안녕하세요, 허재연입니다. 이번 리뷰에서는 다룰 논문은 OpenSeeD라는, Open Vocabulary Segmentation과 Detection를 둘 다 수행할 수 있는 프레임워크를 제안한 논문입니다. 리뷰 시작하도록 하겠습니다.
Introduction
대표적인 대규모 사전학습 VLM으로 강력한 zero-shot transfer 능력을 보여준 CLIP의 등장 이후로, 많은 연구자들이 대규모 image-text pair로 학습한 지식을 활용해 open-vocabulary segmentation / detection을 수행하고자 시도하였습니다. 이 때, 저자들은 핵심 vision task인 detection 및 segmentation은 vacabulary의 크기나 지도학습 시 공간적 세분화 수준 측면에서 상당한 차이를 보인다고 지적하였습니다(Figure 2참고). 예를 들어, 일반적으로 사용되는 공개 detection 데이터셋인 Object365에는 약 170만 장의 이미지에 365개 concept에 대한 box annotation이 있지만, 이에 비해 COCO의 mask annotation에는 단 10만장의 이미지에 133개 카테고리에 대한 label밖에 없다고 합니다.
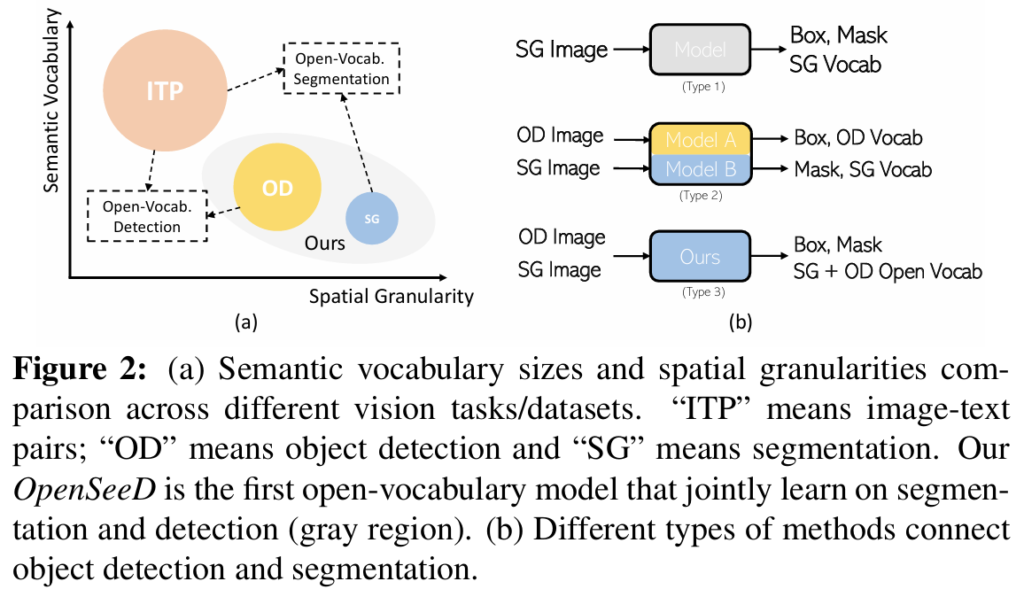
기존 연구들은 멀티모달 파운데이션 모델로부터 vision-sementic representation을 distilling하거나, 새로운 contrastive learning법을 고안하거나, pseudo label을 활용하는 등의 방법을 활용해 open-vocabulary detection / segmentation을 수행했습니다. 하지만 이러한 기존 연구들은 detection 혹은 segmentation 하나의 task에 대한 성능을 올리는데 집중하였고, 이미지 인스턴스 단위로 학습된 지식을 fine-grained task로 전이하는 데 세분화(granularity) 수준 차이를 완화하기 위해 정교한 프레임워크 구조 설계를 할 필요가 있었습니다. 저자들은 여기서 다음과 같은 질문을 던집니다 : “보다 깔끔하고(노이즈가 적고), 상대적으로 세분화 수준 차이가 적은 detection과 segmentation을 연결해서 두 task 모두 잘 수행할 수 있는 open-vocabulary model을 구축할 수는 없을까?”. 결국, open-vocabulary setting에서 detection 및 segmentation을 잘 수행하는 모델을 구축하고자 합니다.
detection 과 segmentation을 결합하려는 시도는 이전부터 있었습니다. 대표적으로 잘 알려진 게 Mask R-CNN이죠. Mask R-CNN은 COCO 데이터셋을 활용해 detection과 instance segmentation을 공동으로 학습한 초기 연구입니다. 이외에도 Mask DINO를 제안한 논문이 Object365에서 사전학습한 모델이 COCO panoptic segmentation task에 효과적으로 전이될 수 있음을 보인 연구라고 합니다. 하지만 위의 Figure 2(b)에서 볼 수 있듯 Mask R-CNN 방법의 경우 bounding box와 mask에 대한 라벨이 모두 있는 동일한 데이터셋에서 모델을 훈련해야 한다는 제약이 있고, Mask DINO와 같은 방법은 사전학습 이후 미세 조정을 하는 방식으로 진행되어 결과적으로는 두개의 서로 다른 closed-set 모델이 만들어진다고 합니다. open-set 세팅에 바로 적용시키기에는 적절하지 않죠.
