안녕하세요, 60번째 x-review 입니다. 이번 논문은 arXiv 2025에 얼마 전 올라온 DepthMaster라는 논문으로, 제가 요즘 읽고 있는 논문들과 동일하게 Marigold를 기반으로 Monocular Detph Estimation을 수행한 논문 입니다.
그럼 바로 리뷰 시작하겠습니다 !

1. Introduction
Monocular Depth Estimation(MDE)는 다른 입력 데이터를 쓰는 방식 대비 간단하고 cost가 덜 든다는 장점이 있습니다. 간단하다고는 하지만, RGB 이미지를 하나만 써서 다양한 분야에서 사용할 수 있는만큼 일반화를 달성해야 하는 task 입니다. 그런 관점에서 봤을 때 real world에서 다양한 depth 분포와 조도 환경 때문에 마냥 단순한 task라고는 할 수 없습니다.
본 논문에서는 MDE, 그 중에서도 zero shot MDE 연구를 두 갈래로 나누어서 보고 있는데, 바로 데이터 기반 / 모델 기반으로 나눕니다. 데이터 기반은 아무래도 대규모의 이미지와 depth pair 데이터를 가지고 학습을 하는데, 이때 학습에는 많은 시간과 리소스가 들겠죠. 반대로 모델 기반은 stable diffusion과 같이(본 논문에서 diffusion을 사용해서 예시로 든 느낌이 있네요) 사전학습된 모델을 사용합니다. 그 중에서 Marigold는 저도 리뷰를 하였지만 Diffusion 기반으로 zero shot MDE를 수행하는데 모델인데요, 높은 일반화 성능을 가진다고 평가받고 있습니다. 그런데 Diffusion 기반이다보니 추론 속도가 느리다는 한계가 존재하죠. 그 외에도 Diffusion 기반의 모델로 연구를 진행하곤 있지만, 생성형 feature를 discriminative task에 효과적으로 적용할 수 있는 방식에 대해서 제대로 된 연구가 진행되진 않았다고 합니다.
그래서 본 논문에서는 diffusion 모델의 feature 표현력에 대해 많은 분석을 진행하였다고 합니다. 일반적으로 Marigold 뿐만 아니라 많은 diffusion 모델이 인코더-디코더 구조와 denoising 네트워크로 구성되어 있습니다. 인코더-디코더 구조는 입력으로 들어오는 이미지를 latent 공간으로 변환하고 denoising 네트워크에서는 원본 이미지로 복원하게 되죠. 분석 결과 denoising 네트워크의 feature 표현력에 bottleneck 현상이 나타나는 것을 발견했다고 합니다. 실제로 denoising 네트워크를 사전학습할 때 사용되는 reconstruction 과정에서 모델이 데이터의 구조적인 특징보다 텍스처와 같은 의미론적인 디테일에 우선순위를 두도록 학습되어서, 이런 네트워크를 depth 예측에 사용할 때는 현실에 없을 비현실적인 depth 이미지가 만들어지게 됩니다. 따라서 Diffusion 모델을 완전히 MDE에 활용하기 위해서는 denoising 네트워크의 표현력을 향상시키고 우선순위로 두지 않아도 되는 텍스처에 대한 의존도를 줄일 수 있어야 합니다.
