
안녕하세요, 허재연입니다. 이번에는 Scene Graph Generation(SGG)분야 논문을 들고 왔습니다. CVPR 2022년에 게재된 논문으로, DETR의 철학을 많이 참고한 느낌의 방법론입니다. task가 아직 저에게 꽤 낯설고 수식도 워낙 많아서 리뷰 작성에 시간이 오래 걸렸네요.
리뷰 바로 시작해보겠습니다.
Introduction
Scene Graph Generation(SGG)은 이미지의 장면 이해를 목표로 하는 하위 task 중 하나입니다. 이미지에서 각 물체들을 검출하고, 물체들의 속성과 관계를 잘 찾아내는 것이 목표인데요, 이를 잘 수행할 수 있게 되면 지금보다 더욱 고차원적인 인지/추론을 수행하는 기반이 될 것입니다(Image Captioning, Visual Question Answering, Image Retrieval .. ). 그리고 이렇게 만들어낸 객체 간 관계를 Scene Graph라고 합니다. 말 그대로 이미지에서 추출한 정보를 graph 자료구조 형태로 기술하기에 붙은 이름입니다. 아래 그림을 보면 바로 이해가 되실 겁니다.
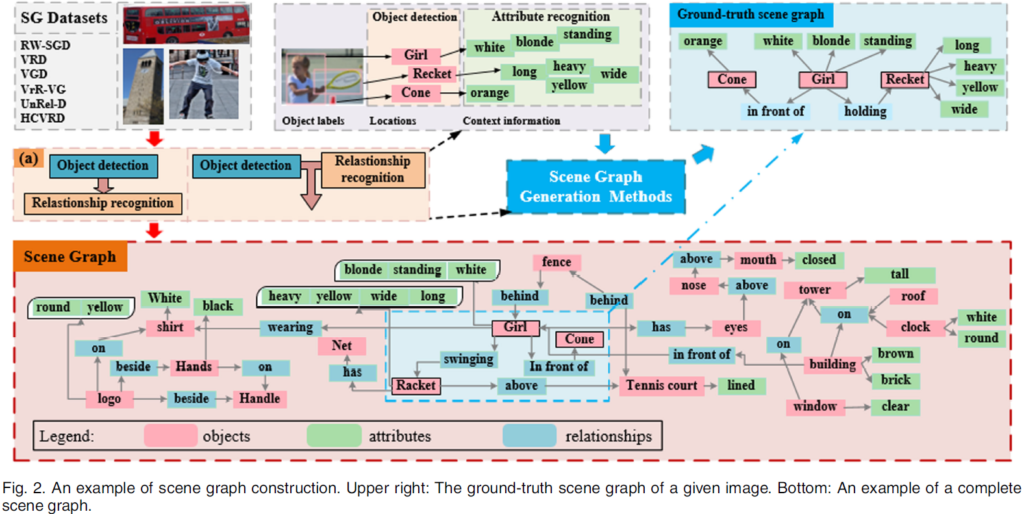
이 그림은 2023 TPAMI에 게재된 SGG 서베이 논문에서 발췌한 것입니다. Scene Graph가 무엇인지 한 눈에 이해할 수 있습니다. 각 object와 object의 attributes, relationship을 완벽히 감지하여 완전한 그래프 형태로 만들어내는 것이 최종적인 목적입니다. 상당히 어려운 task죠. task가 도전적이어서 그런지, 아직은 object와 relation을 잘 탐지하는데 그 연구 흐름이 집중되고 있는 것 같습니다. 특히 object detection은 요즘 굉장히 잘 되고 있기에, relation을 잘 찾아내는 데에 많은 관심이 모이는 것 같습니다. 여기서 object는 말 그대로 물체를 의미하고, relation은 두 물체 간 관계/연결을 기술하게 됩니다. 보통 <subject(주어)-predicate(술어)-object(목적어)> triplet 형태로 표현합니다. 여기서 predicate는 position이나 action 등 다양하게 올 수 있습니다(ex : girl swinging racket, cone placed in front of a girl ..). 특히 predicate/relation의 경우 자주 등장하는 술어의 수가 너무 많고, 잘 등장하지 않는 술어의 경우 데이터셋에서 그 수가 현저히 작은 long-tail 문제를 겪고 있기에 이 부분에 개선을 시도하는것이 하나의 연구 흐름이라고 합니다. 이런 SGG의 구현 방법으로 기존에는 RNN/LSTM을 활용하거나, object detector로 물체를 검출한 뒤 이들의 relation을 추론한다거나, GNN을 활용하여 SGG을 수행한다거나 등의 굉장히 다양한 구현 방법들이 있었다고 합니다(다양한 고전 방법론들의 세부적인 내용은 잘 모르기에 자세히 다루지 않겠습니다)
저자들은 특히 SGG의 도전 과제에서 객체 간 관계를 효율적으로 잘 모델링하는데에 집중합니다. 기존 연구들이 이 문제를 해결하기 위해 1. bottom-up 방식의 two-stage 접근법, 2. point 기반 one-stage 접근법을 사용하였다고 합니다. bottom-up 방식의 two-stage 접근법은 보통 먼저 N개의 entity proposal들을 검출한 뒤 이들 조합에 대한 predicate category를 예측하는 방식으로 수행되고, point 기반 one-stage 접근법은 relation proposal set의 크기를 줄이기 위해 이미지로부터 entity와 predicates를 별도로 추출하는 방식으로 동작합니다. bottom-up two state 방법론의 경우 prediate가 O({N}^{2})개 제안되어야 때문에 계산 복잡도가 크게 증가하고 context modeling 과정에서 상당히 많은 노이즈가 발생한다는 문제가 있고, one-stage 방법론들의 경우는 interaction region이 겹치지 않는다는 가정을 깔고 있어 복잡한 장면을 모델링 할 때 활용도가 크게 떨어진다는 단점이 있습니다.
