안녕하세요 류지연입니다.
한주 간 VLAD로 이미지 분류 성능을 개선시키는 것을 진행했습니다. 본 연구에서 제안하는 방법론을 적용했습니다. 한주를 마무리하며 연구에서 제안하는 방법론들에 대해 정리하고자 해당 논문으로 리뷰를 쓰게 되었습니다.
그럼 리뷰 시작하도록 하겠습니다.
1. Introduction
객체 단위의 image search 연구는 근 10년간 발전이 많았습니다. BoW 이후 descriptor 자체를 다르게 정의해 더 구별력있는 표현 방법에 대한 연구, descriptor를 클러스터의 centroid로 양자화하는 과정에서 발생하는 quantization loss를 줄인 연구, 이미지 반환 정확도를 개선한 연구가 있었습니다. 많은 연구중에서도 VLAD 연구가 단연 제일 해당 분야의 발전에 기여한 방법이라고 저자는 얘기합니다. 이후 VLAD를 사용했을 때 이미지를 나타내는 descriptor를 저차원으로 표현하면서도 retrieval 성능은 유지가 돼 대량의 이미지 데이터셋에 대해서도 적용이 가능했습니다. 해당 분야의 연구는 이후에 메모리 사용과 검색 성능 개선의 트레이드오프를 해결하기 위한 연구로 발전돼왔습니다.
VLAD는 locally invariant descriptor인 SIFT를 양자화하는 방법입니다. BoW의 방법과 다른 점이 cluster center 마다 매칭되는 descriptor의 개수를 세기 보단 descriptor와 cluster center 간의 잔차를 기록한다는 데 있습니다. VLAD는 SIFT descriptor가 그렇듯 locally 불변한 특성을 가져 회전이나 스케일에 불변하고 clipping에도 강합니다.
VLAD는 BoW에서와 달리 메모리 절감을 위해 이미지의 local descriptor보관하지 않는다고 합니다. BoW의 경우 visual word 개수만 세어서 이미지내 공간적인 정보를 반영하지 못한는 단점을 보완하기 위해 검색 시스템으로의 적용에서 Spatial Verification을 통해 reranking 해 이미지를 매칭했었습니다. VLAD의 경우 클러스터 중심을 기준으로 매칭된 local desrciptor의 분포가 반영된다는 점에서 Fisher Vector와 더 유사한 방법이라고 할 수 있습니다.
논문이 작성된 시점을 기준으로 해당 분야의 연구는 VLAD 벡터를 가지고 성능을 개선하는 방향으로 연구가 이어오고 있었는데 본 연구 또한 VLAD의 성능을 개선하기 위해 제안하는 논문입니다. 본 연구에서는 총 3개의 contribution을 내세웁니다.
- Intra-normalization
burstiness 문제를 다루기 위해 VLAD 벡터를 정규화하는 새로운 방법입니다. VLAD 벡터의 일부 차원에서 유독 값이 커 같지 않은 두 이미지에 대해 유사도가 높게 나오는 것이 burstiness 문제에 해당됩니다.
- Multi-VLAD
하나의 이미지를 여러개의 tile로 나눈 다음 각 tile에 대한 벡터로 이미지를 나타내 작은 객체에 대한 검색 성능이 향상시키기 위해 제안됐습니다. (해당 방법은 효과적인 localization을 제안하기 위한 방법이기도 합니다)
- Vocabulary adaptation
다른 데이터셋으로 생성된 코드북을 가지고 이미지에 대한 VLAD 벡터를 나타냈을 때의 문제를 언급합니다. vocabulary apaption의 방법을 사용해 현재 사용하려는 데이터셋에 대해 코드북을 재생성하지 않고도 해당 문제를 해결합니다.
첫 두 방법은 VLAD의 성능을 향상시키기 위한 방법들이입니다. 세번째 방법은 실제 상황에 적용했을 때 발생할 수 있는 문제를 다룹니다. 기존의 데이터베이스에서 이미지가 추가 되기 때문에 이전 데이터베이스로 만든 vocabulary를 가지고 추가된 이미지 까지 전부 커버하기에는 어려움이 있었습니다.
2. VLAD review, datasets and baseline
2.1 VLAD
이미지에서 affine 변환에 불변한 영역 (키포인트)가 추출되고 128차원의 SIFT descriptor로 기술됩니다. 각 local descriptor는 k개의 cluster로 clustering이 되며 제일 유사한 것과 매칭됩니다. 각 k개의 cluster 마다 매칭된 local descriptor간의 잔차가 누적돼 계산됩니다. k를 cluster의 개수라고 할 때, k X 128 차원의 벡터가 도출됩니다. 이를 unnormalized VLAD라고 지칭합니다.
