안녕하세요 류지연입니다.
오늘 리뷰할 논문은 이전에 작성했던 TESTR 모델의 근간이 되는 DETR입니다. TESTR을 읽을 때 DETR에 대해서 알고자 간단하게 블로그만을 참고했었는데요 깊게 알고자 논문을 읽고 리뷰까지 하게 되었습니다. TESTR에서 부족했던 설명을 본 리뷰로 보충하고자 합니다.
그럼 이만 글을 줄이고 바로 리뷰 진행해보겠습니다!

1. Introduction & Related Studies
객체 검출은 객체에 대한 바운딩 박스와 해당 객체가 포함되는 클래스를 예측하는 하나의 set prediction 문제라고 볼 수 있는데요. 기존 연구들이 이러한 문제를 다룰 때 제안하는 방법들은 대부분이 region proposal, anchor box, window center등을 설정하고 이어서 NMS 같이 중복 예측을 제거하는 중간과정이 필요하며 이를 위해 사람의 개입이 요구됩니다. 논문의 저자는 이러한 문제를 지적하며 저자는 이 과정을 단순화한 DEtection TRansformer를 (이하 DETR) 제안합니다. 이렇게 end-to-end하게 예측하는 방법은 다른 도메인에서는 꾸준히 시도되어 왔지만 객체 검출 분야에서는 본 연구가 처음이라고 합니다. (비슷한 시도를 한 연구도 있었지만 대부분이 새로운 prior knoledge 방법을 사용하거나 기존 베이스라인 모델보다 우세한 성능을 보이지 못했다고 합니다. 본 연구는 이런 연구들과는 달리 postprocessing이나 어떠한 다른 prior knoledge를 필요로 하지 않으면서도 베이스라인 모델의 성능보다 우세한 결과를 낸 방법입니다.)
object detection을 어떠한 prior knowledge 없이 direct하게 다뤘다는 점이 이 연구의 제일 중점이 되는 contribution이라고 할 수 있겠습니다. 저자는 인코더와 디코더 구성의 트랜스포머 구조로 모델을 설계해 detection 과정을 direct한 set prediction 문제로 전환하였고 bipartite matching(이분 매칭) loss와 각 객체에 대한 예측을 병렬적으로 디코딩하는 것으로 해결할 수 있었다고 합니다. 보통 어떤 시퀀스를 예측하기 위해 사용하던 transformer를 어떻게 object detection 태스크에 적용되었느지에 대해서는 이후 글에서 차차 설명 드리도록 하겠습니다.
2. The DETR model
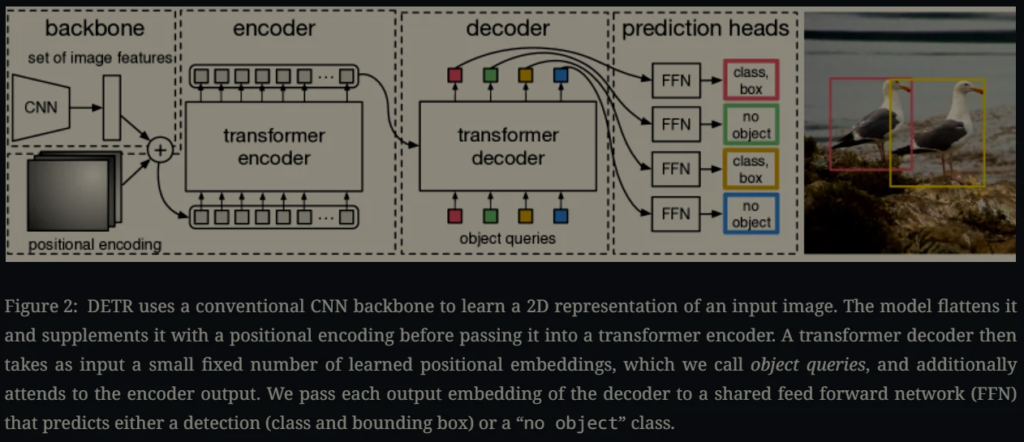
DETR의 direct한 dectection process가 구현될 수 있었던 요소로 두가지가 설명됩니다. 하나는 모델의 예측과 GT 간의 중복되지 않는 매칭을 수행하기 위한 loss 정의를 한 것이고 또 하나는 한번의 pass 만으로 예측이 수행되는 그 구조를 제안한 것이라고 할 수 있는데요 각각에 대해 자세하게 보겠습니다. 우선, 전체 모델 구조는 다음 도식도에 나타나 있습니다.
