이번 리뷰 논문은 Physical AI를 선도 하는 그룹인 Physical intelligence의 최신 VLA 논문으로 π0의 후속 논문입니다. 굉장히 fancy한 접근과 파격적인 실험 결과를 보여준 논문입니다. 아래의 동영상 중 29초에서 “we tested it in AIRBNB across San Francisco that our robot had never seen before”란 문구가 있습니다. VLA 태스크에서는 처음으로 long-horizon task를 한번도 보지 못한 환경에서 end-to-end로 수행한 기법입니다.
Intro

로봇이 일상 생활에 녹아져 서비스를 하기 위해서는 제약되고 가공된 랩실 환경을 벗어나 와일드한 일상 환경에서도 동작이 가능해야 합니다. 최근 VLA에서는 한 종의 로봇 뿐만이 아니라 다양한 로봇 플랫폼에서도 하나의 end-to-end인 VLA로 일반화가 가능함을 보였습니다. 또한, 복잡한 태스크도 수행하는 결과를 보여줍니다.
허나, 기존의 연구들은 long-horizon task, 예를 들어 “침대를 치워줘”에서는 한계를 보여주며, “베개를 제자리에 정리해줘”와 같이 sub-task에선 효과적임을 보이고 있습니다. 이러한 한계를 극복하기 위해서 long-horizon task를 low-level task로 쪼개기 위해서 high-level planner로 VLM을 추가로 채용하여 수행하는 연구를 진행하고 있습니다.
저자는 로봇의 진정한 일반화로 나아가기 위해서는 VLA이 long-horizon task 조차도 end-to-end로 수행해야만 한다고 주장합니다. 이를 수행하려면 어떻게 해야 할까요? 저자는 사람의 학습 방법에 주목합니다. 사람은 관련된 일들을 직접 경험을 통해서 학습을 수행하기도 하지만 책을 통해서도 간접적인 체험을 얻어 이를 적응적으로 응용해 해당하는 일들을 헤쳐나가기도 합니다.

저자는 사람의 행동에 대한 학습 방법을 모티브 삼아 로봇의 액션 뿐만이 아니라 fig 1과 같이 web data(image observations, language commands, object detections, semantic subtask prediction)에 대한 간접적인 지식을 습득하여 적응적으로 수행할 수 있음을 보입니다. 실험 결과, 기존 VLA 연구들은 학습 데이터와 유사한 환경에서 테스트를 수행한 것에 반해 처음으로 fig 2와 같이 한번도 보지 못한 가정 환경에서 테스트를 진행하여 end-to-end로 수행이 가능함을 보입니다.
Method
PRELIMINARIES
VLA은 일반적으로 다양한 로봇 데이터 셋 D에서 모방 학습을 통해 학습되며, observation o_t와 language instruction l이 주어졌을 때 action a_t ~ action chunck a_{t:t+H}의 log-likelihood를 최대화하는 것을 목적으로 합니다.
observation에는 일반적으로 robot joint이 노출된 하나 이상의 이미지 I_1^t, …, I_n^t 및 로봇의 현재 상태 (proprioceptive state) q_t가 포함됩니다.
VLA의 아키텍쳐는 입력과 출력을 discrete(“hard”) 또는 continuous(“soft”) token representation에 매핑하는 modality-specific tokenizers와 입력에서 출력 토큰으로 매핑하도록 학습된 대규모 auto-regressive transformer backbone을 사용하여 modern language 및 vision-language models의 설계를 따릅니다. 대체로 VLA에서는 이러한 모델의 가중치는 사전 훈련된 vision-language model를 활용하여 초기화됩니다.
로봇의 액션에 대한 정보도 토큰화된 표현으로 정책 입력 및 출력을 인코딩함으로써, 모방 학습 문제는 observation, instruction and action token에 대한 간단한 next-token-prediction problem로 해결이 가능하게 됩니다.
여기서 영상과 텍스트에 대한 tokenizers는 최신 vision-language models을 따릅니다.
