제가 이번에 리뷰할 논문도 3D 모델에 대한 affordance를 추정하는 논문입니다. CVPR 2025 논문이라합니다.
Abstract
3D affordance grounding는 3차원 공간에서 물체를 조작하기 위해 대응되는 영역을 찾는 작업으로, 저자들은 인지과학으로부터 영감을 얻어 언어 지시(language instructions), 시각 정보(visual observations), 그리고 상호작용(interactions)을 기반으로 Grounding 3D object affordance을 수행하는 새로운 task를 제안합니다. 새로운 task를 위한 데이터 셋 AGPIL(Affordance Grounding dataset with Points, Images and Language instructions)를 수집하였으며, 3차원 물리 세계에서 관찰 방향과 물체의 회전, 공간적 제약 인한 occlusion 등을 고려하여 full-view, rotation-view, partial-view의 affordance를 데이터를 포함합니다. 이 task를 위해 저자들은 LMAffordance3D라는, 최초의 멀티모달 언어 기반 3D affordance grounding 네트워크를 제안하였으며, LMAffordance3D는 VLM을 적용하여 2D와 3D의 공간적 특징과 의미론적 특징을 융합합니다. 저자들은 제안하는 데이터 셋 AGPIL에 대하여 제안한 LMAffordance3D 모델의 효과를 입증하였으며, unseen 상황에서 우수하게 작동함을 보였습니다.
Introduction
affordance는 물체를 어떻게 사용할 수 있을지에 대한 정보로, 3D affordance grounding는 입력된 장면에 대하여 물체의 affordance 영역을 인지하는 것을 목표로 하며, 이는 로보틱스에서 중요한 역할을 합니다. 많은 연구들이 2D에서 이루어졌으며, 3D 공간에 대한 affordance 예측은 아직 어려움으로 남아있습니다. 일부 연구들이 3D 데이터를 이용하여 3D affordance grounding를 수행하고자 하였으나, 일반화의 한계로 인해 unseen 물체로 적용하는 데 어려움이 있고, 유사한 물체에 혼란이 발생합니다.
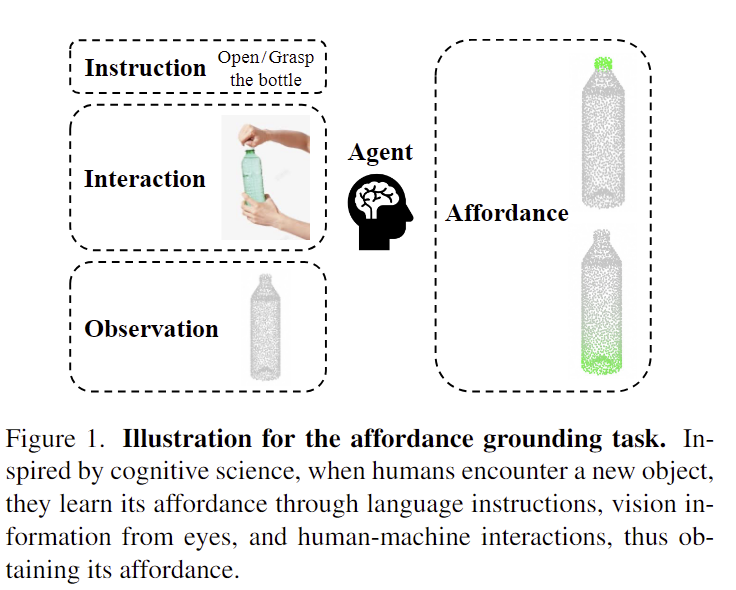
실제로 사람이 affordance를 학습할 때는 언어적 지시뿐만 아니라 이미지나 비디오로 된 시연을 통해 학습이 이루어지며, 이는 언어 지시문과 기하학적 관계, 장면 정보를 이해해야 하는 복잡한 작업임입니다. 저자들은 인지하는 시각적 구성과 청각적 언어 단서가 새로운 사물을 사용하거나 조작하는 능력을 향상시킬 수 있다는 인지과학으로부터 착안하여 언어 지시와 시각 정보, 상호작용을 기반으로 3D affordance grounding를 수행하는 새로운 task를 제안합니다.
