안녕하세요 류지연입니다. 이번에도 6D 자세 추정에 대한 논문으로 가져왔습니다. 앞서 리뷰했던 PVNet, PVN3D, FFB6D 논문에서의 연구방향과 흐름을 살펴보았을 때 자세추정을 위해 키포인트를 검출할 때 Depth 이미지를 함께 사용해 Depth 이미지로부터 뽑아낸 특징을 가지고 RGB 이미지만을 사용했을 때의 부족한 점을 보완하게 해 (물론 그 반대도 동일하게 적용) 키포인트 예측의 정확도를 올렸었는데요 이번 논문은 방법이 조금 다릅니다. FFB6D 이후에 공개된 논문이지만 Depth 이미지를 사용하지 않고 하나의 RGB 이미지만으로 자세추정하는 방법을 사용합니다. 여기서 저자는 추정 정확도 특히 다른 물체에 가려지는 occlusion 상황에서의 추정 정확도를 개선하는 방법을 제안합니다. 그럼 바로 이어서 설명드리겠습니다.

Introduction
제가 3차원 물체의 자세를 추정하는 연구에 대한 리뷰를 계속 진행하고 있는데요. (이번 논문이 벌써 4번째 입니다) 6D 관련 논문을 처음 접하는 분들을 위해 한번 더 설명을 드리자면 6D 자세 추정을 한다는 것은 3차원 공간에 있는 물체의 위치와 그 물체가 바라보는 방향까지 알아내는 것을 말합니다. 자세를 알고자 하는 물체를 3차원으로 본뜬 mesh 모델이 있는데 이 mesh model의 object 좌표계와 world 좌표계 간의 회전, 평행이동 변환 관계를 예측해서 mesh model을 영상에서 보이는 것과 정확히 맞아 떨어지도록 위치시키는 것을 목표로 합니다. (이때, 기본적으로 카메라 내부 파라미터는 학습과 평가 시 기본적으로 제공됩니다)

로봇이 어떤 물체를 조작하게 하기 위함이나 증강현실을 구현할 때 실제 물체와 상호작용이 되도록 가능하게 하는 기술인 셈입니다. 조작하거나 상호작용을 하지 않아도 자율주행에서 여러 물체를 인지하는 게 중요한데 이럴때도 중요하게 적용되는 기술이기도 합니다.
앞서 설명했지만 자세 추정 문제를 다룰 때 그 정확도를 향상시키기 위해 이전 연구들은 Depth 이미지를 이용해 단일 RGB이미지만을 가지고 자세 추정 하던 방법을 개선시키는 방향으로 연구가 되었습니다. 그 결과 역시 좋았고요. 하지만 저자는 Depth 이미지를 사용하지 않고 온전히 RGB 이미지만을 사용해서 자세 추정 문제를 다룹니다. (Depth 이미지를 취득하지 않고도 충분히 정확하게 자세 추정을 할 수 있는 실용적인 방법을 찾고자 한 것이라고 볼 수 있겠습니다) 그리고 RGB 이미지만을 가지고 추정했을 때 더 취약할 수 밖에 없는 occlusion 상황에서의 예측에 대한 정확도를 개선하는데 포커스를 둔 연구라고 볼 수 있습니다.
본 연구도 기존의 two-stage 방법론을 따릅니다. RGB 이미지에서 키포인트를 추정한 후 RANSAC 기반의 PnP solver로 예측한 키포인트와 mesh model에서의 키포인트간의 변환 관계를 (R, t: 회전과 평행이동 변환 행렬) 구하는 방식으로 나뉘어서 자세 추정이 진행됩니다. 기존의 two-stage 방법론 에서도 occlusion에 강인하도록 여러 방법이 시도가 됐었는데요 특히 two-stage에서 제일 먼저 선행되는 키포인트 검출을 할 때 앞서 리뷰했던 PVNet에서 처럼 특징을 추출하는 네트워크를 통과하고 나온 feature map이 업샘플링을 통해서 원본 이미지와 같은 크기를 갖도록 하고 각 픽셀이 원본 이미지에서의 위치를 그대로 보존하도록 하면서 각 픽셀값을 이용해 pixel-wise하게 키포인트를 추정하는 방식이 있었습니다. 하지만 저자가 지적하기로는 이 경우 각 키포인트에 대해서 독립적으로 추정이 되기 때문에 최종적으로 추정되는 키포인트가 coherence하지 않게 되는 게 한계였습니다. (키포인트가 coherent 하지 못하다는 것은 GT 키포인트들간이 이루는 그 분포와 차이가 크다는 것입니다) 아래 그림을 참고해서 설명을 하면 빨간색 landmark를 GT라고 했을 때 초록색의 prediction 2가 파란색의 prediction 1보다 더 나은 coherence를 갖는다고 얘기할 수 있습니다.