VLAD 가 처음 제안됐을 때 VLAD 벡터는 L2 normalization가 적용됩니다. (VLAD 벡터를 벡터의 크기로 나눠 단위 벡터가 되도록 함) 이후 연구에서는 여기서 더 나아가 Fisher vector에서 사용되던 SSR (signed square rooting)을 VLAD에도 적용하는 것으로 제안됐습니다. 벡터의 각 원소마다 부호는 유지하고 값에 루트를 적용하는 과정입니다. SSR 적용 후에는 동일하게 L2 normalization이 적용됩니다. (이미지 마다 local descriptor의 개수가 다를 수 있기 때문에 정규활를 수행합니다)
2.2 Benchmark datasets and evaluation procedure
본 연구에서는 두가지 데이터셋을 (Oxford building, Holidays) 가지고 검색 시스템에서 정확도를 확인하기 위한 실험에서 사용합니다. 평가지표로는 mAP가 사용되었습니다.
Oxford buildings
Flickr로부터 5,062장의 이미지를 다운로드해 구성한 데이터셋입니다. 이를 Oxford 5K라고 지칭합니다. 이중 55장은 쿼리에 사용됩니다. large scale에서의 검색 성능을 파악하기 위하 실험에서는 100k 장의 Flickr 로 부터 다운받은 이미지를 데이터셋에 추가한 Oxford 105k 데이터셋을 사용합니다.
Holidays
고해상도의 1,491장의 이미지 데이터 구성된 데이터셋입니다. 이 중 500장을 쿼리에 사용합니다. 마찬가지로 large scale retrieval 성능을 확인하기 위해서 더 많은 양의 데이터가 필요한데 Flickr1M을 사용해 최종적으로 Holidays+Flicker1M 대용량 데이터셋을 구성합니다.
Vocabulary sources
codebook 생성 위해 (본문에서는 vocabulary building이라고 한다.) 또 다른 3개의 데이터셋이 사용됩니다. Oxford builing 데이터셋과 비슷한 Paris6k (프랑스에 있는 건축물 이미지 데이터셋), Flickr로 부터 60k 이미지를 다운받아 구성한 데이터셋인 Flickr60k가 있다. no-vocabulary란 것은 Holidays 데이터셋에서 SIFT descriptor k개를 무작위로 뽑아서 코드북을 생성하는 방법입니다.
3. Vocabulary adaptation
앞서 contribution 중 3번째로 언급됐던 cluster adaptation입니다. 데이터가 계속 추가돼서 cluster center가 항상 같지 않은 경우 (not consistent한 경우) 에 대해서 retrieval 성능을 향상시키기 위해 제안된 방법입니다. 다른 데이터셋으로 만들어진 코드북을 가지고 VLAD 벡터를 define하고 image retrieval을 진행한 경우 이런 inconsistency 문제가 성능 하락의 원인이 됐었습니다. 물론 그냥 간단하게 생각했을 때 새롭게 얻은 데이터셋에 대해서 코드북을 재생성하는 방법이 있겠으나 비용이 많이 들고 기존 데이터셋 (추가되기 전의)의 descriptor가 필요하다. (앞서 얘기했는데 local descriptors를 저장해두지 않는다고 합니다.) 본 연구에서 제안한는 방법은 코드북 재생성이 필요하지 않습니다.
클러스터 k에 대해서 두 이미지의 descriptors 집합을 (즉 각 k번째 차원의 값을) xk(1) xk(2)라고 했을 때 두 벡터간의 유사도는 다음과 같이 계산됩니다.
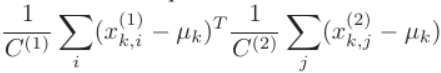
유사도가 양의 값을 나타내는 경우 두 벡터간의 유사도가 높은 것입니다. 예를 들어 두벡터가 동일한 cluster center를 기주으로 하고 다른 방향을 가리킨다면 유사도는 negative 값이 나오게 됩니다.
아래 그림을 참고해 VLAD 벡터간의 유사도가 cluster center가 어디에 위치하는지에 따라 다를 수 있다는 것을 봅시다.
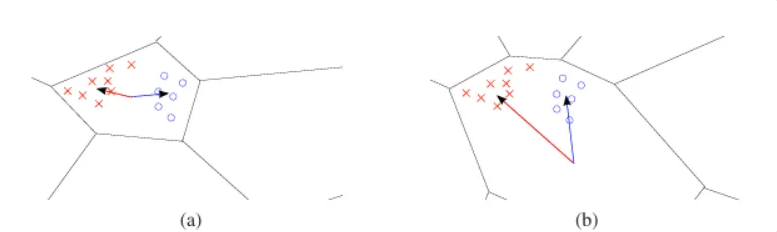
(a)에서 두 벡터간의 방향이 cluster center 기준으로 달라 유사도가 negative 하게 나오지만 같은 데이터를 가지고도 cluster center를 다르게 위치시키면 두 벡터가 비슷한 방향을 가지게 되며 두 벡터간의 유사도가 증가하게 됩니다. 이 처럼 cluster center가 완전히 다른 유사도를 갖게 되는 것이지요.
