오늘은 다소 예전 논문을 가져왔습니다. 최근 Video-Text Retrieval 중심으로 서베이를 진행중인데요, 해당 태스크에서 Loss로 많이 사용하는 MIL-NCE (Multiple Instance Learning and Noise Contrastive Estimation)를 제안한 논문입니다. 구체적으로, 사람의 언어를 따라 설명하는 내레이션이 포함된 비정제(Uncurated) 비디오에서 학습하여, 별도의 라벨 없이도 비디오를 학습할 수 있는 방법론을 제안한 논문입니다.

- Conference: CVPR 2020
- Authors: Antoine Miech, Jean-Baptiste Alayrac, Lucas Smaira, Ivan Laptev, Josef Sivic, Andrew Zisserman
- Affiliation: ENS/Inria, DeepMind
- Title: [CVPR 2020] End-to-End Learning of Visual Representations from Uncurated Instructional Videos
1. Introduction
기존의 비디오 모델들은 대개 대규모 라벨링 데이터에 의존하고 있습니다. 하지만 비디오 라벨링은 비용이 많이 들고 확장성도 떨어지며, 특히 시간 정보가 포함된 액션 영상의 경우 어떤 구간에 어떤 행동이 일어나는지 등 이를 라벨링하는 데 많은 인력이 필요합니다. 특히, 복잡한 인간 활동이 포함된 비디오에서는 적절한 어휘 선택, 시간 구간 설정 등 주석 자체가 주관적이고 어려운 경우가 많죠. 이러한 한계를 극복하기 위한 대안으로, 웹에 존재하는 대규모 내레이션 영상, 예컨대 유튜브의 ‘요리하는 법’이나 ‘가구 조립하기’와 같은 설명 영상들이 주목받고 있습니다. 이들 영상은 사람이 말로 설명하면서 동시에 어떤 작업을 수행하기 때문에, 직접적인 라벨링 없이도 언어와 시각 정보를 함께 학습할 수 있는 장점을 가지죠.
특히, HowTo100M 데이터셋은 1억 개 이상의 비디오-내레이션 쌍으로 구성된 대규모 데이터셋으로, 사용자가 특정 작업을 수행하면서 말로 설명하는 ‘튜토리얼’ 형식의 비디오들로 구성되어 있습니다. 이 논문은 이러한 내레이션 기반 비디오를 활용해 비디오 표현을 end-to-end로 학습하는 것을 목표로 하며, 그 과정에서 등장하는 문제점인 “비디오와 내레이션 간의 정렬 불일치 문제(misalignment)” 를 해결하고자 합니다.

그럼 여기서 misalignment란 무엇일까요? 위 그림 1을 통해 설명드리겠습니다. 상단에는 실제 사용자가 작업을 수행하는 비디오, 하단에는 해당 구간에서 추출된 내레이션이 있습니다. 하지만 사용자의 말은 실제 동작보다 앞서거나 늦게 등장할 수 있고, 때로는 동작 없이 말만 하거나, 비디오에는 나오지만 말로는 설명되지 않는 경우도 존재합니다. 이러한 비정렬된 학습 데이터를 그대로 사용하면 모델이 잘못된 연관성을 학습할 수 있기 때문에, 이에 대한 대응이 필요합니다.
저자들은 이러한 문제를 해결하기 위해, MIL-NCE (Multiple Instance Learning – Noise Contrastive Estimation) 라는 새로운 Loss 함수를 제안하였습니다. 이 Loss는 하나의 비디오 클립에 대해 주변 시간대의 여러 내레이션을 함께 고려하고, 이들 중 적절한 것을 선택적으로 학습하도록 설계되어 있습니다. 즉, 하나의 (비디오, 텍스트) 쌍만을 정답으로 가정하는 기존 방식 대신, 여러 개의 후보 중에서 올바른 조합을 구별해내는 방식으로, 비정렬된 데이터 상황에서도 강건하게 학습할 수 있는 구조입니다.
이러한 방식으로 학습된 비디오 표현은 별도의 라벨 없이도 다양한 다운스트림 비디오 인식 태스크에서 기존 self-supervised 방식이나 일부 fully-supervised 모델을 뛰어넘는 성능을 기록하였습니다. 지금부터 이 논문에서 제안한 핵심 아이디어와 실험 결과에 대해 차례로 리뷰해보겠습니다.
