안녕하세요, 62번째 x-review 입니다. 이번 논문은 WACV 2025 oral paper로 게재된 논문으로, 제가 최근에 읽었던 논문들과 동일하게 Marigold를 베이스로 하는 depth estimation 논문 입니다.
그럼 바로 리뷰 시작하겠습니다 !
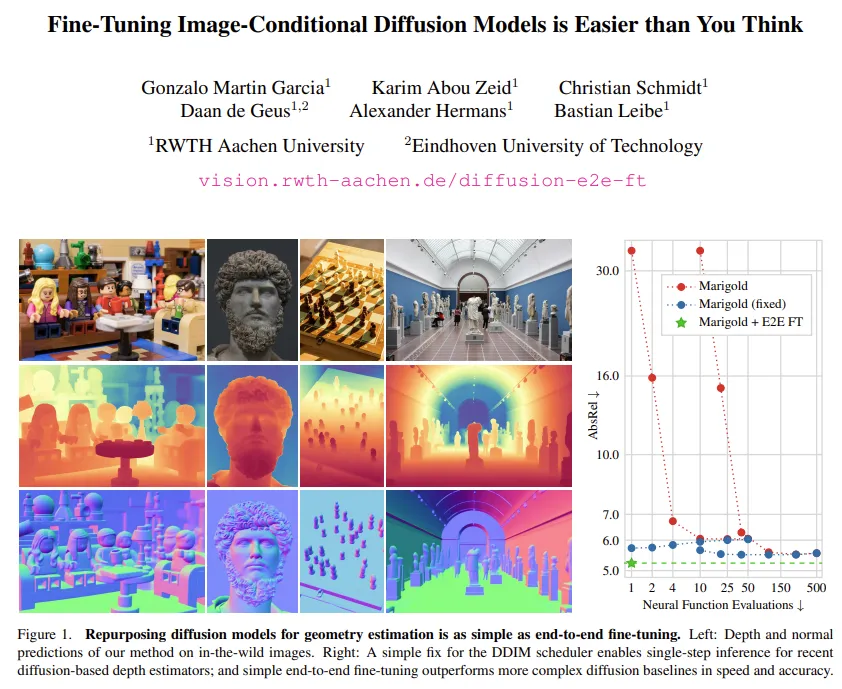
1. Introduction
Monocular Depth Estimation(MDE)는 기본적으로 스케일 모호성이 존재하기 때문에 학습 기반의 방법론들이 잘 동작하기 위해서는 의미론적인 prior를 잘 활용할 수 있어야 한다고 합니다. 그러한 이유로 최근에는 MDE에 conditional diffusion task를 적용하는 연구들이 많이 등장하고 있습니다. 이는 매우 디테일한 정보까지 살리는 depth map을 예측할 수 있지만, diffusion을 사용하기에 속도가 느리다는 한계가 존재하죠. 속도가 느린 이유 중 하나는 수십번의 time step을 거쳐서 denoising을 거쳐야 하기 때문인데, 본 논문의 저자는 Marigold와 그 후속 연구들의 inference에서 단 한 번의 step만으로도 합리적인 예측을 할 수 있어야 한다고 주장합니다. Marigold를 분석해본 결과, 일반적인 50-1000개의 step을 써서 depth를 복원하는게 아니라 few-step, 즉 1-4개 step 정도로 복원해보면 사용할 수 없을 정도의 결과를 보였다고 합니다. 사실 이러한 적은 step에서의 diffusion 성능 하락은 이미 많이 알려져 있지만, 저자는 특히나 Marigold와 같이 이미지 조건부 방법론들에서는 성능이 하락되는 원인을 잘 분석해야 한다고 이야기 합니다. 이 말이 모델 자체가 적은 step으로 depth를 복원하는데 한계가 있는 것일 수도 있지만, denoising step의 수를 줄일 때 노이즈 스케줄 계산을 잘못하거나 latent scale, 정규화 처리 등 모델을 쓰는 방식이 틀렸을 수도 있다는 것 입니다. (논문에서는 이를 “버그”라고 표현하네요)
그래서 저자는 버그에 대해 약간만 수정하여 Marigold를 비롯한 유사한 모델들에서 단일 스텝만으로 200배 빠른 속도로 여러 스텝의 inference 결과와 유사한 성능을 얻을 수 있었다고 합니다. 이렇게 inference를 단순화하면서 diffusion 모델이 기존의 discriminative 모델처럼 빠르게 동작할 수 있게 됩니다. 거기에 추가적으로 Marigold를 scale와 shift invariant loss를 사용해서 end-to-end로 fine tuning하였는데, 이러한 구조가 Marigold 기존의 베스트 세팅보다 더 좋은 성능을 보였다고 합니다. 거기에 surface normal task도 동일하게 해봤는데 마찬가지였으며, 아예 stable diffusion 역시도 fine-tuning을 통해 개선했다는 것 입니다. 즉, 논문에서 말하고자 하는건 현재 생각보다 너무 어렵게 diffusion을 쓰고 있는데, 그냥 간단하게 fine-tuing만 해도 충분히 더 잘 작동한다는 걸 확인한 것이죠.