본 논문에서는 detection 및 segmentation data를 함께 사용해 학습하면서, detection 및 segmentation 모두를 수행할 수 있는 open-vocabulary model을 최초로 제안합니다. 사실 저는 두 task를 따로따로 잘 수행하는 모델 두 개를 사용하면 되지 않나.. 라는 생각이 들기는 하지만, 기존부터 꾸준이 있었던 연구 흐름이기에 학습 방법을 잘 공부해놓으면 나중에 아이디어를 활용할 일이 있지 않을까 싶네요. open-vocabulary 세팅에서 detection과 segmentation을 모두 수행하려면, 다음 요소들을 잘 해결해야 합니다.
1. detection과 segmentation 데이터 간 의미론적 지식(semantic knowledge)를 어떻게 전이할 것인가?
2. 학습 과정에서 box 및 mask supervision 간의 간극을 어떻게 메울 것인가?
두 task 간 vocabulary에는 상당한 차이점이 있기에 두 vocabulary 범주를 모두 포함하며 더 나아가 open-vacabualry로 확장할 필요가 있습니다. 또한, sementic segmentation과 panoptic segmentation의 경우 전경 객체뿐만 아니라 하늘 / 건물 / 도로 같은 배경 객체를 모두 다뤄야 하는 반면 detection의 경우 오직 전경 객체만을 다루기에 task 간 gap이 있습니다. 여기에 추가적으로 box 기반 학습은 본질적으로 mask 기반 학습과 그 정보 밀도가 다르며, mask 정보를 box로 변환하는것은 쉽지만 box 정보를 mask로 변환하는건 거의 불가능합니다. detection과 segmentation이 언뜻 보면 유사한 task인 것 같지만, 이러한 차이들로 인해 통합 모델을 구축하는데 어려움이 있습니다.
이에 저자들은 OpenSeeD라는 인코더-디코더 프레임워크를 제안하여 위의 문제점들을 완화해 detection 및 segmentation 작업의 통합을 시도합니다. 보다 구체적으로 살펴보면, 첫 번째로 single text encoder로 데이터 안에서 등장하는 모든 개념들을 인코딩하고 , 시각 토큰(visual token)과 의미 정보(semantics)를 공동 표현 공간에서 정렬하도록 학습을 진행합니다. 두 번째로, 디코더 내 object query들을 전경 쿼리(foreground query) 및 배경 쿼리(background query)로 구분하여 사용합니다. 전경 쿼리는 segmentation 및 detection에서 모두 전경 객체를 담당하고, 배경 쿼리는 segmentation에서만 등장하는 배경(background, stuff) 개념을 처리합니다. 세 번째로 conditioned mask decoding 기법을 도입하여 segmentation 데이터의 GT box로부터 마스크를 디코딩하는법을 학습하고, 이를 바탕으로 detection 데이터에 대한 보조 마스크(mask assistant)를 생성하도록 합니다.
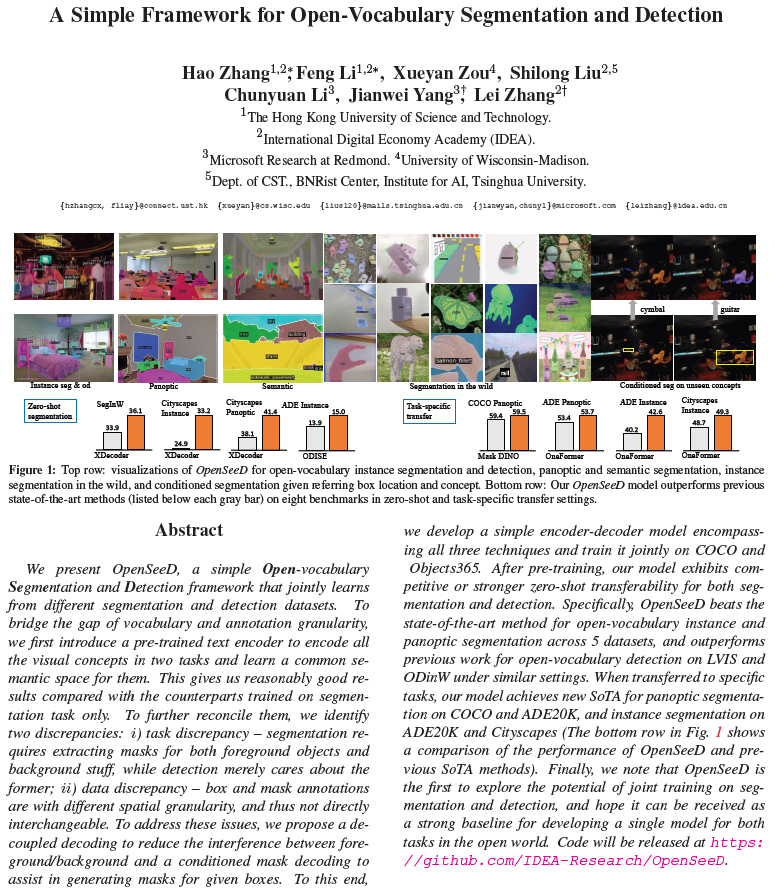
이런 방법을 통해 OpenSeeD는 detection 데이터와 segmentation 데이터를 별도로 학습하면서도 이를 효율적으로 통합할 수 있게 하였으며, 다양한 task 및 데이터셋에 대해 경쟁력 있는 zero-shot 및 전이학습 성능을 보여주었습니다. Figure 1에는 instance / panoptic / semantic segmentation 및 detection에서 OpenSeeD 적용 결과를 시각화한 결과 및 conditioned segmentation 능력을 나타내었습니다.
