안녕하세요, 쉰 일곱번째 X-Review입니다. 이번 논문은 2023년도 ICCV에 올라온 CLIPTER: Looking at the Bigger Picture in Scene Text Recognition논문입니다. 바로 시작하도록 하겠습니다. ?
1. Introduction
본 논문은 Scene Text Recognition(이하 STR) 논문으로써, scene 이미지 내에 존재하는 text를 읽어내는 task라고 보시면 됩니다. 논문에저 저자가 언급하는 기존 STR 문제점은 crop된 text 이미지만을 입력으로 받아 인식을 수행한다는 점입니다. 풀어말하자면 기존 STR 모델들은 Text가 이미지 전체에 꽉 차게 그려진 그런 영상만을 입력 받도록 설계되었다는 점이죠. 그렇기 때문에 그 text가 실제로 어떤 scene에서 등장한 Text인지, 혹은 그 text 주위에 무엇이 있는지 등등 scene-level의 정보를 전혀 활용하지 못한다는 한계점이 있습니다.
하지만, 실제로 우리가 좀 흐릿하거나 일부가 가려진 text를 읽을 때면 그 배경이나 주위 맥락 정보를 참고하는 것처럼 STR 모델들도 전체 scene을 볼 수 있다면 더 정확한 인식을 수행할수 있어 보입니다. 본 논문에서 제안된 CLIPTER는 이런 아이디어에 착안하여 제안된 모델입니다.
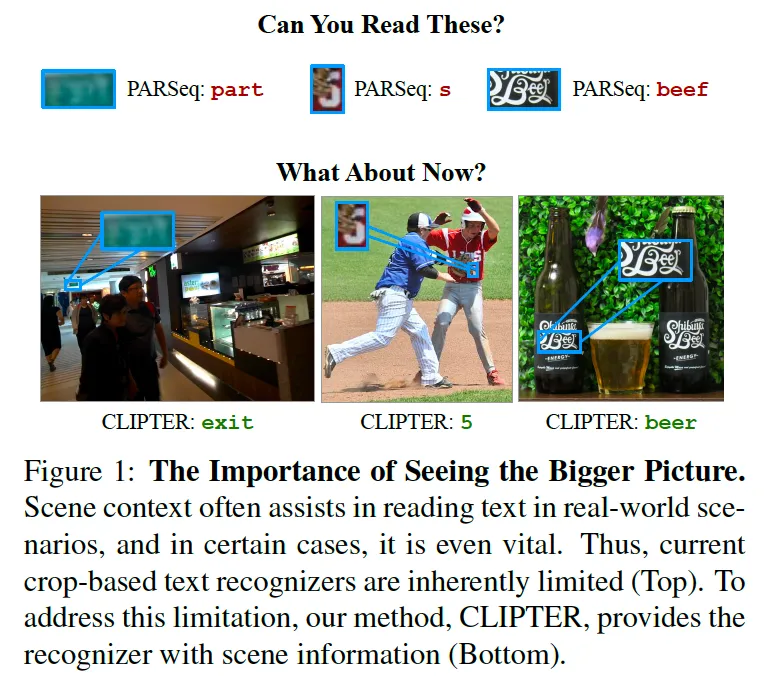
위 Fig1에 이에 대한 그림이 그려져 있는데요. 보시면 상단 부분은 ‘Can You Read These?’라고 하면서 블러처리됐거나 폰트가 독특하여 읽기 어려운 그림과 함께 기존 모델(PARSeq) output이 적혀져 있습니다. 실제 사람이어도 읽기 힘들어보이는 예시들로 보이죠.
반면, ‘What About Now?’라고 적혀있는 하단 부분에는 CLIPTER가 scene-level의 정보를 활용해 더 정확히 텍스트를 인식하는 모습을 보입니다. 즉, 주변 사물이나 색상, 맥락 정보를 활용해 영상을 이해하고 최종적으로 text를 prediction할 수 있는 것입니다. 예를 들어 맥주병 정보를 통해 beef가 아닌 beer라고 인식할 수 있는 것입니다.
