안녕하세요, 쉰 여덟번째 X-Review입니다. 이번 논문은 2024년도 WACV에 올라온 Hierarchical Text Spotter for Joint Text Spotting and Layout Analysis논문입니다. 바로 시작하도록 하겠습니다. ?
1. Introduction
기존의 text spotting은 text를 검출하고 인식하는 것까지만 다루었고, 영상 내의 text가 어떻게 배치되어 있는지 즉, geometric layout까지 파악하는 것은 document image에 대해서만 적용이 되었고 scene image에서는 다뤄지지 않았습니다. 다시 말해 문서 이미지에서는 text block들을 따로 구분하는 task같은게 있었지만 spotting에서 주로 다루는 scene image에서는 텍스트의 배치까지는 신경쓰지 않았던 것이죠. 구체적으로, 기존 spotting 방법들은 보통 word-level로 text를 detection하고 recognition해오는 방식을 고수해왔는데, 단어 별로 구분하는 것은 단순하고 직관적인 접근이긴 하지만, 문장 전체나 단락처럼 더 넓은 구조적인 정보를 활용하는 데는 한계가 있습니다. 본 논문의 저자들은 여기서 text spotting과 layout 분석을 따로따로 할 게 아니라, 둘을 하나로 통합해 처리하면 서로를 보완할 것이라는 점을 주장합니다.
하지만, word-level이외의 구분 방식으로 접근한 연구가 처음은 아닌데요. Unified Detector라고 해서 text를 line-level로 detection하거나 서로 관련있는 text line을 묶어 문단으로 묶는 것까지 수행하는 모델이 존재합니다. 하지만, 이 Unified Detector는 오직 detection만 가능하고 recognition은 수행하지 않는 모델이기에 text가 존재하는 위치까지는 알려주지만 그 text가 정확히 어떤 글자인지, 혹은 character다 word 단위로 다시 분리해주는 기능까지는 없다고 볼 수 있죠.
따라서 본 논문에서는 이런 문제를 해결하기 위한 Hierarchical Text Spotter(이하 HTS)라고 하는 모델을 제안합니다. 이 HTS는 단순 text detection에만 그치는 것이 아닌, localize하고 recognize하고 더 나아가 text들 사이의 기하학적인 관계까지 복원하도록 설계되어ㅆ습니다.
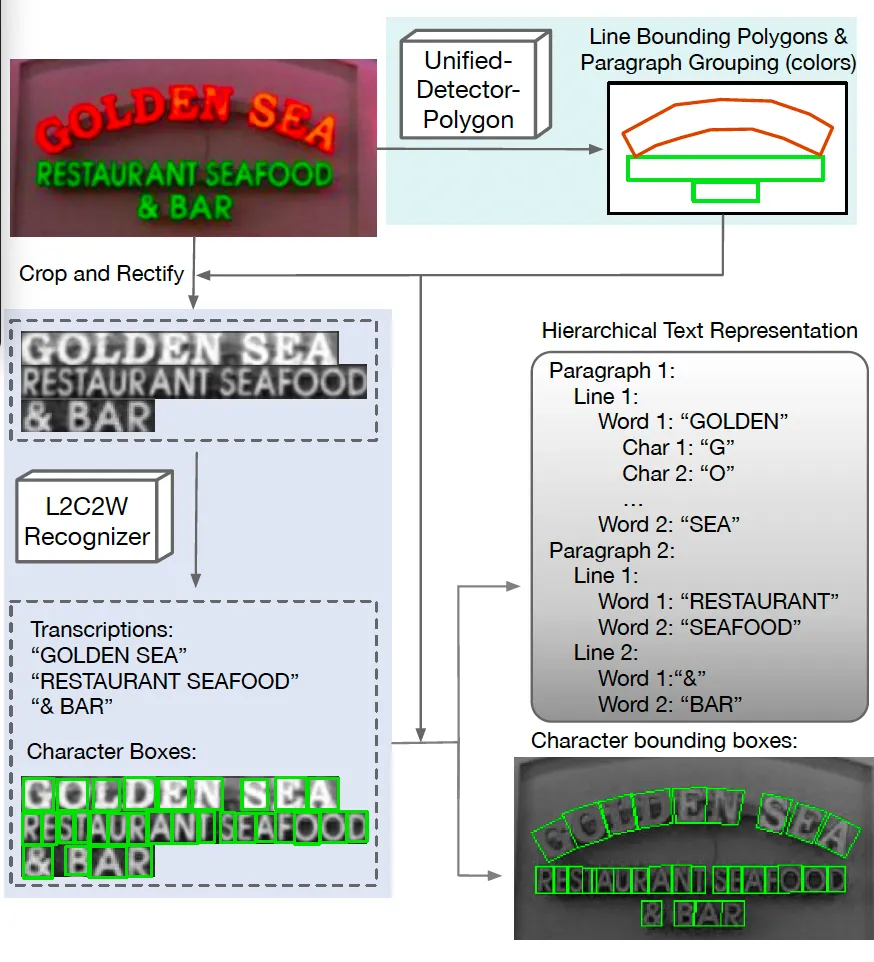
위 FIg1에 제안된 HTS의 전체적인 구조가 그려져 있습니다. 보시면, HTS는 Hieracrchical Text representation이라는 이름처럼 영상 내에 존재하는 text들을 다단계로 구조화해서 나타내고 있으며, 총 4단계로 나눠볼 수 있습니다. 가장 낮은 것부터 말씀드리자면 character(문자), word(단어), text line(라인), paragraph(문단)이 되겠죠. 쉽게 생각하면 글자가 모여 단어를 이루고, 단어가 모여 line을 이루고, line들이 모여 문단을 이루게 되며 HTS는 이렇게 영상 내의 text의 구조적인 배치를 완전히 표현할수 있습니다.