2. 1 Object detection set prediction loss
DETR은 이미지당 고정된 개수의 (N개) 예측을 수행하도록 설계되어 있습니다. 이미지에 있는 객체의 개수보다 많은 수로 N을 적절하게 설정하였다고 합니다. detection이 어려운 이유 중 하나가 모델의 예측을 GT와 적절히 매칭하고 GT간의 차이를 줄여나가도록 학습시키는 것인데요 DETR은 bipartite matching을 도입하고 이를 Hungarian algorithm으로 풀어 이를 간단하게 해결합니다.
최적의 매칭을 나타내는 수식을 다음과 같습니다.
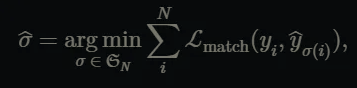
y를 GT 집합이라고 하고 \hat{y}을 N개의 모델 예측의 집합이라고 할 때 여러 매칭 중 match loss를 제일 작게하는 permutation \hat{\sigma }을 찾는 것으로 정의가 된다고 보시면 됩니다. 모델이 N개의 예측을 수행하기 때문에 GT 또한 N개의 원소로 구성된 집합인데요 이미지속 객체가 N개 보다 적다면 나머지는 no object (\o로 패딩이 됩니다. (채워집니다) 모델의 모든 예측이 일대일로 GT와 매칭이 되도록 합니다.
그리고 최적의 permutation \hat{\sigma }은 헝가리안 알고리즘의 방법으로 구해집니다. 위 수식안에 있는 matching loss에 대해서 설명드려볼게요. 우선 GT는 다음과 같이 표현될 수 있습니다.
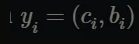
여기서 c_{i}는 객체에 대한 class label이 되고 bi는 (cx, cy, w, d) 으로 바운딩 박스의 좌표를 나타냅니다. 시그마 i로 매칭이 되었을 때 각 매치의 matching loss는 다음과 같습니다.
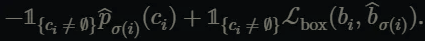
해당 매칭 방법은 이전 연구들이 propos된 영역이나 앵커 박스를 GT와 매칭하는 방법을 대신합니다.
그리고 최종적인 Hungarian loss는 다음과 같이 모든 permutation에 대해 정의됩니다.
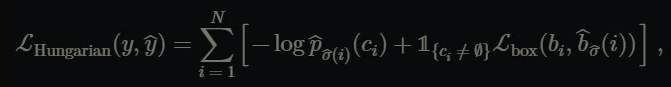
2.1.1 Bounding box loss
기존 detection에서 사용되는 box loss와 해당 연구에서 헝가리안 loss로 사용되는 box loss 정의가 조금 다른데요. 단순히 l1 loss로 박스의 좌표간의 거리를 loss로 정의했을 때 객체 크기에 따라 상대적으로 오차의 정도가 달라진다는 문제를 지적하며 l1 loss와 generalized iou loss를 선형적으로 결합해 scale invariant한 새로운 loss를 box loss로 제안합니다. 수식은 다음과 같이 정의됩니다.
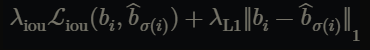
여기서 각 람다값은 하이퍼파라미터로 직접 설정해줍니다.
2.2 DETR architecture
논문에서는 여러번 제안하는 모델의 구조가 기존과 다르게 정말 간단하다는 것을 여러 차례 강조합니다. 우선 3개의 요소로 구성돼 있는데요. 1. 이미지의 특징을 추출하기 위한 CNN 백본, 2. 인코더와 디코더 구성의 트랜스포머 구조, 3. 최종적인 예측을 뱉는 FFN으로 구성돼 있습니다.