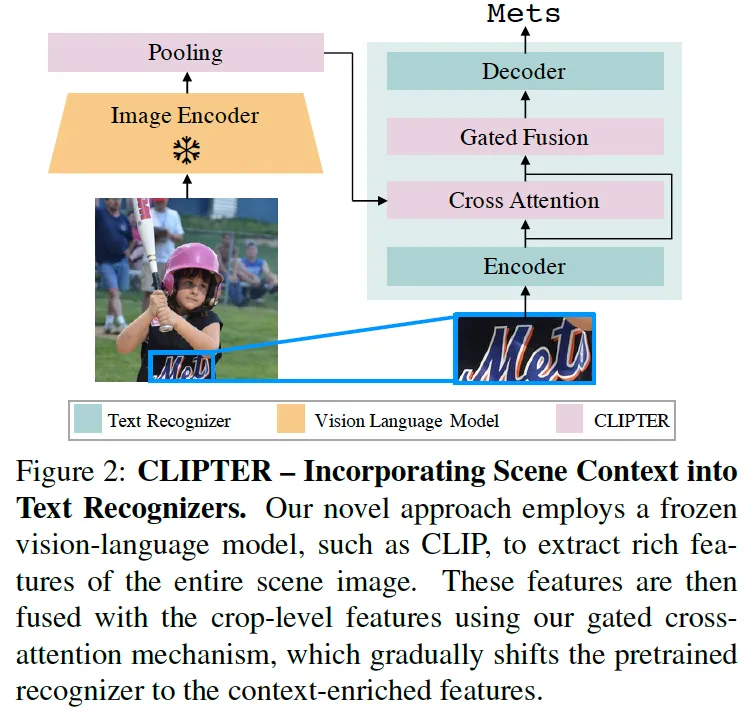
위는 CLIPTER가 전체적인 구조가 도식화되어 있는 그림입니다. 간략하게 설명드리면 Vision language model(CLIP 등)을 활용해 전체 scene image에서 representation을 뽑아내고 있구요. 또 우측에 기존 recognition model이 crop된 text 영상을 받아 뽑아낸 crop-level feature와 gated cross-attention 방식을 통해 두 feature를 합치게 됩니다. 단순하긴 한데, 이 구조는 기존 recognizer를 그대로 변형하지 않고 사용하면서 scene 정보를 가지고 보완하는데 사용할 수 있도록 설계된 것입니다.
정리하자면 저자가 제안한 이 CLIPTER 프레임워크는 특정 recognizer에 속하지 않는 범용적인 구조 즉 쉽게 plug할 수 있는 방식으로 설계가 되었다고 볼 수 있겠습니다. 이를 위해 저자는 다양한 encoder와 다양한 fusion 방식, 다양한 integration point(어디에서 합칠것인지)를 조합할 수 있도록 함으로써 상황에 따라 모델의 성능과 효율성을 조절할 수 있도록 하였습니다. 보다 구체적인 내용은 아래 method단에서 설명드리도록 하겠습니다.
2. Methodology
3.1. Building Blocks
이 섹션에서는 CLIPTER의 전체 architecture의 구성 요소들을 하나씩 설명드리도록 하겠습니다. 총 4가지 구성인데 각각은 scene-level 정보를 효과적으로 사용하기 위해서 또, 기존 recognizer에 쉽게 통합될 수 있도록 구상되었습니다. 이 넷은 Image Encoder, Image Feature pooling, Integration Point, Fusion mechanism입니다. 각각에 대해 살펴보도록 하겠습니다.
Image Encoder
Image Encoder는 전체 scene 이미지를 입력으로 받아 scene-level의 representation을 뽑게 되며, 이를 통해 recognizer의 word-level 정보에 context 정보를 제공합니다. 여기서 사용된 인코더는 크게 두 가지 계열로 나뉩니다. 첫 번째는 ViT, MAE, DINO같은 vision only 기반 모델이구요. 다른 하나는 CLIP, BLIP 등과 같은 vision language 기반의 모델입니다.
