이번 리뷰 논문의 유뷰트 보고 요리하는 로봇에 대해서 다루고자 합니다. 분야 관련 게시물들을 보다가 발견한 기사에서 해당 논문에 대해서 다루는 것을 보고 읽게 되었습니다. 기법은 예상 가능한 수준이지만… 굉장히 흥미로운 방향을 제시하고 구현한 논문이라고 판단하여 리뷰를 진행하게 되었습니다.
Intro
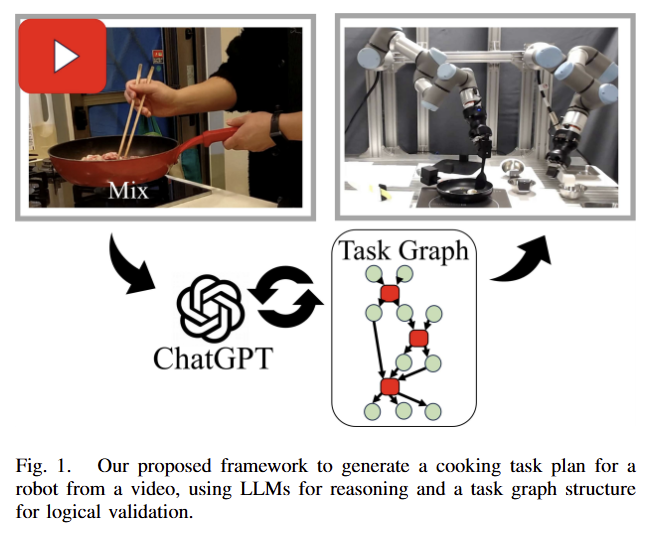
최근 비디오 플랫폼의 대중적인 유행으로 인하여 정말 많은 요리법들을 동영상으로 접근 할 수 있게 되었습니다. 만약에 해당 요리법들을 이용하여 로봇이 요리를 할 수 있다면 엄청난 파급력을 가져 올 겁니다. 하지만 이러한 요리 영상들은 비 표준화된 구조를 가지고 있기 때문에 로봇이 직접 활용 하기 어렵다고 저자가 주장합니다. 구체적인 예시를 들자면 다양한 카메라 앵글과 도구들을 활용함으로써, 장면 내 상태를 정확하게 인지하는 데에 어려움을 주게 됩니다. 또한, 비디오 속 환경과 실제 로봇의 환경의 차이를 적응적으로 인식 가능해야겠죠. 더 나아가, 많은 비디오에서는 주방 기구나, 재료들을 준비하거나 옮기는 행위들은 생략하고 핵심적인 장면만 보이도록 편집을 진행합니다. 실제 로봇에서 동작하기 위해서는 생략된 장면들을 논리적으로 추론하고 이를 채워서 동작을 수행해야만 합니다.
위와 같은 한계를 해결하기 위해서 저자는 VLM과 task structures의 그래프 기반 표현인 Functional Object-Oriented Network (FOON)을 결합한 방법을 제시합니다.
인터넷 스케일의 방대한 지식을 학습한 LLM을 활용하여 요리 비디오와 자연어 지시가 결합된 정보를 토대로 이에 대응되는 로봇의 액션을 생성할 수 있습니다. 허나, LLMs은 hallucination으로 인해 부정확한 출력 결과를 내보는 경우가 많을 수 있습니다. 특히, 복잡하고 long-horizon tasks에서는 더 두드러지게 됩니다.
저자는 task planning의 정확도를 개선하기 위해서 환경에 비의존적인 task planning이 가능한 FOON으로부터 생성한 task graph structure를 활용하는 방법을 제시합니다. 구체적으로는 FOON’s functional units의 입력과 출력을 각 계획은 step들은 비교함으로써, 논리적인 비일관성을 검출하고 이에 따른 feedback prompts를 생성하여 보다 정확하게 만듭니다.
+ 여기서 FOON은 LLM을 활용합니다.
