
안녕하세요, 허재연입니다. 오늘 다룰 논문은 CLIP과 같은 image-text pair로 대규모 사전학습을 진행한 VLM모델들의 지식을 dense prediction task에 효율적으로 전이할 수 있는 방법을 제안한 논문입니다. 제안하는 방법론이나 성능 결과가 좋아서 내용이 알찬 듯 하면서도, 서술이 명확하지가 않아서 문장을 여러 번 읽어보고 코드를 찾아보게 만드는 점이 아쉬운 논문이었습니다. 한번 살펴보겠습니다.
Introduction
이제 딥러닝 기반 컴퓨터 비전에서 사전학습+미세 조정의 패러다임은 하나의 표준이 되었습니다. ImageNet과 같은 대규모 labeled dataset으로 사전학습한 가중치를 활용해 transfer learning을 진행하는 방법이 많이 사용되었고, 2020년 이후에는 SimCLR, MoCo, BYOL 등등 image 데이터를 활용한 contrastive learning 계열의 self-supervised learning(SSL)이 우수한 성능을 보여주어 SSL로 학습된 인코더 백본을 fine-tuning하여 사용하기도 했죠. 특히 픽셀 단위 예측이 필요한 task들의 경우 라벨링 비용이 높아 사전학습이 더욱 중요해졌습니다. 이렇게 잘 사전학습된 가중치를 활용하는것은 빠른 수렴을 보장하고 데이터 추가 구축에 대한 필요성을 완화시키기에 어느 순간부터 보편적으로 활용되기 시작했습니다.
기존의 전통적인 방법과는 다르게, 웹에서 수집한 대규모 image-text pair를 활용한 contrastive learning을 활용하여 매우 뛰어난 visual representation을 확보한 CLIP이 제안되어 매우 뛰어난 zero-shot 성능을 보여 주목을 받기 시작하였습니다. 이미지와 텍스트 간 의미적 관계를 활용하여 CLIP은 텍스트 데이터의 풍부한 지식을 활용할 수 있었고, 다양한 visual task에서 좋은 결과를 보여주었습니다. 하지만 당시 대부분 image classification, image-text retrieval과 같은 이미지 인스턴스 단위의 task에서 평가가 이루어졌고 segmentation, detection과 같은 dense prediction task로의 적용은 크게 고려되지 않았었습니다.
본 논문에서 저자들은 CLIP의 upstream contrastive learning 과정과 downstream의 픽셀 단위 task간 차이에 대한 문제에 집중하여, 사전학습된 CLIP 모델을 어떻게 해야 dense prediction task에 잘 적용할 수 있을지 탐구하였습니다. 사전학습 단계에는 이미지 인스턴스-텍스트 인스턴스 간 비교를 통해 학습을 진행하기 때문에 이미지 / 텍스트의 세부적인 요소가 충분히 고려되지 않을 수 있고, downstream task가 이미지에서 세부적인 정보를 기반으로 수행되기 때문에 이를 고려할 필요가 있다는 것이죠. 이런 문제정의가 낯설지만은 않은게, 기존의 SSL 연구 흐름에서도 SimCLR, MoCo, BYOL 등의 방법론들이 이미지 인스턴스 전체 단위의 비교를 통해 사전학습을 진행하여 데이터의 세부적인 요소에 대한 고려가 부족한 것을 문제 삼아, 영상 데이터의 local feature를 보다 잘 학습할 수 있는 방법들이 연구되었습니다(DenseCL, PixPro, InsLoc, SoCo ..). 어찌보면 자연스러운 연구 흐름이라고 생각되네요. 하지만 DenseCL계열의 논문들의 경우는 사전학습 과정에서 어떻게 image data의 국소적인 영역 정보를 더 잘 학습할 수 있을지 방법을 제안하였다면, 본 논문은 사전학습된 CLIP의 지식을 어떻게 dense prediction task에 잘 전이할 수 있을까, 어떻게 하면 좋은 fine-tuning을 수행할 수 있을까에 집중한 연구로 생각하시면 되겠습니다. 기존의 SSL 방법론들은 주로 ImageNet 데이터를 활용해서 데이터셋을 활용하기 용이하고 학습 크기도 그렇게 크지 않았지만, CLIP의 경우 데이터 규모가 4억개의 image-text pair이기에 그 용량이 훨씬 크고 학습에 사용된 데이터셋이 공개되지 않아 사전학습 단계에서 무언가 수정하기엔 쉽지 않은 부분이 있습니다.
사전학습된 CLIP의 지식을 활용하는 가장 단순한 방법은 사전학습된 모델을 바로 downstream task에 fine-tune하는건데, 저자들은 이런 단순 적용으로는 CLIP model의 표현력을 충분히 활용할 수 없다고 생각하였습니다. CLIP의 학습법인 contrative learning 프레임워크에 영감을 받아서, 저자들은 본래 CLIP의 image-text matcing 문제를 변형하여 pixel-text score map을 활용한dense prediction model을 학습법을 제안합니다.