정리하면, 복잡한 멀티 스텝 inference나 generative 방식 없이도 간단한 deterministic 모델로도 더 빠르고 정확하게 동작이 가능하다는 것이고, diffusion 모델을 downstream task에 바로 fine tuning하는 접근 방식이 유의미하다는 것 입니다.
2. Image-Conditional Latent Diffusion Models
2.1. Marigold

Fixing Single-Stem Inference
본 논문은 Marigold의 구조를 Single-Step으로 변형하였으며, 대부분의 방법론 내용이 Marigold 동작 내용에 대한 설명인데, Marigold에 대한 내용은 이전 리뷰를 참고해주시면 좋을 것 같습니다.
기존의 Marigold inference 과정을 보면, Fig.2(b)와 같이 50 step별 픽셀 단위의 표준 편차를 확인해볼 수 있습니다. 거의 모든 픽셀에서 큰 차이 없이 모델이 inference 중에 하는 예측이 거의 변하지 않는데요, 이는 첫번째 step이 이미 최종 출력과 거의 일치한다는 걸 의미합니다. 그러면 단일 스텝으로 inference를 했을 때 비슷한 결과라 나올거라고 기대할 수 있는데, 막상 단일 스텝으로 해보면 Fig.2(c)와 같이 완전 노이즈에 가까운 결과가 나오게 됩니다. 그 이유를 저자는 모델이 받아들이는 타임스텝 정보와 실제 입력되는 노이즈 수준이 불일치하기 때문이라고 분석합니다. 단일 스텝으로 inference를 하면 모델은 마치 거의 완벽한 depth map을 받아야 한다고 이해하는데, 실제로는 노이즈만 들어와서 모델이 그냥 노이즈를 그대로 출력해버리는 것이죠. 그래서 간단하게 타임 스텝을 실제 입력 노이즈 레벨과 align을 맞춰주면 될거다고 가정했고 그러기 위해서 trailing 세팅을 활용했다고 합니다. 해당 세팅은 이전 연구에서 제안된 것으로, 타임스텝을 노이즈 수준과 일치시키는 것 입니다.
더 자세히 얘기하면, 원래 diffusion 모델은 inference할 때 노이즈를 조금씩 제거하면서 이미지를 복원해가는 방식인데, 어떤 타임스텝 순서로 노이즈를 제거할지 정하는 규칙이 필요하게 됩니다. 원래 diffusion의 DDPM은 50, 100, 그 이상의 큰 스텝을 설정해서 denoise하게 되는데, 실제로 inference 할 때는 빠른 속도를 위해 1, 4, 10과 같이 짧은 스케줄로(DDIM) 설정하는 경우가 있죠. 이렇게 짧은 스케줄을 짤 때 어떤 타임 스텝을 뽑아서 진행할지 정해야 하는데, 이 때 leading이나 trailing이라는 두 가지 스케줄 방식이 있다고 하네요. 여기서 trailing 스케줄은 가장 마지막의, 완전 노이즈 상태부터 시작해서 노이즈를 제거해나가는, 즉 입력이 완전 노이즈인 것을 가정하고 시작하기 때문에 모델이 기대하는 입력과 맞게 되는 것이죠. 지금 원하는 목표가 단일 스텝에서 한번에 답을 내야 하는 구조이기 때문에 시작이 틀리면 아예 답이 노이즈로 발생하게 돼서, trailing 스케줄을 단일 스텝 inference에서 설정하는게 중요한 부분이 됩니다. trailing 설정으로 고쳐서 inference 했을 때 Fig.2(d)를 보면 원래의 Fig.2(c) 결과보다 훨씬 더 유의미한 결과를 뽑을 수 있다는 걸 알 수 있습니다.
