Introduction
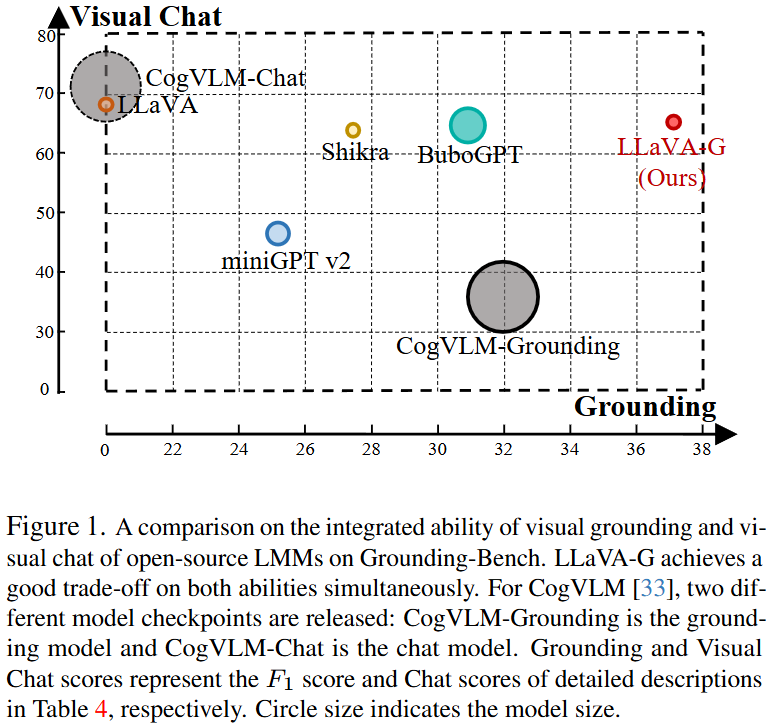
GPT-4, LLaMA의 LMM (MLLM) 시대 이후 사용자의 지시문이나 입력 이미지에 대한 Visual Chat 능력이 중요시 되고 있습니다. 하지만 이들은 이미지 전반적인 이해력은 높지만 특정 영역에 대한 이해력은 저조합니다. 예를 들어 특정 객체/세부 요소를 지시하는 Visual Grounding 능력이 부족합니다. 기존 방식들은 LMM을 활용해 Detection/Segmentation은 잘 해내지만 특정 영역을 언어로 표현하는 Grounding 능력이 저조하며, 실제로 LLaVA에 질문과 함께 “described as bounding box (coordinate)”와 같이 입력하면 [0~1]의 상대좌표로 나오지만, 시각화해보면 결과가 좋지 않습니다. 이를 보여주는 위 Figure 1을 보면 최근의 miniGPT v2, Shikra, BuboGPT, CogVLM-Grounding는 Grounding 능력은 늘어나지만 그에 반면 Visual Chat 능력은 줄어들고 있습니다. 또한 이 모델들은 입력 텍스트에 대해 좌표로 표현만 가능할 뿐, 픽셀 단위의 Grounding/Referring으로 영역을 설명하는 능력은 저조합니다. 이를 극복하고자 저자는 Grounded Visual Chat (GVC)에 대해 세 가지의 Contribution을 제안합니다: Data Creation, Network Architecture, 그리고 Benchmark. 차례로 Data Creation은 GVC 학습을 위한 데이터를 생성하는 과정으로, GPT-4를 활용해 Chat Instruction 데이터를 생성해내는 LLaVA의 과정을 영역 별로 수행합니다. 이는 이미지에 대한 이해를 넘어 영역에 대한 이해를 위해 추가적인 학습을 하고자 수행됩니다. Network Architecture에서 저자는 LLM을 Grounding Model과 연결합니다. 이는 무슨 말이냐 하면 LMM이 Visual Grounding을 잘 수행하지 못하는데, 이를 해결한 방법이 LMM을 모델링하기 보다는 LMM에 기존 Grounding Model을 연결하는 것입니다. 몇몇 연구들에서도 특히 SAM이나 다른 Foundation Model을 그대로 인코더나 디코더로 활용하는 것을 볼 수 있는데, 바로 그런 모습을 떠올리면 됩니다. 