안녕하세요, 오늘 소개드릴 논문은 Video-R1입니다. Github 에서는 본 논문을 [?the first paper to explore R1 for video] 라고 소개하고 있습니다. 즉, 저자들은 본 논문을 DeepSeek-R1에서 처음 제안한 R1 페러다임을 비디오에 활용한 첫 논문이라고 홍보하고 있네요. 그렇다면 R1 페러다임이 무엇인지, 어떻게 비디오 도메인에 이를 활용하는지 알아보겠습니다.
강화학습이 세상을 모사하는법
내용에 들어가기 앞서, 논문에서 사용되는 용어를 이해하기 위해 강화학습에 대한 간단한 컨셉을 소개하겠습니다. 일반적인 지도학습은 세상을 모사하는 파라미터를 찾기 위해 학습 데이터를 활용하여 목적함수에 최적화 되도록 파라미터를 업데이트합니다. 이때, 학습 데이터가 세상에 존재하는 모든 데이터를 대표한다는 가정이 전재되어 있습니다. 반면 강화학습은 미래의 상태는 현재의 상태만을 반영한다는 마르코프 과정의 정의를 기반으로, 학습 데이터를 통해 세상을 모사하는 것을 목표로 합니다. 이때 매번의 샘플링(관찰, 하나의 iteration)을 통해 세상에 대해 모사한 파라미터들을 업데이트 합니다. 해당 과정은 학습 데이터게 세상에 존재하는 모든 데이터를 대표한다는 가정이 없어, 적은 데이터로 학습할 때 더욱 유리합니다.
세상에 대해 모사하는 파라미터 설계는 지도학습과 강화학습이 서로 다른데요, 일반적으로 지도학습은 설계된 모델 구조에 맞는 파라미터 θ 집합을 하나 도출하게 됩니다. 반면 일반적인 강화학습은 agent와 environment라는 개념이 나뉘는데, state와 value를 통해 세상(enviroment)을 모델링하고, agent가 enviroment에서 최적의 선택을 하도록 최적의 policy를 찾도록 설계됩니다. 이때 value는 reward를 기반으로 생성됩니다. 예를 들어 agent가 세종대 학생이라고 하고, 어린이대공원에서 대양AI센터까지 최단거리로 가야하는 문제를 강화학습을 통해 해결한다고 합시다. 그렇다면 학생이 이동할 수 있는 면적이 enviroment가 되고, 각 좌표가 state가 됩니다. 학생이 100번의 등교를 통해 각 좌표가 최단거리로 대양AI센터에 도착할 가능성을 value로 모델링한다면, 학생만의 policy를 학습할 수 있게됩니다. 예시를 통해 강화학습의 용어에 조금 친숙해져 보았습니다. 다음으로 본 논문의 비디오 추론(Video reasioning)을 위해 활용하고자 했던 RL 패러다임인 R1 페러다임의 컨셉을 알아보겠습니다.
R1 페러다임
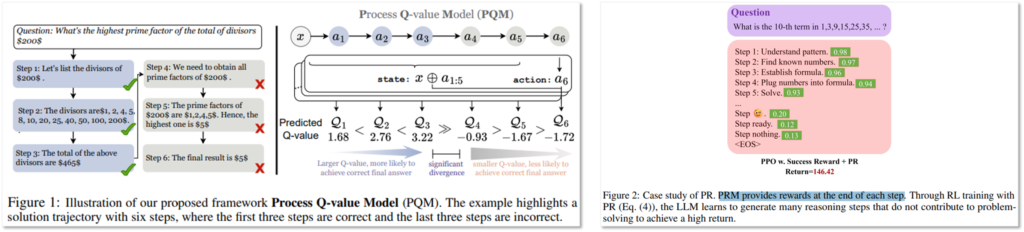
R1 페러다임은 간단히 말하면 추론 문제(Reasoning)를 간단한 RL(강화학습, Reinforce learning)을 통해 해결하는 방식입니다. 최근에는 LLMs(Large Language Models)을 활용하여 추론 문제를 해결하고자 했습니다. [Fig. A]는 기존의 추론 문제 해결 방식인데요, 우선 우측은 Process-supervised Reward Model (PRM) 방법의 예시로, 추론의 매 step 마다 리워드를 지도학습 방식으로 제공해 학습하는 방법입니다. 좌측도 마찬가지로 Q-value라는 agent가 수행하는 action에 의한 보상을 설계하여 학습하고 있습니다. 이처럼 기존 방법은 agent가 환경에서 어떠한 추론을 할지 설계할 때, 그 생각을 단위(step)마다 학습했기에 어려웠습니다. 특히 Reward를 명확하게 정의하기 힘든것이 문제였는데요, 예를 들어, 세종대학교 학생이 하나의 agent라면, 어린이대공원 역에서 대양AI 센터로의 최단거리를 찾기 위해 매 걸음(step)마다 지금 당장 오른쪽으로 가야할지(action1), 왼쪽으로 가야할지(action2)를 선택해야하고, 이 선택에 따른 reward를 정의하기가 어려웠습니다. 반면 R1 페러다임은 최종 정답값 만으로 RL 설계를 하여 기존 설계의 어려움을 해결했습니다. 즉, step 마다 reward를 계산하는 것이 아닌, 모든 action(한걸음)을 수행하여 하나의 event가 완료되었을때(대양 AI센터 도착, 상황 종료)만 보상을 설계하여 유의미한 Reasoing 경로를 설계해 문제를 해결한 것입니다.
