안녕하세요. 이번 리뷰도 매니퓰레이터 강화학습에 관한 내용으로 들고 왔습니다. 로봇과 태스크 변화에도 일반화를 보이는 강화학습 기법에 대한 가능성을 풀어나간 논문입니다. 리뷰 시작하겠습니다.
1. Introduction
이게 17년도 논문인데, 다양한 로봇 작업 및 서로 다른 로봇 플랫폼 간의 정책 이전은 로봇 제어 분야에서 오랜 기간 연구되어 온 도전 과제였습니다. 기존의 end-to-end 학습 방식이나 단일-task에 초점을 맞춘 접근법들은 실제 환경에서의 복잡한 상호작용과 환경 변화에 대응하는 데 한계를 보였습니다. 특히, 각기 다른 작업과 로봇 구조에 대해 개별적으로 학습된 정책들은 데이터 효율성이 낮고, 새로운 작업 또는 로봇에 일반화하기 어려워 재학습의 부담이 컸습니다.
즉, 본 논문은 다음 질문에서부터 출발합니다.
- “로봇이 과거에 수행한 task 경험 또는 다른 로봇이 수행한 task 경험을, 새로운 robot-task 조합에 바로 활용할 수 없을까?”
저자들의 핵심 가설은 로봇 매니퓰레이션 task 수행에서 반드시 학습해야 할 지식은 크게 두 종류로 나눌 수 있다는 것인데, 바로 Task-specific knowledge(Perception, 단계적 작업 플랜 등)과 Robot-specific knowledge(Dynamics, Kinematics, Low-level control 등)으로 나누는 것입니다. 그래서 이런 가설을 기반으로 저자들은 로봇 정책을 모듈화(modularization)하는 방안을 생각하게 됩니다.
본 논문에서는 위에서 언급한 기존의 여러 문제점과 가설을 기반으로, 다중 작업 및 다중 로봇 환경에서도 효과적으로 정책을 적용할 수 있는 modular neural network policy framework를 제안합니다. 제안된 접근법은 크게 세 가지 핵심 아이디어에 기반하여 구성됩니다. 1. 로봇 작업의 다양한 특성을 반영하기 위해 네트워크 구조를 모듈화하여, 각 모듈이 특정 기능(예: 감각 정보 처리, 행동 결정 등)에 집중하도록 한다. 2. 모듈 간의 인터페이스를 명확히 정의함으로써 서로 다른 작업 간의 공통 요소와 특수 요소를 효과적으로 분리, 재사용할 수 있게 한다. 3. 다중 로봇 및 다중 작업 환경에서의 경험을 통합함으로써, 개별 task에 한정되지 않는 일반화된 정책 학습이 가능하도록 한다. 였습니다.
제안된 모듈형 정책 학습 프레임워크의 contribution은 다음과 같습니다.
- 모듈화된 정책 네트워크 설계
기존의 단일 네트워크 구조와 달리, 제안된 시스템은 다양한 기능을 담당하는 서브 모듈들로 분할되어, 각 모듈이 독립적으로 학습되면서도 전체 정책으로 통합되는 방식으로 설계되었습니다. 이를 통해 task-specific feature의 추출과 일반적인 행동 결정 사이의 균형을 효과적으로 맞출 수 있었습니다. - 다중 작업 및 다중 로봇 전이를 위한 효율적 학습 전략
모듈 간 정보 공유 및 인터페이스 표준화를 기반으로, 하나의 작업 또는 로봇에서 학습된 모듈을 다른 작업이나 로봇 환경에 재활용할 수 있게 하였습니다. 이 과정에서, 기존의 재학습 문제를 크게 완화하고 데이터 효율성을 향상시키는 결과를 도출하였습니다. - 실험적 검증 및 비교 분석
제안한 방법은 다양한 시뮬레이션 및 실제 로봇 작업 환경에서 평가되었으며, 기존의 단일-task 학습 방식 및 end-to-end 접근법에 비해 학습 속도, 성능 안정성, 일반화 능력 면에서 우수한 결과를 보였습니다. 이러한 결과는 모듈화 접근법이 복잡한 실제 로봇 응용 환경에서 유망한 해결책임을 시사합니다.
2. Methods
일단 기본적으로 서로 다른 로봇 구조와 작업 등 이산적인 변화의 정도(Discrete degrees of variations, DoVs)라는 것을 갖는 여러 세계에서, 각 세계마다 독립적으로 최적의 정책을 학습하는 대신, 서로 간의 공통성을 활용하여 일부 세계에서 학습한 정책을 다른 미지의 세계로 효과적으로 전이하는 방법을 제안합니다.
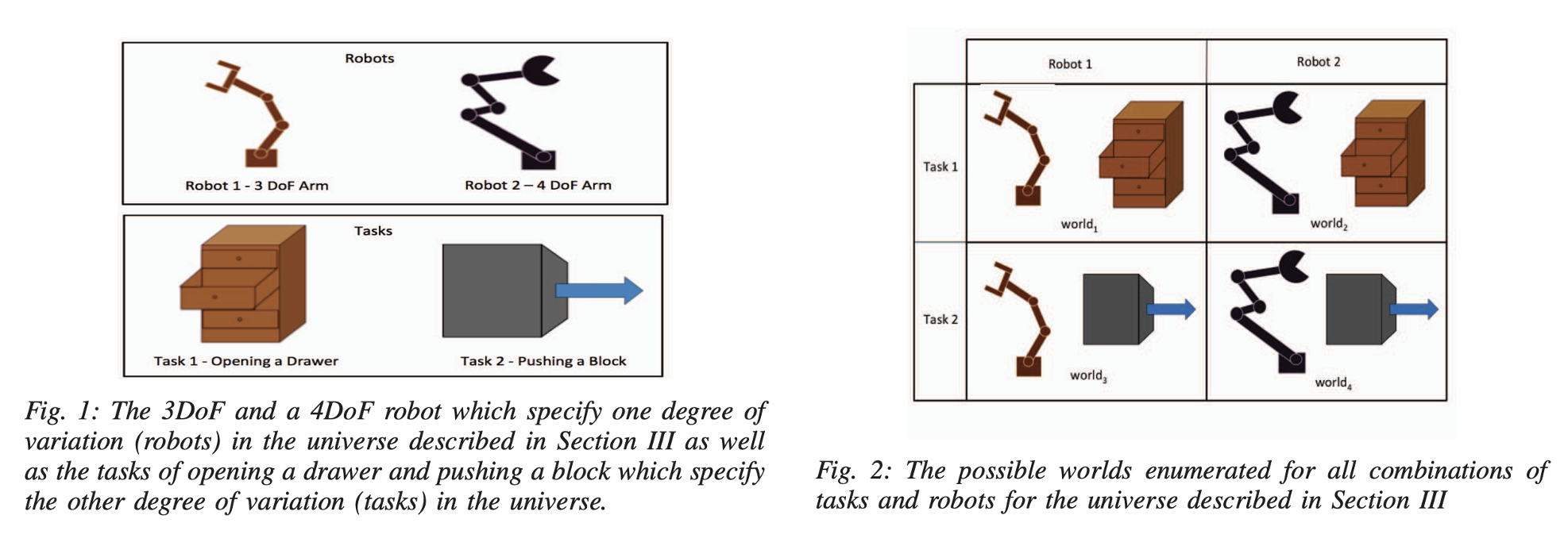
위 그림을 보시면 좀 와닿는 설명이 가능한데요.