이 HTS는 크게 두 가지 구성으로 이루어져 있는데요. 첫 번째는 그림 윗 부분에 보이는 Unified-Detector-Polygon(이하 UDP)이라고 적혀 있는 부분입니다. 이 UDP는 text line들을 곡선 형태로 표현하기 위해 bezier curve기반의 polygon을 예측하게 되고 동시에 각 text line들을 문단 단위로 묶어주는 affinity matrix도 함께 생성해내는 역할을 합니다. 두번째로는 가운데 보이는 Line-to-Character-to-Word(이하 L2C2W)라고 적혀있는 부분입니다. 이 L2C2W는 transformer 기반의 인코더-디코더 구조를 활용해 text line 영상을 입력으로 받아서 각 문자의 class와 character box 좌표를 동시에 예측해냅니다. 또, 이 모델은 space(공백) 문자를 함께 학습해서 text line을 word level로 구분할 수 있도록 설계되어 있습니다. 이때 기존 character detection기반 모델들은 모든 학습 데이터셋에 character level의 annotation이 필요했었는데 본 HTS는 일부 데이터에만 character-level의 annotation이 있어도 충분히 학습 가능한 모델입니다. 아래 method단에서 본 HTS에 대해 구체적으로 살펴보도록 하겠습니다.
2. Methodology
2.1. Unified Detection of Text Line and Paragraph
먼저 본 2.1저에서는 text line과 문단 level까지 검출하는 과정을 설명하도록 하겠습니다.
Preliminaries
그 전에 base로 삼은 Unified Detector 모델에 대해 간략히 언급하고 넘어가도록 하겠습니다. Intro에서도 잠깐 언급했었던 이 Unified Detector는 text line을 검출할 수 있는 모델이었는데요. 구체적으로, object query와 pixel feature간의 내적을 계산해 각 text line에 대한 instance segmentation mask를 생성해낸 후 이 mask를 가지고 각 text line을 pixel level로 구분하는데 사용하는 모델입니다. 또 단순 text line 검출만 하는게 아니라 각 line이 어떤 문단에 속하는지 grouping하는 작업도 함께 수행한다고 했었는데요. 이는 object query에 추가적인 transformer layer를 거쳐 layout feature를 추출한 다음 이 layout feature들 간의 내적을 통해 affinity matrix를 계산한 다음 이를 통해 문단 단위로 line을 묶도록 한 것입니다.