2.2.1 Backbone
CNN 백본을 태워 이미지 추출하고 출력으로 저해상도의 featrure map을 반환합니다.
2.2.2 Transformer encoder
1×1 크기의 커널로 합성곱 연산이 수행돼 채널수를 줄입니다. 그리고 각 feature map을 flatten 시킨 후 encoder의 입력으로 전달합니다. 각 인코더 블록은 multi-head self-attention module과 feed forward network로 구성됩니다. 인코더 설계 상 입력에 대한 순서가 고려되지 않기 때문에 attention을 수행하기 전에 추가적으로 position encoding을 더해줍니다.
2.2.3 Transformer decoder
디코더 역시 기존 트랜스포머의 구조와 같은데요 차이가 있다면 각 디코더 레이어 마다 N개 객체에 대한 예측을 병렬적으로 함께 입력으로 전달해 attention을 모든 N개의 예측에 대해서 수행한다는 점입니다. DETR의 디코더는 non-autoregressive하지 않다고 이해하시면 되겠습니다. 디코더의 출력으로 나오는 N개의 object query에 대해서 FFN을 통과해 나와 최종적인 좌표 예측과 클래스 예측이 수행됩니다.
2.2.4. Prediction feed-forward networks (FFNs)
앞선 잠깐 얘기했던 최종 예측은 3 layer의 mlip와 하나의 linear projection layer로 바운딩 박스의 좌표 4개와 클래스 레이블이 나오게 됩니다.
2.2.5. Auxiliary decoding losses
어떤 제안된 영역 없이 direct하게 객체 예측을 하는 DETR의 경우 학습 초기에 충분한 정보가 없어 정확한 개수의 객체를 검출하지 못하고 바운딩 박스나 클래스 예측도 부정확할 수 있습니다. 그렇기 때문에 앞단의 디코더 레이어는 학습에 기여하는 정도가 낮을 수 밖에 없다고 하는데요 이를 해결하기 위해 저자는 각 디코더 레이어마다 FFN(디코더 내부의 FFN이 아님)을 통해 나온 예측을 가지고 앞서 설명 드렸던 hungarian loss를 고려하도록 설계하였습니다. 각 레이어 마다 FFN으로 예측을 수행하게 되면 파라미터 개수가 많아지게 되는데 그래서 각 FFN layer에 대한 파라미터는 각 디토더 블록이 공유하도록 했다고 합니다.
3. Experiments
기존 SoTA인 Faster R-CNN과 COCO 데이터셋에 대해 성능 비교를 한 결과 DETR이 꽤나 겸줄만한 결과를 냈다고 합니다. 이에 대한 정량적인 지표를 살펴보겠고요 또한 DETR에 대해 여러 ablation 연구가 진행되었는데 이에 대해서도 하나씩 살펴보겠습니다.