해당 논문의 기여는 다음과 같습니다. 에러 수정과 환경-비종속적인 planning이 가능하며, 자막이 있는 요리 영상으로부터 cooking task plans을 생성하는 LLM과 FOON이 통합된 프레임워크를 제안합니다. 해당 프레임워크는 5개의 요리 영상으로부터 실제 로봇 환경에서 실험을 진행하였으며, few-shot prompt를 활용한 baseline이 1개만 수행한 결과 대비, 4개의 레시피를 성공함으로써, 프레임워크의 효과를 입증합니다.
Method
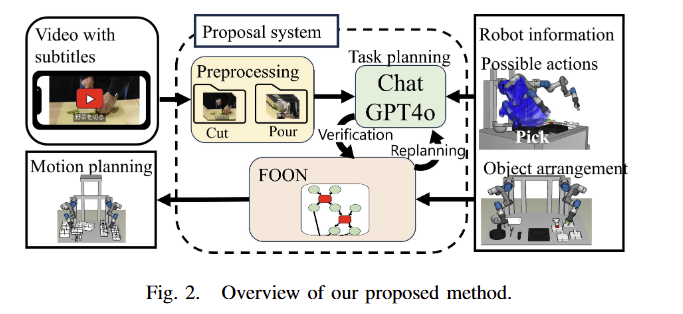
overview
Fig 2에서 제안하는 프레임워크의 전반적인 방법을 확인 가능합니다. 사람이 직접 요리하는 자막이 있는 유튜브 영상으로부터 영상을 추출합니다. 해당 영상들은 실행 가능한 로봇의 행동 집합, 로봇 작업 공간의 현재 배치 정보들을 함께 LLM에 입력으로 제공되며, LLM은 로봇을 위한 cooking task plans을 기반으로 일련의 행동을 생성합니다. 그 다음, 해당 계획은 연속적으로 FOON’s functional unit으로 변경되고, graph structure에 추가됩니다. 만약에 변환을 실패하면 계획 중 실패한 순간과 원인을 발견하여 LLM에게 re-planning을 위한 feedback으로 error prompt을 제공합니다. 해당 프로세스는 전체 FOON이 성공적으로 생성될 때까지 반복적으로 적용됩니다. 이후, robot의 motion planning으로 활용되어져 로봇을 실행하게 됩니다.
Functional Object-Oriented Network (FOON)
FOON은 로봇 조작과 관련된 작업 구조를 모델링하기 위해서 사용되는 그래프 기반의 지식 표현 방식입니다. FOON의 기본 이념은 로봇이 작업 목표를 이해하고, 해당 작업을 수행하기 위한 적절한 객체와 상태, 그리고 행동을 생성하는 것을 목적으로 합니다. 해당 방법론에서는 LLM을 활용해 cooking videos로부터 생성된 cooking task plan을 검증하고, object motion plannning을 위해서 task-sequence graph의 representational form으로 구성된 FOON을 이용합니다.
Graph structure
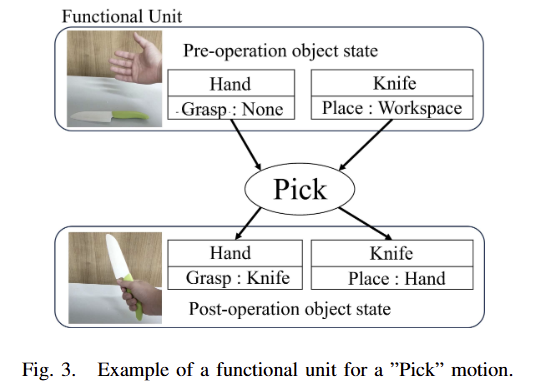
fig 3에서는 functional unit이라고 불리우는 FOON’s 가장 작은 유닛을 예시로 보여줍니다. 해당 구조는 [1]을 따릅니다.
