이번에 리뷰할 논문도 기존에 리뷰하던 Video-Text Retrieval 입니다… 그런데 이제 Audio 를 곁들인…. 비디오 연구에서까지 점차 모달을 확장하고 있는 것 같은데, 멀티모달 RAG 과제 대비할 겸 리뷰해보려고 합니다.

- Conference: CVPR 2025
- Authors: Boseung Jeong, Jicheol Park, Sungyeon Kim, Suha Kwak
- Affiliation: POSTECH
- Title: Learning Audio-guided Video Representation with Gated Attention for Video-Text Retrieval
1. Introduction
기존 비디오-텍스트 검색 연구들은 주로 비디오의 시각적 정보와 텍스트를 결합했지만, 오디오 정보는 사용하지 않았습니다. 그런데 오디오는 화자의 정체성, 배경 소리, 감정적 뉘앙스 등 비디오 이해에 중요한 단서를 제공할 수 있다는 장점이 있죠.
물론 일부 연구에서 오디오를 활용하려는 시도가 있었지만, 오디오의 품질이나 관련성에 상관없이 단순하게 결합을 시도한다는 문제가 있었습니다. 특히 관련 없는 배경 소음까지 반영되면서 비디오 표현력이 오히려 저하되기도 했고, Query마다 비디오-오디오-텍스트를 함께 다시 처리해야 해 검색 속도도 느려지는 단점이 있었습니다.
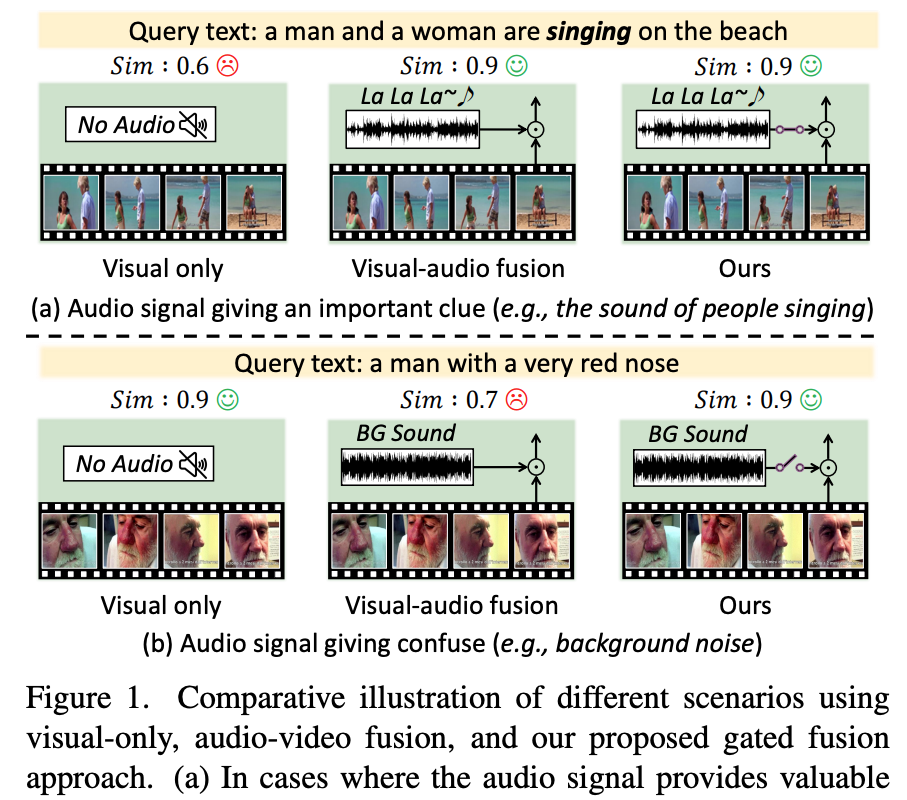
이러한 문제를 상단 그림 1에서 다시 확인할 수 있습니다. 그림 1(a)는 사람들의 노래 소리처럼 유용한 오디오 신호가 있을 때는 오디오를 활용하는 것이 검색 성능을 높이는 데 도움이 된다는 걸 확인할 수 있습니다. 반면 그림 1(b)는 배경 소음처럼 혼란을 주는 오디오가 섞이면, 오디오를 무조건 결합할 경우 오히려 검색 성능이 떨어질 수 있다는 걸 나타냅니다.
본 논문은 이러한 한계를 해결하기 위해 AVIGATE(Audio-guided VIdeo representation learning with GATEd attention)를 제안하였습니다. AVIGATE는 오디오가 유용할 때만 반영하는 게이트 메커니즘을 제안하고, 비디오와 텍스트를 독립적으로 처리해 검색 효율성을 높였다고 합니다. 자세한 내용은 다음 리뷰를 통해 알아보도록 하겠습니다.