이 논문의 contribution을 정리하자면 여전히 two-stage 방법론이 occlusion 에 취약하다는 점을 문제 삼고 이를 개선하기 위해 총 두가지의 방법을 제안합니다. 논문에서는 해당 방법을 Robust Object Pose Estimation (ROPE)라고 간단히 지칭하고 다음과 같이 나뉩니다. 첫번째, occlusion에 강인하게 특징이 추출되도록 하는 방법인 OBA를 제안하였는데요 이는 hide-and-seek, random erasing, batch augmentation의 방법에 착안한 것으로 새롭게 occlude-and-blackout batch augmentation를 적용한다는 방식입니다. 두번째로는 모델이 예측하는 landmark가 보다 나은 coherence를 갖도록 하는 multi-precision supervision 아키텍쳐(MPS)를 제안하였습니다. 그럼 다음 절에서는 각 방법에 대해 조금 더 자세하게 살펴 보도록 하겠습니다.
3. Proposed Methods
RGB 이미지에서 landmark를 예측하기에 앞서 이미지로 부터 특징을 추출해야하는데 이 부분은 Mask R-CNN 모델을 사용합니다. 저자는 이 모델의 백본을 HRNet으로 바꿔 학습합니다.
3. 1. Robust landmark Prediction
1. Occlude-and-blackout batch augmentation (OBA)
앞서 얘기한 것 처럼 자세를 추정할 때 occlusion 상황이 심한 경우 추정 정확도는 떨어질 수 밖에 없습니다. 다른 물체에 가려져서 occlusion이 발생하기도 하지만 3차원 물체 같은 경우 카메라로 촬영했을 때 뒷 부분은 촬영되지 않기 때문에 포착되지 않은 뒷부분에 해당하는 landmark를 추정하는 건 또 다른 난관입니다. 저자는 이런 것 까지 포함해 하나의 큰 occluion 문제라고 정의하고 이런 상황에 대해 robust한 방법으로 OBA라는 증강 기법을 제안합니다. 각 배치에서 학습 이미지에 대해 기본적인 증강이 적용되고 나서 원본 이미지의 복사본을 배치에 한 장 더 추가하는 데 이때 물체의 바운딩 박스안의 이미지를 패치로 나누고 각 패치를 랜덤하게 1) 노이즈를 주거나 2) 같은 이미지내 다른 패치로 교체하거나 3) black-out 시키는 방식입니다. 또한 바운딩 박스 바깥의 background의 이미지 패치들은 모두 black-out 시켜줍니다. 해당 방법으로 증강이 적용된 이미지는 원본 이미지와 동일한 GT로 학습됩니다. 이렇게 해서 occlusion 상황을 인위적으로 만들고 이런 occlusion이 severe한 상황에서도 landmark를 정확하게 예측하도록 특징 학습이 잘 유도 하는 방법이라고 할 수 있습니다.
이 증강이 적용된 것은 다음과 같습니다.

