안녕하세요, 63번째 x-review 입니다. 이번 논문은 4월 초에 arXiv에 올라온 따끈따끈한 논문으로, depth completion에 열화상을 처음으로 적용한 논문 입니다.
그럼 바로 리뷰 시작하겠습니다 !
1. Introduction
Depth Completion은 보통 RGB 이미지를 위해 잘 만들어진 데이터셋, 가령 KITTI DC나 NYUv2 등을 사용합니다. 그러나 이러한 데이터셋으로 학습하면 자율주행 씬에서의 모든 저조도, 악천후 환경에 대해 고려할 수 없게 됩니다. 이런 실제 일어날 수 있는 환경까지 고려한 depth completion을 위해서는 그런 상황에서도 강인하게 동작할 수 있는 다른 센서를 고려해봐야겠죠.
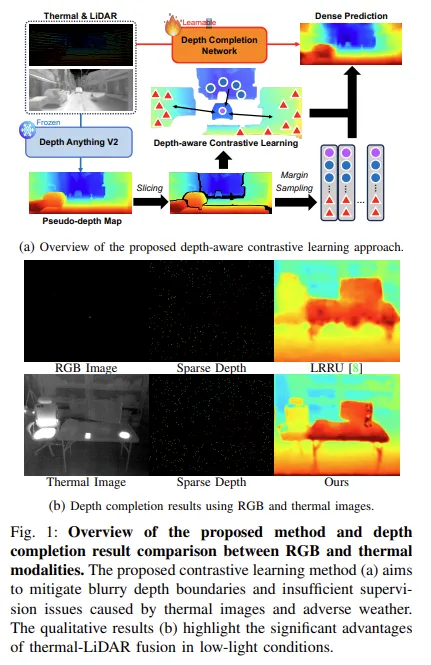
Fig.1(b)에서 보면, RGB 이미지는 장면 자체에 조명이 없으면 아예 어떤 정보도 담을 수 없는 반면, 열화상 카메라는 외부 조명의 유무에 관계없이 장면 구조를 일관되게 포함하고 있습니다. 따라서 열화상 기반의 depth completion은 일반적인 상황 외 이상 환경에서도 구조적인 디테일을 유지할 수 있을 거라고 가정하는 것이죠. 실제로 본 논문의 열화상에서의 depth completion 결과를 봐도 가정이 잘 맞았다는 걸 알 수 있죠.
사실 열화상이야 depth estimation이나 object detection 등에서는 이미 연구에 많이 활용하고 있는데, depth completion에서는 아직까지 이용되진 않았습니다. 그래서 본 논문에서는 MS2와 ViViD 데이터셋을 이용해서 열화상에 대해 기존 RGB 기반의 depth completion 방법론들을 처음으로 벤치마킹하였습니다. 특히 MS2 데이터셋은 낮, 밤, 그리고 비 등의 다양한 outdoor 장면에 대한 RGB/열화상 pair의 데이터를 제공합니다. 반대로 ViViD 데이터셋은 indoor 장면에 대한 RGB/열화상 데이터를 제공하며, 여기에는 다양한 조도 환경이 포함되어 있습니다.

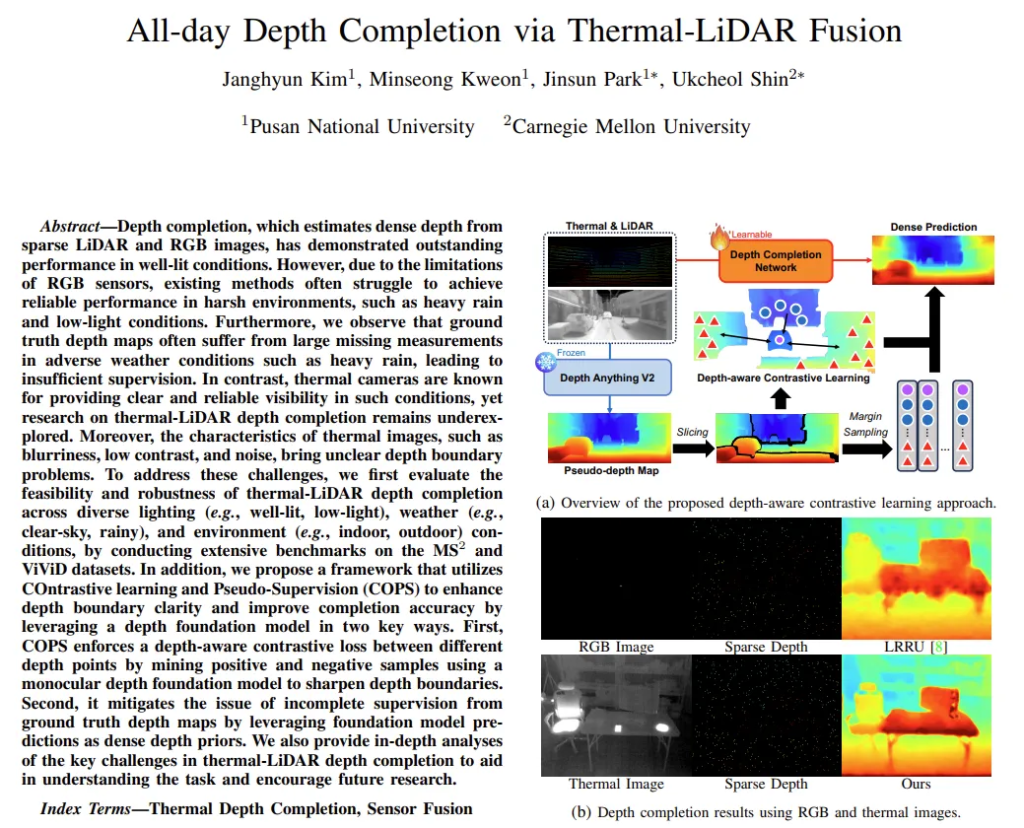
그러나 RGB를 열화상으로 바꿨다고 해서 단번에 문제가 해결되는 것은 아닙니다. depth completion에서 처음으로 사용하는 열화상 카메라로 이상환경에까지 강인하게 동작할 수 있도록 하기 위해서 COntrastive learning and Pseudo-Supervision(COPS)라는 프레임워크를 제안합니다. Fig.2를 보면, 저자는 열화상으로 depth completion을 하는데 두 가지를 고려해야 한다고 이야기 합니다. 먼저, 열화상 이미지에 대한 불분명한 depth 경계, 두번째는 이상 환경에서 LiDAR 센서의 한계로 인해 발생하는 누락되는 GT 영역 문제 입니다.
