
안녕하세요, 허재연입니다. 이번 리뷰에서 다룰 논문은 보다 fine-grained 한 사전학습을 통해 FILIP이라는 새로운 VLM을 구축한 연구입니다. 리뷰 시작하겠습니다.
Introduction
CLIP, ALIGN과 같은 대규모 Vision-Language 사전학습법이 제안되었고, 이들은 컴퓨터비전분야의 수많은 downstream task에서 경쟁력 있는 성능을 보였습니다. 이러한 방법론들은 웹에서 수집한 대규모의 image-text pair를 활용해 데이터셋을 구축하여 간단한 contrastive learning을 수행해 강력한 representation을 가진 encoder를 구축할 수 있었습니다. 대규모 사전학습 덕분에 뛰어난 zero-shot 성능을 보여주었고, 임베딩 공간에서 contrastive learning을 통한 텍스트 데이터와의 정렬을 수행하였기 때문에 텍스트 데이터의 지식을 활용한 다양한 task(open-vocabulary 등)에 활용할 수 있었습니다. 이런 VLP모델 구축 과정에서 핵심은 이미지 인코더-테스트 인코더의 dual-stream model을 통한 global contrastive alignment에 있다고 할 수 있죠. 하지만, CLIP과 ALIGN모델은 단순히 각 모달리티 global feature 간 유사도를 활용하여 data instance 단위의 학습을 진행하였기 때문에 이미지의 객체나 문장에서의 단어와 같은 보다 세부적인 수준의(finer-level) 정보를 포착하는 능력이 떨어졌습니다. 이미지 전체 및 텍스트 전체를 단순히 하나의 벡터로 임베딩하여 비교하는 학습을 수행하다보니, 각 데이터의 세밀한 요소들에 대한 표현력을 풍부하게 갖추기 어려웠겠죠. 본 논문의 저자들은 이러한 문제에 주목하여 모달리티 간 세밀한 요소의 상호작용 메커니즘을 고려한, 보다 간단하고 효율적인 대규모 Vision-Language Pretraining 방법을 제안합니다.
기존에도 관련하여 (1) 사전학습된 object detection 모델을 활용해 RoI feature을 뽑아서 이를 text pair와 함께 사전학습하는 방법 및 (2) 각 모달리티의 토큰 단위 / 패치 단위 representation을 동일 공간에 투영하여 cross-attention이나 self-attention으로 세밀한 정보 간 상호작용을 유도하는 방법론이 있기는 하였지만, 저자들은 이에 대해 (1)의 방법은 수많은 RoI feature를 사전에 연산하고 이를 저장해야해서 프레임워크가 복잡해지는 동시에 detector의 성능 및 지식에 따라 zero-shot 예측 능력이 제한된다는 한계가 있고, 기존의 (2) 계열 방법론들의 경우에는 인코더-디코더 구조로 cross-attention을 해야하거나 각 모달리티의 시퀀스가 길어짐에 따라 attention 연산 복잡도가 급격히 켜져 train/inference 과정이 너무 비효율적인 한계가 있었다고 주장합니다.
본 논문에서 저자들이 제안하는 FILIP(Fine-grained Interactive Language-Image Pre-training) 프레임워크는 기존 연구들의 이러한 한계를 극복하기 위해, fine-grained semantic alignment에 기존처럼 cross attention이나 self-attention을 쓰는 대신, visual / textual token 간 토큰-단위 유사도를 최대화하는 방식으로 contrastive loss를 수정하여 학습을 진행하게 됩니다. 이 방법을 통해 이미지 패치 및 텍스트 단어의 표현을 효과적으로 학습할 수 있었다고 합니다. 이에 단순히 학습법만 제안하는데 그치지 않고 인터넷에서 수집한 데이터를 바탕으로 FILIP300M라는 대규모 사전학습 데이터셋을 구축하였습니다. (CLIP이 데이터셋을 공개하지 않았기 때문에 VLP 계열 논문들은 학습 방법론뿐만 아니라 데이터셋을 새로 구축하는게 일반적인 흐름 같습니다)
결과적으로 FILIP은 fine-grained representation을 효과적으로 학습하여 zero-shot image classification, image-text retrieval과 같은 다양한 downstrema task에서 좋은 성능을 달성할 수 있었습니다.