VLM은 image와 text pair로 학습되다 보니 단순 visual feature 뿐 아니라 semantic한 정보까지 담고 있다는 장점을 갖고 있죠. 실험적으로도 VLM을 적용한 경우가 더 좋은 성능을 보였다고 합니다. 본 논문에서는 transformer 기반의 encoder를 사용하였으며 학습 중에는 frozed된 다음 추가적인 파라미터 튜닝 없이 generalization 성능을 유지할 수 있도록 하였습니다.
Image Feature Pooling
다음은 image feature pooling입니다. Image encoder로부터 생성한 feature의 크기가 크다면 이후에 word-level feature(기존 recognizer가 cropped text image를 입력으로 받아 추출한 feature) 와 합치는 과정에서 계산량이 커지게 됩니다. 두 feature를 가지고 cross-attention 연산을 할 때 계산 복잡도는 다음과 같이 정의가 됩니다.
O(N_{global} \cdot N_{local} \cdot d)여기서 N_{global}은 image-level representation의 길이, N_{local}은 word-level representation의 길이, d는 feature의 차원을 나타냅니다.
무튼, 커지는 계산량을 줄이기 위해 pooling layer를 도입하였습니다. 구체적으로 말하자면 전체 scene level image에서 뽑은 global feature에서 [class] token에 해당하는 representation은 그대로 냅두고 나머지 patch-level feature에 대해 2D avg pooling을 적용하는 것입니다. 이 과정을 거친 feature는 다음과 같습니다.
F_{global} \in \mathbb{R}^{(1 + HW / k^2) \times d}여기서 k는 pooling kernel의 크기를 의미합니다. 논문에서는 이 K값을 다양하게 해보면서 성능 속도 간의 trade-off를 실험했으며 엄청 극단적으로 k가 무한대로 [class] token만 사용하는 경우에도 일정 수준 이상의 성능 향상이 가능하다는 점을 보였습니다.
Integration Point
다음은 integration point에 대한 부분입니다. 이 integration point는 image-level feature를 recognizer의 어느 부분에서 합칠 적인지에 대한 것입니다. 본 논문에서는 다양한 recognizer를 가지고 여러 위치에서 integration을 해보았는데, 일반적으로 이 integration point는 두 가지 방식으로 구분할 수 있다고 합니다.
첫 번째는 Early fusion으로, recognizer의 feature extractor 안에서 integration을 하는 것입니다. 두번째는 late fusion으로 decoder 단에서 image-level의 feature를 활용하는 것입니다. autoregressive decoder같은 경우에는 매 decoding step 마다 cross-attention을 수행해야 하기때문에 속도가 좀 느려질 수 있겠죠.
이런 fusion 방식은 기존에도 많이 활용되긴 하지만 본 CLIPTER는 이를 local(crop-level)과 global(scene-level) 정보를 결합하여 STR task에서 처음으로 적용한 것을 어필하고 있는 듯 합니다.
Fusion Mechanism
다음은 어떻게 image-level feature F_{global}과 word-level feature F_{text}을 fusion할지에 대한 방법 소개입니다.
먼저 fusion하기 전 global feature를 word-level feature와 동일 차원으로 projection시킨 다음 두 방식 중 하나를 선택해 fusion하게 됩니다. 첫 번째 fusion 방식은 Multi Head Cross Attention으로, 이는 가장 일반적인 fusion 방식이라고 볼 수 있습니다. 본 논문에서는 word-level feature를 query로 두고 image-level feature를 key value로 사용하여 MHCA를 수행하도록 하였습니다.
