안녕하세요 지금부터 비디오 생성의 퀄리티를 높이기 위해 Test-Time Scaling(TTS)을 어떻게 적용하는지를 다룬 논문을 소개하겠습니다. Test-Time Scaling은 추론 단계(test-time)에서 연산량과 같은 리소스를 확장(scaling)하여 예측의 품질을 개선하는 방법인데요, 본 논문은 해당 컨셉을 Video Generation에 처음 접목한 논문입니다. Video Generation에 TTS 기법을 도입해야 하는 이유와, 도입 방법에 대해 리뷰를 통해서 알아보겠습니다.
Vide generation (2025-04-22 테스크 설명 추가)

논문을 소개하기에 앞서 Video generation 테스크에 대해 간단히 소개하겠습니다. Video generation은 자연어 입력으로 영상을 생성하는 기능입니다. 여러분에게 익숙한 sora 를 떠올리시면 쉽게 이해가 될 것입니다.
한편, 생성된 비디오가 물리적 직관이나 상식과 벗어나는 경우가 많지요. 문제 사항을 개선하기 위해 학습 데이터를 생성하고 모델을 재학습하는 등 근본적인 해결은 비용적 문제로 어려운 경우가 많습니다. 본 논문은 inference 과정에 테크닉을 적용해 학습 없이 문제사항을 개선하고자 하는 논문입니다. Figure 1은 inference에 테크닉(TTS)를 적용한 것(녹색 영역)과 적용하지 않은(붉은 영역)을 비교한 결과입니다. 첫번째 예시인 Figure1의 노란색 박스 부분을 보면 “코기가 드럼을 친다” 라는 입력에 대한 생성 결과물을 비교하고 있는데요, 모델의 성능에만 의존해서 생성된 붉은 영역의 비디오는 코기가 사람으로 변하는 등 입력과 매칭되지 않는 결과를 생성했습니다. 그러나 학습없이 inference에서 테크닉을 적용하므로써 코기가 드럼을 치는 고품질의 영상을 생성할 수 있음(녹색 부분)을 확인할 수 있습니다.
Video generation 테스크에 대한 간단한 소개와 본 논문이 제시하고자 하는 솔루션을 간단하게 언급했는데요, 이어서 어떤 테크닉을 이용하여 개선 효과를 이루었는지 살펴봅시다.
Why Test-Time Scaling is needed for Video generation ?
Test-Time Scaling(TTS)는 LLMs에서는 이미 많이 연구되고 있는 분야입니다. 학습에 많은 리소스가 필요한 분야에서는 특히 추론을 통한 출력 개선방법인 TTS가 필수적입니다. 가장 잘 알려진 예시로는 중간 추론 단계를 통해 연산량을 높여 답변의 정확도를 높이는 기법인 Chain-of-Thought(CoT) Prompting이 있습니다. 그 외에도 여러개의 출력을 생성하여 최적의 선택을 출력값으로 하는 Best-of-N, 여러 출력 중 일치하는 출력을 선택하는 Self-consistency 방법, 최적의 선택에 높은 점수를 부여해 모델 기반으로 선별하는 Reward-guided search 방법역시 TTS에 속합니다.
본 논문은 학습에서 많은 연산이 발생하는 Video generation에 TTS를 처음 적용한 논문이라는 점에서 독창성을 갖습니다. Video generation은 학습에 많은 리소스가 필요한 테스크 입니다. 학습 리소스에 증가없이 효과적으로 성능을 높이기 위해 저자는 TTS를 적용해야한다고 주장했으며 단계별로 연산량을 높이는 CoT의 컨셉과 많은 예측을 생성하고 거기서 최적을 선택하는 augmentation 기반의 컨셉(Best-of-N, Self-consistencyy, Reward-guided search)을 적절하게 적용한 Video-T1을 제시합니다.