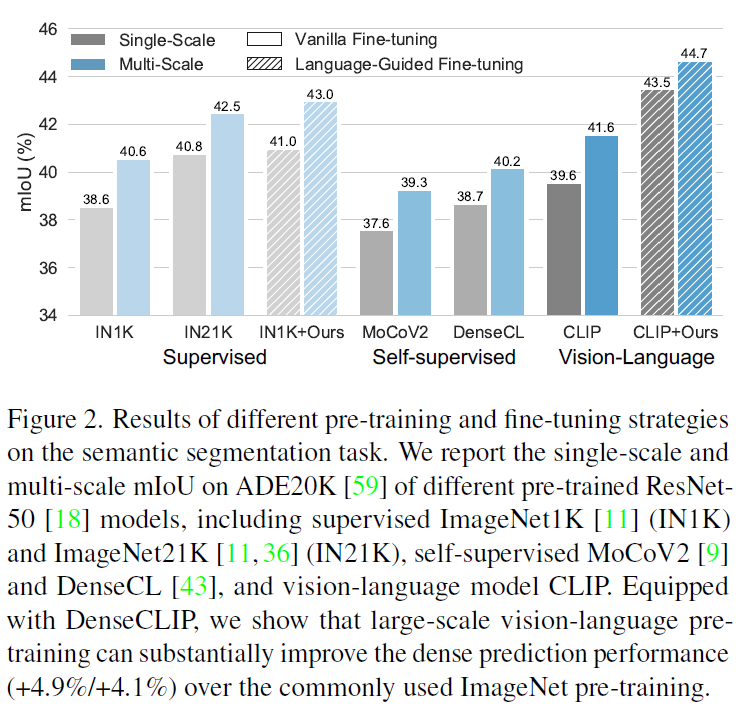
Figure 2를 보시면 Semantic Segmentation(ADE20K)에서 supervised imagenet, self-supervised learning 방법론들, CLIP, 그리고 저자가 제안하는 DenseCLIP을 비교하였습니다. 다른 방법론들의 경우 바로 fine-tuning을 진행하였습니다. 결과적으로, CLIP 모델이 약간의 하이퍼파라미터 변경만으로 ImageNet 사전학습 기반 모델들보다 좋은 성능을 보여주었으며, 이와 비교해서 CLIP 사전학습 모델을 DenseCLIP방법을 활용해서 fine-tuning한 것이 더욱 경쟁력 있는 결과를 보임을 확인할 수 있습니다.
논문이 전반적으로 이미지 인코더는 ResNet을, task로는 semantic segmentation을 고려하며 작성된 것이 느껴집니다. 물론 다른 백본 및 task에도 적용할 수 있지만, 논문/리뷰를 읽으실 때 이를 염두하시며 읽으시면 이해가 더 쉬울 것 같네요.
Approach
Preliminaries: Overview of CLIP
CLIP은 이미지 인코더(ResNet 혹은 ViT)와 텍스트 인코더(트랜스포머)로 구성됩니다. 4억개의 image-text pair를 활용해서 이들을 각각 임베딩 공간에 투영한 후 정렬하는 contrastive learning을 수행해 학습을 진행합니다. 이렇게 학습된 모델을 분류에 적용할 때 “a photo of a [CLS]”과 같은 템플릿을 활용한 텍스트 프롬프트를 활용합니다, 각 이미지에 대해 image-text prompt 간 임베딩 유사도를 측정해서 가장 유사도 점수가 높은 클래스를 해당 이미지의 클래스로 지정하는 방식이죠. 그럼 이런 성능 좋은 CLIP을 보다 더 복잡한 vision task에 적용시키려면 어떻게 해야 할까요? ResNet / ViT와 같은 이미지 인코더를 단순히 사전학습된 백본으로 취급해서 바로 파인튜닝을 진행하는게 간단한 방법이긴 하지만 저자들은 이렇게 할 경우 텍스트 인코더에 포함된 language prior가 무시된다는 문제가 있다고 합니다. 또한 사전학습 때 진행된 데이터 인스턴스 단위 대조학습과, 목표로 하는 픽셀 단위의 downstream task간 격차가 상당하기에 이를 고려할 필요가 있다고 합니다.
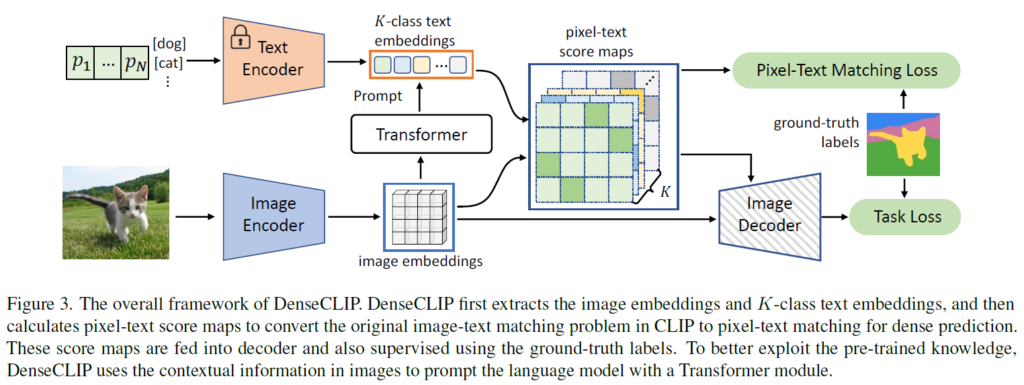
Language-Guided Dense Prediction
위에서 언급한 문제를 완화하기 위해, 저자들은 사전학습된 CLIP의 language prior를 더 잘 활용할 수 있는 language-guided dense prediction framework를 제안합니다. 제안하는 파이프라인은 Figure 3과 같습니다.
