제가 이번에 리뷰할 논문은 CVPR 2024에 공개된 segmentation 분야의 continual learning 관련 논문입니다. 제가 주로 담당하고 있는 산자부 미학습 물체 파지 과제도 새로운 대상에 대하여 확장이 가능하도록 하는 연구 내용을 담고 있어, 해당 논문을 리뷰하게 되었습니다.
Abstract
대부분의 continual segmentation은 문제를 픽셀별 classification 문제로 간주하였습니다. 그러나 이러한 방식에는 어려움이 있으며, 해당 논문의 저자들은 objectness가 내장된 query 기반의 segmentation 방식이 강력한 transfer 능력과 forgetting(class가 추가됨에 따라 이전에 학습한 class를 잊어버리는 문제)에 저항성이 있다는 점을 확인하였습니다. 따라서 저자들은 (1)forgetting-resistant continual objectness learning과 (2)well-researched continual classification 두 단계로 이루어진 새로운 프레임워크 CoMasTRe를 제안하였습니다. 첫 번째 단계에서 클래스와 무관하게 객체에 대한 mask를 제안하고, 이후 두 번째 단계에서 이를 식별합니다. continual learning과정에는 단순하고 효과적인 distillation 방식을 적용하여 objectness를 강화합니다. 또한, forgetting을 완화하기 위해 segmentation에 적절한 multi-label class distillation 전략을 설계합니다. 해당 논문은 PASCAL VOC와 ADE20K에 대해 실험을 통해 기존 방식보다 우수한 성능을 달성하였습니다.
—
Query-based Segmentation?
Query-based segmentation은 mask classification을 통해 이미지 분할 문제를 통합하고, semantic, instance, panoptic segmentation을 하나의 프레임워크로 해결하였습니다. mask classification 패러다임은 DETR과 같은 query기반 detector에서 유래되었으며, 학습 가능한 query를 통해 객체 proposal과 class label을 예측하도록 모델을 학습시킵니다. MaskFormer는 최초로 semantic segmentation에서 지배적인 픽셀 수준의 classification 패러다임에 mask classification을 도입했습니다. 이후 Mask2Former는 mask refinement를 위한 masked attention, 작은 객체 인식 성능을 높이기 위한 multi-scale feature 사용을 제안하여 MaskFormer를 개선한 방식을 제안하였습니다. kMaX-DeepLab은 클러스터링된 이미지 feature에서 query를 생성하는 방식을 통해 학습 수렴 속도를 향상시켰으며, OneFormer는 모든 segmentation task를 공동으로 학습할 수 있는 범용적인 솔루션을 제안하였습니다. 그러나 이런한 기존 query기반 segmentation 방식들은 마스크와 클래스를 동시에 예측하도록 학습하므로, continual segmentation에는 적합하지 않았다고 합니다.
—
Introduction
기존의 신경망 기반 Computer Vision 연구들은 대부분 완전하게 주석된(fully annotated) 데이터를 활용한 single-shot learning 방식(한 번의 학습 이후 추가 학습을 고려하지 않는 방식)으로 진행되어 왔습니다. 이에 반해, Continual Learning은 점진적으로 지식을 습득하는 인간의 학습 방식을 모사하는 것을 목표로 하며, 주석 작업에 많은 비용이 소요되는 semantic segmentation과 같은 dense prediction이나, 개인정보 문제로 인해 데이터 수집이 어려운 의료 영상 분야 등에서 주목 받고 있습니다.
그러나, continual learning은 학습을 지속함에 따라 이전에 학습한 대상에 대하여 잊어버리는 catastrophic forgetting 문제가 존재하며, 이는 해당 분야에서 중요한 문제입니다. 특히, 픽셀의 주변 패턴을 분석하여 픽셀 수준의 classification이나 regression을 수행하는 dense prediction은 태스크 자체로 어려운 문제이므로, 이러한 분야에 continual learning을 적용하는 것은 더욱 어렵습니다. 따라서 저자들은 continual learning에서 forgetting 문제를 실현 가능한 방식으로 완화하기 위한 방식을 고민하였고, mask classification에 새로운 방식을 제안합니다. query 기반의 segmentation 방식을 기반으로 하며, 클래스와 무관한 이진 mask를 생성한 뒤, 클래스를 인식하는 두 단계를 거쳐, 이전 클래스에 대한 지식을 잊지 않고 학습할 수 있는 구조를 제안합니다.