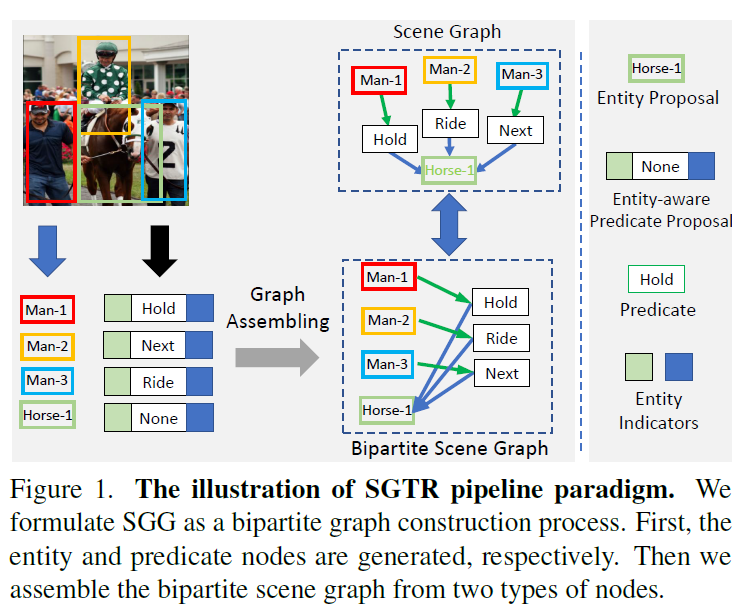
본 논문은 위 문제를 완화하기 위해, transformer 구조를 기반으로 SGG task를 이분 그래프 생성(bipartite graph construction) 문제로 구조화하여 해결한 방법론 SGTR(Scene graph Generation TRansformer)을 제안합니다. 이름에서 엿볼 수 있듯 DETR구조에서 아이디어를 얻은 것 같네요. 여기서 이분 그래프는 relation triplet을 두 물체를 노드, 관계를 엣지로 표현한 방향 그래프를 의미합니다. [object] -[relation]->[object]형태의 그래프가 되겠죠. 이 구조를 활용해 entity/predicate proposal 및 이들 간 연결을 공동으로 생성할 수 있게 하였습니다.
SGTR은 1. entity node generator, 2. predicate node generator 2. graph assembling module 3가지 모듈로 구성됩니다. 우선 입력 이미지에 대해 두 개의 CNN+Transformer 네트워크를 사용하여 entity와 preddicate node들을 각각 생성합니다(entiry node generator, predicate node generator). 이후 ntiry-aware predicate representaiton을 만들기 위해 3개의 병렬 트랜스포머 디코더로 구성된 predicate generator를 사용하여 predicate feature를 entity indicator representation으로 fusion하게 됩니다. entity, predicte node representation을 생성한 다음에는 graph assembling module을 사용해 bipartite graph의 edge를 예측하게 됩니다. 이렇게 설계한 방법론을 Visual Genoem 및 OpenImages-V6 데이터셋에서 검증하여 기존 SOTA모델들과 비교해 좋은 성능 및 추론 시간에서 효율성을 개선할 수 있었다고 합니니다.
저자들이 주장하는 주요한 contribution은 다음과 같습니다 :
- 우리들은 새롭게 트랜스포머 기반의 end-to-end SGG방법론을 고안하였다. 이 방법론은 기존의 2-stage, 1-stage 방법론들의 이점을 모두 활용할 수 있는 bipartite graph constuction 과정을 활용한다.
- 우리는 시각적 관계의 구성적 특성(compositional properties of visual relationships)을 활용하기 위해 entity-aware 구조를 개발하였다.
- 제안하는 방법론은 추론 시간은 훨씬 효율적으로 줄이면서 기존 SGG 방법론들의 평가에서 사용된 모든 성능 지표에서 SOTA 방법론들과 경쟁력 있는 성능을 달성하였다.
Method
본 논문에서는 SGG를 input image를 입력했을 때 noun entity에 대한 node set 및 subject-object entity pair 사이 관계를 나타내는 predicate edge set을 생성하는 task로 정의하고 알고리즘을 제안합니다. 여기서 각 entity는 category label이 부여되어있고, bounding box를 통해 해당 물체가 image에서 어디 있는지를 표시합니다. 주어와 목적어가 되는 두 물체 사이의 관계를 기술하는 predicate도 데이터셋에 predicate class로 미리 라벨링이 되어 있죠. 결국 주어진 이미지에 대해 relationshiop triplet(주어-술어-목적어)를 잘 추출하면 되는데, 저자들은 이를 bipartite graph construction task로 해석하여 relation triplet을 만들어냅니다.
좀 더 자세히 살펴보면, 저자들의 그래프는 각각 entiry representation과 predicate representation을 의미하는 두 노드 {V}_{e}, {V}_{p}로 이루어집니다. 이 두 노드 그룹들은 directed edge {E}_{e->p}, {E}_{p->e} 로 연결됩니다. e->p는 entity->predicate, p->e는 predicate->entity를 의미합니다. 이렇게 만들어진 bipartite graph는 {G}_{b} = {V}_{e}, {V}_{p}, {E}_{e->p}, {E}_{p->e}의 형태를 갖게 됩니다. 모델 {F}_{sgg}는 이미지를 입력받아 bipartite graph를 생성하게 되죠({g}_{b} = {F}_{sgg}(I)).
bipartite graph 구축은 크게 1. 노드(entity랑 predicate) 생성과 2. 방향 간선 연결(directed edge connection) 두 단계로 구성됩니다. 1. 노드 생성 단계에서는 이미지로부터 entity node generator와 predicate node generator를 통해 각각 entity node와 predicate node를 추출합니다. 이 중 predicate node generator는 3개의 병렬 디코더를 사용하여 predicate proposal에 entity 정보를 보강하게 됩니다. 2. 이후 directed edge connection 단계에서는 graph assembling module을 설계하여 entity 및 predicate proposal로부터 bipartite scene graph를 생성하게 하였습니다. 아래에서 자세히 살펴보겠습니다.