이를 위해 저자는 OpenSeeD라는 Detection/Segmentation 모델을 활용하며, 이 모델은 사실은 저자 소속의 예전 논문입니다. 마지막으로 Ground Visual Chat을 평가하고자, 저자는 Grounding Bench 이름의 벤치마킹을 도입합니다. 이는 LLaVA와 같이 Conversation/Detailed Description/Complex Reasoning의 복잡하고 심층적인 질문의 세 단계로 구성된 문맥에서 평가하는 것으로, 이를 토대로 모델의 정량적 능력을 평가하고자 합니다. 이 때 한 가지 의문이 들 수 있는데, 바로 “누가 평가하지?”입니다. 다시 말하면 단순한 Detection/Segmentation이 아니기 때문에 모델이 다양한 답변을 내면 그것이 정답인지를 판단하는 기준을 세우기가 힘들 것인데, 그렇기에 저자는 이 평가를 위해 GPT-4를 또 활용합니다. 이런 흐름은 최근에도 이어지는데, 특히 Visual Chat 분야는 동일한 장면을 보고 누군가는 “말이 사람을 태우고 있다”, 또 다른 누군가는 “사람이 말을 타고 있다”라고 한들, 그 둘 중 누구는 맞고 누구는 틀렸다고 단정하기는 어렵습니다. 따라서 이들의 적합성은 GPT를 통해 평가되며, 그렇기에 실제로 모델 학습 이후 본인의 모델을 평가하기 위해서는 일정 금액의 돈을 내면서 GPT한테 평가해달라고 해야하는 꼴입니다 (제가 다음 주에 리뷰하려는, 연구의 베이스라인으로 삼은 방법론 또한 GPT를 통해 평가해야 해서 API를 등록했습니다).
Method
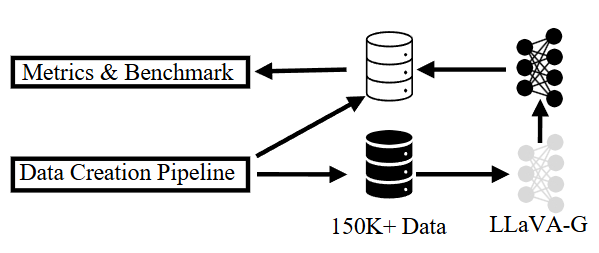
위 그림은 저자가 제안하는 LLaVA-Grounding을 위한 전체 도식입니다. 우선 Data Creation Pipeline을 통해 150K 양의 데이터를 생성해내고, 이를 활용해 저자가 제안하는 LLaVA-Grounding을 학습합니다. 동일하게 Data Creation Pipeline을 통해 평가를 위한 데이터(명사구)를 토대로 모델을 평가합니다. 그럼 하나씩 살펴보겠습니다.
Grounded Visual Chat Data Creation
Grounded Visual Chat을 위해선 단순한 질문-답변의 데이터가 아닌 명사구와 그 명사구에 대응하는 이미지 내의 객체를 연결하는 Grounding 데이터가 필요합니다. 그런데 기존 LLaVA의 Instruction Tuning 데이터의 경우 대화의 품질 자체는 훌륭하지만, “어떤 텍스트가 어떤 객체를 가리키는지”에 대해서는 나타나 있지 않았습니다.