기존의 픽셀 수준의 classification 방식과 달리, query 기반의 방식은 이미지에서 객체를 찾는 능력인 objectness 능력이 내장되어있어 continual segmentation에 유리합니다. 먼저, mask를 제안하는 과정을 학습할 때 background를 포함하므로, objectness 를 unseen class로 전달할 수 있습니다. 위의 Figure1-(a)는 픽셀 수준의 classification을 수행하는 DeepLabv3과 query기반의 방식인 Mask2Former를 비교한 결과로, learned classes에 있는 유사한 class가 있는 경우 Mask2Former가 unseen classes에 대해 더 좋은 mask를 생성하는 것을 확인할 수 있습니다. 또한, query 기반의 모델은새로운 class에 대해 fine-tuning을 수행하더라도 이전 class에 대한 mask생성 능력을 쥬지할 수 있어, forgetting 문제를 완화하는 데 도움이 됩니다. 위의 Figure1-(b)는 이를 보여주는 결과로, 1열은 1~15까지는 table과 people에 대한 class를 학습한 결과이고 2열은 이후 plant와 TV를 추가 학습하였을 때의 실험 결과로, DeepLabv3은 이전에 학습한 class에 대해 잊어버리지만 query 기반 방식인 Mask2Former는 성능은 저하되었지만, 기존 class에 대해서도 여전히 예측이 이루어지는 것을 확인할 수 있습니다.
저자들은 이러한 발견을 기반으로 CoMasTRe(Continual Learning with Mask-Then-Recognize Transformer decoder)라는 새로운 프레임워크를 제안합니다. CoMasTRe는 continual segmentation을 클래스에 무관하게 객체를 인식하는 objectness learning과 class recognition으로 분리함으로써, 보다 단순하고 효과적인 방식으로 학습할 수 있도록 설계하였습니다. 이때, CoMasTRe는 query 기반 segmentation 방식이 내포하고 있는 objectness의 일반화 능력을 계승하고 있어, 새로운 마스크를 제안하는 과정이 용이하며, continual setting에 적합합니다. 또한, CoMasTRe는 forgetting 문제를 완화하기 위해 (1) 장기 학습에도 기존 클래스의 objectness를 보존할 수 있도록 단순하고 효과적인 objectness distillation을 적용하고, (2) task-specific 분류기에 multi-label class distillation 전략을 적용합니다.
저자들은 PASCAL VOC 2012와 ADE20K 데이터셋에 대한 실험을 통해 SOTA를 달성하였음을 입증하였습니다. 특히, VOC 데이터셋에서는 추가된 class에서 성능이 개선되었고, ADE20K에 대해서는 모든 class에 대한 성능이 크게 개선됨을 보였습니다.
해당 논문의 contribution을 정리하면,
- continual segmentation을 objectness learning과 class recognition으로 단순화하여 분리하는 CoMasTRe 제안
- forgetting 문제를 완화하기 위한 2가지 전략 제안
- PASCAL VOC와 ADE20K에 대해 SOTA 달성
Method
0. Problem Definition
데이터 셋 \mathcal{D}는 이미지 x \in \mathbb{R}^{C⨉H⨉W}와 M개의 target y = \{(m_i^{gt},c_i^{gt})\}^M_{i=1} 쌍으로 이루어지며, 각 target은 이진 마스크 m_i^{gt} \in \{0,1\}^{H⨉W}와 정답 클래스 c_i^{gt} \in \mathcal{C}로 이루어집니다. 여기서 C는 클래스를 의미하며, continual segmentation에서는 학습 과정을 T개의 task로 분한하고 각 step t=1,2,...,T마다 \mathcal{C}^t가 되도록 데이터 셋을 구축하고, 이때 모든 step의 \mathcal{C}^t의 합집합은 \mathcal{C}가 되고, 교집합은 \varnothing가 되도록 합니다. step t에서만 새로운 class 집합 \mathcal{C}^t가 주어지며, 모델 예측에는 이전 class까지 모두 포함한 \mathcal{C}^{1:t}를 고려합니다.
1. CoMasTRe Architecture
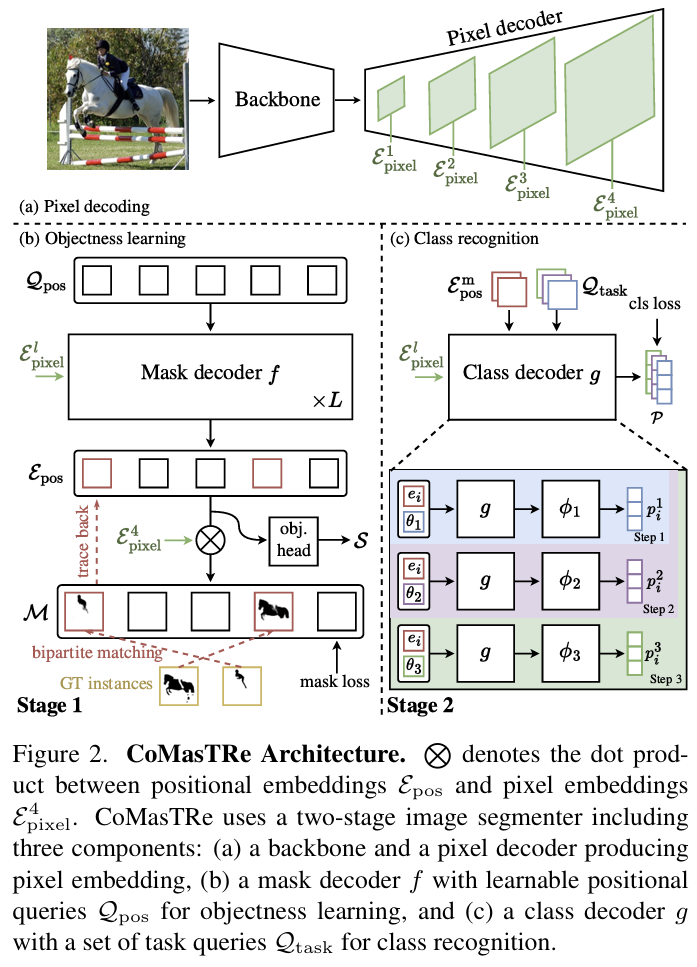
CoMasTRe는 Mask2Former를 기반으로 하여 백본과 pixel decoder 구조를 이용하며, 여기에 추가로 2개의 transformer decoders를 추가하여 objectness learinng(stage1)과 class recognition(stage2)를 분리합니다. 이러한 구조는 위의 Figure 2를 통해 확인하실 수 있으며, 전체적인 학습 과정은 다음과 같습니다.