Unified-Detector-Polygon (UDP)
이제 저자가 제안한 Unified Detector Polygon을 살펴보도록 하겠습니다. 이 UDP는 앞서 설명드린 Unified Detector가 갖고 있는 한계를 극복하기 위해 제안된 것인데요. 기존 Unified Detector는 text instance를 검출할 때 mask만을 사용했었는데, 이 방식은 곡선 형태로 휘어진 text line을 제대로 보정하거나 표현하는 데 어려움이 있었다고 합니다. 결국 detection 이후 recognition을 수행하기 위해서는 detection 결과를 보정하는 등의 복잡한 후처리 과정이 필요했다는 말이 되겠죠.
이런 문제를 해결하기 위해, 본 논문에서는 encoding된 object query를 입력으로 하는 Bezier polygon head를 추가하였습니다.
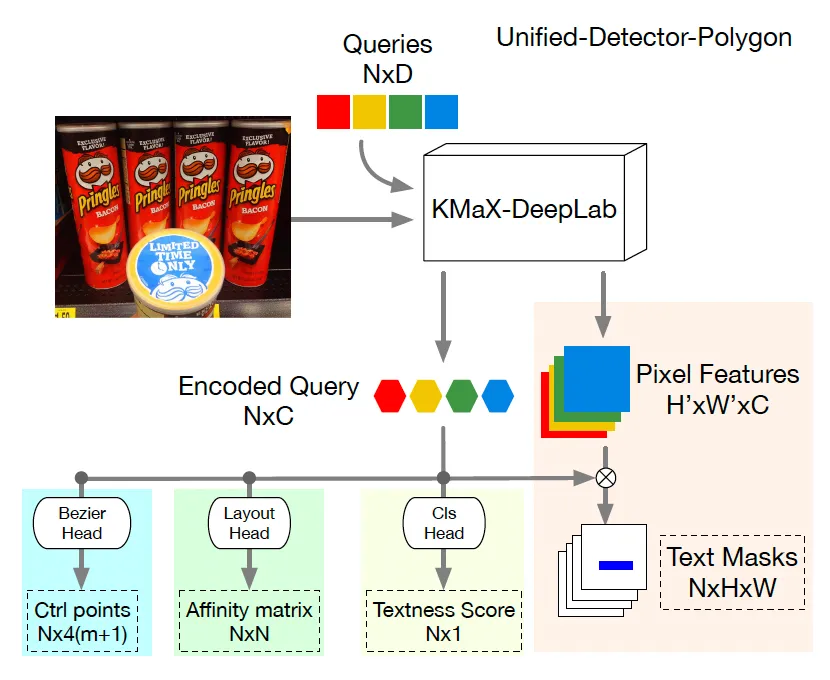
요 그림을 보시면 되는데요. 기존 layout head, cls head는 원래 Unified Detector에 있는 것이고 좌하단에 있는 Bezier head가 추가로 붙은 것이라고 보시면 됩니다. 이 Bezier Polygon head는 Bezier curve를 기반으로 text line을 polygon 형태로 나타내는데, 구체적으로 하나의 text line은 두 개의 bezier curve로 표현되며 이때 하나는 text line 상단부분을, 다른 하나는 하단 부분을 나타내게 됩니다. 학습할 때는 이 bezier curve의 control point를 예측하도록 하며, 추론 시에는 예측한 control point로부터 text의 경계를 복원하게 됩니다. Bezier curve에 대한 보다 자세한 설명은 다음 리뷰를 참고바랍니다.
Location and Shape Decoupling Module
이번에는 저자가 제안한 Location and Shape Decoupling Module(이하 LSDM)을 살펴보겠습니다. 이건 기존 논문들이 하나의 FFN(feed forward network)을 사용해 bezier curve의 control point를 prediction하고 여기에 L1 loss를 사용해 학습하는 방식을 많이 사용했었는데, 이렇게 했을 경우 다양한 위치, 종횡비, shape을 가진 text line이 많은 데이터셋의 경우 성능이 잘 안나오는 문제를 해결하기 위해 제안하는 부분입니다.