저자들은 CLIP의 인코더에서 global feature 뿐만 아니라, language-compatible feature map을 추출할 수 있는 점에 집중합니다. ResNet을 예로 들면, 마지막 conv layer에서 feature map을 용할 수 있을 것입니다. 이 때 CLIP은 attention pooling이라는 기존의 ResNet과 다른 추가적인 요소를 활용하였는데요, 마지막 feature map x4에서 global average pooling을 수행해 \bar{x}4를 추출합니다. 이후 concat한 feature [latex]\bar{x}4, x4[/latex]를 다음과 같이 Multi-Head Self-Attention layer에 넣습니다.

일반적인 CLIP에서는 이미지 인코더의 출력으로 global feature \bar{z}를 사용하고, z는 사용되지 않고 무시됩니다. 하지만 저자들은 z가 여전히 풍부한 공간적 정보를 가지고 있어서 featuremap으로 사용할 수 있음에 주목하였습니다. 이때 ResNet encoder의 경우 flatten된 형태의 z가 다시 H,W정보를 활용해 reshape하고, ViT의 경우도 transformer encoder를 통과한 다음 permute 및 reshape(B, -1, H, W) 연산을 통해 feature map 형태로 만들어줍니다. text feature의 경우 CLIP text encoder를 활용해 text feature t를 추출하고, text feature t와 language-compatible feature map z를 활용해서 다음과 같이 pixel-text score map을 계산해줍니다:
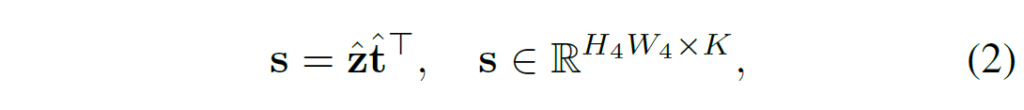
\hat{z}와 \hat{t}는 각각 z, t를 l2 normalized해준 것입니다. 정규화 한 후 내적을 수행했으니 각 요소는 cosine similarity가 되겠죠. 이렇게 만들어진 score map은 일종의 낮은 해상도의 segmentation map으로 볼 수 있고, 이를 auxiliary segmentation loss에 활용하여 학습을 도울 수 있습니다. 또한, score map을 최종 feature map에 concat하여 명시적인 language prior로 활용할 수도 있습니다.
Context-Aware Prompting
저자들은 이에 그치지 않고 text feature t를 만드는 부분에서도 prompt learning을 활용해 추가적인 성능 개선을 시도하였습니다.
CLIP은 “a photo of a [CLS]”와 같은 사람이 정의한 프롬프트를 사용하는데, 프롬프트 엔지니어링을 수행하기에는 비효율적이기 때문에 prompt를 학습하는 연구가 기존에 수행되었습니다. 대표적으로 CoOp은 prompt template을 learnable vector로 만들어 CLIP의 각 encoder를 freeze해 학습을 진행하여 역전파를 통해 prompt template을 학습하도록 하였죠. 다음 수식 (3)에서 p는 prompt template에 해당하는 learnable vector, ek는 class k에 해당하는 부분입니다.
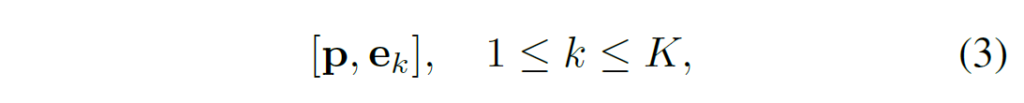
Vision-to-language prompting
언어적 정보를 활용하여 visual feature를 더 풍부하게 만들 수 있을 뿐만 아니라, 반대로 시각적 맥락을 활용하면 텍스트를 활용하면 텍스트를 더 정교하게 다듬을 수 있습니다. 저자들은 이에 visual context를 활용해 text feature를 더 정교하게 다듬는 방법을 연구하였습니다. 시각적 정보와 언어적 정보간 관계를 모델링하는 다양한 방법이 있지만, 저자들은 자주 사용되는 방법인 cross-attention을 활용하였습니다.