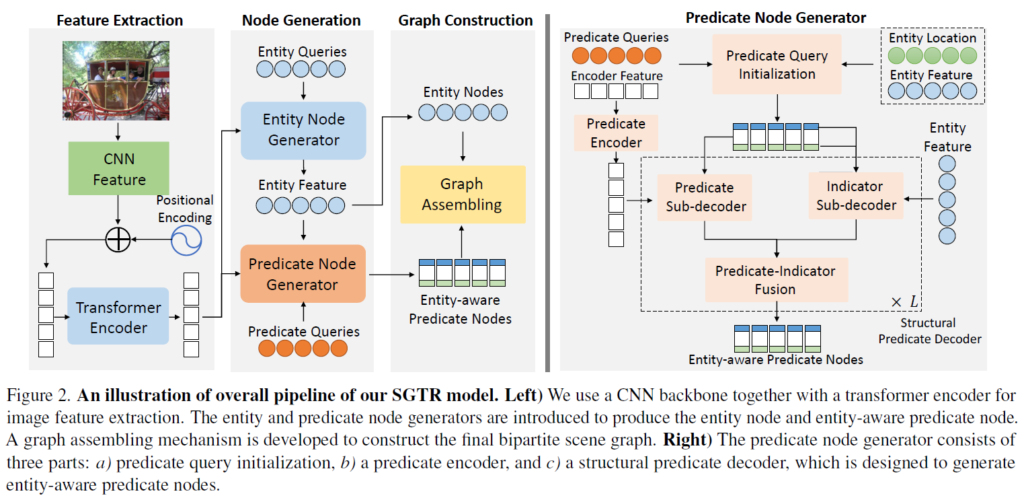
제안 프레임워크는 크게 다음의 submodule 4개로 구성됩니다. (1) 장면의 feature representation을 생성하기 위한 backbone network, (2) entity proposal을 예측하기 위한 트랜스포머 기반 entity node generator, (3) predicate node들의 디코딩을 위한 structural predicate node generator, 마지막으로 (4) entity nodes 및 entity-aware predicate nodes들의 연결을 통해 최종 bipartite graph를 구축하는 bipartite graph assembling module.
이제 각 모듈들을 살펴보겠습니다.
Backbone and Entity Node Generator
일단 image feature를 뽑기 위해 backbone network를 사용합니다. 논문에서는 ResNet을 사용하였습니다. 이후 DETR처럼 convolutional feature를 트랜프모퍼 인코더에 입력해 feature를 한번 더 정제합니다.
이후 entity node generator에서 DETR의 디코더를 활용해 learnable entity 쿼리 집합으로부터 {N}_{e}개의 entity node를 만듭니다. entity decoder를 {F}_{e}, 디코더 입력에 사용되는 initial entity query를 {Q}_{e} 디코더에 입력되는 feature map을 Z, 출력되는 entity location 및 class score를 {B}_{e}, {P}_{e}, 쿼리 및 feature map 정보가 반영된 출력 feature representation을 {H}_{e}라고 하면 다음과 같이 표현할 수 있습니다.
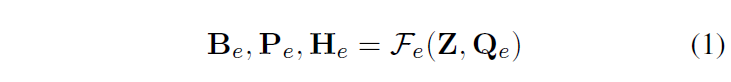
이 때 {B}_{e} = {b}_{1}, ... , {b}_{Ne}, b = ({x}_{c},{y}_{c},{w}_{b}, {h}_{b})입니다.
Predicate Node Generator
predicate node generator는 각 predicate 노드에 관련된 객체 제안 정보를 통합해서 entity-aware predicate representation을 생성하는 것을 목표로 합니다. 이 모듈을 활용해 각 predicate와 그 주어/목적어 객체 간의 잠재적 연관성을 효과적으로 인코딩할 수 있게 하여 그래프 엣지 예측을 수행하고 visual relation triplet을 효율적으로 생성하게 됩니다. 그림 2에서 확인할 수 있듯 predicate generator는 (1) entity-aware predicate query를 초기화하기 위한 ‘predicate query initialization 묘듈’, (2) 이미지 특징 추출을 위한 ‘predicate encoder’, (3) entity-aware predicate node들 집합의 디코딩을 위한 ‘structural predicate decoder’ 세 요소로 구성됩니다.
Predicate Encoder
우선 predicate-speific한 이미지 피쳐를 추출하기 위해 predicate encoder에 CNN+transformer를 feature Z를 입력합니다. predicate encoder는 여러 층의 multi-head self-attention 및 FFN으로 구성됩니다(일반적인 트랜스포머 인코더로 생각하시면 됩니다). 이 출력으로 predicate-specific feature {Z}^{p}가 나옵니다.