2. Leveraging Uncurated Instructional Videos
Uncurated 내레이션 비디오로부터 라벨 없이 텍스트-비디오 간 의미적 관계를 학습하는 방법에 대해 설명드리겠습니다. 학습 데이터는 3.2초짜리 비디오 클립과 최대 16단어로 구성된 내레이션 쌍으로 구성되며, 의미적으로 유사할 경우 가까운 임베딩 공간에 위치하도록 학습하는 것이 목적입니다. 마치 Contrastive Loss와 같죠? 다만 저자는 기존 Contrastive loss는 비디오와 내레이션 사이의 misalignment를 고려하지 못한다는 문제에 집중하였습니다.
따라서 이러한 문제를 해결하기 위해, 하나의 정답 쌍이 아닌 여러 개의 정답 후보를 고려하는 Multiple Instance Learning 기반 접근법을 도입하였습니다. 이는 하나의 비디오에 대해 주변 시간대의 여러 내레이션을 positive 후보로 설정하고, 이 중 일부만 실제로 의미적으로 연관되어 있을 수 있다는 전제를 둡니다. 이를 반영한 Loss 함수가 바로 MIL-NCE (Multiple Instance Learning and Noise Contrastive Estimation)이며 수식은 다음과 같습니다:
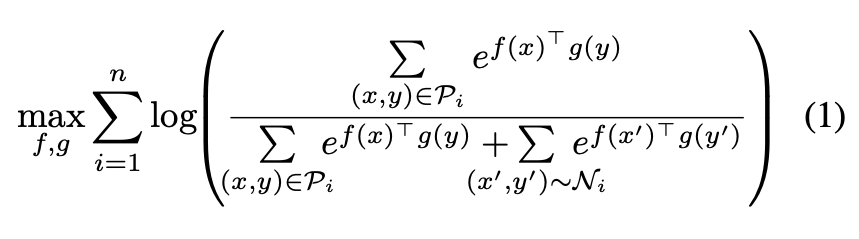
여기서 x는 비디오클립, y는 해당 클립에 대응하는 내레이션을 의미합니다. f(x)는 비디오 인코더를 통해 얻은 비디오임베딩이며, g(y)는 텍스트 인코더를 통해 추출한 내레이션 임베딩이죠. 또한 P_i는 하나의 비디오와 그 주변 내레이션들로 구성된 positive 후보 집합, \mathcal{N}_i는 negative 쌍을 의미합니다. 이 수식은 정답 후보들의 유사도 합을 전체 유사도 대비 최대화하는 방식으로, noisy한 데이터에서도 안정적인 학습이 가능하도록 설계되었다고 합니다.
2.1. A simple joint probabilistic model
해당 파트에서는 텍스트와 비디오를 동일한 임베딩 공간으로 투영하고, 의미적으로 관련 있는 쌍이 높은 유사도를 갖도록 유도하는 모델을 정리하였습니다. 이후 저자가 제안하는 MIL-NCE 손실 함수는 이 확률 모델을 기반으로 구성됩니다. (2020년 논문이다보니 지금과는 좀 서술 방식이 달라서, 리뷰에는 글머리표를 사용해서 핵심만 정리하고 넘어가겠습니다)
- x: 비디오 클립
- y: 내레이션 (텍스트)
- f(x): 비디오 인코더가 출력하는 d 차원 비디오 임베딩 ex. CNN 기반 인코더 (예: I3D, S3D)
- g(y): 텍스트 인코더가 출력하는 d 차원 내레이션 임베딩 ex. word2vec 임베딩 기반으로 문장을 단일 벡터로 변환하는 간단한 인코더
- 비디오와 텍스트 간의 유사도는 두 임베딩 벡터의 내적을 통해 측정되며, 수식은 아래 (2) 와 같습니다
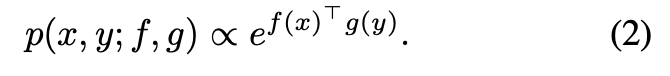
2.2. Learning from uncurated data: MIL-NCE
저자는 비디오와 내레이션이 정확히 정렬되어 있지 않은 비정제(Uncurated) 비디오 데이터에서 학습하기 위해, MIL-NCE(Multiple Instance Learning – Noise Contrastive Estimation)라는 Loss 함수를 제안하였습니다. 기존의 contrastive learning 방식은 하나의 정확한 (비디오, 텍스트) 쌍만을 정답으로 간주하지만, 비정제 데이터에서는 실제 의미적으로 관련된 쌍이 여러 개일 수 있기 때문에, 이를 반영한 구조가 필요하기 때문이죠.