다음은 본 연구에서 제안한 cluster center adpatation 방법론에 대한 설명이다. 두단계로 설명이 돼 있다. 새롭게 추가된 이미지의 local descriptor를 기존 code book의 cluster로 clustering한 이후 클러스터 마다 descriptor의 평균을 새로이 클러스터 center로 설정한다. 새로이 갱신한 cluster center에 대해 새로운 VLAD 벡터를 갱신하는 방법입니다. 이때 cluster 마다 매칭된 local descriptor의 합을 저장하고 있다면 이 값에서 새롭게 갱신된 cluster center를 뺌으로서 VLAD 벡터를 계산할 수 있게 됩니다.
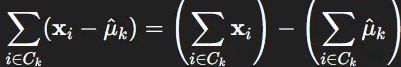
굳이 각 local descriptor와 새롭게 갱신된 cluster center간의 잔차를 구한 후 누적해 VLAD 벡터를 계산하지 않아도 됩니다.

(b)에서의 center를 데이터에 알맞게 조정한 것이 (c)라고 볼 수 있겠습니다. 새롭게 추가된 데이터에 대해 clustering을 해서 완전히 다른 코드북을 만들 었을 때 (a)의 형태를 띌텐데요 cluster adaptation의 방법으로 clustering을 반복하거나 조정한 위치의 center와의 residual을 계산하지 않아도 center 위치를 비슷하게 조정할 수 있었습니다.
center adaptation 방법을 평가하기 위해 다음과 같은 실험을 진행했습니다. Flickr60k 로 구성된 vocabulary를 가지고 Oxford 5k 데이터셋에 대해서 adaptation을 적용했을 때 original vocabulary (Flickr60k로 만든 vocabulary)와 Oxford 5k에 대해 위치 조정을 한 center 간의 평균 차이가 (클러스터 k개 에 대하 평균을 낸 값) 0.209가 나왔습니다. RootSIFT의 크기가 1인 점을 고려했을 때 상당한 차이가 있는 것이다. Oxford 5k와 유사한 paris 데이터셋으로 vocabulary를 구성했을 때는 그 차이가 0.022로 비교적 낮았다. Oxford 5k와 Paris 데이터셋 모두 유럽의 건축물에 대한 것이라 큰 조정이 필요하지 않았던 것일 거다.
다음은 그 image retrieval 성능을 정량적으로 분석한 실험 결과이다. 각 데이터셋 (Oxford, Holidays)에 대해 3개의 다른 데이터셋으로 만든 vocabulary를 가지고 여러 메소드에 대해서 실험한 결과입니다.
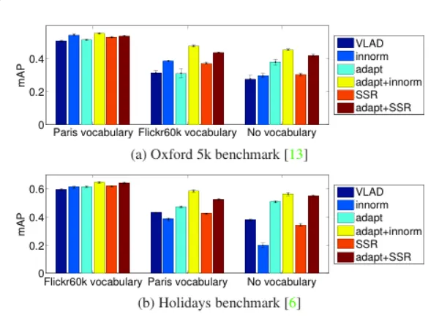
지금은 기본 VLAD 인 네이비색 막대와 adapt를 적용한 민트색 막대를 봐주세요. 모든 경우에서 center adaptation을 적용했을 때 성능 향상을 보입니다. retrieval 에 사용하는 데이터셋과 vocabulary를 만들기 위한 데이터셋이 완전히 다르거나(Holidays – Paris vocabulary) no-vocabulary인 경우 개선된 정도가 더 컸습니다. 자세히 설명 드리자면 Holidays benchmark에 대해서 paris vocabulary에 대해 adaptation을 적용해서 9.7% 향상을 보였지만 Holidays와 상대적으로 유사한 Flickr60k vocabulary에 대해서는 3.2%의 향상으로 비교적 낮았습니다.