Method
저자들은 보다 디테일한 vision-language 간 의미적 정렬을 위해, 이미지 인코더와 텍스트 인코더의 feature 간 학습 과정에 보다 세밀한 부분을 고려할 수 있게 하하였습니다. 제안하는 모델인 FILIP은 트랜스포머 기반의 이미지 인코더, 텍스트 인코더로 구성된 dual-stream model로 구성하였습니다. 이는CLIP처럼 사전학습이 완료된 두 인코더를 각각 offline형태로 활용할 수 있게 하기 위함입니다(CLIP에 익숙한 저한테는 당연히 이렇게 만들어야 하는게 아닌가 하는 생각이 들었는데, 기존의 방법론들 중 일부는 inference 때 두 모달리티를 모두 활용해야했기에 CLIP이나 ALIGN처럼 두 인코더를 따로 offline으로 활용할 수 없었다고 합니다). 비전 모달리티에서는 이미지 인코더로 ViT를 활용해서 이미치 패치들을 projection한 임베딩과 [CLS]토큰을 concat하여 입력하도록 하였습니다. 텍스트 모달리티에서는 CLIP과 같이 vocabulary 크기가 49,408개인 소문자 바이트 페어 인코딩(BPE)를 사용하여 텍스트를 토큰화하여 활용했다고 합니다. 이 때 각 텍스트 시퀀스는 [BOS]토큰으로 시작하여 [EOS]토큰으로 끝나게 됩니다. word embedding layer 이후 토큰 임베딩은 텍스트 인코더에 입력됩니다. 이미지와 텍스트 인코더를 거친 이후에는 text token과 visual token에 linear projection을 적용해 공동의 임베딩 공간으로 매핑하고, 각각 L2 정규화를 적용합니다. 기존 CLIP, ALIGN과 같은 dual-stream 모델들이 이미지 전체와 텍스트 시퀀스 전체의 global feature만을 활용해 cross-modal interaction을 구성한 것과 달리, 저자들은 이미지 패치와 텍스트 토큰 간 보다 세부적인 상호작용을 할 수 있도록 cross-modal late interaction과정을 수행하는 새로운 contrastive learning loss를 고안하였습니다. 학습을 어떻게 수행하는지 살펴보겠습니다.

FINE-GRAINED CONTRASTIVE LEARNING
이미지 데이터셋을 I, 텍스트 데이터셋 T, 이미지 데이터 하나를 {x}^{I} ∈ I, 텍스트 데이터 하나를 {x}^{T} ∈ T, 이미지 인코더를 {f}_{θ}, 텍스트 인코더를 {g}_{ø}로 표기하겠습니다. 인코딩된 각 visual / textual representation은 각각 {f}_{θ}({x}^{I}) , {g}_{ø}({x}^{T})로 표현할 수 있겠죠. 입력된 각 이미지-텍스트가 서로 연관이 있다면 {f}_{θ}({x}^{I}) , {g}_{ø}({x}^{T})간 거리가 가까워지고, 그렇지 않다면 멀어질 것입니다. 각 학습 배치 안에서는 b개의 image-text pair {x}^{I}, {x}^{T}를 샘플링하게 됩니다.
이 때 배치 내부에서 k번째 image data {x}^{I}_{k}에 대한 image-to-text contrastive loss 는 다음과 같이 정의됩니다.
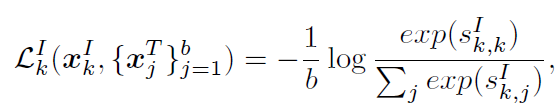
수식에서 {s}^{I}_{k,j}는 k번째 image와 j번째 text 간 유사도를 의미합니다. 비슷하지만 반대로, 배치 내부 k번째 텍스트 데이터 {x}^{T}_{k}에 대한 text-to-image contrastive loss는 다음과 같습니다.
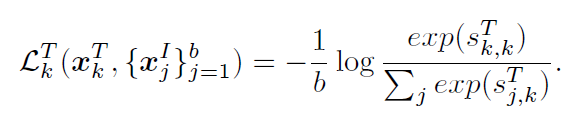
각 미니 배치에 대한 total loss는 이 둘을 합쳐 다음과 같이 구성됩니다.