2. Method
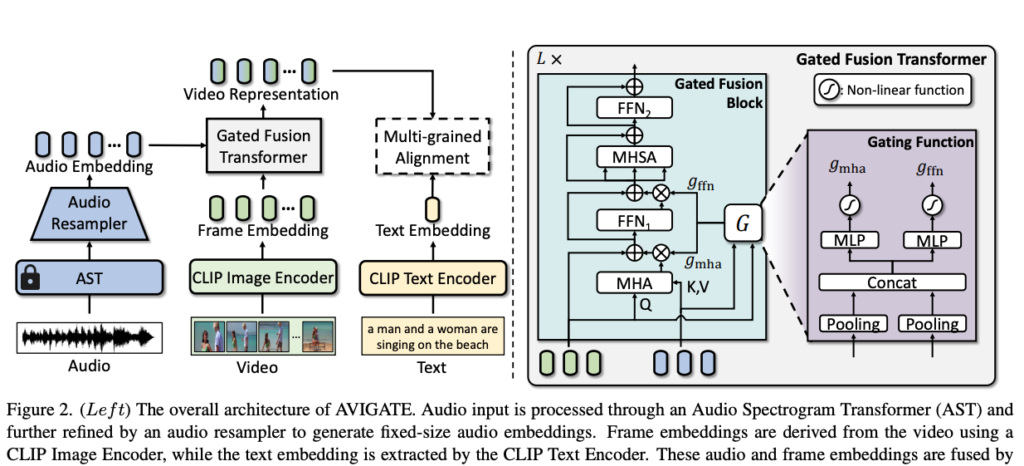
2.1 Embedding Extraction
우선, AVIGATE는 세 가지 pre-trained 인코더로 각각의 모달리티를 처리합니다. 비디오 프레임과 텍스트를 위해 각각 하나씩의 CLIP 인코더를 사용하고, 오디오는 Audio Spectrogram Transformer(AST)를 사용했다고 합니다.
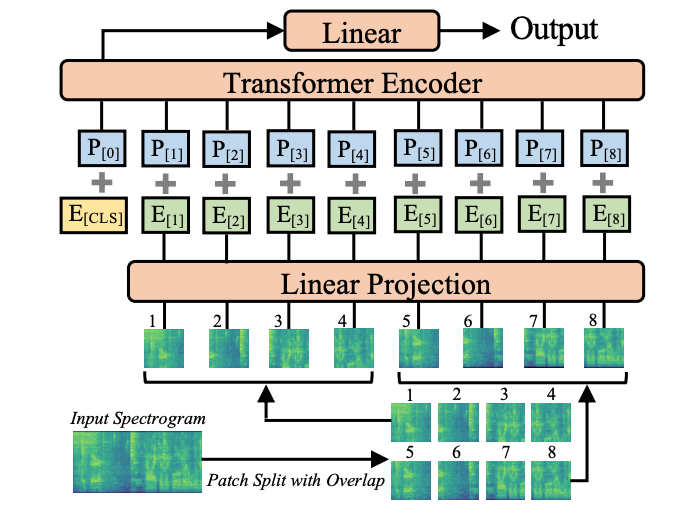
오디오 백본인 AST*는 저뿐만 아니라 다른 분들도 익숙하지 않으실 것 같아 찾아보니, 간단한 ViT 기반의 모델이더군요. 즉, AST는 ViT 기반의 모델로, 오디오를 스펙트로그램 형태로 변환한 뒤 이를 패치 단위로 나누어 시퀀스로 인코딩하는 모델입니다. (스펙트로그램 뽑는 방법은 다들 인공지능 수업 때 수행한 텀프로젝트 기억나시죠 ㅎㅎ?)
*AST: [Interspeech 2021] AST: Audio Spectrogram Transformer
비디오 프레임과 텍스트 임베딩은 각각 CLIP 이미지 인코더와 텍스트 인코더를 통해 얻습니다. 구체적으로, 비디오는 균일하게 샘플링한 N개의 프레임을 입력으로 하여, [CLS] 토큰 기반 임베딩을 생성하고 시퀀스로 구성합니다. 텍스트는 토크나이즈 후 [EOS] 토큰 임베딩을 최종 표현으로 사용합니다,.
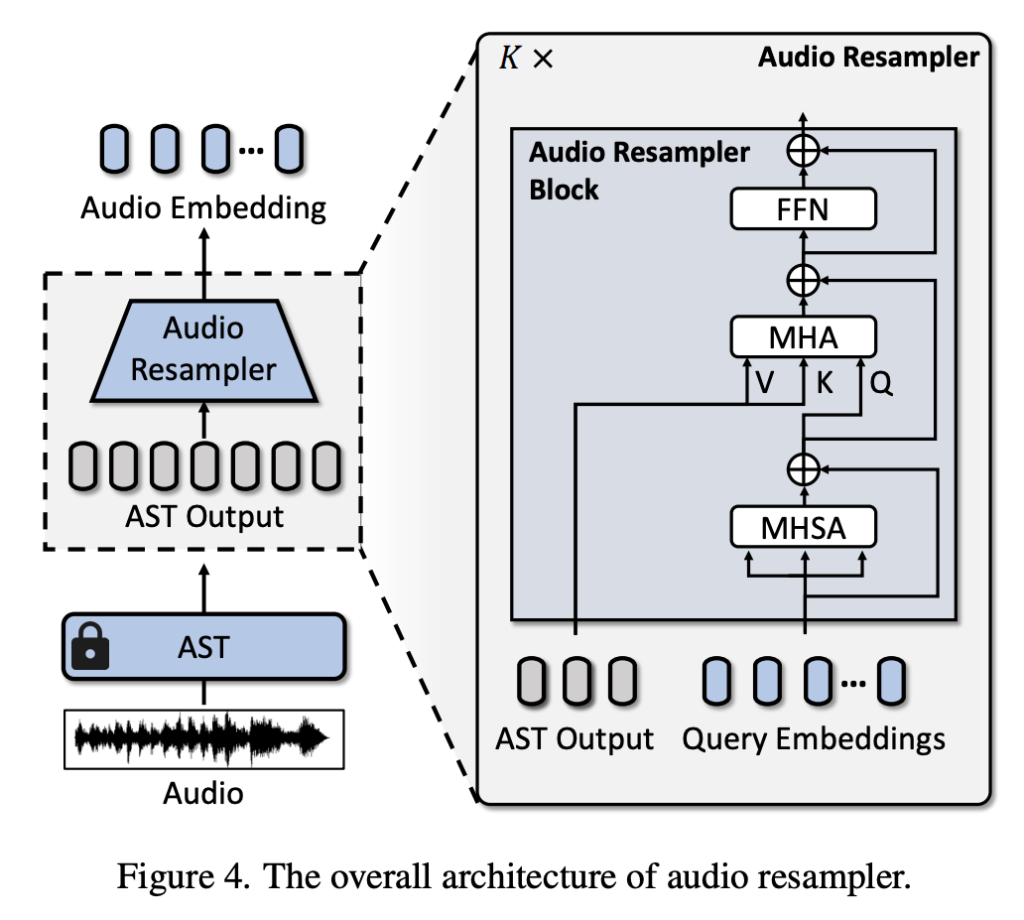
하지만 오디오는 비디오 프레임보다 훨씬 더 촘촘하게 샘플링되기 때문에, 모든 오디오 임베딩을 그대로 처리하면 계산량이 과도해지는 문제가 있습니다. 이를 해결하기 위해 저자는 추가적으로 Audio Resampler를 도입했습니다. Audio Resampler는 상단 그림과 같이, AST 출력을 고정된 개수 M의 오디오 임베딩으로 줄이는 모듈입니다.
