제가 이번에 리뷰할 논문은 강화학습 관련 논문으로, 저희 팀에서 진행하고 있는 미니프로젝트 3단계를 위해 읽게 된 논문입니다. 3단계 목표는 복잡한 작업을 실행하는 것을 목표로 하며, 이때 시뮬레이션에서 로봇 조작을 위한 policy를 학습하고 이를 실제 환경에 적용하기 위해 찾아보다 읽게 된 논문입니다. 해당 논문은 시뮬레이션으로 환경에 대한 탐색 전략을 학습한 뒤, 실제 환경을 탐색하여 더 정확한 시뮬레이터르 만든 뒤, 이를 통해 목표 task에 대한 policy를 학습하여 실세계에 적용하고자 한 연구입니다.
Abstract
강화학습에서 Model-free 방식은 정확한 모델(강화학습에서의 model이란, 환경의 동작 원리를 고려한 정보를 의미합니다. 현재 상태 s에서 action a를 통해 다음 step s’로 넘어갈 확률인 Transition model P와 상태 s에서 action a를 수행할 경우의 보상인 Reward model R를 의미합니다. )이나 시뮬레이터 없이 전략을 학습할 수 있다는 장점이 있으나, 샘플효율성이 떨어져 실제 환경에서 비현실적입니다. Model-based 방식은 이러한 문제를 피할 수 있고, 많은 저렴한 시뮬레이션 데이터를 통해 real-world로 전이할 수 있는 컨트롤러를 학습할 수 있지만, 적절한 시뮬레이션 asset(3차원 시뮬레이션 상의 물체를 의미합니다)과 물리 매개변수를 포함하여 정밀한 시뮬레이션이 요구되므로 환경을 반영하기 위해 사람의 상당한 노력이 요구됩니다. 따라서 해당 논문은 소량의 real-world 데이터로 system을 학습하여 자동으로 시뮬레이션 모델을 개선하고, 실제 환경에 적용 가능하도록 정확하게 컨트롤 전략을 계획하는 ASID(Active Exploration for System IDentification)를 제안합니다. 로봇 조작에서 시스템 식별을 위한 능동 탐사 기법으로, 다소 부정확한 초기 시뮬레이터를 이용하여 실제 세계에 배포를 위해 고품질의 데이터를 수집하는 효과적인 탐색(exploration) policy를 설계하여 효과적인 sim2real transfer를 가능하게 합니다. 저자들은 제안한 방식이 도전적인 로봇 manipulation 작업에서 joint 정보 , 질량 등 물리적인 파라미터를 식별하는 데 효과적임을 입증하며, 소량의 데이터만으로도 sim2real이 가능함을 보입니다.
Introduction
로봇을 제어하여 real-world에서 동적인 goal-directed 행동을 수행하기 위해, 환경에 대해 알려진 모델이 없어도 환경에서 샘플링된 데이터를 통해 행동을 학습할 수 있는 강화학습(Reinforce Learning, RL)을 활용한 연구가 활발히 이루어져왔습니다. 새로운 환경에 사람의 노력을 최소화하여 적용할 수 있으며, 지속적으로 개선이 가능하다는 점에서 table-top 조작부터 보행 등 로봇의 다양한 시나리오에 적용되어왔으나, 강화학습은 reset 매커니즘이나 보상함수를 설계하기 위해서는 환경에 대한 완전한 정보가 필요합니다. 이러한 이유로 잘 구성된 환경에 대한 학습이 요구되며, real-world로 적용을 위해서는 대량의 샘플 데이터가 필요하여 실용적이지 못하다는 한계가 존재합니다. 이러한 한계를 극복하기 위해 시뮬레이터를 활용하여 대량의 데이터를 저렴하게 생성하고, 강화학습을 통해 policy를 학습하는 연구들이 제안되었으나, real-world와 시뮬레이터 사이의 차이로 인하여 여전히 연구가 진행중입니다.

해당 논문은 system identification에서 영감을 받아, sim2real transfer의 핵심이 실제 세계에서 효과적인 시뮬레이터를 학습하는 것으로 보고, sim2real을 위하여 generic한 파이프라인인 ASID(Active Exploration for System IDentification)를 제안합니다. 해당 방식은 exploration과 exploitation을 분리하여 접근하며 아래의 순서로 이루어집니다.(강화학습에서 exploration은 알려지지 않은 새로운 환경이나 상태를 시도하여 환경애 대하여 새로운 정보를 얻는 과정을 의미하고, exploitation은 현재까지 알고있는 정보를 기반으로 가장 높은 보상을 얻을 수 있을 것으로 예상되는 행동을 선택하는 것을 의미합니다.)