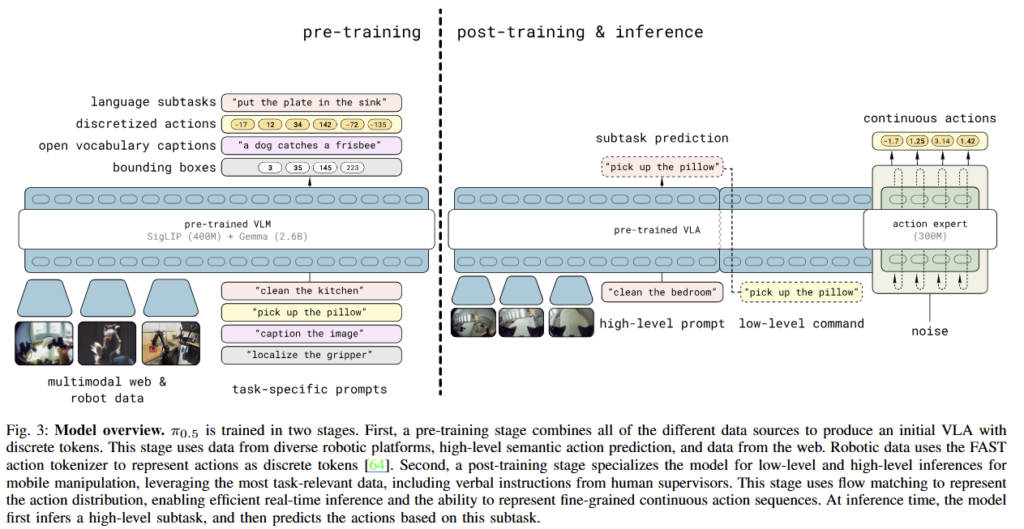
로봇의 동작을 표현하는 action 같은 경우에는 최근에 리뷰한 FAST를 tokenizer를 사전 학습 과정에서의 도구로 채택합니다. 최근 VLA 기법들은 diffusion 혹은 flow matching을 통해서 액션 분포를 통해 연속적인 표현과 실시간성을 확보한 결과를 보입니다. 저자는 사후 훈련에서는 flow matching을 이용하는 π0로 사후 훈련에서 적용하는 구조를 구축합니다. 해당 구조는 “action expert”라고도 불리웁니다. 이러한 구조는 fig 3에서도 확인 가능합니다.
THE π0.5 MODEL AND TRAINING RECIPE
π0.5의 구조와 training recipe는 fig 3와 같습니다. 초기값은 사전학습된 standard VLM으로 초기화되면 액션에 대한 훈련은 두 단계로 구분되어 진행됩니다. 먼저, pre-training stage에서는 다양한 robotic tasks에 적응하기, post-training stage에서는 테스트에 활용되는 mobile manipulation에 효율적으로 특화 시키는 것을 목적으로 합니다. pre-training 동안은 robot action에 대한 discrete tokens을 활용해 간단하고, 적응적이고 효울적인 학습을 진행합니다. post-training 동안은 real-time control을 위한 계산 효율적인 추론이 가능한 π0의 action expert를 이용하여 학습을 진행합니다. inference-time에는 먼저 로봇이 수행행해야 하는 high-level subtask를 추론하여, subtask에 따라 action expert를 통해 low-level actions을 예측합니다.
The π0.5 architecture.
π0.5의 아키텍쳐는 action chunk에 대한 distributions 뿐만이 아니라 tokenized text outputs모두 유연하게 나타낼 수 있으며, tokenized text는 co-training tasks(e.g. VQA)와 high-level subtask predictions에 활용됩니다. 모델의 분포는 \pi_\theta (a_{t:t+H}, \hat{\ell}|o_t, \ell) 로 나타낼 수 있으며, 여기서 o_t = [I^1_t, …, I^n_t, q_t] 는 t 시간대에서의 모든 영상과 로봇의 현재 상태 q_t (robot’s configuration~joint angles, gripper pose, torso lift pose, base velocity)를 나타냅니다. /hat{l}은 모델의 text 형태의 출력물로 예측된 high-level subtask에 해당합니다. 이를 정리하면 아래와 같습니다.
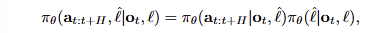
여기서 특정적인 부분은 액션을 예측에 있어 사용자의 명령어가 아닌 모델이 예측한 high-level subtask가 들어간다는 점입니다. 또한, 예측을 수행하는 모델은 동일한 모델이라고 보시면 됩니다.