Audio Resampler는 learnable query를 사용하는 query-based transformer 구조로 설계되었습니다. 먼저, 쿼리 임베딩들이 Multi-Head Self-Attention(MHSA)을 통해 서로 간의 관계를 학습하고, 이후 Multi-Head Cross-Attention(MHA)을 통해 AST의 오디오 출력을 요약합니다. 마지막으로 Feed-Forward Network(FFN)을 거쳐 최종 오디오 임베딩을 생성하였습니다. 이 과정을 K개의 Audio Resampler Block으로 반복하여, 오디오의 핵심 정보를 유지하면서도 계산량을 크게 줄일 수 있었다고 합니다. 이 때, 실험에서는 K=4를 사용하였습니다.
이렇게 리샘플링된 오디오 임베딩은 이후 비디오 프레임 임베딩과의 융합 과정에서 사용되며, 전체 모델의 효율성과 표현력을 동시에 확보하는데 큰 역할을 했다고 합니다. (AST는 학습 중에 freeze 합니다)
2.2 Gated Fusion Transformer
이제 서로 다른 모달리티를 융합하는 모듈에 대해 설명드리겠습니다. AVIGATE에서는 오디오와 비디오 표현을 결합하기 위해 Gated Fusion Transformer를 도입했습니다.
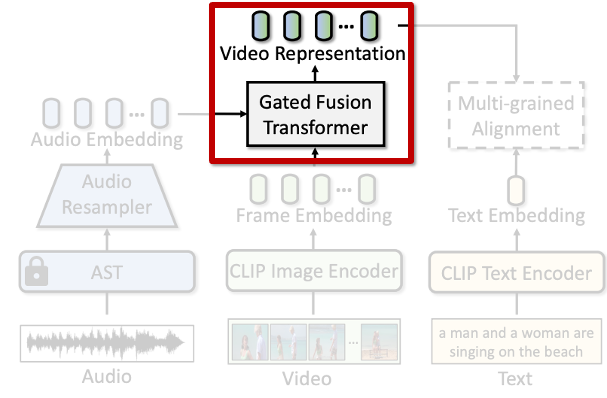
기존 방법들은 비디오와 오디오를 단순히 concat하거나, 무조건적으로 결합하는 방식이 많았습니다. 하지만 오디오는 항상 유용한 정보를 담고 있는 것이 아니기 때문에, 무조건적인 결합은 오히려 모델 성능을 저하시킬 수 있습니다. 이를 해결하기 위해, AVIGATE는 게이트(gate) 메커니즘을 활용해 오디오 정보를 선택적으로 통합하는 방식을 택했습니다.
여기서 궁금증이 생길 것 같습니다. 왜, 비디오와 오디오를 합치지? 오디오랑 텍스트를 합치면 안되나? (제가 궁금했거든요) 이에 대한 이유는 제 생각엔… 오디오의 특성 때문인 것 같습니다. 오디오는 신호 품질이 들쑥날쑥하고, 불필요한 배경 소음이나 무의미한 소리도 많이 포함되어 있어서, 텍스트와 직접 매칭하기에는 오히려 오류를 유발할 가능성이 있을 것 같습니다. 반면 비디오 표현을 보완하는 데 오디오를 활용하면, 오디오가 유용한 경우에만 비디오 임베딩을 강화할 수 있고, 필요 없는 경우에는 영향을 최소화할 수 있다고 합니다. (다시 말하지만 이 이유는 저의 뇌피셜이랍니다.. 저자가 이에 관해 언급하진 않고 기존 관습을 따른 것 같기도 하고… 오디오라는 모달리티에 대한 조예가 깊진 않다는점 참고 바랍니다 허허 훗날 누군가는 오디오랑 텍스트를 결합하는 시도를 하지 않을까요?)
다시 본론으로 돌아와서 Gated Fusion Transformer 대한 과정을 설명드리겠습니다. (1) 오디오 임베딩과 비디오 프레임 임베딩을 입력으로 받아, Cross-Attention을 통해 두 모달리티의 표현을 Fusion 합니다. (2) 이렇게 얻은 오디오 정보를 게이트를 통해 조정합니다. 여기서 게이트는 각 비디오 프레임 임베딩별로, 오디오에서 가져온 정보를 얼마나 반영할지를 조절하는 역할을 합니다. 만약 해당 프레임에 대해 오디오가 유의미한 정보를 제공한다면 게이트를 크게 열고, 그렇지 않은 경우 게이트를 좁혀 비디오 자체 정보를 유지합니다. 딱 LSTM의 게이트 역할이라고 이해하면 좋겠네요.