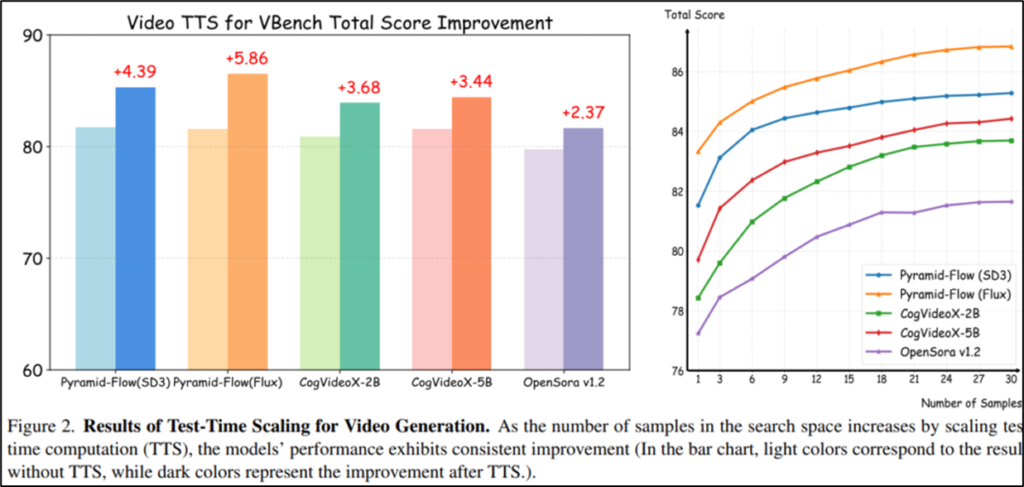
여기서 논문을 처음보는 분들은 저처럼 아무리 좋은 방법이라지만 적용이 필수적인지 의문이 생길 수 있습니다. 본 논문은 이에 대하여 Figure2를 통해 TTS로 어느정도의 성능개선을 낼 수 있는지 보임으로서 필요성을 다시한번 강조합니다. 먼저 Figure 2의 좌측(막대 그래프)는 TTS를 적용했을때, 최신 Video generation 방법론들의 개선효과를 보이는데, 방법론 간의 개선 수치보다 TTS를 적용한 개선 정도가 높음을 확인할 수 있습니다(N=30). 또한 우측(선그래프)는 N개의 샘플을 생성하고 최적의 하나를 선별하는 TTS 과정에서 N의 개수를 1개에서 30개까지 증가시켰을 때 생성 품질의 개선 효과를 보이는데요, 생성 개수가 많을 수록 최종 품질이 개선되는것을 보임으로서 TTS와 최종 출력 품질의 강한 연관관계를 보입니다. 이때, 품질을 평가하는 지표인 Total score는 후에 실험에서도 평가지표로 사용되는 산출법으로 Vbench[1]에서 제시된 16가지 품질(motion smoothness, semantic alignment, aesthetic quality 등)을 종합한 점수입니다. 본 실험을 통해 재학습을 위한 연산량이 큰 Video Generation 분야에서 TTS를 통한 성능개선이 필수적임을 다시한번 확인할 수 있습니다.