특히 그림 1에서 확인한 것처럼 HowTo100M과 같은 내레이터 기반 비디오 데이터셋은, 사람이 말로 설명하면서 무언가를 수행하는 과정을 담고 있습니다. 하지만 이때 말과 행동이 완벽히 일치하는 경우는 드물죠. 예컨대, 사람이 “이제 나무에 사포질을 합니다”라고 말하고 실제로 사포질을 시작하기까지 몇 초간의 시차가 발생하거나, 말은 했지만 행동은 생략되기도 합니다. 실제로 *HowTo100M를 제안한 논문에 따르면 전체 클립-내레이션 쌍의 약 50%가 의미론적으로 불일치한다고 합니다.
*[ICCV 2019] Howto100M: Learning a text-video embedding by watching hundred million narrated video clips.
이를 해결하기 위해 저자들은 한 개의 클립에 대해 여러 개의 내레이션 후보 {y₁, y₂, …, yₖ}를 정답으로 설정할 수 있도록 학습을 설계하였습니다. 이 방식은 Multiple Instance Learning (MIL) 개념을 활용하여, 하나의 클립이 복수의 정답 후보를 가질 수 있게 하며, 이 중 일부만 실제로 올바른 정답이라 하더라도 효과적으로 학습할 수 있게 만들죠
이게 무슨 의미인지 조금 더 자세한 설명을 추가해보겠습니다. 데이터셋에 존재하는 건 비디오 클립과 해당 시점에 함께 제공된 내레이션입니다. 문제는 정확히 어떤 프레임이 어떤 단어와 대응되는지는 알 수 없다는 거죠. 이 문제를 해결하기 위해, 저자는 “여러 개의 후보 중 하나는 맞을 것이다”라는 가정을 도입하였습니다. 즉, 특정 비디오 x_i에 대해 주변의 여러 텍스트 클립 \{y_{i1}, y_{i2}, ..., y_{ik}\}을 positive 후보군 \mathcal{P}_i로 묶습니다. MIL-NCE는 이 중 하나 이상은 의미적으로 관련이 있을 것이라고 가정하고 학습을 진행하는 방식입니다. 반대로, 전혀 다른 비디오에서 가져온 텍스트, 또는 무관한 문맥의 비디오-텍스트 조합은 의미적으로 관련이 없다고 보고 negative로 사용하게 됩니다.
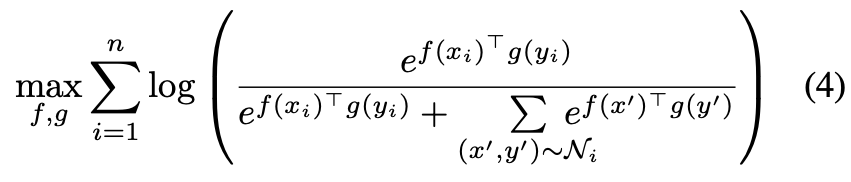
수식 (4), 기존 방식이 exp(f(x)ᵀg(y)) 형태로 하나의 쌍 유사도를 고려하는 반면, MIL-NCE는 이 유사도를 복수 후보 쌍에 대해 합산하여 ∑ₖ exp(f(x)ᵀg(yₖ)) 형태로 확장하였다고 합니다. 이를 통해 한 클립이 여러 내레이션 후보 중에서 하나라도 잘 맞으면 학습이 가능해지는 구조로 변경되게 되는 것이죠.
이후 학습은 Noise Contrastive Estimation (NCE) 방식을 적용하여, 위에서 언급한 다중 positive 후보들과, batch 내 다른 비디오/텍스트로 구성된 negative 쌍들과의 구분 학습을 수행합니다. 즉, positive 후보군 P_i와 negative 샘플들인 N_i에 대하여 수식(4)를 최적화 하게 되빈다.
3. Experiments
Implementation details

학습데이터는 HowTo100M 데이터셋을 사용하여 수행되었습니다. 이 데이터셋은 약 120M 개의 비디오-내레이션 쌍을 사용하였으며, 각 쌍은 타임스탬프를 기반으로 3.2초 길이의 비디오 클립과 해당 내레이션으로 구성됩니다 비디오 길이가 5초보다 짧은 경우는 대칭적으로 연장하여 처리하였다고 합니다.