이와 관련한 구체적인 수식은 아래에 적어두겠습니다. 위 그림에서 Gated Fusion Transformer 에 대한 자세한 구조를 설명하는 부분이라 생각하면 됩니다. 대부분 Transformer 연산과 Gating 에 대해 잘 아실테니, 파트 2.3으로 바로 넘어가도 이해하는데 전혀 문제는 없을 듯 합니다
2.2.1 Gated Fusion Block
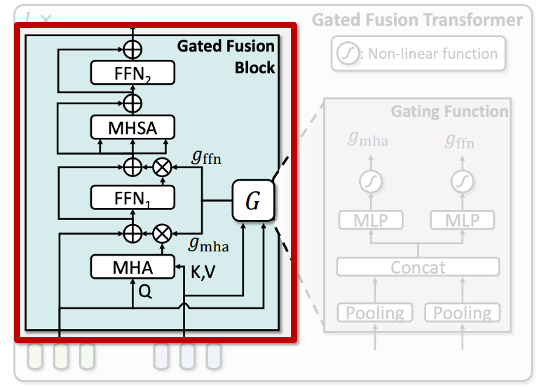
앞서 설명드린대로, Gated Fusion Block은 비디오 임베딩(프레임 단위)과 오디오 임베딩을 입력으로 받아, Cross-Attention과 게이팅 함수를 통해 이들을 융합합니다. 구체적인 구조는 상단 그림 왼쪽 하늘색 부분을 보시죠

여기서, f^{(l-1)}는 이전 layer의 비디오 임베딩, a는 오디오 임베딩을 의미하며, MHA는 Multi-Head Attention을 수행하는 연산입니다. 그리고 g_{\text{mha}}^{(l)}는 게이트 값으로, 오디오로부터 가져온 정보를 얼마나 반영할지 조절합니다.
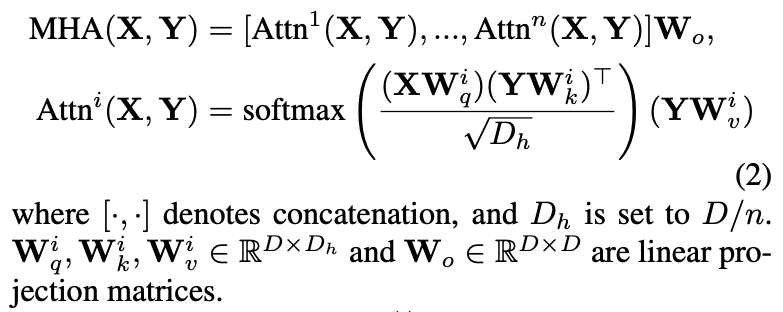
MHA 연산은 상단 수식 (2)처럼 정의됩니다. 입력 X와 Y에 대해, 각각 n개의 Head로 Attention을 수행한 후, 출력을 concat하여 최종 결과를 만듭니다. 그리고 각 head의 Attention은, query X와 key, value Y를 통해 다음과 같이 계산됩니다.
즉, 비디오 임베딩을 query로 하고 오디오 임베딩을 key-value로 사용하는 cross-attention 구조입니다. 그 다음 단계에서는, Cross-Attention 결과를 Layer Normalization한 후 Feed-Forward Network(FFN)을 통과시킵니다. 이 과정은 상단 수식 (1)의 두 번째 줄로 표현됩니다. 이후, 다음으로 넘어가기 전에 오디오가 반영된 비디오 임베딩에 대해, Multi-Head Self-Attention(MHSA)을 수행하고 추가적인 FFN을 적용합니다. 이 과정은 아래 수식 (3)과 같습니다.
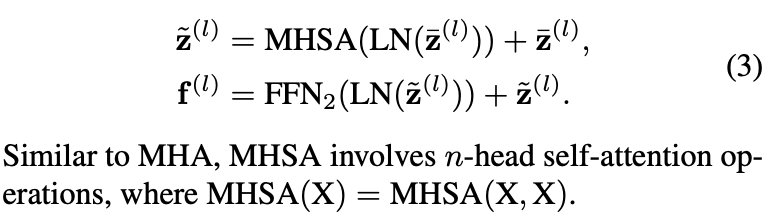
이해에 도움이 될까 해서 적어봤지만.. 다들 아시는 멀티오텐션 연산입니다. 그림만 봐도 충분히 이해가 가능하며 그렇게 어렵지 않습니다.
2.2.2 Gating Function
앞서 설명드린 것처럼, Gated Fusion Block은 오디오 정보를 비디오 임베딩에 선택적으로 반영하기 위해 게이트(gate ) 를 적용합니다. 이 때, 각 게이트 값은 고정된 값이 아니라, Gating Function을 통해 입력 특성에 따라 동적으로 생성됩니다.
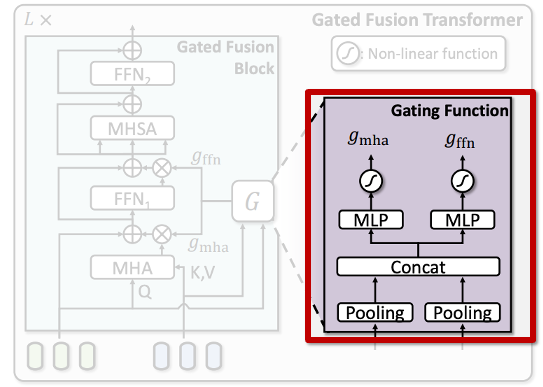
구체적으로, 비디오 임베딩과 오디오 임베딩을 각각 pooling하여 대표 벡터를 만든 뒤, 이 두 벡터를 concat합니다.. 그 다음, 이어붙인 벡터를 작은 MLP에 통과시켜 비선형 변환을 적용하여 최종 게이트 값을 생성합니다. 이때 생성되는 게이트 값은 두 가지입니다.