왜 그들은 Video-R1을 제안해야만 했는가
그렇다면 왜 기존의 DeepSeek-R1 알고리즘이 아닌 Video-R1으로 비디오 추론(Video reasoning)문제를 해결해야 할까요? 저자들은 그 이유로 다음의 기존 방법이 갖는 2가지 한계를 제시합니다: 시간축을 고려하지 않는 Policy optimization 설계, high-quality video reasoning training data의 부족.
기존의 R1 알고리즘은 GRPO(Group Relative Policy Optimization)라는 최적의 policy 탐색 과정을 활용했습니다. 매 스탭마다 value를 업데이트 하도록 설계하여, 매 action 마다 최종 목적에 적합한지 reward에 대한 고려를 해야하는 기존의 Q-learning과 다르게, GRPO는 group 기반으로 학습하여, 한번에 여러 이벤트(action의 집합)를 수행하고, 이벤트 그룹에서 가장 큰 최종 reward를 얻는 예제에 보상을 부여하는 방식으로 간단하고도 높은 성능을 보이는 강화학습 알고리즘입니다.
하지만, 해당 알고리즘(GRPO)은 이미지-텍스트 입력을 기반으로 설계되어, 시간에 대한 고려가 없었습니다. 즉, 비디오 내의 한 프레임만이라도 질의에서 추론하는 상황이 탐지되면, 이것이 최종 결과에 영향을 미치는 shortcuts 현상이 발생했습니다. 아래의 [Fig.B]를 보면 “옥색(cyan)큐브가 장면에 들어왔는가”라는 질문에 GRPO는 No라고 대답하고 있습니다. 이미 옥색 큐브가 포함된 장면을 기반으로, 완전한 이해가 아닌 특정 프레임의 정보를 통해 답변을 생성한 것입니다. 반면 제안하는 방법론은 시간축을 고려하여 옥색 큐브가 장면으로 들어가고 있음을 정확히 추론할 수 있음을 보였습니다.
shortcuts 현상: 모델이 문제를 진짜 이해하지 않고 겉모양(표면 정보)만 보고 쉽게 정답처럼 보이는 방식으로 추론하는 현상.

시간축을 고려하는 T-GRPO 알고리즘 뿐 만 아니라, 저자들은 새로운 데이터셋을 제시했습니다. 이들은 기존 DeepSeek-R1의 알고리즘과 동일하게 학습의 2 단계 (Supervised Fine-tuning, RL datasets)를 위한 데이터셋 2가지(Video-R1-COT-165k, Video-R1-260k)를 제안하였습니다.
정리하면, 저자들은 DeepSeek R1 페러다임을 비디오 추론 분야로 확장하기 위해, 비디오 도메인 특성에 적합하게 시간축을 고려하는 정책 업데이트 방식(T-GRPO)를 제안하였으며, 비디오 도메인의 R1 페러다임 알고리즘 학습에 적합한 데이터셋을 제시하여, 도메인 맞춤형 R1 페러다임 솔루션인 Video-R1-7B 모델을 설계한 것입니다.