이를 해결하고자 저자는 Grounded Visual Chat (GVC) 데이터를 생성해내고자 했습니다. 질문-답변 구조가 있고 또한 GPT-4로 만든 텍스트이기에 품질이 좋다 판단하여 LLaVA의 Instruction Tuning 데이터를 기반으로 활용했으며, 여기에 COCO의 GT를 활용해 Grounding Label (명사구-객체)를 연결하고자 합니다. 이 과정 또한 GPT-4로 문장에서 명사구를 추출하고, GT를 전달해준 이후 COCO와 의미적으로 가장 잘 맞는 것을 찾아 매칭시킵니다. 아래 그림을 통해 보면 Context type 1은 COCO의 GT, Context type 2는 LLaVA의 Instruction Tuning 대화 데이터, Response는 GPT-4가 명사구와 객체를 연결한 결과입니다.

명사구와 객체에 대한 연결이 성공한 경우에 대해, 저자는 시작-끝과 segmentation 마스크를 표현하는 토큰 ( <g_s>, <g_e>, <seg> )을 추가하여 구성합니다. 아래의 예를 보겠습니다.
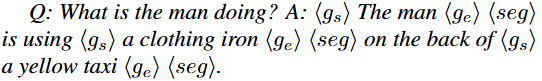
추가로, 사용자의 Instruction (마우스 포인트/박스)를 지원하기 위해 위 GVC와 유사하면서 Question에 <obj> 토큰을 삽입하는 방식을 활용합니다. 다음의 예를 보겠습니다. 위의 예시에서 “the man”이 “<obj>”로 대체되었으며, 이는 사용자가 “the man”에 해당하는 부분에 마우스 클릭을 하거나, 박스를 치는 등의 입력에 대응하고자 합니다. 이를 GVC-R 데이터셋이라고 합니다.
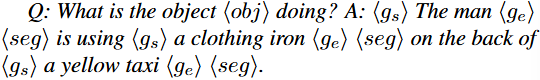
Network Architectures
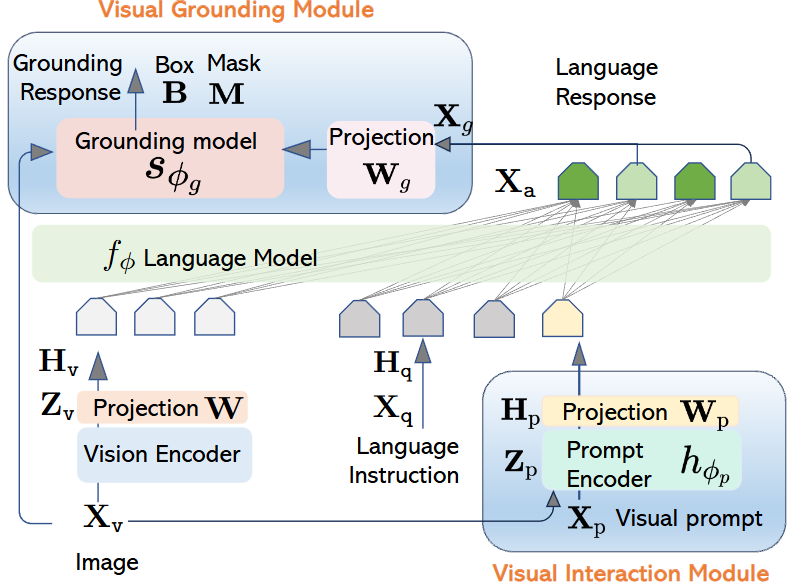
다음은 네트워크 구성입니다. LLaVA를 기반으로 하며 주목할 점은 Visual Interaction Module과 Visual Grounding Module입니다. 모델 구조는 텍스트 내 명사구와 이미지 내 객체 영역의 매칭이 핵심입니다. 차례로 살펴보면 입력 이미지 X_v 와 시각 프롬프트 (마우스 클릭 등) X_p 에 대해, 사전학습된 Semantic-SAM을 Visual Interaction Module의 Prompt Encoder ( h_{\phi_p} )로 사용합니다. Prompt Encoder를 통과한 Visual Feature를 LLM에 통과시키기 위한 Language Embedding 토큰 ( H_p )로 바꾸기 위해 Linear-GELU-Linear와 Project matrix W_p 를 활용합니다. 이렇게 입력 이미지 외에도 사용자의 시각적 입력을 처리하기 위해 사전 학습된 네트워크를 사용한단 점이 주목됩니다. 위에서 언급한 Data Creation Pipeline을 따르면 이들이 곧 <obj> 토큰에 대체됩니다.