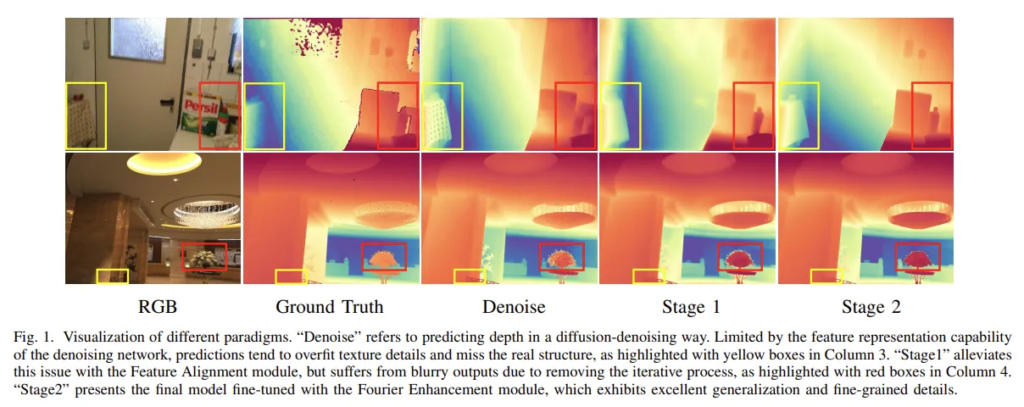
diffusion 모델의 결과는 반복적으로 refinement 과정을 거쳐서 만들어지는데요, 초기 time step에서는 모델이 전체 scene에 대한 일반적인 구조를 만드는 방법을 학습하고, 뒷단 time step에서 영역을 디테일하게 세분화하여 복구하는 방식을 학습합니다. 근데 만약에 하나의 step으로 재구성하게 되면, 모델이 한번의 forward 과정만으로 기본적인 구조와 디테일한 영역에 대해서 모두 학습해야 해서 Fig.1의 4번째 열과 같이 모호한 depth를 출력하게 됩니다. 따라서 하나의 스텝만으로 MDE를 위해 diffusion을 어떻게 하면 잘 활용할 수 있을 지도 고민해야할 부분 중 하나라고 합니다.
그래서 본 논문에서는 MDE에서 일반화와 디테일한 depth 보존이 모두 가능하도록 단일 스텝의 diffusion 모델인 DepthMaster를 제안하였습니다. 먼저 denoising 네트워크의 feature 표현력을 향상시키기 위해 높은 퀄리티의 외부 데이터를 활용한다고 하는데요, 이에 대해서는 방법론에서 더 자세하게 살펴보도록 하겠습니다. 여하튼 이렇게 사용하는 외부 데이터가 인코더를 타고 나온 feature와 diffusion 모델의 분포를 alignment 맞추기 위해 feautre alignment 모듈을 설계하였습니다. 두번째로는 반복적인 과정을 제거하려다 보니 디테일이 부족해지기 때문에 이를 해결하기 위해 푸리에 향상 모듈이라는 것을 제안합니다. 주파수 도메인에서 동작하게 되는데요, 단일 forward 과정에서 저주파의 구조적인 feature와 고주파의 디테일 feature의 균형을 조정하여 여러 time step으로 진행하던 denoising 과정을 단일 과정에서도 유사하게 동작하도록 구성하였다고 합니다. 이 푸리에 향상 모듈은 2단계 학습 방식인데, 1단계에서는 feature alignment 모듈을 사용해서 scene의 전체적인 구조를 학습하는데 집중합니다. 2단계에서 디테일한 구조를 개선하기 때문에 이렇게 2단계 학습 방식을 통해 여러 time step 과정에서 진행했던 것을 하나의 time step만으로도 가능하게 했습니다.
여기서 본 논문의 main contribution을 정리하면 다음과 같습니다.
- diffusion의 생성 feature를 depth estimation에 적합하도록 설계한 DepthMaster 제안
- 높은 퀄리티의 외부 feature를 사용해서 feature alignment 모듈과 주파수 영역에서 세분화된 디테일을 개선시키는 푸리에 향상 모듈 설계
- 다양한 데이터셋에서 타 diffusion 기반 방법론과 비교하여 zero shot 방식에서 SOTA 달성
2. Method