저자들의 주장하는 contribution을 요약하면 다음과 같습니다 :
- 우리들은 detection 및 segmentation 데이터를 공동으로 학습하여 두 task 모두에 open-vocabulary로 동작하는 강력한 베이스라인 모델을 최초로 제안한다.
- 두 task 및 데이터셋 간 차이점(discrepancies)를 분석하고, 이를 완화하기 위해 shared semantic space, decoupled decoding, conditioned mask assistance등의 기법을 제안한다.
- detection 및 segmentation 데이터를 모델에 공동으로 학습시켜, 다양한 segmentation 데이터셋에서 zero-shot task transfer에 대해 새로운 SOTA를 달성하고, zero-shot object detection 성능에서도 경쟁력 있는 결과를 보여준다.
Method
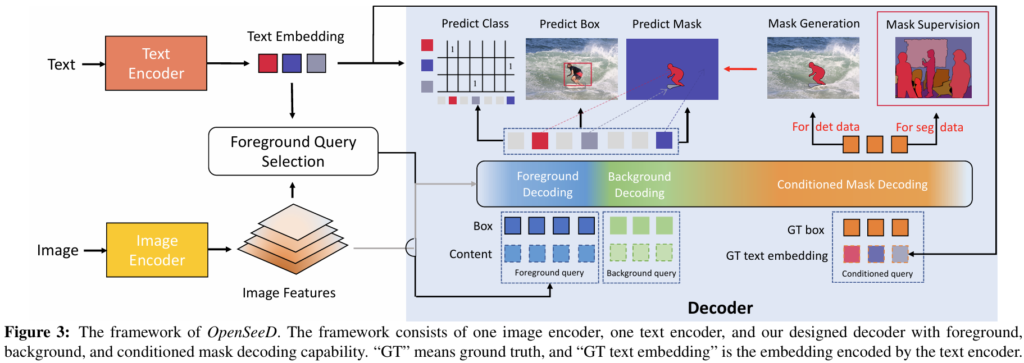
저자들이 제안하는 OpenSeeD의 프레임워크는 Figure 3과 같습니다. open-vocabulary setting에서 detection과 segmentation을 모두 수행하기 위해, 일반적인 인코더-디코더 구조를 설계하고 OpenSeeD모델에 텍스트 인코더를 도입하였습니다. 보다 세부적으로는 하나의 이미지 인코더, 하나의 텍스트 인코더, 하나의 디코더로 구성됩니다. 모델은 입력으로 이미지 I와 vocabulary V를 입력받아 예측 결과를 출력합니다. 예측 결과로는 마스크 {P}^{m}, 바운딩박스 {P}^{b}, 분류 점수 {P}^{c}를 출력합니다. 입출력을 전체적으로 표현하면 ⟨{P}^{m}, {P}^{b}, {P}^{c}⟩ = OpenSeeD(I, V)로 표현할 수 있습니다. 주어진 이미지 I와 vocabulary V에 대해, 우선 이미지 인코더와 텍스트 인코더를 활용해 image feature O(HxWxC)와 text feature T(t1, t2, .. t_K)를 추출합니다.
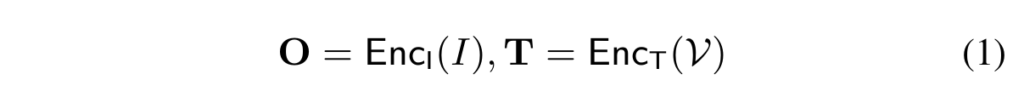
그 이후, 디코더는 L개의 쿼리 Q를 입력으로 받아 image feature와 cross-attention을 수행해 출력 결과를 생성합니다.
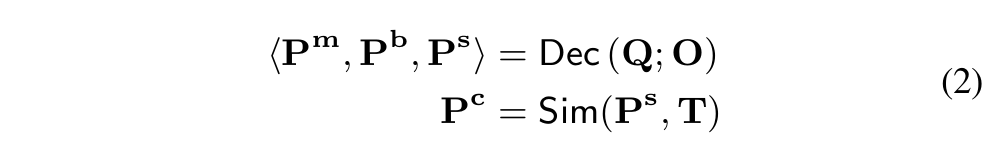
여기서 {P}^{s}는 디코딩된 의미 표현(semantics)입니다. visual-semantic matching score {P}^{c}는 {P}_{s}와 T간의 유사도 점수를 계산한 Sim({P}){s},T) 로부터 얻으며, 이 점수는 학습 중에는 loss function을 계산하는데 사용되고, 추론 시에는 카테고리 예측에 사용될 수 있습니다.