이제 Grounding 능력을 위해, 저자는 입력 이미지를 Grounding Model에 입력시킵니다. 물론 단순히 Grounding만 함은 아니고 LLM 결과인 Language Response ( X_g )를 함께 입력시킵니다. 역시나 이 과정에서 사전학습된 OpenSeeD 모델을 활용하며, 이 모델은 Detection/Segmentation을 동시에 수행할 수 있습니다. 어찌보면 전체 네트워크 구성은 LLaVA를 철저하게 따르면서도 (저도 이 모델로 최적화를 시도해보려 세팅을 해보았기에 아는), 사용자의 입력을 처리하기 위한 Visual Prompt, 그리고 Grounding을 위한 OpenSeeD의 활용에만 차이점이 있습니다.
Training
제안한 모델의 학습을 위해, 다음의 데이터를 활용하여 3가지의 순차적인 전략을 설계합니다. 차례로 Pretraining for alignment, Instruction tuning for grounded visual chat, 그리고 Extension to visual prompt이며 각각을 스테이지 별로 차례로 살펴보겠습니다.

Stage 1은 Pretraining for Alignment입니다. 해당 스테이지의 목적인 Visual Encoder의 Feature를 Alignment하고 Grounding Model (OpenSeeD)가 이해할 수 있는 LLM의 출력 Feature를 Alignment함에 있습니다. 이를 위해 RefCOCO/COCO+/COCOg, Visual Genome, LLaVA, Flick30K 데이터를 활용하며, 우선 Vision Encoder의 Alignment를 위해선 CLIP vision encoder에서 나온 feature를 language space와 맞추기 위한 projection layer (W)를 학습합니다. 또한 Grounding 모델을 위해 LLM의 마지막 레이어 hidden states 중 <seg> 토큰에 해당하는 Feature인 <x_g> 를 위한 projection layer를 학습합니다.
Stage 2에서는 Grounded Visual Chat (GVC)를 위한 Instruction Tuning을 수행합니다. 이때는 위 표의, 저자가 설계한 GVC 데이터를 활용하며 동시에 LLaVA 150K도 활용합니다. 이 과정에서는 CLIP vision encoder는 Freeze한 채로, 나머지 Projection Layer나 Grounding Model을 Fine-tuning합니다. Grounding Model 학습 시 <seg> 토큰에 대한 Grounding Loss와 특이하게도 추가로 LLM의 마지막 레이어를 학습합니다.
마지막으로 Stage 3는 사용자의 입력 Visual Prompt를 받을 수 있도록 하학습하는 과정으로, 이 과정에서는 RefCOCO/+/g, Visual Genome 이외에도 저자가 만든 GVC-R (입력 Question에 <obj> 토큰을 포함한)을 사용해 학습합니다. 이 과정에선 Semantic-SAM의 Prompt Encoder로 Visual Feature를 뽑고, 이를 Language Space에 매핑하는 Projection Layer를 학습합니다. GVC-R에서는 <obj> 토큰에 Visual Feature를 넣고, 이를 기반으로 정답 문장을 생성하도록 학습한다고 이해하면 됩니다.