2. Multi-precision supervision (MPS)
다음으로는 landmark가 coherenct하게 예측되도록 그래서 GT와의 차이를 줄이고 결과적으로 추정정확도를 올리는 방법인 MPS입니다. 우선 본 연구에서는 RGB 이미지에서 landmark를 예측할 때 landmark마다 heatmap을 가지고 예측됩니다. (Mask R-CNN을 통과해 이미지의 feature map이 도출된다고 하였는데 이때 heatmap이 나오는 거라고 보시면 됩니다) 이때 heatmap의 분산은 하나의 하이퍼파라미터이고 이에 따라 예측 정확도가 달라지는데요 본 연구에서 제안하는 방법은 각 landmark 마다 분산이 서로 다른 3 단계의 (High, Medium, Low precision) 히트맵을 예측하도록 하는 것입니다. 아래는 본 연구에서 제안하는 모델의 구조도입니다.

기존 Mask R-CNN에서 백본 모델의 출력 feature map은 RoI proposal 이후 mask head에 전달되는데요 본 연구에서는 이 mask head를 3개의 키포인트 헤드로 변경합니다. 그리고 각 키포인트 헤드의 출력으로 분산이 서로 다른 heat map이 나오는 방법입니다. 본 연구에서는 \sigma를 8, 3, 1.5 픽셀로 설정한 다음 \sigma^2를 분산으로 하는 GT 히트맵을 학습 시 사용합니다.
아래는 모델을 학습 과정에서 사용되는 loss function입니다. \Phi^*는 GT landamark를 기준으로 그려지는 히트맵을 나타내고 \Phi는 모델이 예측하는 landmark에 대한 히트맵입니다. \phi는 channel wise하게 적용되는 softmax function이고 JSD는 Jensen-Shannon Divergence로 두 확률 분포간의 차이를 측정하는 지표입니다. 이 값이 0에 근사하도록 두 분포간의 차이를 줄여나가도록 학습됩니다.
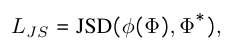
평가할 때는 high precision heatmap만을 사용해서 최종적인 landmark를 예측 합니다. medium, low precision heatmap이 평가 시 사용되지는 않지만 학습 과정에서 중요한 역할을 합니다. 저자가 분산이 다른 히트맵을 제안한 이유에 대해서 설명을 하자면 lower 한 precision heatmap에서는 분산이 크므로 하나의 landmark에 대한 히트맵이 다른 landmark의 위치를 고려하게 됩니다.

그림과 보시면 그림 상단의 부분이 히트맵이 하나로 결정되는 single precision supervision이고 보면 서로 다른 landmark에 대해 receptive filed가 feature tensor에서 겹쳐지 않는다는 것이 확인이 됩니다. 반면 하단에는 논문에서 제안하는 Multi-presion supervision의 방법이고 low precesion의 히트맵을 출력하기 위해서 keypoint head로 전달되는 receptive field가 두 landmark 사이에서 겹치는 부분이 생김을 알 수 있습니다. 이와 같은 경우 각 landmark에서 그려지는 low precision heat map에서 각 landmark의 위치를 함께 고려한 채 학습이 됩니다. 이렇게 학습을 함으로써 feature tensor는 각 landmark를 GT와 근사하게 예측되도록 하는 것 뿐만 아니라 조금 더 넓게 바라보면서 물체의 전체 자세를 고려한 학습이 가능해집니다.
3. 2. Landmark filtering
여러 자세 추정 모델은 추정 정확도를 올리기 위해서 추가적으로 조정하는 작업을 진행합니다. 하지만 저자는 이런 후처리 작업이 추가적인 연산을 더하기 때문에 실시간으로 정확한 예측이 필요한 경우 사용하기 어렵다고 합니다. 그래서 저자는 비교적 적은 양의 연산량으로도 추정 정확도를 올릴 수 있는 방법으로 앞서 MPS를 통해 각 히트맵에서 예측되는 landmark 중 아래의 집합에 포함되는 (식에 대해서 설명하자면 x_i는 high precision heatmap에서 예측된 landmark이고 x_i^*는 medium precision heatmap에서 예측된 landmark인데 둘 간의 거리가 verification threshold \epsilon보다 짧은 경우 high precision heatemap에서 예측된 landmark가 정확하다고 보고 해당 landmarks만을 PnP Solver에 전달해 최종적인 자세 추정이 정확하게 이뤄지도로 하는 방법을 제안한 것입니다.