Basic Loss Formulation
기본적인 구조에서, 저자들은 다른 이슈들을 건드리지 않고 shared visual-semantic space를 조정하여 두 task를 조합하고자 하였습니다. 여러 task 및 dataset에 대해, 기본적인 손실 함수는 다음과 같이 활용할 수 있습니다(각 loss term에 대한 가중치는 생략되었습니다.) :

segmentation의 경우, mask m으로부터 정확한 box b를 만들어 이를 이용해 박스 손실함수를 계산할 수 있습니다. 이 항들을 모두 더해 학습에 사용함으로, 우수한 open-vocabulary 성능을 달성할 수 있었다고 합니다.
이 loss를 활용한 학습을 통해 좋은 성능을 달성할 수는 있지만, detection 및 segmentation 모두를 수행하는 좋은 모델을 만들기 위해서는 두 task 간 본질적인 차이를 고려해야 합니다. 앞에서 말했던 것처럼, semantic, panoptic segmentation은 전경과 배경 모두를 인식해야 하지만, object detection은 전경 객체를 찾는 것에만 집중합니다. 저자들은 이에 두 task에 동일한 query를 사용하는 것은 서로 충돌을 일으며 성능을 크게 저하시킬 수 있다고 합니다. 또한, bounding box 예측을 잘 할 수 있으면 일반적으로 mask 예측도 잘 할 수 있으며, 반대 또한 마찬가지라고 합니다(dense prediction task를 어느정도 잘 할 수 있으면 다른 dense prediction task에 잘 transfer 되나 보네요). 이런 맥락에서 저자들은 detection 및 segmentation 데이터를 활용해 box head와 mask head를 별도로 학습시키면 두 데이터셋으로부터 얻을 수 있는 공간적 정보 시너지를 활용할 수 없다고 분석하였습니다.
이런 문제들을 해결하기 위해, 저자들은 OpenSeeD에 쿼리를 3가지 유형으로 나누는 새로운 디코더 설계를 도입하였습니다. 각각 전경 쿼리 {Q}_{f}, 배경 쿼리{Q}_{b}, 조건부 쿼리(conditioned query) {Q}_{d}로, 각 유형에 대한 쿼리별 연산 방식을 제안합니다.
아래에서 보다 자세하게, task 간 불일치를 해소하기 위해 전경 및 배경 디코딩을 어떻게 분리하였는지 및 데이터 간 불일치를 해결하기 위해 mask decoding을 어떻게 활용하였는지 설명하겠습니다.
Bridge Task Gap: Decoupled Foreground and Background Decoding
저자들은 일반성을 해치지 않는 선에서 instance segmentation 및 object detection에 등작하는 시각 개념(visual concepts)들을 전경(foreground)로 정의하고, panoptic segmentation에서의 stuff 범주들을 배경(background)로 처리하였습니다. task 간 불일치를 완화하기 위해 {Q}_{f}와 배경 쿼리 {Q}_{b}를 사용해 각각 전경과 배경 디코딩을 수행하게 됩니다. 보다 구체적으로, 이 두 쿼리 유형애 대해 디코더는 전경을 위한 출력 <{P}^{m}_{f}, {P}^{b}_{f}, {P}^{c}_{f}>과 배경을 위한 출력 <{P}^{m}_{b}, {P}^{b}_{b}, {P}^{c}_{b}>의 두 가지 출력 집합을 예측합니다. 또한, segmentation 데이터셋의 GT를 두 그룹 ({c}_{f}, {m}_{f}) 와 ({c}_{b}, {m}_{b})로 나누고, 그림 4(a)에서 확인할 수 있듯 각 그룹에 대해 독립적인 hungarian matching을 수행합니다. 결괒거으로 전경 , 배경 디코딩 모두 segmentation 에 사용되며, detection에는 전경 디코딩만 사용됩니다.

결과적으로, 앞에서 봤던 수식 (3)의 loss를 다시 다음과 같이 수정하게 됩니다 :

\hat{b}_{f}, \hat{b}_{b}는 각각 {m}_{f}, {m}_{b}로부터 도출됩니다(mask에서 box를 만드는건 어렵지 않죠). 이런 명시적인 분리(decoupling)를 통해 모델이 detection, segmentation 데이터셋으로부터 얻은 전경 정보에 대한 학습 지식의 시너지를 극대화하고, 전경 및 배경 범주 간 간섭을 효과적으로 줄일 수 있었다고 합니다. 비록 디커플링되어있긴 하지만 그림 4(b)에서 확인할 수 있듯 이 두 종류의 쿼리는 동일한 디코더를 공유해 self-attention을 통해 상호작용하게 됩니다. 전경 쿼리 및 배경 쿼리가 어떻게 되는지는 아래에서 설명하겠습니다.