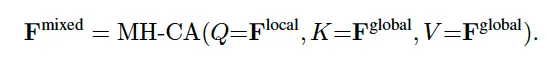
다음 방식은 gated attention 방식인데 이건 보다 경량화된 대안책으로 볼 수 있습니다. attention처럼 복잡한 연산을 안 쓰고, 간단한 gating 방식으로 두 feature를 합치는 방식이죠. 이건 앞서 pooling 과정에서 k를 극단적으로 무한대로 두어 하나의 global representation만 남겨둔 경우에만 적용가능 합니다. ([class] token 하나만 남은 경우)
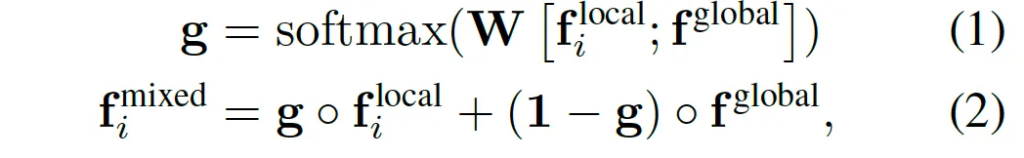
위 식에 그 과정이 나와있는데, \circ는 element-wise 곱을 의미합니다. 수식을 봐보자면 먼저 word-level과 image-level feature를 concat하구 있구요 그 다음 softmax를 적용해 gate vector를 뽑아 내는데 이 gate는 결국 각 dimension마다 얼마나 local 정보를 사용할지 얼마나 global 정보를 사용할지 결정하는 역할이라고 볼 수 있습니다. (식2 참고)
또, 기존 recognizer에 갑자기 global feature를 섞기 시작하면서 생길 수 있는 성능하락을 방지하고자 학습 초기에는 recognizer가 원래의 word-level feature만을 사용하도록 하고 학습이 진행될수록 점점 fusion한 feature를 반영하도록 하였습니다.
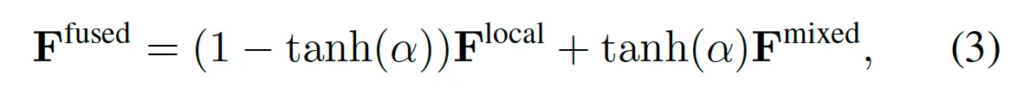
위 식에 그 내용이 나와있는데 그냥 tanh-gating으로 보면 되겠습니다.
3.2. Training Protocol
본 섹션에서는 CLIPTER를 다양한 recognizer에 효율적으로 적용하기 위한 학습 프로토콜을 설명드리도록 하겠습니다.
우선적으로 CLIPTER는 pre-trained된 base recognizer를 그대로 가져와 초기화합니다. 이후 fine-tuning할 때는 recognizer 자체와 fusion 모듈만 학습하고 image encoder(global feature 뽑는)은 frozed하도록 하였습니다. 이 방식은 recognizer가 사전에 합성 데이터로 학습한 파라미터를 그대로 사용할 수 있다는 장점을 갖죠 .
또, image encoder가 frozed되기 때문에 학습 효율성을 높이기 위해 image-level feature를 학습 전에 미리 다 뽑아놓은 다음 그 뽑아놓은 feature를 추후 학습에 사용하도록 하였습니다. 이로써 첫 epoch에 feature를 cache해두면 이후에는 더 빠르게 학습시킬 수 있겠죠. 이런 최적화로 인해 전체 학습 iteration 당 기존 recognizer에 비한 시간 증가량은 10%도 안된다고 합니다.