- real에서 exploration을 통해 unknown 파라미터에 대해 수집
- real에서 수집된 데이터를 통해 시뮬레이션에서 refinement를 수행
- 업데이트된 시뮬레이터에서 목표 task 수행을 위해 policy 학습
저자들은 1번 과정을 통계학적 개념을 기반으로 수행하였으며, 초기 exploration을 통해 real-world에 대한 매개변수를 정확하게 추정함으로써 3단계에서 zero-shot 방식으로 전이가 가능함을 보였으며, 이는 real에 대한 추가 지식 없이 시뮬레이션에서 policy를 학습하는 경우에도 적용이 가능합니다.
해당 연구의 핵심 insight는 목표 task를 수행하기 위해 시뮬레이션에서 학습되는 policy가 효과적으로 전달되지 않을 수 있지만, 시뮬레이션에서 효과적인 탐색 전략을 학습할 경우 실제에서도 효과적인 탐색이 가능하다는 것입니다. 이에 대한 예시로, 로봇 팔이 공을 치는 task를 수행하는 경우를 생각해보면, 시뮬레이션에서 공의 질량에 대한 정보 없이 공을 치는 policy를 학습하면, 실제 환경에서는 질량이라는 중요한 요소를 고려하지 못해 task 수행에 실패할 수 있습니다. 이에 대해 저자들은, 로봇 팔이 공과의 어떠한 접촉(덜 정확한 움직임을 필요로 하며 질량에 대한 사전지식X)을 통해 공의 질량에 대한 정보를 추론하도록 하여, 사전 지식 없이도 물리적 파라미터를 탐색하고 식별할 수 있는 방식을 제안합니다. 이 과정을 통해 시뮬레이터는 실제 환경과 더 유사해지고, 더 사실적인 시뮬레이터를 통해 학습된 policy는 실제 환경에서도 잘 작동할 수 있습니다. 즉, 시뮬레이션을 통해 효과적인 탐색 정책을 먼저 학습하고, 이를 실제 환경에 적용하여 물리적 파라미터에 대한 정보를 수집합니다. 이렇게 보완된 시뮬레이터 위에서 최종 목표 task에 대한 policy를 학습함으로써, sim-to-real transfer가 가능한 보다 정확한 시뮬레이션 기반 학습이 가능해집니다.
저자들은 ASID에 대하여 4가지 작업(구형 조작, 노트북 조정, 막대 균형 잡기, shuffleboardd)으로 평가를 수행하며, 실제 환경에 대한 매개변수(기하학 정보, joint 정보, 질량 중심 등의 물리적 매개변수)가 알려지지 않은 시나리오에서 해당 매개변수들을 효과적으로 식별할 수 있음을 보였으며, 이렇게 취득한 정보를 기반으로 시뮬레이션에서 목표 task에 대한 policy를 학습하여 적은 양의 데이터로도 sim-to-real로 전이가 성공적으로 가능함을 보입니다. (single 에피소드로도 sim2real transfer가 충분하였다고 합니다.)
Related work
<System Identification>
해당 논문은 System dynamics를 효율적으로 학습하는 방법을 다루는 System Identification 연구를 기반으로 합니다. System Identification은 시스템의 환경 매개변수를 효과적으로 학습하기 위해 입력을 어떻게 선택해야하는지에 대해 연구되어왔으며, 환경에 대한 일부 정보를 다루는 연구들도 존재합니다. 이러한 연구는 Fisher Information Matrix를 최대화하는 방향으로 입력을 선택합니다. 저자들은 시뮬레이터를 활용하여 효과적인 exploration policy를 학습하고 이를 로봇 task에 적용한 연구로, 고전적인 system Identification 연구와 현대의 real2sim 연구를 연결하는 연구임을 이야기합니다.