+ [1] K. Takata, T. Kiyokawa, I. G. Ramirez-Alpizar, N. Yamanobe, W. Wan, K. Harada, Efficient Task/Motion Planning for a Dual-arm Robot from Language Instructions and Cooking Images. IEEE/RSJ Int. Conf. on Intelligent Robots and Systems, 2022.
- Object nodes: representing ingredients, cooking utensils or containers;
- Hand nodes: representing the hand state;
- Motion nodes: description of the action;
각 functional unit은 motion node에 설명된 action 이전의 state를 나타내는 input object와 hand node, 그리고 action 이후의 state를 나타내는 output object와 hand node로 구성된 single action으로 구성됩니다.
예를 들어, fig 3에서 “Pick” motion의 input node는 “Hand”와 “Knife”로 초기에는 손은 비워져 있고, 칼은 워크스페이스에 위치해 있습니다. Motion “Pick”에 대한 action이 수행된 이후, output node에 “Hand”에는 “Knife”가 쥐어져 있고, “Knife”의 위치는 “Hand”로 이동 되어져 ‘손에 칼을 쥐고 있는 상태’를 표현하게 됩니다. 즉, 연속적인 행위들을 수행하면서 환경의 상태 정보를 효율적인 표현하기 위한 표현 도구라고 보시면 됩니다.
Task graph는 다중의 functional units의 결합으로 구성되며, 각 object node는 액션 전후에 필요한 객체 상태를 모두 나타내므로, 단계 별로 행동에 대한 객체 상태 조건이 충족되었는지 확인 가능하게 됩니다. 이러한 특성은 LLM으로 생성된 cooking task planning에 대한 feasibility checks를 수행하는 데에 있어 logical soundness를 보장합니다.
1) Environment object nodes and Target object nodes
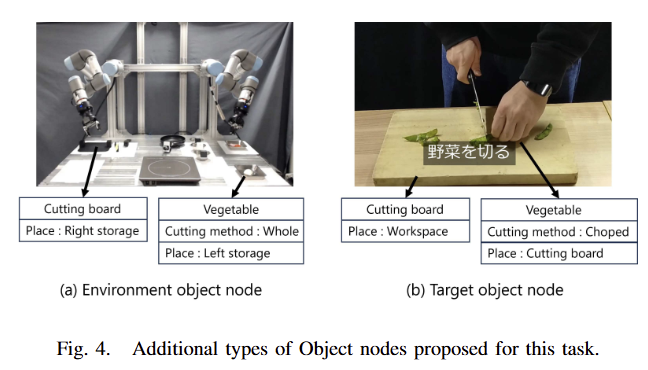
저자는 기존 object node에 추가적으로 fig 4와 같이 environment object nodes와 Target object nodes를 제안합니다. 먼저, Environment object node는 로봇의 local execution environment의 state를 나타냅니다. object placement와 같이 추가 속성 정보를 주어진 환경과 연관 시켜 나타냅니다. (e.g. ”Cutting board” is in the ”Right storage”, which is a predefined region of the local environment) 또한, 재료의 요리 상태를 나타냅니다. Target object nodes는 video frames에서 관측된 모든 객체의 state를 표현합니다. 해당 노드에서도 Environment object node와 동일한 속성을 추가합니다.
2) Functional unit with variables
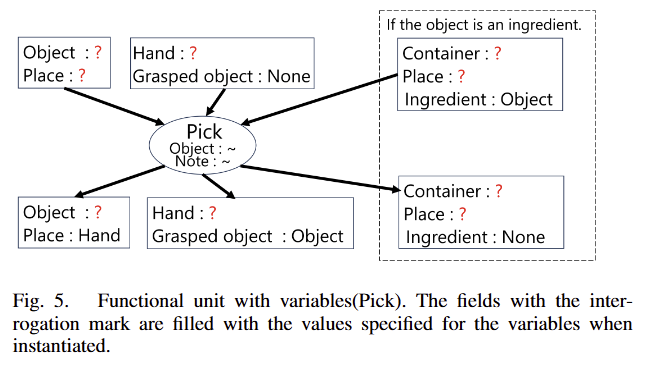
저자는 [1]에서 제안한 functional unit with variables를 이용한다고 합니다. 복잡한 내용은 아니고… 정의된 functional unit을 재사용하기 위해서 fig 5에서 객체의 속성들을 변수로 다루는 것을 의미하며, prompt engineering으로 정해진 motion “Pick”이 요구하는 템플릿은 고정하되, ?로 구성된 요소들은 변경하도록 한다는 이야기로 이해하시면 됩니다.