제안된 데이터셋
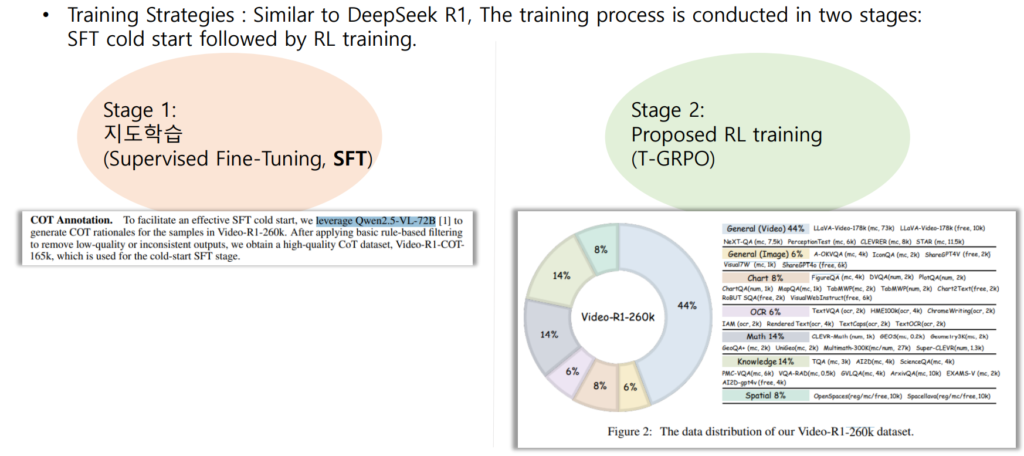
Video-R1-260k: 본 논문에서는 기존의 Video Reasoining(비디오 추론) 학습을 위한 데이터셋의 부재를 해결하기 위해 기존의 7 타입의 데이터셋(Video, Image, Chart, OCR, Math, Knowledge, Spatial)을 통합한 Video-R1-260k 데이터셋을 제안합니다. 저자들은 \혼합형 데이터셋으로 강화학습의 Reward 설계에 적합한 혼합형 데이터셋을 설계하여 다양한 reasoining 패턴을 학습하고자 했습니다. 특히 이미지 QA(Question answering)에 활용되는 데이터셋을 통해 추론의 정확도와 다양성을 높이고 있으며, 이를 ablation study로 검증했습니다.
Video-R1-COT-165k: 저자들은 DeepSeek-R1 알고리즘의 1단계 학습인 Supervised Fine-tuning 스테이지(초기학습)를 학습하기 위해 수집한 Video-R1-260k에서 추론 라벨링을 생성할 수 있는 고품질 데이터셋을 선별해 Video-R1-COT-165k를 제안했습니다. 이는 Video-R1-260k에서 Qwen2.5-VL-72B 모델로 라벨을 CoT 라벨을 생성하였고, 이후 저품질의 데이터를 제거한 것입니다.
제안된 알고리즘

제안된 알고리즘인 T-GRPO는 위의 수식처럼 매우 간단합니다. 기존에 event의 집합인 group 기반 reward(r_i)를 생성했었는데, 해당 이벤트들을 수행할 때, 비디오 입력의 shuffle을 통해 시간축의 정보를 손실한 입력에 대한 예측의 성공 확률(p~), 시간축을 보존한 입력에 대한 예측의 성공확률(p)보다 낮게되도록 설계한 것입니다. 즉 p가 p~보다 큰 policy에 최적화 되도록, 해당 policy를 수행할 때, reward, r_t를 추가적으로 받도록 설계한 것입니다.
실험
제안 알고리즘의 유효성 검증을 위한 실험은 6가지의 비디오 데이터셋에 대해 진행 되었습니다. 특히 논문에서는 데이터셋을 아래의 2타입으로 나누었습니다:
- Video Resoning Benchmark:
비디오 이해 능력을 판별하기 위한 벤치마크로 시간축을 고려한 복잡한 추론 가능성을 평가하기 위함. VSI-Bench, VideoMMMU, MMVU 데이터셋을 포함함. - Video General Benchmark:
Reasoning에 초점을 맞춘 데이터는 아니지만, 시각적 이해, 인식과 같은 일반적인 비전 문제 해결 능력을 평기하며, 비디오의 전반적인 이해 능력도 평가할 수 있음. MVBench, TempCompass, VideoMME 데이터셋을 포함함.