최근에는 이론 중심의 연구였던 system identification 연구를 실제 환경에 적용하기 위한 물리적 매개변수를 능동적으로 인식하는 연구 뿐만 아니라 운동학적 구조 식별 등의 연구가 등장하였으며, 시뮬레이터의 매개변수를 학습하여 하위 policy를 학습하는 연구들도 진행되었습니다. 이러한 연구들은 task-specific policy나 regret({최적의 보상}-{실제로 얻은 보상}={regret}이라 합니다.)을 최소화하는 exploration policy를 사용하여 데이터를 수집합니다. 그러나 이러한 연구들은 알려지지 않은 매개변수를 학습하기 위한 탐색 정책을 고려하지 않거나, 하위 작업에 대하여 고려하지 않으며, 더 복잡한 작업으로는 확장이 어려운 기술에 의존한다는 한계가 존재합니다.
<Simulation-to-Reality Transfer>
sim2real gap은 여전히 해결해야 하는 문제로 남아있으며, 이를 해결하고자 시뮬레이션 내의 환경분포에 실세계 분포가 포함되기를 기대하고 환경분포를 다양하게 바꿔가며 policy를 학습하는 Domain Randomization(DR)과 같은 연구들이 등장하였습니다. 이후 환경에 대한 분포를 적응적으로 변화시키거나, 실제 데이터를 시뮬레이션에 통합하는 연구들이 진행되었으며, 해당 논문은 이러한 흐름과 유사하지만 시뮬레이션에서 real로 전이하는 과정에 집중하기보다, 시뮬레이션 자체가 실제와 같아지도록 하는 데 집중합니다. 또한, 일반적인 연구들은 시뮬레이션에서 policy를 학습한 뒤 이를 실제 환경으로 미세조정하는 것을 목표로 하지만, 시뮬레이션 자체가 미세조정에 필요한 학습이 덜 필요한, 도전적인 연구라고 어필합니다.
<Model-Based RL>
우선 해당 방법론은 물리적 파라미터를 이용하여 model에 대한 정보를 고도화 한 뒤 작업에 대한 policy를 학습하는 방식으로 Model-Based RL에 해당합니다. 대부분의 Model-based RL 연구들은 환경의 dynamic을 모델링하기 위해 복잡한 모델과 많은 파라미터를 이용하여 policy를 학습합니다. (fully learned dynamic models를 사용한다고 표현합니다.) 그러나 해당 논문은 시뮬레이터를 “model”로 사용하여 핵심적인 소수의 파라미터(articulation, 질량, 마찰계수 등)만을 학습하여 샘플효율성을 높이는 것을 목표로 합니다. 또한, 기존 Model-Based RL은 exploration을 수행하지 않지만, 해당 논문은 명시적으로 exploration 과정을 통해 시뮬레이터의 고도화를 진행한다는 점에서 차이가 있습니다.
Preliminaries
강화학습은 일반적으로 의사결정과정을 Markov Decision Processes(MDP)로 공식화합니다. MDP는 순차적인 의사결정 문제를 수학적으로 표현하는 모델로, M^⋆ = (\mathcal{S,A,}\{P^⋆_h\}^H_{h=1},P_0,\{r_h\}^H_{h=1} )의 튜플로 정의됩니다. 여기서 \mathcal{S}는 state 집합, \mathcal{A}는 액션집합, P_h: \mathcal{S ⨉ A → \Delta_S}는 특정 상태에서 다음 상태로 전이될 확률 분포, P_0 \in \Delta_{\mathcal{S}}초기 상태의 분포, r_h: \mathcal{S ⨉ A →\mathbb{R}}는 보상함수를 의미합니다.
에피소드가 시작될 때, 에이전트의 상태 s_1 \sim P_0를 관찰한 뒤, 액션 a_1 \in \mathcal{A}를 수행하고, 이에 따라 다음 상태 s_2 \sim P_1(\cdot|s_1,a_1)로 전이하여 보상 r_1(s_1,a_1)을 받습니다. 이러 step을 H번 반복한 뒤 종료되면 에피소드가 끝나는 것으로, 저자들은 실제 환경에서 최대 보상을 얻을 수 있는 policy \pi_{task}를 학습하는 것을 목표로 합니다. policy에 대한 value는 V^{\pi}_0 := \mathbb{E}_{M^\star , \pi} [\Sigma^H_{h=1} r_h(s_h,a_h)]로 정의되며, 이는 MDP M^\star에서 policy \pi_{task}를 실행하여 얻은 trajectories에 대한 기댓값을 의미합니다. 최종 목표는 수행하고자 하는 목표 task를 완료하고 V^{\pi}_0가 최대가 되도록 하는 policy \pi_{task}를 찾는 것 입니다.