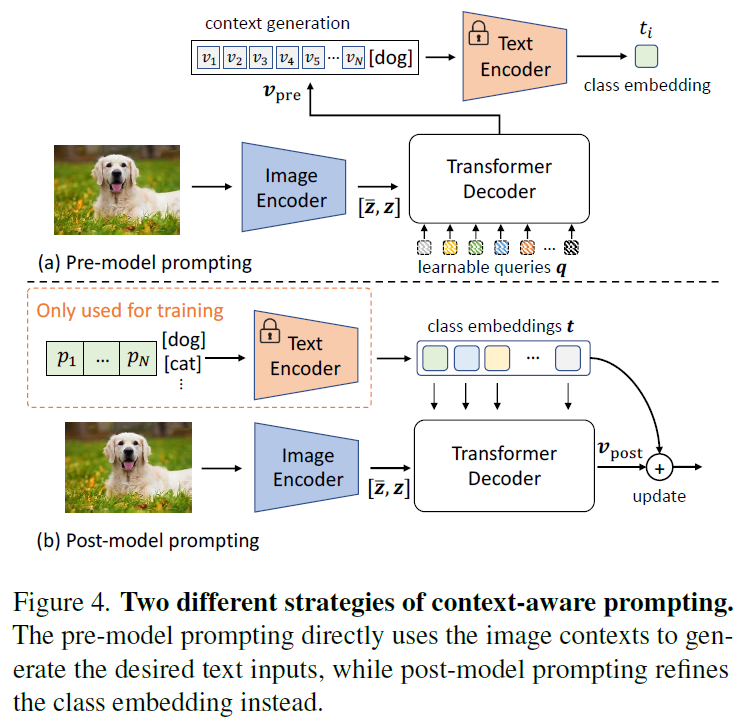
이 때, 두가지 옵션이 있습니다. Fig.4에서 확인할 수 있듯 visual-text interaction을 text encoder를 거치기 이전에 수행할수도, 이후에 수행할수도 있습니다 (a) pre-model prompting의 경우 feature [\hat{z},z]를 트랜스포머 디코더에 태워 다음과 같이 연산을 수행합니다.
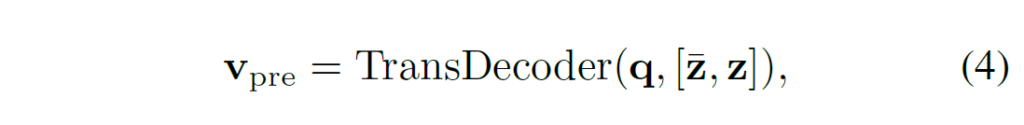
(4)에서 q는 learnable query 집합이고 {v}_{pre}는 추출된 visual context입니다. (3)수식의 p를 {v}_{pre}로 교체하여 이를 text encoder의 input으로 사용할 수 있습니다.
또 다른 방법은 text encoder이후에 text feature를 정제하는 방법입니다. 위 Figure 4의 (b)post-model prompting에 해당하는 방법으로, CoOp을 활용해 text feature를 생성하고 이를 바로 Transformer decoder의 쿼리로 사용하는 방법입니다.
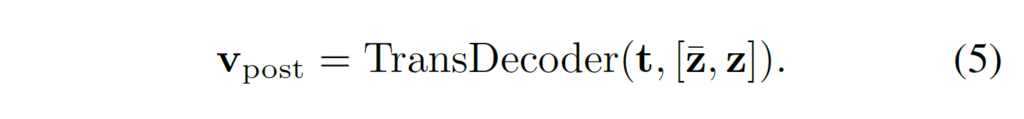
이런 형식의 구현을 통해 text feature가 가장 관련있는 visual clues를 찾을 수 있도록 하고, text feature를 다음의 residual connection으로 업데이트 합니다.
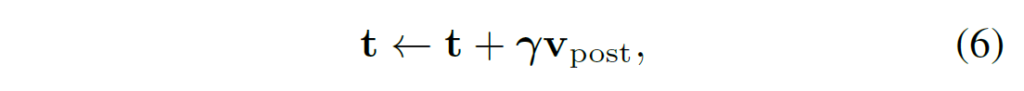
이떼, 업데이트를 아주 조금씩 하여 text feature에서 나온 language prior를 보존할 수 있게 구현하였다고 합니다.
(a) pre-model과 (b)post-model 방법 중, pre-model prompting 방법은 입력이 image에 의존성을 갖기 때문에 inference 단계에서 별도의 forward pass를 필요로 해서 비효율적이고, 최종 성능도 비교적 떨어졌기 때문에 저자들은 post-model prompting 방법을 사용하였다고 합니다.
Instantiations – Semantic Segmentation
앞에서 설명했던 것처럼 제안하는 프레임워크는 pixel-text score map을 활용해 segmentation에서 보조적인 손실함수를 활용하도록 하엿습니다. score map은 일종의 작은 segmentation 결과로 볼 수 있기에, 저자들은 다음과 같이 보조적인 segmentation loss를 만들었습니다.
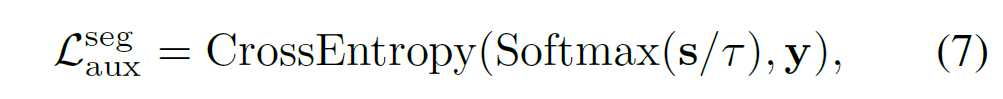
여기서 y는 ground truth label을 의미하며, temperature parameter(tau)는 0.07로 설정되었습니다. 저자들은 이런 auxiliary segmentation loss가 feature map이 빠르게 국소적 정보를 찾을 수 있도록 도와주기에 detection이나 segmentation과 같은 dense prediction task에 도움을 줄 수 있다고 분석합니다.
Instantiations – Object detection & instance segmentation
object detection이나 instance segmentation같은 경우에는 GT segmentation label을 가지고 있지 않으므로, segmentation에서의 auxiliary loss를 설정하는것과 비슷하도록 구성하기 위하여 bounding box와 label을 활용해 y∈{0,1}의 binary target을 구성하였습니다.이를 활용해 auxiliary objective는 다음과 같이 binary cross-entropy형태로 설계하였습니다.