Video Pre-processing
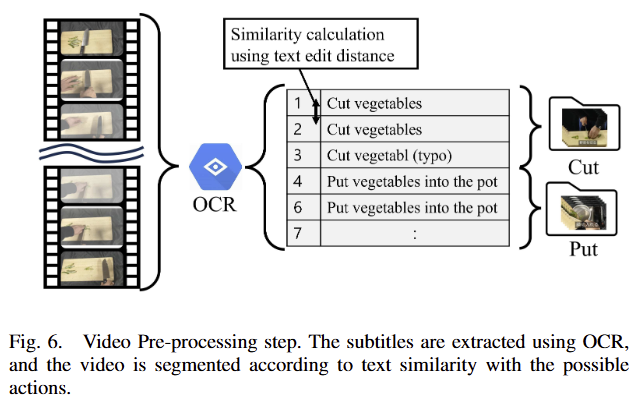
Cooking video들은 비디오 형태이기에 LLM에 입력하기 적절하지 못합니다. 저자는 이를 고려하여 fig 6과 같은 트릭을 제시합니다. 먼저, 비디오로부터 OCR*을 이용하여 자막을 추출하고 이를 기반으로 video의 key frames을 추출하고, segmenting scenes을 수행합니다. 대응되는 key frames는 3×3 grid로 재구성되어져 LLM에 입력 영상으로 활용됩니다.
+ *OCR을 어떤 기법을 활용했는지 확인이 안됩니다.
Graph Generation
해당 섹션에서는 preprocessed viedo images으로부터 task graph를 생성하는 방법을 설명합니다.
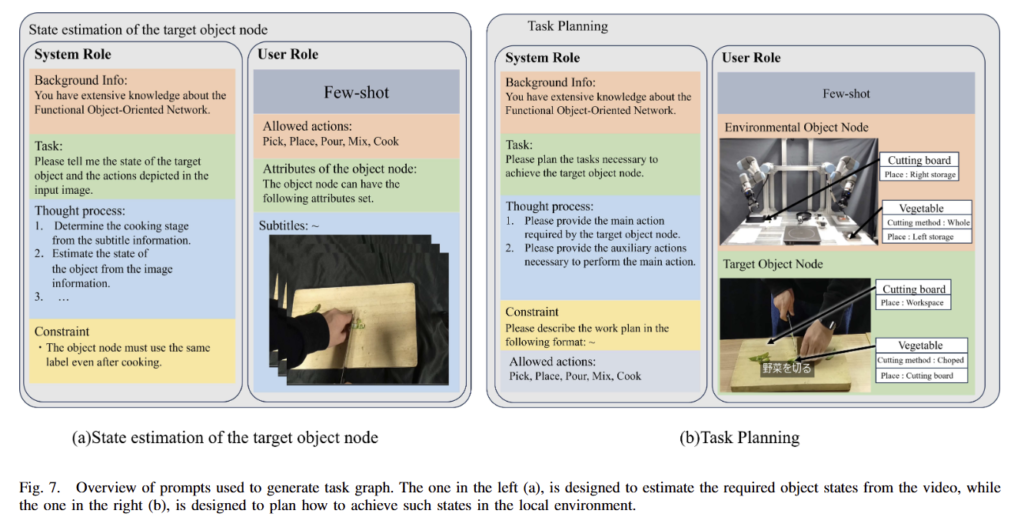
1) Estimation of Target Object Node: cooking task plan을 수행하기 위해서는 재료와 같은 object의 state를 정확하게 정의하는 것은 cooking actions에 큰 영향을 줄 수 있기에 굉장히 중요합니다. 저자는 이를 소화하기 위해서 Target Object Node에 대한 prompting (background information, task description, thought process, constraints, allowed actions, attribute, subtitles과 추출한 key frames)을 수행합니다. 해당 프롬프팅 정보는 fig 7-(a)에서 확인 가능합니다. 저자는 응답 정확도를 높이기 위해서 “System”-“User” role-playing 기법을 이용하며, FOON에 대한 배경 지식을 제공합니다. 먼저, system role에서는 전체 task information, 원하는 format과 reasoning process이 제시됩니다. … thought process는 CoT를 활용하고 Constraints으로 executable graph in Python로 제시한다고 합니다. 다음으로 user role에서도 prompting (possible robot actions, the object node attributes, such as position and cooking state, and the subtitles and key frames of the video)을 부여합니다. user role에서는 원하는 형태를 따르는 값을 얻기 위해서 target object node와 motion node에 대한 예시가 작성된 few-shot prompting을 이용해 가이드를 줍니다. 또한, 최종 결과물이 JSON format을 따르도록 합니다.
