안녕하세요 박성준 연구원입니다. 오늘 리뷰할 논문은 incremental learning을 다룬 논문입니다.
Incremental Learning
인공지능은 대부분 오프라인 학습을 기반으로 설계되어 있습니다. 오프라인 방식은 대량의 데이터를 미리 수집한 후에 전해진 학습 단계를 통해 모델을 학습하는 방식을 말합니다. 이와 같은 방식은 학습이 완료된 이후에는 고정된 지식을 토대로 추론 만을 진행합니다. 고정된 지식만을 활용하게 되면 새로운 정보에는 대응할 수 없기에 시간이 지남에 따라 새로운 데이터나 클래스에 대응할 수 없다는 한계가 있었습니다. 이 한계를 해결하기 위한 학습 방법이 Incremental Learning입니다.
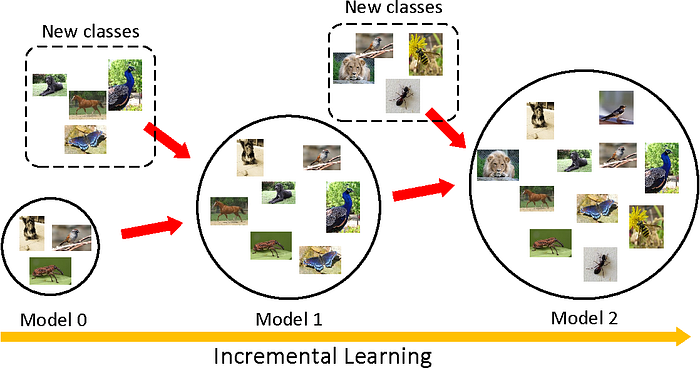
Incremental Learning은 증분 학습으로 기존 모델에 새로운 입력 데이터가 지속적으로 들어오는 학습을 말합니다. 새로운 입력 데이터는 일반적으로 새로운 클래스가 포함되어 있어 점진적으로 모델이 클래스의 범위를 확장하여 학습합니다. 새로운 데이터를 추가로 학습하면서도 기존의 지식을 유지하여 새로운 환경 변화에 실시간으로 대응할 수 있도록 하는 것을 목표로 하는 학습으로 앞서 설명드린 새로운 데이터에 대응할 수 있다는 장점이 있는 반면 다음과 같은 문제 혹은 도전과제를 갖고 있습니다.
- Catastrophic forgetting: 새로운 데이터를 학습하는 과정에서 기존에 가지고 있던 지식을 잊는 현상입니다. 이는 모델이 새로운 분포에 적응하는 과정에서 이전 데이터의 분포가 망가지기 때문에 생기는 현상입니다.
- Class Imbalance: Incremental Learning에서 새로 들어오는 학습 데이터는 일반적으로 기존 클래스에 대한 정보는 일부만 사용하고 새로운 클래스에 대한 정보는 풍부한 경우가 많습니다. 따라서 클래스 간 불균형이 존재합니다.
- Scalability(확장성): 새로운 클래스나 태스크가 추가될 때에 모델의 크기, 학습 시간, 메모리 등이 증가하는 문제가 발생합니다. 따라서 효율적으로 지속 가능한 학습을 위한 설계가 필요합니다.
위 3가지를 해결하기 위한 방법으로 기존에 많이 사용되던 전략은 Parameter-based 접근법과 Distillation-based 접근법입니다. 파라미터 기반은 모델의 핵심 파라미터를 보존하는 것으로 기존 지식의 분포를 유지하기 위해 노력한 방법이고, Distillation 기반은 새로운 모델이 기존 모델의 출력을 따라하도록 유도하는 것으로 기존 지식에 대한 정보를 유지하려했습니다. 본 논문에서 저자는 Joint Training 즉, 데이터를 한번에 학습하는 방식에 비하면 위 두가지 방법은 부족함이 많음을 지적하며, 성능 저하의 근본적인 원인을 기존 클래스와 새로운 클래스 간의 불균형으로 얘기하고 Rebalncing을 통해 성능 개선을 달성합니다. 3가지 방법을 통해 Rebalancing합니다.