3.1. Comparison with Faster R-CNN
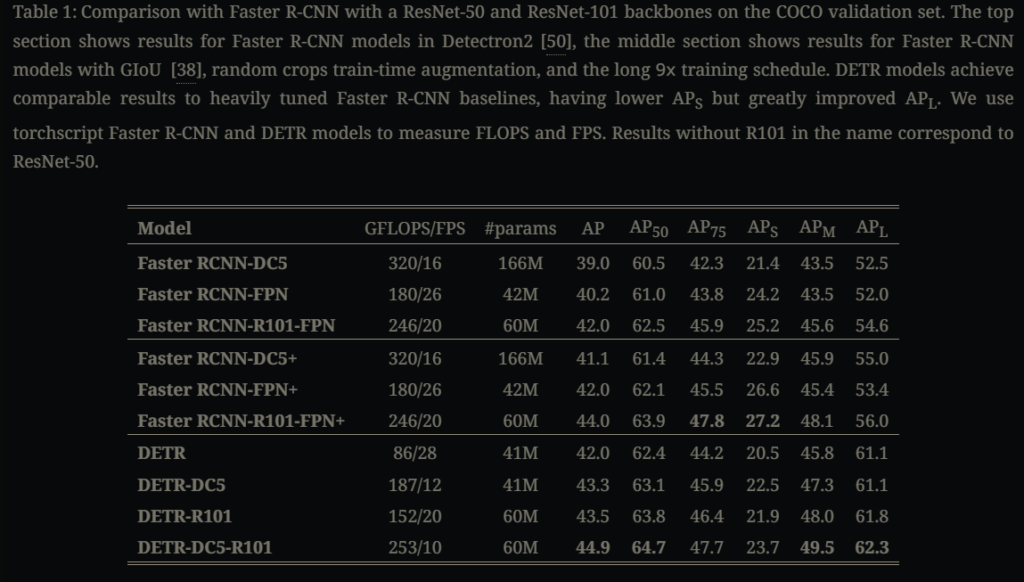
위 테이블 기존의 object detection에서의 SoTA였던 Faster-RCNN과 성능을 비교한 실험입니다. 각 모델에 여러 변주를 주었는데요 우선 ResNet-50, ResNet-101 모델을 백복으로 사용한 모델은 각각 DETR, DETR-R101로 나타나져있습니다. 백본 모델의 C5 단계에서 dilation을 주고 C5의 첫 convolution에서 stride를 제거해 resolution을 늘린 경우 DCS가 붙습니다. (DCS의 경우 테이블에서도 확인할 수 있겠지만 작은 객체에 대한 APS이 비교적 높습니다.) Faster RCNN 모델에 대해 뒤에 + 가 붙은 모델은 학습 epoch를 늘린 모델들입니다. 물론 DETR과 Faster-RCNN 모델 모두 더 오래 학습을 시킨다면 이보다 더 높은 정확도를 낼 수 있겠지만 위 실험만으로 충분히 DETR이 비슷한 개수의 파라미터로도 충분히 FCNN과 견줄 정도의 정확도를 보인다고 할 수 있겠습니다.
3.2. Ablations
3.2.1. Number of encoder layers
인코더 레이어를 줄이는 실험을 통해 인코더 계층의 깊이가 크기가 큰 객체에 대한 검출에 주는 영향을 확인할 수 있습니다. 인코더를 사용하지 않은 경우에는 기본 (인코더 6 layer) 전체적인 AP가 3.9 정도나 줄었다고 합니다 (AP: 40.6 → 36.7) 큰 객체만을 가지고 계산된 APL의 경우에는 그 정도가 더 컸고요. (APL: 60.2 → 54.2)
다음은 인코더의 마지막 레이어에서의 attention map을 시각화한 것인데요 일부 영역에 집중돼 있는 것을 보아 인코더에서 부터 객체 간의 구분이 이뤄졌다고 볼 수 있을 것 같습니다.

3.2.2. Number of decoder layers
다음은 디코더 계층마다 추가적으로 더했던 FFN과 그 matching loss에 대한 ablation study입니다. 각 레이어를 통과할 때 마다 점차 AP가 증가하는 것으로 보아 해당 방법론이 효과적이었음을 확인할 수 있습니다. 아래의 그래프를 참고하면,
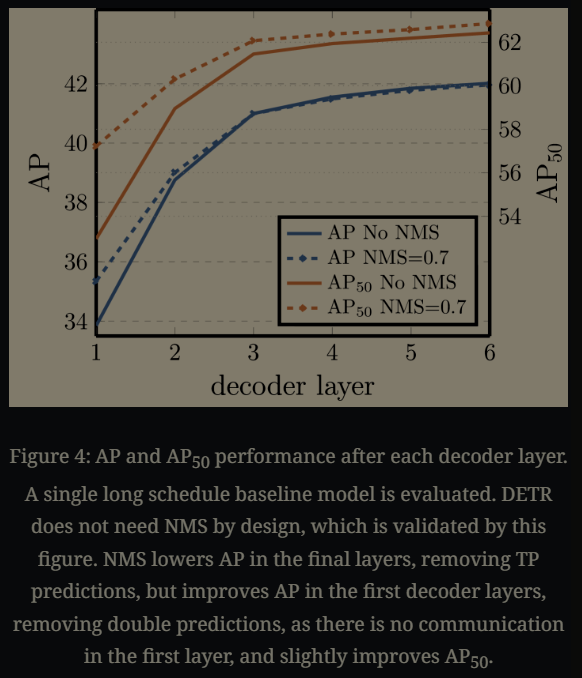
NMS를 추가했을 때 초기 레이어에서는 NMS가 없는 방법보다 AP가 높지만 decoder layer를 추가적으로 더 통과하고 나서는 그 차이가 줄어들고 NMS 없이도 비슷한 성능을 낸다는 것을 확인할 수 있습니다. 고로 NMS 없이도 정확하게 GT와 모델의 예측이 잘 매칭되고 학습이 되었다고 볼 수 있겠지요?