해당 모델은 multimodal input tokens x_{1:N}을 받아 multimodal outputs y_{1:N}을 예측합니다. 이는 y_{1:N} = f(x_{1:N} , A(x_{1:N}), \rho(x_{1:N}) 로 나타낼 수 있습니다. 각 x_i는 text token은 x^w_i, image patch x^I_i, flow matching (~action expert)의 robot action x_a_i이 될 수 있습니다. 각 token type에 따라서 서로 다른 encoder 혹은 transformer 내에 서로 다른 expert를 통해 처리됩니다. image encoder는 vision encoder, text token은 embedding matrix에 따라 진행됩니다. action은 선형 사영되어 expert를 통해 denoising되어 처리됩니다. attention matrix A(x_{1:N}) \in [0, 1]^{N\timesN}에 따라 서로 참고해야 하는 모달을 정해줍니다.
저자는 해당 모델이 high-level subtask를 표현하는 text와 실제 환경에서 subtask를 수행하는 action을 분리하여 출력하기를 원합니다. 즉, output tokens은 (y_{1:M}^l, y_{1:H}^a) 를 구성하기를 원합니다. 여기서 M+H =< N이며, 모든 출력은 loss에 활용되진 않습니다.
Combining discrete & continuous action representations
해당 모델은 최종적으로 π0와 동일한 action expert를 사용합니다. 그러나 해당 그룹의 이전 연구인 FAST에서는 action chunk를 압축한 action token을 이용하면 보다 빠르고 효율적인 VLA 학습이 가능함을 보였습니다. 허나, 해당 기법은 discrete token을 이용하기 때문에 auto-regressive decoding을 수행하기 때문에 flow matching보단 실시간성이 떨어진다는 단점이 있습니다. 이에 따라 discrete action으로 학습한 모델을 flow mathing을 사용해서 추론 시간에 continuous action을 생성하면 두 장단점을 합칠 수 있게 된다고 저자는 주장합니다.
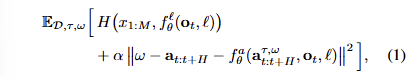
수식 1에서 H(x, f_l)은 text tokens과 FAST~action tokens에 대한 cross-entropy loss이며, f^a는 action expert에 대한 loss에 해당합니다. 여기서 \alpha는 trade-off parameter에 해당합니다. 수식 1의 구조는 먼저 pre-training (\alpha = 0)으로 action을 text token으로 다뤄 standard VLM transformer를 수행합니다. 그런 다음에 post-training에서 continuous action tokens in a non-autoregressive인 action expert의 가중치를 학습합니다. 해당 방식을 이용하면 안정적으로 사전 학습이 가능하며 VLA의 language following 능력이 아주 훌륭해진다고 합니다. 추론에서는 standard autoregressive decoding을 통해 subtask인 text token \hat(l)을 받아 10 denoising step을 통해 action chunk를 예측합니다.
+ 좀 정리해주면 VLA는 VLM에 모방 학습에서 큰 반향을 일으킨 action expert ~ diffusion policy를 이용하는 기법과 standard VLM을 재학습하는 auto-regressive transformer 방법, 두 방식으로 구분이 가능합니다. 저자는 두 가지 방법을 합쳐서 사용하는 방법을 이용합니다. 아마 standard VLM이 범용적인 지식 전이에 효과적이긴 하겠죠. 이를 주장하고 싶지만 증명할 방법이 마땅치 않아 따로 이야기하진 않을 것 같습니다.

Pre-training
해당 논문의 핵심입니다. 먼전 사전 학습에서는 넓은 범위의 로봇 데이터와 non-robot data를 사용하여 학습을 합니다. 이에 대한 정보는 fig 4에서도 확인 가능합니다. 해당 단계에서는 standard auto-regressive transformer를 학습합니다. 해당 모델은 text, object locations, FAST (action tokens)에 대한 next-token prediction을 수행합니다. 학습에 활용된 데이터는 아래와 같습니다.