- 이미지를 백본을 통과시키고 pixel decoder를 통과시켜 4개의 layer에서 pixel embeddings \{\varepsilon ^l_{pixel}\}^4_{l=1}를 추출합니다.
- 학습 가능한 positional queries \mathcal{Q}_{pos}를 임의의 값으로 초기화 한 뒤, objectness learning 단계인 stage 1에 입력하여 mask decoder f를 통과시켜 positional embeddings \varepsilon _{pos}를 추출하여, 클래스에 무관한 mask proposals \mathcal{M}과 object scores \mathcal{S}를 구합니다. 학습에는 GT와 대응되는 하나의 proposal만 매칭시키는 bipartite matching을 포함합니다.(Figure 2-(b))
- 매칭된 propositional embeddings \varepsilon^m_{pos}와 pixel embeddings는 stage 2의 class decoder g에 입력으로 들어갑니다. task query \mathcal{Q}_{task}와, task에 특화된 classifiers \phi_1, .., \phi_t는 task별로 학습됩니다. (Figure2-(c))
- 마지막으로 stage 1의 mask proposals와 objectness score를 stage 2의 class에 대한 예측 결과와 결합하여 최종적인 segmentation 결과를 얻게 됩니다.
Stage 1: Objectness Learning
objectness learning은 mask decoder f를 통해 수행됩니다. mask decoder는 L개의 트랜스포머 블록으로 구성되며, N개의 학습 가능한 positional queries \mathcal{Q}_{pos}=\{q_1, .. ,q_N\} \in \mathbb{R}^{N⨉d}와 중간의 pixel embeddings \{\varepsilon ^l_{pixel}\}^3_{l=1}를 입력으로 사용합니다. mask decoder는 positional embeddings \varepsilon_{pos} = \{e_1, ... , e_N\} \in \mathbb{R}^{N⨉d}를 출력하며, 이는 mask proposal과 objectness score, stage 2에서 사용됩니다. mask proposal \mathcal{M} = \{m_1, ... , m_N\} \in [0,1]^{N⨉H⨉W}은 MLP와 Upsampling을 통해 원본 이미지 크기에 대한 예측값으로 생성되고, 해당 mask proposal이 객체일 지에 대한 점수를 의미하는 objectness score \mathcal{S} = \{ s_1, ..., s_N\} \in [0,1]^N는 objectness head를 통해 구하게 됩니다.
학습 과정에서는 N개의 mask proposals \{m_i\}^N_{i=1}과 M개의 GT mask \{m_i^{gt}\}^N_{i=1}사이의 비용을 고려하여 bipartite matching을 수행합니다. 이때 N ≫ M라는 점을 고려하여 GT에 “no object” \varnothing를 채워 넣어 일대일 대응이 가능하도록 합니다. 매칭은 헝가리안 알고리즘을 이용하고, 이를 통해 N개의 예측값에 대한 최적의 순열 \sigma를 구하고, 이를 기반으로 아래의 loss 수식을 계산하여 학습을 수행합니다.
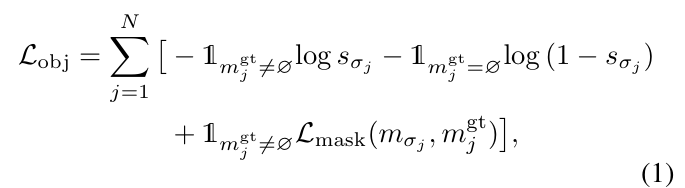
- \mathcal{L}_{mask}: 이진마스크에 대한 binary cross-entropy loss와 Dice loss의 합
이후 M개의 GT mask와 매칭이 이루어진 M개의 positional embeddings는 stage 2의 class recognition으로 전달되고, 매칭이 이루어진 proposal의 objectness score가 높아지고 나머지는 objectness score가 높아지도록 학습을 수행합니다. 이때 매칭이 이루어지지지 않은 나머지 positianl embedings는 \varepsilon^u_{pos}라 표시하고, 이후에 forgetting을 완화하기 위한 distillation 과정에 이용합니다.