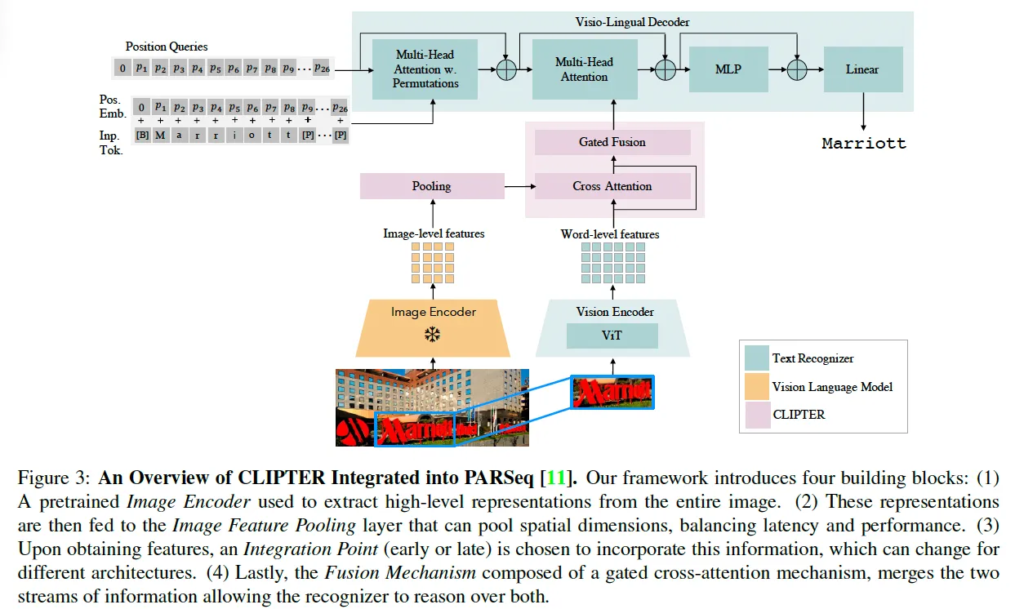
마지막으로 Fig3을 통해 정리하고 method 마무리하도록 하겠습니다. 위 그림은 PARSeq이라고 하는 recognizer를 base로 삼고 CLIPTER를 적용한 그림을 보여줍니다. 먼저 cropped image는 기존 recognizer와 동일하게 Vision Encoder를 통해 word-level feature를 추출해내게 되구요 동시에 scene 전체 영상은 pre-trained된 Vision language model에 들어가 scene-level representation을 추출해내게 됩니다.
이렇게 추출한 image-level feature는 pooling layer를 거치게 되는데 이 pooling layer는 [class] token은 그대로 유지하고 나머지 patch-level representation에 대해서 2D avg pooling을 적용했었죠. 이렇게 연산량을 줄인 후 global feature와 word-level feature는 fusion 방식을 통해 합쳐지게 됩니다. 이떄 fusion은 cross attetion 혹은 gated fusion 중 하나를 택하게 됩니다. 최종적으로 fusion된 feature가 PARSeq의 decoder로 들어가 decoding을 통해 순차적으로 text를 prediction하게 됩니다. 그림에서는 예시로 ‘Marriott’이라는 단어가 디코딩되고 있죠.
이 CLIPTER 아키텍처는 전체 영상으로부터 얻은 scene-level 정보와 croppted text로부터 얻은 word-level 정보를 효과적으로 융합함으로써 효과적으로 recognition을 수행할 수 있게 합니다.
3. Experiments
3.1. Improving State-of-the-Art Recognizers
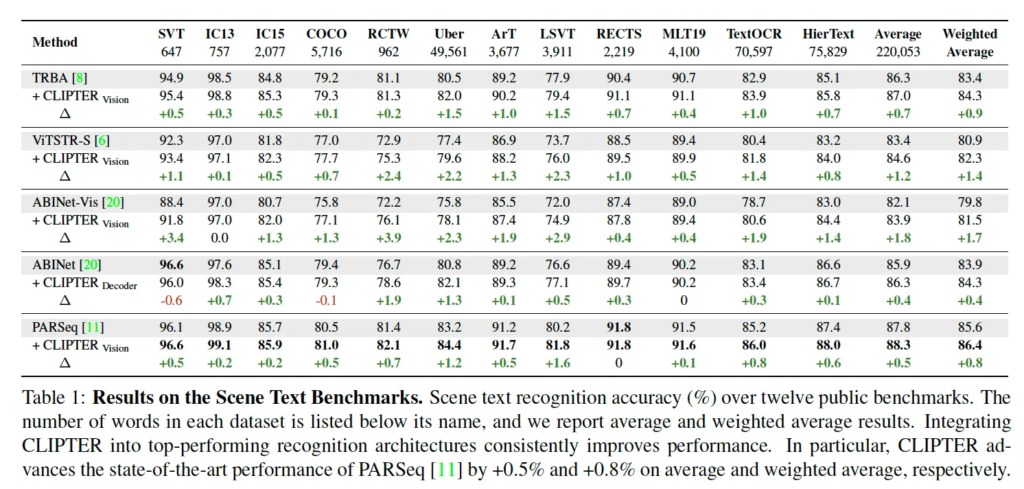
마지막으로 실험 살펴보도록 하겠습니다. 위 table에서는 cnn 기반의 recognizer와 transformer 기반, autoregressive decoder와 parallel decoder 까지 서로 아키텍처가 다른 다섯 base recognizer(TRBA, ViT-STR, ABINet, ABINet-VIS, PARSeq)에 CLIPTER를 적용했을 때 일관되게 성능이 향상된 결과를 보여주고 있습니다.