2.1. Deterministic Paradigm
본 모델은 사전학습한 Stable Diffusion v2를 기반으로 하되, 추론 속도를 향상시키기 위해 iterative denoising 방식이 아니라 단일 단계의 denoising 네트워크를 설계하여 MDE를 수행합니다.
먼저 RGB 이미지 I \in \mathbb{R}^{H \times H \times 3}을 식(1)과 같이 I2L(Image-to-Latent) 인코더를 사용해서 latent 공간의 벡터로 변환합니다.

- \mathcal{E} : I2L 인코더
그 다음에 만든 latent 표현을 denoising U-Net \epsilon_{\theta}에 입력으로 넣어서 타임 스텝을 1로 고정하여 식(2)와 같이 depth latent인 z_{pred}를 예측합니다.

여기서 포인트는 기존의 반복 방식이 아니라 한번에 depth를 생성한다는 것 입니다. 또한 단순한 depth가 아니라 squre-root disparity를 예측한다고 하는데요, 이는 원래 더 예측하기 어려운 근거리 depth에 대해서 정확하게 예측할 수 있도록 하며 데이터 분포를 균일하게 만들어서 학습의 효율을 높일 수 있다고 합니다.
학습은 우선 GT depth를 [-1,1] 범위로 정규화하고, I2L 인코더를 통해 동일하게 latent 공간의 표현력을 가지도록 Z_{GT}를 변환합니다. 학습 loss는 식(3)과 같이 z_{GT}와 z_{pred} 간의 차이를 최소화하도록 학습합니다.

이렇게 학습하게 되면 기존 diffusion 방식과 유사한 성능을 유지하면서도 반복적인 연산 없이 빠른 추론이 가능하도록 합니다.
2.2. Feature Alignment Module
Stable diffusion v2는 I2L 인코더-디코더 구조와 Denoising U-Net 구조로 구성되어 있습니다, 여기서 U-Net은 노이즈를 제거하면서 이미지 복원에 집중하다보니 텍스처 정보에 과하게 초점을 맞추기 때문에 실제 구조적인 정보나 다른 의미 있는 scene에 대한 이해가 약해지며 이러한 현상을 pseudo-texture 현상이라고 부른다 합니다.
이를 해결하기 위해 본 논문에서 Feature Alignment Module을 설계하였는데, 이는 의미론적인 정보를 이해하는 능력을 향상시키면서 low level의 디테일에 대한 과적합을 줄이고자 합니다. 더 자세하게 보면, 사전학습된 external 인코더 f로 DINOv2를 사용하고 있습니다. 입력 RGB 이미지 I가 들어오면, 의미론적인 정보를 담은 feature 벡터 F_{ext} = f(I) \in \mathbb{R}^{N \times D}를 생성합니다. 동시에 U-Net의 중간 단계 블럭에서 feature F_{unet} \in \mathbb{R}^{h \times w \times C}를 추출합니다. 이렇게 두 feature를 추출하고 나면 alignment를 맞추게 되는데요, F_{unet}을 MLP를 태워 F_{ext}의 feature 공간으로 변환하게 됩니다. (\bar{F_{unet}})
두 feature에 대해서 단순히 값에 대해 비교하는게 아니라 분포 자체를 비슷하게 하기 위해 두 feature 사이의 거리를 최소화하도록 하였습니다. 식(4)의 dist()가 거리를 측정하는 부분을 의미합니다.

더 자세하게는 식(5)와 같이 거리를 측정하는데 KL Divergence 방법을 사용했는데, 이는 A라는 분포가 기준이 되는 B와 얼마나 다른지를 측정할 수 있죠.