What is Video-T1 ? (conceptual explanation)
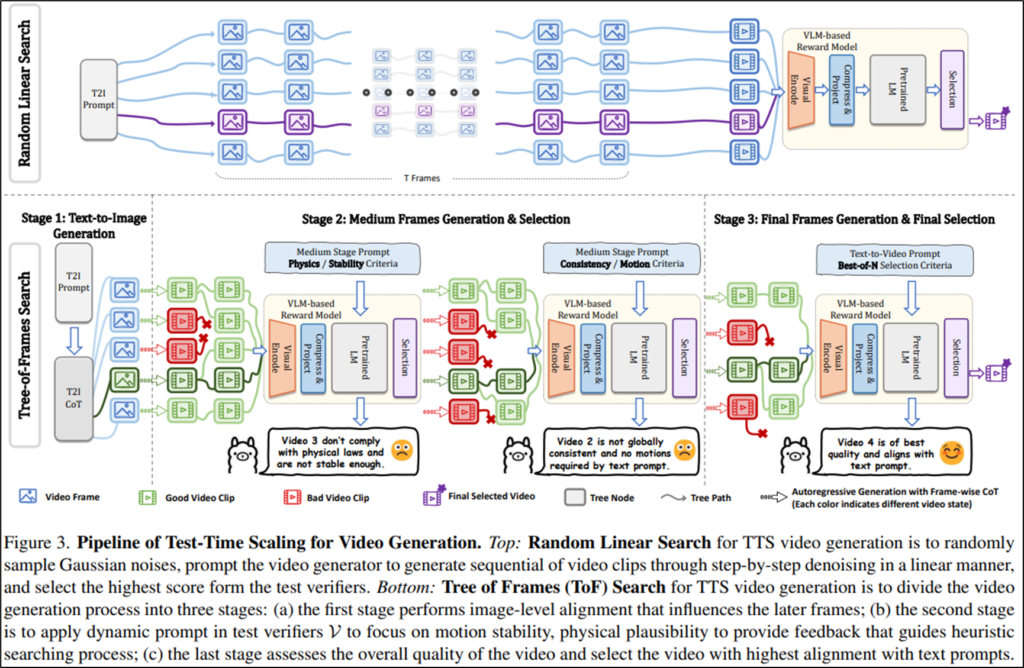
앞서서 Video-T1은 Video generation에 TTS를 적용하기 위해 “추론 자체에 연산량을 높이는 CoT의 컨셉과 많은 예측을 생성하고 거기서 최적을 선택하는 augmentation 기반의 컨셉을 적절하게 적용”하였다고 소개했습니다. LLMs의 대표적인 두가지 TTS기법(이하 Cot, Augmentation)이 어떻게 Video-T1의 파이프라인에 적용되었는지 알아보겠습니다.
Video-T1의 기본적인 파이프라인은 Figure3의 Tree-of-Frames(ToF)로, “효과적으로 많이 만들어서 좋은것을 잘 선택하자 “가 근본적인 방법론의 컵셉입니다. 가장 직관적인 TTS를 적용한 Video-generation 프레임워크는 Random linear search로 Figure3의 상단 그림에 해당합니다. prompt로 부터 수많은 비디오를 끝까지 생성해낸 다음, VLM 모델을 기반으로 최적의 비디오를 선택하는 것으로, 연산량이 많이 낭비되게 됩니다. 본 논문은 이러한 베이스라인의 문제를 개선하기 위해 프래임 단위로 생성하며 적합하지 않은 생성 프로세스를 종료하여 “효과적으로 많이 만들기”를 구현했습니다. 또한 각 단계마다 Verifier를 수행한다는 관점에서 잘못된 예측을 생성할 확률을 줄임으로서 CoT의 컨셉도 파이프라인에 잘 접목시켰습니다.
The detailed of Tree-of-frames

Algorithm1의 Random linear search는 전체 비디오를 한번에 생성한 후(line 5-line7), verifier로 평가(line 9)하여 가장 고품질인 비디오를 선별하는 반면, 제안 방법인 Algorithm2는 프레임 단위로 생성하며, 매 프레임 평가(line7-line22)를 통해 생성을 지속할지 결정합니다. 생성을 지속할 프레임((line19-line21)에 대해서 다시 n개의 후보 프레임을 생성(line 12)하고 평가(line 13)를 지속하기 때문에 더욱 고품질의 비디오를 비교적 낮은 연산량으로 생성할 수 있게됩니다.
Experiments
논문은 제안 방법의 효과를 6가지의 오픈소스 비디오 생성 모델에 적용해 실험했습니다. 실험에 사용된 모델은 비디오의 모든 프레임을 생성할 때 단일 노이즈를 기반으로 생성하는 디퓨전 기반 모델 3가지와 (OpenSorav1.2, CogVideoX-2B, CogVideoX-5B) 이전 프레임의 정보를 기반으로 순차적으로 생성하는 autoregressive 모델 3가지 (NOVA, Pyramid-Flow (SD3), and Pyramid-Flow (FLUX))입니다. 다음으로, ToF에서 생성된 비디오의 품질을 평가하는 Verifier는 3가지의 multi-model 보상 모델(VisionReward, VideoScore, VideoLLaMA3)의 측정값을 모두 합하여 최종 평가 스코어를 산출하도록 구성했습니다. 이때, VBench는 비디오 품질 평가에서 ground-truth로 자주 사용되는 측정 방법으로, 본 논문에서도 해당 metric을 통해 결과(Total score)를 비교했습니다.