이를 해결하기 위해 먼저 Fig.1(a)인 depth-aware contrastive learning 입니다. 이는 서로 다른 depth 포인트 사이에 contrastive learning을 적용해서 depth foundation model을 통해 생성한 선명한 depth 경계를 목표하는 depth completion으로 끌고오는 것을 목표로 합니다.
두번째는 pseudo depth인데요, FM에서 뽑은 depth map을 GT 영역에서 누락된 부분을 보정하는 pseudo 클래스로 사용한다고 합니다. 이렇게 되면 COPS는 선명한 depth 경계를 가지고 이상환경에서 불완전한 GT 영역의 문제까지 보완하여 depth completion의 성능을 크게 향상시킬 수 있습니다.
여기서 본 논문의 main contribution을 정리하면 다음과 같습니다.
- 실제 여러 환경을 고려한 데이터셋에서 열화상에 대한 표준화된 벤치마크를 위해 depth completion 알고리즘을 처음으로 평가
- depth aware contrastive learning과 pseudo 클래스를 통해 모호한 경계와 누락된 GT를 보완하여 새로운 COPS 프레임워크 제안
- 열화상-라이다 depth completion에서 나타나는 문제와 앞으로의 연구에 대한 분석 제공
2. Method
2.1. Overall Framework
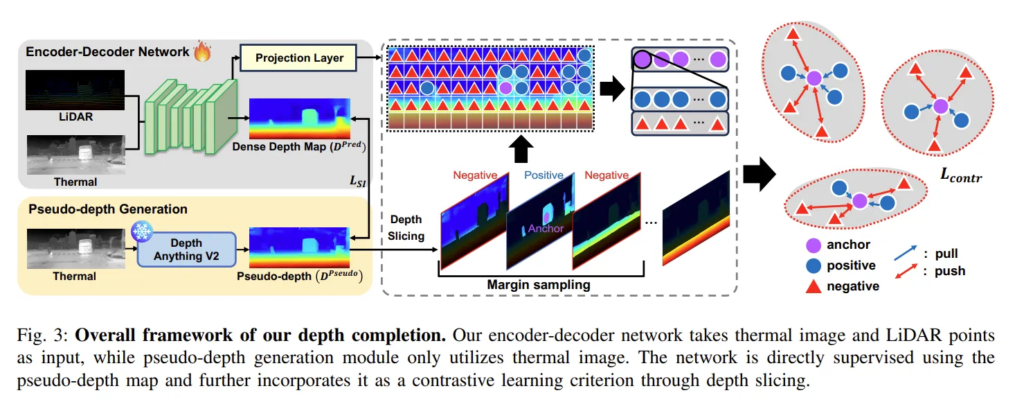
Fig.3은 본 논문의 전체적인 프레임워크를 보여주고 있습니다. 해당 프레임워크는 기존의 여러 depth completion 네트워크에서 원활하게 추가하여 사용할 수 있도록 설계되었다고 합니다. 크게 3가지 모듈로 나뉘는데요, 먼저 (1) Depth Completion Network 입니다.
간단하게 인코더-디코더 네트워크를 사용하는 기존의 depth completion 방식들에 따라 GT를 가지고 열화상 이미지에서 dense한 depth map을 생성합니다. 이 구조는 조금 이따 나올 pseudo depth map을 활용해서 기존의 구조를 유지할 수 있도록 설계되었습니다.
(2) pseudo depth generation은 pseudo depth라는건 이제 monocular depth foundation model에서 나오는 결과를 의미합니다. 저자는 metric depth를 추정할 수 있는 Depth Anything v2를 FM으로 사용해서 pseudo depth를 삼았다고 하네요.
(3) COPS는 feature의 표현력을 향상시켜서 열화상 영상에 대한 선명한 depth 경계를 표현합니다. 구체적으로, 만들어진 depth map을 슬라이스하여 각 depth 범위에 인덱스, 이걸 클래스라고 하는데요, 클래스를 할당 합니다. 기준이 되는 앵커 픽셀을 정해서, 주변 픽셀과 depth 차이를 계산하여 차이가 1 이하인 경우에는 positive 샘플로 간주합니다. 반면 클래스 차이가 1이상이면서 최대 마진 이하인 경우에는 negative 샘플로 여깁니다. 이 범위 안에 드는 negative 샘플은 헷갈리기 쉬운 depth 값을 가진 픽셀이라고 할 수 있죠. 이렇게 샘플링한 positive/negative 샘플을 기반으로 contrastive loss를 계산해서 유사한 depth class끼리 가까이, 다른 class끼리 멀리 떨어지도록 학습합니다.