Stage 2: Class Recognition
stage 2는 매칭이 이루어진 mask proposals에 대하여 클래스를 인식하는 과정으로, 앞서 pixel decoder에서 구한 pixel embeddings를 함께 입력으로 이용합니다. T step동안 별도의 classifier를 이용하여(task-specific classifier라 합니다) 이전 task의 간섭이 줄어들 수 있도록 합니다.
먼저 step t에서 task queries \mathcal{Q}_{task}= \{\theta_1, ..., \theta_t\}와 매칭된 mask proposals를 class decoder g에 입력하여 task embedding k를 얻습니다. 여기서 class decoder는 task들에 대하여 파라미터가 공유된다고 합니다. 각 positional embedding에 대하여 task embeddings \varepsilon_{task}=\{k_1,..,k_t\}가 생성되고, task별로 classifier \phi_j \in j=1, ... ,t를 이용하여 각 mask proposal에 대하여 task별 class probability p=sigmoid([\phi_1(k_1), ..., \phi_t(k_t)])를 구합니다. 이후 GT 라벨과 비교하여 아래의 식을 통해 학습을 수행합니다.
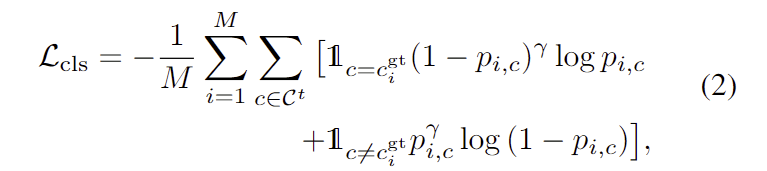
- p_{i,c}: i번째 proposal이 c 클래스에 해당할 확률
- \gamma: 하이퍼파라미터
최종적인 total loss는 objectness loss와 classification loss를 합한 \mathcal{L}_{seg}=\mathcal{L}_{obj}+\mathcal{L}_{cls}로, 두 stage를 함께 학습하게 됩니다. inference시에는 score가 낮은 예측값을 거르기 위해 stage 1에 대하여 임계값을 설정하여 objectness score가 일정 수준 이상인 경우만 stage 2로 넘어가도록 합니다.
2. Learning without forgetting with CoMasTRe
해당 논문의 저자들은 continual learning 과정에서 이전에 학습한 class에 대한 정보를 잊어버리는 forgetting 문제를 해결하고자 하였고, 이를 위해 2가지 distillation 방식을 도입하였습니다. 각 방식에 대해 살펴보겠습니다.
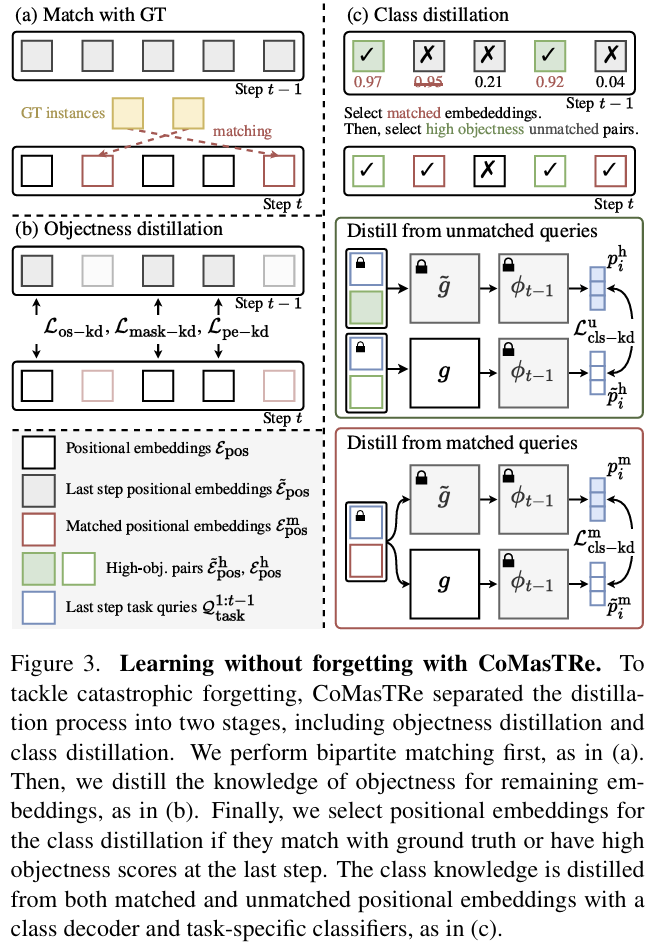
Objectness Distillation
먼저 모델을 학습할 때는 bipartite matching을 통해 GT에 대응되는 positional embeddings를 이용합니다. 그러나 task별로 포함되는 class가 달라지므로, 이전 class에 속하는 경우에는 objectness score가 낮아지도록 학습이 이루어집니다. 따라서 이전 task의 class를 잊어버리는 문제가 발생하므로, 저자들은 이를 보존하기 위해 mask proposal과 positional embeddings에 대한 2개의 distillation losses \mathcal{L}_{mask-kd}와 \mathcal{L}_{pe-kd}를 제안합니다.