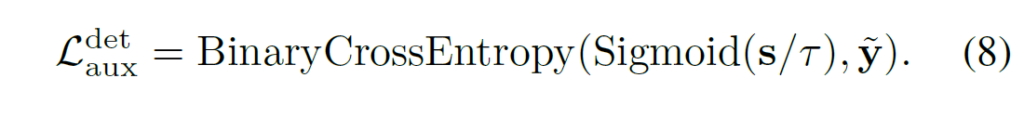
Experiments
주요한 실험은 sementic segmentation task에서 이루어졌습니다. 벤치마킹은 대규모 데이터셋(2만개의 학습 셋 및 150개 클래스로 구성)인 ADE20K에서 이루어졌습니다.
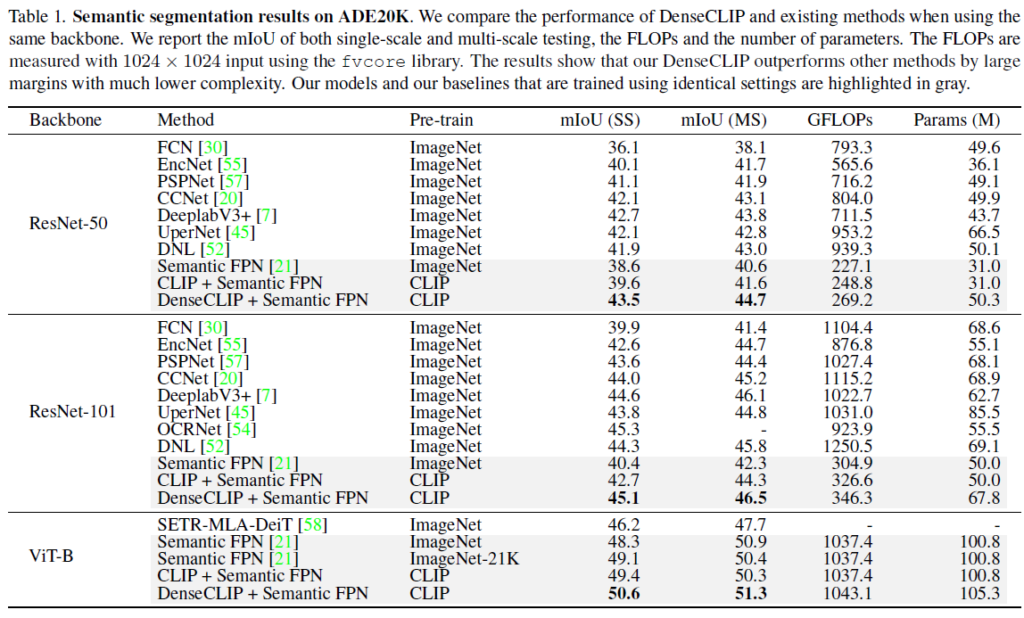
Table 1에서 확인할 수 있듯, 다양한 모델 및 방법론과 비교해서 CLIP 사전학습 모델을 DenseCLIP법으로 transfer한것이 일관적으로 좋은 성능을 보였습니다.
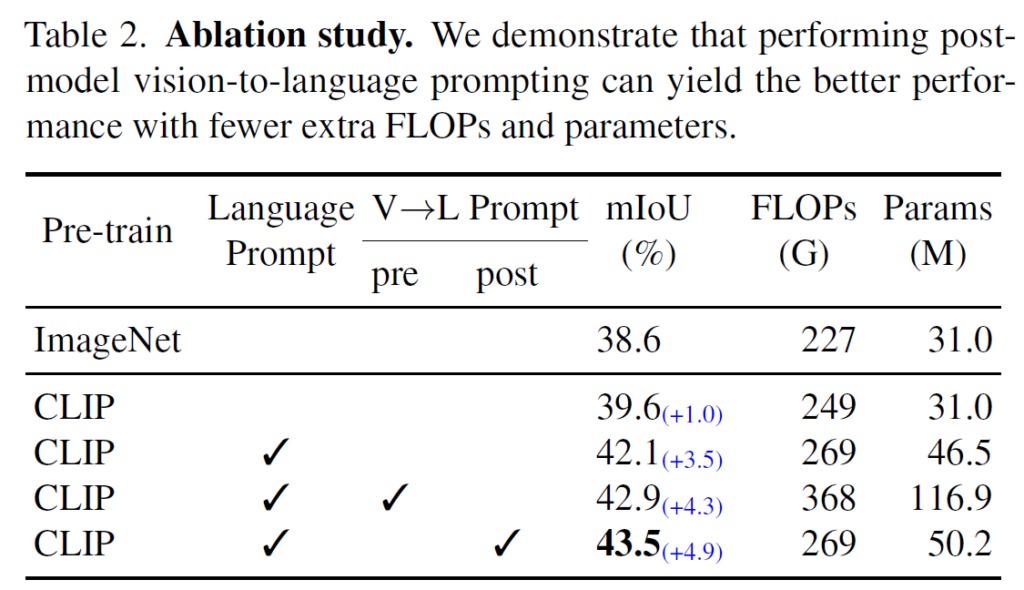
DenseCLIP의 각 구성요소의 효과를 확인하기 위한 Ablation study도 수행되었습니다. 각각 디테일한 ablation은 ResNet-50을 기반으로 수행되었습니다. 결과적으로 language prompt를 활용한 것과, Visual->Language prompt를 활용하는것 둘 다 성능에 긍정적인 영향을 미치며, post-model promping이 pre-model prompting보다 효과적인것을 확인할 수 있었습니다. pre-model prompting의 경우 이미지를 활용해야 해서 추가적인 forward를 해야해서 그런지 FLOPs와 Params가 비교적 높네요.