2.2. Depth Completion Network
이제 각 모듈에 대해 더 자세하게 살펴보도록 하겠습니다.
대부분의 depth completion 알고리즘은 인코더-디코더 구조를 가지는데요, 입력으로 sparse depth map과 이미지가 들어가면 출력으로 dense한 depth map이 나오죠.
보통의 RGB 이미지 대신 열화상 영상을 사용하려면 추가적인 처리 방식이 필요합니다. 우선 RGB 이미지는 3채널이지만 열화상 이미지는 단일 채널로 구성되어 있어서 열화상 이미지를 원래 RGB 기반 구조에 그대로 사용할 수가 없습니다. 그래서 간단하게, 열화상 이미지를 3채널로 그대로 복제하여 기존 RGB 네트워크를 수정하지 않고 사용할 수 있도록 합니다.
그 다음에는 Spatial Propagation Network(SPN)의 포함 여부에 따라 처리 방식이 달라지는데, 먼저 SPN이란 depth 정보를 이용해서 depth를 refinement하는 모듈을 의미합니다. 즉, 디코더를 타고 나온 depth map을 추가로 개선하는 네트워크인데, SPN이 있으면 이 때 guidance feature(이미지의 엣지나 구조적인 정보)를 활용해서 affinity와 offset을 학습합니다. 만약에 없다면 그저 단순히 디코더의 출력값을 바로 예측 depth map으로 간주합니다.
2.3. Depth-aware Contrastive Learning
(1) Pseudo-class Generation
논문에서 하고자 하는 contrastive learning을 하려면 각 픽셀에 대해서 클래스 정보를 할당해야 하는데요, depth completion은 특정 클래스를 다루지 않기 때문에 명확한 클래스 정보가 있지 않습니다. 이를 위해 저자들은 FM으로 뽑은 pseudo depth map을 활용해서 각 픽셀을 depth 기반으로 구간을 나누어서 pseudo 클래스를 할당하였습니다.
Depth 범위의 구간은 먼저 전체 depth 범위 [d_{min}, d_{max}]를 M개의 구간으로 나눕니다. 최소 depth는 0, 최대 depth는 pseudo depth에서 가장 큰 값으로 설정합니다. 각 구간의 차이는 0.5m로 고정하는데요, 예를 들어보면 최소 depth를 10이라고 했을 때 (최대 depth(10) – 최소 depth(0)) / 구간 차이(0.5m)로 계산하여 depth 구간을 20개로 나누게 됩니다. 이렇게 나눈 구간에서 만약에 pseudo depth 값 중 하나가 1.3m라고 하면 이 픽셀은 20개의 구간 중에서 2번 구간에 속하여 pseudo class를 2로 할당하는 것 입니다.
(2) Margin Sampling
이번엔 이렇게 pseudo class를 할당한 상태에서 어떤 픽셀을 positive, negative로 정할지 샘플링하는 과정 입니다.
우선 비교를 위한 기준이 되는 픽셀인 쿼리 픽셀 q를 정의하며, 쿼리 픽셀이 속해있는 pseudo 클래스는 y_q 입니다. 식(2), (3)은 각각 positive/negative 샘플 집합을 정의한 것 입니다.
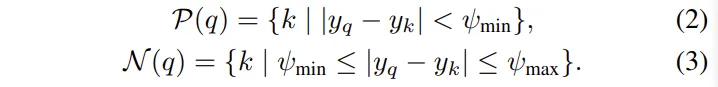
식(2)를 먼저 보면, 같은 클래스에 속한 픽셀들만 선택하는데, 논문에서는 \psi_{min}을 1로 설정했기 때문에 같은 구간에 속한 픽셀들만 positive로 설정합니다. 그 다음 식(3)의 negative 샘플 집합은 조금 다른 클래스 구간에 속한 픽셀들인데요, 완전히 다른 depth가 아니라 약간 다른, 즉 헷갈리기 쉬운 depth 구간에 속함을 의미합니다. 이 조금 다른 클래스 구간이라는 걸 중요하다고 이야기하는데, 너무 멀면 학습 효과가 적고 너무 가까우면 구분이 안되기 때문에 그 적당한 차이가 필요하다는 것이죠.
보통의 contrastive learning은 완전히 다른 negative 샘플을 사용하곤 하는데, depth를 학습할 때는 그런 너무 다른 negative는 오히려 별로 도움이 되지 않는다고 합니다. 오히려 비슷한 depth지만 촘촘하게 나눈 구간에서 다른 클래스인 샘플을 골라야 선명한 경계를 학습하는데 효과적이라고 하네요. 이를 통해 모델이 정확한 depth 픽셀 사이의 경계를 구분할 수 있도록 할 수 있습니다.
(3) Contrastive Learning Loss
우선 depth completion 네트워크에서 마지막 디코더 layer에서 feature f를 추출합니다. 그 다음 1×1 projection layer을 사용해서 임베딩 차원을 줄이거나 정규화를 시키는데, 이 feature가 contrastive learning에 쓰이는 벡터 입니다.