먼저, 매칭이 이루어지지 않은 mask proposals \mathcal{M}^u = \{m^u_1, ...,m^u_{N-M} \}과 그에 대한 objectness scores \mathcal{S}^u = \{s^u_1, ...,s^u_{N-M} \}로부터 추출된 positional embeddings \varepsilon^u_{pos} = \{e^u_1, ...,e^u_{N-M} \}이 있을 때, 각각에 대응되는 이전 step 모델의 output들(\tilde{\mathcal{M}}^u = \{\tilde{m}^u_1, ...,\tilde{m}^u_{N-M} \}, \tilde{\mathcal{S}}^u = \{\tilde{s}^u_1, ...,\tilde{s}^u_{N-M} \}, \tilde{\varepsilon}^u_{pose} = \{\tilde{e}^u_1, ...,\tilde{e}^u_{N-M} \})이 필요합니다.
- Distill objectness scores
- 해당 loss는 obejct일 확률을 의미하므로, 이전 task에서도 동일하게 유지되어야 합니다. 따라서 저자들은 기존 연구에서 사용되던 knowledge distillation loss를 그대로 사용하였습니다.
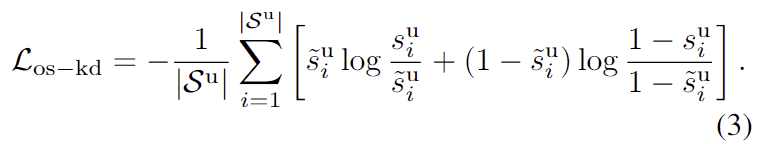
- Distill mask proposals
- mask proposal에 대한 지식을 유지하며 높은 objectness score를 가진 proposal에 집중하기 위해, mask distillation의 가중치를 조정합니다. 이때, 일부 mask proposal은 unseen class에 해당하지만 objectness score가 낮은 경우가 있으므로, 이러한 경우도 학습이 될 수 있도록 가중치를 조정하여 distillation이 이루어지도록 합니다. 이러한 mask distillation loss는 아래의 식으로 정의되며, 여기서 w_i = (\tilde{s}^u_i)^\beta는 하이퍼파라미터 \beta로 조정된 가중치를 의미합니다.
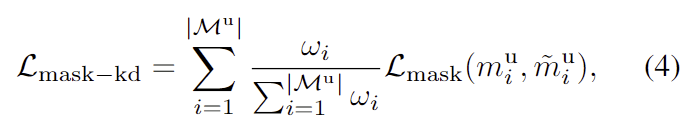
- Distill positional embeddings
- positional embeddings \varepsilon^u_{pos}도 mask distillation loss와 유사하게 가중치를 조정하며, 추가로 현재 step t의 embeddings와 이전 step t-1의 embeddings 사이의 코사인 유사도(cos(\cdot))를 이용하도록 loss를 설계하였습니다.
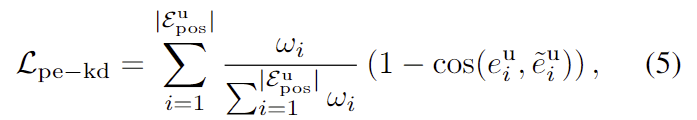
최종적으로 objectness에 대한 distillation은 위의 3가지 loss를 합한 \mathcal{L}_{obj-kd} = \mathcal{L}_{os-kd}+ \mathcal{L}_{mask-kd}+ \mathcal{L}_{pe-kd}로 정의됩니다.
Class Distillation
stage 2는 본질적으로 continual mutli-label classification이며, class distillation에서 2가지 시나리오를 고려합니다.
1. 아직 GT와 매칭되지 않은 높은 objectness score를 가진 embeddings에서 예측 class를 전이하기
이전 step에서 매칭되지 않은 embeddings \tilde{\varepsilon}^u_{pos}에 대하여 임계치 \alpha 이상의 objectness score를 갖는 n개의 embeddings \tilde{\varepsilon}^h_{pos}를 선택합니다. 이에 대응되는 현재 step에서의 embeddings \varepsilon^h_{pos}를 찾은 뒤 class decoder를 통과시켜 \{\tilde{z}^h_i\}^n_{i=1}과 \{z^h_i\}^n_{i=1}를 구한 뒤, softmax를 적용하여 \tilde{p}^h_i와 p^h_i를 구한 뒤, KL divergence를 이용하여 distillation을 수행합니다. 이에 대한 knowledge distillation loss 식은 다음과 같습니다.