4. Experiments
본 연구는 LINEMOD, (LINEMOD의 확장 버전인) Occluded-LINEMOD, YCB-Video 데이터셋에 대해 ADD(-S)로 구한 AUC를 평가지표로 사용해 성능을 검증합니다.
각 데이터셋은 아래와 같은 환경에서 촬영한 이미지로 구성됩니다. 각 데이터셋마다 특징이 다른데요 LINEMOD와 Occluded-LINEMOD는 같은 환경에서 촬영된 이미지를 사용하지만 LINEMOD는 하나의 객체에 대해서만 annotation을 제공하고 각 물체가 거의 가려지지 않은 이미지로만 구성돼 있습니다. 그와 반면 Occluded-LINEMOD는 모든 물체에 대해 annotation을 제공하고 때문에 물체 간의 occlusion이 발생하게 됩니다. Occluded-LINEMOD는 occlusion 상황에서도 모델이 정확히 자세를 추정하는지를 확인해볼 수 있는 적절한 데이터셋입니다.

LINEMOD, Occluded LINEMOD에 대한 실험에서는 ADD(-S)를 지표를 가지고 결과를 확인하고 YCB-V의 경우에는 ADD(-S)에 대해서 정답 예측이라고 인정하는 그 거리를 달리해서 구한 AUC를 가지고 결과를 냅니다.
mesh model에서의 GT landmark는 FPS의 방법으로 물체 표면상의 점들 중 제일 고르게 분포해서 잘 대표하도록 landmark를 뽑습니다. 본 연구에서는 landmark 개수를 11로 설정합니다. 그러면 다음으로 각 실험과 그 결과에 대해서 설명 드리겠습니다.
Ablation studies

우선 본 연구에서 제안됐던 OBA, MPS 가 각각 성능을 향상시키는데 영향을 준 것인지를 확인하기 위한 실험이었습니다. 실험을 위해 두 방법 모두 적용한 original, OBA는 적용하지만 MPS를 적용하지 않는 방법의 MV1, OBA와 MPS 모두 적용하지 않은 모델인 MV2를 두고 각 모델에서의 자세 추정 결과를 비교합니다. 정량적으로 확인했을 때 (위 이미지의 좌측 막대 그래프 확인) 논문에서 제안하는 방법을 모두 적용한 original이 ADD(-S)의 평균이 45.95로 제일 정확하게 나왔습니다. 정성적인 결과를 확인해봤을 때도 두 방법을 적용하지 않는 경우 GT와 차이가 나는 정도가 크고 완전히 다른 엉뚱한 곳에서 추정된 것도 확인할 수 있습니다. 반면에 OBA, MPS방법을 적용한 것이 GT와 근사하게 예측됨을 확인할 수 있습니다.
Comparing to SOTA methods
다음 실험 결과는 각 데이터셋에 대해 기존 모델과 비교한 결과입니다. 하나씩 살펴보겠습니다.

위 테이블은 LINEMOD에 대한 실험 결과입니다. 추가적인 조정 작업이 있는 모델과 없는 모델 통틀어서 논문에서 제안하는 방법론이 ADD(-S) 평균 값이 제일 높고 물체에 대한 개별적으로 보아도 대체적으로 본 연구에서 제안한 것이 높았습니다. 저자의 제안이 충분히 SoTA의 성능을 넘는다고 얘기할 수 있겠습니다.

위 표는 Occluded-LINEMOD에 대한 실험 결과로 조정 작업이 없는 그룹에서 Ours의 성능이 두번째로 높습니다.