sim2real 세팅에서는 보상(reward)는 알려져 있지만 실제 환경에 대한 dynamics P^\star = \{P^\star_h\}^H_{h=1}는 모른다고 가정합니다. 그러나, 알려진 파라미터\mathcal{P} := \{P_\theta : \theta \in \Theta\}에 속한다고 가정하여, P^\star=P_{\theta ^\star }가 되는 \theta^\star \in \Theta에 존재한다고 가정합니다. 여기서 \theta는 알려지지 않은 파라미터(질량, 마찰 등)로 하여 P_\theta는 파라미터 \theta에 따른 dynamic을 나타냅니다. 임의의 \theta와 \pi에 대하여 dynamics P_\theta는 state-action trajectories \boldsymbol{\tau}=(s_1,a_1,s_2,a_2, ... , s_H,a_H)에 대한 확률분포를 유도하며, 이를 p_{\theta}(\cdot|\pi)로 나타냅니다. 시뮬레이터는 p_{\theta}(\cdot|\pi)를 구현한 것으로 볼 수 있으며, 시뮬레이터가 policy \pi하에서 \theta를 갖는 MDP의 dynamics를 정확히 모방할 수 있다는 가정에 따라 샘플 \boldsymbol{\tau}\sim p_\theta(\cdot|\pi)를 생성합니다.
시뮬레이터에서 얻은 샘플은 수집이 용이하므로 저자들은 “free”라 표현을 하며, \theta와 \pi에 대하여 원하는 만큼 많은 trajectories \boldsymbol{\tau}\sim p_\theta(\cdot|\pi)를 수집하고, 시뮬레이션을 통해 \theta에서 최적의 policy \pi를 찾기 위한 강화학습을 수행할 수 있습니다. 이때 실제 환경에 대한 파라미터 \theta^\star를 알면 시뮬레이터를 통해 실제 환경에 대한 최적의 policy를 찾을 수 있으므로, 저자들은 실제 환경에 대한 파라미터 \theta^\star를 식별하는 것에 집중하였습니다.
학습 프로토콜은 다음과 같습니다.
- 탐색 정책 \pi_{exp}를 선정하여 real에서 1개의 에피소드를 실행하여 trajectory \boldsymbol{\tau}_{real} \sim p_\theta(\cdot|\pi_{exp})를 생성
- \boldsymbol{\tau}_{real}과 시뮬레이터를 이용하여 어떤 작업에 대한 policy \pi_{task}를 획득
- policy \pi_{task}를 실제 환경에 배포하여 loss max_\pi V^\pi_0 - V^{\pi_{task}}_0를 구함(즉 최대 value와 task에 대한 value의 오차를 의미하는 것으로 이해하였습니다..)
정리하면, 실제 환경에서 하나의 상호작용 에피소드를 통해 최대한 정보를 취득하고, 이를 기반으로 real에서 task를 수행하기 위한 policy를 구하는 것을 목표로 하는 것 입니다.
<Parameter Estimation and Fisher Information>
앞서 related work의 System Identification 파트에서 Fisher Information matrix를 언급하였는데, 이는 exploration policy \pi_{exp}를 선택하는 데 중요하다고 합니다. 따라서 이에 대하여 간단하게 설명을 해보면 다음과 같습니다.
먼저, 분포 p_\theta에서 정규성 조건을 만족할 경우 Fisher Information matrix는 아래의 식으로 정의됩니다.

- \mathcal{D}=(\boldsymbol{\tau}_t)^T_{t=1}로, t=1,2, ... , T step에 따른 trajectory \boldsymbol{\tau}
- \hat{\theta}(\mathcal{D}): \theta^\star의 unbiased estimator(추정량의 기댓값이 모수와 일치하는 경우를 의미합니다)
Cramer-Rao lower bound 에 따르면, \hat{\theta}(\mathcal{D})의 공분산은 아래의 식을 따릅니다.

따라서, Fisher Information이 평균 오차 제곱 하한 역할을 할 수 있다는 것을 알 수 있습니다.

저자들은 Fisher Information을 파라미터 추정의 근본적인 하한으로 적용하여 exploration 과정을 수행하게 됩니다.