이제 픽셀 간의 feature 유사도를 계산해야 하는데요, s(q,k)=f_q \cdot f_k^T와 같이 내적을 이용합니다. 여기서 f_q는 기준 픽셀 q의 feature 벡터이고 f_k는 비교 대상인 픽셀 k의 feature 벡터를 의미합니다. 이 내적 결과는 결국 q와 k가 feature 공간에서 얼마나 유사한지를 나타내게 되겠죠. 이걸 모든 픽셀 쌍에 대해 계산하면 self-similarity matrix를 만들 수가 있습니다. 이렇게 구한 유사도를 가지고 contrastive loss를 계산하는 것이죠.
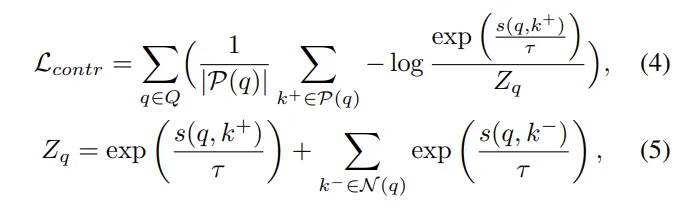
- Q : 쿼리 픽셀 집합
- P(q) : q의 positive 샘플들 (같은 pseudo depth 클래스)
- s(q, k^+) : positive 샘플과의 유사도
식(4)의 contrastive loss는 positive 쌍이 다른 쌍들보다 유사도가 높도록 학습시키는 softmax 기반의 loss 입니다. 여기서 중요한 건 어떤 픽셍를 positive, negative로 선택할지이겠죠. 이는 이미 식(2),(3)을 통해 정의한대로 샘플링한 픽셀을 사용합니다. 이렇게 헷갈릴 수 있는 애매한 negaitve들을 negative 샘플로 사용함으로써 헷갈리는 값들을 구분할 수 있는 능력을 depth 예측의 정확도를 높이는데 활용하고자 합니다. 여기서 식을 보시면 아시다시피 GT가 있는 픽셀은 사용하지 않고 아예 제외합니다. 이에 대해서 저자는 이미 supervised learning으로 이미 잘 학습되어 있고, 오히려 pseudo depth 기반의 contrastive learning이 효과적인 영역은 라벨이 없는 영역이기 때문에 GT가 없는 픽셀들에 집중해서 self supervised 표현력을 학습하기 위함이라고 합니다.
2.4. Pseudo-depth Supervision
pseudo depth의 목적은 실제 GT 역시도 sparse하기 때문에 대부분의 픽셀에 정답 depth가 없다는 걸 해결하는 것 입니다. 그래서 논문에서는 Depth Anything v2를 사용해서 pseudo depth map을 얻지만 이것 여기도 실제 GT가 아니기 때문에 좀 더 고려해야할 부분들이 생깁니다.
그래서 식(6)과 같이 scale invariant loss로 학습을 합니다. Depth anything v2가 metric depth를 예측하지만 그 값이 GT와 스케일의 범위가 다를 수 있습니다. 그래서 절대적인 값의 차이보다는 예측하는 상대적인 depth 구조에 집중할 수 있도록 scale invariant loss를 사용합니다.
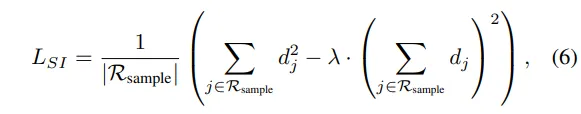
- d_j = logD^{Pseudo}_j - logD^{Pred}_j : pseudo depth와 예측 depth 사이의 log 차이
- R_{sample} : 전체 픽셀 중 일부만 샘플링한 픽셀 집합
여기서 d_j가 log 계산을 하는 이유는 depth의 비율을 보기 위함이고, 이것이 scale invariance를 고려하기 위한 구조라고 볼 수 있습니다. 그리고 일부 샘플링한 픽셀 집합을 사용한다고 했는데 이는 랜덤 샘플링 입니다. 왜 랜덤 샘플링을 쓰냐하면 우선은 계산 효율성인데요, 모든 픽셀에 대해 loss를 계산해서 연산량이 커지게 됩니다. 또 하나는 데이터의 bias를 방지하기 위함인데, sparse depth는 전체 장면 중에서 depth가 채워져 있는 영역이 한 쪽에 몰려있는 경우가 많습니다. 그걸 그대로 학습하면 특정 영역에 대해서만 잘 찾아내도록 최적화된 모델이 될 수 있기 때문에, 이를 방지하기 위해 이미지 전체에서 랜덤하게 픽셀을 뽑아서 학습하였다고 합니다. 이를 통해 전체 depth 영역에 대해 balance 있는 학습과 일반화를 갖춘 depth 예측이 가능하도록 하였습니다.
2.5. Loss Functions
(1) Depth Completion Loss
이제 전체적인 학습 loss를 볼건데, 우선 여러 depth completion 알고리즘들과 공정하게 비교하기 위해 기본적인 loss 함수를 동일하게 설정하였다고 합니다. 식(7)이 이러한 세팅을 위한 기본적인 loss 함수 L_{base}를 의미합니다.
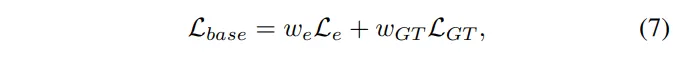
L_e는 식(8)과 같이 정의한 smooth edge loss 입니다.