다음은 앞서 인코더에서도 확인한 것과 동일하게 디코더 레이어에서의 학습된 attention map을 이미지위에 각 객체마다 색이 다르게 시각화한 것인데요. 인코더에서는 전역적으로 각 객체를 구분하기 위해 객체가 이미지 속 차지하는 영역 전체가 attention 값이 컸다면 decoder에서는 객체에 대한 구분이 어느정도 된 후 정확한 객체의 바운딩 박스를 치기 위해 객체의 바운더리 영역이 조금 더 집중되고 있다는 것을 알 수 있습니다.

3.2.3. Importance of FFN.
트랜스포의 인코더와 디코더 블록의 FFN을 제거해 41.3 → 28.7M으로 대폭 줄인 후 성능 비교해보았는데 실험 결과, AP가 2.3 줄어들어 FFN의 중요성을 확인했다고 합니다.
3.2.4. Importance of positional encodings.
추가적으로 DETR에는 두가지 종류의 positional encoding이 더해지는데 ( feature map에서의 위치 정보 보존 위한spatial encoding, 디코더에서 각 object 쿼리마다 집중하는 객체를 구분하기 위해 더해지는 output positional encoding) 이에 대한 ablation 결과는 다음과 같습니다. spatial positional encoding이 없어도 성능이 아예 나오지 않는 것은 아니지만 성능 하락 폭이 큽니다. 인코더, 디코더에 모든 레이어 마다 spatial positional encoding과 output positional encoding을 더했을 때가 제일 결과가 좋습니다.

3.2.5. Loss ablation
모델 학습에 관여하는 loss에는 3개의 loss가 계산돼 함꼐 고려가 되는데요 (분류에 대한 loss, 바운딩 박스에 대한 l1 loss와 GIoU loss) 우선 object detection 태스크 상 분류는 수행돼야 하기에 classification loss는 기본적으로 모두 수행한다는 전제하에 l1 loss, GIoU loss를 제거함에 따라 성능 변화를 확인한 실험입니다. 두가지를 사용하는 게 제일 좋은 성능을 냈지만 실험 결과 신기했던 게 GIoU를 단독으로 사용했을 때 성능 하락이 거의 이뤄지지 않은 반면 GIoU를 제거하고 L1 loss에 대해서만 고려했을 때는 성능 하락 정도가 컸다는 것입니다.
또한 추가적인 실험이 하나 더 있는데요.. 꽤나 흥미롭습니다. 데이터셋에 같은 객체가 여러번 (15회 이상) 나오는 경우는 없다보니 학습을 통해 쿼리 마다 특정 객체에 대해서만 잘 학습도록 돼 있지 않을까 싶기도 한데요 그래서 저자는 기린을 여러번 복사해서 모든 쿼리에서도 기린으로 예측된 것을 보여 DETR에는 class-specialization이 있지 않음을 확인하였습니다.

4. Conclusion
본 연구를 요약하자면 기존의 object detection을 위해 prior knowledge가 필요한 앵커 박스 설정, region proposal 그리고 각 예측을 GT와 매칭 할 때 같은 객체에 대한 중복된 예측을 제거하기 위해 사용하던 NMS 같은 과정을 없애고 detection 자체를 holistic 하게 한번에 수행되도록 한 것이 DETR의 제일 중요한 contribution인 것 같습니다. 논문의 저자는 트랜스포머 기반으로 모델을 설계 해 single pass로 예측이 수행되도록 했고 hungarian 알고리즘으로 최적의 이분 매칭을 찾도록 해 앞선 방법이 가능하도록 구현하였습니다. 본 논문은 실험도 다양하게 많아 여러 궁금증을 해소해준 논문이었습니다.