메인 실험:
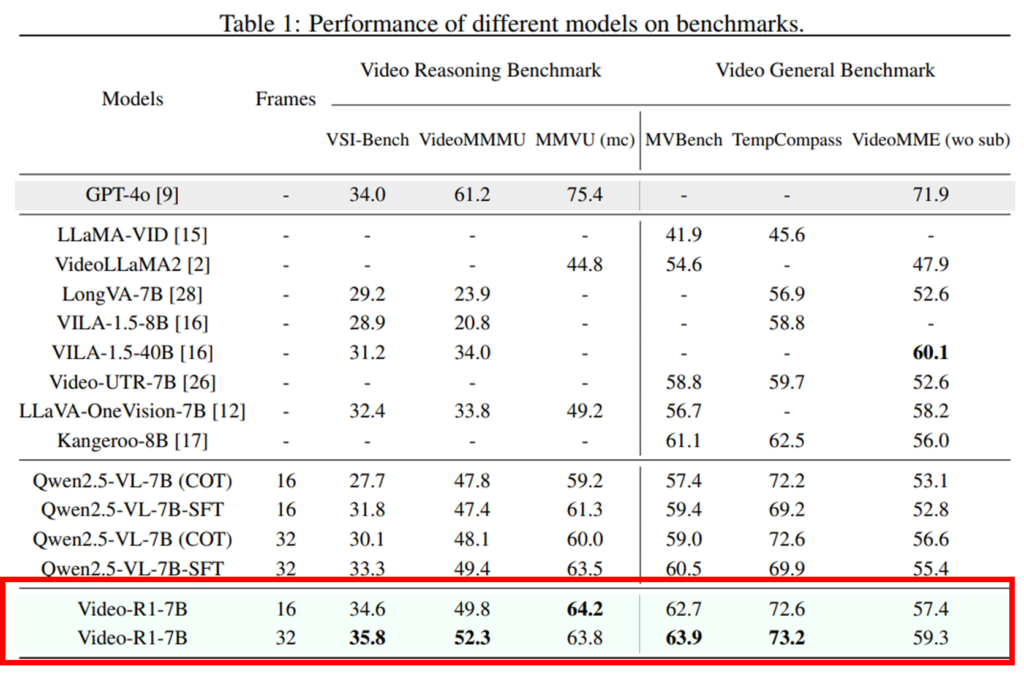
본 논문의 메인 실험인 Table1은 제안된 모델이 기존 모델 대비 성능을 보여줍니다. 특히 7B의 작은 오픈소스 모델로 일부 데이터셋(VSI-Bench)에서는 GPT-4o을 능가하는 성능을 보였다는 것에 의미가 있다고 강조합니다. 또한 베이스라인 모델인 Qwen2.5-VL-SFT를 통해 동일 세팅(16, 32 프레임 사용)에서 기존 대비 높은 성능향상을 보였습니다. 기존 연구들에 Frame이 표시되지 않은 이유가 직접적인 언급은 없었으나, 기존 연구대비 적은 frame으로 높은 성능을 달성함은 강조했습니다.
Ablation Study:
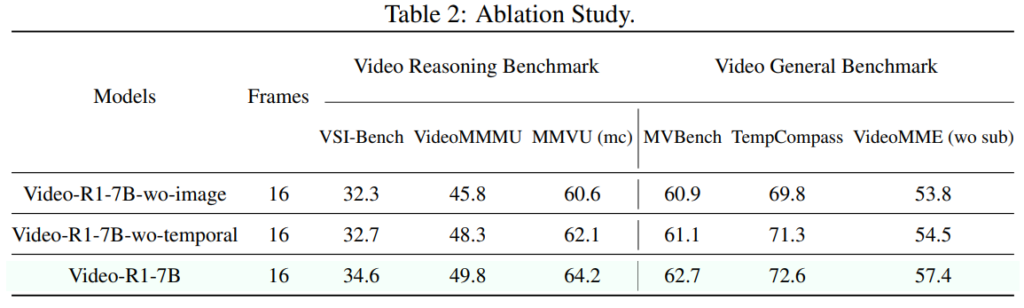
본 논문은 기존 R1 페러다임을 비디오 추론에 확장하기 위해 1) 이미지 기반 데이터셋과 비디오 기반 데이터셋을 혼합한 새로운 벤치마크를 설계했고, 2) 시간축을 고려하는 최적 policy 탐색 방법인 T-GRPO를 제시했습니다. 본 Ablation study에서는 이러한 제안점의 효과를 측정하였고, 제안 데이터셋에서 이미지 기반 데이터를 제거한 Video-R1-7B-wo-image 성능과, T-GRPO를 기존 GRPO로 대체한 Video-R1-7B-wo-temporal 성능을 최종 성능(Video-R1-7B)와 비교했습니다. 그 결과 제안한 요소들이 모두 비디오 추론에 효과적이였음을 확인할 수 있었습니다.
