안녕하세요. 제가 이번에 리뷰할 논문은 이전 리뷰인 두 PuMer, LLaVA-PruMerge을 읽고 이해하셨다면 저자의 새로운 기여는 하나 밖에 없습니다 (대부분은 이전 리뷰에서 차용해온 방식을 그대로 사용했습니다). 그럼에도 본 논문을 리뷰하는 이유는 MLLM으로 본다면 아직까지 LLaVA-PruMerge와 본 논문, 둘 밖에 없는 것으로 보입니다. 그렇기에 트렌드를 따라가보며 새로운 아이디어를 궁리중에 있습니다.
Introduction
리뷰를 하면서 결국 LLaVA-PruMerge (이하 LLaVA-PM)가 계속 나오게 됩니다. 아직은 MLLM의 성장에 분명 초점이 더 맞쳐줘있지만 결국 실용성을 고려하면 최적화가 요구됩니다. 가벼운 구조 (파라미터와 구조적 복잡함을 푸는), 최적화를 위한 요소 설계 등이 있지만 본 논문에서도 결국 LMM에 전달하는 이미지 토큰의 수를 줄임이 중요하다는 입장입니다. 특히 이 접근 방식은 해상도가 큰 이미지나 비디오에 대해서 특히 효율적으로 작용합니다. MLLM에서 유일한 Token Reduction은 LLaVA-PM입니다. 저자는 “사람이 주의집중하는 방식”에 영감받아 CLIP의 이미지-텍스트 간 연관성을 계산하고자 합니다. 주목할점은 제가 세미나에서 말씀드린 바와 같이 MLLM에서는 텍스트에 대해 (LLaVA는) Instruction으로 바로 LLM에 입력하기 때문에 이미지-텍스트 간 연관성을 계산하는 과정이 원래 존재하지 않습니다. 이 과정에서 Cross-Attention의 힘을 빌릴 수는 없습니다. 이를 위해 CLIP의 Text Encoder만 태운 다음 둘 사이 유사도 (Cosine Similarity)로 연관성을 봅니다. 본 논문에선 이 과정만 다른 논문과 다른 점이라고 볼 수 있습니다.
Method
그렇게 소개하는 방법론이 TRIM, Token Reduction using CLIP Metric입니다. 이미지와 텍스트 사이 CLIP Metric를 유사도로 연관성을 활용합니다. 지난 두 논문에서도 이야기 했지만, Token Reduction의 핵심은 “어떤 토큰이 중요한지”를 알아내는 것입니다. 저자의 논리로는 “선택적 주의집중 이론”은 사람이 시각적 집중에 있어 우선순위를 정하며 연관성이 미미한 정보를 버린다고 합니다. 이 주의집중을 위해, 원래 Language Instruction을 Fig. 1의 LLM Tokenizer에 바로 입력하던 방식과 달리 Token TRIM 모듈에 입력합니다. 이 과정을 자세히 보면 Fig. 1의 Language Instruction은 Token TRIM의 Text Encoder와 CLIP Projector를 통과합니다. 물론 CLIP의 Text Encoder와 얇은 Projector를 태운단 점에서 아쉬움은 있습니다. 이때 모든 텍스트 토큰을 활용하진 않고, 물론 CLIP Text Encoder를 태운단 점에서의 한계를 일부러 언급하지 않고 넘어가지만 그나마의 최대한 최적화하기 위해 [eot] (EOS) 토큰만을 활용합니다. 이 [eot] 토큰은 CLIP의 Vision Encoder (ViT)의 [CLS] 토큰처럼 텍스트에 대한 전체적인 정보를 함축하고 있습니다. 이제 [eot]와 전체 이미지 토큰과 거리를 계산합니다. 이 과정이 Fig. 1의 CLIP Repr. Subspace에 그려져 있습니다 (CLIP Metric Measurement). 거리 계산은 Cosine Similarity (Eq. 1), 거리로 연관성 (점수)을 결정하는 부분은 소프트맥스 기반의 Eq. 2로 표현됩니다.