ASID
1. Exploration via Fisher Information Matrix
효과적으로 작업 수행에 대한 policy를 학습하기 위해, 정확한 환경 파라미터 \theta^\star를 식별하는 것이 중요합니다. 해당 과정은 학습 프로토콜의 1단계로, exploration을 통해 \theta^\star에 대한 가능한 많은 정보를 제공할 수 있는 실제 환경에 대한 trajectory를 생성하는 policy \pi_{exp}를 수행하는 것을 목표로 합니다. 해당 과정에서 앞서 설명한 Fisher Information Matrix를 이용하여 데이터의 유용성에 대하여 정량화합니다.
\boldsymbol{\tau}_{real}은 \pi_{exp} 에 따라 결정되며, Fisher Information은 데이터 분포에 의존하므로, Fisher Information은 exploration policy에 따라 달라집니다.

앞서 Fisher Information Matrix가 오차제곱 평균의 하한이 된다는 식 (1)에 따라 tr(\mathcal{I}(\theta^\star, \pi_{exp})^{-1}) 가 하한이 되므로, 아래의 식 (2)를 만족하는 exploration policy를 찾습니다.

Fisher Information이 커지면, tr(\mathcal{I}(\theta^\star, \pi_{exp})^{-1}) 이 작아지므로 (2)를 풀기 위해 Fisher Information이 최대가 되도록 하는 policy \pi_{exp} 를 찾습니다.
<Implementing Fisher Information Maximization>
저자들은 Fisher Information의 행렬이 dynamics 구조 p_\theta(\cdot|\pi)에 따라 매우 복잡해질 수 있므로 이를 직접적으로 최적화하기 어렵다는 것을 이야기하며, 이를 단순화하여 접근합니다. 단순화를 위해, 다음 state s_{h+1}이 가우시안 process 노이즈를 따르는 아래의 식으로 간단하게 표현된다고 가정합니다.

이로부터 단순화된 Fisher Information Matrix는 아래의 식으로 단순화됩니다.

또한, 식 (2)에 대한 최적화를 위해서는 실제 환경에 대한 파라미터 \theta ^\star가 중요하지만, 이에 대해 모른다는 문제가 있으므로 이를 해결하고자 Domain Randomization을 도입하여 해결합니다.

마지막으로 시뮬레이터나 dynamic가 일반적으로 미분가능하지 않기 때문에 gradient에 근사하는 방식을 통해 알려지지 않은 파라미터에 대한 민감도를 효과적으로 측정하고, PPO(Proximal Policy Optimization)과 같은 최적화 알고리즘을 통해 식(4)를 최적화하여 exploration에 대한 policy를 탐색합니다.
2. System Identification
다음으로 exploration policy를 통해 단일 trajectory \boldsymbol{\tau}_{real}를 생성하여 시뮬레이터를 업데이트합니다. 해당 과정의 목표는 \boldsymbol{\tau}_{real}과 가장 유사한 trajectory를 만들어내는 시뮬레이터의 파라미터를 구하는 것으로, 아래의 식을 최소화하는 q_\phi를 찾습니다.

- p_\theta(\cdot | \mathcal{A}(\boldsymbol{\tau}_{real})): 파라미터 \theta에 대한 시뮬레이터로 생성된 trajectory 분포를 의미하며, 이는 \boldsymbol{\tau}_{real}에서 수행한 행동과 동일한 행동입니다.
저자들은 ASID 프레임워크에 대하여 다양한 최적화 알고리즘을 적용할 수 있다는 점을 어필하며 넘어갑니다. (강화학습의 특정 최적화 방식을 선택하는 것이 아니라 일반적으로 다양하게 적용할 수 있다고 열어두고 넘어갑니다.)
3. Solving the Downstream Task
앞의 과정을 통해 실제와 더 유사해진 고도화된 시뮬레이터를 활용해 목표 작업에 대한 policy \pi_{task}를 zero-shot 방식으로 실제 환경에 적용합니다. 여기서 zero-shot이라 하는 이유는 시뮬레이션을 통해 많은 데이터 샘플을 생성하여 정책을 학습하고 이를 실제 환경에 대하여 적용하기 때문입니다. 해당 과정에 대해서도 저자들은 어떠한 policy 최적화 방식도 적용할 수 있다는 점을 어필하며, 특정 방식을 선택하지 않고 넘어갑니다.