- Degrees of Variation (DoVs, 변화의 정도):
사전에 정의된 이산적인 변화의 정도(DoVs)를 기준으로 다양한 상황 간의 지식 전이를 가능하게 하는 문제를 다룹니다. 여기서 DoVs는 로봇의 구조, 객체의 특성 등 여러가지로 정의될 수 있습니다. 정의하기 나름인 것 같지만 이걸 어떻게 정의하냐가 사실 핵심일 것 같습니다. - 세계(world)와 우주(universe):
- 세계 (w): DoVs의 특정 조합으로 구성된 하나의 인스턴스 즉, 각 세계는 여러 DoVs 중 하나의 구체적인 조합을 나타냅니다.
- 우주 (U): 가능한 모든 세계(w)들의 집합입니다.
- 예를 들어, 위 Figure처럼 우주가 Robots와 Tasks DoVs 만으로 구성된다고 가정하면(이는 최종적으로 저자들이 방법론 내에서 쭉 끌고 가는 가정입니다.),
- 첫 번째 DoV: 로봇 구조 (3 자유도(DoF)와 4 자유도)
- 두 번째 DoV: 작업 (서랍 열기와 블록 밀기)
- 이 경우 가능한 세계는 다음과 같이 4가지가 됩니다. 3 DoF 로봇이 서랍을 여는 세계, 3 DoF 로봇이 블록을 미는 세계, 4 DoF 로봇이 서랍을 여는 세계, 4 DoF 로봇이 블록을 미는 세계.
근데 이제 우주의 각 세계마다 최적의 정책은 상이할 수 있기 때문에, 모든 세계에 대해 하나의 단일 정책을 학습하는 방식은 비효율적이라는 점에 주목하면 될 것 같습니다. 기존의 표준 강화학습 알고리즘은 각 세계를 별개의 문제로 인식하여, 처음부터 해당 세계에 맞는 최적의 정책을 독립적으로 학습하는 형태였는데, 저자들이 주목한 점은 바로 서로 다른 세계들 간에도 공통된 요소가 존재한다는 점이었습니다. 예를 들어, 3 DoF를 가진 로봇이 서랍을 여는 작업과 블록을 밀어내는 작업은 수행하는 태스크 자체는 다르지만, 동일한 로봇 구조라는 공통점을 공유하고 있는 것처럼, 이러한 공통 요소를 활용하면, 한 세계에서 학습된 정책의 일부를 다른 미지의 세계로 전이시켜 적용할 수 있다고 저자들은 생각했습니다.
그래서 궁극적인 목표는 전체 우주의 모든 세계에서 정책을 학습하는 것이 아니라, 일부 세계에서 학습한 정책 지식을 바탕으로 새로운 미지의 세계에 효과적으로 전이시키는 것이었습니다. 이를 위해 논문에서 채택한 DoVs는 Robot, Task에 한정하여 문제를 다룹니다. 여기서 로봇의 수는 R로 표기하는데, 이는 서로 다른 시스템 파라미터, 모폴로지, 심지어 상태 및 행동 공간의 차원까지 포함할 수 있는 개념이고, 작업의 수는 K로 표기하는데, 모든 로봇이 K개의 작업을 달성할 수 있다는 가정을 전제로 합니다. 이런 접근 방식을 통해 각 세계별로 독립적인 학습 비용을 줄이고, 공통적인 특성을 기반으로 보다 효율적인 정책 전이를 실현하고자 하였습니다.
A. Preliminaries
먼저 강화학습 문제 설정에 필요한 기본적인 요소를 정의하면 다음과 같습니다.
각 세계(world) w 는 특정 로봇과 특정 작업의 조합으로 정의됩니다. 여기서 각 세계는 상태(state) x_w, 관찰(observation) o_w, 제어 명령(control) u_w 으로 구성됩니다. 관찰 o_w 는 로봇이 작업 수행 시 얻게 되는 모든 입력으로 이미지, 인코더 정보, 모션 캡처 데이터 등을 포함할 수 있습니다. 제어 명령 u_w 은 로봇 모터에 전달되는 관절 토크, 속도 또는 위치 명령 등의 값입니다.
각 세계 w 에 대해서 정책(policy) \pi_w(u_w|o_w) 를 정의할 수 있습니다. 이 정책은 관찰값 o_w 을 입력으로 받아 제어 명령 u_w 의 분포를 출력합니다. 정책 최적화의 목표는 정책 공간 내에서 최적의 파라미터를 찾아 비용(cost) c(o_w, u_w) 의 기대 합을 최소화하는 것입니다. 여기서 정책 최적화 과정은 각 세계에 대해 개별적으로 이루어지며, 이를 통해 얻어진 최적 정책 \pi_w^*(u_w|o_w) 는 주어진 관찰에서 행동을 결정할 수 있습니다.
관찰값 o_w 는 로봇에 따라 달라지는 intrinsic 요소 o_{w,R} 과 작업에 따라 달라지는 extrinsic 요소 o_{w,T} 로 구분될 수 있습니다. 일반적으로 로봇의 관절 상태나 센서 측정값과 같은 요소는 intrinsic 관찰에 속하며, 이미지나 물체의 위치 등 작업과 관련된 요소는 extrinsic 관찰로 분류됩니다. 예를 들어 로봇의 end-effector 위치는 intrinsic 및 extrinsic 관찰 모두에 포함될 수 있는데, 이는 로봇의 현재 상태와 작업의 진행 상황을 모두 결정짓는 중요한 요소이기 때문입니다.
비용 함수 역시 intrinsic 상태와 extrinsic 상태로 구분할 수 있습니다. 즉, 비용 함수는 c(x_w, u_w) = c_R(x_{w,R}, u_w) + c_T(x_{w,T}) 와 같이 표현됩니다. 제어 명령은 intrinsic 상태에만 영향을 미치며, 이는 로봇이 수행하는 동작 자체가 intrinsic 특성을 가지기 때문입니다. 이러한 상태와 비용의 구분은 정책의 모듈화를 가능하게 하는 핵심 가정입니다. 이를 통해 논문의 중심이 되는 modular policy networks의 효과적인 학습과 전이를 실현할 수 있습니다.