4. Intra-normalization
기존에 VLAD 벡터는 벡터의 일부 차원에서 값이 큰 경우 (어떤 반복되는 패턴이 중복되는 경우 바닥, 벽지 패턴 같은) retrieval 수행 시 image간의 유사도를 판단하는 과정에서 영향을 끼처 잘못된 매치를 내는 burstiness 문제가 있었는데요 이를 줄이고자 이전 연구에선 VLAD 벡터 전체에 대해 L2 정규화를 하거나 SSR (signed square rooting)의 방법으로 벡터의 각 원소를 discounting 하는 식으로 적용이 됐지만 burstiness의 문제가 완전히 해결되지는 않았습니다. 이를 다루기 위해 본 연구에서 새로운 방식을 제안한 것이 Intra-normalization입니다.
벡터에 bursty한 element가 포함된다면 비교적 작지만 중요한 feature의 영향은 무시될 수 있단 점이 문제입니다. 이를 우선 해결하고자했던 것이 SSR인데 벡터의 모든 원소를 부호를 유지하면서 루트를 씌워 discount의 효과를 내는 방법이었습니다.
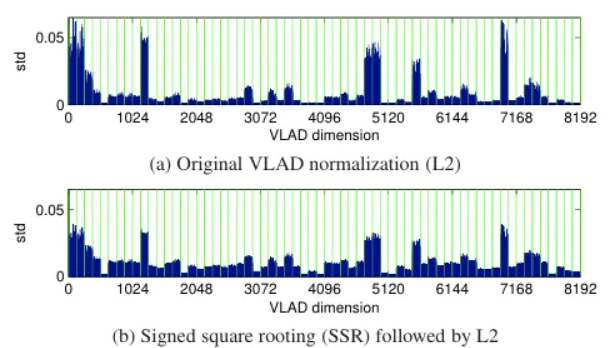
다음은 Holidays 데이터셋의 모든 이미지에 대해서 각 벡터의 차원마다 표준 편차 (energy)를 계산해서 나타낸 그래프입니다. 어떤 차원에서의 energy가 클 수록 이미지간의 변동 복이 크다는 의미입니다. 즉 bursty 한 element가 그대로 나타나고 있다는 뜻입니다.
저자가 제안하는 Intra-normalization은 local descriptors를 clustering한 후 cluster마다의 잔차 합을 독립적으로 L2 정규화를 적용하는 방법입니다. 그리고 기본 VLAD나 앞서 설명한 SSR 와 동일하게 이후 전체 벡터에 대해서도 L2 정규화를 진행합니다. 해당 방법의 경우 bursty 한 element을 효과적으로 억제합니다.
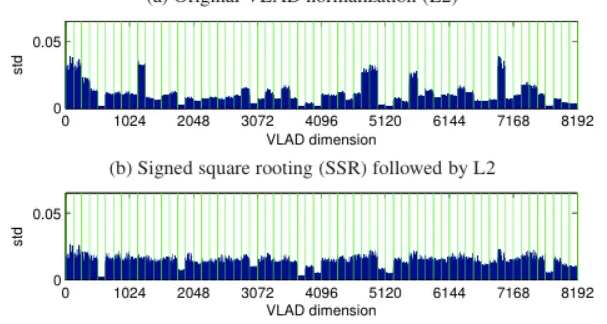
결과를 화인해보아도 energy가 높은 봉우리가 거의 없습니다.
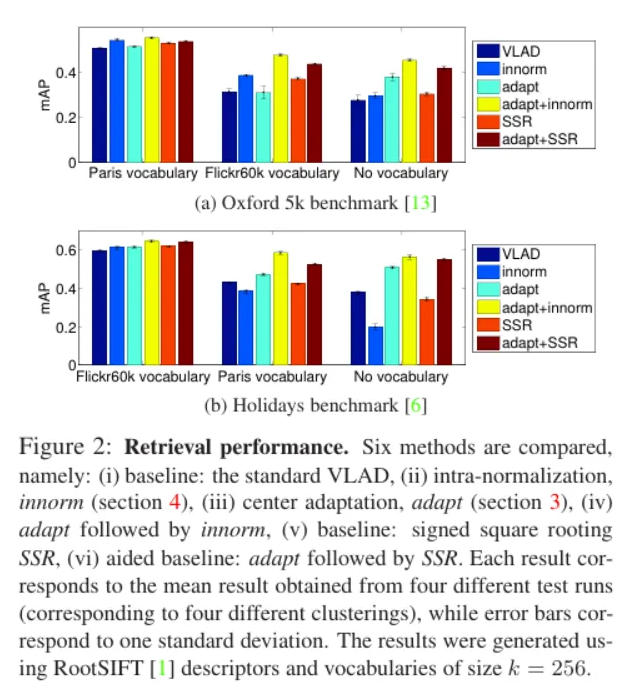
center adaptation과 innorm를 함께 적용했을 때 위 결과에서 확인할 수 있는데요 모든 경우에 대해 성능이 향상됐었습니다. 그리고 다른 방법보다 제일 높은 성능을 냈습니다
5. Multiple VLAD descriptor
저자가 제안한 contributions 중 이제 마지막 방법론입니다. 해당 방법은 이미지 하나를 하나의 벡터만으로 표현하는 게 아닌 이미지를 tiling해 (다른 크기의 패치로 나눠 각 패치에서의 벡터를 계산한 후 concatenate함) 나타내는 방법을 제안합니다. 우선 저자는 14개의 패치로 tiling하는 14MultiVLAD을 계산합니다. 같은 크기로 3×3로 나눈 finest scale에서의 tile, 2×2 로 나눈 medium scale의 tile, 그리고 이미지 전체를 하나로 보는 tile까지 해서 총 14개의 패치로 나눠 VLAD 벡터를 구하는 것입니다. 그리고 이를 가지고 하나의 이미지ㅡㅌ 나타내는 것입니다. 해당 방법은 작은 물체에 대해서도 retreival 성능을 향상시키는 방법인데요 이를 localization에서도 적용해볼 수 있습니다. 논문에서는 이를 localization으로 적용한 게 주인 것 같았습니다.