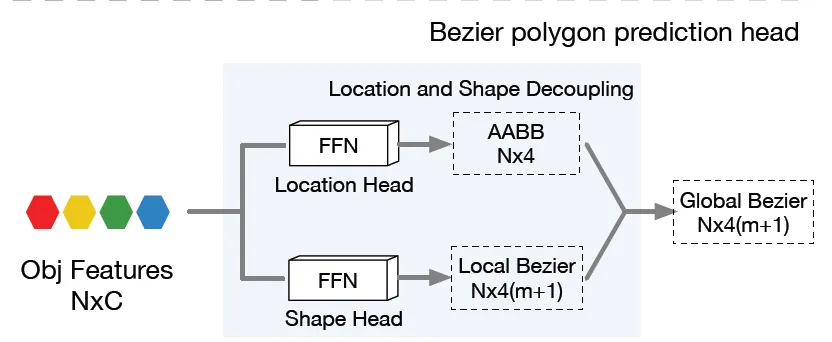
요 구조는 위 그림에 그려져 있는데요, 간단히 말해 FFN을 두 개로 쪼갠 구조라고 보시면 됩니다. 하나는 Location을 예측하도록 하고, 다른 하나는 shape을 예측하는 역할을 하는 것이죠. 먼저 location head에서는 text instance의 중심 좌표와 가로폭, 높이를 예측하게 됩니다. 이걸 수식으로 표현하면 이렇게 되죠.
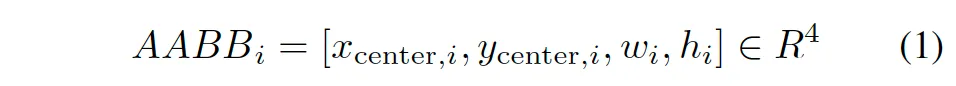
하나의 텍스트 라인을 감싸는 axis-aligned bounding box를 예측한다고 보시면 됩니다. 그다음 Shape Head에서는 이 AABB 내부를 기준으로 local한 bezier control point를 예측합니다.
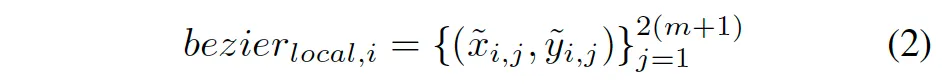
여기서 m은 베지어 커브의 차수인데, 보통 cubic(3차) 커브를 쓰니까 m=3이 됩니다. 따라서 local control point를 8개 예측하는 구조인 것이죠.
그 다음은 예측된 local bezier를 global image space로 변환해야겠죠. 변환식은 다음과 같습니다.
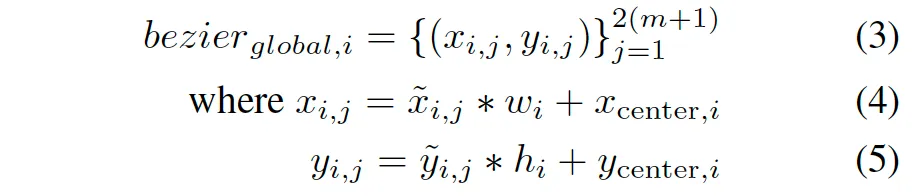
location head에서 예측한 w_i, h_i, x_{center}, y_{center}을 사용해 변환하게 됩니다. 이런 식으로 Location과 Shape을 따로따로 예측해주니까, 다양한 location, 다양한 shape의 text line들을 훨씬 안정적으로 처리할 수 있다는 거죠.
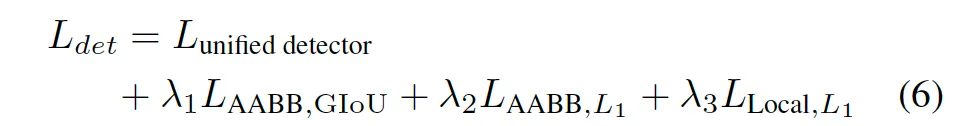
이때, 기존 Unified Detector의 기본 loss에다가, AABB에 대한 GIoU loss, AABB에 대한 L1 loss, local control point에 대한 L1 loss까지 더해서 최종적으로 학습을 진행합니다.

AABB, Local Bezier, Global Bezier 그림을 참고하면 이해에 도움이 되실 것 같습니다.
2.2. Line-to-Character-to-Word Recognition
이번에는 저자가 제안한 Line-to-Character-to-Word recognition에 대해 살펴보겠습니다.