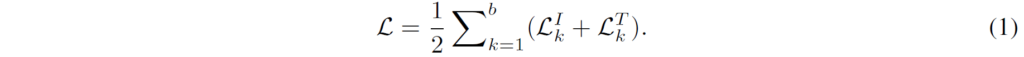
CROSS-MODAL LATE INTERACTION
위 수식 (1)의 contrastive learning loss를 통해, 이제 문제는 i번째 image 및 j번째 text에 대한 similarity {s}^{I}_{i,j} 및 {s}^{T}_{i,j}를 어떻게 구성할지로 바뀌었습니다. CLIP, ALIGN과 같은 기존 연구에서는 간단하게 image와 text 각각을 d차원 실수 벡터 형태의 global feature {f}_{θ}({x}^{I}_{i}), {g}_{ø}({x}^{T}_{j})로 인코딩한 다음과 같이 유사도를 계산하였습니다.
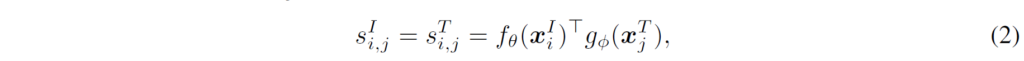
이런 단순한 cosine similarity 형태는 word-patch alignment와 같은, 두 모달리티의 보다 세부적인 요소 간 상호작용을 고려하지 않았습니다(대신 dual-stream model 형태로 학습 및 추론에 대한 효율성을 유지할 수 잇었죠). 저자들은 기존 연구를 참고하여, 토큰 단위의 cross-modal interaction을 수행할 수 있도록 cross-modal late interaction을 도입하였습니다.
i번째 이미지 및 j번째 텍스트의 (패딩되지 않은) 토큰의 수를 각각 n1 및 n2라고 하면, 인코딩된 feature {f}_{θ}({x}^{I}_{i}), {g}_{ø}({x}^{T}_{j})는 각각 n1×d, n2×d 의 형태가 됩니다. k번째 visual token에 대해서, 저자들은 모든 {x}^{T}_{j} textural token과의 유사도를 계산한 뒤 가장 큰 값을 {x}^{T}_{j}와의 token-wise maximum simiarity로 사용하였습니다. 이는 다음 수식 3으로 나타낼 수 있습니다.
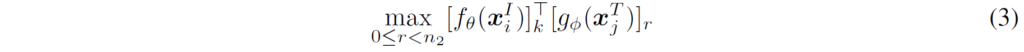
이후, 이미지(또는 텍스트) 내의 패딩되지 않은 모든 토큰에 대해 토큰별 최대 유사도를 계산한 뒤, 이들의 평균값을 이미지와 텍스트 간의 유사도(또는 텍스트와 이미지 간의 유사도)로 사용하게 됩니다. i번째 image와 j번째 text 간 유사도는 따라서 다음과 같이 구성하게 됩니다 :
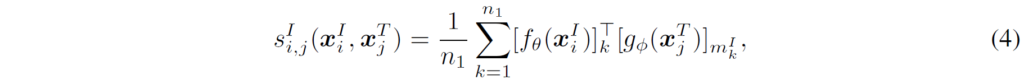
여기서 {m}^{I}_{k}는 위 3번 수식에서 구한, 유사도가 가장 큰 인덱스를 의미하며 다음과 같습니다.
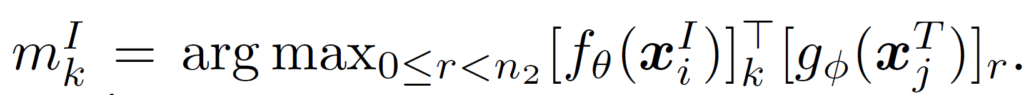
수식 (4)와 비슷하게, j-번째 text와 i-번째 image의 유사도는 다음과 같이 계산합니다.
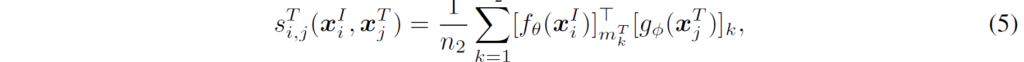
여기서 {m}^{T}_{k}도 위와 비슷하게 다음과 같습니다.