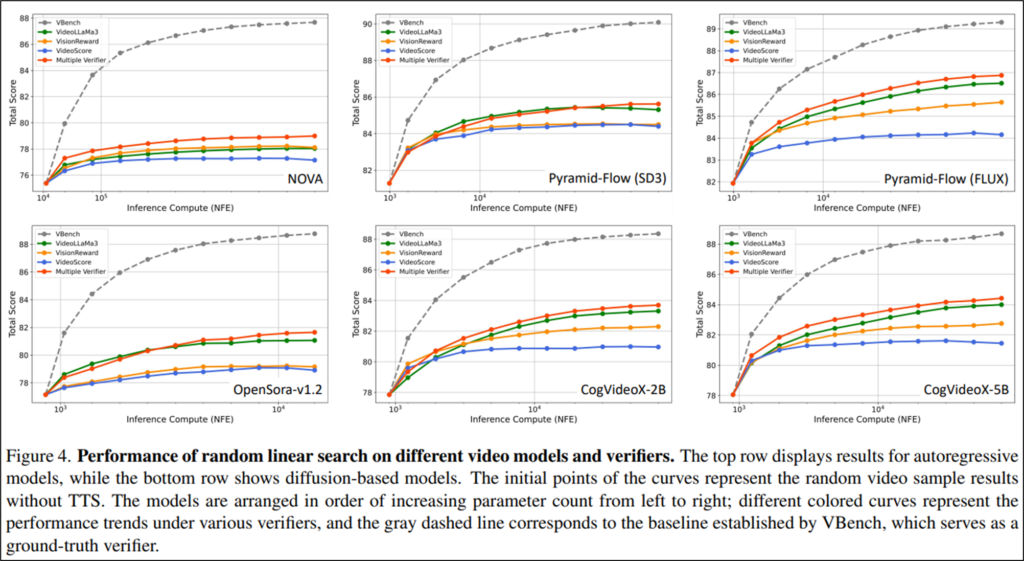
논문은 먼저 Test-Time Scaling(TTS)의 필요성을 확인하기 위해 Figure4에서 inference에 사용된 연산량에 따른 비디오 품질 향상도를 Random linear search 결과를 통해 확인하였습니다. 실험 결과 6가지 비디오 생성 모델 모두 추론 연산량이 증가할수록 품질이 높아짐을 알 수 있으며, 특정 수준 이후에는 품질 개선이 미미한 것을 통해 좋은 TTS 방법론을 적용하면 해당 지점을 더욱 적은 연산량으로 도달할 수 있음을 기대할 수 있습니다. 본 논문은 ToF를 통해 이를 구현하고자 했습니다.