- g_{\text{mha}} : Cross-Attention 출력을 얼마나 반영할지 조절
- g_{\text{ffn}} : Feed-Forward Network 출력을 얼마나 반영할지 조절
각 게이트는 0과 1 사이 값을 가지며, 입력된 비디오와 오디오 특성에 따라, 오디오 정보를 많이 반영할지 적게 반영할지를 동적으로 결정합니다. 쉽게 말해,
- 오디오가 비디오 정보에 도움이 되는 경우에는 게이트를 크게 열어 오디오 정보를 적극적으로 활용
- 오디오가 필요 없거나 노이즈가 많은 경우에는 게이트를 닫아 오디오 영향을 최소화
2.3 Adaptive Margin-based Contrastive Learning
이제 Gated Fusion Transformer를 통해 얻은 비디오 임베딩과 텍스트 임베딩의 alignment를 맞춰 Loss를 계산하는 과정으로 넘어가보겠습니다. 여기서 저자는 Adaptive Margin-based Contrastive Learning 방식을 제안하였습니다.
기본적으로, Cross-modal Contrastive Learning은 텍스트-비디오 정렬을 위해 사용되는 대표적인 학습 방법입니다. positive 쌍은 유사도를 높이고, negative 쌍은 유사도를 낮추는 방식으로 학습이 진행됩니다. 이때, 기존 방법들은 모든 negative 샘플에 대해 고정된 margin을 적용해왔습니다. 하지만 실제 데이터에서는 샘플 간 의미적 유사도가 다를 수 있기 때문에, 고정된 margin만으로는 충분히 세밀한 판별력을 얻기 어렵다는 한계가 있었습니다.
이를 해결하기 위해 AVIGATE에서는 negative 샘플 사이의 의미적 유사도에 따라 동적으로 margin을 조정하는 방법을 제안했습니다. 만약 두 비디오가 시각적으로 유사하거나, 두 텍스트가 의미상 유사하다면, 이들의 cross-modal 매칭 역시 어느 정도 관련성이 있을 가능성이 높습니다. 따라서 negative 쌍이라 하더라도, intra-modal 간 유사성이 높은 경우 더 작은 margin을 적용하여 학습의 난이도를 조절하는 것입니다.
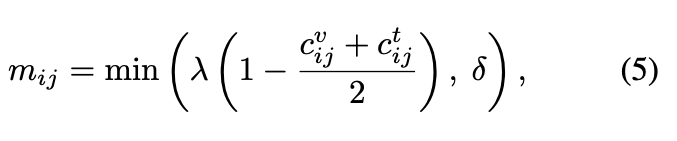
구체적으로, 주어진 비디오-텍스트 쌍 배치 \mathcal{B} = \{(V_i, T_i)\}_{i=1}^B에 대해, 각 negative 샘플 (V_i, T_j)의 intra-modal 유사도를 기반으로 adaptive margin m_{ij}를 계산합니다. 이때 margin은 상단 수식 (5)로 정의됩니다. 여기서 c_{ij}^{v}는 비디오 임베딩 간 cosine similarity, c_{ij}^{t}는 텍스트 임베딩 간 cosine similarity를 의미합니다. λ는 스케일링 계수, δ는 margin의 최대값을 제한하는 값입니다.
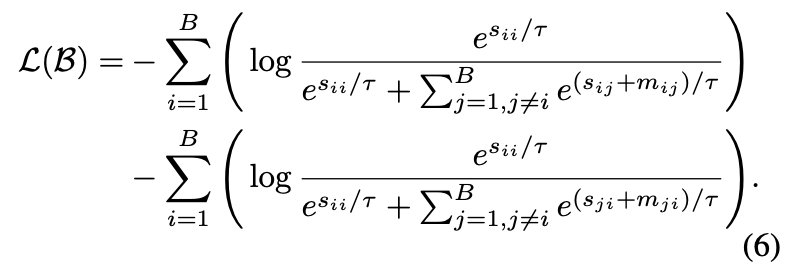
이렇게 계산된 adaptive margin은, contrastive loss 상단 수식 (6)에 반영되어 negative 쌍의 유사도 스코어에 적용됩니다. Adaptive margin을 통해, intra-modal 유사도가 높은 negative 샘플일수록 덜 엄격한 penalization을 적용하고, 유사도가 낮은 negative 샘플일수록 더 강하게 구분하도록 학습됩니다.
더 나아가 AVIGATE는 단순한 cosine similarity 대신, Global + Local 시점을 함께 고려하여 비디오-텍스트 유사도를 계산했습니다.
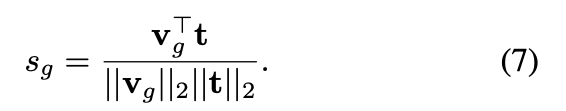
Global Alignment: 비디오 전체 프레임들의 평균을 이용하여 global 비디오 표현 \mathbf{v}_g를 생성하고, 이를 텍스트 임베딩 t과 cosine similarity로 비교. 상단 수식 (7) 참고
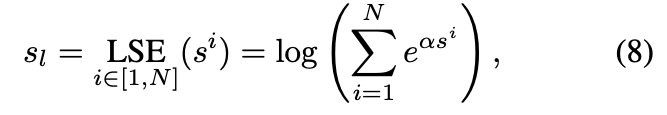
Local Alignment: 각 프레임 임베딩 v_i 별로 텍스트 임베딩과의 유사도를 계산하고, 이를 log-sum-exp 방식으로 계산. 상단 수식 (8) 참고

여기서 s^i는 프레임 i와 텍스트 임베딩 사이의 cosine similarity이며, α는 하이퍼파라미터입니다. 최종 유사도 s는 Global Similarity s_g와 Local Similarity s_l의 평균입니다.