- Diverse Mobile Manipulator data (MM). 100 곳의 다른 가정 환경에서의 집안일을 약 400 시간 동안 mobile manipulators으로 취득한 데이터입니다. 평가 환경과 가장 유사한 정보를 가지고 있습니다.
- Diverse Multi-Environment non-mobile robot data (ME). non-mobile robot data로 single-arm, two-arm을 다양한 가정 환경에서 수집한 데이터입니다.
- Cross-Embodiment laboratory data (CE). 실험실 환경에서의 wide range of tasks를 담긴 variety of robot types에 대한 데이터입니다. 해당 데이터는 OXE data를 포함합니다.
- High-Level subtask prediction (HL). high-level task commands에 대한 subtask를 예측하기 위한 데이터입니다. subtask를 만들 수 있는 MM, ME에 수동으로 annotation을 진행한 데이터입니다. 해당 데이터에는 관련된 객체에 대한 bbox를 포함합니다.
- Multi-modal Web Data (WD). 다양한 web data입니다.
image captioning (CapsFusion, COCO), question answering (Cambrian-7M, PixMo, VQAv2), Object localization (Object localization은 기존 데이터셋?에다가 가정 환경에 대한 bbox를 추가?)
모든 action data는 joint 혹은 ee pose로 예측이 가능합니다. 이를 구분하기 위해서 저자는 <control_mode> joint/end effector <control_mode>를 text prompt로 지정해줍니다. 또한, action data는 1%와 99%에 대한 quantile로 [-1, 1]로 개별 데이터에 따라 정규화합니다. 또한 모든 데이터 셋에서 가장 큰 action configuration 수를 action dimension으로 고정하고, 이보다 작은 경우는 zero-pad로 대응합니다.
+ discrete tokens으로 280k steps 수
Post-training
post-training에서는 적용하고자 하는 환경에 구체화 시키고 action expert를 활용하는 것을 목적으로 합니다. 허나, 해당 스테이지에서는 next-token prediction을 공동으로 학습을 수행합니다. 이는 text prediction 능력 저하를 방지함을 목적으로 합니다. 그리고 action expert는 random weight로 초기화합니다. 기본적인 최적화는 수식 1을 따르면 \alpha = 10.0으로 80k steps을 수행합니다.
post-training 액션 데이터셋은 MM 및 ME 로봇 데이터로 구성되며, 성공적인 에피소드 중 고정된 길이 임계값 미만인 것들로 필터링됩니다. 모델의 semantic and visual 능력을 예방하기 위해 WD 포함하며, 다중 환경에 대응하기 위해서 HL을 유지합니다. 또한, 적절한 high-level subtask를 예측하는 모델의 능력을 향상시키기 위해 verbal instruction demonstrations, VI를 수집합니다. VI는 전문가가 language demonstrations과 로봇에게 모바일 조작 작업을 단계별로 수행하도록 명령하는 적절한 서브태스크 명령을 선택하여 구성됩니다. 이러한 예시들은 학습된 low level policy로 작업을 수행하기 위해 언어를 사용하여 로봇을 실시간으로 “teleoperating”하여 수집되며, 이는 기본적으로 학습된 정책에 대한 좋은 high-level subtask 결과를 제공한다고 합니다.
+ 테스트 환경에서 수행해여 하는 subtask에 대한 예측 값을 주어준다고 생각하시면 됩니다.
Robot system details

해당 실험에서는 fig 5에 해당하는 두 종의 로봇을 활용합니다. 구성에 대해서는 fig 5의 캡션을 참고하시길 바랍니다.
+ camera는 두 팔 사이에 앞과 뒤를 비치는 카메라와 두 팔 손목에 탑재된 카메라 4대를 사용해 high-level inference에 활용, low-level inference에는 앞면과 두 팔의 카메라만 사용
Experiment
Can π0.5 generalize to real homes?