즉, 각 feature를 feature 차원 방향으로 정규화해서 확률 분포 형태로 바꾸어서 비교를 하는 것 입니다. 정규화된 이 feature 분포를 최소화하는 loss를 통해, 다시 말해서 KL Divergence가 최소화가 되도록 합니다. 이러한 과정을 통해 U-Net은 더 의미론적인 feature를 학습할 수 있고, 텍스처와 같은 low level의 정보에 과적합 되는 것을 방지할 수 있습니다.
2.3. Fourier Enhancement Module
원래의 stable diffusion은 원래 여러 time step에서 서서히 이미지를 복원하면서 디테일한 생성이 가능한데요, 본 논문에서는 단 하나의 단계에서 바로 depth 이미지를 만들기 때문에 디테일이 확실하지 않은 흐릿한 이미지가 만들어진다는 문제가 있습니다.
이를 보완하기 위해서, 바로 고주파의 세부적인 정보를 복원하는 방식을 사용했다고 합니다. 이는 Fig.2의 오른쪽 아래에서 그림을 확인할 수 있는데, 크게 spatial pass와 frequency pass로 나뉘게 됩니다. 해당 모듈이 입력은 또 U-Net의 중간 단계 feature인 F_{mid}이며 fourier transform FFT 사용해서 주파수 정보 F_{mid_f}로 변환합니다. 이렇게 주파수 정보로 변환하고 나서 \sigma(Conv())를 통과하여 주파수 채널을 고주파/저주파로 조절하여 필요한 세부 디테일을 강조하거나 억제할 수 있도록 합니다. 이렇게 주파수를 조절하여 필요한 정보를 얻고 나서는 다시 이미지 형태의 feature map으로 돌리기 위해 inverse fourier transform을 거치며, 위의 과정을 식으로 정의하면 식(6)과 같습니다.

위의 과정까지가 주파수를 이용한 frequency pass 과정이었고, 이렇게 구한 F_f를 spatial pass 과정과 식(7)과 같이 합쳐야 합니다.

- || : concat 연산
spatail pass feature와 frequency feature를 합친 다음에 다시 conv를 통과함으로써 전체적인 구조 정보와 세부 디테일 정보를 가진 최종적인 feature를 완성할 수 있습니다.
주파수 정보를 활용함으로써 단일 step만을 사용하면서 생기는 부족한 디테일 정보를 기존 diffusion처럼 재현할 수 있게 됩니다.
2.4. Weighted Multi-directional Gradient Loss
해당 과정은 만들어지는 depth map에서 엣지나 더 디테일한 부분의 구조를 잘 만들어내기 위해서 설계한 loss에 대해 설명하고 있습니다. depth를 더 선명하게 예측하기 위해서, 다양한 방향의 gradient 차이를 고려한 loss 함수를 설계하였다고 합니다. GT depth D_{GT}와 예측한 depth D_{pred}에 대해서 4가지 방향(수평, 수직, 두 방향의 대각선)의 gradient를 계산하여 결과적으로 한 픽셀 당 gradient 4개 G_{GT}, G_{pred} \in \mathbb{R}^{H \times W \times 4}를 계산합니다.
픽셀들 중에서도 전경과 배경의 경계가 포함되면 gradient가 크게 튀는 경향이 있는데요, 이렇게 크게 튄 gradient 값 때문에 학습이 불안정해지면서 모델이 세부적인 정보를 잘 학습하지 못하게 됩니다. 그래서 본 논문에서 아래 식(8)과 같이 Huber loss를 변형하여 사용합니다.

- \delta : 임계값
즉 두 gradient의 차이가 작으면 MSE loss처럼 계산하고, 차이가 크면 MAE처럼 계산하여 튀는 gradient를 완화해줄 수 있습니다. 이렇게 설계한 loss는 outlier의 영향을 줄이면서 단순히 큰 엣지에 무조건적으로 집중해서 학습하는게 아니라 작은 영역의 구조나 패턴같이 세부적인 디테일도 잘 학습할 수 있도록 유도합니다. fourier enhancement 모듈과 유사하게 예측하는 depth map이 디테일한 부분의 구조를 잘 학습도록 도와주는 것이죠.
2.5. Two-stage Training Curriculum
이제 전체적인 학습을 어떻게 하는지 살펴보면, 우선 U-Net만 fine-tuning을 하고 있습니다. 다만 latent space에서 loss를 주게 되면 전체적인 scene을 잘 이해하지만, 이미지로 넘어가서 픽셀 레벨에서 loss를 주면 디테일은 향상하지만 전체적인 구조가 왜곡된다는 것을 실험적으로 확인하였다고 합니다. 그래서 두 레벨에서 분리하여 2단계 학습 방식을 제안하고 있습니다.
먼저 첫번째 단계의 목적은 다양한 시나리오의 scene이 들어오더라도 모두 잘 작동하여 일반화된 구조를 이해할 수 있는 모델을 설계하는 것 입니다. 그래서 1단계는 latent space에 적용하는 loss를 의미하며, 식(9)와 같이 feature alignment 모듈까지 포함됩니다.