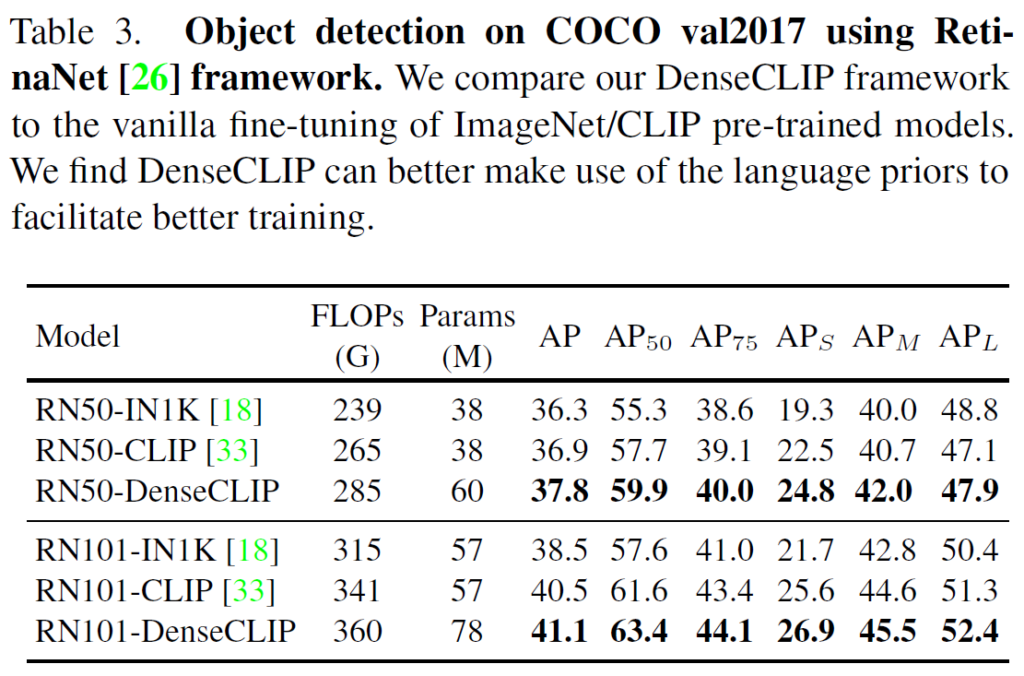
COCO 데이터셋에서 RetinaNet을 활용한 벤치마크에서는, ResNet50 및 ResNet101 백본 모두에서 DeseCLIP방법이 단순히 이미지넷 / CLIP 사전학습 모델을 곧바로 파인튜닝한것보다 매우 일관적으로 좋은 결과를 보였습니다.
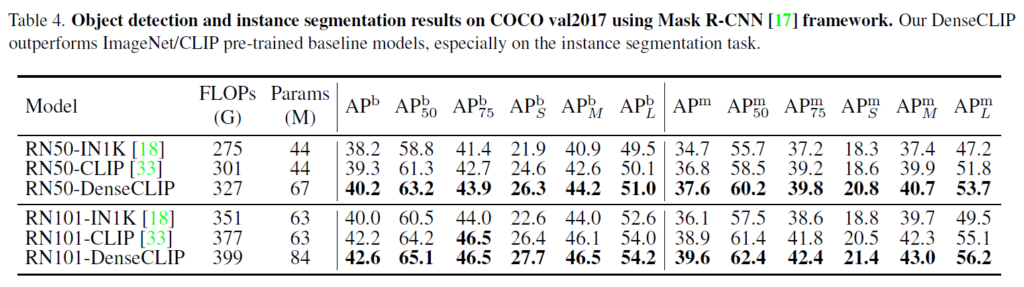
다음은 Mask RCNN을 활용한 COCO데이터셋에서의 detection 및 instance segmentation 결과를 Table 5에 나타내었습니다. 한두개 정도 성능은 최고 성능이 아닐만도 한데.. 일관적으로 비교군을 압도하는 성능을 기록하였습니다. 굉장히 깔끔해서 놀랍네요.