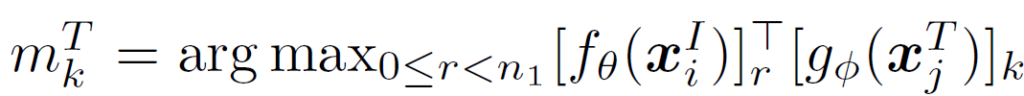
저자의 설명으로는, 수식 (3)에서의 token-wise maximum similarity는 각 이미지 패치에 대해 가장 유사한 textural token을 찾는 것을 의미하며, 비슷하게 각 textual token에 대해 가장 가까운 이미지 패치를 찾게 된다고 합니다. 이를 수식 (4), (5)에 적용하여 dual-stream model이 image patch와 textual token 사이 fine-grained alignment를 학습할 수 있게 된다고 합니다. 계산 과정에서 토큰별 최대 유사도의 평균을 사용하는 이유는, 텍스트마다 패딩되지 않은 토큰의 수가 다르기 때문에 단순 합산 방식을 사용할 경우에는 유사도 값의 크기(magnitude)가 크게 달라질 수 있어 학습이 불안정해지고 최종 성능도 저하되지 때문이라고 하네요.
저자들은 [prefix] [label], [category description]. [suffix]. 형태의 템플릿을 사용하였다고 합니다. 여기서 [prefix]는 CLIP의 “a photo of a”와 같은 문맥 내부 설명을 의미하고, “label”은 데이터셋의 클래스 레이블, “[category description]”은 해당 클래스가 속한 범주에 대한 설명을 의미합니다. CLIP 논문에서 이런 category description이 fine-grained classification 데이터셋에서 성능 향상에 도움을 줄 수 있다고 하네요. 예를 들어, Oxford-IIIT Pets 데이터셋에서는 “a type of pet”라는 category description이 사용된다고 합니다(데이터셋마다 템플릿이 약간씩 다르게 활용된다고 합니다). 추가적으로, 저자들은 경험적으로 프롬프트 끝에 “i like it”과 같이 reference word “it”을 포함하는 접미사(suffix)를 추가하면 FILIP에서 zero-shot classification 성능이 향상되는것을 관찰했다고 합니다. 저자들은 이를 “it”과 같은 참조어가 대상 객체의 이미지 패치들과 정렬될 수 있기에 fine-grained cross-modal alignment를 강화해주는 효과가 있기 때문이라고 분석하였습니다.
Image and Text Augmentation
사전학습 과정에서 더 많은 데이터를 활용하는 효과를 위해 augmentation을 적용하게 됩니다. 이미지 데이터에는 강화학습 기반 데이터 증강 기법인 AutoAugment를 적용하였고, text의 경우는 본래 문장과 의미적으로 유사하게 만들기 위해 back-translation을 활용해 original text를 재작성했다고 합니다. back-translation은 일종의 text augmentation 기법으로, target language로 해당 문장을 번역했다가 source language로 다시 번역하는 것입니다. 저자들은 독일어와 러시아어로 target language를 설정하여 추가적으로 두 개의 text 를 구축하였으며, 배치를 구성할 때 이들 3개의 후보(하나의 orinigal text, 두개의 back-translated text) 중 무작위로 하나가 선택되도록 하였다고 합니다. 신기한 증강 방법이네요..
PRE-TRAINING DATASET
좋은 Vision-Language Pretraining을 수행하기 위해서는 충분히 큰 image-text pair 데이터셋이 필요합니다. CLIP과 ALIGN은 각각 4억개와 18억개의 image-text pair로 구성된 데이터셋을 구축하기도 했었죠(ALIGN은 데이터가 많은 대신 데이터셋이 보다 더 noisy합니다). 본 논문에서도 저자들은 인터넷에서 수집한 3억개의 image-text pair로 구성된 데이터셋인 FILIP300M을 구축하였습니다. 데이터셋 수집 과정에서 이미지 데이터의 경우, 변의 길이가 200픽셀보다 작거나, aspect ratio가 3보다 큰 이미지는 필터링하였다고 합니다. 텍스트 데이터의 경우 영어 텍스트만을 활용했으며, ‘img 0.jpg’와 같이 의미가 없는 텍스트 데이터 및 동일한 텍스트가 10회 이상 반복되는 데이터도 제외하였다고 합니다. 여기에, 추가적인 공개 데이터셋인 Conceptual Captions 3M (CC3M), Conceptual 12M (CC12M), Yahoo Flickr Creative Commons 100M (YFCC100M)도 함께 활용하였다고 합니다. 최종적으로는 사전학습에 약 3억 4천만개의 image-text pair를 사용하였다고 하며, 비록 CLIP이나 ALIGN보다 적은 양의 학습 데이터를 사용하기는 하였지만 FILIP이 대부분의 downstream task에서 이들보다 우수한 성능을 낼 수 있었다고 합니다.