- \mathcal{L}_{latent} : latent space에서 예측된 depth와 GT 간의 차이
- \mathcal{L}_{fa} : feature alignment loss
- \lambda_{fa} = 1 : 두 loss를 동일한 가중치로 반영
그 다음 2단계에서는 1단계와 반대로 미세한 경계나 텍스처, 그리고 구조적인 관점에서의 디테일을 보완하는 것을 목표로 하기 때문에 픽셀 레벨의 MSE loss를 적용하였습니다.

정리하면 구조적인 정보는 1단계에서 찾고, 디테일한건 2단계에서 보완함으로써 본 논문에서 계속 중요시하게 여기는 전체적으로 선명하고 의미론적인 정보가 담겨있는 depth map을 생성하기 위한 2단계 학습 방식으로 동작하는 것이죠.
3. Experiments
실험은 합성 데이터인 Hypersim과 Virtual KITTI로 학습하고, 평가는 NYUv2와 ScanNet을 사용하여 zero shot 성능을 평가하였다고 합니다.
3.1. Qualitative and Quantitative Comparison


Tab.1은 다른 zero shot 기반 MDE 방법론들과의 비교 실험 입니다. 중간선을 기준으로 위쪽은 데이터 기반의 방법론이며, 아래 방법론은 diffusion 기반 방법론들을 나타냅니다. 실험 결과, diffusion 모델 기반 방법론은 상대적으로 적은 학습 양을 사용하여도 이미 large scale의 데이터에 의존하는 다른 방법론 대비 높은 성능을 보이는 것을 알 수 있습니다. 본 논문의 방법론은 diffusion 기반 중에서도 단일 단계를 이용하였음에도 불구하고 베이스 모델로 사용했던 Marigold보다 KITTI에서 AbsRel 메트릭이 17.2% 향상되는 것을 통해, 효율적인 과정을 설계함과 동시에 가장 높은 성능을 달성한 것을 확인할 수 있습니다.
정성적으로 살펴보면, 빨간색 박스로 표시한 부분을 봤을 때, 본 논문의 방법론은 놓치기 쉬운 풀잎의 모양과 같이 디테일한 부분을 잘 표현하고 있습니다. 이는 전체적인 구조를 파악하는 것 뿐만 아니라 세밀한 디테일을 잘 예측하여 흔히 생성 모델에서 발생할 수 있는 텍스처에 대한 과적합을 피한다는 것을 보여주고 있습니다.
3.2. Ablation Studies
Depth Process


여기서부터는 ablation study로, 본 논문에서는 depth가 squre root disparity를 구하였기 때문에 이에 대한 비교 실험을 진행하였습니다.
결과적으로 depth를 예측하는 것보다 disparity를 구했을 때 정확성이 향상되는 것을 확인할 수 있습니다. 이러한 결과에 대해 저자는 disparity가 전경에 대한 구조를 더 잘 파악하도록 하여 모델이 타겟으로 하는 물체에 더 집중하도록 도와주기 때문이라고 하네요. 또한 거기서 나아가 sart disparity로 예측을 하면 추가적으로 성능 개선이 이루어지는데, 이는 Fig.5에서 보여주듯이 나머지 두 예측 방식보다 균일한 깊이 분포를 생성해서 depth의 범위를 효율적으로 사용할 수 있기 때문이라고 이야기하고 있습니다.
Feature Alignment module