Language-guided foreground query selection
open-vocabualry 세팅에서는 기존의 closed-set세팅과는 달리 모델이 학습 과정에서 본 vocabulary(base class) 범주를 넘어서는 훨씬 많은 범주의 전경 객체들(novel class)을 탐지해야 합니다. 하지만 저자들이 제안하는 디코더가 보유한 전경 쿼리 수가가 제한적이며(보통 수백개 수준) , 따라서 영상 내에서 등장할 가능성이 있는 모든 범주들을 처리하기에는 한계가 있습니다. 저자들은 이 문제를 해결하기 위해 언어 기반 전경 쿼리 선택(language-guided foreground query selection)법을 제안하여 주어진 텍스트 개념에 따라 쿼리를 적응적으로 선택할 수 있게 하였습니다(Figure 3의 왼쪽 참고). image feature O와 text feature T가 주어졌을 때, 경량화된 모듈을 사용해 각 feature에 대한 bounding box 및 score를 예측합니다.
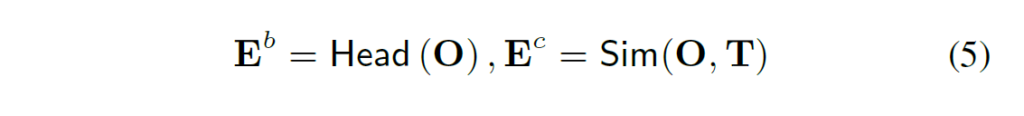
위 식 (5)에서 Head는 box head를 의미합니다. 그런 다음, 점수 {E}_{c}를 기준으로 {E}_{b}와 O에서 상위 {L}_{f}개의 항목을 선택합니다. 이렇게 선택된 {L}_{f}개의 이미지 특징과 바운딩 박스는 디코더에 전경 쿼리로 입력되며(그림3의 파란색 사각형), 디코더 쿼리로 텍스트와 관련된 토큰만 선택함으로써 의미적으로 무관한 정보를 디코딩하는 문제를 완화하고, 쿼리를 더 잘 초기화 할 수 있도록 하였습니다. 이런 형식의 foreground query 방식을 통해 text 시점에서 새로운 vocabulary로 효과적인 transfer가 가능하도록 하였습니다.
Learnable background queries
배경 쿼리로는 전경 쿼리와 달리 learnable query embedding을 사용하게 됩니다. 저자들은 두 가지 이유 때문에 이렇게 설정하였다고 합니다. 첫째는, query selection 방식은 선택된 reference point가 크기가 크거나 non-convex한 배경 영역을 자주 벗어나기 때문에 제대로 작동하지 않아 최적의 결과를 기대하지 못할 수 있기 때문이며, 둘째로 배경(stuff) 범주가 전경보다 상대적으로 그 수가 적으며, 일반적으로 이미지 하나에 sky, building과 같이 stuff 몇개가 포함되어 있기 때문이라고 합니다. 이 때문에 모델에 learnable query를 사용해도 충분하며 open-vocabulary 세팅에서도 잘 일반화 된다고 합니다. 그림 3에서는 배경 쿼리가 초록색 사각형으로 표시되었습니다.
Comparison with previous works
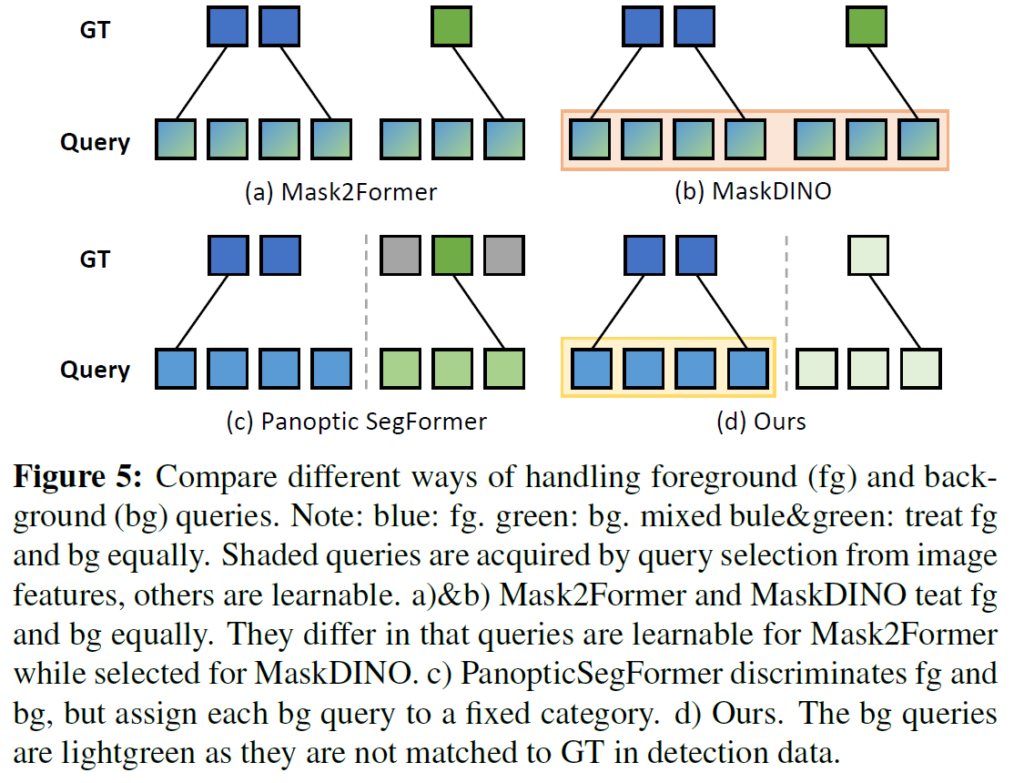