기존 보다 14배의 저장 공간을 필요로 하지만 단독 이미지에 대해서 나타냈을 때
Implementation detatils
grid로 나눌 때는 각 grid가 같은 크기로 나눠지도록 합니다. 특징이 거의 없는 가장자리 부분을 제외하기 위해 모든 특징점을 포함하면서도 제일 크기가 작도록 조정한다고 합니다.
5.1.Fine object localization
쿼리 이미지에서의 ROI와 데이터베이스 이미지의 각 타일과 유사도를 비교해 쿼리 객체가 result image에 어디에 위치해 있는지를 알 수 있습니다. 쿼리 ROI와 결과 이미지에서의 각 grid를 나타내는 두 VLAD 간의 유사도와 각 영역의 겹치는 정도가 상관관계를 가지고 있습니다. (같은 객체에 대해서 ROI와 grid의 크기가 비슷하지 않을까란 생각에서 시작된 것이었습니다. 실제 그 상관 관계 또한 확인이 됐습니다.) 이런 특성을 활용해 선형 회귀의 방법으로 쿼리 객체를 result image 에서 찾습니다.
다음은 그 식입니다.
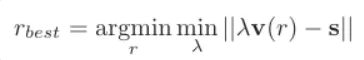
s는 ROI VLAD와 result image의 한 tile의 VLAD간의 유사도가 되겠습니다. v(r)은 ROI가 해당 tile과의 overlap입니다. result image에서 ROI가 image tile과의 overlap이 유사도와 같은 grid를 찾는 방식인 셈입니다. 식에서 residual을 최소화하는 람다를 찾는 것은 least square 문제를 푸는 것과 같습니다.
Localization accuracy
localization에 대한 평가를 진행하기 위해 GT ROI와 predicted ROI간의 겹쳐진 비율로 확인하였는데. 각 쿼리마다의 이 값의 평균을 구한 것으로 평가 지표로 사용했습니다. MultiVLAD로 center adaptation과 intra-normalization을 적용해서 Oxford 5k에 대해서 localization 성능을 확인한 결과 0.518의 mAP가 나왔습니다.
6. Results and discussion
6장에서는 cluster center adaptation과 intra-normalization를 기존 연구의 방법론과 비교해보았습니다. 다음은 해당 실험에서의 적용된 설정들과 채택한 방법론에 대한 설명입니다.
우선 RootSIFT descriptors를 가지고 VLAD 벡터를 총 256개의 클러스터로 clustering을 진행했고요 Paris, Flickr60k 데이터셋으로 만들어진 vocabulary를 가지고 Oxford5k, Holidays 데이터셋에 대해 실험을 진행했습니다.
Full size VLAD descriptors

차원축소를 하지 않아 상당히 큰 차원의 VLAD 벡터를 가지고 retrieval 성능을 확인한 실험입니다. center adaptation과 intra-normalization을 함께 수행한 경우 기존 모델 보다 우수한 성능을 보였습니다. Holidays 데이터셋에서 같은 경우 기존의 제일 성능이 좋았던 Improved Fisher method 보다 3.2% 증가한 성능을 보였습니다. Oxford 5k에 대해서는 4.3%의 향상을 보였습니다.