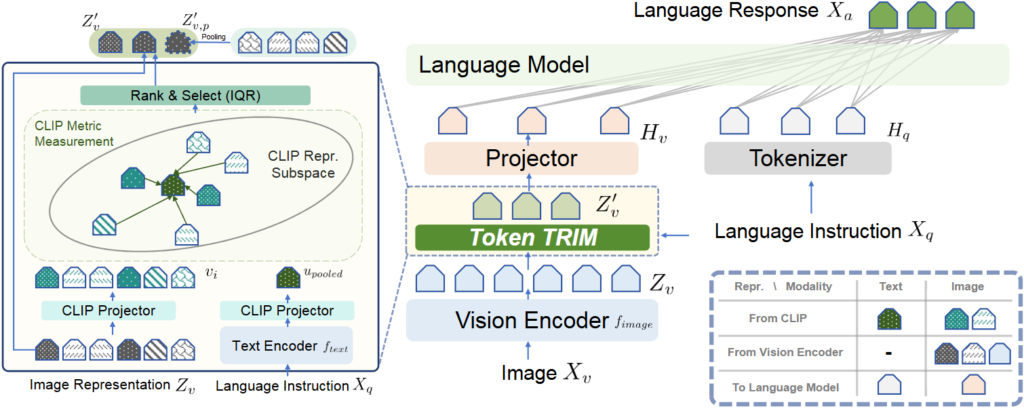
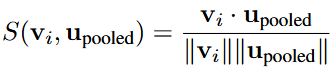
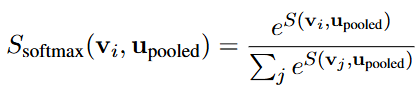
이후 Rank & Select 과정은, LLaVA-PM의 IQR로 Outlier를 제거하는 방식을 사용합니다. 이 과정에 대해서는 LLaVA-PM에 자세히 소개하였으므로 넘어가겠습니다. 한 문장으로만 요약하자면 사사분위의 Q1~Q4에 대해 Q3-Q1의 IQR에 대해 IQR-Q1X1.5를 Lower Bound, IQR+Q4X1.5를 Upper Bound로 두고 범위 밖의 토큰을 Outlier로 정의해 제거하는 방식입니다. 이후 제거된 (Unselected) 토큰들의 평균으로 하나의 토큰을 만들어 남겨진 토큰 뒤에 붙입니다. 이 과정은 본 논문에서 처음 본 방식이긴 하지만, 정보 손실을 방지하기 위한 추가 하나 토큰이 평균으로 생성된단 점에서 참신함은 약하다고 생각합니다. 저자는 이 정보들이 마치 배경의 정보를 포함한다는 가정에서, 정보의 보완을 기대한다고 볼 수 있습니다.
Experiment
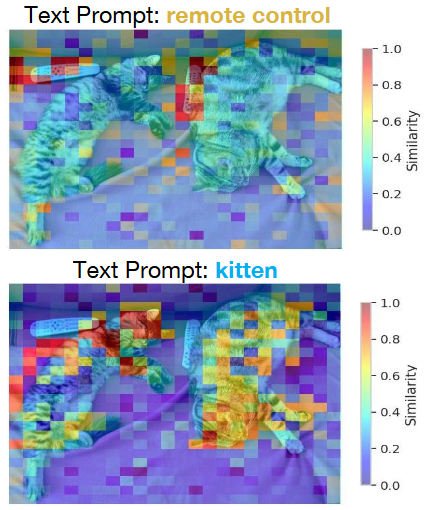
우선 본 논문에서 언급하는 핵심이 이미지-텍스트 연관성이다 보니, 이에 대한 시각화 결과가 Fig. 2에서 확인할 수 있습니다. “remote control”과 “kitten (새끼 고양이)” 단어에 대해 Similarity를 보면 얼만큼 연관되어 있는질 알 수 있습니다.