3. End-to-End Fine-Tuning of LDMs
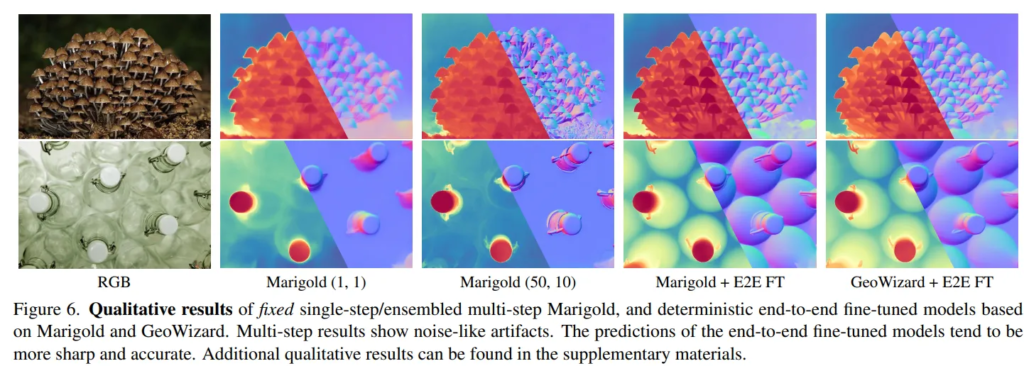
Diffusion 모델로 depth를 예측하면 보통 성능도 높고 디테일을 잘 잡고 있는데, 다만 출력이 블러 현상이 나타나거나 샤프닝 혹은 아티팩트들이 생기게 됩니다. Fig.6을 보면 멀티 스텝으로 출력했을 때 아티팩트와 같은 노이즈 결과가 있는 걸 볼 수 있습니다.
왜 이런 문제가 발생했는지 보면, 학습 loss 자체가, diffusion 모델이 기본적으로 denoising만 잘 하라고 학습된다는 것 입니다. depth estimation과 같은 downstream task를 위해 학습된게 아니라서 depth를 얼마나 잘 맞출지를 학습에 반영할 필요가 있다는거죠. 그래서 본 논문에서는 단순히 노이즈를 잘 제거하라는 걸 넘어서 depth map을 정확하게 만드는 것을 목적으로 diffusion 모델 전체를 아예 end-to-end로 다시 fine-tuning 합니다. 그런데 end-to-end로 fine-tuning이려니 diffusion 모델이 보통 수억 개 이상의 파라미터와 수백 스텝의 반복적인 과정을 거쳐서 이걸 다 backpropagation 하기에는 메모리와 연산량이 너무 많이 들게 됩니다. 그래서 앞선 inference 파이프라인 수정을 먼저 한 것인데, 단일 스텝 결과로 이미 의미있는 depthmap이 나오니까 한번만 backpropagation 할 수 있고 end-to-end fine tuning이 가능해지는 것 입니다.
어떻게 했는지 fine-tuning 과정을 보면, 원래 diffusion 학습에서는 매번 랜덤하게 타임스텝을 샘플링했는데, 이제는 항상 최대 타임스텝 T으로 고정해서 학습을 합니다. 왜냐면 단일 스텝으로 inference 하는걸 목표로 하기 때문에 완전 노이즈 상태로 처리하는걸 항상 학습할 수 있도록 하는 것 입니다. 다만 이제는 T가 원래 의미하는 완전 노이즈 상태는 실제로 적용되지 않고, 그저 모델 입력 포맷을 깨지 않기 위한 형식적으로 주는 값일 뿐이라고 합니다. 그리고 원래는 노이즈 \epsilon을 추가했는데 이제는 노이즈를 0으로 세팅합니다. 즉, RGB 이미지 latent만 입력으로 하고, depth latent는 노이즈 없이 예측하도록 만드는 것이죠. 이 예측된 latent를 VAE 디코더로 depth map을 복원하는데, 복원되는 depth map은 GT depth map과 비교해서 loss를 계산 합니다. 앞서 이야기한 것처럼 depth estimation에 맞게 loss를 짜기 위해 식(1)과 같이 affine-invariant loss를 사용했다고 합니다.