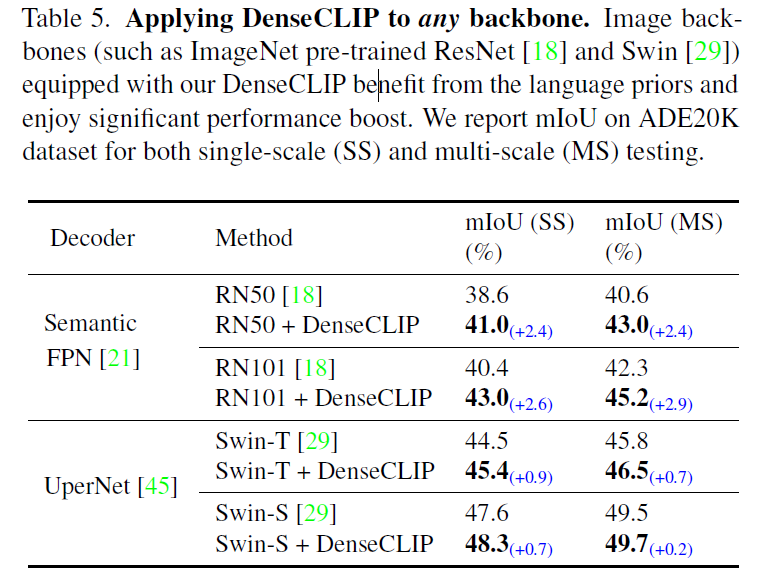
DenseCLIP은 visual backbone을 finetuning하는데 language prior를 활용하게 됩니다. 하지만 해당 프레임워크는 CLIP visual encoder뿐만 아니고 다른 백본으로 교체에도 적용할 수 있습니다. 이에 저자들은 text 정보가 없는 다른 백본으로도 해당 프레임워크가 좋은 결과를 낼지 실험을 수행하였습니다.
결과적으는, 매우 일관적으로 semantic segmentation에서 DenseCLIP을 적용한 것이 좋은 성능을 보여주었습니다. 맨처음 본문을 읽을 때는 글의 서술이 타 CVPR들보다 매끄럽거나 명확하지 않아서 아쉬웠는데, 성능으로 찍어누른 느낌이 없지 않은 것 같습니다(지극히 개인적인 생각입니다).

정성적인 결과를 보고 리뷰 마무리 하도록 하겠습니다. 어느정도 체리픽이 들어갔긴 했겠짐나, ImageNet, CLIP, 과 비교하여 DenseCLIP으로 학습한 segmentation 모델인 좋은 segmentation 을 수행하는 것을 확인할 수 있었습니다.
당시 주목받은 CLIP을 dense prediction task에 효과적으로 적용시킨 논문이었습니다. 비록 fine-tuning을 해야하기에 open-vocabulary setting에 활용할수는 없겠지만, 제가 이런 transfer learning계열 논문을 별로 읽어본 적이 없어서 신선했습니다. 이제 더 성능이 압도적인, 또 open-vocabulary / zero-shot으로 활용 가능한 모델들이 많이 나와서 이 방법론을 직접적으로 활용하지는 않겠지만, 문제 정의 및 제안하는 방법이 좋다는 생각이 드네요. 이만 리뷰 마무리하도록 하겠습니다.
감사합니다.
안녕하세요 재연님 리뷰 감사합니다.
세미나 때도 궁금했었는데, 최근에 관심을 가지기 시작하셨다고 들었어서 혹시 어떤 연구를 위해서 찾아보고 계신건지 궁금합니다!!
또 DenseCLIP은 dense prediction task에 CLIP의 지식을 효과적으로 전이하는 걸 목표로 했는데, 현재는 SAM-CLIP 형태로 결합해서 사용하는것이 같은 방식인데 더 효과적인 방법이 된건가요? 세미나 질문때 들었었는데 확실하게 정리가 되지 않아서 여쭤봅니다!!
아마 앞으로는 scene understanding 계열 연구를 수행할 것 같습니다. 세부적으로는 open-vocabulary Scene Graph Generation을 염두하고 있습니다. open-vocabulary 세팅의 문제를 해결하기 위해서는 결국 VLM의 지식을 잘 활용해야할것으로 생각되어서 관련 논문들을 살펴보았습니다.
SAM과 CLIP을 결합하는 방법과 비교하기 위해서는 단순 비교는 적절하지 않고, 각각의 특성을 고려하여 원하는 상황에 알맞게 적용해야 할 것 같습니다. 일단 DenseCLIP은 transfer learning을 목표로 하며, open-vocabulary detection/segmentation을 수행할 수 없습니다. 만약 DenseCLIP을 활용하는 방법이 SAM+CLIP계열의 방법론들보다 추론 속도가 빠르거나, closed-set 세팅에서 정확도가 높으면 부분적으로 DenseCLIP을 활용하는게 유리할 수 있겠으나, 그렇지 않은 경우에는 SAM과 CLIP이 워낙 강력한 프레임워크이다보니 이들을 활용하는게 더 좋지 않을까 하네요. DenseCLIP의 경우 CLIP 등장 직후 제안된 방법론이기에, 지금 시점을 기준으로 본다면 아쉬운 부분이 있는것이 사실입니다.
안녕하세요 재연님 리뷰 감사합니다.
질문이 3가지 있습니다.
먼저, DenseCL 계열의 경우 영상의 국소적인 영역 정보를 잘 학습하도록 개선한 반면 본 논문은 dense prediction task에 맞게 전이학습 하다록 개선했다고 설명해주셨는데요, 국소적인 영역정보와 dense prediction task가 실제로 다른 의미를 갖는지 궁금합니다. 전자를 크게 개선하면 후자가 동시에 해결된다고 이해해도 될까요?