3. Experiments
3.1 Experimental Setup
- Dataset: MSR-VTT, VATEX, Charades
- Evaluation Metric: Recall at K (R@K, with K = 1, 5, 10) and RSUM(the sum of all R@K metric)
3.2 Results
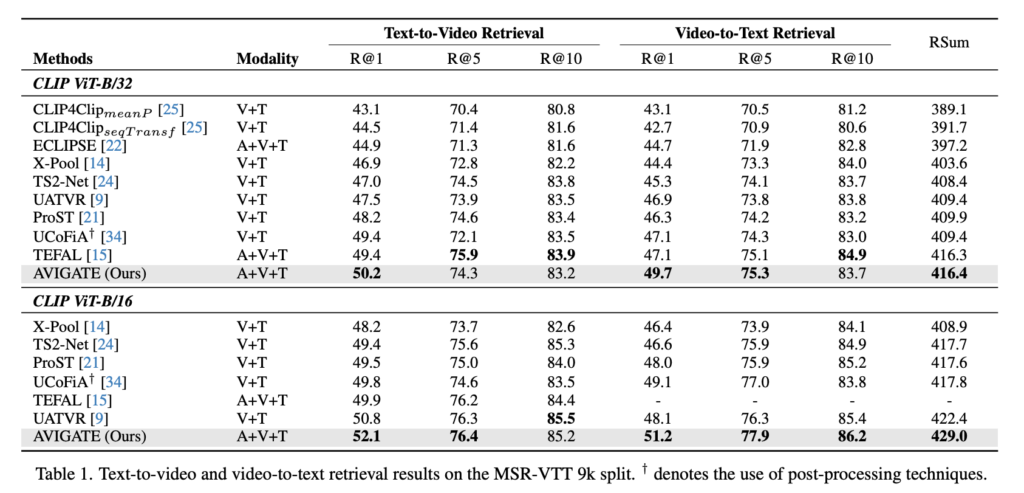
Table 1 (MSR-VTT 9k) MSR-VTT 9k split 실험 결과, AVIGATE는 모든 CLIP ViT backbone에서 기존 방법들 대비 R@1 기준 우수한 성능을 보였습니다. 특히 기존 오디오 기반 SOTA였던 TEFAL 대비 text-to-video retrieval에서는 0.8%, video-to-text retrieval에서는 2.6% 향상을 보였습니다. 이는 AVIGATE가 오디오 정보를 선택적으로 통합하고, 보다 정교하게 텍스트-비디오 정렬을 수행했기 때문으로 해석할 수 있다고 합니다.
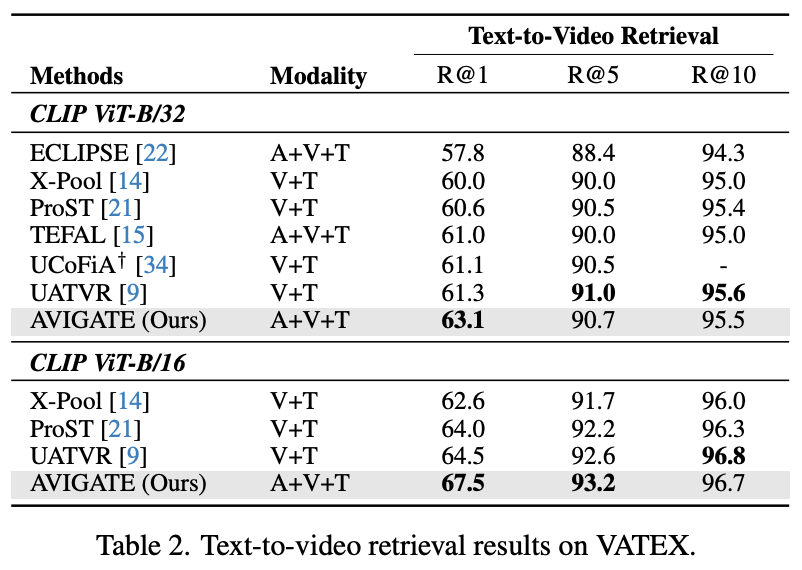
Table 2 (VATEX) VATEX 데이터셋에서도 AVIGATE는 기존 SOTA인 UATVR을 크게 능가하는 성능을 보여주었습니다. 오디오 없이 학습된 UATVR과 비교해, AVIGATE는 text-to-video retrieval task에서 1.8%의 R@1 향상을 보였습니다. 특히 AVIGATE는 대규모 멀티모달 정보(비디오 + 오디오)를 효과적으로 통합한 덕분에, 복잡한 장면과 다양한 액션이 등장하는 VATEX에서 더욱 큰 이점을 얻은 것으로 보인 것이라고하네요
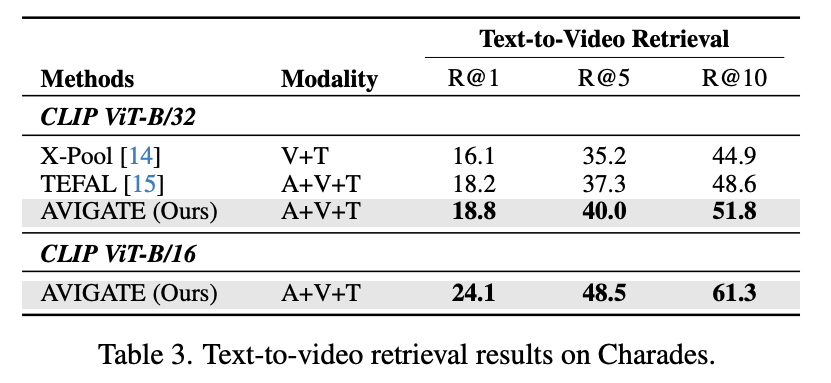
Table 3 (Charades) Charades 데이터셋에서도 AVIGATE는 TEFAL 대비 R@1 기준 0.8% 향상. Charades는 실내 활동 기반의 장면들이 많아 오디오 신호의 품질이 상대적으로 불안정할 수 있는데, AVIGATE는 게이트 메커니즘을 통해 오디오 정보를 필요에 따라 조정함으로써 이러한 환경에서도 안정적인 성능 향상을 이끌어낼 수 있었습니다.