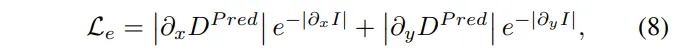
- D^{pred} : 예측한 depth map
- I : 해당하는 위치의 intensity 이미지 (열화상 이미지에서의 밝기 정보)
- \partial_x, \partial_y : x,y 축 방향의 미분으로, 이미지에서의 gradient 의미
smooth edge loss는 본 논문 말고도 depth estimation 논문과 같이 depth를 다루는 논문들에서 거의 필수록 들어가는 loss 입니다. 이미지에서 엣지 영역은 depth가 갑자기 바뀌는 부분인데, 일반적인 smooth loss는 모든 곳에서 depth 표현이 부드러워지도록 학습되기 때문에 표현되어야 하는 경계까지 smooth하게 표현합니다. 그래서 이미지에서 강하게 edge로 표현되어야 하는, 즉 gradient가 큰 부분은 depth를 부드럽게 표현하지 않도록 하고, 반대로 edge가 아닌 영역은 기존과 동일하게 smooth한 표현이 되도록 유도합니다.
다음은 식(9),(10)에 따른 smooth L1 loss 기반 L_{GT} 입니다.
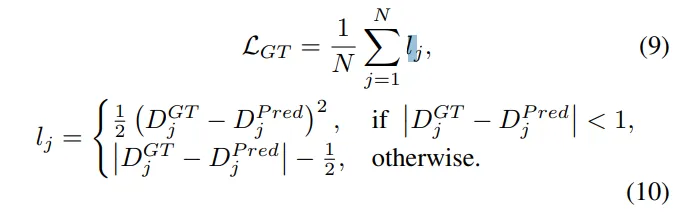
이는 GT와 예측값 사이의 오차를 줄이기 위함인데, 단순히 L2 loss를 쓰면 큰 오차가 있을 때 학습이 불안정할 수 있어서 outlier에 덜 민감하도록 설계하였습니다.
(2) Contrastive and Pseudo-supervised Loss
기본적인 베이스 loss에 이어, 논문에서 제안하는 contrastive loss와 pseudo depth를 위한 loss 입니다.
본 논문은 depth completion을 위해 두 가지 학습 방식을 사용하는데, 앞서 설명한대로 scale invariant loss와 contrastive loss가 있죠. 먼저 scale invariant loss는 이미지 전체에서 전반적으로 depth 구조를 잘 파악하도록 하고, contrastive loss는 더 지역적인 디테일을 표현할 수 있도록 합니다. 그러나 이 두 loss를 동시에 강하게 적용하면 학습 신호가 충돌할 수 있습니다. 한 쪽에서는 전체 구조를 부드럽게 이어서 표현하려고 하고, 다른 한 쪽에서는 명확하게 구분하려 하기 때문에 충돌할 수 있다는 의미 입니다. 그래서 저자는 이 두 loss를 적용하는 시점을 분리하여 적용하는데, 이를 식(11)과 같이 stage learning 전략이라고 표현 합니다.
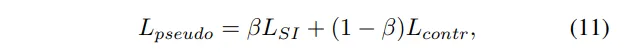
\beta = 1\{t \leq T/2\}가 사용하는 시점을 나누는 기준 입니다.
T는 전체 학습 에포크이고, t는 현재 에포크로, 현재 에포크가 학습 초반이라면 scale invariant loss를 사용하고 학습 후반 에포크라면 contrastive loss로 학습하도록 설정하였습니다. 즉, 초반에는 장면에 대해 전체적인 구조와 일관성을 학습하도록 하고, 후반으로 갈수록 각 영역마다의 디테일한 depth 구조를 표현할 수 있도록 합니다. 이렇게 서로 다른 장점을 가진 loss를 서로 충돌하지 않도록 단계별로 분리하여 학습을 진행하였습니다.
3. Experimental Results
데이터셋은 열화상이 포함된 데이터셋으로, outdoor는 MS2, indoor는 ViViD 데이터셋을 사용하였습니다.
3.1. MS2 Dataset
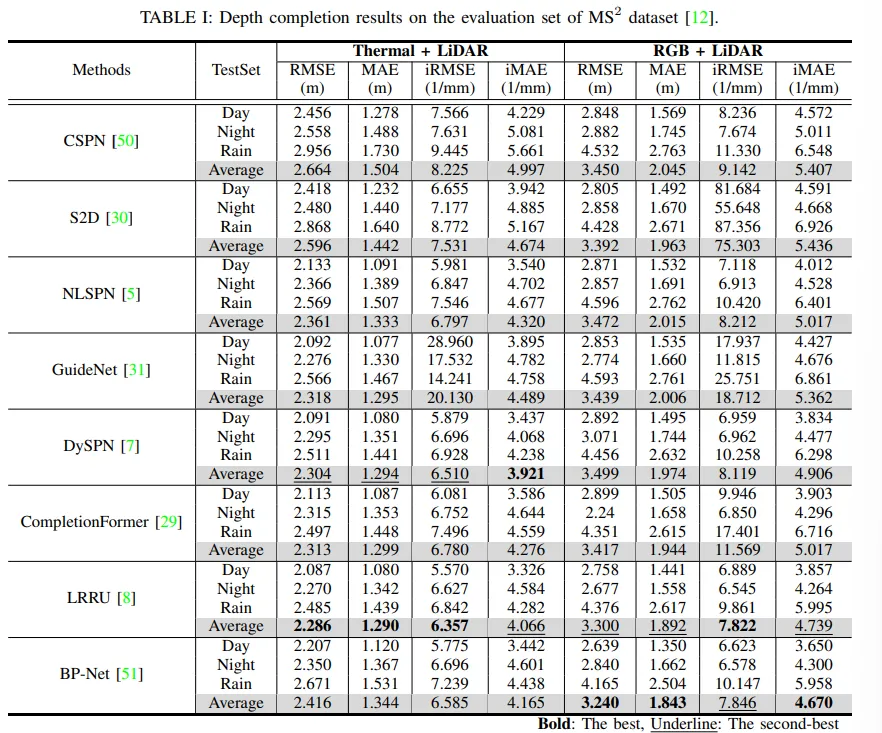

먼저 MS2 데이터셋에 대한 실험 결과 입니다.