또한, 저자들은 해당 논문을 통해 최초로 멀티모달의 multi-view 데이터 셋인 AGPIL을 제안하였습니다. AGPIL 데이섯 셋의multi-view는 언어 지시문과 사람과 물체 사이의 상호작용 정보(HOI, human-object interaction)와 물체의 표면에 대한 point cloud를 포함하는 full-view, 물체의 한 면이나 일부 point cloud를 포함하는 partial-view, XYZ 축을 따라 무작위로 회전한 rotation-view로 이루어집니다. 또한, 각 view의 데이터 셋은 모델의 일반화 성능 평가를 위해 seen과 unseen 구성으로 나누어져있습니다.
저자들은 제안하는 언어 지시와 시각 정보, 상호작용 기반의 3D affordance grounding를 위해 VLM을 기반으로 하는 end-to-end의 멀티모달 언어 기반 3D affordance grounding 네트워크인 LMAffordance3D를 제안하였습니다. LMAffordance3D는 one-stage 방식으로 2D와 3D 공간 특징응ㄹ 통합하고, MLP를 통해 이를 언어 공간으로 투영한 뒤, 모든 특징을 VLM의 입력으로 합니다. 디코더를 이용하여 VLM의 output을 2D 와 3D 공간 특징과 융합한 다음 segmentation head를 통해 affordance 영역을 표현합니다.
해당 논문의 contribution을 정리하면 다음과 같습니다.
- 언어 지시와 시각 정보, 상호작용 기반의 3D affordance grounding task를 제안. 또한, multi-view로 구성된 text-이미지-point cloud 쌍의 AGPIL 데이터 셋 제안.
- 제안한 AGPIL 데이터 셋을 기반으로 seen과 unseen 세팅의 3가지 시점(full-view/partial-view/rotation-view)에 대한 종합적 벤치마크를 설정함. 또한, VLM을 기반으로 하는 end-to-end의 멀티모달 언어 기반 3D affordance grounding 프레임워크인 LMAffordance3D를 베이스라인으로 제안하여 일반화 성능의 개선을 보임.
Method
Dataset
1. Collection and Generation
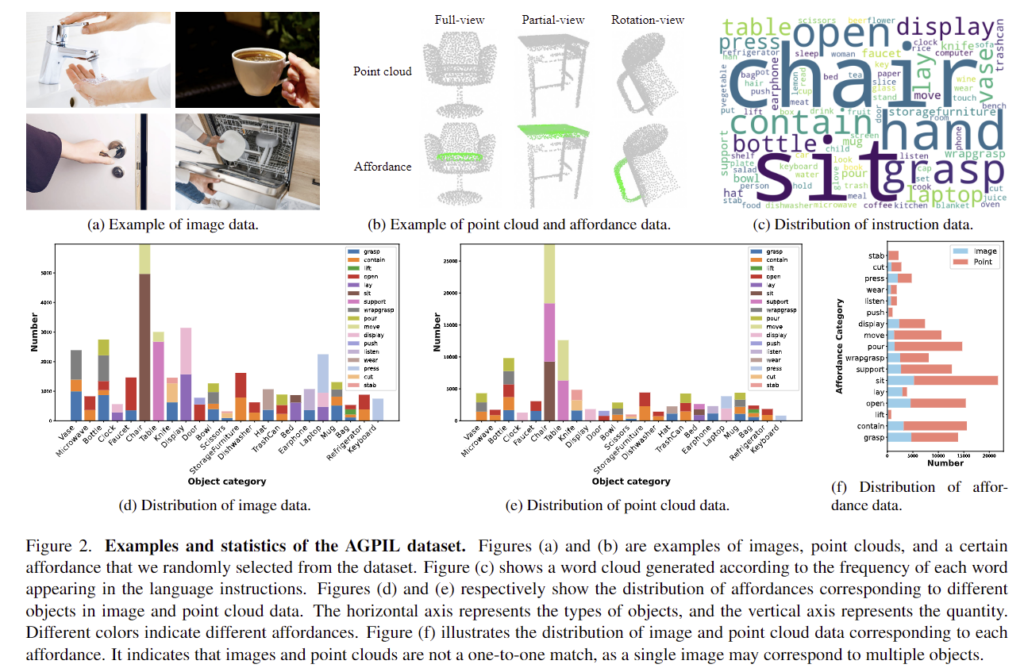
저자들은 3D affordance grounding을 위해 point cloud와 이미지, 언어 지시문으로 이루어진 AGPIL 데이터 셋을 제안합니다. point cloud는 기존 데이터 셋인 3D AFfordanceNet을 이용하였으며, point cloud의 형태가 시점과 물체의 위치, 공간적 제약 등에 의해 달라진다는 점을 고려하기 위해 3가지 시점(full-view/partial-view/rotation-view)으로 데이터 셋을 구성하였습니다. full-view는 물체 표면에 대한 모든 point cloud가 제공되며, partial-view의 경우 한쪽 면이나 일부 point cloud, rotation-view는 xyz축으로 임의로 회전시킨 한쪽면의 point cloud로 구성됩니다. (Figure 2의 예시를 참고해주세요.)