정성적 분석:
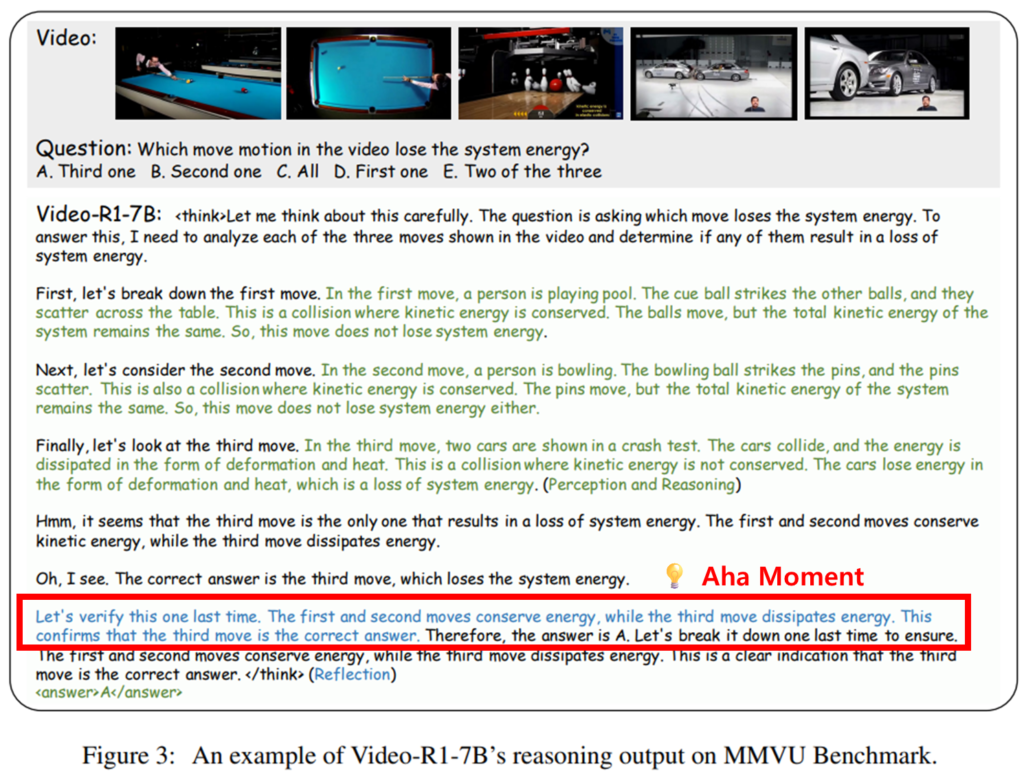
논문에서는 제안하는 Video-R1-7B 모델의 특징을 분석했습니다. 바로 Aha Moment 인데요, 모델이 스스로 추론의 정확도 여부를 판단해 Reasoning 경로를 수정하는 순간을 의미합니다. 기존 모델과 다르게 Video-R1-7B는 추론 도중 재검토를 하는 Self-reflection 과정을 통해 논리적 오류를 바로잡는 포인트가 추론에 포함됨을 확인했다고 하는데 위의 예시를 보면 이해가 쉽습니다. 먼저 질문인 손실이 발생하는 운동의 정답으로는 탄성 충돌로 에너지가 보존되는 First one, Second one은 정답이 아니고, 열손실이 발생하는 Third one(A)가 정답입니다. Video-R1 -7B는 비디오에 포함된 각 움직임에 대해 순차적으로 분석한 후(녹색 글) Self-reflection 과정(파란 글)인 Aha moment 과정을 거쳐 정답을 찾아내고 있음을 확인할 수 있습니다. 이는 모델이 내적 피드백 루프를 형성하여, shortcuts과 같은 표면적 정보를 통한 추론이 아닌, 실질적인 예측을 수행하고 있음을 보인다는 점에서 유의미 하다고 합니다.