Introduction
본 논문은 Incremental Learning 중에서도 Multi-Class Incremental Learning을 다루고 있습니다. 이는 새로운 클래스가 점진적으로 주어지는 상황에서 모델이 모든 클래스를 다룰 수 있도록 하는 것을 목표로하는 task입니다. 따라서 기존 클래스에 대한 정보를 잘 유지하는 동시에 새로운 클래스에 대한 정보를 잘 모델리하는 것이 중요합니다.
단순하게 fine-tuning하는 것은 앞서 설명드린 Catastrophic Forgetting 문제를 야기할 수 있습니다. Catastrophic Forgetting 현상이 일어나는 이유로 저자는 학습을 진행하는 과정에서 새로운 클래스는 수천개의 클래스가 주어지고, 기존의 클래스는 수십개가 주어지는 경우가 대부분이기 때문이라고 지적합니다. 따라서 모델은 자연스럽게 새로운 데이터세 대해 더 큰 가중치를 부여하게 되고 이는 모델의 표현 공간을 변화하게 만들어 기존 클래스와의 충돌을 야기합니다. 저자는 이러한 문제를 해결하기 위해 모든 클래스를 균등하게 다룰 수 잇는 unified classifier의 필요성을 강조합니다.
기존의 연구들의 접근에 대해서는 자세하게 다루지 않겠지만 간략하게 설명하면, 파라미터 기반의 방법론은 모델의 파라미터 중 핵심 파라미터의 정보를 유지하는 것인데 이 방법은 파라미터 수준의 보존 만을 고려할 뿐 실제 표현 공간의 왜곡을 방지하지 못하기에 효과적이지 못합니다. 또 Distillation 기반 방법은 결국 클래스 불균형에는 구조적으로 취약합니다. 신규 클래스에 편향될 가능성이 굉장히 크다고 합니다.
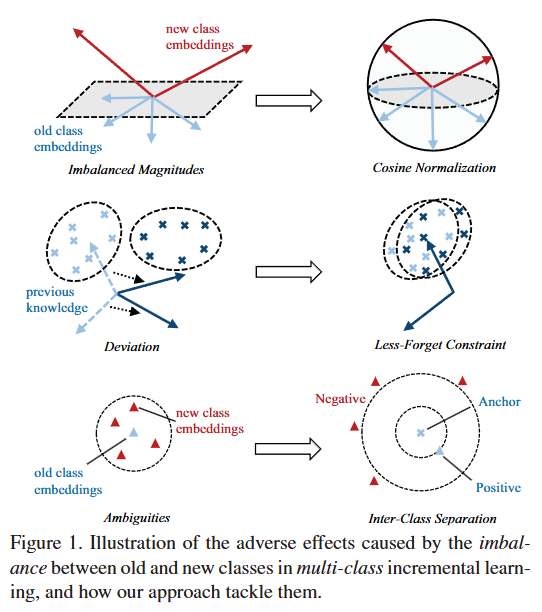
저자는 따라서 기존의 방법이 아닌 다른 방법으로 Incremental Learning에서의 문제를 해결하고자 했고, Figure 1. 은 이를 위해 저자가 제안하는 3가지 방법(loss)을 보여주고 있습니다. 순서대로 Cosine Normalization, Less-Forget Constraint, Inter-Class Separation입니다.
- Cosine Normalization: 기존 분류기(모델)에서는 클래스 별로 가중치 벡터의 magnitude가 서로 가르기 때문에 softmax에서 큰 영향을 미치게 됩니다. 특히, 새로운 데이터는 더 많은 데이터를 학습하기 때문에 가중치의 크기가 자연스레 커지게되어 softmax에서 큰 분포를 차지하게 됩니다.