마지막으로 YCB-V에 대한 실험 결과로 without refinement 상황에서 ADD(-S) 지표로 비교했을 때 평균값이 제일 높습니다. 하지만 평가지표를 AUC of ADD(-S)로 설정했을 때 without refinement에서는 GDR보다는 낮았고 refinement한 모델과들도 성능 차이가 있었습니다.
본 연구에서 제안하는 방법론이 모든 상황에서 매번 제일 성능이 높았던 것은 아니지만 추가적인 후처리 조정 작업 없이도 기존 SoTA나 후처리 작업을 적용한 것에 근사하거나 넘는 성능을 보였다고는 충분히 얘기할 수 있겠다고 생각합니다.
5. Conclusion
본 연구에 대해서 정리를 하자면 해당 연구는 RGB 단일 이미지만을 가지고 자세 추정 문제를 다뤘었는데 이때 RGB 이미지만을 사용했을 때의 보다 occlusion 상황에서의 정확도가 떨어지는 것에 대해서 landmark을 추가적로 조정하는 후처리 작업 없이도 강인하게 자세 추정이 되는 방법인 ROPE을 제안합니다. 구체적으로 occlusion 상황에서도 landmark 가 정확히 예측될 수 있도록 기본적으로 학습시 적용되던 증강 말고도 OBA라는 증강 기법을 제안하여 추가적으로 진행하였고 landkmark간 보다 높은 coherence를 갖도로 각 landmark에 대한 추정과정에서 다른 landmark의 위치에 대한 정보를 함께 고려되도록 하는 방법으로 MPS가 제안되었습니다. 그리고 여기서 추가적으로 computation을 늘려 부담을 주지않으면서도 정확도를 향상시킬 수 있는 방법으로 landmark filtering 방법도 함께 제안하였습니다. 논문에서 제안한 ROPE란 방법으로 정량적으로는 기존 모델보다 성능을 뛰어넘는 다는 것을 확인할 수 있었고 정성적으로도 확인해 보아도 예측되는 landmark가 GT와 차이 나는 폭이 작았고 무엇보다 GT가 차이가 있을지라도 각 landmark간 이루는 분포가GT의 landmark들이 이루는 것과 더 비슷하다는 했습니다.
안녕하세요 지연님 리뷰 감사합니다.
medium, low precision heatmap이 평가 시 사용되지는 않지만 학습 과정에서 중요한 역할을 하는데 평가할 때는 high precision heatmap만을 사용해서 최종적인 landmark를 예측하는 이유가 있을까요??
또 OBA를 학습할 때 적용해서 데이터를 증강하는데, 실제 세계에서 사용한다고 했을 때는 고려되야할 점들이 있을까요?
안녕하세요 김영규 연구원님 질문주셔서 감사합니다.
우선 평가 할 때는 정확한 키포인트(랜드마크)를 찾아야 하기 때문에 coarse한 medium, low precision map을 쓰기 보단 high precision heatmap만을 사용하는 것으로 생각됩니다.
또한 OBA라는 게 학습 이미지의 일부를 정해진 크기의 마스크로 가린 것과 아닌 이미지를 같이 학습해 occlusion 상황에서도 landmark 예측을 잘 할 수 있도록 하는 방법인데 실제 세계에서는 occlusion이 단순히 박스 형태로 가려지는 형태로 나타나는 경우는 거의 없기 때문에 완전히 occlusion 상황을 구현했다고 보기에는 어렵겠다는 생각이 듭니다.
감사합니다.
좋은 리뷰 감사합니다 류지연연구원님.
해당 논문에서 “3차원 물체 같은 경우 카메라로 촬영했을 때 뒷 부분은 촬영되지 않기 때문에 포착되지 않은 뒷부분에 해당하는 landmark를 추정하는 건 또 다른 난관”라 하셨는데, 제안한 OBA 방식으로 이를 어떻게 해결할 수 있는 지 정리 부탁드립니다.
또한, MPS에서 test시에는 high precision heatmap만을 사용한다고 하셨는데, 그럼 medium과 low는 학습 시에만 사용하는 것으로 이해하였는데, 학습 과정에서 각각은 어떤 정보를 학습하기 위해 사용하는지와 평가시에 이를 모두 고려하는 경우에 대한 실험 결과가 따로 없었는 지 궁금합니다. 또한, 두 landmark에 대해 receptive field가 겹치는 부분이 생기는 것이 어떤 효과가 있는 지도 설명 부탁드립니다.