2) Action Estimation: Cooking task를 성공적으로 이뤄내려면, 추정된 target object node의 state를 따르는 일련의 로봇 액션을 정의해야 합니다. 비디오로부터 정의된 target object node와 비교하기 위한 새로운 LLM agent를 이용해 local environment에서의 object state 추론해 비교를 진행합니다. 해당 기법도 1) Estimation of Target Object Node과 유사한 구조를 따릅니다. 자세한 내용은 fig 7-(b)를 참조하시길 바랍니다. 다른 점은 System role에서는 사전에 정의된 로봇 모션 중 가능한 가능한 액션 Allowed actions이 추가됩니다. 출력물은 environment object node의 초기 state를 생성하는 것을 목적으로 합니다.. User role에서는 JSON format인 추정된 environment object node와 target object node가 제공되어집니다. 출력물로 environment object node의 액션을 정의하고 액션 이후 상태를 생성합니다. 해당 LLM agent의 출력값은 environment object node를 생성하는 것을 목적으로 합니다.
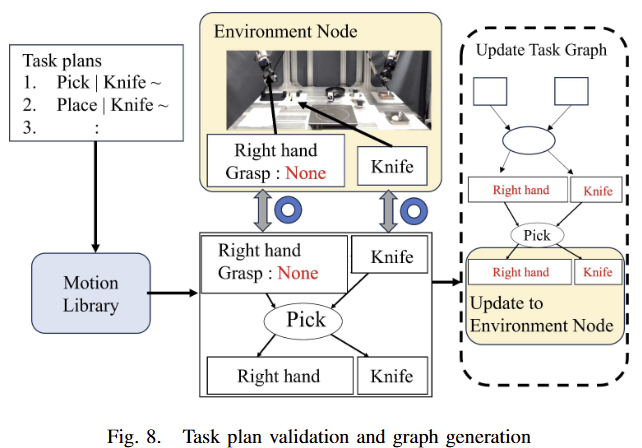
3) Task validation and graph generation: 예측된 Motion node를 task graph에 추가하기 전에 검증을 수행해야 합니다. 전반적인 구조는 fig 8에서 확인 가능합니다. 검증 방법은 매우 간단합니다. functional unit은 환경에 비 종속적이기에 각 스텝 별로 평가가 가능합니다. 이러한 점을 이용하여 environment object node와 target object node의 state를 비교합니다. 만약 state가 일치한다면 feasible하다고 판단하고 불 일치한다면 infeasible하다고 판단하여 re-planning을 수행하도록 합니다.
4) Re-planning: 3)에서 매칭이 실패한 정보를 LLM에게 다시 제공하여 re-planning을 수행합니다. 해당 프로세스는 모든 task plans이 feasible하다고 판단되어질 때까지 반복합니다.