Small image descriptors(128-D)
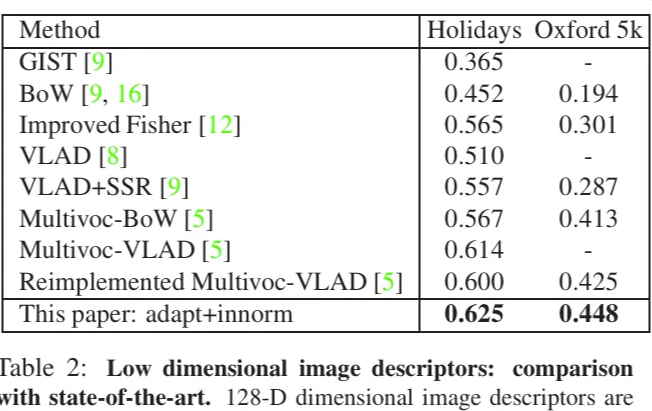
한 이미지에 대해 여러 vocabulary 마다 여러 VLAD 벡터를 계산하고 이렇게 증가된 차원을 PCA와 화이트닝 연산으로 차원을 축소한 것에 대해서 기존 메소드와 retrieval 성능을 비교한 실험입니다. Oxford 5k에 대한 실험에서는 Paris vocabulary를 사용합니다. (하나의 데이터셋으로도 여러번 clustering을 진행하게 되면 서로 다른 vocabulary를 얻게 되는데 이를 가지고 VLAD 벡터를 계산하는 것이 Multivoc 기법입니다.) Holidary 에 대한 실험에서는 Flickr1M 데이터셋에서 마지막 10k개의 이미지를 가지고 vocabulary를 생성하고 PCA를 학습합니다. 실험 결과 SoTA인 방법 보다 각각 5.4%, 1.8%의 성능 향상을 보였습니다. 본 연구에서 제안하는 adapt + innorm의 방법을 사용했을 때 벡터의 차원을 줄여도 기존 방법보다 성능이 우수하다는 것을 확인할 수 있는 실험이었습니다.
Effect of using vocabularies trained on different datasets
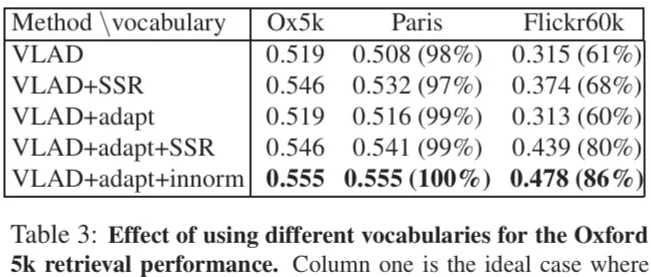
이 실험은 실험에서 사용하는 데이터셋 과 다른 데이터셋으로 만들어진 vocabulary로 학습했을 때의 성능차이와 본 연구에서 제안하는 방법을 적용했을 때의 개선 정도를 확인하기 위한 실험입니다. 우선 실험을 진행하는 Oxford 5k에 대해서 vocabulary를 구성하는 경우 성능이 제일 좋습니다. 그리고 모든 메소드에서 다른 데이터셋인 Paris나 Flickr60k로 만든 vocabulary를 가지고 retrieval을 진행한 경우에는 떨어지는 경향을 확인할 수 있는데요 이때 adapt + innorm의 방법을 사용했을 때 하락하는 정도가 제일 낮습니다. 저자가 제안하는 방법이 inconsistent한 cluster를 갖는 상황에서 적용됐을 때 성능을 높게 유지할 수 있는 방법이라고 할 수 있겠습니다.
7. Conclusion
기본 VLAD 방법론의 성능 개선을 위한 방법으로 저자가 제안한 3가지 contribution에 대해서 각각 살펴보았습니다. 정리하자면 1) cluster center adaptation 2) intra-normalization 3) MultiVLAD 가 있었습니다. 1) cluster center adapation은 데이터베이스에 이미지가 계속해서 무수한 양이 추가되는 경우 매번 vocabulary를 다시 생성하는 데의 비용 부담을 줄이고자 제안한 방법으로 cluster마다 데이터의 local descriptor의 평균으로 center를 조정하는 방법이었습니다. 2) VLAD 벡터의 일부 bursty한 elements를 억제하기 위한 방법으로 intra-normalization 이 제안됐었습니다 기존의 전체 벡터를 L2 정규화하는 것과 SSR을 수행하는 것 보다 각 차원에서의 energy를 줄일 수 있는 방법이었습니다. 3) MuliVLAD 방법은 작은 객체에 대한 image retrieval 성능을 향상시키는 방법이면서도 논문에서 다뤘던 localization을 가능하게 하는 방법이기도 했습니다. 이후 실험으로 center adaptation의 방법이 inconsistent한 cluster center를 갖는 상황에서 성능 개선에 효과적이라는 것과 여기다가 추가적으로 intra-normalization을 적용한 것이 burstiness를 줄이고 VLAD의 차원을 축소해도 성능을 유지시킴을 확인하였습니다.