또한 각 클립-내레이션 쌍에 대해, 시간적으로 가까운 내레이션을 기준으로 positive candidate pair를 구성하였습니다. 예를 들어, 3개의 candidate를 사용할 경우 (x, y), (x, y₁), (x, y₂)와 같이 주변 내레이션도 positive로 포함된다고 하네요. Negative pair는 간단하게 같은 배치 내 다른 샘플들 간 조합으로 구성됩니다.
Downstream tasks
저자들은 제안한 비디오 표현의 일반성을 확인하기 위해, 총 5개의 서로 다른 유형의 다운스트림 태스크에서 성능을 평가하였으며, 이 평가에는 총 8개의 데이터셋이 사용되었습니다.
- Action Recognition
- 데이터셋: HMDB-51, UCF-101, Kinetics-700
- Text-to-Video Retrieval
- Text-to-Video Retrieval
- 데이터셋: YouCook2, MSR-VTT
- 태스크: 주어진 텍스트 설명에 가장 잘 맞는 비디오를 검색
- 평가지표: Recall@K (K=1,5,10), Median Rank (낮을수록 좋음)
- 특이사항: 학습에는 해당 테스트 데이터셋을 사용하지 않음. 즉, zero-shot 조건에서 평가됨
- Action Localization
- 데이터셋: YouTube-8M Segments
- 목적: 비디오 내에서 특정 행동이 발생하는 구간을 찾기
- 평가지표: mAP (mean Average Precision)
- Action Step Localization
- 데이터셋: CrossTask
- 목적: 복잡한 작업 과정을 단계별로 분할 및 인식
- 평가지표: Average Recall (CTR)
- Action Segmentation
- 데이터셋: COIN
- 목적: 비디오를 시간 축에 따라 행동 단위로 프레임 단위 분할
- 평가지표: Frame-wise Accuracy (FA)
3.1 Comparison to the state-of-the-art
Video only representation
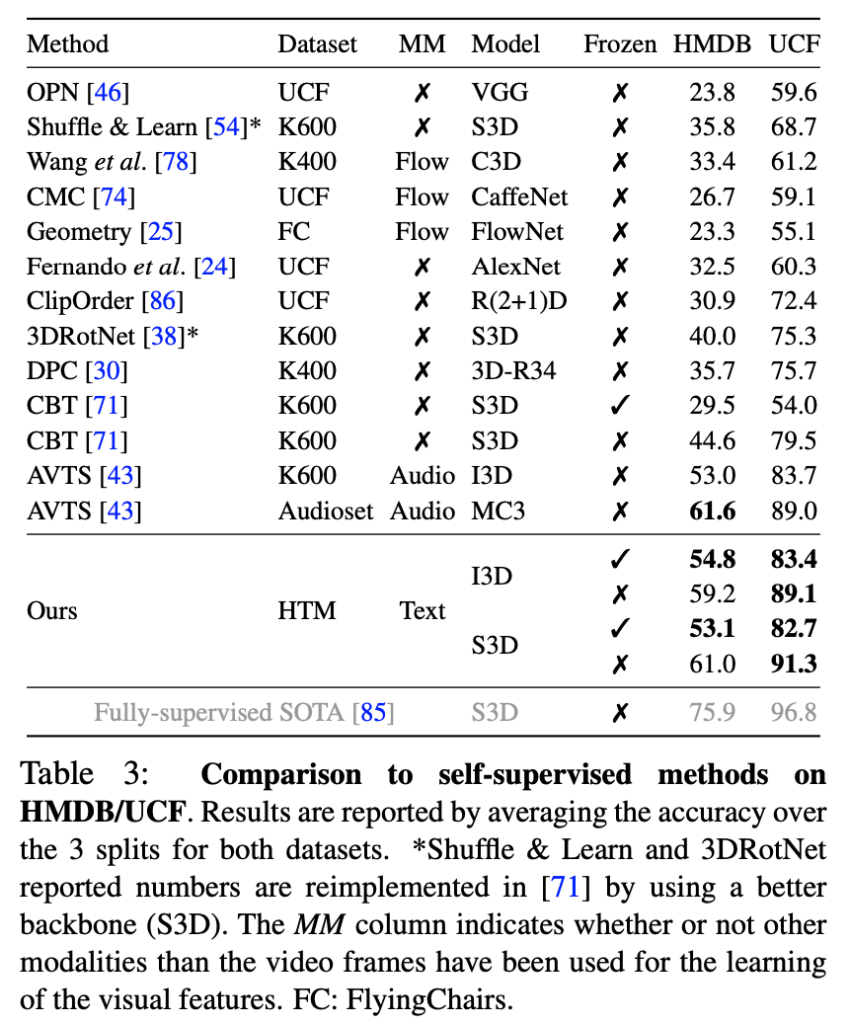
먼저, HMDB-51과 UCF-101 데이터셋을 활용한 Action Recognition 실험인 Table 3에서는, HowTo100M에서 학습데이터로 사용했을 때의 평가 결과입니다. 학습에는 어떠한 레이블도 사용하지 않았음에도 불구하고, UCF-101에서는 기존 self-supervised 방식 중 최고 성능을 기록하였으며, HMDB-51에서도 AVTS 등과 비교해 유사하거나 더 나은 성능을 보였습니다. 특히 I3D 또는 S3D 백본을 사용하는 경우 모두에서 기존의 ImageNet이나 Kinetics 기반 fully-supervised 모델과 유사한 수준의 정확도를 기록했다는 점은 MIL-NCE로 학습된 표현의 일반화 능력이 매우 우수하다는 것을 보여주는 결과죠