Predicate Query Initialization
predicate 예측에 사용할 predicate query를 설계하는 가장 나이브한 방법은 DETR처럼 단순히 learnable한 벡터 집합을 사용하는 것이긴 하지만, 이런 형식의 쿼리 를 사용하는 방법은 시각적 관계(visual relationship)를 구성하는 요소들의 특성과 entity 후보들의 정보를 제대로 반영할 수 없다고 주장합니다. 저자들은 이 문제를 해결하기 위해 (predicate query)를 세 가지 요소 {{Q}_{is}, {Q}_{io}, {Q}_{p}}로 분리한 구성적 관계 쿼리 표현(compositional query representation)을 사용합니다. predicate query {Q}^{e}_{p}를 subject/object entity indicator {Q}_{is}, {Q}_{io}와 관계 표현(predicate representation) {Q}_{p} 형태로 나누어 {{Q}_{is}, {Q}_{io}, {Q}_{p}}형태로 구성하게 됩니다. 이 때 초기 predicate query {Q}_{init}과 entity representation {B}_{e}, {H}_{e}를 사용해 entity 정보를 담고 있는 predicate query {Q}^{e}_{p}를 만들어냅니다. 이를 위해 먼저 efficient DETR에서 적용한 것과 같이 key와 value를 수식 2처럼 설정하여 기하 정보 기반의 객체 표현(geometric-aware entity representation)을 구성합니다.
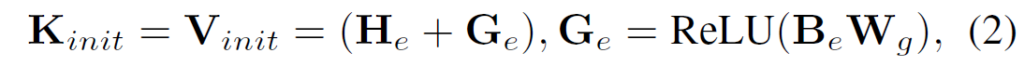
수식에서 {G}_{e}는 entity proposals들의 learnable geometric embedding이고, {W}_{g} 는 bounding box 위치를 embedding 공간으로 변환시키는 행렬입니다. 이후 initial predicate queries {Q}_{init}과{K}_{init}에 multi-head cross attention 연산을 적용해 predicate queries {Q}^{e}_{p}를 계산합니다. 연산은 A(q, k, v) = FFN(MHA(q,k,v))형식으로 수행됩니다. 연산은 3개의 sub-query들 {Q}_{is}, {Q}_{io}, {Q}_{p}에 대한 변환 행렬 {W}_{e} ∈ [{W}^{is}_{e}, {W}^{io}_{e}, {W}^{p}_{e}]를 활용해서 다음과 같이 수행됩니다.
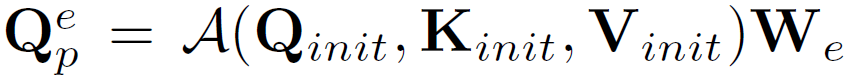
이 방법으로 entity 정보를 predicate query에 통합하는 structural query를 얻게 됩니다. 여기서 저자들은 sub-query {Q}_{is}, {Q}_{io}를 이후 predicate-query 연관성을 포착하는데 사용되므로 entiry indicator라고 표현합니다.
Structural Predicate Node Decoder
predicate query {Q}^{e}_{q}를 만든 다음, 이후 구조적 특성(compositional property)를 활용하여 entity/predicate 특징 맵으로부터 predicate triplet을 디코딩하는 structural predicate node decoder를 적용합니다.
structural decoder는 1. predicate sub-decoder, 2. entity indicator sub-decoders 3. predicate indicator fusion 3가지 모듈로 구성됩니다(그림 2 참고). 두 종류의 서브 디코더는 각각 encoder 특징 맵 {Z}_{p}와 entiry feature {H}_{e}를 입력으로 받아, predicate query의 세 구성 요소를 각각 독립적으로 업데이트 하게 됩니다. 이후 업데이트된 쿼리 구성 요소를 기반으로 predicate-indicator fusion은 전체 predicate query를 정제하여, 각 compositional query 내에서 entity-predicate 간의 연관성을 향상시키는 것을 목표로 합니다. 디코더에는 일반적인 트랜스포머 디코더 구조를 활용하였습니다. 아래 표기에는 간단한 표시를 위해 각 서브 디코더의 단일 디코더 계층만을 표시하고 self-attention 연산을 생략하였습니다.
Predicate Sub-decoder.
predicate sub-decoder는 영상의 특징맵 {Z}_{p}로부터 predicate representation을 정제하도록 설계되었으며, 이미지 내의 공간적 문맥(spatial context)를 활용하여 predicate representation을 업데이트하게 됩니다. 디코딩 과정은 일반적인 cross-attention 연산을 사용합니다.
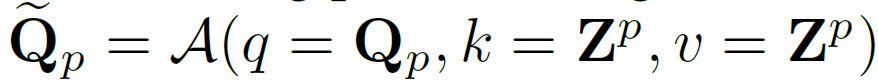
{Q}_{p} hat은 업데이트 된 predicate representation입니다.
Entity Indicator Sub-Decoders.
entiry indicator sub-decoder는 predicate query에 연관된 entity indicator를 정제하는 역할을 합니다. 이때 이미지 특징에 의존하는 대신 scene 내에서 보다 정확한 객체 특징(entiry feature)를 활용합니다. entity indicator {Q}_{is}, {Q}_{io}와 entity node generator로부터 나온 entity proposal feature {H}_{e} 간 크로스 어텐션을 수행하여 entity 연관성에 대한 표현을 개선하고자 하였다고 합니다. entity indicator의 업데이트 된 representation은 수식 (3)과 같이 일반적인 cross attention 연산으로 만들어집니다.
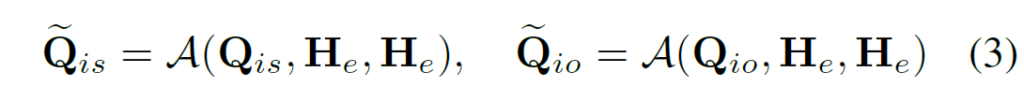
Predicate-Indicator Fusion
각 predicate query와 해당 entity indicator들 간의 문맥적 관계(contextual relation)을 인코딩하기 위해, predicate-indicator fusion을 수행하여 쿼리의 세 구성 요소 특징을 보정합니다. 이는 현재 l번째 디코더 계층의 출력 \hat{Q}^{l}_{p}, \hat{Q}^{l}_{is}, \hat{Q}^{l}_{io}를 퓨전하여 다음 계층에서 사용할 쿼리인 \hat{Q}^{l+1}_{p}, \hat{Q}^{l+1}_{is}, \hat{Q}^{l+1}_{io}를 각각 업데이트 하는 방식으로 수행됩니다. entity indicator representation을 업데이트 하는데 아래와 같이 fc layer를 적용합니다.