Motion Planning
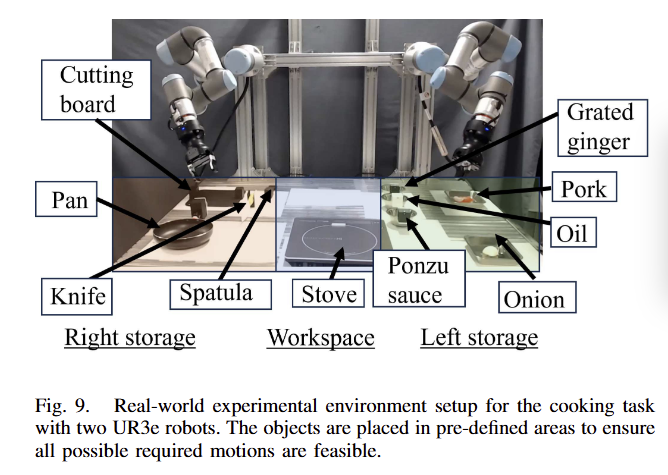
우선 해당 논문은 cooking video를 활용하여 robot task planning을 목적으로 하기 때문에 객체의 위치, 파지법 등과 같은 정보를 고려하지 않고 진행됩니다. 즉, 실제 로봇 환경 내의 object의 state는 fig 9와 같이 사전에 정의된 상태에서 진행되어집니다. motion은 RRT-Connect와 linear trajectory planning을 이용합니다.
Experiment
해당 기법에서는 평가를 위해 1분 이내의 유튜브 shorts에서 자막이 있는 10 cooking videos를 선정하여 평가를 진행합니다. 해당 비디오에는 “cutting”, “mixing”, “heating”. “pouring”과 같은 cooking action 포함하고 있습니다. 실제 로봇에서의 평가는 10개 중 5개를 선정하여 평가를 진행합니다
1) Video Pre-processing
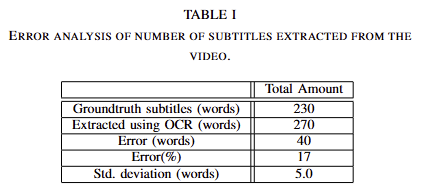
해당 방법에서는 key-frames을 선정에 대한 평가를 진행합니다. tab 1을 보면 error 17%가 발생했습니다. 이는 OCR이 중복된 자막을 생성하여 GT를 초과된 예측을 수행한 결과로, 저자는 이를…. LLM이 해결 가능하다고 합니다.
2) Target Object Node Estimation
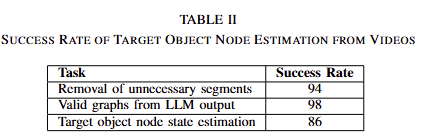
앞선 1) Video Pre-processing을 통해서 276장의 key-frames을 구성해 평가를 진행합니다. 해당 영상 중 134장은 요리 방법과 직접적으로 상관 없는 영상으로 대체로 소개 영상 혹은 중복된 영상으로 구성됩니다. 해당 실험 결과인 tab 2의 1열을 확인해보면 LLM이 영상 구성의 노이즈에 영향을 크게 받지 않고 적절한 재구성을 수행하는 결과를 보여줍니다. tab 2의 2열은 graph representation에 대한 평가 결과로, 98%의 높은 결과를 보여줍니다. 해당 결과의 실패 케이스는 “Dish”라는 정의되지 않은 케이스가 등장했다고 합니다. 이는 few-shot이 모든 표현을 담는데 부족했기 때문에 발생했다고 주장하네요. 마지막 3열은 86%을 달성했으며, 이에 대한 이유를 2가지를 정리합니다. (1) 사전 정의된 액션을 벗어나는 경우, (2) object naming이 다양한 표현…
3) Generation of Task-sequence graph
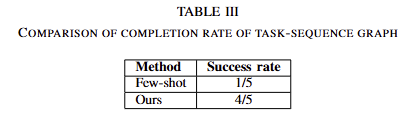
마지막으로 전체 task를 생성한 결과에 해당합니다. 실제 로봇 (bi-ur5)에서의 평가 결과로, 베이스라인으로 few-shot prompting을 수행한 LLM을 비교합니다. 베이스라인은 1개의 케이스에서만 성공한 것에 반해 저자가 제안한 베이스라인은 hallucination을 극복하고 4개의 케이스에서 성공하는 결과를 보여줍니다. fig 10-D에서는 비디오에서 설명이 빠진 양파 썰기를 적응적으로 수행한 결과를 보여줍니다. 정석적인 결과는 하단 fig 10에서 확인 가능합니다.