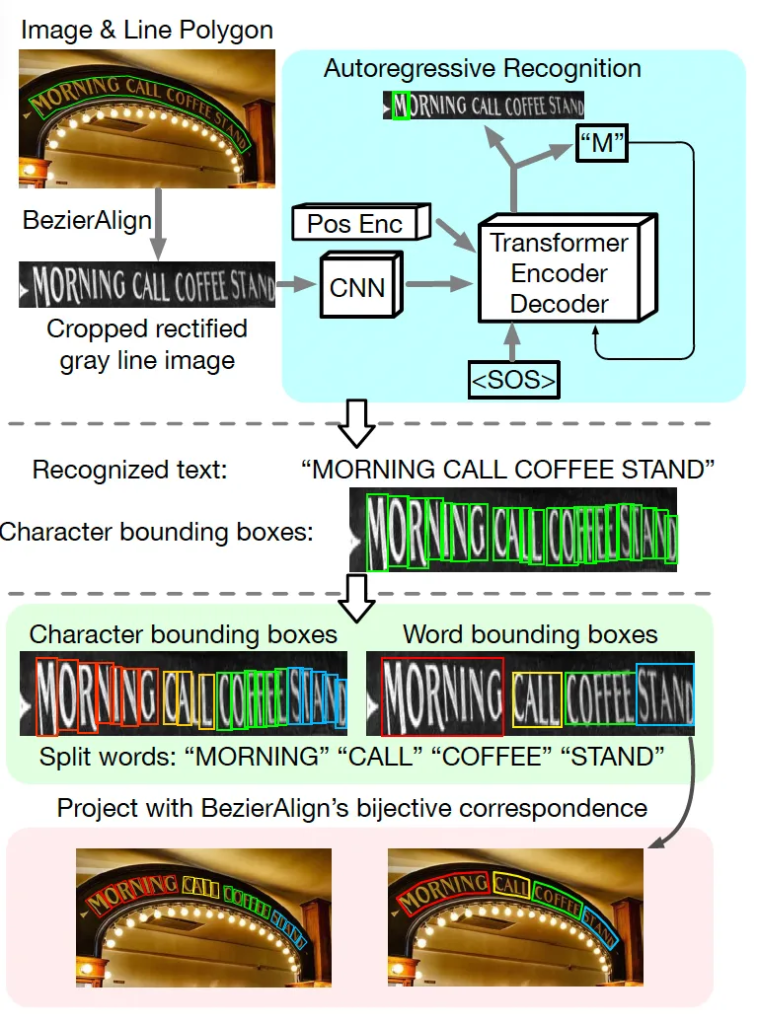
위 그림을 보면 전체적인 흐름을 파악할 수 있습니다. 간단히 말하면, text line level로 잘라낸 영상을 입력으로 받아 character level의 recognition과 word level의 grouping을 동시에 해내는 구조입니다. 먼저 입력은 원본 영상에서 BezierAlign을 사용해 crop하고 rectification(평평하게 펴주는)까지 거친 text line 영상이구요. 모델은 이에 대해 우선 character level의 prediction을 수행합니다.
이때, 단순 character를 하나씩 예측하는 데 그치는 것이 아니라 이 line안에 있는 공백(space)을 기준으로 단어를 나눠야 하죠. 따라서 저잗르은 printable character(말 그대로 화면에 출력할 수 있는 문자)와 special space character도 함께 학습하는 방식을 사용하였습니다. 학습할 때부터 space(공백)을 하나의 문자로 취급함으로써 모델이 이 spacing을 prediction할 수 있도록 설계한 것이죠. 이렇게 하면 inference시에 예측한 space를 기준으로 text line을 쉽게 word-level로 나눌 수 있습니다.
전체 과정을 정리하자면, character recognition, character bbox prediction, 그리고 이 character box를 묶어 word -level의 box를 만드는 것까지 한번에 처리하는 구조라고 볼 수 있습니다.
Training
학습 할때는 character classification loss(CE loss)와 localization loss(L1 loss)를 함께 사용합니다. 이 character -level의 학습을 하기 위해서는 당연하게도 character 단위의 annotation이 필요합니다. 그런데 real image 데이터에서는 character level의 bbox gt가 거의 없고 주로 합성 데이터셋에만 존재하게 되죠. 그래서 학습할 때 실제 real data와 synthetic data를 섞어서 학습하면서, character bbox 정보가 있는 경우에만 localization loss를 적용했다고 합니다.
이때 전체 loss는 아래와 같습니다.