B. Modularity
모듈화에서는 각 정책을 robot-specific module과 task-specific module로 구분합니다. 예를 들어, 3DoF 로봇 팔이 서랍 열기와 블록 밀기 작업을 수행하는 두 개의 세계를 고려할 때, 두 작업은 서로 다르지만 동일한 로봇 구조를 공유하기 때문에 로봇 특화 모듈을 공유할 수 있습니다. 즉, 로봇 구조와 관련된 정보는 동일한 모듈에서 처리하고, 작업과 관련된 정보만 다른 모듈에서 처리하여 정책의 효율적 전이를 가능하게 합니다.
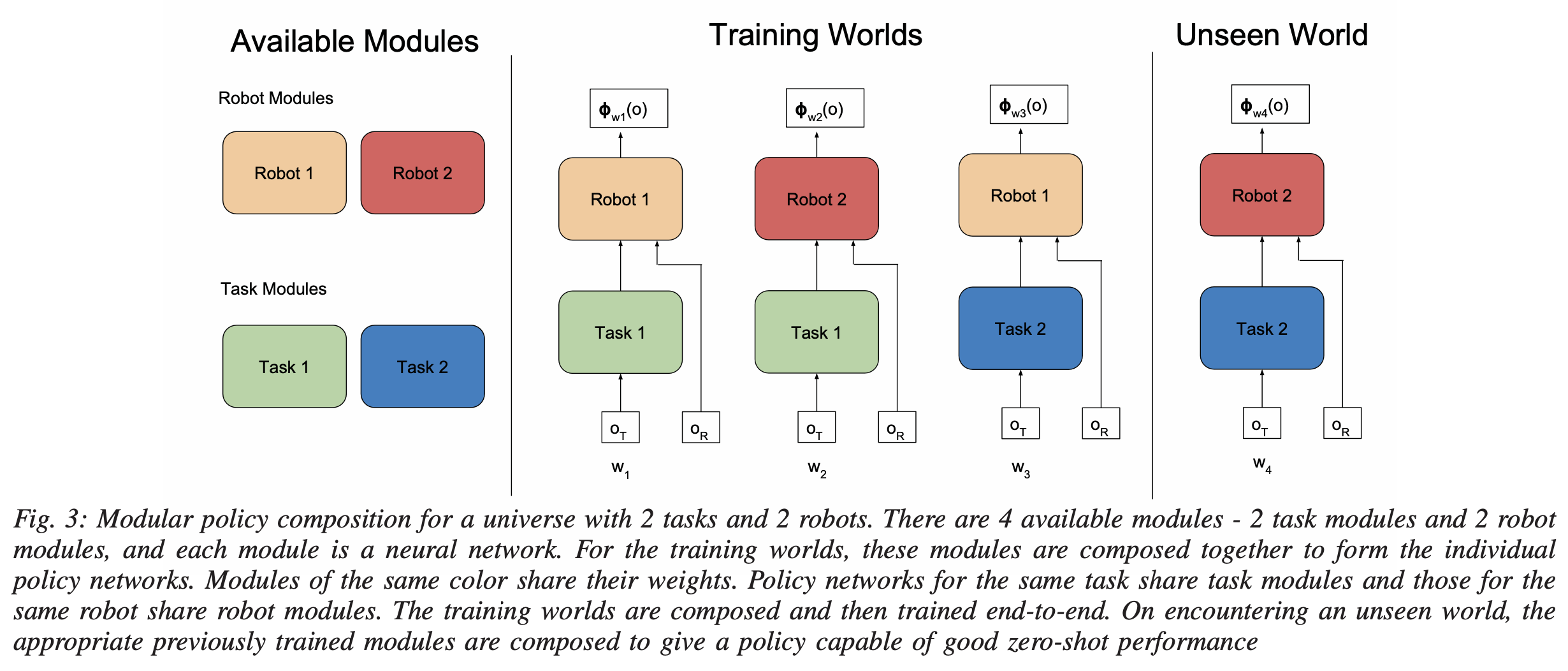
좀 더 구체적으로, 세계(world) w 의 정책 \pi_{wrk}(u|o) 은 로봇 r 과 작업 k 에 따라 정의됩니다. 이 정책은 일반적으로 다음과 같은 함수 \phi_{wrk}(o)로 파라미터화된 분포로 표현할 수 있습니다.
\pi_{wrk}(u|o) = N(\phi_{wrk}(o), \Sigma)여기서, 정책 평균(mean)을 나타내는 \phi_{wrk}(o)는 robot-specific module f_r과 task-specific module g_k의 합성함수 형태로 표현됩니다.
\phi_{wrk}(o_w) = f_r(g_k(o_{w,T}), o_{w,R})즉, 로봇 모듈 f_r은 작업 모듈 g_k의 출력을 입력으로 받아 intrinsic 관찰 o_{w,R}과 결합하여 최종적인 행동 출력을 생성합니다. 여기서 작업 모듈의 출력값은 미리 정의된 명시적인 의미가 아니라 학습 중 얻어진 잠재 표현(latent representation)으로, 로봇 모듈의 입력과 결합하여 행동을 결정하는 역할을 수행합니다. 위 그림을 보면 직관적으로 이해할 수 있는데, 각 w1, w2, w3 들에 대해 학습한다고 하면, 처음엔 o_{w,T} 를 인풋으로 받아 task 모듈을 한번 거친 후, 그 모듈의 출력을 o_{w,R} 인풋과 같이 받아 Robot 모듈을 거치는 구조인 것입니다. 그래서 task 모듈이 우선적으로 작업 수행 계획과 관련된 정보를 처리한 후, robot 모듈에서 최종 제어 명령을 결정합니다. 그러나 이러한 구조 외에도 저자들은 다양한 모듈 구성 방식이 가능하다고 열어두며, 일반적인 경우 모듈들을 Directed Acyclic Graph (DAG) 형태로 구성할 수 있다고 합니다.
본 모듈화 접근 방식의 장점은 학습되지 않은 새로운 세계 w_{test}, 즉 이전에 보지 못한 로봇-작업 조합에서도 기존에 학습된 모듈을 조합하여 바로 사용할 수 있다는 것인데 단순히 위 식들에서 test 텀만 붙어서 완전 새로운 observation들이 들어오면 됩니다. 이를 통해 별도의 추가적인 학습 없이 zero-shot transfer의 정책 성능을 기대할 수 있었고, 여기서 중요한 점은 모듈의 학습이 많고 다양한 세계에서 이루어질수록 해당 모듈은 다른 요소의 변화에 강건해지며, 결과적으로 일반화 능력이 향상될 것이라고 저자들은 기대합니다.