3.3 Ablation Studies
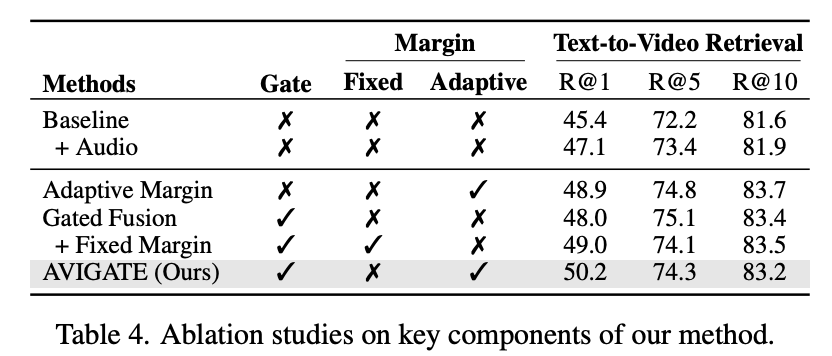
(Table 4) AVIGATE의 ablation study 결과입니다. 기본 베이스라인은 CLIP 인코더만을 이용해 비디오와 텍스트 임베딩을 학습하는 모델입니다. 여기에 오디오 모달리티를 추가한 “Baseline + Audio” 실험에서는, text-to-video retrieval 성능(R@1)이 1.7% 향상되며 오디오가 retrieval 성능 향상을 가져온다는 것을 확인할 수 있습니다.
이후 Gated Fusion Transformer와 Adaptive Margin 기법을 각각 추가한 결과, 베이스라인 대비 모든 지표에서 성능 향상이 있었습니다. 특히, 오디오 정보를 동적으로 통합하는 Gated Fusion 구조와, negative 쌍마다 semantic similarity를 고려하는 Adaptive Margin 기법이 합쳐질 때 가장 큰 성능 개선을 보였고, 최종적으로 full 모델은 R@1 기준 50.2%의 성능을 달성했습니다.
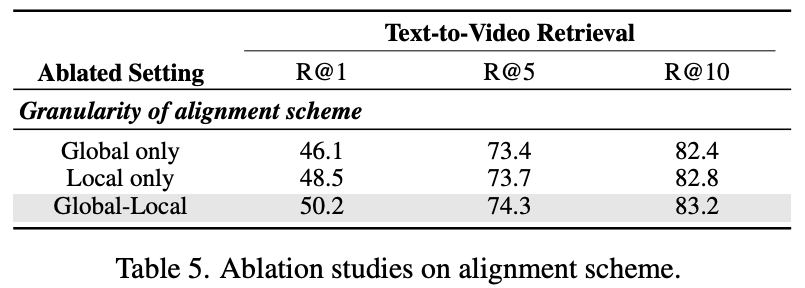
(Table 5) Alignment granularity가 retrieval 성능에 미치는 영향. AVIGATE에서는 비디오 전체를 요약한 global representation뿐만 아니라, 프레임 단위의 local representation까지 함께 고려하는 multi-grained alignment 방식을 사용했습니다. 실험 결과, global-only alignment에 비해 global-local 결합 방식을 사용할 때 모든 평가 지표에서 일관된 성능 향상이 있었습ㄴ다.
이는 비디오의 전체적인 의미(context)뿐만 아니라, 세부적인 프레임 레벨 특징까지 반영하는 것이 text-video retrieval 정확도를 높이는 데 효과적이라는 것이라고 합니다. 이러한 multi-grained alignment는 coarse한 전역 정보와 fine-grained local 정보를 모두 활용함으로써 보다 정밀하고 안정적인 cross-modal 매칭을 가능했다고 하네요.