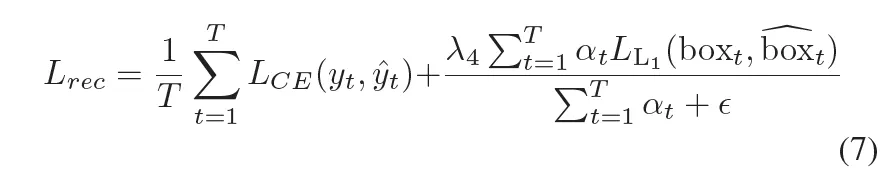
여기서 T는 text line안에 포함되어 있는 문자들의 개수이구요. \alpha_t는 특정 문자에 대해 bbox gt가 존재하는지 여부를 나타내는 indicator입니다.
3. Experiments
3.1. Results on End-to-End Text Spotting
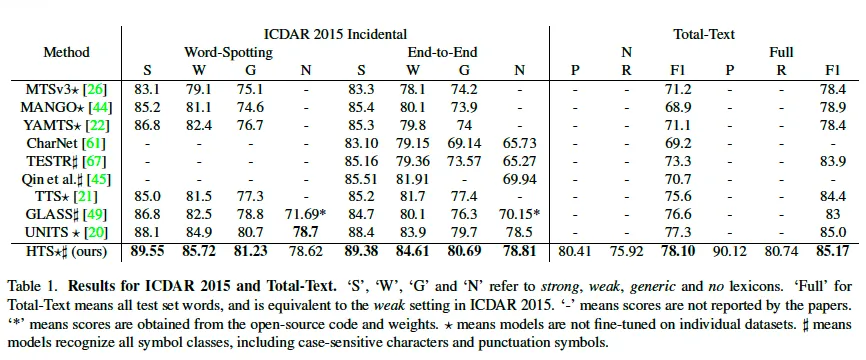
이제 실험 파트 살펴보도록 하겠습니다. 먼저 기존 e2e spotting 방법론들과 비교한 결과입니다. Table1을 보면 ICDAR2015, TT 데이터셋에 대해 실험이 수행되고 있는데, 이 중 ICDAR2015의 평가 프로토콜을 말씀드리자면, 대소문자를 구분하지 않으며 구두점(마침표나, 쉼표, 슬래쉬 등)으로 시작하거나 끝나는 경우, 예측할 때 이 구두점이 없더라도 정답으로 인정해주게 됩니다.
실험 결과를 보시면, ICDAR2015에서 제안된 HTS는 sota 방법론은 UNITS보다 더 좋은 성능을 보입니다. 다만 N이라고 적혀있는 non-lexicon인 경우에서는 UNITS와 유사한 성능을 보이네요. 여기서 non-lexicon이라고 하면 단어 사전 없이 성능을 평가한 것인데 S, W, G는 각각의 lexicon이라고 하는 단어 사전 내에서 edit distance가 가장 짧은 단어를 선택해 gt와 비교하는 식으로 평가가 수행됩니다. 또 spotting외에 e2e에서도 모든 lexicon에 대해 HTS가 더 좋은 성능을 보이고 있습니다. 여기서 볼만한 점은 UNITS라고 하는 모델은 추가적으로 TextOCR이라고 하는 외부 데이터를 가지고 학습을 했다는 점으로, HTS는 외부 데이터 없이 더 좋은 성능을 달성한 것으로 보아 제안하는 방식의 유효성을 시사합니다.
3.2 Results on Geometric Layout Analysis

이번에는 제안된 HTS 모델이 image안에 있는 text의 layout 구조를 얼마나 잘 추정하는지에 대한 실험입니다. 위 FIg4를 살펴보면 character부터 해서 word, line, paragraph level로 layout을 분석하고 있음을 확인할 수 있습니다.