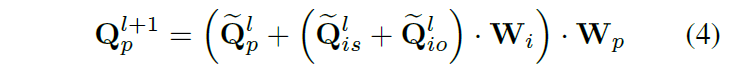
W_i, W_p는 각각 업데이트를 위한 파라미터입니다. entity indicator의 경우에는 간단히 이전 계층의 출력값을 입력으로 사용하였다고 합니다.
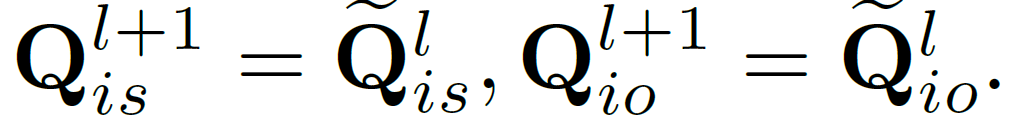
이렇게 정제된 predicate query를 기반으로, 다음 수식을 통해 predicate node의 기하적/의미적 예측 뿐만 아니라, 해당 predicate에 연결된 entity indicator의 위치와 카테고리까지 예측하게 됩니다.
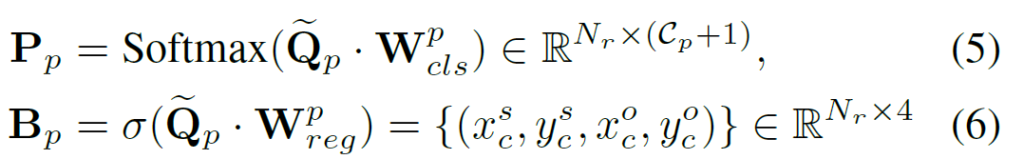
여기서 {P}_{p}는 predicate의 클래스 예측값이고, {B}_{p} = ({x}^{s}_{c}, {y}^{s}_{c}, {x}^{o}_{c}, {y}^{o}_{c}) 는 주어/목적어 entity들의 박스 중앙 좌표가 됩니다. entiry indicator는 각 엔티티에 대한 위치 예측값 및 이에 대한 분류 예측값으로도 해석할 수 있게 됩니다.
전체적으로, 각 predicate decoder 계층은 모든 entity-aware predicate query들에 대한 위치 및 클래스 분류 정보를 만들어냅니다. 저자들은 predicate decoder가 이런 구조를 통해 predicate 및 entity 간 연관성의 품질을 점진적으로 향상시킬 수 있다고 합니다.
Bipartite Graph Assembling
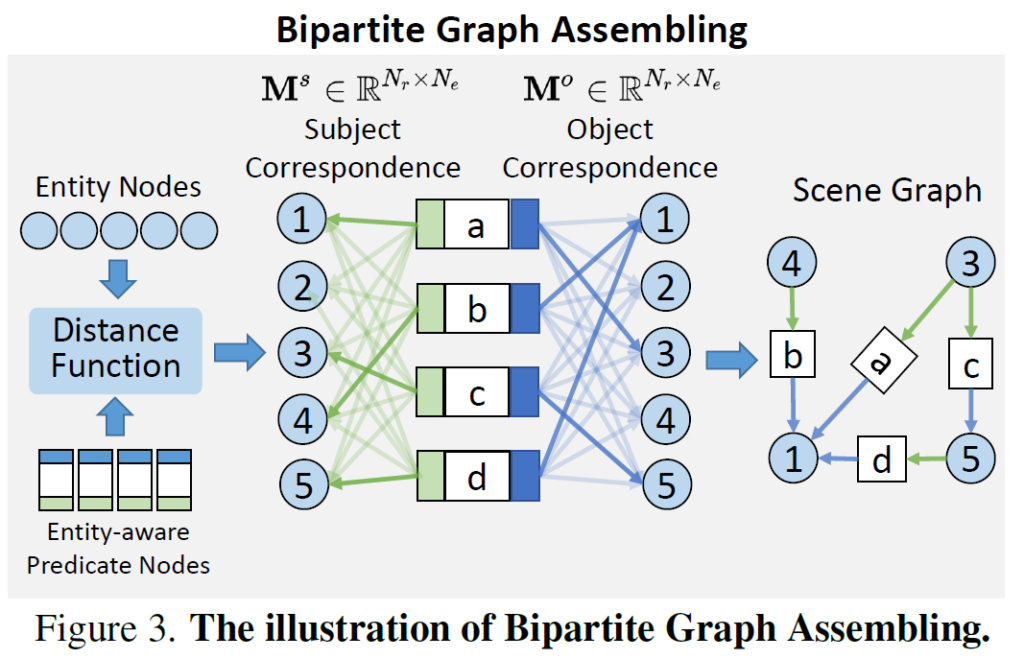
저자들은 {N}_{e} entity nodes와 {N}_{r} predicate node로 구성된 bipartite graph 구조를 구축하고자 합니다. 그래프 조합의 목표는 entity-aware predicate node를 적절한 entity node와 연결하는 것입니다. 이를 위해서는 {N}_{e}개의 entity node와 {N}_{r}개의 predicate node 간의 인접 행렬(adjacency matrix)를 구해야 합니다. 저자들은 이를 predicate node 의 entity indicator와 entity node 간의 거리를 기반으로 대응 행렬(correspondence matrix)을 정의하여 이를 구현하였습니다. 예를 들어 주어 엔티티(subject entiry) indicator에 대해서, 다음과 같이 나타냅니다.