읽어주셔서 감사합니다. ^^!!!
안녕하세요 지연님, 저번 리뷰의 배경이 되는 논문 잘 읽었습니다.
설명이 유기적으로 잘 되어 있어서 간략하게 드는 궁금증 질문 드리자면
디코더의 앞단이 제안된 영역이 존재하지 않아 초반 학습에 방황하는 모습을 해결하고자 공유하는 파라미터를 가진 FFN을 설계하여 많은 파라미터를 추가하지 않고도 초기 gradient 를 학습시킬 수 있게 한 것이라 이해했는데, 이러한 공유되는 FFN의 문제점은 없는지 궁금합니다. 결국 같은 파라미터를 공유하게 된다면 일반화가 더 잘된다거나 여러개의 디코더로 나눈 의미가 퇴색되는 것은 아닌지 싶어서 질문드립니다.
감사합니다.
안녕하세요 신인택 연구원님 댓글 감사합니다
질문에 적어주신 대로 디코더 블록 마다 FFN의 가중치를 공유하는 것에 장단점이 모두 존재합니다.
장점으로는 얘기해주신 것 처럼 일반화에 도움이 되고 안정적으로 학습할 수 있다는 점들이 있습니다. 특히나 초반에 불안정할 수 밖에 없는 본 모델에서 적합한 방식입니다.
하지만 디코더의 각 레이어마다 학습되는 게 다른데 (앞단 레이어는 coarse한 정보를 뒷단의 레이어는 더 fine한 정보를 처리한다고 합니다.) 가중치를 공유함으로써 각 레이어 마다 특화된 표현력을 낼 수 있는 것을 제한한다고 합니다.
안녕하세요 지연님, 좋은 리뷰 감사합니다!
DETR의 구조가 기존 객체 탐지 방식들과 비교해 매우 간결하고, anchor-free 및 end-to-end 방식이라는 점에서 인상 깊었습니다.
리뷰를 읽으며 한 가지 궁금한 점이 생겼습니다
DETR은 객체 탐지(object detection) 문제를 set prediction 문제로 재정의하면서 트랜스포머 구조를 효과적으로 적용하는 연구로 이해했는데 혹시 이와 같은 구조가 segmentation task 특히 semantic segmentation이나 instance segmentation에도 그대로 적용될 수 있을지 궁금합니다! 예를 들어, DETR에서 object query를 사용해 객체의 위치와 클래스 정보를 예측하는 것 처럼, segmentation task에서도 object query를 통해 pixel-level에서 직접 예측하는 방식으로 확장할 수 있는지 궁금합니다. 또한, 실제로 DETR 구조를 기반으로 segmentation에 확장한 연구나 모델이 있는지도 함께 여쭙고 싶습니다.
감사합니다!
안녕하세요 안우현 연구원님.
댓글 감사합니다.
찾아보니, 해당 방법론을 segmentation task에도 적용한 연구가 있었습니다.
제가 최신 연구까지 모두 찾아보진 못했지만 Maskformer2라고 2022년 CVPR에 기재돼 발표된 연구로 DETR의 방법론을 적용해 segmentation을 수행했더라고요. segementation에도 instance segmentation, semantic segmentation, panoptic segmentation 등 여러 종류에 segmentation이 있는데요 기존에는 각 종류에 특화된 모델이 개별적으로 연구가 되어왔었고 이를 모두 만족하는 모델의 경우 각각 특화된 모델의 성능에 미치지 못하였다고 합니다. 하지만 Maskformer2의 경우 DETR 기반으로 설계해 모든 segmentation task이 대해서 범용적으로 수행이 되면서도 기존 특화된 방법들 만큼 성능을 보였다고 합니다. 추가로 궁금하시다면 더 찾아보는 것도 좋을 듯 합니다.
Maskformer2의 경우 object query 하나 자체가 pixel level의 mask 예측을 의미하진 않지만 학습된 query들로 pixel level의 segmentation map을 만들어 내도록 설계가 되었다고 합니다.