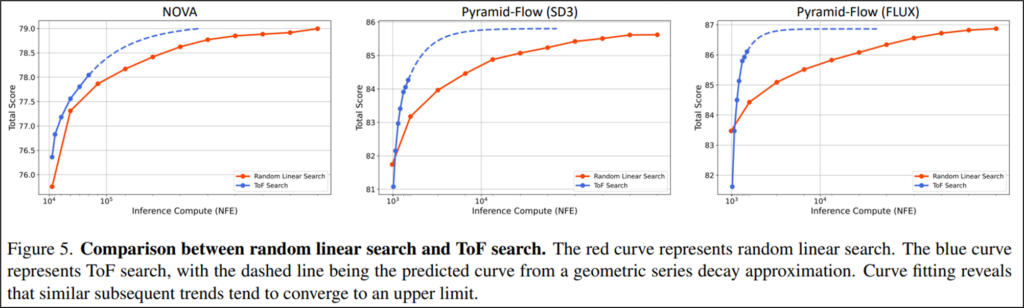
앞선 실험에서 TTS의 필요성을 확인했는데요, 다음 실험인 Figure 5에서는 제안 방법론인 ToF가 Random linear search 보다 얼마나 효과적인지 확인하였습니다. ToF는 프레임 단위로 피드벡을 통해 생성된 영상의 품질을 개선하는 방법으로, 프레임 단위 영상 생성을 지원하는 autoregressive 모델에만 적용 되었습니다. 실험 결과 동일 연산량 대비 빠른 성능 향상을 보였습니다. 또한 추세선(Figure 5의 파란 점선)을 통해 품질 개선이 수렴하는 수준에 Random linear search 대비 얼마나 빠르게 도달할 수 있는지 확인할 수 있습니다.
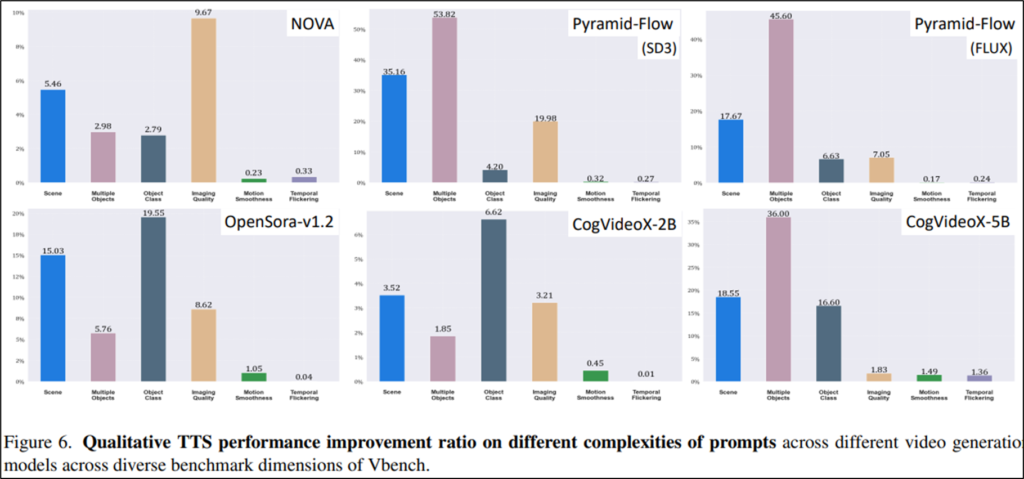
마지막으로 논문은 프롬프트 난이도라는 변수에 따른 TTS의 효과도 Figure6을 통해 비교했습니다. 각 막대 그래프는 TTS 적용 점수에서 TTS를 적용하지 않은 점수를 뺀 차이에 대한 그래프이며, 장면 설명(Scene), 객체 설명(Object) 같은 일반적으로 자주 사용되는 프롬프트에 대해 TTS 효과가 큼을 확인할 수 있습니다. 이를 통해 기존의 출력이 최적이 출력이 아니였음을 확인할 수 있습니다. 한편 움직임 관련된 지표인 Motion Smoothness와 Temporal Flickering에서는 성능 개선이 적었으며, 이는 현재 비디오 생성 프레임워크의 한계라고 지적했습니다.
참조
[1] Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024
이상으로 비디오 생성의 품질을 높이기 위한 방법을 알아보았습니다. Random linear search 구조에서 트리구조를 활용해 비디오 생성의 효율을 높인 것으로 이해할 수 있을 것 같습니다. 개인적으로 본 논문에서 몇가지 아쉬운 점은 있습니다. 예를 들어 중요한 실험 중 하나인 Figure 5에서 제안 방법론의 성능에 추세선을 사용했다는점, Figure6의 실험 세팅을 명확하게 밝히지 않은 점이 있으나, 비디오 생성 분야에서 TTS 연구의 필요성을 명확히한 점, 비디오 생성 모델이 개선해야할 부분(motion, time에 따른 연속성 등)과 TTS가 개선할 수 있는 부분을 명시적으로 나눈 점 등에서 다양한 인사이트가 있는 논문이라 생각합니다. 앞으로 더 눈길이 가는 연구가 있다면 소개해보도록 하겠습니다. 감사합니다.