Grounding Bench
Grounding Bench는 Grounded Visual Chat의 성능을 평가하기 위해 저자가 구축한 벤치마크입니다. 이는 기존 RefCOCO/+/g나 Flickr30K와 같은 Grounding 벤치마크는 있지만 대화형 시나리오에서 Visual Grounding을 평가할 수 있는 벤치마크는 부재했기에, 저자가 이를 제안합니다. 이를 위해 우선 COCO를 기반으로 Grounding이 가능한 대화만 남깁니다. 예를 들면 모델이 텍스트 내에서 객체를 명확히 언급할 수 있는, “The man in red shirt”와 같은 대화만 선택합니다. 이후 질문-답변 내에서 명사구를 추출하고, 각각이 COCO 내의 객체와 매칭되도록 자동화된 + 수작업의 프로세스를 거칩니다. 이 결과 3K개의 질의-답변 쌍을 구성하였습니다. 이제 이를 평가해야 하는데, 이는 답변 생성과 Grounding에 대한 평가의 두 가지로 나뉩니다. 우선 질의에 대한 답변을 모델이 생성하면 그 텍스트 내에서 명사구를 추출하고 명사구가 이미지의 특정 객체를 정확히 지칭하는지 맞추는 것이 관점입니다. 이는 기존 LLaVA와 달리 텍스트-이미지 내 일치성이 아닌 텍스트-객체 간 일치성을 본다는 점에서 차이가 있습니다.
이를 평가하기 위한 평가 지표로는 Grounded Recall/Precision, F1-Score를 제안하며 각각 모델이 정답 객체를 모두 언급했는지 (Recall), 모델이 언급한 객체가 정확한지 (Precision)을 다룹니다. 이 때, 평가 시에는 단순히 하나의 정답으로 평가하는 것은 모호하기 때문에 GPT-4를 활용해서 생성 텍스트와 텍스트 내 정답 객체 간 의미적인 일치성을 평가합니다. 앞서 말한 바와 같이 이처럼 GPT-4를 생성형이 아닌 평가를 위한 수단으로 활용되는 모습은 LMM에서 이제는 흔해보입니다.
Experiments
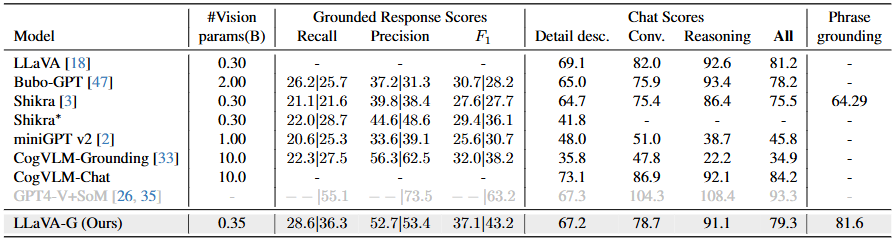
이제 실험 결과 몆 가지를 살펴보겠습니다. 우선 저자가 제안한 Grounding-Bench에 대한 평가입니다. 다음은 저자가 설계한 GVC 데이터에서 모델의 Grounding 능력을 비교합니다. 우선, 저자는 OpenSeeD를 추가로 활용했기에 Vision Parameter에서 LLaVA와 0.05B의 차이가 있습니다. 주요 비교로는 Bubo-GPT/Shikra/miniGPT v2/CogVLM-Grounding(Chat)이 있으며 이들 모델은 저자가 Introduction에서 설명한 Grounding 능력이 있는 데이터입니다. 결과로 따지고 보면 LLaVA-G가 Grounded Response Scores에서 이전 모델들을 모두 상회합니다. 하지만 단순한 Chat Scores로 보면 LLaVA에도 미치지 못하게 됩니다. 반면 Phrase Grounding은 Shikra 외 다른 모델들은 모두 하지 못했으며 성능 또한 LLaVA-G가 앞섭니다. Chat Scores에서 성능이 저조한 이유에 대해 따로 언급은 없지만.. Stage2/3때는 분명 다른 요소들을 Freeze헀음에도 왜 이런 성능 하락이 온지에 대한 언급이 적어 아쉽습니다.