Table4(a)에서는 Action Segmentation 태스크인데, COIN에서도 MIL-NCE로 학습된 비디오 표현이 좋은 성능을 보였습니다. Kinetics나 ImageNet으로 학습된 모델보다 높은 frame-wise accuracy를 기록하였으며, 심지어 Table 4(d) CrossTask에서의 step localization 태스크에서도 기존 SOTA인 CrossTask 모델을 능가하는 성능을 달성하였다고 합니다. 이는 저자들의 표현 방식이 coarse한 비디오 수준의 레이블이 아닌, 시간적으로 세밀하게 정렬된 내레이션 기반으로 학습되었기 때문이라는 해석이 가능하다고도 언급하였습니다.
또한 Table4(b) YouTube-8M Segments 데이터셋에서는, MIL-NCE 모델이 기존 fully-supervised 백본들보다 높은 mAP를 기록하며 우수한 전이 학습 성능을 보여주었습니다. 특히 이러한 성능은 별도의 라벨 없이, 오직 자동 생성된 내레이션 텍스트와 시각 정보만으로 학습한 결과라는 점이 의미있는 결과라고 합니다.
Table 4(c) Kinetics-700에 대한 전이 학습 실험에서도, 무작위 초기화나 ImageNet 기반 초기화보다 MIL-NCE를 통한 사전 학습이 더 높은 성능을 보였습니다. 특히, I3D 백본에 MIL-NCE로 학습된 가중치를 초기화한 경우, 무작위 초기화 대비 4%, ImageNet 대비 1.4% 향상된 정확도를 달성하였습니다.
Joint text-video representation.
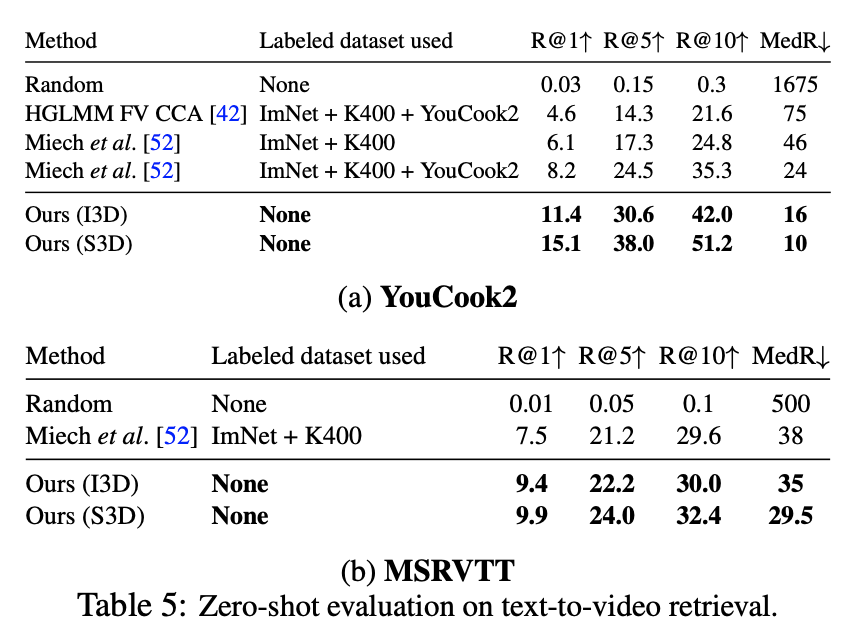
마지막으로 Table 5, 텍스트-비디오 임베딩을 활용한 zero-shot 검색 태스크에서도 MIL-NCE가 우수한 성능을 보였는데요. YouCook2와 MSR-VTT 데이터셋 모두에서, 기존 Kinetics + ImageNet 기반의 사전학습 모델을 뛰어넘는 성능을 보였고, 특히 YouCook2에서는 이전 최고 성능 대비 R@1이 15.1로 크게 향상되었습니다. 주목할 부분은 이 모델이 YouCook2나 MSR-VTT를 전혀 학습에 사용하지 않았다는 점으로, 일반화 성능 측면에서 매우 우수함을 보였다고 합니다.