3.4 Computational Cost Analysis
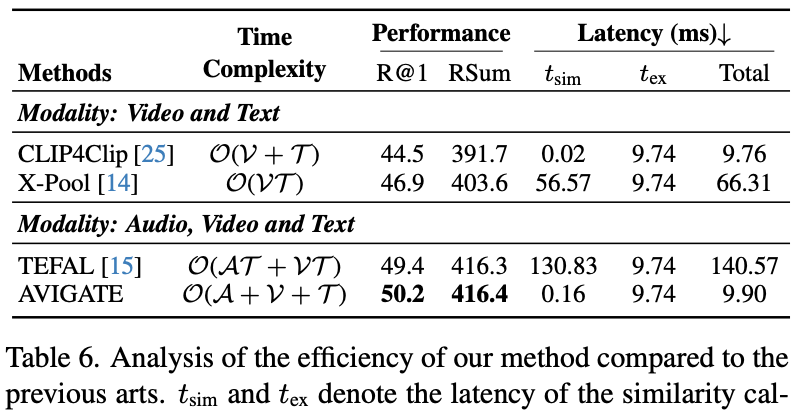
(Table 6) AVIGATE의 연산 복잡도와 Latency 비교. AVIGATE는 텍스트, 비디오, 오디오 수에 대해 복잡도 \mathcal{O}(A+V+T)를 가지며, 반복적인 cross-modal interaction이 필요한 TEFAL(\mathcal{O}(AT+VT))보다 훨씬 효율적입니다. MSR-VTT-9k 실험 결과, AVIGATE는 TEFAL보다 14배, X-Pool보다 6배 빠른 속도를 보였습니다. 또한 CLIP4Clip과 비교해도 multi-grained alignment를 적용했음에도 latency 증가가 제한적이었다고 하네요
4. Conclusion
AVIGATE에서는 비디오-텍스트 검색 성능을 향상시키기 위해 오디오 정보를 선택적으로 통합하는 Gated Fusion Transformer와, intra-modal 유사도에 따라 negative 쌍 margin을 조정하는 Adaptive Margin-based Contrastive Learning 기법을 제안했습니다. 이 때, 프레임 단위의 비디오와 오디오 임베딩을 게이트로 조정하며 통합하고, 유사도 계산 시 global-local을 모두 고려하여 전체 맥락과 세부 정보를 모두 반영할 수 있었다고 합니다. 총 세 가지 데이터셋에서 기존 방법 대비 성능 향상을 보였으며, 효율성 측면에서도 TEFAL과 X-Pool 대비 훨씬 낮은 연산 복잡도와 빠른 응답 속도를 보였습니다.
안녕하세요 주영님 좋은 리뷰 감사합니다.
2.1 Embedding Extraction에서는 오디오 임베딩을 그대로 사용하지 않고, 고정된 개수 M으로 줄여 사용한다고 하셨습니다. 하지만 오디오 임베딩을 이렇게 축소하면, 비디오 임베딩과의 Fusion 과정에서 Alignment가 맞지 않을 수 있다는 생각이 듭니다.
물론 Cross-Attention 연산을 수행하기 때문에 관계를 학습할 수 있을 것 같기는 하지만, 이 부분에 대해서 논문에서는 언급된 내용이 있을까요?
감사합니다.
해당 내용은 리뷰에 적혀있는데, 오디오는 샘플링 수가 비디오에 비해 훨씬 큽니다. Cross-Attention 연산을 수행할 때 연산량이 커지니까 M으로 줄이는 겁니다. latency를 확보하기 위해 해당 resampler가 적용된 것이죠. 다만 이 sampler 적용 여부나 M 값에 따른 실험은 없어 alignment 정확도를 판단하긴 어려울 것 같습니다. 그러나 어떻게 보면 오히려 불필요한 샘플 수가 줄어들어 alignment를 맞출 수 있지 않을까요?
안녕하세요 홍주영 연구원님
좋은 리뷰 잘 읽고 갑니다
여러모로 친절한 리뷰라는 생각이 듭니다 감사해요
오디오를 video-text retrieval task에 효과적으로 활용하기 위해 gated fusion의 방법을 적용해 오디오에서 오로지 필요한 부분만을 취해 비디오와 결합된 연구라고 이해하였고 실험 결과를 보니 저자가 제안한 방법이 적절한 방법이라는 생각이 듭니다.
질문 하나 드리겠습니다. 이 연구에 대한 질문 자체는 아니고요
contrastive loss를 정의할 때 negative sample에 대해서 margin을 적용한다는 게 조금 생소한데요 이를 사용하는 이유가 궁금합니다.
여러 단계로 나눠서 답변을 드리겠습니다.
1. Contrastive loss란?
contrastive loss는, “같은 건 가깝게, 다른 건 멀게” 만드는 방식입니다. 예를 들어 텍스트와 비디오가 주어졌을 때, 정답쌍은 유사도를 높이고, 오답쌍은 유사도를 낮추도록 학습하는 것이죠.
여기서 정답쌍(=positive sample)은 예를 들어 “고양이가 소파 위에 있다”라는 문장과 그에 해당하는 영상이고, 오답쌍(=negative sample)은 “고양이가 소파 위에 있다”라는 문장과 관계없는 영상들에 해당됩니다.
2. 여기서 margin은 무슨역할?
일반적인 contrastive loss는 단순히 정답은 가깝게, 오답은 멀게만 학습합니다. 그런데 문제는, 이미 충분히 멀어진 오답쌍에 대해서도 계속 loss를 부여한다는 점입니다.
아래와 같이 오답쌍(negative)가 있다고 가정해보겠습니다.
– 원숭이 영상 – “고양이가 소파 위에 있다”
– 자동차 영상 – “고양이가 소파 위에 있다”
사실 두 영상 모두 정답과 전혀 상관없어서, 굳이 둘 다 더 멀게 만들 필요는 없을 수 있죠.
이럴 때 “여기까지만 멀어지면 된다”라고 기준을 정해주는 것이 바로 margin입니다.
따라서 margin이 도입된 contrastive loss는 다음과 같이 동작합니다
– 오답쌍의 유사도가 정답쌍보다 margin만큼 떨어지지 않으면 → loss를 전달 O
– 이미 margin보다 충분히 떨어져 있으면 → loss를 전달 X
이렇게 하면 모델은 헷갈릴 수 있는 오답(=hard negative)에 집중해서 학습할 수 있고, 이미 잘 구분되는 오답은 무시하는 효과를 가져오고자 도입된 것이죠