Figure 5에 기존 방법과 제안하는 방법론의 전경 / 배경 처리법을 비교하여 나타내었습니다. Mask2Former와 MaskDINO는 panoptic segmentation을 수행할 때 전경과 배경을 동일하게 취급하기 때문에, 동일 모델을 foreground class(instance segmentation)에만 학습시킨 경우보다 foreground object에 대한 mask average precision(AP)이 낮아지게 된다고 합니다. Panoptic Segformer는 전경 쿼리와 배경 쿼리를 분리하긴 하지만 각 배경 쿼리가 사전에 정의된 배경 범주에 대응하도록 고정되어 open-vocabulary 세팅에 적용하기에는 한계사 있습니다. 저자들은 제안하는 방법이 language-guided selection mechanism을 통해 전경 쿼리를 구성하고 배경 쿼리는 학습 가능하도록 해서 이전 방법론들의 한계를 해결했다고 강조합니다.
Bridge Data Gap: Conditioned Mask Decoding
저자들은 multiple task에 대해 다음과 같은 단일 loss function을 사용하여 data gap을 줄이는 것을 목표로 합니다. D는 detection, segmentation 데이터셋의 합집합입니다.
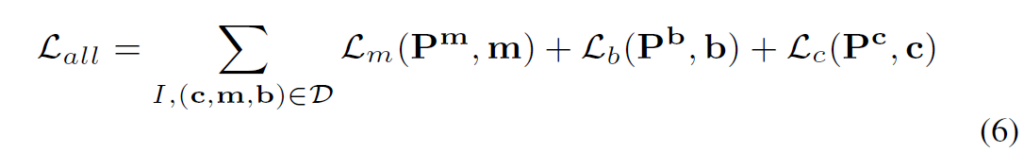
하지만 위 loss function에는 detection data에 대한 mask annotation 및 segmentation data에 대한 box annotation이 필요해 학습 과정에서 두 작업 간 공간적 세분화 수준에서 불일치가 발생합니다. object mask m은 손쉽게 box로 변환할 수 있으므로, 본래의 segmentation 데이터를 detection 데이터 형태로 확장할 수 있지만 detection data의 경우 mask 라벨을 바로 만들 수 없습니다. 저자들은 여기서, 주어진 category 및 box 정보로 mask를 얻을 수 있는지 여부를 연구하였습니다. 문제 해결을 위해 풍부한 box->mask 매핑 정보를 가지고 있는 segmentation 데이터를 활용하여, (c, b) -> m의 매핑 관계를 학습하기 위해 conditioned mask decoding을 제안하였습니다( Figure 3의 가장 오른쪽 부분). 주어진 GT concept 및 box (c,b)에 대해, 디코더가 mask를 디코딩하도록 하였습니다.
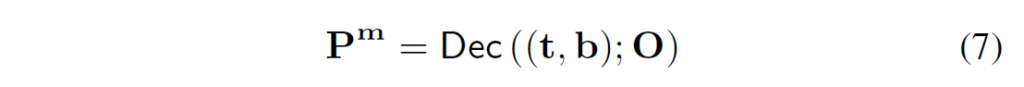
Conditioned Mask Decoding Training
저자들은 모든 GT box 및 label을 조건부 쿼리(conditioned query)로 추가하여 그림 3과 같이 전경/배경 디코딩과 조건부 마스크 디코딩을 동시에 학습하도록 하였습니다. 이를 통해 모든 task를 통합하고 모델이 joint semantic space에서 보다 일반화된 conditioned decoding을 학습할 수 있도록 하였습니다. 이를 기반으로, 저자들은 object detectio n데이터에 대한 pseudo mask를 생성하여 이를 이용해 확장된 데이터셋을 생성하였습니다.