Experiment
실험 결과를 살펴보겠습니다. 기본적인 모델 구조는 CLIP을 따랐다고 하며, FILIP_base의 경우 ViT-B/32를 이미지 인코더로, FILIP_large의 경우 ViT-L/14를 이미지 인코더로 사용하였다고 합니다. 전반적으로 image classification task에서 실험이 수행되었습니다.
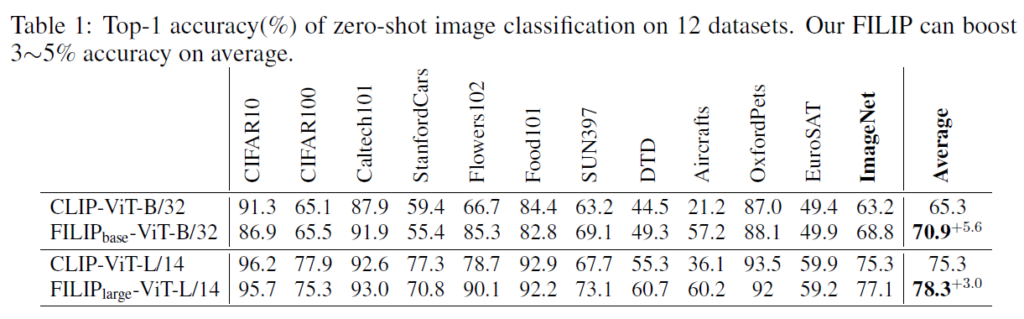
table 1에서는 12개 데이터셋에 대해 평가를 진행하였습니다. CLIP보다 학습 데이터가 적음에도, 이미지 인코더를 다르게 설정한 두 실험에서 FILIP이 비교적 상당한 성능 개선을 이루었습니다. 하지만 워낙 다양한 데이터셋에 대한 실험인만큼 항상 FILIP이 우세했던 것은 아니지만, Aircraft와 같은 domain-specific한 몇몇 데이터셋에서는 압도적으로 좋은 성능을 보였습니다. 저자들은 이를 CLIP이 이미지 전체의 정보를 [CLS]토큰에 모으지만, FILIP의 경우 이미지 패치를 텍스트 target object와 곧바로 정렬할 수 있어서 target object에 더 잘 집중할 수 있기 때문이라고 설명합니다.
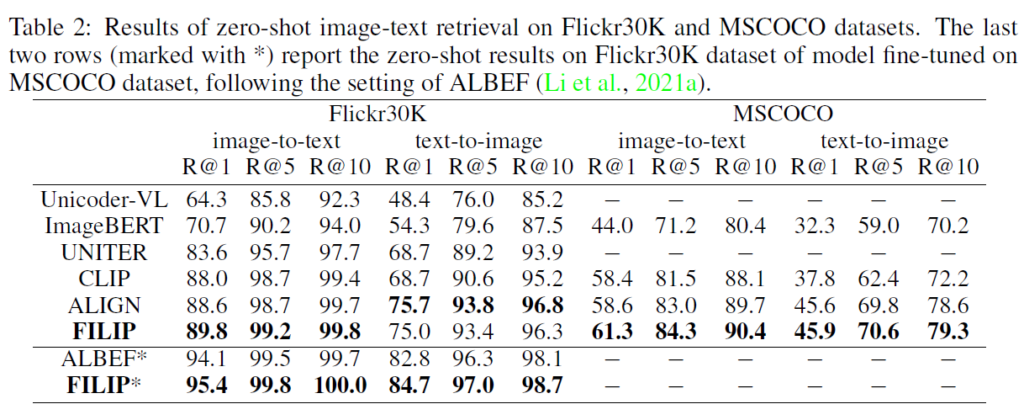
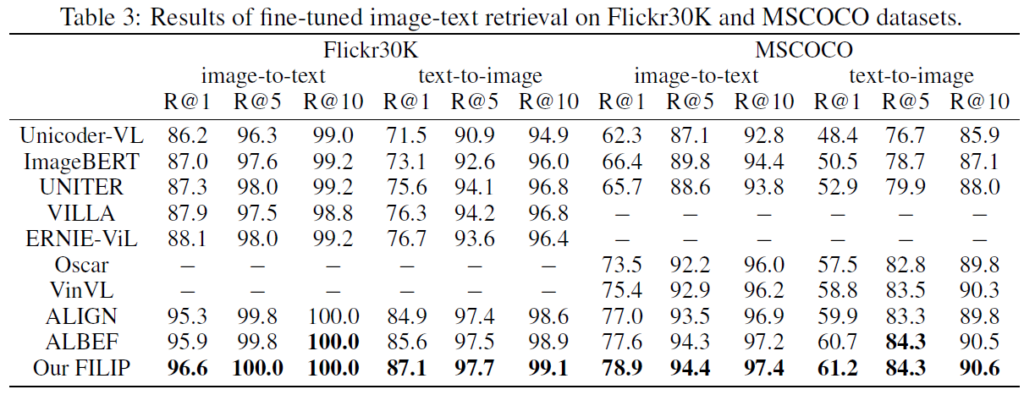
Image-Text retrieval은 Flickr30K 및 MSCOCO 데이터셋에서 zero-shot 및 finetuning이 모두 수행되었습니다. Table 2는 zero-shot 결과를, Table 3는 fine-tuning 결과를 보여주는데, 다양한 방법론들과 성능 비교를 하였을 때 FILIP이 Flickr30K zero-shot을 제외한 모든 부문에서 가장 좋은 성능ㅇ르 보여주는것을 확인할 수 있었습니다