이미지는 물체와 사람이 상호작용에 대한 이미지로 구성된 데이터 셋인 AGD20K와 PIAD를 주로 이용하여 데이터를 수집하였다고 합니다. 이미지는 point cloud에서 물체의 affordance에 해당하는 상호작용을 선정하였으며, PIAD 데이터와 다르게 AGPIL 데이터에는 상호작용하는 사람과 물체에 대한 Bbox 정보가 주어지지 않습니다.

다음으로 언어 지시문을 효과적으로 생성하기 위해 위해 저자들 GPT-4o에 이미지와 잘 설계된 프롬프트를 입력합니다. 프롬프트는 “Please describe the in- teractive relationships in the image in one phrase, reflecting the actions and the object being acted upon” 이며(위의 Figure 3에 예시가 있습니다.), 정확성을 보장하고자 일관성, 단어 선택의 적절성, 의미적 완성도, 문장 구조의 다양성을 기준으로 생성된 텍스트에 대해 점수를 매겨 낮은 점수일 경우 수동으로 언어 지시문을 다듬었다고 합니다.
2. Annotation
annotation을 위해 저자들은 3D AffordanceNet 데이터의 3D affordance 영역에 대한 segmentation 정보를 이용하여 부분적인 수준의 예측이 가능하도록 합니다. 각 annotation은 (2048(point cloud의 포인트 수), 17(affordance 종류의 수))의 행렬로, 각 요소는 점이 특정 affordance에 해당할 확률을 나타냅니다. 또한, 이미지와 언어 지시문에 대응되는 affordance는 1개가 되도록 하였다고 합니다. (언어 지시문이 달라지면 다른 affordance에 해당하는 것입니다.)
3. Statistic Analysis
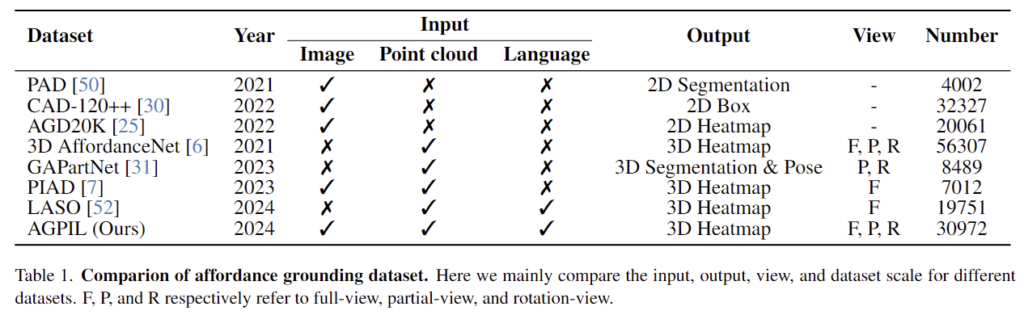
저자들은 Table 1을 통해 자신들의 데이터 셋에 대하여 수치적으로 어필합니다. 총 데이터 세트는 41,628개의 포인트 클라우드, 30,972개의 이미지, 30,972개의 언어 지시문으로 구성되어 있으며, 23개의 객체 범주와 17개의 affordance 클래스를 포함합니다. 각 객체에는 평균 2.4개의 functional part가 있습니다. 특히, 이미지와 point cloud의 객체는 동일한 장면에서 캡처되지 않으며 객체 범주에 따라 짝을 이룹니다. 또한, 데이터 셋은 Seen과 Unseen 두 가지 설정이 있어서, Seen에서는 학습 및 테스트 set의 객체와 affordance 클래스가 일치하지만, Unseen에서는 일치하지 않습니다.
또한, 데이터셋에 대한 더 예시와 통계는 Figure 2에서 확인할 수 있습니다. chair가 가장 많은 물체이며 sit이 가장 많은 affordance에 해당하고있습니다.