C. Architecture and Training
일단 핵심은 앞선 그 모듈들이 신경망으로 구현된다는 것입니다. 신경망을 선택한 이유는 높은 표현력과 확장성, 그리고 모듈 간의 조합을 통한 효율적인 전이를 용이하게 만들기 때문이라고 합니다. 17년도임을 고려하면 이 땐 막 강화학습에 Deep Learning을 도입하던 시기라 이런 당연한 표현들이 조금 이해가 갑니다. 아무튼 신경망 구성은 로봇 r 과 작업 k 로 구성된 세계 w 에서 정책 \pi_{wrk}(u|o) 는 신경망으로 표현된 함수 \phi_{wrk}(o) 를 통해 평균값을 가지는 가우시안 분포로 모델링됩니다. 이 신경망 함수 \phi_{wrk}(o) 는 로봇 모듈 f_r 과 작업 모듈 g_k 두 개의 하위 신경망으로 구성되며, 정책의 평균을 표현합니다. 본 논문에서 사용된 신경망의 구조는 다음과 같습니다.
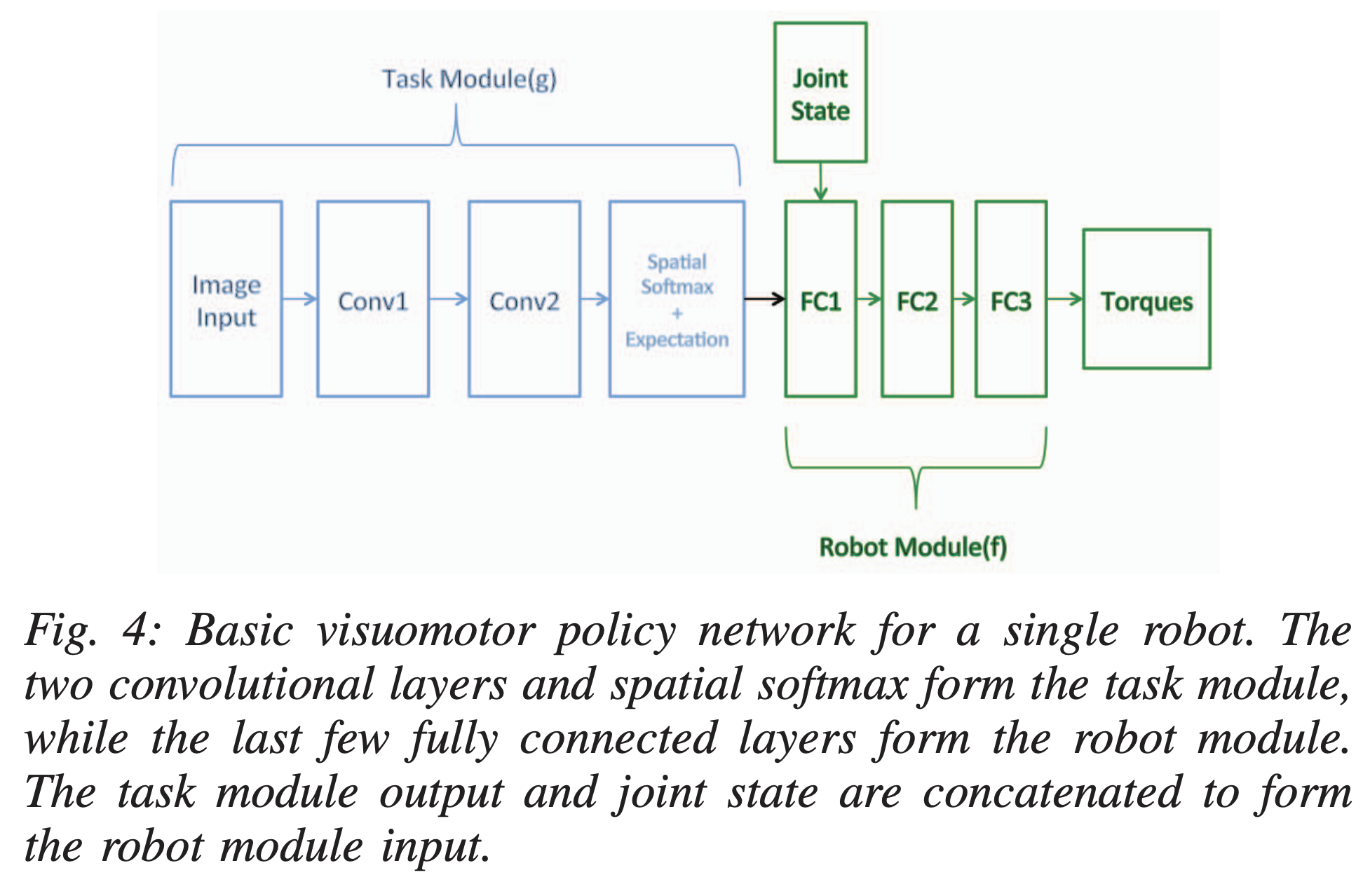
- 작업 특화 모듈 (g_k)
작업 모듈은 관찰 중 extrinsic 요소(o_{w,T})를 입력으로 받아 이를 잠재 공간(latent representation)으로 변환하는 역할을 수행합니다. 여기서 잠재 공간의 출력값은 별도의 의미적 제약 없이 학습 중 자동으로 형성되는 값입니다. - 로봇 특화 모듈 (f_r)
로봇 모듈은 작업 모듈에서 생성된 잠재 표현과 intrinsic 관찰 (o_{w,R})을 입력으로 받아, 최종적으로 로봇 제어 명령을 출력합니다.
전반적인 정책은 학습 과정에서 여러 작업-로봇 조합으로부터 동시에 수집한 데이터를 입력으로 하여 학습됩니다. 각 모듈의 파라미터는 공유되어, 같은 로봇을 사용하는 다양한 작업에서 로봇 모듈이 공통적으로 학습되고, 같은 작업을 수행하는 서로 다른 로봇에서 작업 모듈이 공통적으로 학습됩니다. 즉, 각 모듈은 최소한 하나 이상의 세계에서 학습된 후, 다른 모듈들과 조합될 때도 동일한 파라미터를 유지합니다.
정책 모듈의 학습은 모든 선택된 세계에서 동기적으로 이루어집니다. 즉, 먼저 각 세계로부터 샘플을 수집한 다음, 각 세계에 대응하는 모듈을 통해 입력 데이터를 forward pass로 각 세계의 예측 제어 명령을 산출하는 방식으로 수행됩니다. 이 과정에서 loss function L 은 다음과 같이 정의됩니다. L = \sum_{w} L_w
여기서 각 세계 w 에 대한 손실 L_w 은 구체적인 강화학습 알고리즘에 따라 달라질 수 있습니다. 본 논문에서는 Guided Policy Search(GPS) 알고리즘을 사용하였으며, GPS는 local trajectory optimization를 통해 supervised signal을 생성하여 신경망 정책을 학습시키는 방식으로 진행됩니다. 이 때 각 세계 w 에서의 손실 함수 L_w 는 GPS에 의해 생성된 최적화된 제어 명령과 신경망의 예측 제어 명령 간의 Euclidean distance를 최소화하는 지도 학습 형태로 정의됩니다.