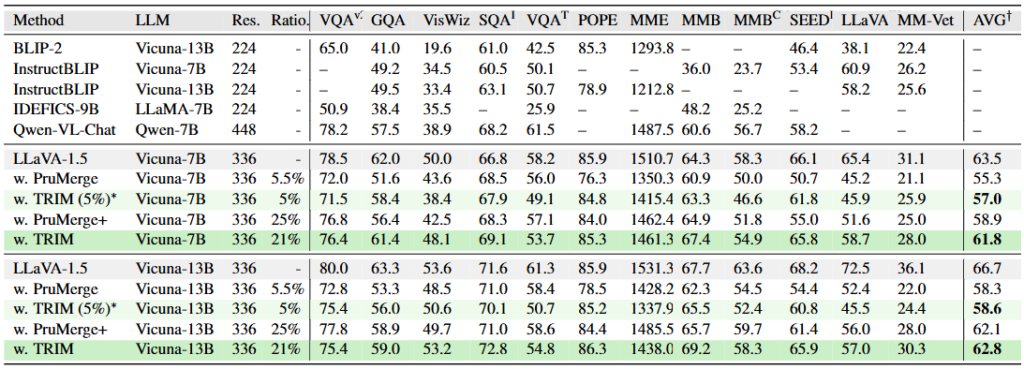
Main Table인 Tab. 1을 보면 본 논문에서 제안하는 TRIM과 이전 논문 (LLaVA-PM)의 PruMerge와 비교하고 있습니다. 여전히 위 논문들의 주요 목적은 사람과의 상호작용이므로 VQA에 대해 평가합니다. 수 많은 VQA 벤치마킹에서 비교한 결과, Vicuna-7B와 13B에서 유사한 압축 비율(25%는 4개 중 하나만 사용한단 의미)만큼 토큰을 줄인 결과로 비교하면 PruMerge와 PruMerge+에 대해 약 2% 내외의 성능 향상을 보입니다 (AVG 평균). 여기서 의문점은 TRIM은 Ratio를 조절할 수 있는지입니다. 즉, 본 방법론도 PruMerge와 똑같이 IQR로 적응적으로 줄일 것이라 생각했는데, 그렇다면 PruMerge와 TRIM의 Ratio.를 유사하게 맞추도록 조절하긴 어렵기 때문입니다.
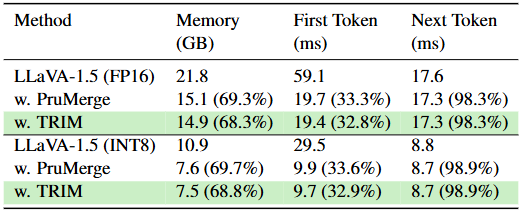
두 번째의 최적화 실험에서 Memory, First Token, Next Token (LLM에서 Token 처리 속도; Prefilling Time이라고도 함)과 비교했을 때, 속도 측면에선 PruMerge와 크게 다른 점은 없지만 Memory는 줄어든 모습입니다. 음 글쎄요. 저 Memory에 대해 좀 더 알아봐야할 것 같습니다. 그러니 즉 제 생각에선 CLIP Text Encoder를 쓴단 점에서 분명 PruMerge에 비해 높을 수 밖에 없다 생각하는데 그것을 측정에서 제외한건지 (LLM쪽만 측정했다던지), 의구심은 듭니다. 아마 이 부분은 코드 돌려보면서 확인해봐야겠네요.
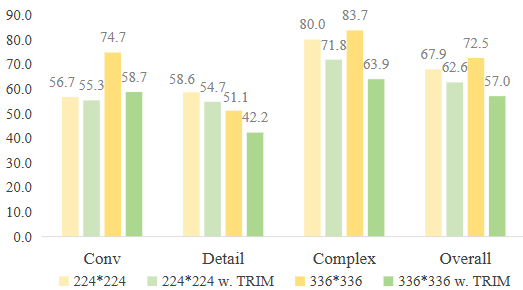
이미지 해상도에 따른 Ablation을 살펴보면 224×224와 TRIM 적용을 비교했을 때, Conv(ersation), Detail (자세한 묘사), Complex (복잡한 추론), Overall (전반적인)에 대한 성능 비교 시, TRIM을 적용했을 때 성능이 해상도가 224에선 성능이 유사한데 336에선 차이가 꽤 납니다. 결론적으로 제 생각에는 아직 이 연구가 전체적으로 방법론에 따라 성능이 고르지는 않은 느낌입니다. 그럼 다음 주에는 혹시 더 최신 논문이 있는지 또는 연관성을 알 수 있는 조금 더 가벼운 방법에 대해 알아보려 합니다.