\mathcal{L}_{cls-kd}^u = {1 \over n} \Sigma ^n_{i=1} D_{KL} (p^h_i||\tilde{p}^h_i)
D_{KL}(p^h_i||\tilde{p}^h_i) = \Sigma \ p^h_i \ log({{p^h_i}\over{\tilde{p}^h_i}})
- 2. 매칭된 embeddings에서 class 지식 전이하기
- 이전에 매칭된 class에 대한 지식을 사전지식으로 간주하여 이후 step에도 계속하여 전이하기 위한 loss를 설계합니다. 매칭된 embeddings \varepsilon^m_{pos}에 대한 class 확률 분포가\{p^m_i\}^M_{i=1}이 이전 step에서의 class 확률 \{\tilde{p}^m_i\}^M_{i=1} 분포를 따르도록 matched class distillation loss 식을 정의하며, 이를 통해 이전 class에 대한 정보를 전이합니다.
\mathcal{L}_{cls-kd}^m = {1 \over M} \Sigma ^M_{i=1} D_{KL} (p^m_i||\tilde{p}^m_i)
D_{KL}(p^m_i||\tilde{p}^m_i) = \Sigma \ p^m_i \ log({{p^m_i}\over{\tilde{p}^m_i}})
최종적으로 class에 대한 지식을 전이하기 위한 loss는 \mathcal{L}_{cls-kd} = \mathcal{L}^u_{cls-kd}+ \mathcal{L}^m_{cls-kd}로 정의되며 추가로 old class와 new classes에 대하여 1+|C^t|를 예측하여 \mathcal{L}_{cls-aux}를 추가합니다.
CoMasTRe에서 학습에 사용되는 total loss는 \mathcal{L} = \mathcal{L}_{seg}+\mathcal{L}_{obj-kd} + \mathcal{L}_{cls-kd} + \mathcal{L}_{cls-aux}로 정의됩니다.
Experiments
CoMasTRe는 semantic segmentation 성능을 평가하기 위해 continual segmentation 연구에서 많이 사용되는 PASCAL VOC 2012 데이터셋과 ADE20K 데이터셋을 사용하였습니다. PASCAL VOC 2012는 20개의 객체 클래스와 배경 클래스로 구성되고, 학습과 평가에는 각각 10,582개와 1,449개의 샘플이 사용되었습니다. ADE20K는 150개의 annotation된 클래스로 구성된 대규모 semantic segmentation 데이터셋으로, 학습과 평가에 각각 20,210개와 2,000개의 샘플이 사용되었습니다.