좋은 질문 감사합니다. 답변을 드리자면
OBA 자체가 self occlusion을 구현한 거라기 보단 다른 물체로 부터 가려지는 현상을 나타낸 거에 더 가깝다는 생각은 듭니다. OBA를 통해서 가려진 키포인트를 알 수 있는 것은 아니지만 해당 방법으로 학습했을 때 가려져서 보이지 않는 키포인트의 위치를 다른 landmark를 가지고 추정할 수 있는 능력이 학습된다고 보시면 되겠습니다!
medium, low precision heatmap 모두 특정 landmark의 위치를 추정하는 히트맵인데요(히트맵은 랜드마크의 존재 여부에 대한 가능성의 분포를 나타냅니다) high precision heatmap보다 분산이 커 feature map에서 차지하는 영역이 더 넓은 이 둘을 함께 사용하게 되면 figure 3 에서 그려진 것과 같이 feature map에서 활성화되는 영역이 서로 다른 landmark의 히트맵간의 공유되며 겹쳐지는 landmark의 위치가 함께 고려됩니다. 결국 feature map에서 다른 landmark 간 holistic한 represenation 학습이 되며 coherence가 높아지는 방향으로 랜드마크를 추정하게 된다고 합니다. (마지막 질문에 대한 답변도 되었다고 생각하는 데 맞을까요?)
궁금해하시는 low, medium precision heatmap을 가지고 평가에 적용해서 이를 비교하고 분석한 실험은 본 연구에서는 진행되지 않았습니다.
감사합니다.
안녕하세요, 좋은 리뷰 감사합니다.
OBA에서 이미지 안의 바운딩 박스에서 패치를 나누어 랜덤하게 마스킹하거나 노이즈를 주는 방식이라고 말씀하셨는데요, 예시 이미지에서 뭔가 블랙아웃 시킨 영역이 물체를 검출한 영역과 크게 연관이 없어보여서 .. 단순히 전체 이미지에 대해 패치 단위로 나누어 OBA를 적용한다고 이해하면 되는걸까요 ? 그렇게 적용된다고 했을 때 해당 OBA 방식이 물체의 occlusion에 강인할 수 있도록 영향을 주는 이유가 무엇이라고 생각하시나요 ?
안녕하세요! 건화 연구원님!
질문 감사합니다.
바운딩 박스 바깥 영역에 대해서는 일괄적으로 모두 black out 처리가 된다고 알고 있습니다. 저자가 이렇게 하는 이유는 과적합을 방지하고 보다 general하게 task를 수행하게 하기 위함이라고 설명합니다. 정리하자면 모델이 배경 상관없이 객체 자체에 대한 인식 능력을 키우기 위함입니다. 어떤 배경에 의존해서 객체를 인식하는 것을 막고 다른 배경, 환경에서도 동일하게 검출이 되도록 하고자 했답니다!
그리고 OBA를 적용하는 건 모델이 일부 landmark가 가려져서 보이지 않는 상황에 대해 다른 landmark의 위치를 가지고 보다 정확하게 추론할 수 있는 능력을 길러준다고 합니다.
감사합니다.
좋은 리뷰 감사합니다, 류지연 연구원님.
리뷰를 읽다 보니 추가로 궁금한 점이 생겼습니다.
논문에서는 각 keypoint마다 heatmap을 예측한 뒤, high precision heatmap을 이용해 최종 keypoint 위치를 결정한다고 설명해주셨는데요, 이때 heatmap에서 실제 keypoint 좌표를 추출하는 방법 에 대해 구체적인 설명은 따로 없었던 것 같습니다.
이 부분에 대해 일반적으로 어떤 방식으로 keypoint를 추출하는지에 대해 개인적인 의견을 들을 수 있을까요?
안녕하세요 손우진 연구원님
질문에 답변을 드리자면 논문에서는 각 히트맵에 대해 argmax를 취해 하나의 픽셀값을 취하는 게 아닌 soft-argmax (논문에서 직접적인 언급은 업었지만) 각 픽셀에 해당하는 softmax값과 히트맵안에 포함되는 픽셀의 좌표를 곱해 기대값을 구해 최종 좌표를 구한다고 합니다.
감사합니다.