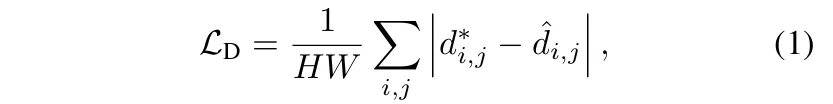
단순히 픽셀별 차이를 비교하는게 아니라, scale과 shift를 맞춰서 비교하는 방식을 사용했다고 합니다. \hat{d}=s \cdot d + t로 해서, 여기서 s,t과 각각 least-squares fitting으로 찾은 scale과 shift가 됩니다.
그 다음은 monocular depth map을 예측할 때 값만 정확한 걸 떠나서 기하학적인, surface normal 같은 것도 정확해야 하는데요, 이런 기하학적 퀄리티를 위해서 식(2)와 같이 surface normal loss를 추가하였습니다.
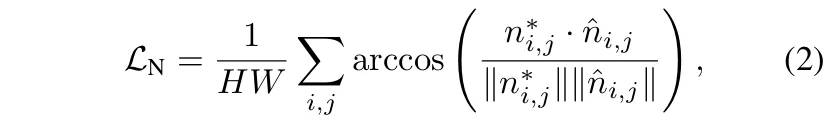
- n^*_{i,j} : 픽셀 (i,j)에서 GT surface normal
- \hat{n}_{i,j} : 예측한 surface normal
surface normal 예측에 대해 추가적으로 설명되어 있진 않지만, depth map에서 local 기울기를 계산하여 normal vector로 변환한 다음에 GT depth에서도 마찬가지로 local 기울기를 계산해서 두 normal vector의 각도 차이를 계산합니다. 그 다음에 각도 차이가 작아지도록 식(2)와 같이 loss 계산을 한다고 이해해주시면 좋을 것 같습니다.
이렇게 depth 값이 만약 좀 틀리더라도, surface normal이 정확하면 물체의 형태나 구조를 제대로 재현할 수 있기 때문에 단순히 depth 차이로 알 수 없는 기하학적인 구조까지 fine-tuning하기 위해 추가했다고 볼 수 있을 것 같네요.
4. Experimental Evaluation
학습 데이터는 기존의 Marigold와 동일하게 합성 데이터인 Hypersim, Virtual KITTI 2를 사용했다고 합니다. 평가 데이터는 monocular depth estimation에서 흔히 쓰이는 indoor 데이터인 NYUv2, ScanNet을 사용했습니다. indoor, outdoor를 모두 포함하는 데이터로는 ETH3D, DIODE를 사용했고 마지막으로 outdoor driving scene에 대해서는 KITTI로 평가하였네요.
Comparison with Marigold
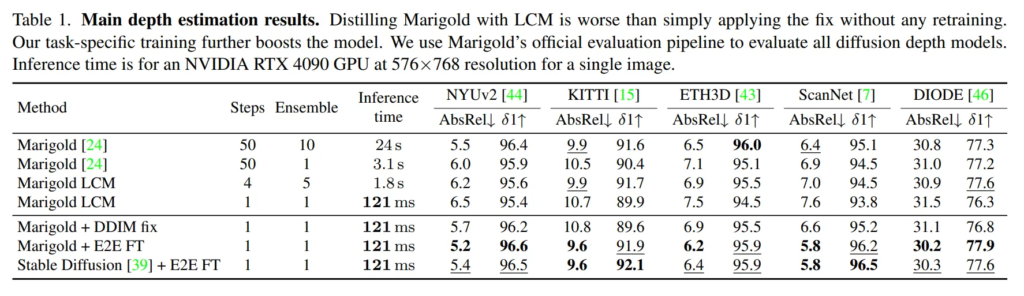
Tab.1은 Marigold와의 비교 실험 입니다.
우선 Marigold LCM에서 step 4에 앙상블 5번으로 평가하였을 때와 단일 스텝으로 변경했을 때를 비교하면, 단일 스텝에서 성능이 크게 떨어지는 것을 확인할 수 있습니다.