Experimental Evaluation
실험을 통해 저자들은 (1) ASID의 exploration 전략이 unknown 파라미터 식별을 위하여 충분한 정보를 제공하였는지? (2) 식별한 파라미터를 이용하여 ASID 성공적으로 downstream task에 대한 policy를 학습할 수 있는지? (3) ASID에서 제안한 패러다임이 실제 환경으로 전이 가능한지? 를 확인하고자 하였습니다.
이를 위해 2가지 시나리오에서 평가를 수행합니다. 먼저, ASID의 exploration, system identification, downstream task에서의 동작을 검증하고자 시뮬레이터를 실제 환경이라 가정하고 실험을 수행합니다. 그 다음, 실제 데이터를 활용하여 ASID가 실제 세계엥서 작동할 수 있는지에 대한 평가를 수행합니다.
<Ablations and Baseline Comparisons>
ASID를 기존의 베이스라인 방식들과 비교하며, 비교에 사용된 방식들은 다음과 같이 정리할 수 있습니다.
- 탐색 (Exploration)
- Fisher Information을 이용한 exploration의 효과을 비교하기 위해 기존 연구 2가지를 이용합니다.
- 임의의 policy로부터 취득한 데이터를 이용하여 system identification을 수행하는 단순한 방식
- 관심있는 환경 파라미터와의 상호작용 정보가 최대가 되도록 trajectory를 생성하는 방식으로, 매개변수를 추론한 뒤 오류가 줄어들도록 보상을 부여하여 최적화를 수행함
- Fisher Information을 이용한 exploration의 효과을 비교하기 위해 기존 연구 2가지를 이용합니다.
- System Identification
- 최적화 기반의 system identification 방식과 end-to-end로 학습하는 방식을 적용하여 비교실험을 수행합니다.
- Downstream Policy Learning
- downstream task를 해결하기 위해 ASID 파이프라인과 Domain Randomization 방식에서 구한 환경 파라미터를 비교하여 실험을 수행합니다.
<Simulated Task Description>

저자들은 다음 작업들에 대한 평가를 수행합니다.
- Sphere Manipulation
- 물리적 파라미터를 모르는 두 가지 구형 조작 작업에 대한 평가를 수행합니다.
- task1: 마찰에 대한 정보를 모르는 상황에서 골프공을 목표 지점까지 치는 것 (Figure 3-(b))
- task2: 서로 다른 표면(마찰에 대한 정보가 다른)으로 이루어진 상황에서 골프공을 치는 것 (Figure 3-(c))
- 물리적 파라미터를 모르는 두 가지 구형 조작 작업에 대한 평가를 수행합니다.
- Rod Balancing
- 막대의 균형을 식별하여 블록 위에 올리는 것 (Figure 3-(a))
- Articulation
- 일반성을 어필하기 위해 질량과 마찰 등의 물리적 파라미터 뿐만 아니라 로봇의 관절 위치와 각도 등의 운동학적 구조도 고려하는 상황에 대한 평가를 수행합니다. (Figure 3-(d))
Results
exploration에 대한 평가를 위해 여러 파라미터를 모르는 상황을 고려합니다. Figure 3-(c)에 해당하는 여러 표면이 존재하는 상황에서의 exploration policy에 대한 평가를 수행합니다. 아래의 Figure 4는 exploration 과정에서 공이 지나간 영역의 heatmap을 나타낸 것으로, 좌상단이 목표 지점, 중간 부분이 공의 시작점을 나타내는 것으로 보입니다. 저자들은 결과에 대하여 ASID 방식이 전반적인 영역을 고려하여 공을 타격하는 방식에 대한 학습이 이루어지는 반면, (b)는 시작 영역에서 다른 영역으로 효과적으로 이동시키지 못한다고 설명합니다.

Quantitative Results of Downstream task

위의 Table 1은 Rod Balancing과 Sphere Striking 작업에 대하여 시뮬레이션에서의 정량적 평가 결과입니다. Rod Balancing의 경우, 블록 위에 막대를 올려 균형을 잡고 그때 기울어진 정도를 나타내는 것으로 이해하였으며, 실험 결과 기존 연구들에 비해 크게 성능 개선이 이루어졌음을 확인할 수 있습니다. 또한 Sphere Striking은 골프 공을 목표지점으로 치는 작업으로, 작업 성공률에 대한 평가를 수행합니다. 해당 task는 마찰과 거리 등의 물리적 파라미터가 중요한 역할을 하며, 해당 task는 이러한 물리적 파라미터를 방법론이 직접 탐색하여 시뮬레이터를 고도화하였다는 점에서 ASID가 환경 파라미터에 대하여 효과적을 파악할 수 있다는 것을 시사합니다.