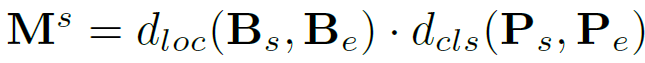
여기서 {d}_{loc}(⋅)와 {d}_{cls}(⋅)는 각각 location 및 class 차원에서의 매칭 품질을 측정하는 거리 합수입니다. 목적어 entity에 대한 대응 행렬 {M}^{o} 또한 동일하게 연산됩니다. 이 correspondence matrix를 기반으로, 각 predicate node에 대해 매칭 점수 기준 top-K개의 link를 선택하여 edge로 사용합니다.
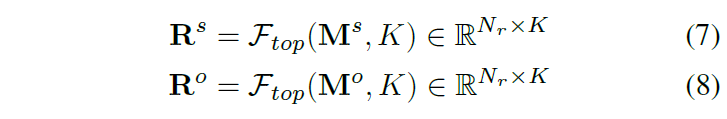
.수식에서 {R}^{s}, {R}^{o}는 relation triplet에서 각각 주어, 목적어 entity에 대한 index matrix이고, {F}_{top}은 top-K index를 선별하는 연산입니다.
이제 index 행렬 {R}^{s}, {R}^{o}까지 활용하여, 최종적인 relationship triplet을 만들 수 있습니다. relation triplet은 다음 형태로 구성됩니다. 구성 요소에서 {b}^{s}_{e}, {b}^{o}_{e}는 subject / object entity의 bounding box이며, {p}^{o}_{e}, {p}^{o}_{e}는 클래스 예측값입니다. {p}_{p}는 각 predicate의 클래스 예측값이며, {b}_{p}는 predicate entity의 중심 값입니다. 마지막으로, 이 정보들을 기반으로 graph assembling module이 scene graph를 생성하며, 이 값이 SGTR 모델의 출력이 됩니다.
Learning and Inference
SGTR모델 학습에는 entity generator 및 predicate generator를 위한 loss {L}^{enc}, {L}^{pre}를 사용합니다. 전반적인 loss는 다음과 같습니다 :
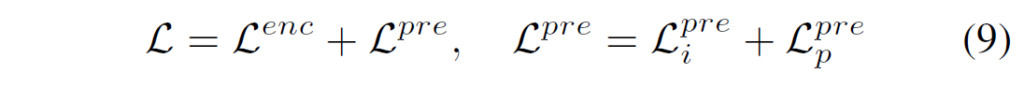
기본적으로 DETR 구조를 많이 차용했기에 {L}^{enc} 부분은 DETR의 loss로 생각하시면 됩니다. 논문에서도 이에 대해선 자세한 언급 없이 {L}^{pre}에 대해 설명하네요. predicate node generator loss 계산을 위해 우선 헝가리안 매칭 알고리즘을 활용해 예측값 및 GT값 사이의 매칭 행렬을 계산하고 visual relation의 GT값들을 SGTR모델의 출력과 동일한 형태의 triplet representation으로 변환합니다. set matching에 대한 cost는 다음과 같이 계산됩니다.
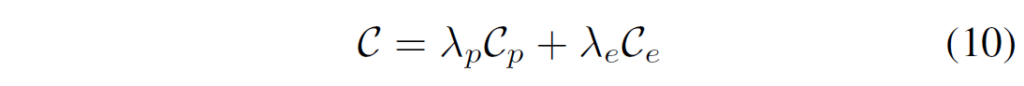
total cost는 두 항으로 이루어지는데, 각각 predicate과 subject/object entity에 대한 비용을 나타냅니다. triplet 예측과 정답간의 매칭 인덱스 {I}^{tri}는 다음과 같이 계산됩니다. GT와 prediction triplet에서 cost가 가장 작은 index를 선택하는 연산입니다.
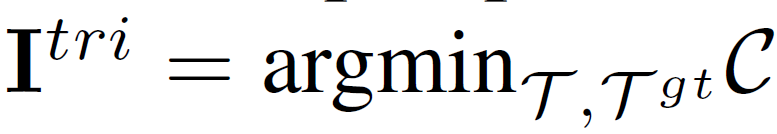
이 인덱스는 이후 predicate node generator의 loss 계산에 사용됩니다.
predicate node generator의 두 sub-decoder를 학습하기 위해서 {L}_{pre} = {L}^{pre}_{i} + {L}^{pre}_{p}를 사용하게 됩니다. entity indicator sub-decoder의 경우에는, 각각 localization loss(L1 및 GIoU), entity indicator Ps, Bs, Po, Bo에 대한 cross-entropy loss를 사용하여 다음과 같이 구성됩니다.
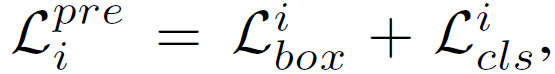
비슷하게 predicate sub-decoder에 대해서는 다음과 같이 연산됩니다. 여기서는 cls loss가 predicate category 분류에 사용됩니다.
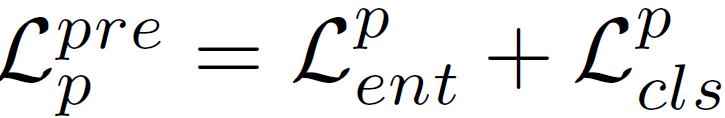
추론 단계에서는 assembling stage 이후 K·{N}_{r}개의 visual relation 예측값을 만들고 후처리 과정을 통해 subject와 object가 동일한 triplet과 같이 성립되지 않는 쌍들을 제거합니다. 이후에 남은 예측값들을 triplet score로 정렬하여 top N개의 relationship triplete들을 최종 출력으로 사용합니다.