흠… 해당 논문이 나아가는 방향이 틀린 방법은 아니라고 생각합니다만… 제시한 프레임워크들이 신규성과 창의성을 인정 받기에는 부족함이 느껴지는 논문 같습니다. (인공지능과 비전을 전공한 사람이라서 로봇 환경 정보를 추론을 안해서 비관적 평을 부여했지만… 순수 로보틱스에서는 다른 평을 할 수도 있습니다) 또한, tab 3에서 few-shot prompting을 적용해도 1개의 케이스에서 성공한다는 것을 보면… LLM의 task planning 능력이 생각보다 뛰어난 것 같습니다. 추후 연구에서는 해당 논문의 실험 결과를 베이스로 빠르게 쌓아 올려봐야겠습니다.
좋은 리뷰 감사합니다.
환경에 비의존적인 task planning을 통해 요리 영상으로부터 cooking 작업을 수행할 수 있는 LLM과 FOON이 통합된 프레임워크를 제안한 것으로 이해하였습니다.
이전 상태와 액션 이후의 상태가 주어졌을 때, “pick”이라는 행동을 수행해야한다는 것을 인지하는 방법에 집중한 것으로 이해하였습니다. 물체의 위치, 파지법 등과 같은 정보를 고려하지 않는다고 하셨는데, 따지면 해당 논문은 affordance와 같은 정보를 추정하는 과정이 필요하지 않을까 합니다.
하나의 완성된 프레임 워크를 위한 개선이 이루어지면 좋을 것 같은데, 해당 논문을 적용해보실 생각이 있으신지 궁금합니다.
Q1?. 이전 상태와 액션 이후의 상태가 주어졌을 때, “pick”이라는 행동을 수행해야한다는 것을 인지하는 방법에 집중한 것으로 이해하였습니다. 물체의 위치, 파지법 등과 같은 정보를 고려하지 않는다고 하셨는데, 따지면 해당 논문은 affordance와 같은 정보를 추정하는 과정이 필요하지 않을까 합니다.
A1. 넵 제 생각에도 인지 모델이 추가적으로 붙으면 더 좋은 방법론이 될 것이라고 생각합니다. 추후 연구에서는 해당 기법을 기반으로 저희가 가진 인지 모델 기술들을 붙이는 방향도 고려하고 있습니다.
Q2. 하나의 완성된 프레임 워크를 위한 개선이 이루어지면 좋을 것 같은데, 해당 논문을 적용해보실 생각이 있으신지 궁금합니다.
A2. 넵 있습니다.
안녕하세요 태주님, 좋은 리뷰 감사합니다.
video 내의 key-frame 인풋과 prompting 기법을 사용하여 LLM으로부터 task planning을 수행토록 하고, 이 와중에 FOON이라는 task graph 구조를 활용하면서 LLM task planning으로 나온 결과를 잘 써먹기 위해 validation – generation – replanning 하여 최종적으로 요리작업을 수행할 수 있는 것이라고 이해했습니다.
질문이 2가지 있습니다!