이는 저희가 아는 일반적인 신경망 역전파 알고리즘을 통해 학습할 수 있다고 합니다. 정책 \pi_{wrk} 가 로봇 모듈의 파라미터 \theta_r 와 작업 모듈의 파라미터 \theta_k 로 파라미터화되어 있기 때문에, 각 모듈의 파라미터에 대한 gradient는 다음과 같이 계산됩니다.
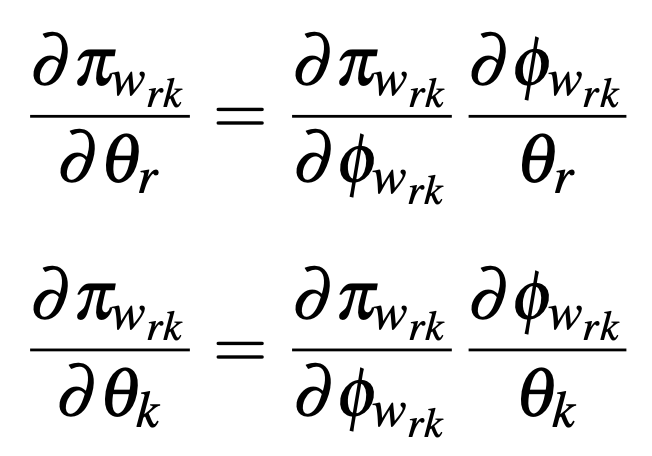
근데 이제 \phi_{wrk}(o_w) = f_r(g_k(o_{w,T}), o_{w,R}) 이니, gradient를 다시 표현하면 다음과 같습니다.
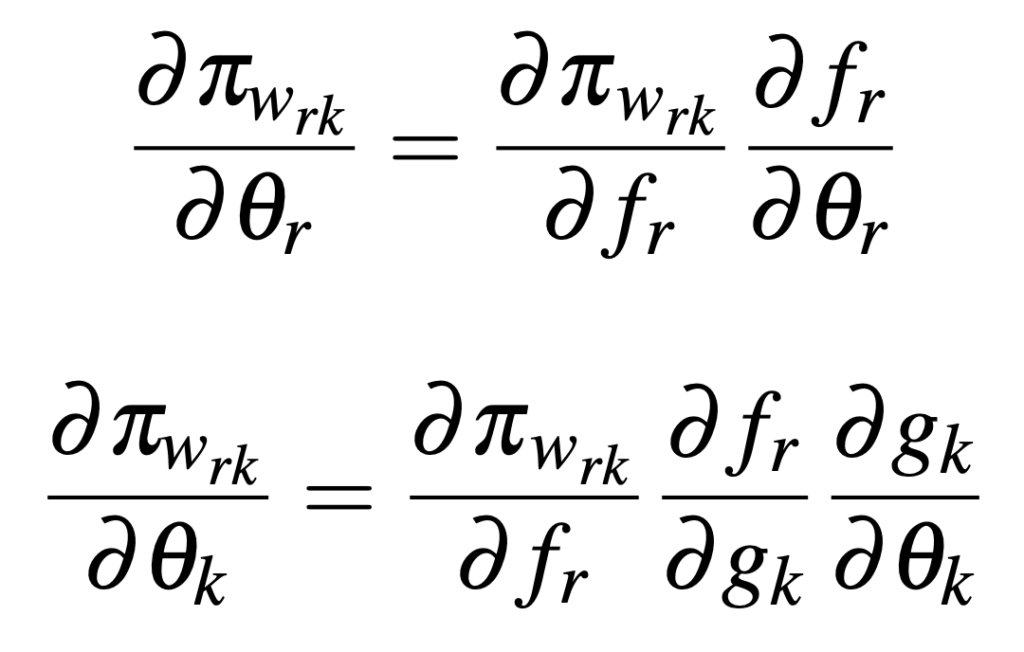
즉, 로봇 모듈과 작업 모듈에 대한 gradient는 각 모듈 간의 연결을 따라 기존의 역전파 알고리즘을 통해 효율적으로 계산될 수 있게 되는 것입니다.
D. Regularization
여기는 좀 임팩트가 약했는데요. 17년도 논문임을 감안하면 괜찮은 건가 싶으면서도 너무 basic한 regularization 기법을 쓰길래 조금 의아했습니다.
모듈형 정책 네트워크의 과적합을 방지하고 새로운 로봇-작업 조합에 대한 일반화 성능을 높이기 위해 두 가지 정규화 방법을 도입하는데,, 그냥 단순히 네트워크의 hidden unit 수를 제한하고, dropout을 사용해서 과적합을 방지했다고 합니다. 이게 zero-shot transfer에 성능 기여가 있었다고 하는데, 임팩트가 약해서 그냥 넘어가겠습니다.
3. Experiments
Reinforcement Learning Algorithm
본 논문에서 개별적인 모듈형 신경망 정책을 학습하기 위해 사용한 강화학습 알고리즘은 기본적으로 Guided Policy Search (GPS)입니다. GPS는 정책 탐색을 궤적 최적화(trajectory optimization)와 지도 학습(supervised learning)의 두 단계로 나누어 수행하는 방식으로, 상대적으로 적은 수의 샘플로도 효율적인 신경망 정책 학습이 가능합니다.
GPS 알고리즘은 먼저, 로컬 선형 가우시안 제어기(local linear-Gaussian controller)를 각 초기 상태(initial state)에 대해 개별적으로 최적화하여 생성합니다. 이 단계에서는 로컬 궤적 최적화 기법을 활용하여 각 상태로부터 최적의 제어 명령을 계산합니다.
다음으로, 이렇게 생성된 로컬 제어기들은 전역적(global) 신경망 정책을 지도 학습 방식으로 훈련시키는 데 사용됩니다. 즉, 로컬 제어기로부터 얻어진 최적의 제어 명령을 지도 학습의 목표값(label)으로 설정하고, 이를 따라 신경망이 제어 명령을 예측하도록 훈련됩니다. 이 과정에서 신경망 정책은 유클리디안 거리(Euclidean distance)를 최소화하는 regression objective를 사용하여 최적의 제어 명령을 근사합니다.
본 논문에서 사용된 GPS의 변형인 BADMM(Bregman Alternating Direction Method of Multipliers) 기법은 신경망 정책에서 생성된 궤적과 로컬 제어기의 궤적 간 차이를 최소화하는 추가적인 제약(penalty)을 도입하여 학습 안정성을 높입니다. 본 연구는 GPS 알고리즘을 선택했지만, 모듈형 정책 네트워크는 정책 그래디언트(policy gradient)나 액터-크리틱(actor-critic)과 같은 다른 표준 강화학습 알고리즘과도 쉽게 결합할 수 있다고 합니다.
실험은 시뮬레이터인 Mujoco 기반으로 실험했다고 합니다.