이 12개의 벤치마크 중에서도 CLIPTER를 적용했을 떄 그 효과가 잘 보이는 경우는 street-view dataset 계열인데요. 예를 들어 Uber, SVT, LSVT 등의 데이터셋에서는 PARSeq의 경우에서 error가 10%가까이 감소했다고 합니다. 이 데이터셋들은 대부분 거리의 이름이나, 간판, 로고 등 현실 세계에서 흔히 볼 수 있는 복잡하고 왜곡된 텍스트를 포함하고 있어서 scene context가 특히 더 효과를 보인 것으로 해석해 볼 수 있죠.
또, CLIPTER는 text가 엄청 빽빽하게 포함된 영상에서도 좋은 성능을 보였는데, 예를 들어 TextOCR이나 HierText와 같이 한 영상당 텍스트 개수가 30개 ~ 100개 정도 되는 데이터셋에서도 기존 recognizer 대비 향상된 결과를 보입니다ㅏ. 이는 단순 하나의 단어나 문장만을 보는 것이 아니라 scene 전체를 통해 보다 의미론적인 reasoning을 할 수 있음을 시사하고 있죠.

위 Fig4는 base 모델 PARSeq의 정성적 결과와 여기에 대해 CLIPTER를 적용했을 때의 결과를 비교하고 있습니다. 우측에는 CLIPTER만 틀렸을 경우와 두 모델 다 틀렸을 경우도 함께 리포팅되고 있습니다.
3.2. Performance on Out-Of-Vocabulary
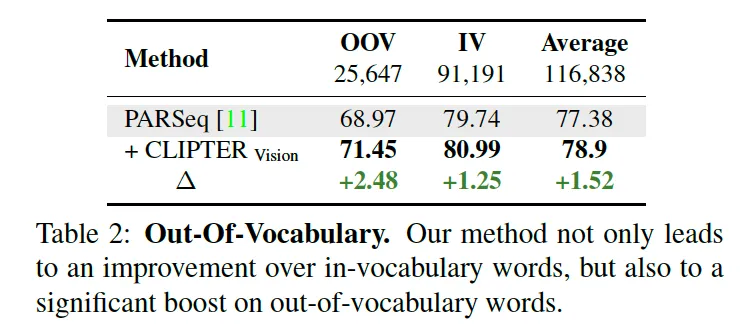
마지막으로 CLIPTER가 학습 데이터셋에 존재하지 않는 단어 다시 말해 out-of-vocabulary text에 대해 얼마나 robust하게 동작한지를 평가하는 부분입니다. 이 실험은 앞선 street-view 데이터셋에서 확인되었던 성능 향상이 context 정보에 기반한 generalization 능력과 관련 있을 것이라는 가설에서 수행한 것입니다.