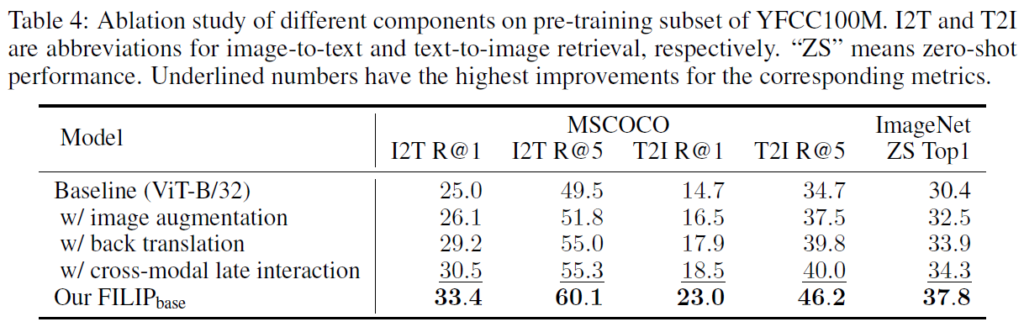
Table 4는 Ablation study 결과입니다. FILIP의 각 구성요소를 잘 활용하면 좋은 결과를 얻을 수 있음을 확인할 수 있었습니다.

시각화 결과를 확인하고 논문 리뷰를 마무리하겠습니다. 패치 수준에서 텍스트 토큰과 정렬하는 학습을 수행했으니 실제로 세부적인 요소를 잘 고려할 수 있는지 확인을 해야겠죠. Figure 2는 ImageNet 데이터셋의 4개 클래스에 대해 word-patch alignment 결과를 FILIP과 CLIP에 대해 나타내었습니다. 그림에서 볼 수 있듯, FILIP이 이미지에 대해 보다 더 세밀한 이해를 하고 있는 것을 확인할 수 있습니다. “small white butterfly”의 시각화 결과를 보면, 객체를 포함하는 이미지 패치들이 모두 올바르게 분류되었고, “balloon”과 “lifeboat” 클래스의 시각화에서는 서로 다른 모양과 위치에 있는 모든 대상 객체에 해당하는 이미지 패치들이 잘 분류되었습니다. “electric locomotive”에서도 “electric”과 “locomotive”의 텍스트 토큰 5,6이 각각 정확한 위치에 있는 것을 확인할 수 있습니다. 반면 CLIP은 토큰이 정확하게 이미지 패치에 대응되지 않는 것을 확인할 수 있었습니다.
이미지 패치 및 문장의 토큰 단위로 사전학습을 하는 방법론이기에, 논문을 읽기 전에는 segmentation, detection과 같은 dense prediction task를 위한 방법론인 줄 알았지만, 그렇지는 않았습니다. 오히려 이미지 패치의 세부적인 부분을 더 잘 고려할 수 있게 고안한 방법이었네요. 이후 fine-grained 요소를 고려할 일이 있다면 해당 아이디어를 고려해 볼 수 있을 것 같습니다.