본 논문은 비디오 추론에 기존 R1 페러다임 확장을 위해 데이터셋과 시간 고려 정책 업데이트 알고리즘을 제시하였는데요, 이를 통해 비교적 작은 모델로 다양한 데이터셋에 대해 높은 비디오 추론 성능을 보일 뿐 만 아니라, Aha moment라는 현상을 통해 기존 추론의 가장 큰 문제였던 shortcuts을 효과적으로 해결하였음을 보이고 있습니다. 아직은 citation이 없지만, 어떻게 활용이 될지 궁금해지는 논문입니다. 이상으로 논문의 리뷰를 마치겠습니다.
참조
[1] Wendi Li and Yixuan Li. Process reward model with q-value rankings. arXiv preprint
arXiv:2410.11287, 2024.
[2] Jiaxuan Gao, Shusheng Xu, Wenjie Ye, Weilin Liu, Chuyi He, Wei Fu, Zhiyu Mei, Guangju Wang, and Yi Wu. On designing effective rl reward at training time for llm reasoning. arXiv preprint arXiv:2410.15115, 2024.
본 논문은 R1 페러다임을 비디오 추론 분야에 적용하여 베이스라인을 제시한 논문입니다. 해당 논문이 어디에 게재될 지는 잘 모르겠으나, 잘 되어서 해당 베이스라인으로 자리잡힌다면 좋겠네요. 그럼 리뷰를 마치겠습니다.
안녕하세요, 좋은 리뷰 감사합니다.
강화학습에 대한 간단한 예시와 설명이 있어서 이해하기 편했습니다
그러다 든 간단한 궁금점입니다.
“R1 패러다임이 최종 정답값 만으로 RL 설계를 하여 기존 설계의 어려움을 해결했습니다.”
라는 부분에서 기존의 강화학습이 step 마다 -1의 reward를 주고 최종 목적지에서 +100의 reward 를 주는 방식에서 그냥 모든 action을 포함하여 결론에 도출한것에 reward를 주는 방식이면 최단경로는 학습해내지 못할 것 같은데 어떤식으로 해결이 되는건지 예시가 있었으면 좋겠습니다.
감사합니다.
안녕하세요 신인택 연구원님
댓글 감사합니다. R1 페러다임은 이벤트의 집합으로 학습하는 GRPO 방식을 차용합니다. 따라서 최종 목적지에 도달하거나 혹은 도달하지 못하고 종료된 시행들 중에서, 이동 경로가 가장 짧았던 시행에 리워드를 주는 상대적인 측정 방식으로 점차적으로 최적 정책에 도달 할 수 있습니다.
예를 들면 S(시작 스테이트, 어린이대공원역), T1(종료 스테이트1, 대양AI센터, 리워드+100), T2(종료 스테이트2, 앤유PC방, 리워드+0)라고 할 때, 아래의 5가지 시행(에피소드)으로 구성된 그룹을 학습할 때, Ep4가 비교군(EP1,2,3,5)들 중 가장 큰 리워드를 받도록 지속적으로 학습하면, 최단 경로를 찾는 정책을 학습할 수 있을 것 입니다.
Ep1) S->대양홀->집현관->광개토관->T1
Ep2) S->세종대 쪽문 -> T2
Ep3) S->세종대 쪽문 -> 광개토관->T1
Ep4) S->대로변->T1
Ep5) S->어린이대공원->S->T2
감사합니다.
재밌는 논문 리뷰 감사합니다.
2가지만 질문하고 갈게요.
Q1. DeepSeek-R1이 사용하는 입력 양상과 달라지면서 학습 방식에 차이가 발생 했을 겁니다. 어떤 식으로 차이가 생겼는지 알려주시면 좋을 것 같아요.
Q2. Tab 2에서 이미지 데이터를 제거하고 학습한 결과, GRPO->T-GRPO로 바꾼 결과… 마지막은 ours인데… 뭘 추가한 걸까요? 그리고 해당 실험은 뭘 보이고 싶은 건지 유추가 안됩니다.
안녕하세요, 황유진 연구원님. 좋은 리뷰 감사합니다.
제가 강화학습쪽은 잘 몰라서 재밌게 읽으면서도 이해가 쉽지 않은 부분이 있어 질문 남기겠습니다.
1. video reasoning이라는 task가 정확히 어떤 task인가요? 뭔가 비디오와 질문을 입력해서 답변을 받는 것인가요? 또 그 성능은 어떻게 측정하는지 궁금합니다.
2. 기존에 사용하던 DeepSeek-R1알고리즘이 어떤 형식으로 동작하나요?
감사합니다.