이를 위해 저자는 softmax 계산에서 dot product 대신에 cosine similarity를 사용합니다. 가중치를 정규화하고 유사도를 계산하는 것으로 모든 가중치 벡터가 동일한 크기를 가지게 되어 여러 클래스 사이 비교에서 특정 클래스에 편향되는 것을 방지합니다. 따라서 전체 표현 공간을 고차원의 구 형태로 설계합니다. - Less-Forget Constraint: Cosine Normalization은 벡터의 크기를 일치화하는 데에 효과적이지만, 저자는 여전히 특징 벡터의 방향이 달라질 수는 있다고 지적하고 있습니다. 즉, 표현 공상이 회전하거나 변형되게 된다면, 특징 벡터의 크기를 일치화하더라도 기존 클래스에 대한 정보를 잃어버릴 수 있음을 지적합니다.
이를 방지하기 위해서 저자는 feature의 방향을 보존하는 loss(Less-Forget Constraint)를 도입합니다. 이는 모델에서 추출한 feature와 새로운 모델의 feature 사이의 cosine 유사도를 최대화하는 방식을 통해 기하학적 구의 형태를 유지할 수 있도록 유도합니다. 이 loss는 새로운 클래스의 수에 비례하여 가중치를 조정할 수 있도록 설계합니다. - Inter-Class Separation: 새로운 클래스가 추가됨에 따라 기존의 결정 경계를 공유하는 문제가 생길 수 있습니다. 결정 경계를 공유한다는 것은 기존 클래스와 새로운 클래스를 구분하는 데에 있어 모델에게 혼란을 야기할 수 있기에 저자는 이러한 모호성을 없애는 것이 중요한 요소 중에 하나라고 말합니다.
이를 해결하기 위해 저자는 Margin Ranking Loss 기반의 Inter-Class Separation을 제안합니다. 이는 이전 클래스의 샘플을 앵커로 사용하고 그에 따른 positive와 neagtive를 선택하여 일정한 margin을 가지도록 학습하여 결정경계가 섞이는 것을 방지합니다. 기존 클래스의 표현과 새로운 클래스의 표현을 구조적으로 분리할 수 있도록 설계합니다.
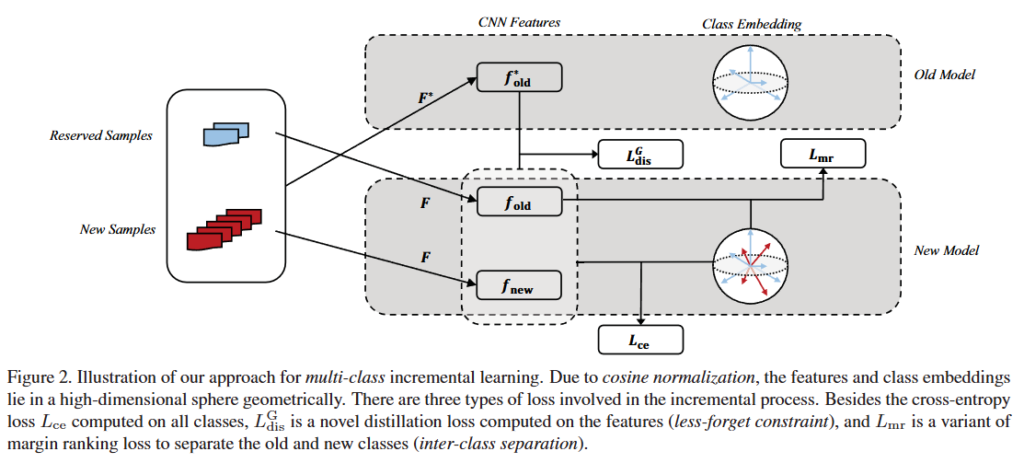
Figure 2.는 Multi-class incremental learning과정에서 모델의 학습 프레임워크와 함께 저자가 제안하는 위의 3가지 학습 loss의 적용 위치를 보여주고 있습니다. cosine normalization을 통해 feature와 weight 벡터가 구 형태의 표현 공간에 매핑되고 feature의 방향을 고정시킨 후 기존 클래스와 새로운 클래스 사이의 margin을 두는 것으로 분류 성능을 올리는 것입니다.