실험 결과, MIL-NCE가 비정제 내레이션 비디오로 다양한 비디오 이해 태스크에서 강력한 성능을 낼 수 있음을 입증하였고, self-supervised 방식의 새로운 가능성을 제시한다고 해석할 수 있을 것 같습니다.
Summary
본 논문은 별도의 라벨 없이도 대규모 비디오-텍스트 쌍에서 비디오 표현을 학습할 수 있는 방법론을 제안하였습니다. 기존의 self-supervised 방식들이 curated 데이터셋이나 사전 학습된 표현에 의존했던 반면, 저자들은 noisy하고 misaligned된 내레이션 기반의 비디오 데이터를 직접 활용하여 학습을 수행하였죠.
이를 위해 저자들은 Multiple Instance Learning과 Noise Contrastive Estimation을 결합한 MIL-NCE Loss를 제안하였습니다. 이 Loss는 하나의 클립에 대해 복수의 텍스트 후보를 positive로 처리함으로써, 비디오와 내레이션 간의 시간적 불일치 문제를 완화할 수 있도록 설계되었습니다. 실험 결과, MIL-NCE는 다양한 다운스트림 태스크에서 기존 self-supervised 방식은 물론, 일부 fully-supervised 방식보다도 더 우수한 성능을 보였습니다
기존 Video-Text Retrieval 논문을 읽다가 MIL-NCE Loss에 궁금해서 알아보게되었습니다. 기존 Contrastive Loss의 한계를 언급하고, 데이터셋에 적절한 해결책을 아주 간단한 방식으로 해결하였다는 점이 역시 Simple is best 지 않나 싶네요
안녕하세요, 주영님. 좋은 리뷰 잘 읽었습니다.
비디오와 내레이션 간의 정렬 불일치 문제를 이렇게 간단하게 해결한 방식이 신기하네요.
본문에서 설명하신 학습 방식과 관련해 궁금한 점이 있어 질문드립니다.
하나의 클립에 대해 시간적으로 가까운 여러 개의 내레이션 후보를 생성한다고 하셨는데, 같은 비디오 주제에서 추출된 클립과 내레이션이라 유사성은 있을 것으로 보입니다. 하지만 정확한 매칭은 어려울 수도 있다는 생각이 들었습니다.
이와 관련해, 자막과 세 개의 내레이션 후보를 모두 positive pair로 간주한다고 이해했는데, 맞을까요? 혹시 더 정확한 클립-내레이션 매칭을 위해 사용된 추가적인 기법이나, 이에 대한 저자의 언급이 있었는지도 궁금합니다.
감사합니다!
질문이 좀 여러 개인 것 같아서 쪼개서 답변드리겠습니다.
일단 이해하신 것처럼 본 논문에서는, 하나의 클립에 대해 시간적으로 가까운 여러 개의 내레이션 후보를 Positive 후보 집합(P)으로 간주합니다. 예를 들어 클립 x에 대해, x와 가장 가까운 시점의 내레이션 y 외에도, 그 주변 시점의 내레이션 y1, y2 등을 함께 positive candidate로 포함시키는 방식이죠.
1. 그럼 이 후보들이 모두 Positive Pair인가요?
정확히 말하면, “모두가 진짜 정답일 것이다”라고 가정하지는 않습니다. MIL-NCE 방식은 이 중에서 하나 이상이 올바른 매칭일 것이라는 가정 하에 학습을 진행합니다.
2. 정확한 매칭을 위한 추가 기법이 있었나요?
애초에 정렬되지 않아 정확하게 매칭하기 어려운 비디오-텍스트 데이터셋의 misalignment 문제를 해결하기 위한 것이 해당 논문의 메인 아이디어 입니다. 해당 질문에 대한 답변은 추후 연구에서 이루어져야할 문제가 아닌가 싶네요