RGB와 열화상을 각각 사용하여 depth completion을 진행하였을 때 이상 환경에서 명확하게 차이가 보이는 것을 알수 있습니다. RGB 기반은 day 환경에서는 확실히 좋은 성능을 보이지만 저조도나 악천후로 갔을 때 성능이 크게 저하됩니다. 반면, 열화상 기반으로 depth completion을 했을 때는 다양한 환경에서 RGB 대비 일관되게 안정적인 성능을 보이며 열화상 특유의 특성을 통해 환경에 강인한 결과를 내는 것을 확인할 수 있습니다.
Fig.4는 이에 대한 정성적인 결과로, Night scene에서 RGB를 사용한 depth completion은 차량이 움직이는 순간의 이미지나 조명의 변화에 따른 노이즈에 영향을 많이 받습니다. 반면에, 열화상 카메라는 그러한 외부 조명이나 시간대에 크게 영향을 받지 않고 depth map을 예측함으로써 발생하는 노이즈에 강인하게 작동하는 것을 알 수 있습니다.
BPNet은 RGB 기반 depth completion에서 SOTA 모델이지만, 열화상으로 이미지를 변경했을 때 비교적 낮은 성능을 보입니다. 이에 대해서 저자는 BPNet의 전처리 단계가 RGB 이미지에 맞추어져 있기 때문이라고 합니다. 여기서 드는 의문은 열화상 이미지에 맞게 이미지 전처리를 통일하여 처리했으면 어떤 결과였을지 생각도 듭니다만 .. 본 논문에서는 기존 논문의 과정을 그대로 따른 것으로 보입니다.
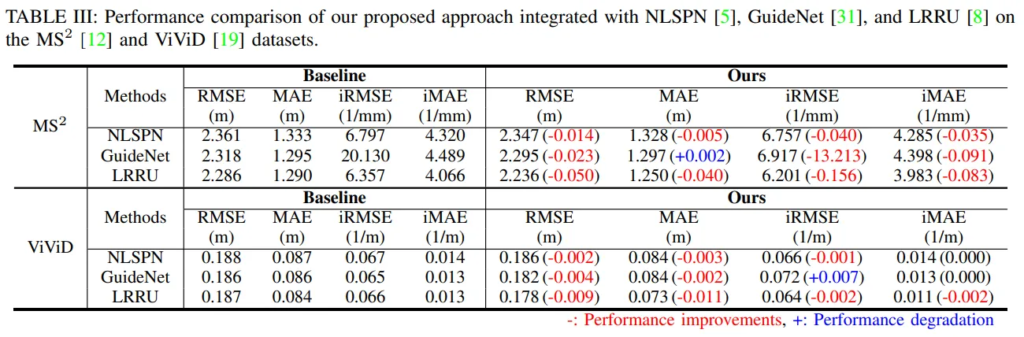
Tab.3은 depth FM을 사용한 본 논문의 supervision 방식으로, inference 중에 추가적인 과정이 없을 때 실험 결과를 보여줍니다. 이렇게 FM을 활용했을 때 모든 방법론에서 일관되게 좋은 성능을 보이는데, 다만 GuideNet에서 MAE가 약간의 성능 저하가 발생하지만, 유독 성능이 낮았던 iRMSE가 안정된 6.917로 나오면서 다른 depth completion 방법론들과 비교할 수 있을 정도로 개선된 것을 확인할 수 있습니다. 이를 통해 사전학습된 depth FM의 depth map을 활용하는 것의 효과를 보여주고 있습니다.
ViViD 데이터셋에서도 역시나 열화상으로 학습하였을 때 depth completion을 위한 추가적인 정보를 제공함으로써 성능이 향상되는 것을 확인할 수 있습니다. 비교적 성능 향상이 크지 않아 보일 수도 있지만, 저자는 이에 대해 이러한 개선이 inference 시에 추가적인 cost 없이 나올 수 있는 결과이기 때문에 더욱 효율적이라고 분석하고 있습니다.