1. LLM에 input prompting 으로 넣을 video의 key frames을 추출할 때, OCR기반의 자막 추출이 활용된다고 하셨는데, OCR로 자막추출 이후 segmenting scene 은 어떻게 이뤄지는 지 궁금하고, 제가 생각했을 땐 해당 과정이 저희 연구실의 비디오 팀의 연구주제인 video retrieval과도 관련이 있는 유사한 내용인 것 같다고 이해했는데 이해한 게 맞을까요?
2. Task validation – graph generation – re-planning 과정에서 결국 feasible 판단이 실패하면 feasible이 될 때까지 계속 LLM Prompting을 수행해야되는 것으로 이해했는데, 해당 방식으로 hallucination을 극복한다고 해도 그만큼 gpt api에 대한 cost나 작업 수행에 대한 time cost가 꽤나 늘어날 것으로 생각이 들었습니다. 또한 이것과 관련해서 table1에서의 내용처럼 video key-frames에 대한 error나 노이즈 frame이 조금 있어도 table2의 success rate가 굉장히 높게 나온 모습을 보인 것을 보면, 저는 이것이 feasible이 나올 때까지 계속 task validation 돌리고 re-planning 돌리는 과정을 거쳐서 나오게 된 것이 아닐까.. 하는 우려가 생깁니다. 논문 상에서 task validation과 re-planning에 대한 ablation study는 따로 없어보였는데,, task validation과 re-planning은 보통 몇 회 수행될지, 혹은 그것들의 중요성이 컸는지에 관한 저자들의 분석은 없었는지 궁금합니다!
Q1. LLM에 input prompting 으로 넣을 video의 key frames을 추출할 때, OCR기반의 자막 추출이 활용된다고 하셨는데, OCR로 자막추출 이후 segmenting scene 은 어떻게 이뤄지는 지 궁금하고, 제가 생각했을 땐 해당 과정이 저희 연구실의 비디오 팀의 연구주제인 video retrieval과도 관련이 있는 유사한 내용인 것 같다고 이해했는데 이해한 게 맞을까요?
A1. 오~ 저도 비디오팀 연구들을 활용 가능한 구조를 가지고 있다고 생각했습니다. 실제로도 금일 오후에 주영님에게 해당 논문에 대해서 이야기 드리며 같이 연구해보는 것이 어떻냐는 제안을 드리긴 했습니다.
Q2-1. Task validation – graph generation – re-planning 과정에서 결국 feasible 판단이 실패하면 feasible이 될 때까지 계속 LLM Prompting을 수행해야되는 것으로 이해했는데, 해당 방식으로 hallucination을 극복한다고 해도 그만큼 gpt api에 대한 cost나 작업 수행에 대한 time cost가 꽤나 늘어날 것으로 생각이 들었습니다.
A2-1. 말씀하신 바와 같이 time cost가 높을 것으로 예상됩니다만… 최근 연구 수준으로는 시간까지 크게 고려하진 않고 ‘일단 되고 보자’가 주된 것 같습니다.
Q2-2. 또한 이것과 관련해서 table1에서의 내용처럼 video key-frames에 대한 error나 노이즈 frame이 조금 있어도 table2의 success rate가 굉장히 높게 나온 모습을 보인 것을 보면, 저는 이것이 feasible이 나올 때까지 계속 task validation 돌리고 re-planning 돌리는 과정을 거쳐서 나오게 된 것이 아닐까.. 하는 우려가 생깁니다. 논문 상에서 task validation과 re-planning에 대한 ablation study는 따로 없어보였는데,, task validation과 re-planning은 보통 몇 회 수행될지, 혹은 그것들의 중요성이 컸는지에 관한 저자들의 분석은 없었는지 궁금합니다!
A2-2. 재찬님이 궁금해 하시는 분석 내용은 아쉽게도 작성되어 있지 않습니다. 해당 논문이 아직 완성본이 아닌 것 같습니다. 아마 리비전을 걸치면서 논문 내용이 보완될 것이라고 생각합니다. 그때 재찬님이 궁금해하시는 부분도 추가되지 않을까 싶습니다.