LMAffordance3D

저자들은 언어 지시, 시각적 정보 및 상호작용을 통해 학습하여 3D affordance grounding을 위한 프레임워크인 LMAffordance3D를 제안합니다. 전체적인 구조는 Figure 4를 통해 확인할 수 있으며, 크게 4가지 요소로 이루어집니다.
1) Vision Encoder
이미지와 point cloud 등 멀티 모달 데이터를 처리하여 2D와 3D 특징을 인코딩하고 융합하는 Vision Encoder는 색상, 장면, 물체 간 상호 작용에 대한 정보가 포함한 RGB 이미지와 물체의 모양, 크기, 형상에 대한 다양한 정보가 포함된 Point Cloud로부터 정보를 추출합니다. Vision-Language 분야에서 시각-언어 정보의 alignment를 맞추기 위해 가장 일반적으로 CLIP을 사용한뒤 이미지 feature를 의미론적 공간으로 투영하는 방식을 이용합니다. 그러나 CLIP모델의 큰 FLOPS와 파라미터 크기로 인해 로보틱스로 적용하기에는 어려움이 있어서 저자들은 2D vision encoder에는 Resnet18를 이용하여 F_{2D} \in \mathbb{R}^{B ⨉C_I⨉H⨉W}, 3D vision encoder에는 PointNet++을 이용하여 F_{3D} \in \mathbb{R}^{B ⨉C_P⨉N_P}를 구합니다.(여기서 N_p는 point cloud 개수로 2048가 됩니다.) 이후 융합모듈은 MLP와 self-attention을 사용하여 멀티모달 spatial feature F_s \in \mathbb{R}^{B ⨉N_s⨉C_s}를 구합니다.
2) Vision-language model
VLM 모델은 에이전트가 자연어를 이해하고 의미론적 특징과 공간적 특징을 통합하여 affordance feature를 얻기 위해 사용됩니다. 저자들은 LLaVA-7B를 백본으로 이용하였으며,(기존에 리뷰했던 AffordanceLLM도 해당 모델을 이용하였습니다), 동작 명령어가 주어졌을 때 tokenizer를 거쳐 text에 대한 feature F_{T} \in \mathbb{R}^{B ⨉N_L⨉C_L}를 구하고, 2개의 선형 layer와 활성화 layer로 이루어진 adapter를 이용하여 공간적 feature인 F_s를 의미론적 공간으로 투영하여 투영된 feature F_{SP} \in \mathbb{R}^{B ⨉N_s⨉C_L}를 얻습니다.
3) Decoder
이후, affordance feature F_A \in \mathbb{R}^{B ⨉N_A⨉C_A}를 얻기 위해 모든 종류의 feature를 융합하는 attention 기반의 디코더를 설계합니다. 2D 와 3D 공간 feature를 query로, 지시어 feature를 key, 의미론적 feature를 value로 하여 affordance feature를 얻게 됩니다.
4) Head
3D affordance grounding을 수행하기 위한 head로, affordance feature F_A를 upsampling하고 2개의 선형 layer, 활성화 layer, Bach Norm 레이어를 통해 3D affordance O \in \mathbb{R}^{B ⨉2048x1}를 예측합니다.
Loss Function
각 point cloud가 특정 affordnace에 속할 확률을 예측하도록 학습하기 위해 저자들은 focal loss와 dice loss를 가중합하여 네트워크를 학습합니다. 이때 VLM은 freeze 되어있습니다.
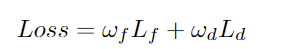
Experiments
Metrics
PIAD 벤치마크를 따라서 AUC와 aIoU, SIM, MAE를 평가지표로 사용합니다. AUC는 3D Point cloud heatmap에 대한 ROC 커브의 아래 영역을 구한 것이며, aIoU는 average IoU(=mIoU인것으로 보입니다.), SIM은 GT와의 유사도, MAE는 확률에 대한 절댓값 오차의 평균을 측정한 것 입니다. AUC와 aIoU, SIM은 높을수록 좋은 성능이며, MAE는 낮은게 좋은 것 입니다.