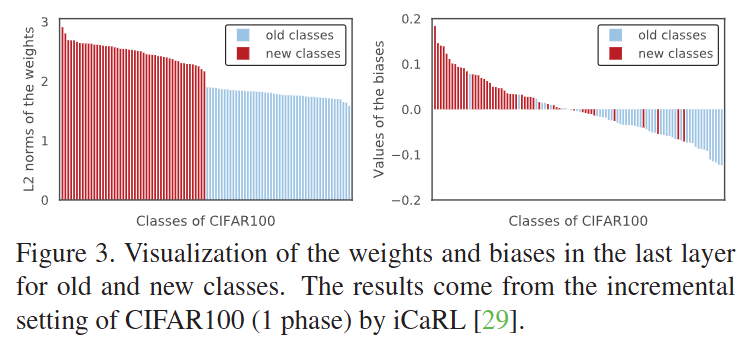
위 Figure는 기존 클래스와 새로운 클래스 사이의 가중치 분포 차이를 보여주고 그림입니다. 위 그림을 통해 저자는 cosine normalization의 필요성을 설명하고 있습니다. 앞서서도 설명드렸지만, 새로운 클래스의 데이터가 풍부하여 새로운 클래스의 weight가 더 잘 훈련됨에 따라 magnitude가 더 커지게되서 softmax가 새로운 클래스에 편향됩니다.
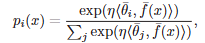
수식으로 표현하면 다음과 같습니다. 결국 크기를 정규화하고 방향 정보만을 활용하는 것입니다. 지금에서야 흔한 아이디어지만, 당시에는 이러한 접근이 흔치않은 접근이었던 것 같습니다. \theta_i는 클래스 i의 가중치를 l2 정규화한 벡터이고 f(x)는 입력 x에 대한 feature를 l2 정규화한 벡터입니다. 크기를 같게 만들고 방향정보를 통해 구분하는 것으로 데이터 사이의 불균형을 해결했습니다.
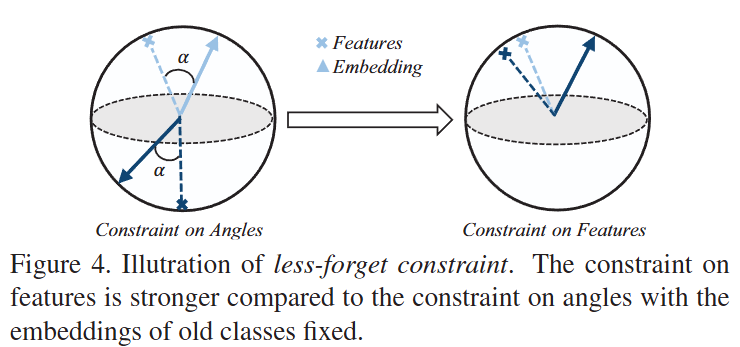
Figure 4.는 less-forget constraint에 대한 이해를 돕기 위한 그림입니다. 즉, cosine normalization을 통해 방향으로 구분을 하게되더라도 feature의 방향 자체가 변화할 수 있기에 feature의 방향이 왜곡된다면 정확한 예측을 할 수 없다는 것인데요. 기존 모델에서 추출한 feature와 현재 모델의 feature 간의 cosine 유사도를 유지하도록 하는 것으로 기존 모델에 대한 정보를 “조금”만 잊어버리도록 하는 것입니다.