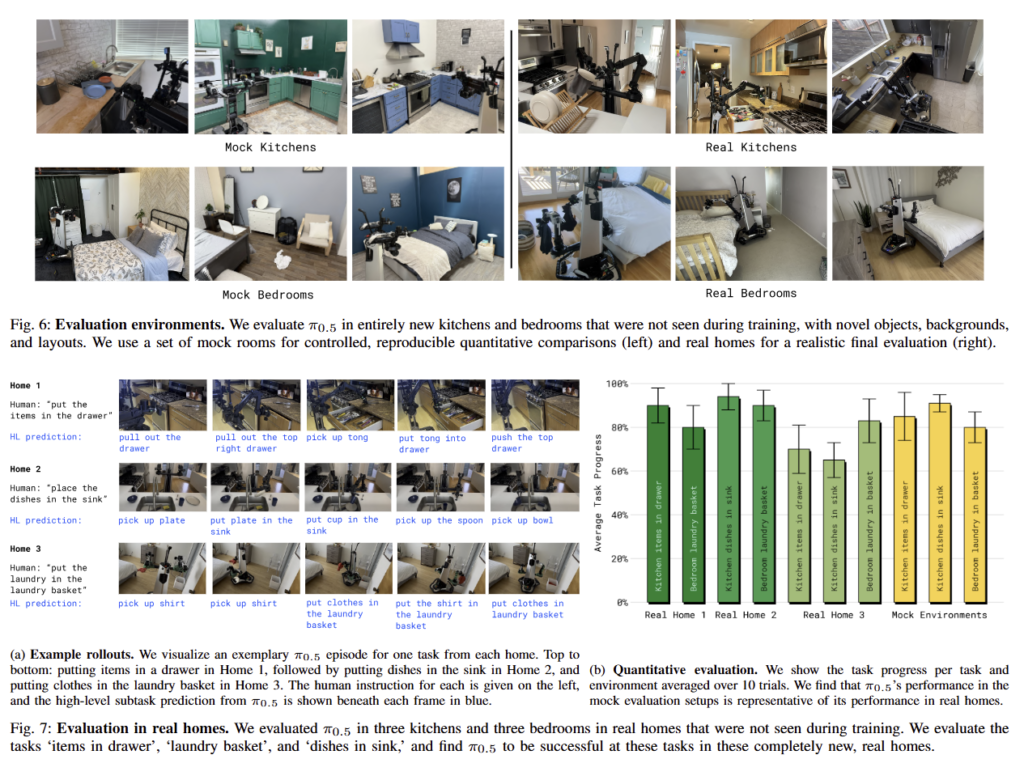
Fig 6과 같이 학습 데이터에서 보지 못한 환경에서 실험을 진행함. Fig 7-(a)와 같이 보지 못한 환경에서도 subtask를 적절하게 예측하는 결과를 보여줌. Fig 7-(b)에서도 다양한 태스크에서도 효과적인 결과를 보여줌. 이를 통해 π0.5는 새로운 환경에서 복잡한 다단계 태스크에서 일반화된 성능을 보임을 증명함
How does generalization scale with the number of scenes?
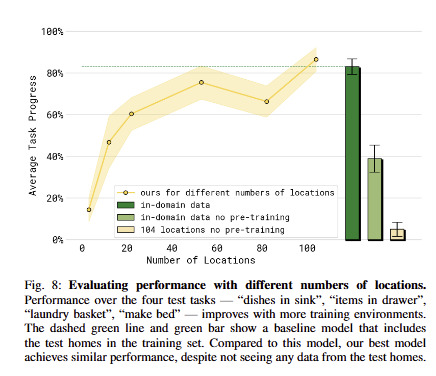
학습에 활용된 장소의 수에 따른 영향을 분석한 실험으로 3, 12, 22, 53, 82, 104 곳으로 학습 데이터를 구분 지어 모델을 평가를 수행함. fig 8에서 보이는 바와 같이 장소의 증가에 따라 성능이 향상되고 있음
in-domain data는 평가 장소를 학습에 활용한 결과인데도 불구하고 이에 준하거나 넘는 성능을 보여줌, 또한 pre-training 없이 해당 장소에서의 사전 학습으로 학습한 in-domain data no pre-training은 더 저조한 성능을 보여줌
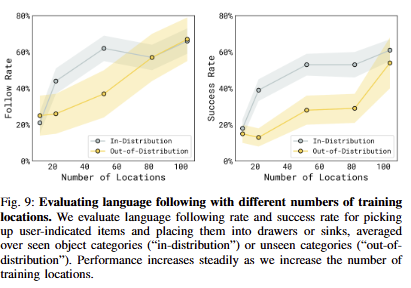
또한 fig 9에서는 ood 객체를 subtask prediction으로 발견한 정도인 follow rate와 작업 성공률을 success rate를 표시한 결과에 해당. OOD에 대해서도 장소가 증가함에 따라 성능이 향상됨을 보임
How important is each part of our co-training recipe?