안녕하세요 류지연 연구원님 좋은 리뷰 감사합니다.
VLAD는 local descriptor로 SIFT를 사용하고 있는데, SIFT를 사용하는 특별한 이유가 있나요? SIFT 외의 다른 알고리즘을 통해 local descriptor를 생성하게 되면 VLAD 알고리즘에 어떠한 차이점이 생기는 지 궁금합니다.
추가로, image간의 유사도를 판단하는 과정에서 영향을 끼처 잘못된 매치를 내는 burstiness 문제를 Intra-normalization을 통해서 VLAD는 해결하였는데, 전체 VLAD 벡터를 L2 정규화하는 것는 왜 이러한 burstiness 문제가 생기는 지 궁금합니다. 나이브하게 생각했을 때 모든 벡터의 크기를 균등하게 스케일링하기에 특정 feature에 치중되는 것을 방지할 수 있을 것 같은데 image 간의 유사도를 판단할 때 왜 잘못된 매치가 생기는 지 궁금합니다.
감사합니다.
1) 논문에서 여러 알고리즘을 두고 SIFT를 사용한 이유에 대해서는 서술돼 있지 않은데요 다른 알고리즘을 사용했을 때 생기는 차이점에 대해서는 잘 모르겠지만 SIFT descriptors는 우선 회전, 스케일 변화에 강인한 표현방법이고 이에 이미지 매칭으로 성능이 검증이 되었다는 점 또한, 고차원의 벡터로 표현된다는 점에서 VLAD에 적용해서 쓰기에 적절했기 때문에 사용하지 않았을까 생각됩니다.
2) 기존에 전체 벡터에 L2 정규화를 하던 방법 자체가 burstiness 문제를 일으키는 것은 아니고요 원래 VLAD 벡터 자체가 가지는 문제인데 L2 정규화만으로는 충분히 bursty 한 feature의 영향을 줄이지 못하기 위해서 SSR이나 이 논문에서 제안하는 Intra norm이 사용된다고 보시면 되겠습니다.
질문 주셔서 감사합니다.
안녕하세요 지연님 리뷰 감사합니다.
Vocabulary Adaptation 방법론에서, 새로운 이미지의 local descriptor를 기존 codebook의 클러스터에 할당한 후, 각 클러스터에 속한 descriptor들의 평균을 새로운 클러스터 센터로 사용하는 방식이 기존 codebook과 inconsistency 문제를 어떻게 효과적으로 완화하는 것인지 약간 이해가 덜 됐는데 조금만 설명을 해주실 수 있을까요??
네 안녕하세요 영규님 댓글 감사합니다
기존의 데이터베이스 descriptor로 구성된 cluster에 새로운 이미지셋의 local descriptor들이 할당이 될텐데요 adaptation을 적용하고 나면 물론 새로운 이미지셋에서 독립적으로 clustering 했을 때의 그 cluster center와 완전 같아지지는 않겠지만 그 효과를 비슷하게 낼 수 있는 방법입니다. 기존의 cluster center를 새로 들어오는 데이터셋에 맞게 조정하는 작업인 것입니다. 그리고 adaptation 전 기존 cluster로 한 번 local descriptor들이 모이기 때문에 이전 데이터베이스의 정보가 없어지는 것도 아닙니다. cluster의 위치에 따라 같은 데이터 분포를 가지더라도 잔차를 누적한 합에 대한 벡터가 가리키는 방향이 완전히 다를 수 있다는 게 논문에서 지적한 inconsistency 문제입니다. adaptation의 방법으로 cluster center의 위치를 조정함으로써 새로 들어온 데이터셋이 가지던 분포가 유지될 수 있게 합니다.
감사합니다.
안녕하세요 지연님, 좋은 리뷰 감사합니다.
뭔가 3가지 방법론중 center adaptation이 제일 유의미한 성능차이를 낼 줄 알았는데 최종 여러 vocabulary 에 대한 성능표를 보면 과적합이 되는건지 성능이 비슷하거나 오히려 떨어지는 모습이 보여서 어떻게 생각하시는지 궁금합니다.
물론 해당 방식에 innorm 까지 적용하는게 가장 성능유지가 잘 되지만 생각 알려주시면 감사하겠습니다.
우선 adapation 자체가 VLAD 벡터를 더 잘 표현하는 방법이 아니여서 해당 방법 자체가 retrieval 성능을 개선시키지 못했을 것입니다.