Results on real-world
실제 환경에서 ASID가 작동하는 지 검증하기 위해 해당 논문의 저자들은 Franka Emika Panda 로봇을 이용하여 실제 세계에 대한 exploration을 수행합니다. 사용한 센서는 캘리브레이션 된 2대의 RealSense D455로, 물체의 위치와 방향을 인식하기 위해 두 센서로 구성한 point cloud에서 색상에 대한 임계치로 파악하였다고 합니다. (즉, 물체에 대해 사전에 정의된 정보 기반의 알고리즘을 적용하여 파악하였다는 것으로 이해하였습니다. 해당 파트를 추후 인식 알고리즘을 적용하여 대체하여 대상 물체에 대한 일반화가 가능하도록 적용하면 좋을 것 같습니다.)
1) Rod Balancing
real world의 환경을 탐색(exploration)하고 그 결과 데이터를 이용하여 시뮬레이션에서 적절한 물리 파라미터를 찾아 질량 분포를 모르는 막대의 균형을 잡는 것을 목표로 하는 작업입니다. 시뮬레이션에서 최적화된 policy를 이용하여 실제 세계에서 작업을 수행하여 이에 대한 검증을 수행하는 것으로 Figure 5를 통해 이러한 방식이 어떻게 이루어지는 지 확인하실 수 있습니다.

pick-and-place에 해당하는 downstream task로, 막대의 질량 분포와 관성, 마찰 계수 등을 모두 유추해야하며 실제 환경에서의 실험 결과를 통해(Table 2) ASID가 DR(domain randmoization)에 비해 성능이 개선되었음을 보였습니다.
2) Shuffleboard
미끄러운 판 위에서 목표 지점에 퍽을 넣어야 하는 게임을 table-top으로 축소시킨 task라 합니다. 보드에 왁스를 부어 마찰을 줄였으며, 퍽이 움직이면서 왁스가 밀리기 때문에 보드이 표면 마찰이 계속 변하게 되어 어려운 작업이라 합니다. 퍽이 노란 영역과 파란 영역을 치는 것을 각각의 목표로 하고, end-effector를 퍽과 일정 거리 떨어지는 곳에 위치시킨 뒤, 퍽을 치기 위한 힘을 예측하도록 downstream task를 설정합니다.
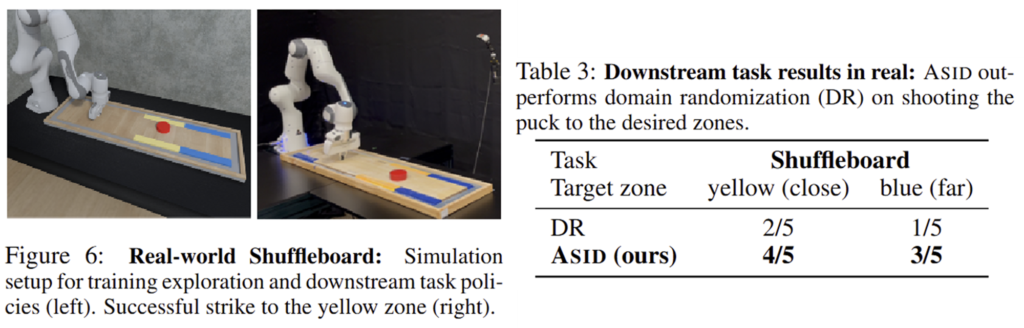
Table 3은 이에 대한 실험 결과로, 마찰 정보가 변하는 복잡한 작업임에도 개선된 성공률을 보였습니다.
논문이 예상 이상으로 어려운 것 같아요….
몇 가지 질문만 하고 가도록 하겠습니다.
Q1. 내용이 어려워서 전반적인 그림이 안그려지는 것 같아요. real과 sim의 관측 정보는 뭔지 잘 모르겠어요…
Q2. 직접적인 물리 정보를 예측하는 것이 아니라 policy를 학습하는 것이 목적인 것으로 이해했습니다. 혹시 맞을까요??
저도 슬슬 공부 시작해야겠습니다.. 너무 어려움…
질문 감사합니다.