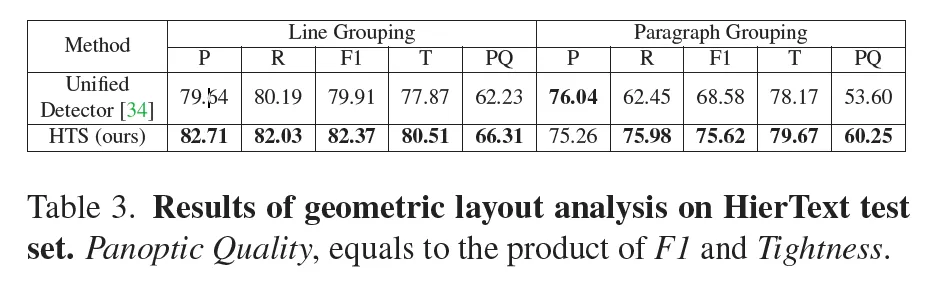
추가적으로 HierText라고 하는 데이터셋을 사용해 geometric layout analysis 성능을 정량적으로 평가하였습니다. 위 Table3을 보시면 제안된 HTS가 기존 베이스로 삼은 Unified Detector 대비 line grouping에서 4정도 paragraph grouping에서 6정도 더 높은 Panoptic Quality를 보입니다. 이 Panoptic Quality는 precision과 Tightness(일치정)을 둘 다 고려한 평가 지표입니다.
특히, HTS는 line및 paragraph를 예측할 때 단순 mask만을 사용하는 것이 아니라 underlying character boxes를 합쳐 만들었다는 점을 주목할만 하는데요. 즉, 각 문자를 정확하게 인식을 하고 난 후에 이 문자들을 합쳐서 단어와 라인, 문단으로 이어 붙이는 방식을 사용했었는데. 이는 곧 unified detector가 하지 못하는 character level의 localization이 정확하게 수행됐다는 점을 간접적으로 드러내며, word-level box역시 잘 예측하고 있음을 알 수 있습니다.
3.3. Ablation Studies
마지막으로 ablation study 살펴보고 마무리하도록 하겠습니다.
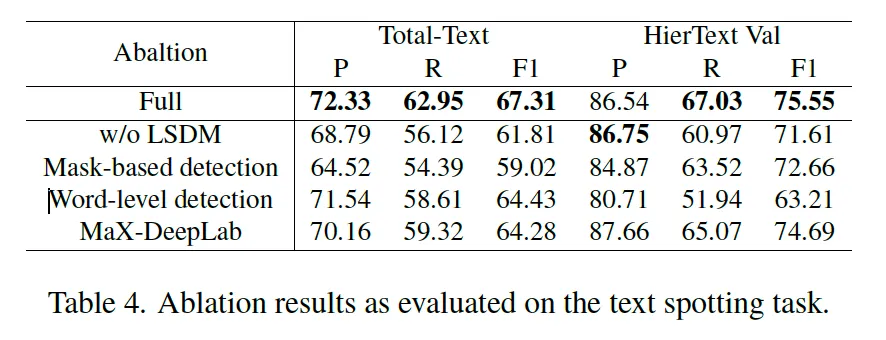
Table4에는 본 논문에서 제안된 여러 모듈들을 추가해가면서 성능을 확인한 실험 결과를 담고 있습니다. 먼저 맨 위에 LSDM같은 경우는 Location and Shape Decoupling 모듈로써 단일 FFN을 사용하는 것보다 이를 두 역할 location과 shape을 예측하는 각각으로 나눔으로써 학습하는 모듈이었죠. 이걸 제거하고 단일 FFN branch를 통해 바로 global bezier를 예측하도록 했더니 F1score가 각각 5.5%, 4% 정도 하락한 것을 볼 수 있습니다.

또, 위 FIg5를 보면 LSDM이 없는 경우 (첫번째 행)에는 text의 위치는 대략적으로 맞지만 곡선 형태를 제대로 복원하지 못한다는 것을 시각적으로 확인할 수 있습니다. 이는 이런 곡선이나 여러 휘어진 형태를 가진 text들이 많은 데이터셋에는 단순 L1 loss만을 가지고 bezier curve를 학습하게 된다면 location만 학습하게 되고 shape에 대한 학습은 잘 안된다는 것을 보여줍니다. 반면에 본 논문에서 제안된 LSDM을 사용한 경우에는 location과 shape학습을 분리해 수행함으로써 각각 안정적으로 학습할 수 있음을 보입니다.