리뷰 잘 읽었습니다. 궁금한 점이 하나 있어 댓글 남깁니다!
디퓨전 모델은 비디오를 한번에 생성하는것으로 알고있는데, 프레임 단위로 생성하는 해당 알고리즘에 어떻게 적용하였는지 궁금합니다
안녕하세요 홍주영 연구원님, 리뷰 읽어주셔서 감사합니다.
제가 리뷰 작성중에 오류가 있었던 점 사과드립니다.
금일(25-04-22) 기준
“디퓨전 기반 모델 3가지와 (OpenSorav1.2, CogVideoX-2B, CogVideoX-5B) 이전 프레임의 정보를 기반으로 순차적으로 생성하는 autoregressive 모델 3가지 (OpenSorav1.2, CogVideoX-2B, CogVideoX-5B) 입니다. ”
라고 쓰인 내용을
”
디퓨전 기반 모델 3가지와 (OpenSorav1.2, CogVideoX-2B, CogVideoX-5B) 이전 프레임의 정보를 기반으로 순차적으로 생성하는 autoregressive 모델 3가지 (NOVA, Pyramid-Flow (SD3), and Pyramid-Flow (FLUX))입니다.
”
로 수정하였습니다.
먼저 본 논문이 제안한 방법은 프레임 단위의 비디오 생성에서 피드백 과정등을 효과적으로 이용하여 autoregressive 기반 비디오 생성 모델의 동작을 개선하는데 초점을 맞추었습니다.
현재 ToF 적용 실험에 리포팅된 아키텍쳐는 autoregression 모델임을 확인하실 수 있습니다.
즉, 말씀해주신 것처럼 디퓨전 모델은 비디오를 프레임단위로 생성하지 않기에, ToF 적용 성능이 리포팅 되지 않았습니다.
꼼꼼하게 읽어주셔서 감사합니다
안녕하세요, 황유진 연구원님. 좋은 리뷰 감사합니다.
너무 생소한 분야라 이해하기가 어렵네요..질문 드리도록 하겠습니다.
Video Generation이 정확히 어떻게 수행하는 task인가요? 이름 그대로 어떤 입력(prompt?)에 대한 비디오를 생성하는 것 같은데, 어떻게 수행하는 것인지 감이 잘 오지 않습니다. Algorithm 1을 보면 가우시안에 따라 노이즈를 초기화하고, 비디오 프레임 길이만큼 video generator로 생성한 다음 비디오를 디코딩하는것으로 보이는데, video generation 및 decoding이 어떻게 수행되는것인지 궁금합니다.
안녕하세요 허재연 연구원님, 리뷰 읽어주셔서 감사합니다.
먼저 Video Generation은 우리에게 익숙한 Sora[https://openai.com/sora/] 를 생각하시면 좋을것 같습니다. 즉, 입력된 자연어에 맞는 비디오를 생성하는 테스크 입니다.
Video Generation 모델이 inference 과정에서 학습없이 좋은 비디오를 생성하기 위해, 한번에 여러개의 비디오를 생성하고 거기서 가장 품질이 좋은 비디오를 선별하는게 기존의 naive 한 Algorithm1 에 해당합니다.
본 연구는 video generation 및 decoding 모델에 대한 직접적인 개선은 아닙니다. 자연어 요청에 대해 비디오를 생성하는 inference 과정에서, 탐색 트리를 모방한 연산 효율적인 고품질의 비디오를 탐색 방법인 ToF를 제안한 것으로 이해하시면 좋을 것 같습니다.
감사합니다.
(테스크 이해를 위해 본 논문의 메인 이미지인 Figure1을 추가하였습니다.)