3.2. ViViD Dataset
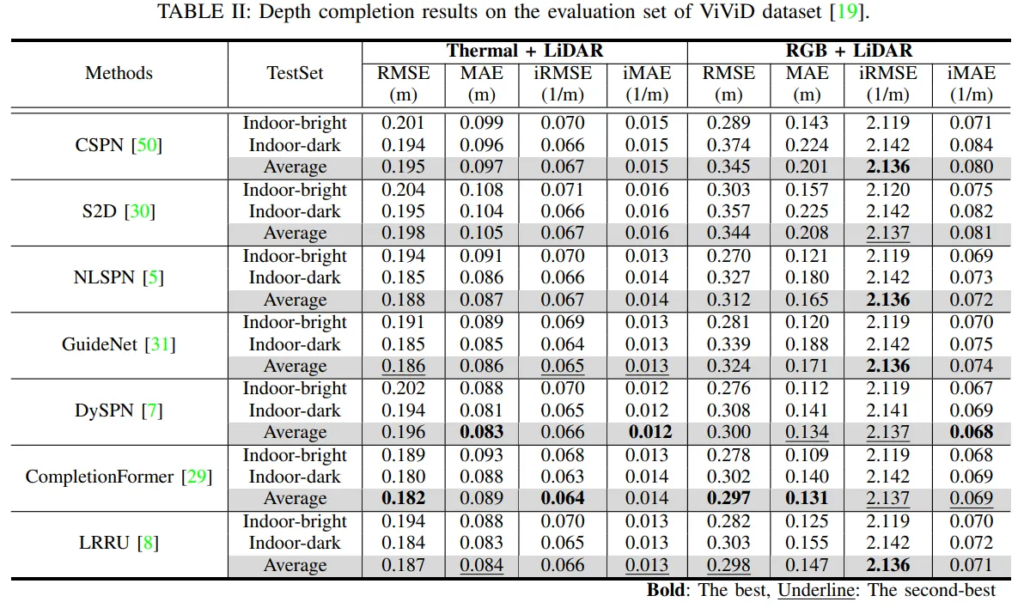

다음 Tab.2는 ViViD 데이터셋에서의 depth completion 실험 결과로, indoor에서의 열화상 이미지 필요성을 보여주고 있습니다.
ViViD 데이터셋이 가시성이 매우 떨어지기 때문에, RGB로 depth 예측을 하는데 굉장이 어려운 데이터셋이라고 합니다. 그래서 모든 depth completion 결과가 열화상과 차이가 많이 나는 것이 보이는데요, 열화상 이미지는 실내에서 밝을 때와 저조도일 때 모든 방법론이 RMSE에서 0.01 정도 차이로, 거의 변화가 없이 유지되는 것을 확인할 수 있습니다. 이를 통해 RGB가 저조도 실내 환경에 크게 영향을 받아 학습이 불안정해져서 성능이 저하되는 것을 보여주며, 열화상 영상의 필요성을 어필하고 있습니다. Fig.7은 정성적인결과로, 한번 더 열화상 이미지의 장점을 강조하고 있습니다. 열화상 영상은 테이블의 다리와 같이 RGB에서 놓치기 쉬운 디테일까지 효과적으로 표현하고 있으며, 저조도의 RGB는 전혀 보이지 않는 반면 열화상은 명확하게 구조를 인식할 수 있어서 depth를 더 정확하게 예측하고 있죠.
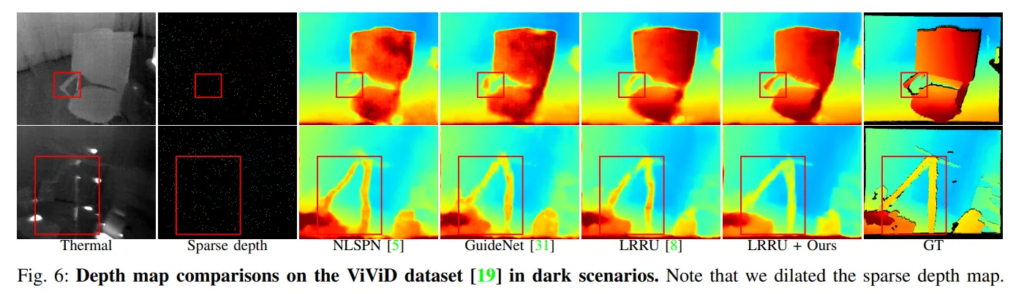
또한 Fig.6에서 볼 수 있듯이, 가시성이 저하된 실내 환경에서 작은 물체에 대한 depth 표현력에서의 효과도 확인할 수 있습니다. 빨간색 박스로 표시된 영역은 디테일한 표현에 있어서 본 논문의 효과를 보여주고 있는데, GT에서조차도 누락된 영역을 직접 pseudo depth로 사용하여 표현할 수 있게 되었습니다. 이를 통해 작은 물체나 영역에 대한 예측 오차를 줄이고 물체가 아닌 영역을 가까운 영역이라고 잘못 표현하는 것을 방지하여 저조도 환경에서도 신뢰할 수 있을 만한 depth completion을 하는데 도움을 주고 있습니다.
3.3. Ablation Study
(1) Depth-aware Contrastive Learning
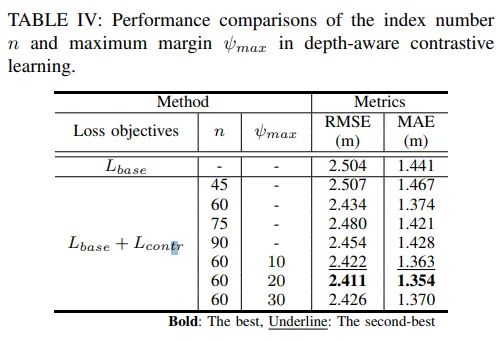
이제 ablation study로, 먼저 depth aware contrastive learning의 효과를 평가하기 위한 실험 입니다. pseudo depth의 슬라이싱하는 인덱스 수와 마진 샘플링 수를 조절하여 평가하였다고 합니다.
먼저 샘플링 수 n을 45로 설정하면, 해당 모델은 base loss에 비해 개선되지 않는데, 이는 충분하지 않은 샘플링은 특징을 효과적으로 분리하지 못해서 효과를 볼 수 없게 됩니다. 여러 샘플링 수에 대한 실험을 통해 n=60이 가장 최적의 샘플링 수라는 걸 찾았으며 이 때 RMSE와 MAE에서 각각 2.8%와 4.7%의 성능 개선이 가능함을 알 수 있습니다.