다음으로, 현재는 SAM 등으로 dense prediction task에 대한 문제가 어느정도 해결되었다고 알고있는데, 기존 SSL 연구 관점에서 볼 때, 다음 연구는 어떠한 방향으로 진행될지에 대해 어떻게 생각하시는지 궁금합니다.
마지막으로 제가 이해한 바로는 본 논문은 CLIP의 language-compatible feature map 구조를 적극적으로 활용하기 위한 방법을 제안한 것으로 이해했습니다. text와 연관 있는 영역을 학습하는 것이 국소적인 정보에서 dense prediction으로 관점을 바꿀 수 있었던 이유가 궁금합니다.
감사합니다.
1. dense prediction task를 위해서는 국소적인 영역 정보를 잘 활용해야 하기에 다른 의미로 쓴 것은 아닙니다. 해당 부분은 DenseCL, CCrop같은 방법론들의 경우 ‘사전학습’ 과정에서 국소적인 정보를 학습하는데 집중하였다면, 본 논문의 경우 fine-tuning 과정에서 dense prediction task를 고려하였다는 점을 강조하기 위해 작성하였습니다.
2. 제가 2025년 현재의 연구 트렌드까지 자세히 팔로업되어있는 상태는 아니지만, 이제 어느 정도 dense prediction task에 대한 문제가 SAM을 활용하여 해결되었으니, 이제는 보다 fine-grained한 부분에 대한 인식 성능을 개선하거나(의미론적으로 다르긴 하지만 유사한 것을 구분한다던가 .. ), 대규모 사전학습 모델의 지식을 어떻게 효율적으로 가벼운 네트워크에 이식할 수 있는지에 관심이 높아지지 않을까 합니다(지극히 개인적인 의견입니다)
3. 단순한 finetuning 방법은 영상 전역 단위 학습법으로 사전학습된 CLIP image encoder를 곧바로 segmentation task에 fine-tuning하기에 dense한 정보를 다시 찾도록 학습되어야 하고(해당 과정은 text 정보와 사전학습 과정에서 align된 CLIP의 능력을 활용할 수 없겠죠), CLIP encoder가 갖고 있는 language prior를 활용하지 못합니다. DenseCLIP에서는 CLIP feature map이 이미 특정 text와 관련 있는 영역의 정보를 어느 정도 갖고 있으니 language prior를 학습에 추가적으로 활용하게 됩니다. 이를 통해 language 정보를 갖고 있는 CLIP feature를 더 잘 활용할 수 있게 되며, finetuning 과정에서 들어오는 language를 부가적인 정답 값으로 활용하여 더욱 잘 수렴할 수 있게 된다고 보여집니다.
좋은 리뷰 감사합니다.
language-compatible feature map이라는 게 어떤 것인지 설명 해주실 수 있나요? 이미지를 이용하여 CLIP feature를 뽑았을 때, 이 feature가 language와 호환 가능하다는 것이 맞나요? 뒤에 있는 ResNet 예시가 어떤 의미인지 잘 이해가 되지 않습니다..
또한, Table 1의 캡션에 회색 영역이 특정 세팅에서 학습된 베이스라인과 해당 논문의 실험 결과라고 하셨는데, 어떤 세팅의 차이가 있는 지 설명 해주실 수 있을까요??
CLIP은 사전학습 과정에서 image feature와 text feature 간 정렬을 반복하면서 학습했으니, CLIP image encoder에는 text feature에 대한 지식이 어느 정도 확보되었을 것입니다. 저자들은 CLIP image encoder가 text feature의 지식을 갖고 있으니 CLIP image encoder를 downstream task에 맞게 fine-tuning 할 때 language 정보를 추가적으로 활용하자는 아이디어를 가지고 DenseCLIP법을 제안하였습니다. image feature가 language와 compatible하다는 것은 image feature가 text feature와 이미 어느 정도 정렬되어 있으니 text 정보를 활용할 수 있다는 뜻으로 생각하시면 좋을 것 같습니다(단순히 imagenet으로 사전학습한 resnet feature는 text에 대한 지식을 갖고 있지 않을 테지만, CLIP resnet은 text에 대한 지식을 갖고 있으니까요).
Table 1에서 회색 영역은 저자자 제안하는 방법론을 직접적으로 비교할만한 성능들만을 보기 편하게 별도로 표시한 것입니다. 회색 영역 모두 Semantic FPN구조를 기반으로 하지만, 사용한 인코더 가중치 초기화 및 finetuning을 다르게 하여 비교하였습니다. ImageNet으로 사전학습한 인코더와 CLIP인코더를 비교하였을 때 CLIP인코더가 더 좋은 성능을 보여주었으며, CLIP 인코더 기반의 Semantic FPN을 활용하되 저자가 제안하는 DenseCLIP을 활용하여 finetuning을 하면 더 개선된 결과를 얻을 수 있습니다. 이외의 실험 세팅은 (회색으로 표시된 영역끼리) 동일합니다. 회색 영역이 아닌 것들은 다양한 Semantic segmentation 모델들의 성능으로, 모델 구조 및 활용한 가중치가 달라 회색 영역과 직접적인 비교가 적절하지 않습니다(저자가 제안하는 것은 모델 구조가 아닌 finetuning 방법이므로).