다음은 feature alignment 모듈에 대한 ablation study 입니다. Tab.4를 보면, 다양한 external 인코더의 feature를 사용한 결과를 나타내는데, 그 중에서도 DINOv2는 다양한 데이터셋에서 미세하지만 가장 좋은 성능을 보이고 있습니다. 하지만 아주 미세해서 DINOv2를 꼭 써야한다기보다는 이러한 external 인코더를 사용하는 것 자체의 효과를 보여주고 있는 것 같습니다.
Tab.5는 feature alignment 모듈의 위치에 따른 ablation study 입니다. 해당 논문의 U-Net은 3개의 다운샘플링 블럭과 1개의 중간 블럭, 그리고 3개의 업샘플링 블럭으로 구성되어 있는데요, 여기서 첫번째 다운샘플링 블럭에 위치시킨 것이 D1, 두번째 다운샘플링 블럭이면 D2, 그리고 중간 블럭의 feature를 사용하면 Mid라고 표에 표시하였습니다.
결과적으로 얼마나 깊은 레벨 블럭의 feature를 사용하는 지에 따라 성능이 개선되는데요, 이러한 결과에 대해서는 앞단 블럭에는 더 많은 로컬 정보와 디테일이 포함되어 있지만 중간 feature는 DINOv2, 그러니까 external 인코더의 feature와 일치하는 글로벌한 특성이 더 나타나기 때문이라고 분석하고 있습니다. 그러나 Tab.4와 마찬가지로 그렇게 눈에 띄는 성능 차이가 나타나는 것은 아니기 때문에 external feature와 U-Net의 feature를 alignment하여 같이 사용하는 모듈 자체가 효과적이라는 것만 기억하면 될 것 같네요 ..
재밌는 논문 리뷰 감사합니다.
간단한 질문만 남기고 가도록 하겠습니다.
해당 논문은 feature enhancement를 diffusion 기반의 MDE에 잘 적용하기 위한 기법을 제안합니다. 재밌는 점은 feature enhancement 연구들이 대체로 CLIP 혹은 DINO로 연구가 진행되고 있는 점을 역으로 이용하여 feature alignment라는 것으로 재풀이 했다는 점인 것 같습니다.
Q1. FFT의 참조 문헌은 어떤 논문인가요? 제가 알기로는 FFT 기반의 feature enhancement 기법들이 일반화가 어렵고 추론 속도가 느린 것으로 알고 있습니다. 안그래도 느린 방법론에 더 느리게 만들 수 있는 기법이 붙어서… 어떨지 궁금하네요…
Q2. 단일 스텝 MDE라는 뜻이 interation 없이 진행된다는 이야기인가요? 그리고 1 stage와 2 stages는 iteration이 아니라 서로 다른 가중치를 가진 U-net을 태운다는 뜻인가요???
Q3. Q2가 맞다면 굳이 diffusion 구조를 가지는 이야기 이해가 안가는데요… U-net 빼고 DINO 바로 사용해도 문제 안될 것 같은데…??? 왜 구조를 유지하는 걸까요?
Q2. asd
안녕하세요, 리뷰 읽어주셔서 감사합니다.
1. 참조 문헌은 DiffusionEdge라는 논문으로, diffusion 모델을 엣지 검출에 적용하여서 frequency domain에서 다룰 수 있는 방법론이라고 합니다. 말씀하신 것처럼 느릴 수 있는 구조라고도 생각이 들지만, 우선 논문에서는 속도 관련한 언급은 없었습니다. 또한 2D Fast Fourier Transform을 사용했다고 하기도 하고, 기본적으로 단일 스텝 구조에 U-Net 구조 중간 feature에만 적용을 하는거라 연산 비용을 비교적 적게 유지할 수 있었던 것 같습니다.
2. 말씀하신 것처럼 diffusion step을 1로 고정해서 바로 depth를 예측하는 것이 맞습니다. 다만 두 stage에 대해서는,
우선 feature alignment module에 대해서만 학습을 하고, fourier enhancement 모듈과 픽셀 레벨 loss + gradient loss를 추가해서 학습하는 방식으로 나누는 것을 2단계 학습으로 표현합니다. 즉 동일한 네트워크를 사용하지만 loss function이 다르게 두 단계로 나뉘어 학습을 하게 됩니다.