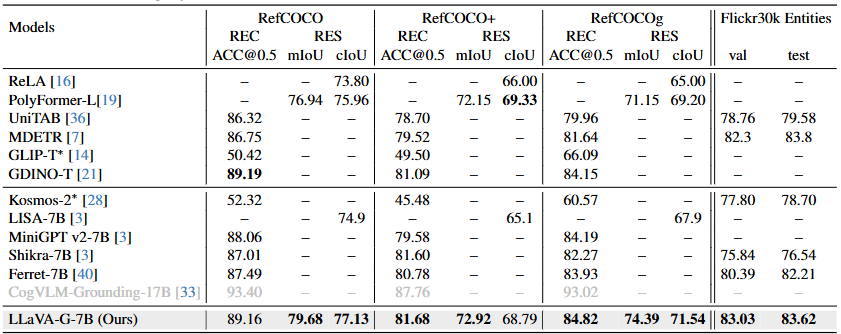
이외 일반적인 Referring Expression Comprehension (REC)와 Referring Expression Segmentation (RES)에 대한 성능도 내세울 수 있습니다. 참고로 제가 레퍼런스로 참고자 하는 방법은 Ferret-7B인데, 그에 비해 높으면서 Segmentation을 해낼 수 있다는 점도 인상깊습니다. 물론 이 Segmentation은 저자가 OpenSeeD 모델을 활용했기 때문이며, 동시에 COCO 데이터셋이였기에 Segmentation 어노테이션이 존재해 평가할 수 있었겠습니다. 사실 그럼에도 저는 이 논문을 리뷰하며 이 논문에 대해 굉장히 부정적인 인식을 가지고 있는 점은, 1. Stage 학습 별 체크포인트를 제공하지 않아 성능을 원복해볼 수 없었습니다. 2. 그렇기 위해 학습을 하려 했으나, 실제로 학습을 위한 Config파일은 존재하지 않았습니다. 위 두 점에 대해 저자에게 물어본 사람도 많았으나 역시 대답이 없는 것을 확인하곤, Ferret-7B로 갈아탈 수 밖에 없었습니다. 시각화 결과는 꽤 인상 깊으니, 몇몇을 살펴보고 마치겠습니다. 특히, Visual Prompt Example에서 사용자의 입력 마우스 포인트에 따라 그에 걸맞은 답변을 보이는 점은 꽤나 흥미롭습니다. 물론 이 또한 Semantic-SAM의 덕분이지만 (코드의 불투명성으로 인해 굉장히 화나있습니다)



안녕하세요 이상인 연구원님 리뷰 잘 읽었습니다
한가지 궁금한 점이 생겨 댓글 남깁니다. Grounding Bench는 COCO 기반으로만 구축됐는데, 더 복잡하거나 오픈 도메인 이미지에도 일반화가 가능할까요?
안녕하세요.
제 생각에는 결국 LLM과 Grounding 모델 덕분일테니, LLM이 잘해주지 않을까 합니다. 우리가 LLM에 기대하는 것이 바로 그런 것과 같이요!
안녕하세요. 좋은 리뷰 감사합니다.
본 논문에서 Grounding Bench 벤치마킹을 위해 모델을 평가하는 과정에서 일정 금액의 돈을 내며 GPT에게 평가를 맡겼다고 하셨고, 상인님이 삼은 베이스라인 방법론도 마찬가지 방식이라고 하셨는데, 한 번 추론할 때마다 일정 금액씩 내야하는 것인지 그 금액은 얼마인지 궁금합니다. 또, 본 LLaVA-G가 Chat Scores에서 성능이 좀 떨어지는 것에 대한 개인적인 견해가 있을까요 ?
감사합니다.
안녕하세요. 읽어주셔서 감사합니다.
금액은 잘 모르겠습니다. GPT에선 토큰 단위로 0.01불 정도 되었던 것 같습니다. 즉, 평가 자체에서 드는 비용은 크진 않습니다.
LLaVA-G는 아무래도 Grounding에 맞춤형으로 제작한 모델이므로 Chating 시나리오에서의 성능은 떨어질 수 있다고 봅니다.