또한 Marigold+DDIM fix → 본 논문에서 DDIM 스케줄을 수정한(trailing 방식으로) Marigold는 단일 스텝만으로 기존의 Marigold(50 스텝, 앙상블 10번)보다 더 나은 성능을 보이고 있습니다. 특히나 앙상블 없이도 단일 스텝만으로 문제가 되었던 성능 하락과 추론 속도를 모두 보완할 수 있게 된 것 입니다. 거기에 E2E FT(end-to-end fine-tuning)까지 하면 DDIM 스케줄만 수정한 것보다도 더 좋은 성능을 보이며 본 논문에서 제안하는 fine tuning의 효과를 보여주고 있습니다. 즉 원래 Marigold의 여러 스텝의 denoising, 그리고 앙상블 없이도 훨씬 좋은 성능을 보일 수 있고 diffusion의 고질적인 한계였던 추론 속도까지 해결할 수 있다는 것을 어필하고 있습니다.
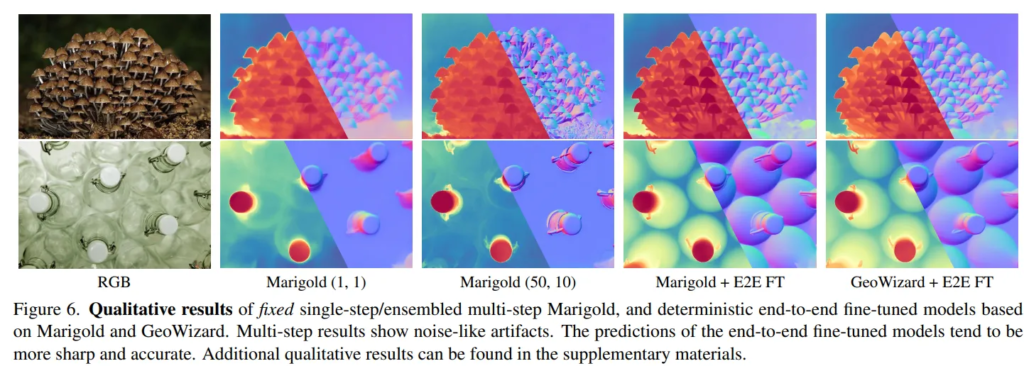
Fig.6은 앞서도 보여드렸던 정성적 결과로, 단일 스텝의 모델은 선명한 결과를 생성하지 못하는 블러한 depth map을 만들고 반대로 여러 스텝의 앙상블 방식은 디테일한 영역을 왜곡하여 노이즈가 발생하게 됩니다. 이러한 결과에 E2E FT을 추가로 진행하면 depth map과 surfac e normal에서 모두 노이즈는 사라지고 디테일한 영역을 잘 표현하면서 가장 정확한 결과를 얻을 수 있다는 걸 보여주고 있습니다.
State-of-the-art Landscape
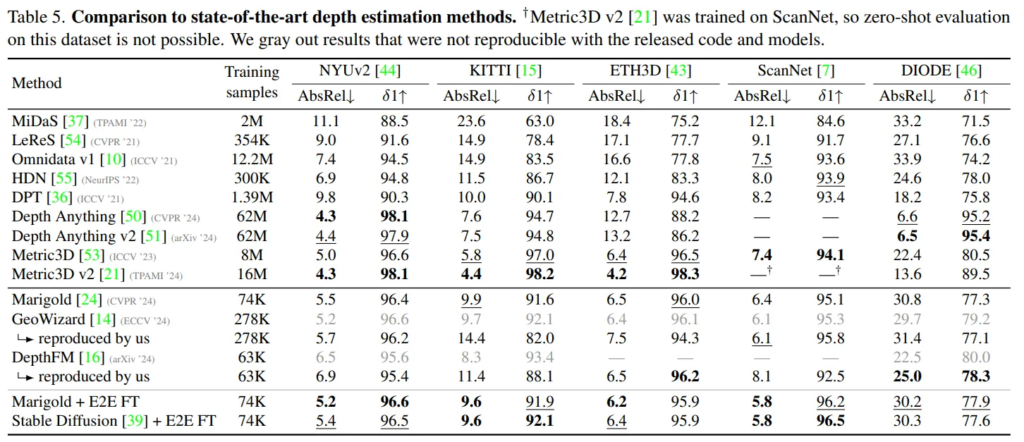
Tab.5는 본 논문의 fine-tuning 방식이 대부분의 데이터셋에서 depth를 추정하기 위한 기존의 생성 모델 기반 방법론보다 좋은 성능을 보인다는 결과의 실험 입니다.