Conditioned Mask Generation to Guide Detection Data
저자들은 모델 학습(detection)을 보조하기 위해 앞에서 생성된 마스크를 활용하는 두 가지 방법 1. online mask assistance와 2. offline mask assistance을 제안하였습니다. onlie nmask assistance의 경우, 하나의 모델만을 학습하여 실시간으로 마스크를 생성하게 됩니다. 생성된 마스크 품질이 좋지 않기 때문에 이 마스크를 직접적으로 supervision에 사용하기보다는 예측 및 정답(GT)인스턴스 간 매칭을 보조하는 용도로 사용합니다. 반면, offline mask assistance에서는 conditioned mask docoding을 먼저 수렴할 때까지 학습한 후, deteciton data에 mask annotation을 생성해 segmentation model을 학습하는데 활용합니다. 이렇게 생성된 마스크들은 segmentation 성능 향상에 기여할 수 있다고 합니다. 박스 정보로 만들어낸 pseudo mask의 품질이 꽤 좋다는 점이 신기하네요.
Experiment
실험에서는 panoptic segmentation 및 object detection 데이터를 공동으로 사전학습시켰습니다. panoptic segmentation에는 COCO2017, object detection에는 Object365를 사용하였습니다. OpenSeeD를 COCO 및 Object365에 사전학습 시킨 후, 다양한 데이터셋에 zero-shot 평가를 진행하였습니다.
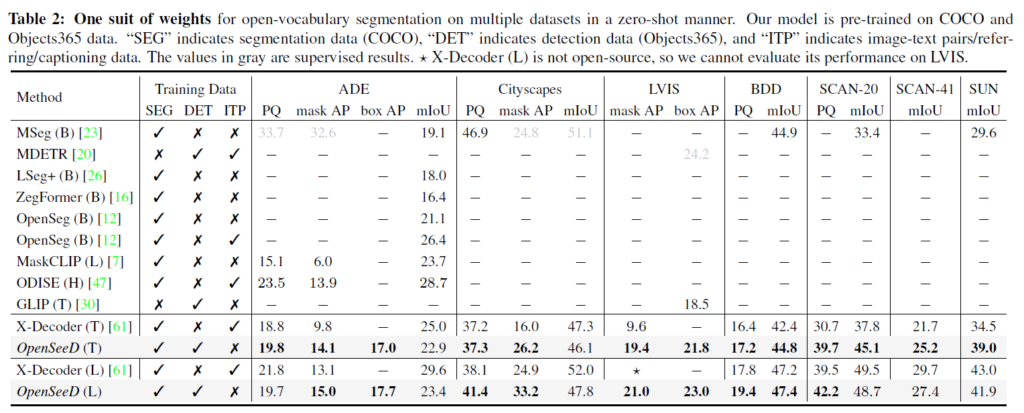
회색은 지도학습 성능입니다. X-Decoder가 오픈소스가 아니어서 LVIS에서 평가할 수 없었다고 합니다. 성능에서 확인할 수 있듯, 기존의 다양한 segmentation 방법론과의 성능을 비교하였고, 상당히 좋은 성능 결과를 낼 수 있었습니다. panoptic, instance, segmentic segmentation 각각에 대한 성능이 PQ, AP, mIoU입니다.
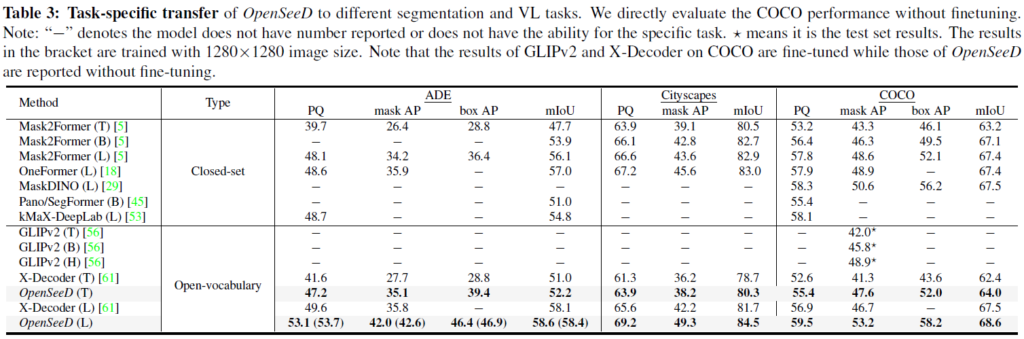
다음에는 task-specific Transfer 성능입니다. 사전학습 이후, downstream segmentation / detection task에 transfer 할 수 있습니다. Table 3에는 closed-set 및 open-vocabulary 방법론들 성능을 나타내었습니다. 위 Table 3에서는 특히 COCO panoptic에서 추가적인 파인튜닝 없이 SOTA를 달성하였다고 합니다. 해당 실험표에서도 OpenSeeD가 좋은 결과를 보여주었습니다.