Experiment
평가는 Openimage V6 dataset 및 Visual Genome이라는 데이터셋에서 진행되었습니다. SGG의 평가에 자주 사용되는 데이터셋들입니다. openimage benchmark에 대해서는 클래스 밸런스를 보정하기 위해 이전 연구들과 동일하게 weighted evaluation metrics를 사용하였고, Visual Genome의 경우 Recall@K와 mean Recall@K를 사용하였습니다. 백본과 entity detector로는 각각 ResNet101과 DETR을 활용하였고, 학습 속도를 높이기 위해 우선 target dataset을 활용해 entity detector를 학습하고 이후에 predicate node generator와 joint training을 진행하였다고 합니다. graph assembling module의 경우 학습 시에는 K=40, 추론 시에는 K=3으로 설정하였다고 합니다
Ablation study
가장 앞에 있는 실험이 특이하게도 ablation study입니다. visual genome에서 각 구성 요소에 대한 비교를 수행하였습니다. 결과는 Table 1에서 확인할 수 있듯 당연히도 제안한 모듈들을 모두 사용한것이 가장 좋은 성능을 내었습니다. Table 2에서는 각 sub-decoder의 계층 개수 설정에 따른 비교를 나타내었습니다.
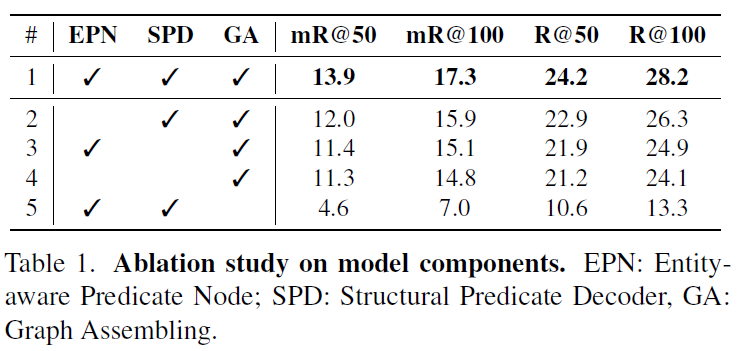
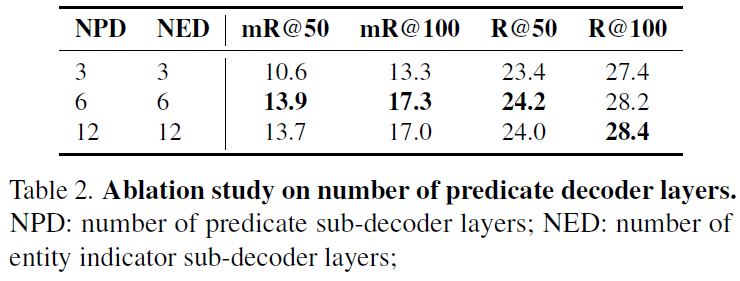
Table 3에는 assembling module에서 서로 다른 distance function을 사용했을 때에 대한 실험 결과입니다. AS-Net이라는 방법론에서는 entity bounding box와 interaction branch가 예측한 엔터티 중심 간의 거리를 기준으로 grouping이 이루어지는데, 이 방식은 entity의 의미론적 정보가 부족하다고 합니다. HOTR이라는 방법론은 predicate과 entity 사이의 피처 공간에서의 코사인 유사도를 활용하였는데, 저자들은 이를 활용하여 entity indicator와 entity node 간 거리 계산에 활용하였다고 합니다. 제안하는 방법이 가장 결과가 좋았고, 저자들은 이를위치 정보만을 활용하는 AS-Net의 유사도 방식과 피처 기반 유사도 방식인 HOTR에 비해, 제안하는 assemble
우리의 조립 메커니즘dl 의미 정보와 공간 정보를 모두 고려한 유사도 계산을 수행하여 더 우수한 성능을 보였다고 분석하였습니다. 추가적으로 실험적으로도 HOTR의 피처 기반 유사도 설계는 수렴 속도가 느리고 학습 안정성이 떨어지는 경향이 있음을 관찰되었다고 합니다.
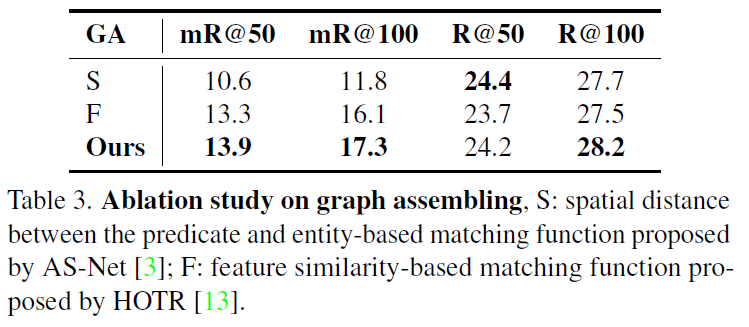
다음은 제안하는 방법론의 비교 실험입니다.