Reaching Colored Blocks in Simulation
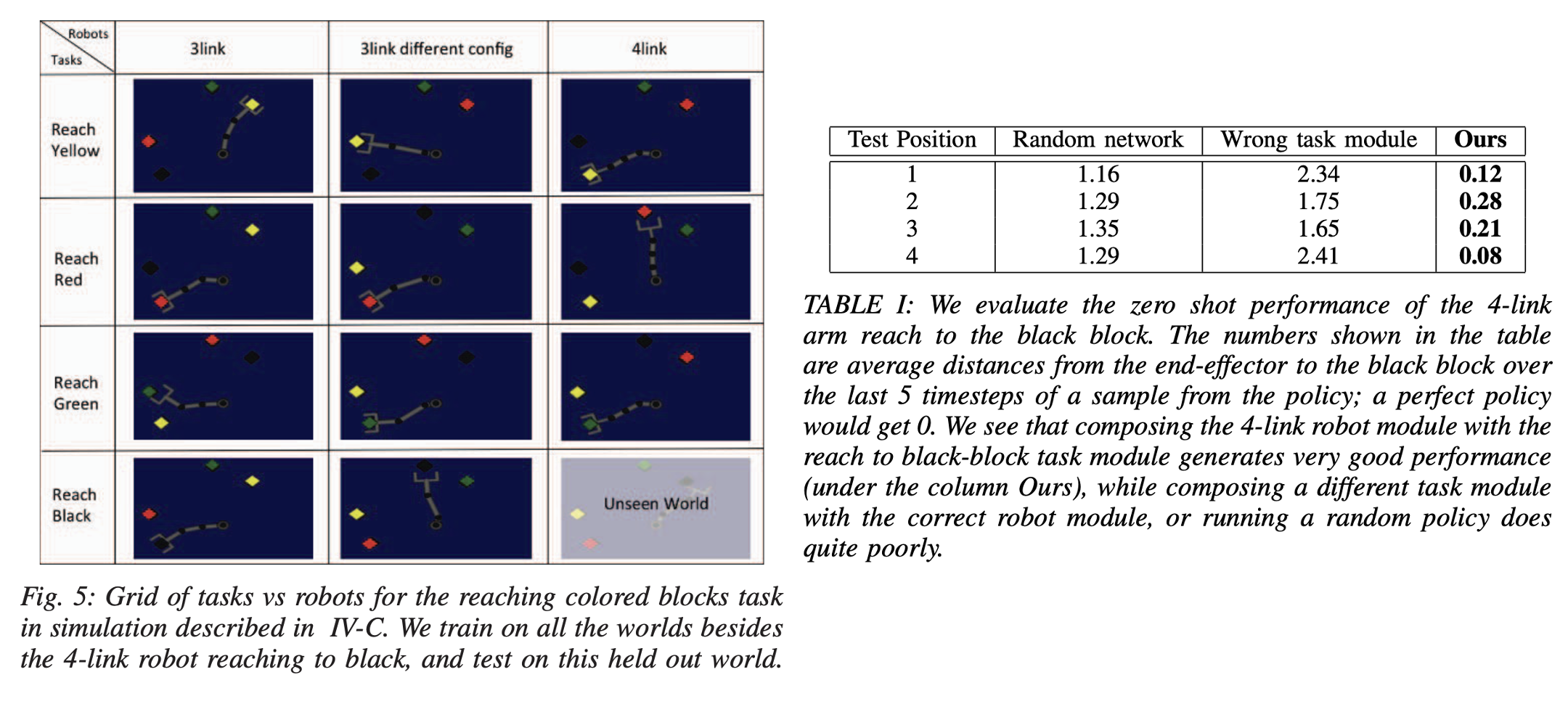
첫 번째 실험은 모듈형 정책 네트워크가 시각적 인식과 로봇 제어의 요소를 효과적으로 분리할 수 있는지 평가하기 위함이었습니다. 이 실험에서 로봇의 작업 환경은 빨강, 초록, 노랑, 검정 네 가지 색의 블록이 무작위로 2D 시뮬레이터 공간에 놓인 형태이며, 로봇은 특정 색상의 블록을 향해 팔을 뻗는 작업을 수행합니다.
실험에는 3개의 서로 다른 로봇이 사용되었습니다. 3링크, 좀 긴 3링크, 4링크입니다. 모듈 네트워크의 입력 데이터는 80×64 크기의 시뮬레이터에서 observe한 RGB 이미지와 로봇의 관절 각도 및 속도로 구성됩니다.
zero-shot transfer 성능을 평가하기 위해 총 12개의 가능한 작업-로봇 조합(world) 중 11개만을 학습하고, ‘검정 블록을 향해 뻗는 4링크 로봇 팔’의 조합은 의도적으로 제외하여 unseen world로 분리했습니다. 실험 결과는 오른쪽 table1과 같은데요. 네 번의 test position으로 실험을 해봤을 때 마지막 5time step에서 얻어지는 결과의 평균 거리를 가지고 나타낸 결과라고 보시면 됩니다. unseen world의 작업-로봇 조합에서도 즉각적으로 좋은 성능을 발휘하여 제로샷 전이가 가능함을 입증했습니다. 반면, 잘못된 모듈을 조합하거나 random하게 학습된 정책을 사용하는 경우 낮은 성능을 보였습니다.