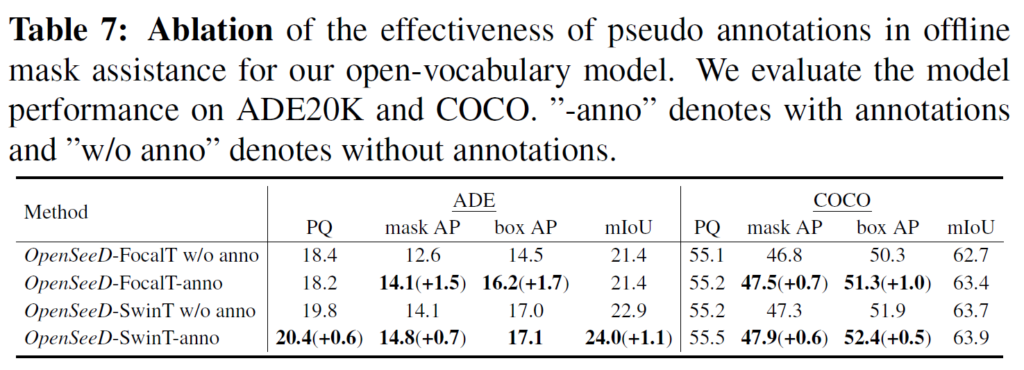
Table 7에는 conditioned mask decoding 과정에서 생성된 pseudo annotation의 효과를 나타내었습니다. pseudo annotation을 생성한 후 이를 활용해 작은 모델을 튜닝했다고 합니다. 평가 결과, mask AP 및 box AP가 상당히 개선되어 박스에서 수도 마스크를 생성해 사용하는 것이 긍정적인 효과를 줄 수 있다는 것을 확인하였습니다.
detection과 segmentation task 모두에 대해 open-vocabulary로 동작할 수 있도록 학습하는 프레임워크를 살펴보았습니다. 제목처럼 이게 정말 simple framework인지, 왜 굳이 detection과 segmentation을 단일 모델에서 수행해야 하는지 아직은 별로 와닿지 않지만.. 그래도 task 간 gap을 어떻게 줄이면서 학습하는지와, detection 데이터 정보를 활용해서 pseudo mask를 만들어 segmentation 학습에 활용하는 것은 흥미로웠네요. 아직 이쪽 세팅이 익숙지 않아서 이해하는데 어려움을 겪었는데, 관련 논문을 계속 읽어보며 익숙해질 필요를 느낍니다.
감사합니다.
안녕하세요. 리뷰 잘 읽었습니다.
1. instance segmentation 및 object detection에 등작하는 시각 개념(visual concepts)들을 전경(foreground)로 정의하고, panoptic segmentation에서의 stuff 범주들을 배경(background)로 처리하였습니다. – 이 부분에서 시각 개념이 의미하는 바가 무엇인지에 대해 여쭙고 싶습니다.
2. Language-guided foreground query selection에서 image feature와 text feature로 similarity를 구하는 것으로 보이는데, 여기서의 similarity는 무엇으로 계산하나요?
1. 해당 논문의 문맥으로 보았을 때, 각 데이터셋의 클래스를 visual concept라고 표현합니다. 시각 개념은 각 데이터셋에 포함되어 있던 클래스/카테고리 정보라고 생각하시면 될 것 같습니다.
2. 여타 VLP 방법론들에서 Vision-Language 임베딩 간 유사도를 계산하는것과 마찬가지로 cosine similarity를 활용합니다.
안녕하세요, 좋은 리뷰 감사합니다.
segmentation과 detection 사이의 vocabulary에 차이가 크기 때문에 이를 합쳐서 만들기 어렵다고 말씀해주셨는데, 이는 단순히 semantic segmentation으로 넘어갔을 때 생기는 stuff 영역들에 대한 text 때문인가요 ?? 혹시 물체에 대해서도 다루는 text 형태 자체가 다른지 궁금해서 질문 드립니다.
감사합니다.
vocabulary의 차이가 크다는 것은, 각 task에 대한 dataset에서 class label(OV 세팅이니 text 정보와 연결지어 생각할 수도 있겠죠)의 범주 및 그 종류가 다른 것으로 이해됩니다. 딱히 text의 형태 자체가 다르다기보다는 instance segmentation, object detection <-> semantic segmentation, panoptic segmentation 에서 stuff/background 유무 여부와, segmentation 및 detection의 task 차이에서 오는 데이터셋의 vocabulary 차이 정도로 받아들이시면 될 것 같습니다.
안녕하세요. 좋은 리뷰 감사합니다.
segmentation gt를 (cf, mf) (cb, mb)라고 하셨는데 이 각각이 의미하는 것이 무엇인지 궁금합니다. 또, 그림 4에서 좀 어둡게 처리된 부분은 두 query간 서로 interaction을 하지 않는 부분을 의미하는 것인가요 ? 그렇다면, conditioned query는 왜 자기 자신만 interaction하는 지 궁금합니다.
감사합니다.
detection에는 foreground 정보만 있지만 panoptic segmentation에서는 foreground가 되는 thing 이외에 background가 되는 stuff들이 있죠. 저자들은 segmentation dataset을 (c_f, m_f) 및 (c_b, m_b) 두 그룹으로 나누어 사용하였습니다. (c, m)은 각각 segmentation의 학습값인 class 및 mask이고, _f는 foreground, _b는 background를 의미한다고 생각하시면 됩니다.
그림 4의 (b)에서 conditioned query는 foreground, background와 다르게 conditioned mask decoding 수행을 위한 쿼리이므로 다른 쿼리들과 attention을 수행하지 않도록 한 것으로 이해됩니다.