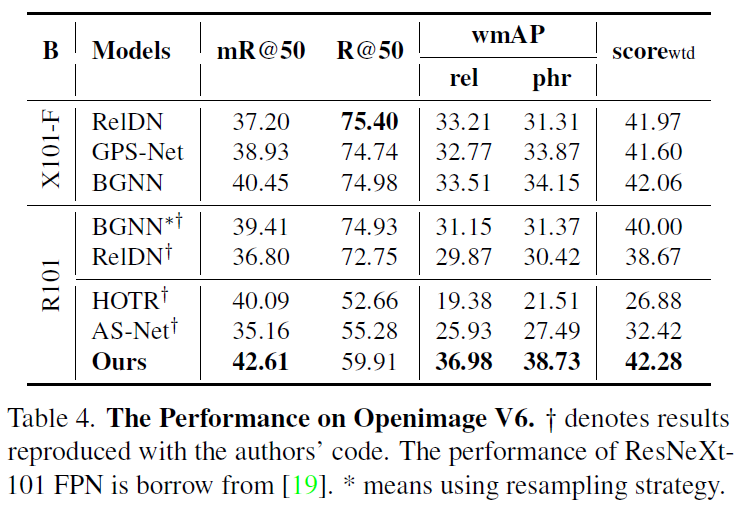
다른 방법론들 중 다른 backbone을 사용한 것들의 경우 공정한 비교를 위해 동일하게 ResNet101을 활용하여 재구현했다고 합니다. OpenImage V6에서는 제안하는 방법론이 가장 좋은 결과를 보여주었습니다.
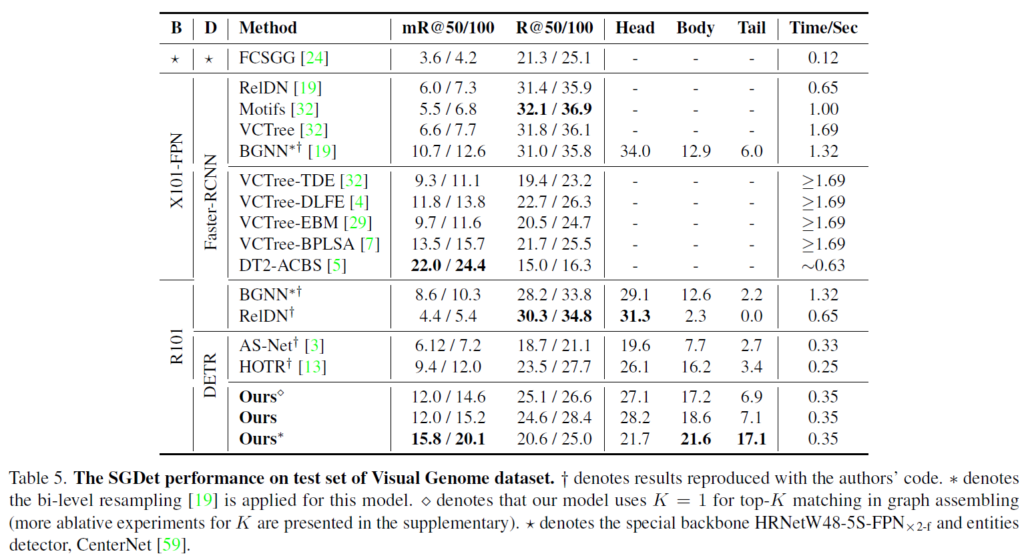
Visual Genome 벤치마크에서도 타 방법론 대비 추론 시간을 크게 줄이면서 경쟁력 있는 성능을 보여주었습니다. 특히 SGG 평가 데이터셋들의 경우 long-tail 문제가 꽤나 심한 편인데, R@50/100에서 mR@50/100으로 바뀔때도 성능 drop이 크지 않고 body, tail쪽에서 상당히 좋은 결과를 보였습니다. head distribution에 편향되어있는 달느 방법론들에 비해 강건한 결과를 보여주었죠. 다른 모델들과 비교해 R@50/100 최고 성능을 달성하기 못한 부분에 대해서는, Visual Genome 데이터셋 같은 경우 small object의 비중이 높은데, DETR의 경우 Faster RCNN보다 small object detection 능력이 떨어져서 이에 대한 영향이 있다고 설명하고 있습니다.
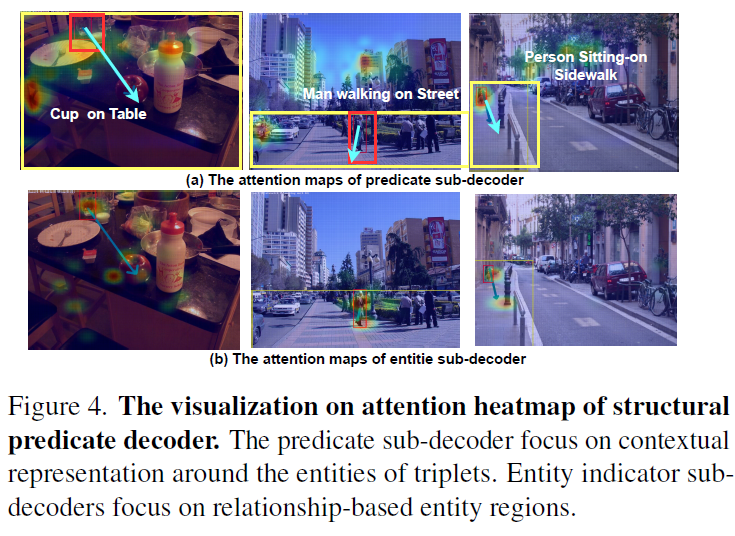
Figure 4에는 시각화 결과를 나타내었습니다. Visual Genome dataset의 validation set에서 predicate sub-decoder와 entity sub-decoder의 attention weight를 표시하였는데, 동일한 triplet 예측값에 대해 predicate sub-decoder는 보다 엔티티 주변의 contextual region에 집중하였고 entity sub-decoder는 entity 에 좀 더 집중한 것을 확인할 수 있습니다.
DETR을 기반으로 SGG를 수행하는 SGTR에 대해 살펴보았습니다. task 자체가 쉽지 않기 때문에 나름 end-to-end 구조인데도 고려해야 할 요소가 상당히 많은 것 같네요. 이후에도 SGG를 살펴보고, open-vocabulary 로 어떻게 확장해나가는지 follow-up해보도록 하겠습니다.
감사합니다.