3. 저도 그 부분이 의문이긴 한 것이 실제로 해당 논문에서도 DINOv2를 feature alignment에 사용하고 있기도 하고 구조 상 U-Net만 fine-tuning 하고 있긴 합니다. 그럼에도 diffusion 구조를 사용하는 이유를 생각해보면 .. latent space에서 동작하면서 U-Net 구조를 기존의 노이즈 제거 목적이라기보다는 의미론적인 정보 추론에 더 잘 활용하기 위해 가져다 사용하고 있다고 생각합니다. 사실 denoising 과정과 샘플링 과정이 모두 없어서 diffusion의 기능 자체를 사용했다기 보다는 구조를 가져다가 변형했다는 표현이 더 맞을 것 같습니다.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
제가 예전에 Depth Pro나 Depth Anything (DPTv2)과 같은 논문들에 대해 리뷰한 적이 있고, 또 수행 과제에서 MDE를 수행할 일이 있어 의문을 가지게 된 점인데, 보이는 실험 테이블에서 물론 몇몇 수치들이 DPTv2보다 아주 일부 높긴 하지만 이들이 Data-driven과 Model-driven을 따로 구분 짓는 이유가 있을까요?
또한, 이건 실제 제가 써볼 수 있을까 하는 의문점에서 속도 측면에선 어떤가요? 제 경험 상으로는 Depth Pro가 0.3초 내에 1536×1536이미지를 MDE하는데, 여기서 속도에 대한 측면은 따로 언급은 없는 듯 하고 또 Diffusion-based인 상태에서 속도는 느리지 않을까 하는 의문이 생겨 질문드립니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
테이블에서 data-driven과 model-driven으로 나누어 놓은 것은 사실 인트로에서 이야기한 것의 연장선으로 표현했다고 보는게 맞을 것 같습니다.
대규모의 데이터로 학습한, 저희가 흔히 아는 VFM들을 data-driven이라고 하고 그 보다 적은 데이터셋 여기서는 diffusion 기반의 모델들을 비교를 위해 model-driven이라고 구분짓고 있습니다.
속도는 본 논문이 어떨진 모르겠습니다만, 베이스 모델로 사용하는 Marigold는 대략 한 장 정도 처리하는데 5-10초 정도 걸린다고 보시면 됩니다. 해당 논문은 빠르다는 것을 어필하긴 했지만 속도에 대해서는 리포팅하진 않네요. 제가 읽은 Diffusion 기반 MDE 모델들도 속도에 대해서는 암묵적으로 잘 리포팅하진 않았던 것 같습니다.
감사합니다.
안녕하세요, 좋은 리뷰 감사합니다.
Fourier enhancement 모듈에서 주파수를 조절하여 필요한 정보를 얻는다고 하셨는데, 푸리에를 통해 얻고자 하는게 세부적인 구조라고 이해했습니다만 .. 주파수 채널 중에서 고주파/저주파 채널을 조절하여 필요한 정보를 모두 얻는다고 하면, 공간적인 정보와 세부 정보가 모두 포함되어있다고 볼 수 있지 않나요 .. !? 따로 spatial pass에서 얻는 정보와 차별점이 무엇인지 조금만 더 자세히 설명 부탁드립니다!
감사합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
주파수 채널에서 주파수를 조절하는 것은 필요로 하는 주파수 레벨에서의 디테일을 강조하거나 억제하기 위함 입니다. 얻고자 하는 것은 전체적인 공간에 대한 정보라기보다는 diffusion에서 단일 스텝을 사용하면서 부족해지는 세부적인 detail 정보라고 생각해주시면 될 것 같습니다. spatial pass는 단순하게 주파수로 변환한 것이 아닌 latent level에서의 정보를 의미하기 때문에 얻을 수 있는 정보가 다르다고 볼 수 있습니다.
감사합니다.