실험 결과에서 B-I 숫자는 B는 base class의 개수, I는 추가되는 class의 개수를 의미합니다. 예를들어 PASCAL VOC에 대하여 19-1일 경우 19개의 class에 대하여 먼저 학습한 후 1개의 class씩 추가 학습하여 2-step의 학습을 수행하고, 15-1일 경우는 15개로 학습한 뒤 1개씩 class를 추가하여 5-step의 학습을 수행하는 것 입니다. 또한, 실험 결과에서 joint는 모든 클래스를 누적하여 학습하는 upper bound를 의미합니다.
Quantitative Evaluation
<Results on PASCAL VOC 2012>
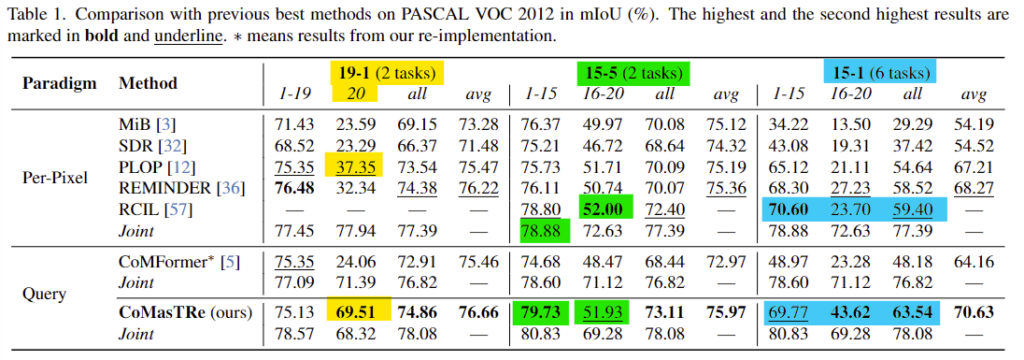
- Table 1은 PASCAL VOC에 대한 SOTA 방법론과의 비교 실험 결과를 리포팅한 것입니다. CoMasTRe는 전반적으로 Query 기반의 방법론인 CoMFormer보다 개선된 성능을 보였으며, 19-1(2 task) 상황에 대해서는 새로 추가된 class에 대한 성능(20)이 mIoU +32.16% 개선이 이루어졌습니다. (노란색 형광펜)
- 15-5의 경우 새로운 클래스에 대해서는 가장 좋은 성능을 달성한 RCIL에 비해 0.07%의 성능 저하가 일어나긴 했지만, 기존 클래스에 대한 성능은 upper bound가 되는 Joint 방식에 비해 0.85% 개선되었음을 어필합니다.(초록색 형광펜)
- 마지막으로 15-1의 실험 결과를 통해 CoMasTRe 방식이 모든 class(all)에 대해 4.14% 의 성능 개선이 이루어졌으며 전반적으로 좋은 성능을 보이고 있음을 어필합니다.(파란색 형광펜)
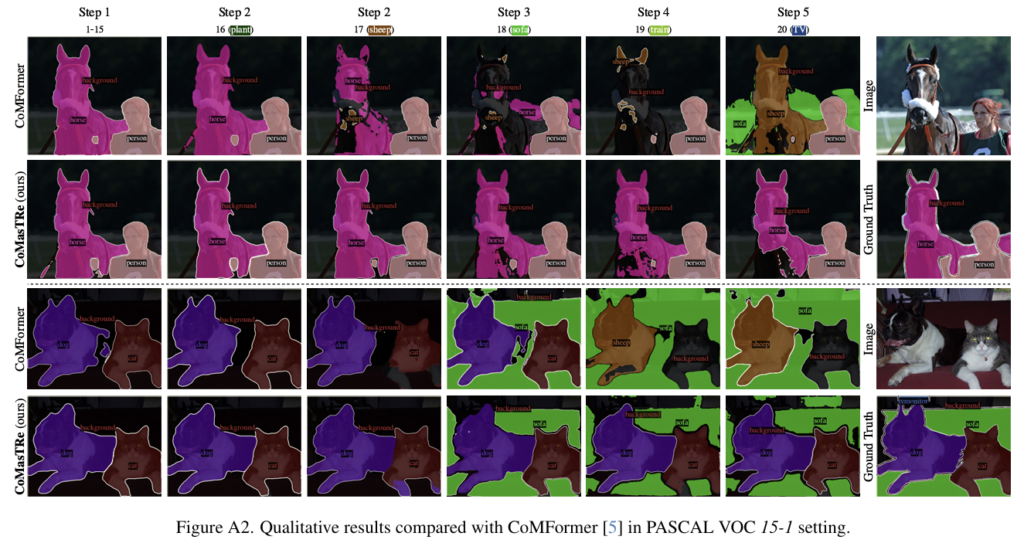
- 아래의 그림은 15-1 상황에 대한 정성적 실험 결과입니다.
<Results on ADE20k>
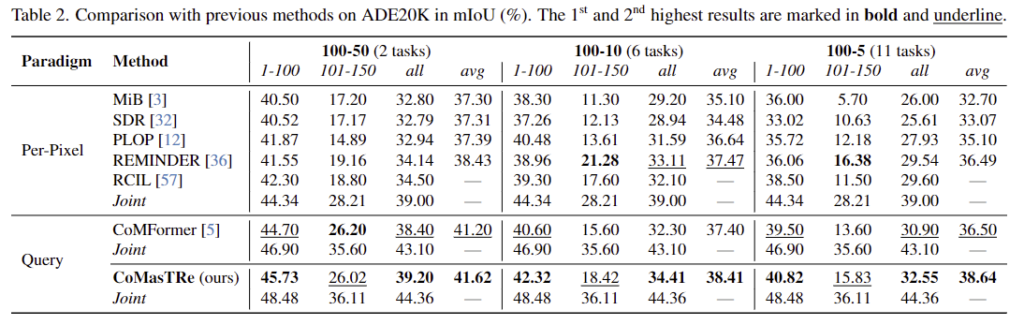
- Table 2는 ADE20k에 대한 실험 결과를 리포팅한 것으로, query 기반 방법론인 CoMFormer와 비교했을 때 성능이 개선되었음을 확인할 수 있습니다.
- 아래의 그림은 100-10 세팅에 대한 정성적 결과입니다.

Ablation studies
<Joint Training results>
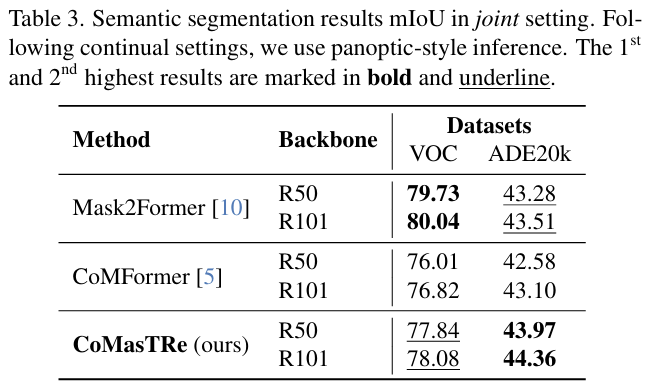
- Table 3은 모든 class에 대하여 한번 학습을 하는 상황에 대한 실험 결과입니다. 저자들이 제안한 CoMasTR2가 Mask2Former와 비슷하거나 좋은 성능을 달성하였으며, 이전의 continual segmentation 방법론인 CoMFormer에 비해서는 성능이 개선되었음을 확인할 수 있습니다.