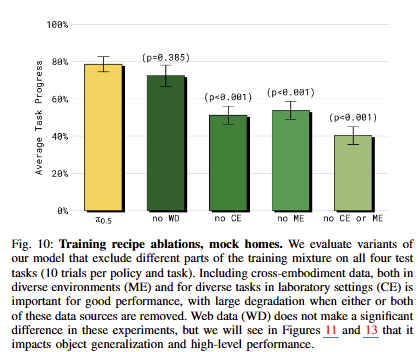
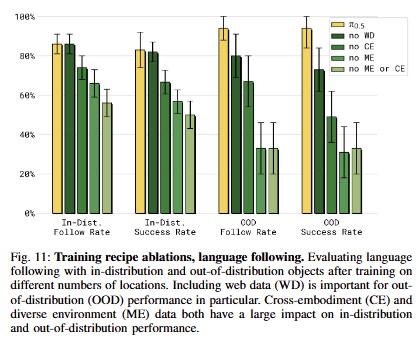
학습 데이터의 활용에 따른 ablation study. fig 10과 fig 11은 서로 동일한 양상을 보여줌. 직접적인 action이 없는 WD가 없는 경우에 성능이 하락되는 경우를 통해서 VLA에도 간접적인 지식이 action 추론에 충분한 도움을 줌을 보임
How does π0.5 compare to other VLAs?
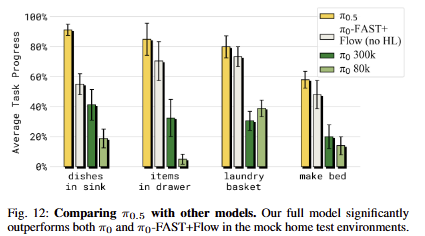
fig 12에서 VLA 기법 간의 비교를 수행함. 라젠다에서 흰색 부분이 흥미로운 결과를 보임. 해당 케이스는 HL만 제거한 경우(~action만 학습), 성능이 떨어짐을 통해 HL에 대한 지식 부여가 중요함을 보임
How important is high-level inference?
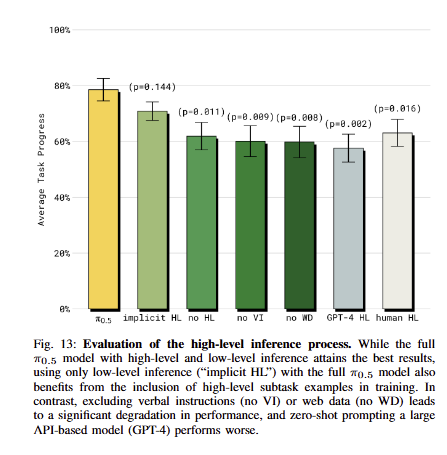
high-level inference process의 중요성을 실험한 fig 13의 실험으로 implicit HL은 예측한 subtask를 action expert에 직접 전달하지 않은 경우인데 두번째로 성능이 높은 점은 주목할만함. no HL은 이를 수행하지 않은 경우, no VI는 VI data를 제외한 케이스, no WD는 WD data를 제외, GPT-4 HL은 GPT 4를 활용해 HL를 예측한 경우, human HL은 전문가가 예측한 subtask를 직접 입력한 경우에 해당함. human HL과 GPT-4 HL에서도 더 좋은 성능을 보이고 implicit HL이 2 번재로 높은 성능을 보인 이유는 VLA이 subtask를 예측하는 end-to-end로 발전해야하는 필요성을 보이는 결과로 해석됨
Appendix에 디테일한 내용이 있어 관심이 있으신 분들은 논문을 참고하시면 좋을 것 같습니다. DISCUSSION AND FUTURE WORK에 좋은 내용이 많아서 관심 있으신 분들은 한번 읽고 고찰해보시면 어떨까 싶습니다.