감사합니다.
리뷰 잘 읽었습니다.
저자는 토큰별 유사도 최대값을 사용하는 방식(max similarity per token)을 택했는데, 평균 유사도나 다른 aggregation 방식과 비교한 실험은 없나요? 해당 기법이 Fine-grained한 태스크에 맞게 설계된 것은 납득이 되는데 이렇게 토큰별 유사도로 계산하는 방식의 영향력이 궁금해서요 만약 해당 실험이 없다면 저자들이 참고한 ColBERT 논문에서는 이와 비슷한 실험은 없는지 궁금합니다
저자들이 대조학습에 토큰별 유사도의 최댓값이 되는 것들을 택한 이유는, s ^ I에서 각 이미지 패치와 가장 연관이 깊은 단어 토큰을 찾고, s ^ T에서는 각 단어 토큰에서 가장 관련이 깊은 이미지 패치를 찾는 방식의 학습을 유도하기 위함입니다. 만약 유사도를 집계하는 방법을 다르게 설정한다면 완전히 다른 새로운 프레임워크가 될 것 같네요. 논문에도 딱히 해당 부분에 대한 ablation은 없습니다. Figure 2를 첨부한 것이 해당 방법으로 계산하는 방식의 영향력을 시각화하기 위함이라고 생각 되는데요, 결과적으로 FILIP은 CLIP과 비교해서 fine-grained한 사전학습 과정 덕분에 word와 patch 간 alignment가 잘 이루어졌습니다. 각 워드 토큰의 번호에 대응되는 패치를 잘 찾는 것을 확인할 수 있습니다. colbert 논문에서는(vision-languag는 아니지만) MaxSim-based late interation에서 maximum similarity를 average similarity로 교체한 ablation이 있는데, average similarity를 사용하자 그 성능이 하락하였습니다.
안녕하세요 재연님 리뷰 감사합니다.
cross-modal late interaction 수행을 위해 contrastive learning loss를 적용했다고 이해했습니다. cross-modal interaction 을 위해 attention 등의 기법을 사용하는 연구가 많은것으로 알고 있습니다. attention 기법을 적용할 경우, 명시적으로 정보를 퓨전할 수 있어 효과적일 것 같은데, 해당 연구들보다 본 연구가 더 효과적인지 궁금합니다.
감사합니다.
사실 본 논문에서는 VLP를 image-text contrastive learning계열과 Language Modeling based 계열로 나누어서 설명하기에 cross-modal interation에 관련해서 자세한 언습은 없었습니다. 만약 vision feature와 language feature간 cross-attention을 하면 정보를 융합하는데 효과적일 수 있겠으나, 그렇게 만들어진 모델(인코더)가 image encoder나 language encoder로써 잘 동작할 수 있을지 의문이 들고, inference단계에서도 image feature와 language feature를 동시에 입력해야 해서 그 범용성에 제약이 있지 않을까 생각이 드네요. 관련해서는 추가적인 팔로업이 필요할 것 같습니다.
안녕하세요. 좋은 리뷰 감사합니다.
저자들은 zero-shot 성능 향상을 위해 prompt suffix로 “i like it”과 같이 “it”을 포함하는 접미사를 추가했다고 언급하셨는데, 혹시 다른 참조어에 대한 비교 실험이 있는지 궁금합니다. 또, 앞단에서 언급했던 offline으로 사용 불가능하다고 한 몇 기존 모델들은 구체적으로 어떤 설계로 인해 그런 제한이 있는건가요 ? 추론 단에서도 항상 image와 text를 함께 입력으로 넣어야 하는 경우인건가요?
감사합니다.
it 이외 다른 참조어 관련 언급은 없지만, appendix 에 보면 it을 포함한 다양한 suffix를 활용한 것을 활용할 수 있습니다(“I like it”, “I hate it”, “It’s ugly”, “It’s common in daily life”, “Hope you like it”, “It’s beautiful” .. )
기존 몇몇 VLM들의 경우 사전학습 및 추론 단계 모두에 image-text를 함께 입력해야 했기에(cross-attention 생각하시면 이해 되실 겁니다) 각 인코더를 별도로 offline으로 활용할 수 없었다고 합니다.