Results
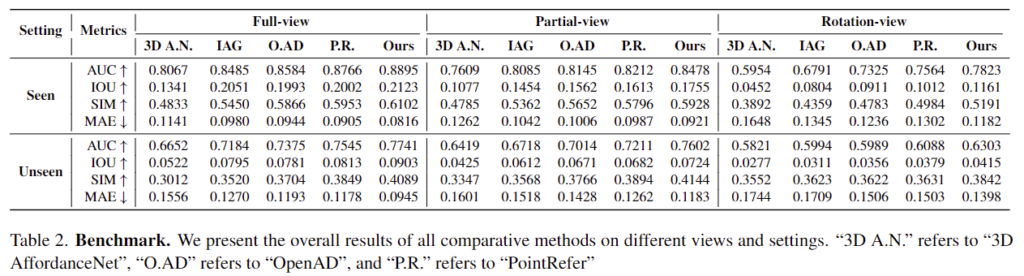
Table 2는 기존 연구 대비 저자들이 제안한 방법론의 성능을 비교한 것으로, 모든 상황에 대해 저자들이 가장 좋은 성능을 보였음을 확인할 수 있습니다. 또한, 동일한 세팅에서 full-view에 새한 성능이 Partial-view난 rotation-view에 비해 더 좋은 결과를 보이는 것을 확인할 수 있습니다.
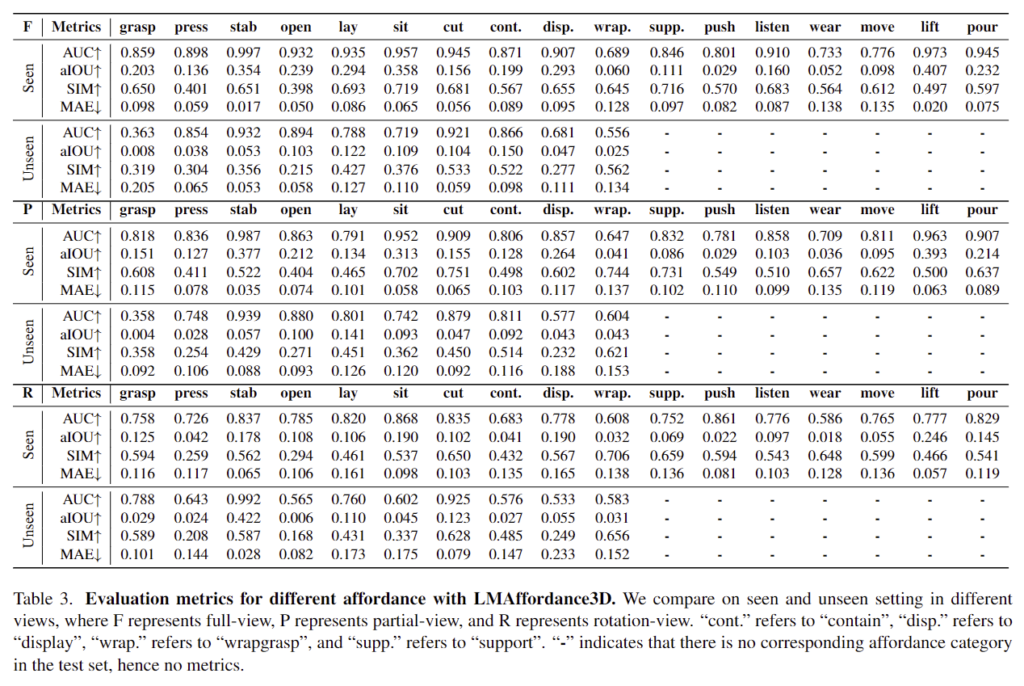
Table 3에서는 저자들이 제안한 방법론이였던 LMAffordance3D를 사용한 다양한 affordance에 대한 결과를 자세히 확인하실 수 있습니다. Seen 세팅에서는 훈련 및 테스트 데이터 셋모두 모든 affordance 카테고리를 포함하지만, Unseen 세팅에서는 훈련 데이터 셋에는 리포팅되지 않은 7개의 카테고리(support, push, listen, wear, move, lift, pour)를 이용하고, 테스트 데이터 셋으로는 나머지 10개(grasp, press, stab, open, lay, sit, cut, contain, display, wrapgrasp)를 이용합니다.

위의 Figure 5는 다양한 view와 기존 방법론의 affordance 예측 결과를 정성적으로 보인 것 입니다. 대체로 자신들의 방법론이 잘 예측하고 있음을 어필합니다. 특히 point cloud가 일부 누락되는 partial-view와 rotation-view에서도 잘 예측이 이루어지고 있음을 보여주며, 저자들이 제안한 방법론(LMAffordance3D)에 대하여 어필합니다.