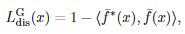
*는 기존 모델을 의미합니다. 즉, 기존 모델과 새로운 모델 사이의 유사도를 가까이하도록 학습하게 유도함으로 기존 모델의 feature의 방향이 망가지는 것을 방지합니다.
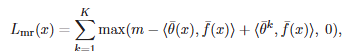
위 수식은 Inter-Class Separation으로 L_{mr}는 margin ranking loss를 의미합니다. 기존의 클래스와 새로운 클래스 사이의 결정 경계가 가까워지는 문제가 생길 수 있기에 margin을 설정하는 것으로 기존 클래스와 새로운 클래스 사이에 구별력을 갖추는 loss입니다. \theta_y는 GT의 정규화된 weight고, \theta_k는 top-K hard negative 클래스의 weight입니다.
최종 loss는 다음과 같습니다.
Experiments
저자는 CIFAR-100과 ImageNet에서 실험합니다. CIFAR-100에서는 먼저 50개의 클래스를 학습한 후에 나머지를 단계적으로 추가하여 학습합니다. ImageNet에서는 먼저 500개의 클래스를 학습한 후에 나머지를 단계적으로 추가하여 학습합니다. 저자는 기존의 방법들에 비교하여 결과를 리포팅하고 있으며 CIFAR-100에서는 기존 SOTA에 비해 6% 이상의 정확도 향상을 보여주고 있으며, ImageNet에서는 13% 이상의 정확도 향상을 보여주고 있습니다.
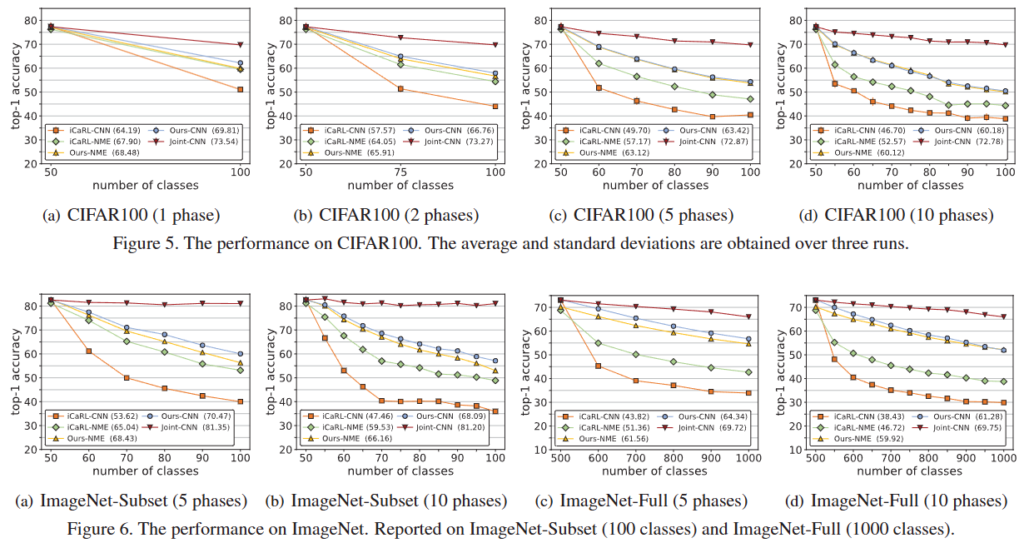
Figure 6.은 저자의 단계적 실험에서의 성능을 보여주고 있습니다. 간략하게 설명드리면, 새로운 클래스가 추가됨에 따라 전체적인 성능이 떨어지는 기존의 방법론과 달리 저자가 제안하는 방법론은 성능이 떨어지지 않는 모습을 보이며 기존 Incremental Learning이 가지고 있던 Catastrophic Forgetting 문제에 잘 대응하고 있는 모습을 보여줍니다.