<Objectness transfer ability analysis>
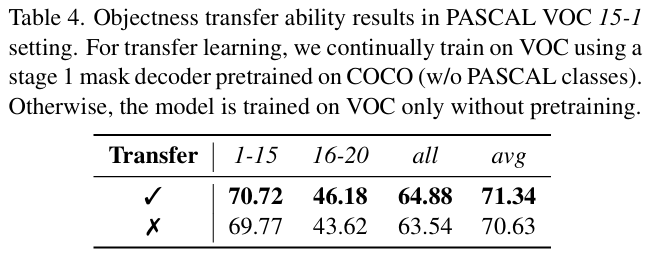
- 저자들은 objectness에 대한 능력을 평가하고자, stage 1은 PASCAL VOC에 존재하지 않는 class만으로 이루어진 수정된 COCO 2017을 이용하여 mask decoder를 학습한 뒤, stage 1에 15-1 상황으로 PASCAL VOC를 전이학습한 결과를 리포팅하였습니다. Transfer를 수행한 경우에 성능이 개선된 것을 통해 objectness distillation이 잘 이루어졌음을 보였습니다.
<Effectiveness of objectness distillation>
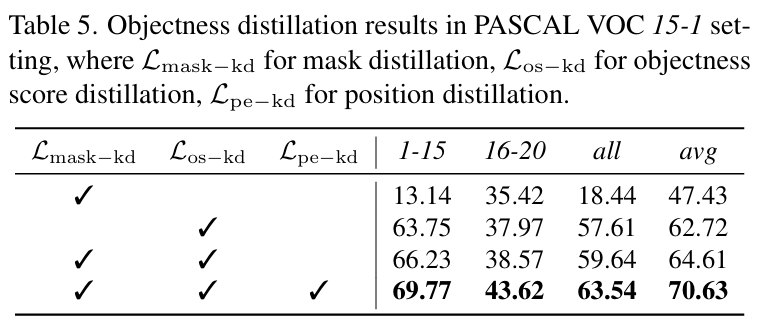
- objectness distillation을 위해 설계한 loss들에 대한 ablation 실험 결과입니다. 1행과 3행의 실험 결과를 통해 objectness distillation loss를 추가함으로써 base 클래스(1-15)에 대한 성능 저하 문제인 forgetting이 완화될 수 있음을 보였습니다. 또한, 2행과 3행, 3행과 4행의 결과 비교를 통해, 각 loss들이 모두 forgetting 문제가 완화에 기여함을 보였습니다.
<Effectiveness of class distillation>
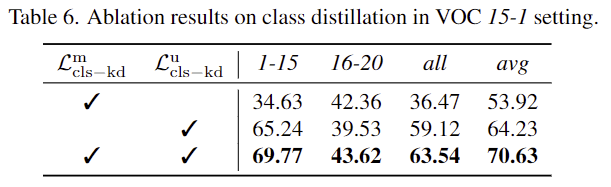
- 저자들은 \mathcal{L}^u_{cls-kd}를 사용함에 따라 forgetting 문제가 완화되었으며,\mathcal{L}^m_{cls-kd}도 함께 사용하여 forgetting 문제가 더 완화되었음을 보였습니다.
좋은 리뷰 감사합니다. 먼저 마스크 디코더로 objectness score 뽑아서 마스킹하고 그 다음 클래스 디코더로 분류를 하는게 object detection 세팅과 유사하네요. 간단한 질문 두 개 드리겠습니다.
1. Class Recognition에서 T step동안 별도의 classifier를 이용하여 이전 task의 간섭이 줄어들 수 있도록 한다고 했는데, 그럼 각 step마다 classifier를 아예 처음부터 학습하여 time step 간 독립적인 분류기를 구축한다고 생각하면 되는 걸까요?
2. transformer 기반 segmentation쪽은 아직 잘 모르는데, segmentation에서는 bipartite matching으로 어떻게 학습을 진행하게 되나요? DETR에서는 각 object 예측 결과를 집합으로 다루어 이를 bipartite matching으로 학습한것으로 알고 있는데, segmentation 세팅에서는 어떻게 학습되는것인지 잘 와닿지 않아 질문 드립니다.
감사합니다.
질문 감사합니다.
1. 넵 classifier는 별도의 파라미터로 진행하다고 하여, 이는 독립적인 분류기로 이해하시면 될 것 같습니다.
2. bipartite matching을 학습하기보다 헝가리안 알고리즘을 통해 bipartite matching을 수행한 뒤 매칭 결과를 이용하여 이후의 예측 결과 도출 및 학습을 수행하는 것으로 이해하였습니다. (M개의 mask proposals 중 N개의 GT 마스크와 대응되는 N개의 mask proposal들을 알고리즘으로 선택하여 해당 예측값들로 loss를 계산하는 것 입니다.)