Table 3. 실험에 대해 조금 더 설명을 드리면요 Oxford 5k 데이터셋의 이미지에 대해서 서로 다른 vocabulary를 사용하면서 cluster center의 inconsistency 문제를 확인하고 adapt를 사용했을 때 이 문제가 보완이 되는가를 확인한 실험입니다. 첫 colum은 retrieval 데이터셋과 동일한 데이터셋으로 vocabulary를 구성한 것이고, Paris vocabulary는 다른 데이터셋이지만 건물 이미지란 점에서 상당히 비슷합니다. 반면 Flickr60k 데이터셋은 Oxford 5k와는 많이 다른 데이터셋입니다. 그래서 table에도 확인할 수 있듯 Ox5k, Paris, Flickr 순으로 성능이 낮아지는 경향을 띄고있습니다.
adapt의 성능 향상에 기여하는 바를 확인하기 위해 table에서 (VLAD, VLAD + adapt), (VLAD + SSR, VLAD + adapt + SSR) 을 비교하면 확인이 쉽습니다. adapt를 적용했을 때 vocabulary와 다른 데이터셋으로 retrieval 을 진행해서 생기는 성능하락을 adapt로 어느정도 막아준다는 것을 확인할 수 있습니다.
감사합니다!
안녕하세요 지연님,
Vlad교육을 저희가 같이받았었는데 추가적으로 더 조사하신거같아서 제가 몰랐던점도 알아가는거같습니다
리뷰에서 소개해주신 MultiVLAD 방식이 새로웠는데 localization 성능 향상에 효과적이었다는 점은 인상 깊었습니다.
다만 개인적으로는, 이미지 전체를 여러 타일로 나누고 각각에 대해 VLAD 벡터를 계산해 concat하는 구조 특성상, 오히려 노이즈나 중복 정보가 많아져서 기존 단일 VLAD 방식보다 localization에서는 성능이 저하되지 않을까 하는 의문이 들었습니다.
실습진행하셨다고 하셔서 혹시 성능이 좋아졌을까요? 궁금합니다
네 충분히 우려가 될 수 있는 부분이라고 생각이 듭니다. 저도 이 부분을 고려하면서 실습을 진행했었던 것 같네요
실습 같은 경우에는 localization을 직접 수행한 것은 아니고 SVM을 학습시켜서 이미지를 분류하도록 하였는데요
기존의 VLAD 벡터로 나타내는 것 보단 이미지를 총 14개의 영역으로 분할한 후 각 영역에 대해 VLAD 벡터를 구하고 이어붙인 방법이 7%의 정확도 향상을 이끌었습니다.
감사합니다
안녕하세요 지연님 좋은 리뷰 감사합니다.
저도 all about VLAD라는 논문을 그래도 최근에 읽었었는데, 지연님 리뷰 덕분에 놓쳤던 부분에 대해서 바로 잡고 갈 수 있었던 것 같습니다.
저는 해당 논문을 읽었을 때, Vocabulary Adaptation부분에 대해서 의문점을 가지면서 읽었었는데, 지연님께서는 해당 부분에 대해서 어떻게 이해하셨는지 궁금해서 답글 드립니다.
저는 cluster adaptation 시 기존 cluster center를 새로운 descriptor의 평균으로 바꾸는 과정이 있었고 이렇게 cluster의 센터를 업데이트를 시키는 것이 기존 center의 의미가 사라지지 않을 까 생각을 했습니다. 기존 center는 원래 vocabulary 데이터 분포를 반영하고 있었는데, 이를 바꾸는 것이 기존 데이터셋과의 일관성을 해치지 않을까 생각이 듭니다! 혹시 이 부분에 대해서 똑같이 고민하신적 있다면 이에 대해서 설명해주시면 감사할 것 같습니다!
그랬다니 앞으로도 리뷰 쓸 때 더 신경 써서 작성해야 겠다는 생각이 드네요!
네 저도 같은 지점에서 의문이 들었었는데요 아무래도 새로운 descriptors만을 가지고 평균을 구하고 그걸 cluster center로 정의한 다음 VLAD 벡터를 구하는 거라 아무래도 기존 데이터셋의 descriptor 정보는 손실이 되는 게 아닌가 하는 생각이 저도 들었었습니다.
클러스터링을 다시 수행해 얻는 cluster center와 adapation으로 조정된 center간의 차이는 분명히 있을 것이기 때문에 정보 손실이 아예 없을 수는 없을 것 같습니다. 다만 이런 손실이 있더라도 간단하게 새로운 데이터셋에 맞게 조정하는 게 더 나은 방법이었기 때문에 사용하는 게 아닐까 싶습니다. 또한 그래도 기존 cluster 자체는 유지한 채로 adaptation이 진행되기 때문에 어느정도 기존의 데이터를 가지고 있다고 봐도 괜찮지 않을까 생각해봅니다.