이제 n은 60으로 고정하고 최적의 negative 마진 범위를 찾도록 실험을 진행하였습니다. 10, 20, 30 모든 테스트한 범위에서 negative 마진이 없는 것보다 성능이 향상되는 것을 볼 수 있습니다. 그 중에서도 20이 가장 적합한 범위로 보여지는데, 이 세팅이 계산적인 효율성을 유지하면서도 표현력을 높이면서 두 평가 메트릭에서도 성능 향상이 가장 크게 나타나는 것을 알 수 있습니다. 마진 범위를 세팅하는 것부터 contrastive learning에 효과적이라는 걸 보여주면서도 그 중에서도 가장 최적의 마진 범위를 찾았다고 볼 수 있습니다.
(2) Effectiveness of the Proposed Framework
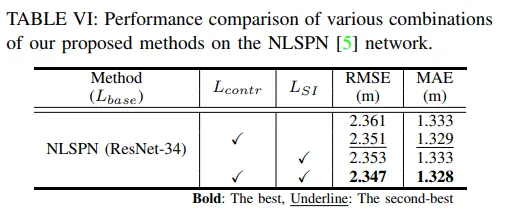
마지막은 본 논문이 제안한 scale invariant loss와 contrastive loss에 대한 평가를 진행하였습니다. 둘 다 MS2 데이터셋 기준으로 적용 여부에 따라 점차적으로 성능이 향상되는 것을 알 수 있습니다.
각각을 사용해도 성능이 향상되지만 두 loss를 모두 사용했을 때 가장 좋은 성능을 보이는데, 이에 대해 저자는 loss들 자체적으로도 도움이 되면서도 단계별 학습 방식이 크게 기여했다고 이야기 합니다. 다른 특성을 가진 loss를 동시에 사용하면 서로 충돌이 발생하여 성능이 저하됐을 수도 있지만, 단계별로 에포크에 맞춰 loss를 다른 시점에 적용하였기 때문에 각 장점을 해치지 않으면서 효과적인 학습이 가능해졌다는 것이죠.
열화상 영상을 이용해서 depth completion을 평가할 수 있는 데이터셋이 많지 않은 상황에서 한 데이터셋에 대해 많은 분석과 실험을 진행했다는 느낌을 받았습니다. 또한 제안하는 방법론 자체는 크게 새롭지 않았다 하더라도 task 자체가 depth completion에서 열화상을 처음 사용함을 강조하면서, 참고할 만한 논문이 거의 없었던 제가 앞으로 많이 도움받을 수 있는 논문이 나온 것 같다고 생각합니다.
건화님 좋은 리뷰 감사합니다.
열화상이 depth completion에 이제서야 처음으로 적용된 이유가 궁금합니다. 기존에는 어떤 어려움이 있어 열화상을 depth completion에 적용하지 못하였는지 간략하게 설명해주실 수 있을까요?
또한, scale invariant loss와 scale invariant loss 가 둘다 강하게 적용될 경우 신호가 충돌날 수 있어 stage learning 전략을 통해 두 loss를 서로 다른 시기에 적용하였다고 하셨는데, 이를 거꾸로 적용한 실험이나 그 비율을 조정하는 실험은 따로 없었는지 궁금합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
depth completion에 열화상이 이제서야 처음으로 적용된 이유는 .. 사실 저도 정확하게는 모르겠습니다. 본 논문에서도 어떤 어려움 때문에 depth completion에 열화상을 활용하지 못했다고는 언급되어 있지 않고도 하고요.
다만 제 생각에는 sparse하여 정보가 굉장히 부족한 depth를 가지고 dense depth를 만들어야 하는데, 이에 추가적인 정보로 원래 RGB 이미지를 사용했었던 것을 일반적인 정상 상황에서 굳이 RGB보다 텍스처나 의미론적인 정보가 부족한 열화상으로 대체할 이유를 찾지 못했던게 아닌가 싶습니다.
그리고 말씀하신 두 loss에 대해서는 거꾸로 적용하거나 비율을 조정한 ablation study는 따로 없었습니다.
감사합니다.
안녕하세요 건화님 리뷰 감사합니다.
pseudo depth supervision에서 log 차이를 이용한 scale-invariant loss를 사용하는 이유가 monocular depth estimation 결과와 GT 간의 스케일 mismatch를 해결하기 위함이라고 이해했는데, 전체 픽셀에 대해 정규화된 depth 값을 사용한 loss 대신 log식을 쓴게 다른 학습적 이점이 있는지, 샘플링 뿐만 아니라 log식 자체가 계산에 이점이 있어서 그런건지 궁금합니다!!
안녕하세요, 리뷰 읽어주셔서 감사합니다.
log식을 사용하는 이유는 리뷰에서도 말씀드린 대로 depth의 비율을 비교함으로써 scale invariance를 고려하기 위함입니다. Depth Anything v2의 metric depth와 GT의 metric depth는 모두 똑같이 metric 단위인데, 여기서는 이제부터 절대적인 값보다는 상대값에 집중하고자 한 것이죠. 계산 효율이나 이런 점에 있어서 log식 자체가 이점이 있는가는 저도 확신할 수는 없습니다만, 저자가 달성하고자 한 목적을 위해서는 확실하게 log식으로 비율 연산을 하는게 맞다고 생각합니다.
감사합니다.