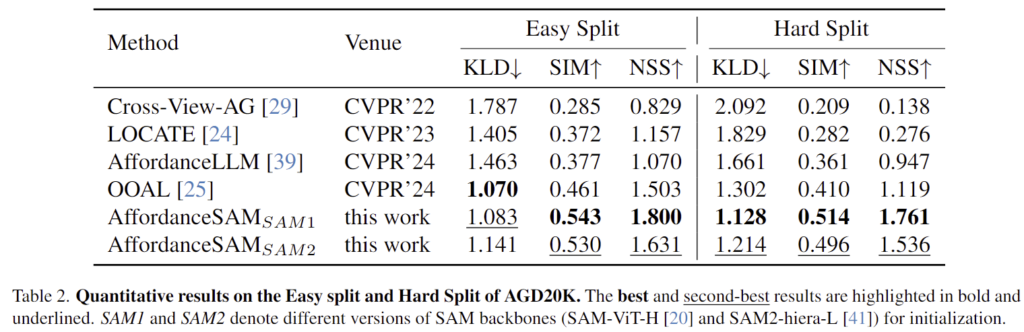
Table 2는 AGD20K에서 easy 및 hard split에 대한 정량적 결과로, SAM-ViT-H 모델인 SAM1에서 특히 좋은 성능을 보였으며, 전체적으로 성능 개선이 이루어졌음을 확인할 수 있습니다. 특히, hard split에서 성능 개선이 두드러진다는 점을 어필합니다. 저자들은 이를 통해 SAM의 일반화 성능을 효과적으로 affordance grounding으로 전이하였으며, 더 어려운 케이스로도 잘 적용이 됨을 보였습니다.

위의 Figure 4는 이에 대한 정성적 실험 결과로, “cup”이라는 객체를 처리할 때 AffordanceSAM은 다른 방식보다도 affordance에 대한 이해 능력이 뛰어나며, “hold”나 “drink”와 같이 다양한 affordance가 주어졌을 때도 적절한 영역을 예측하고 있음을 보였습니다. 또한, 픽셀 수준의 마스크를 생성하는 SAM을 이용하여 일부는 GT보다 더 정확한 affordance map을 생성한다는 점을 어필합니다. (참고로 AGD20K의 GT mask는 affordance에 대한 특정 point 들에 가우시안 필터링을 적용하는 방식이라 윤곽이 명확하지 않습니다.)
Results on Internet Images

마지막으로 일반화 성능에 대한 어필을 위해 저자들은 인터넷 데이터에 대한 실험을 진행합니다. 위의 Figure 5는 이에 대한 결과로, 왼쪽 결과(파란색)는 학습에 사용한 affordance에 대한 시각화 결과이며, 오른쪽 결과(노란색)는 학습하지 않은 affordance에 대한 시각화 결과입니다. 이를 통해 저자들이 제안한 방식은 새로운 행동을 이해할 뿐만 아니라 SAM의 segmentation 능력을 활용하므로써 대응되는 영역에 더 집중할 수 있다는 것을 실험을 통해 보였습니다.
Ablation study
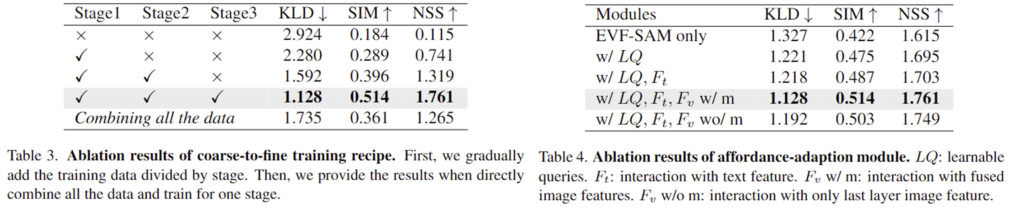
위의 Table 3과 Table 4는 해당 논문에서 제안한 coarse-to-fine training recipe와 affordance-adaption 모듈에 대한 ablation study 결과입니다. 먼저, Table 3의 1행은 베이스라인인 EVF-SAM을 그대로 사용한 결과로, affordance grounding에 대한 지식이 부족하다는 점을 확인할 수 있습니다. 이후 coarse-to-fine 학습 방식의 각 stage를 추가할 때 마다 성능이 개선되는 경향을 확인할 수 있으며, 마지막 행은 모든 데이터를 다 합쳐 한번에 학습을 진행한 경우로 서로 다른 품질의 데이터가 노이즈로 작동하여 성능이 저하될 수 있음을 보였습니다.
Table 4는 affordance-adaption 모듈에 대한 실험 결과로, 구조를 변경하지 않은 EVF-SAM에 affordance-adaption 모듈의 각 요소를 추가함에 따라 성능이 개선되는 결과를 확인할 수 있습니다. 특히, learnable qureies를 도입할 경우 성능이 크게 개선됨을 1행과 2행의 비교를 통해 확인할 수 있습니다.
안녕하세요 승현님 리뷰 감사합니다.
기존의 EVF-SAM을 affordance를 더 잘하게 데이터를 준비해서 finetuning 한 모델이라고 이해했는데요, 그렇다면 잘 못 하는 물체들이나 행동들도 존재한다고 생각하는데, 모델이 gt보다 더 깔끔한 affordance를 예측하는 경우도 있는만큼 이상하게 못 하는 케이스들도 존재하는지 궁금합니다!!
질문 감사합니다.
우선 해당 논문이 사용하는 데이터 셋인 AGD20K는 affordance에 대응되는 지점을 중심으로 가우시안을 적용하여 affordance map을 생성해둔 방식으로, 정성적 결과에서 확인하실 수 있듯 경계가 명확한 형태가 아닙니다. 따라서, 정량적 수치만으로는 정확하게 얼마나 정확한 영역을 예측하고있는지를 확인하기는 어렵습니다. 다만 정성적 결과는 체리피킹일 가능성이 있어 저도 못하는 케이스가 존재하는데 이를 드러내지 않은 것이라 생각합니다..(예시로 컵에 대한 2개 이미지와 서로 다른 affordance 결과를 보여주는데, 사실 하나의 영상에 대해 두 가지 affordance를 보여줄 수 있지 않았을 까 하는 점에서 잘 못하는 부분은 드러내지 않은 것으로 보입니다.)
안녕하세요, 좋은 리뷰 감사합니다.
학습 방식이 정확하게 이해가 안돼서 그러는데, coarse to fine 학습 방식에서 단계마다 다른 데이터가 사용되고 있는데, 이는 단계마다의 데이터셋을 사람이 모두 지정해서 별도로 들어갈 수 있도록 세팅을 하는 것인가요 ?? 만약 맞다면 궁금한 것이 지금 예시에서 모두 knife가 들어가있는 서로 다른 데이터셋의 이미지를 사용하고 있는데 하나의 데이터셋에서의 예시와 다른 데이터셋의 샘플이 매칭되지 않는 경우에는 데이터 처리를 어떻게 하게 되는지 궁금합니다.
감사합니다.
질문 감사합니다.
해당 연구는 단계마다 데이터 정의하고 학습 방식도 정의해두고 별도로 학습을 수행합니다. 두 데이터 셋에서 동일 객체에 대하여 다르게 처리할 경우 이를 조정하거하 하지 않습니다. 제가 개인적으로 생각하기에는 오히려 객체에 대한 다양한 affordance를 모델이 학습할 수 있다는 점에서 이점이 있지 않을까 합니다.