Ablation Study
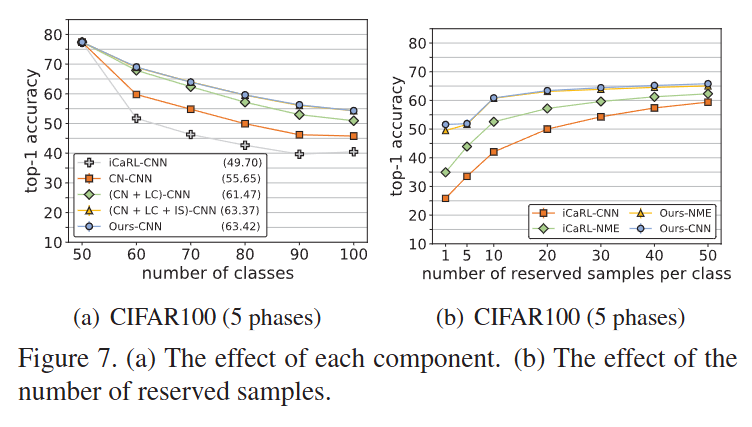
Figure 7.는 저자가 제안하는 방법론의 구성요소들에 따른 성능 변화를 보여주고 있습니다. CN은 Cosine Normalization, LC는 Less-Forget Constraint, IS는 Inter-Class Separation을 의미하고 CBF는 Class Balance Finetune 의미합니다. 단계별 표를 통한 정확한 성능을 보여주고 있지는 않지만, 각각의 구성요소들이 성능에 도움을 준다는 것을 보여주고 있습니다.
저자는 기존 방법들이 지나치게 parameter과 distillation에만 집중하던 것에서 벗어나, 표현 공간에서의 기하학적 균형과 클래스 간의 구조적 분리를 동시에 고려하고 있습니다. 특히, cosine normalization이 본 논문에서 처음 사용된 것인지는 잘 모르겠지만, incremental learning 이외의 연구에서도 자주 활용되는 것을 통해 저자가 제안하는 방법론이 대규모 데이터셋에서 강건한 성능을 보여주고 실용적인 가치가 있다는 것을 알 수 있습니다.
감사합니다.
박성준 연구원님. 좋은 리뷰 감사합니다.
리뷰 중간에 “새로운 클래스가 추가됨에 따라 기존의 결정 경계를 공유하는 문제가 생길 수 있다. 결정 경계를 공유한다는 것은 기존 클래스와 새로운 클래스를 구분하는 데에 있어 모델에게 혼란을 야기할 수 있기 때문이다” 라고 하셨는데, 이에 대해 잘 이해가 되지 않아 더 자세히 설명해주시면 감사하겠습니다.
또한, 제안하는 방법론으로는 3번째 문제점인 scalability는 해결할 수 없는지 궁금합니다.
안녕하세요 허재연 연구원님 좋은 댓글 감사합니다.
먼저, 기존 결정 경계를 공유하여 혼란을 야기할 수 있는 문제는 기존에 잘 형성되어 있는 결정경계에 새로운 클래스가 추가됨에 따라 기존 클래스와 새로운 클래스를 구분하는 결정경계를 생성하는 데에 있어 어려움이 생기는 점을 지적하는 것입니다. 새로운 클래스가 들어옴에 따라 기존 결정경계 또한 수정되어야하지만, 기존 결정 경계는 그대로 있으면서 새로운 클래스의 데이터를 구분하는 결정경계를 생성하게 되면 결정경계에 따른 구분이 모호해지는 문제를 다룬 것입니다. 3번째 문제점인 scalability는 새로운 클래스가 들어옴에 따라 모델의 크기가 커지는 문제를 해결하고자한 것입니다. 저자는 하나의 통합된 분류기(Unified Classifier)를 사용해 새로운 클래스의 데이터가 들어오더라도 모델의 크기가 커지지 않아 3번째 문제를 잘 다룰 수 있다고 주장하고 있습니다.
감사합니다.