생성형 모델 기반이 아닌 Depth Anything, Metric3D는 모두 좋은 결과를 보이지만, 이러한 방법론들은 생성 모델 대비 2-3배 가량 큰 데이터셋에서 학습을 하게 되죠. 따라서 보다 적은 데이터셋을 사용해서 간단한 fine-tuning을 적용했을 때 좋은 성능을 보일 수 있는 본 논문의 방식의 효과에 대해 강조하고 있습니다.
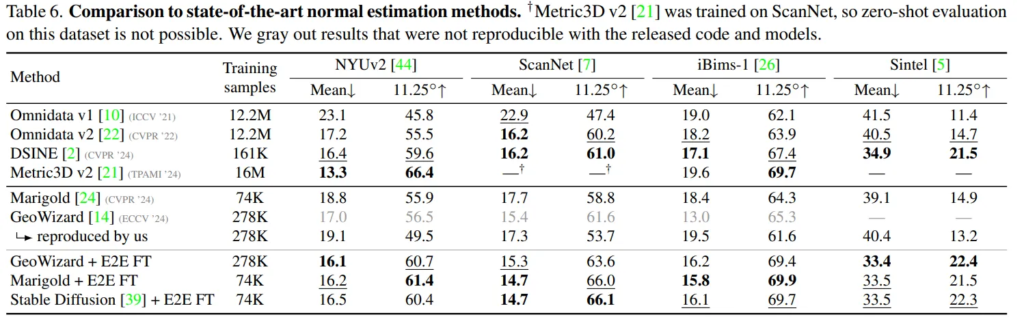
마지막으로는 비슷하게 surface normal 추정 방식과 비교하고 있는데, 이에 대해서는 크게 분석은 없고, depth estimation과 동일하게 FT을 적용했을 때 생성형 모델 중에서 가장 높은 성능을 달성했다는 것만을 어필하고 있습니다. 이를 통해 본 논문에서 fine-tuning 학습에 사용하는 loss 중 surface normal에 대한 loss를 추가한 것이 그 자체만으로도 추정에 효과적이며 depth map을 예측하는데도 기하학적인 요소에 대한 퀄리티 향상에 도움이 된다는 것을 어필하고자 한 것이 아닐까 싶습니다.
재밌는 논문 감사합니다.
정리하자면, fine-tunning을 하는데 가장 노이즈가 많이 가해진 ~ gaussian noise에서 바로 latent도 노이즈 없이 입력 받아 Depth를 예측하도록 하면 단일 스텝으로 예측이 가능해지면 또한 성능도 무시 못할 성능을 보인다라고 이해했습니다. 다른 태스크에도 테스트 해봐도 좋은 연구네요
그럼 질문이 있습니다.
Q1. Fine-tunning 없이 학습을 한 실험은 없을까요? 어느 정도 잘하는 모델을 튜닝만 하는 용도인지 궁금합니다.
Q2. 어떠한 기법도 저자가 제안한 Loss를 사용해야하나요? 다른 기법에 다 끼울 수 있다는 것 같은데 다른 기법에 fine-tunning을 하더라도 저자가 제시한 loss를 사용했는지 궁금합니다.
Q3. Tab 5를 보면 저자가 제안한 기법을 주입한 모델이나 기반 모델이나 동일한 training samples가 동일한 값이 작성되어져 있습니다. fine-tunning에 사용되는 데이터 수는 어느정도 되는 걸까요?
안녕하세요, 리뷰 읽어주셔서 감사합니다.
1. 우선 본 논문에 리포팅된 실험에서는 Fine-tuning 없이 학습을 한 실험은 없습니다. 애초에 논문 contribution 자체가 Marigold와 같이 여러 스텝으로 동작하는 diffusion 모델을 fine-tuning해서 빠르게 동작시켜보자여서 그런지 말씀하신 실험은 따로 있진 않았습니다.
2. 다른 기법이 정확히 어떤걸 말씀하시는 지는 모르겠지만, depth estimation을 위한 diffusion 기반의 모델에서는 저자가 제시한 loss를 사용하는게 맞는 것 같습니다. 저자가 수행한 다른 task는 surface normal estimation인데 이는 저자가 제시한 loss 중에 surface normal 예측 loss 부분만 떼서 진행했다고 이해하였습니다.