Ablation study
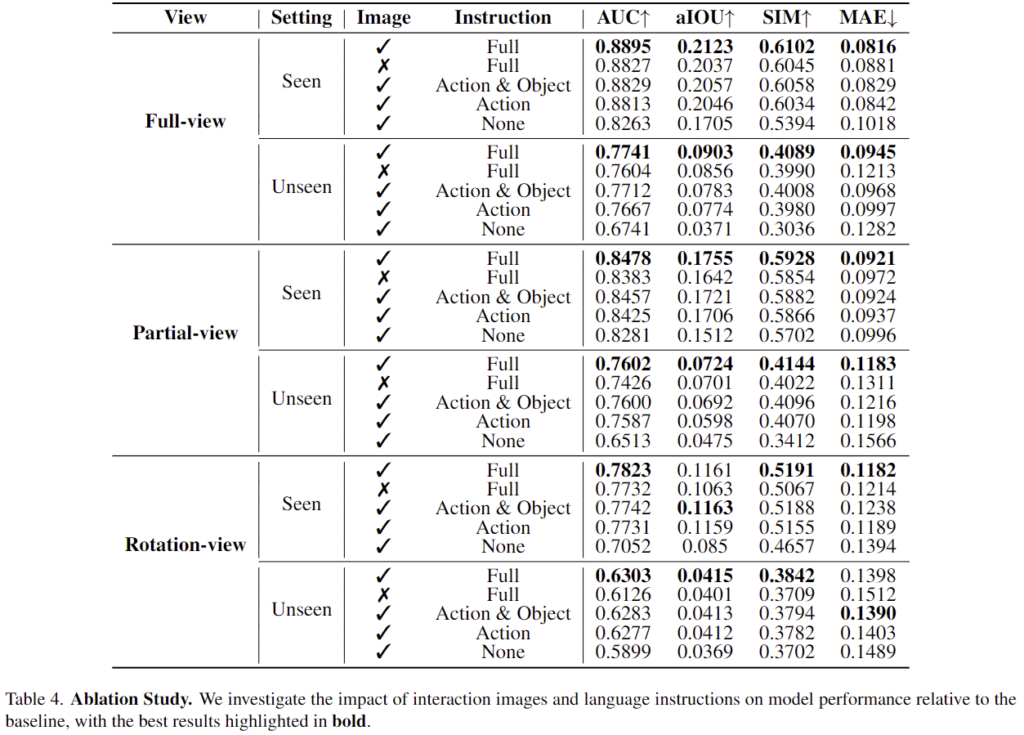
저자들은 ablation study를 통해 상호작용 이미지와 언어 지시문의 영향을 평가합니다. 결과는 table 4에서 확인할 수 있으며, 이미지의 시각적 단서가 affordance 정확도에 미치는 영향을 평가하고자 이미지의 유무를 실험하였고, 그 결과 이미지가 없는 경우 seen과 unseen에서 모두 성능 저하가 발생함을 확인하였습니다. 이를 통해 상호작용 이미지의 필요성을 어필합니다. 개인적으로는 “상호작용 이미지”의 효과를 확인하고자 객체에 대한 이미지만 있는 경우도 따로 실험해보았으면 더 유의미한 실험이 되지 않았을까 합니다. 그러나 데이터 수집의 어려움을 고려하였을 때, 실제 실험을 진행하기는 어려울 것 같습니다.

또한, 언어 지시문이 미치는 영향을 평가하고자 Full/Action&Object/Action/None에 대하여 다르게 변경하여 평가를 수행하였습니다. 실험 결과 Full인 케이스가 대부분 좋은 성능을 보이는 것을 확인할 수 있습니다. 이는 지시문에 더 많은 지식과 정보가 포함되어있기 때문입니다.
Real-world

마지막으로 일반화 성능에 대한 어필을 위해 저자들은 real-world에서 데이터를 수집하여 평가를 수행합니다. 이에 대한 결과는 Figure 6으로 확인할 수 있으며, 언어 지시문과 affordance 클래스는 unseen 세팅으로 저자들이 제안한 방법론이 실제로 어느정도 작동이 가능하다고 어필을 하며 실험을 마무리합니다.