Object Manipulation
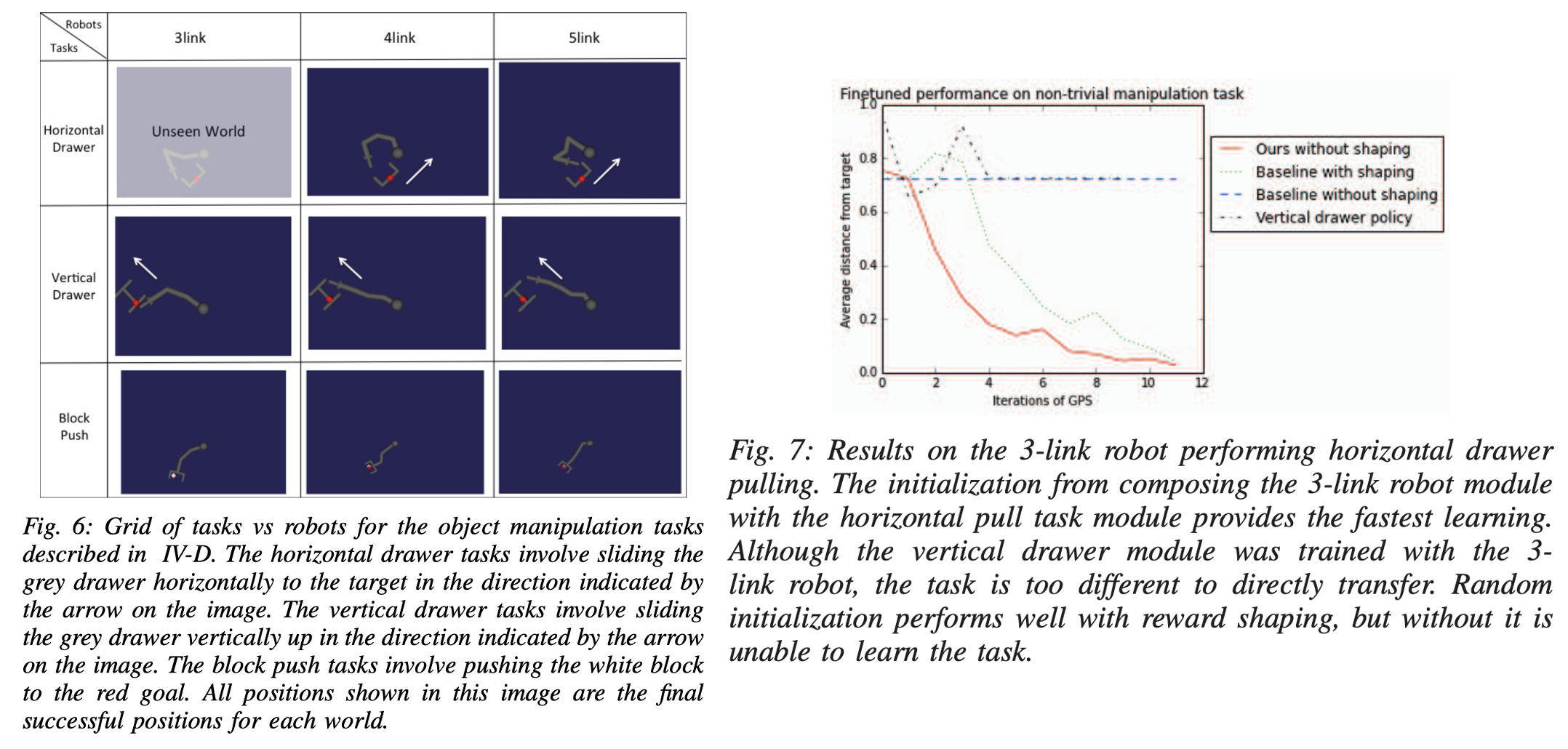
두 번째 실험은 복잡한 물리적 상호작용을 포함한 매니퓰레이션 작업에서 얼마나 효율적으로 전이를 수행하는지 평가하기 위해 설계되었습니다. 본 실험에서는 3링크, 4링크, 5링크 등 서로 다른 로봇 팔과, 수평 서랍 당기기, 수직 서랍 밀기, 블록 밀기 등 서로 다른 3가지 작업을 조합하여 총 9개의 서로 다른 world를 구성하였습니다.
각 작업은 목표 지점에 도달하기 위한 복잡한 접촉 동역학을 포함하며, 입력 데이터는 이미지 대신 목표의 좌표 정보와 로봇의 상태 정보로 구성됩니다. 이 중 ‘3링크 로봇이 수평 서랍을 당기는 작업’을 unseen world로 삼아서 전이 성능을 평가하였습니다.
실험 결과, 모듈형 정책 네트워크는 이 미지의 작업-로봇 조합에 대해 zero-shot transfer를 즉각적으로 성공하지는 못했으나, 추가 학습을 위한 좋은 초기 정책을 제공하여 학습 속도를 현저히 높였습니다. 특히 본 방법으로 초기화한 경우, random initialization로부터 shaping 보상을 활용하여 학습한 정책보다도 빠르게 수렴했으며, shaping 보상 없이 학습을 수행했을 때는 전혀 학습이 이루어지지 않았습니다. 저자들은 해당 원인이 shaping이나 좋은 initialization 없으면 random exploration 문제 땜에 챌린징했던 것이라고 하네요. 결론적으로 실험결과는 로봇의 동역학과 작업의 운동학적 특징을 효과적으로 분리하여, 이전에 경험하지 못한 새로운 작업-로봇 조합에서도 의미 있는 전이를 가능하게 함을 보일 수 있었다고 하는데, 저는 솔직히 동역학적 작업과 운동학적 특징까지 고도로 학습한 것이 맞을지…? 까지는 해당 결과만 보고는 잘 납득이 가지 않았습니다. 하지만 17년도 논문임을 감안하면,, 모듈형으로 generalization을 시도했다는 점에서 계속 강조를 했던 것 같습니다.
Visually Distinct Manipulation Tasks
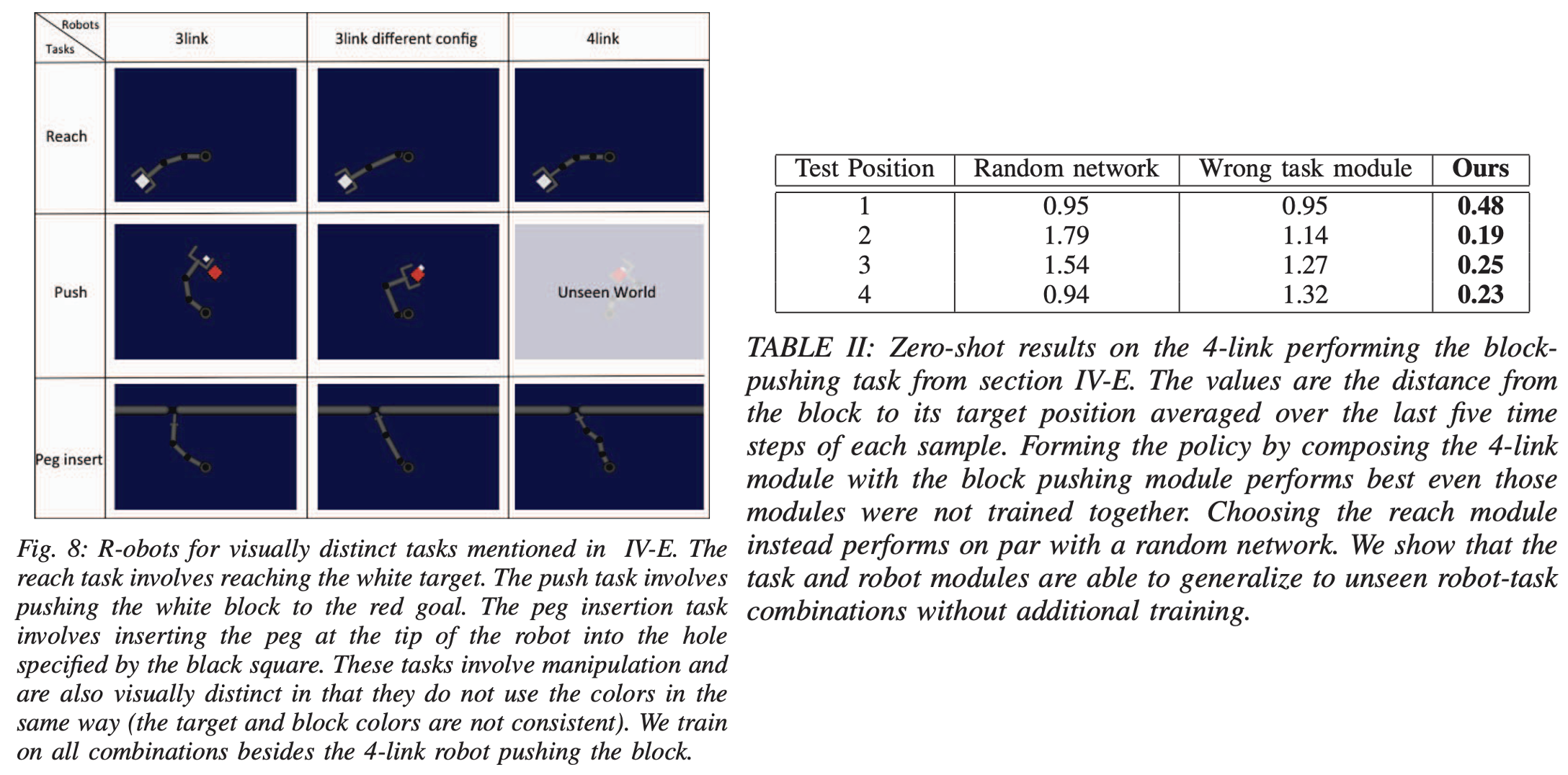
세 번째 실험은 복잡한 물리적 매니퓰레이션뿐만 아니라 시각적으로도 명확히 구분되는 작업들 사이에서 얼마나 효과적으로 전이를 수행할 수 있는지 평가하기 위해 수행되었습니다.