이 OOV 단어들은 실제 scene understanding에 있어서도 중요한 정보를 포함하고 있습니다. 예를 들어 가격이나, 이름, 날짜, 전화번호, 이메일 주소 등등 학습 데이터셋에는 포함되어 있지는 않지만 실제 application 측면에서는 중요한 text들이죠. 그런데 기존 STR 모델들은 저화질이거나 왜곡된 text일 경우 학습 데이터셋에 자주 등장하는 단어로 prediction해버리는 경향이 강했습니다.
Table2를 보면 PARSeq recognizer에 CLIPTER를 적용한 경우 IV에 대해서는 1.25 정도의 성능향상이 있었지만 OOV 단어에 대해서는 2.48% 향상이라는 더 향상된 결과를 보입니다.
이런 결과를 보아 pre-trained된 vlm이 단어를 직접적으로 학습하지 않았더라도 주변의 visual 정보와 문맥 정보를 통해 text를 recognition하는데 도움이 될 수 있다고 결론내려볼 수 있겠습니다. CLIPTER가 OOV에도 robust하게 동작하는 것은, 단순 recognition 정확도를 높이는 것 이상으로 scene level의 reasoning을 가능하게 한다는 점에서 의의를 갖는 것 같습니다.
안녕하세요 리뷰 잘봤습니다. 읽다 궁금한게 생겨 댓글 남깁니다
recognizer마다 integration point를 다르게 적용해봤다고 하셨는데, 결론적으로 어떤걸 사용했고, 어떤 구조에서 early fusion이 더 잘 먹히고, 어떤 경우에는 late fusion이 더 좋은지에 대한 분석이 있었을까요?
댓글 감사합니다.
넵 본 실험에서 기존 여러 recognizer를 base model로 두고 각각의 recognizer 구조에 따라 어떤 fusion 방식이 적합한지에 대한 분석이 있습니다. 표1에 명시되어 있는 모델들에 대한 실험인데, ABINet과 같은 모델은 parallel decoder를 사용하는 모델로써 late fusion(decoder 단에서의 fusion)이 더 높은 성능 향상을 보였고, ABINet-Vis 처럼 앞단 처리가 좀 복잡한 모델은 early fusion이 더 효과적이었다고 합니다.
또, 본문 중간에 언급한 것처럼 PARSeq나 TRBA와 같은 autoregressive decoder 구조에서는 inference 시간 증가를 감안하면 early fusion을 선택하는 것이 효율성 측면에서 낫습니다.
안녕하세요. 좋은 리뷰 감사합니다.
decoder에 입력으로 들어오는 position queries들과 Inp. Tok.같은 것은 어디서 생성되어 들어오는 것인가요? 또 Gated Fusion 방식이 multi-head cross attention보다 경량화된 대안책이라고 볼 수 있다고 했는데, 이건 autoregressive decoder인 경우에만 적용하는 것인가요?
감사합니다.
댓글 감사합니다.
아키텍처 그림을 보시고 질문 주신 것 같은데 deocder에 들어가는 position query와 input token들은 일반적인 transformer 기반의 autoregressive recognizer 구조를 따르는데,
position query는 CLIPTER 내의 learnable positional embeddings이구요. Input token은 decoder 입력으로 들어가는 이전 단계에서 예측한 문자들이라고 보면 되겠습니다.
또, gated fusion 방식은 꼭 autoregressive decoder에만 적용하는 건 아니고 decoder 구조에 관계 없이 적용 가능한 그냥 lightweight한 fusion 방식이라고 보면 됩니다.
안녕하세요 정윤서 연구원님 리뷰 잘 읽었습니다.
궁금한 게 한가지 있어서 댓글 남기고 갑니다!
scene image를 인코딩 과정에 VLM을 사용할 경우 정답이 되는 텍스트를 함께 전달해주는 건가요? VLM에 text input으로 어떤 게 전달되는지가 궁금합니다.
감사합니다
댓글 감사합니다.
본 모델 구조를 보면 아시겠지만 text encoder는 사용하고 있지 않습니다. VLM의 encoder iamge 부분만 가져와 scene image를 embedding한 것을 Fig3에서 확인해보면 될 것 같습니다.