이어서 table4를 보시면 그 아랫줄에 mask기반의 output과 polygon 기반의 output 차이를 비교한 실험이 보입니다. 기존 베이스로 삼았던 Unified Detector 모델의 경우 mask를 가지고 text를 검출했지만 HTS는 bezier polygon을 예측하도록 했었죠. 둘을 비교하면 TT데이터셋에서는 F1score가 8% 이상 떨어졌고 HierText에서는 약 3% 하락한 것을 보입니다. TT데이터셋이 HierText에 비해 곡선이나 여러 모양을 가진 text가 주로 존재하는 데이터셋인데, 이 mask만을 가지고 detection할 때는 곡선 text를 다루는데 있어 crop이나 rectification이 어려워 성능 하락을 가져온 것이라고 볼 수 있겠습니다.
또, 그 아래 word-level과 line level 비교인데요. 여기서는 HTS를 word level spotting에 맞춰 학습한 버전과 line-level spotting에 맞춰 학습한 버전을 비교한 것입니다. 실험 결과 line 기반 모델(맨 위에 Full에 해당)이 각각 약 3%, 12% 더 높은 성능을 보였는데요. 특히 HierText데이터셋에서 성능 차이가 많은 이유가 이 HireText데이터셋은 텍스트가 엄청 빽빽하게 차있는. 다시 말해 밀도가 높은 데이터셋인데 이 경우에는 word로 detection을 수행할 경우 엄청난 성능 하락을 가져올 수 있음을 정량적으로 보입니다.
안녕하세요 윤서님 리뷰 감사합니다.
텍스트의 형태(?)를 이해하고 그 안에서 문맥이랑 띄어쓰기 까지 알아봐서 다양한 모양과 레벨에서 detection이 가능하다고 이해했는데요, 영화 포스터나 팝아트 글씨체같은 텍스트도 검출이 잘 될까요??
또 문득 궁금해진 것인데, text spotting 관련 논문을 계속 보시는 이유도 궁금합니다!!
안녕하세요. 댓글 감사합니다.
1. 합성 데이터셋에는 팝아트 글씨체 같은 폰트의 텍스트가 존재해서 어느정도 검출이 가능하겠지만, 팝아트류의 데이터셋을 추가 학습하지 않는 이상 심하게 변형된 경우에는 좀 어려울 것 같습니다.
2. 관련 연구를 하고 있기 때문입니다 , , ,
리뷰 잘 읽었습니다.
리뷰를 읽다가 한 가지 궁금증이 생겨 댓글 남깁니다. HTS는 character-level로 인식한 후 word-level grouping을 space prediction에 의존한다고 하셨느데, 문장 부호나 다른 특수문자가 많은 경우에도 space 기반 grouping이 항상 잘 작동하나요?
안녕하세요. 댓글 감사합니다.
넵 문장 부호나 다른 특수문자 예를 들어 !나 ? > / 등등을 개별 class로 보기 때문에, 이런 경우에도 space 기반의 grouping이 잘 작동할 것이라고 봅니다.
안녕하세요! 좋은 리뷰 감사합니다.
실험 부분에서 한 가지 질문이 있는데, Tab.4에서 다른 부분은 다 언급해주셨으나 MaX-DeepLab이라는 행은 언급이 없길래 어떤 부분인지 궁금합니다. 이 부분이 저자가 추가로 설계한 부분인가요 ? 그렇다면 Total-Text 데이터셋에서는 성능차이가 좀 있지만, HierText에서는 별 차이가 없는 것에 대한 저자의 의견이 존재하는지 궁금합니다.
감사합니다.
안녕하세요. 댓글 감사합니다.
1. MaX-DeepLab이라고 적혀 있는 부분은 저자가 새로 설계한 부분이 아니라, 기존 베이스로 삼은 모델 Unified Detector의 backbone을 maX-DeepLab로 바꿨을 때의 결과를 보여주는 것입니다.
2. TT에서는 성능 차이가 꽤 있지만, HierText에서는 거의 없는 이유는 직접적으로 언급하고 있지 않습니다. 하지만, 단순 생각해봤을 때 HierText는 text line이 대체로 짧고, 대게 직선 형태의 text가 많은 데이터셋인데 비해 TT는 곡선 형태의 텍스트가 빈번하게 등장합니다. 따라서 이 text의 곡률이나 이 복잡한 형상을 복원한느데 있어 이 바꾼 backbone의 representation이 더 크게 영향을 미치지 않았나 싶습니다.