실험에 사용된 작업은 목표 지점으로 팔을 뻗기(reaching), 목표 위치까지 블록 밀기(pushing), 그리고 핀을 구멍에 삽입하기(peg insertion)로, 각 작업은 서로 다른 시각적 특징과 복잡한 물리적 상호작용을 요구합니다. 로봇은 두 가지의 3링크, 4링크 로봇 팔로 구성되었으며, 총 9개의 가능한 작업-로봇 조합 중에서 ‘4링크 로봇의 블록 밀기 작업’만 unseen으로 치고 전이 능력을 평가했습니다.
실험 결과, 모듈형 정책 네트워크는 추가 학습 없이도 zero-shot 전이 성능을 보여주었습니다. 특히 블록을 목표 위치까지 성공적으로 이동시키는 작업을 수행했으며, 잘못된 작업 모듈을 사용하거나 무작위 정책을 사용하는 경우에 비해 좋은 성능을 달성했습니다. 이러한 결과는 제안된 모듈형 접근법이 시각적 정보와 물리적 제어 정보를 명확히 분리하여 효과적으로 일반화하며, 이전에 경험하지 못한 새로운 시각적이고 물리적으로 복잡한 작업 환경에서도 강력한 전이 성능을 제공함을 보여주었습니다.
4. Conclusions
17년도 논문임을 감안해야 할테지만,, 미리 사전정의되어 구분된 모듈(robot, task)로 모듈형 정책 네트워크를 구성하고, 이것이 결국 unseen world에서도 generalization한 성능을 보일 수 있었다는 논문이었는데, 그것 외에는 조금 임팩트가 약한 것 같습니다. 강화학습 기법도 기존의 이전 방식들에서 사용하던 방법론인지라 새로운 방식은 없어서 좀 아쉬웠고, 그럼에도 얻어갈 만한 내용은 강화학습 신경망 네트워크도 모듈식으로 구성하면 backpropagation이 훨씬 편리하겠구나 라는 생각이 들었습니다.
좋은 리뷰 감사합니다.
강화학습 방법론들을 신경망 기반의 모듈로 구성하여 로봇에 대한 모듈과 task에 대한 모듈을 통해 다양한 작업-로봇 조합에 작동 가능하도록 학습한 것으로 이해하였습니다.
이와 관련하여 궁금한 것이 있습니다. 실험 결과에 Unseen World에 대항하는 정량적 실험 결과들만 리포팅 되어있는데, Seen World에 대한 평가는 따로 없는 지, 학습에는 하나의 에피소드만을 사용하는 지 궁금합니다.
안녕하세요 승현님, 리뷰 읽어주셔서 감사합니다.
1. 본 논문에서는 Seen World에 대한 별도의 정량적 평가는 리포팅되어 있지 않고, 모든 결과들이 Unseen World에 대한 전이 성능을 강조하고 있습니다. 저도 Unseen 말고도 Seen World에 대해 모듈형 정책 네트워크 구조가 좋은 효과를 나타낼 수 있음을 같이 보였으면 좋지 않았을까 싶으나,, 일반화가능성에 가장 무게를 두며 ICRA에 accept 되었던 것으로 보아 이 당시에는 generalization에 큰 contribution 을 주었던 것으로 보입니다.
2. 논문에서 사용된 GPS 기반 학습 방식은 하나의 에피소드로 학습이 끝나는 방식이 아니라, 일반적으로 여러 에피소드로부터 수집된 데이터를 통해 신경망 정책을 점진적으로 업데이트하여 최적화합니다.
감사합니다.
안녕하세요 이재찬 연구원님, 좋은 리뷰 감사합니다.
robot-specific module과 task-specific module의 출력을 받아 결합하는 구조에서, 해당 모듈들이 어떻게 효과적인 조합을 학습하는지가 궁금합니다. 모델의 역할분담이나 모듈 사이의 조화를 위한 추가적인 loss는 없나요?
감사합니다.
안녕하세요 성준님, 리뷰 읽어주셔서 감사합니다.
해당 네트워크 구조는 robot-specific module과 task-specific module을 별도의 독립적인 신경망으로 두고, 두 모듈의 출력을 마치 합성함수처럼 결합하여 output을 내뱉는 식으로 최종 정책을 구성합니다. 하지만 최적화는 항상 모듈 조합 후 정책 전체의 성능에 대한 단일 loss로만 이루어집니다. 즉 여기서 loss는 [latex]L = \sum_{w} L_w[/latex] 였습니다.
모듈이 결합된 전체 정책에서의 최종 action output은 로봇의 어떤 예측된 제어값이고 이에 대한 supervision으로 GPS 기법의 local trajectory optimization를 통해 생성된 최적 제어 값을 supervised signal로 삼은 뒤 이 둘 간의 Euclidean distance가 최종 Loss인 것이고 이를 최소화하는 방향으로 학습되는 것입니다.
전역적으로 End-to-End 처럼 학습이 되기에, 모듈 간의 조화는 최적의 행동 출력을 얻기 위한 표현을 자동으로 학습하게 되는 것으로 생각이 듭니다.
감사합니다.