개인적인 생각으로, 해당 연구는 방법론이나 데이터 수집 과정에서 엄청난 참신성이 있다기보다, 인지과학관점에서 언어-시각정보-상호작용정보를 모두 함께 학습해야하는 것의 필요성을 드러내고, 실험적으로 성능이 좋았다는 점에서 인정을 받은 것 같습니다. affordance 관련 논문들이 대체로 데이터를 수집하고 자신들이 평가하는 방식으로 이루어지는 경향이 있습니다.
재밌는 논문 리뷰 감사합니다.
간단한 질문 남기고 가도록 하겠습니다.
Q1. Image, 3D point, language instruction과 이에 대응되는 3D affordance 를 예측하는 데이터 셋과 기법을 제시한 좋은 방법론인데요. 굳이… Image와 3D point를 다 사용해야하는 이유가 있을까요?
Q2. 그리고 Image와 3D point 간의 align이 안 맞는 문제가 학습과 예측에 영향을 줄 것이라고 생각이 듭니다. 저자는 해당 부분에 대해서 디펜스한 내용이 있을까요?
Q3. 처음에 다중뷰가 영상에 대한 다중뷰라고 생각했는데 point cloud의 다중 뷰였네요? 제일 이해가 안가는 부분이 어차피 pointnet++로 feature를 만드는 거라면… 이미 위치에 대한 불변성은 갖춘 상태이지 않나요?
Q4. 그리고 다중뷰에서는 어떻게 퓨전을 하는지 궁금합니다.
질문 감사합니다.
A1. 우선 해당 방법론이 3D에서의 affordance를 추정하는 것이라 3D Point cloud를 사용하였으며, 사람의 경우 시연을 보면서 학습한다는 점에서 착안하여 사람이 물체와 상호작용하는 Image를 함께 사용하였습니다.
A2. 저자들은 3D Point와 Image가 align 맞지 않다는 점을 문제로 다루지는 않았습니다. 추가로 동일한 인스턴스가 아니며, 형태도 크게 달라서 3D Point와 Image의 align을 맞추기는 무리가 있는 것 같습니다.
A3. 여기서 multi-view는 특정 조건에 따라 3D Point cloud가 달라진다는 차이가 있습니다. 사실 full view로 할거면, 보이는 면만 있어야하지 않나 하는 생각과 “view”라는 표현이 적절한지에 대해서는 저도 의문이 들긴 합니다. 아무튼, point cloud가 full-view는 완전한 물체 표면의 point cloud(실제 물체를 관찰하는 view와 무관하게 모든 표면임)이고, partial-view는 특정 시점에서 봤다고 했을 때 한 면의 point cloud나 일부를 제외한 point cloud, 마지막으로 rotation-view는 일부 point cloud를 랜덤하게 회전시킨 것 입니다. 위치 불변성을 의미하지 않습니다.
A4. 다중 view의 정보를 fusion하지 않습니다. 데이터 셋 구성이 다르게 구성된 것입니다.
안녕하세요, 좋은 리뷰 감사합니다.
데이터셋 구성에서 모델의 전처리 과정으로가 아니라 데이터셋 자체에서 무작위의 축으로 회전한 view를 제공하는 것이 특이한 것 같습니다. 이 부분에서 궁금한 점이, 그렇다면 affordance에 대한 언어 지시문에는 이러한 회전 여부를 표현하게 되나요 ? 무작위로 회전하였을 때의 포인트 클라우드 구조를 회전했다는 여부가 없이 바로 모델이 일반적인 지시문으로 이해할 수 있을지 의문이 들어 질문 드립니다.
또한 partial view는 일부가 누락이 되는 포인트 클라우드 정보라고 하셨는데, 일종의 포인트 클라우드 샘플링이라고 봐도 되는 걸까요 ? 누락하는 정도나 위치에 대한 기준이 있었는지도 궁금합니다.
감사합니다.
질문 감사합니다.
affordance에 대한 언어 지시문에는 회전 여부를 따로 표현하지 않습니다. 이야기하신대로 회전 등의 정보를 제시하지 않아도 모델이 3D point cloud 에서 대응되는 affordance 영역을 인지할 수 있다는 것이 하나의 장점입니다.
또한, partial-view인 경우는 보이는 면의 point cloud만 남기거나 occlusion이 발생한 것 처럼 특정 부분의 point cloud를 지우는 것 입니다. 이에 대한 별도의 기준을 언급하지는 않고있으며, 코드로도 확인이 어렵습니다. 랜덤하게 적용하는 게 아닐까 합니다.