A1. 관측 정보에 대해서 논문에서는 명시적으로 표현하고 있지 않습니다. 제가 코드상으로 확인해보았을때는, joint들의 positions와 velocities 정보인 것으로 보입니다.
A2. 맞습니다. 이야기하신대로 exploration 단계에서는 exploration을 위한 policy를 학습하고 이를 기반으로 real에서의 로봇의 작업을 통해 에피소드를 하나 생성한 뒤, 이를 기반으로 물리적 파라미터를 추론합니다.
안녕하세요 승현님, 좋은 논문 리뷰 감사합니다.
시뮬레이터 자체를 ‘모델’로써 사용하면서 해당 시뮬레이터가 real환경의 MDP dynamics를 가장 잘 모사할 수 있도록 만든 다음 -> 시뮬레이터에서 학습한 policy를 real에 적용하겠다는 관점에서의 model-based RL이라는 게 너무 흥미롭습니다. 크게 보면 sim->real->sim->real 의 그림을 가지는 것 같네요.
방법론 면에서는 특히 Fisher Information Matrix라는 통계학적 요소가 핵심인 것 같습니다.
수식이 좀 이해하기가 어려웠어서,,, 리뷰 읽어보면서 좀 정리를 해보았습니다..
[정리]
정리하면 FIM이 시스템의 파라미터 추정에 대한 민감도를 정량화하기에 이게 클수록 exploration 을 통해 수집한 real에서의 trjectory 데이터가 물리적(환경) 파라미터를 잘 추정하고 있는 것으로 이해했고, 그러기 위해 FIM이 최대가 되도록하는 policy pi_exp를 찾는 것으로 이해했습니다. 근데 FIM을 최대화하는 pi_exp가 실제 환경의 dynamics를 모사하기에 파라미터가 매우 복잡할 수 있어서 직접 최적화는 어려웠기에, 저자들은 이를 단순화하는 과정이 있는 것으로 이해했습니다.
그리고 해당 pi_exp를 통해 수집된 trajectory를 기반으로 시뮬레이터의 파라미터 또한 실제 환경의 파라미터와 유사하게 조정해주고, 실제 환경과 유사한 파라미터로 조정된 시뮬레이터 환경에서, 최종 작업 수행을 위한 policy pi_task를 학습하고 이를 최종 실제 환경에 적용하는 것으로 큰 흐름을 정리해보았습니다… 너무 어렵네요…
정리하고보니 ASID가 어떻게 model-based RL인가 계속 의문을 가지면서 읽었었는데 와닿았습니다.
기본적으로 real 환경의 물리적 dymanics라는 어떤 ‘모델’ 자체를 알 수는 없었지만, 파라미터로써 간접적으로 추정은 할 수 있기에 FIM을 활용한 파라미터 추정을 통해 model-based RL 구조를 따를 수 있었던 거로 이해했습니다. 제가 맞게 이해한 게 맞을까요..?
[질문]
질문이 한개 있습니다.
그럼 exploration policy를 통해 단일 trajectory를 생성해서 시뮬레이터를 업데이트하는 것으로 보이는데, 해당 trajectory의 time 축 길이가 어느 정도냐에 따라 성능향상에 영향을 미칠 것 같습니다(long-horizon task의 경우가 예상됩니다). 저자들은 trajectory 의 길이에 따른 성능변화나 long-horizon task에 있어서의 작업성공률 실험이나 언급은 없었나요?
감사합니다.
질문 감사합니다.
저도 재찬님이 이해하신대로 이해하였습니다. Model-based RL인 이유에 대하여 제가 이해한 바로 설명을 해보자면, 우선 대략적인 시뮬레이터를 통해서 exploration policy를 학습하였고, 여기서 시뮬레이터가 존재하므로 이를 model-based에 해당하고, 이를 기반으로 model을 구성하는 환경 파라미터를 추정할 수 있었으므로, 이후에 task에 대해서도 model-based 방식으로 RL을 수행하여 task policy를 학습한 것으로 이해하였습니다.
질문에 대해서 답변을 드리자면, 저자들은 exploration policy를 예측하기 위한 task에 길이에 대해서는 별도로 이야기하거나 실험한 내용이 없습니다. 그러나 논문에서 이야기한 task 중 공을 쳐서 특정 위치로 보내는 작업의 경우 long-horizon task라 보기는 어렵다고 생각하여, trajectory의 길이는 크게 상관 이 없지 않을까 합니다..