3. Tab.5에 적혀있는 학습 샘플은 fine-tuning 말고 학습 때나 사전학습 때의 데이터 수를 의미합니다. fine-tuning을 위해서는 Hypersim 데이터 중 90%, Virtual KITTI2에서 10%를 이용해서 fine-tuning 했다고 합니다.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
DDPM에 비해 DDIM이 inference에서 step 수를 일부 선택함으로써 inference 속도를 줄이는 방식이라고 이했습니다. 근데 여기서 헷갈리는 부분이 Marigold가 원래 DDIM인데 세팅만 leading이어서 이를 trailing이라고 변경한 것인가요 ?!? 아님 Marigold가 inference 역시도 DDPM인데 이를 DDIM으로 바꾸고 거기에다가 trailing 방식으로까지 변형한 것인가요 ?
추가로 Tab.1에서 Marigold 뒤에 LCM은 무엇을 의미하는지 간단하게만 설명해주시면 감사하겠습니다.
감사합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
먼저 원래 Marigold의 inference도 마찬가지로 DDIM으로 되어있으며 이를 trailing이라고 변경한 것이 맞습니다.
LCM이라는건 정식 Marigold의 논문 버전의 코드가 아니라 Latent Consistency Model 기반으로 distillation해서 경량화한 버전을 의미합니다.
감사합니다.
안녕하세요 손건화 연구원님. 리뷰 잘 읽었습니다.
1. End-to-end fine-tuning 과정에서 입력 노이즈를 0으로 고정했다고 했는데, 이렇게 하면 모델의 일반화 성능이나 OOD(Out-of-Distribution) 데이터에 대한 robustness에는 문제가 생기지 않을까요?
2. 단일 스텝으로 inference를 빠르게 하는 데 성공했지만, 이 접근법이 과연 high-resolution 이미지(예: 4K 해상도)에도 여전히 잘 작동할 수 있을까요?
안녕하세요, 리뷰 읽어주셔서 감사합니다.
1. 모든 경우의 데이터에 대해서 robustness를 가진다고 섣불리 말할 순 없지만, 위의 실험 리포팅 결과가 어쨌든 zero-shot 세팅에서 여러 데이터에 대해 성능을 평가한 것이라서 기존의 연구들에 비해 일반화를 잘 갖추고 있다고 말할 수 있을 것 같습니다.
2. 해당 논문의 데모 사이트를 들어가서 보면 권장되는 resolution이 784×784로 설정되어 있습니다. 원본 이미지 해상도로 늘리면 확실히 depth map이 더 정확해지는 대신 어느 정도 inference 속도가 늘어나게 됩니다. 코드적으로 직접 high resolution의 이미지로 inference를 해봐야 알 수 있는거지만, 우선 논문이나 데모 정도로 봤을 때는 고해상도의 이미지가 크리티컬하게 영향을 미치진 않는다고 생각됩니다.
감사합니다.
2번 질문에 대해 추가 질문이 있어 코멘트를 남깁니다.
해상도에 대해 여쭤보는 이유로, 권장되는 resolution이 784×784로 되어있다는 말씀이 자동으로 resizing을 한다는 의미일까요?? pixel-wise depth를 알아야 하는 태스크이다 보니 그렇지는 않을 것 같고, 고해상도의 이미지가 얼마나 inference에 큰 영향을 미치는지는 학계에서 유명한 주제이다 보니 그 점에 대해서도 견해가 궁금합니다.
안녕하세요, 댓글 감사합니다.
resolution을 784×784로 resize하는게 맞습니다. 이 논문이 아니더라도 다른 diffusion 기반 depth esitmation 논문들에서도 입력 이미지에 대해 resize를 적용하고 있습니다.
고해상도 이미지가 미치는 inference에서의 영향이 성능인지 속도인지는 모르겠습니다만, 제 생각을 말씀드리면 diffusion 기반의 depth task가 diffusion이 아무래도 느리다는 기저가 깔려있기 때문에 속도에 대해서는 일반적으로 유하게 평가한다고 생각을 합니다. 그래서 확실히 고해상도 이미지가 성능을 높이는데 도움은 되지만 trade off 관계를 고려했을 때 어느 정도 낮은 해상도로 inference time을 확보하는 것이 diffusion 기반의 모델이라 할지라도 필요하지 않을까 생각합니다.
감사합니다.