안녕하세요. 이번 리뷰는 세미나에서 소개드린 LLaVA-PruMerge입니다. 세미나에서 방법론에 대해 자세히 다루지는 않았는데, 좋은 기회일 것 같습니다. 그럼 바로 시작해보겠습니다.
Introduction
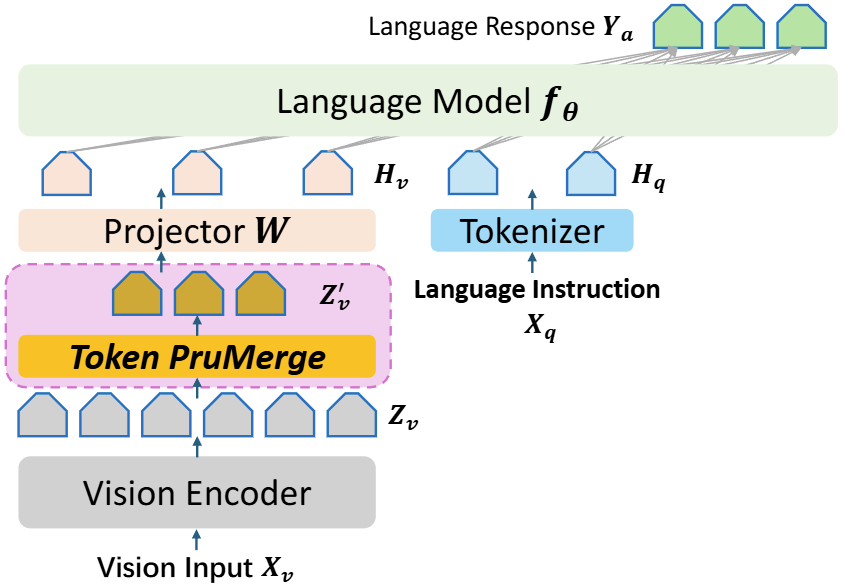
놀라울만한 LLM의 성능에 이은 LMM (MLLM)은 텍스트 뿐만 아니라 이미지를 다루면서 그 활용성을 늘려가고 있습니다. 하지만 LMM은 LLM과 마찬가지로 학습 뿐만 아니라 추론 과정에서 연산량을 많이 필요로 합니다. 이미지를 다룬다는 점에서 실제로는 LLM에 비해 많은 연산량을 필요하지만, 비교해보면 LLaMA, Vicuna의 LLM이 각각 7B, 13B를 요구하는데에 비해 CLIP ViT-L은 0.3B를 요구하여, 실제로 핵심은 LLM의 추론 비용을 줄이는데에 있습니다. 이를 위해 이전의 연구에서 Phi-2 (1.5B)와 같은 비교적 작은 수준의 LLM을 활용해보기도 하였으나, 필연적으로 이들은 LLM의 추론 능력 자체를 저하시키게 만듭니다. 그렇다면 더 좋은 LLM을 사용함이 성능을 위해 당장은 포기하기 어렵다는 전제에서, LLM의 비용을 늘리는 원인을 찾아보면 입력 토큰의 길이입니다. 특히 LMM에서는 이미지 토큰이 추가적으로 포함되는데, 이 때 이미지(Visual) 토큰과 텍스트(Text) 토큰 간의 Attention 연산에서 Quadratic complexity를 요구합니다. 예를 들어, LLaVA-1.5에서는 576개의 이미지 토큰이 활용되는데, Video-LLaVA의 경우 더 많은 토큰이 쓰일 것이며, 자연스럽게 연산량이 늘어날 수 밖에 없습니다.
그럼 위의 문제를 해결하기 위한 직관적인 질문은 다음과 같습니다: “이미지 토큰의 수를 줄이면서도 유사한 성능을 유지할 수 있는 방법은 없을까?”. 저자도 이 측면에서 접근하고자 하며, 다른 연구들과 마찬가지로 이미지 토큰들이 중복되어 있어 이들을 줄이는 방식, 대표적으로 Pruning과 Merging을 활용하고자 합니다. 바로 직전 주 세미나에서 소개드린 PuMer 논문에서도 Pruning과 Merging을 활용하는데, 이 둘이가 대표적이고 가장 흔히 활용되는 방식으로 보이네요. 결론적으로 저자는 LLM에 적은 수의 이미지 토큰을 넘겨주도록 방법을 설계합니다. 아, 김태주 연구원님이 세미나 질문에서 “LLM이 가변적인 Visual Token을 받을 수 있는지, 그러니 즉 Visual Token을 줄이더라도 Padding 등으로 항상 동일한 길이의 Token을 입력으로 받아야하지 않는지”에 대해 찾아봤는데, LLM에서는 보통 훈련 시에 최대 길이까지만 정의하고, 입력은 얼만큼 달라지더라도 그들을 각각 처리하기에 개수가 달라져도 상관 없다고 하네요. 조금 더 자세한 정보는 다음의 링크에서 확인해보실 수 있습니다.
Method
그럼 이제 방법론에 대해 살펴보겠습니다. 우선, VoT의 기본적인 동작 과정을 알아야겠네요. ViT와 LMM의 동작 과정을 아시는 분들은 다음 문단으로 넘어가셔도 좋습니다. ViT에서는 입력 이미지의 특정 크기의 토큰 (패치)로 나눈 다음, 그들에 대해 연산합니다. LMM과 연결하자면 LMM의 입력 Visual 토큰들을 전달해주는 역할을 하죠. 자세히는 입력 이미지를 토큰들로 나눈 이후, 이들과 동시에 [CLS] 토큰으로 불리는 클래스 토큰을 추가하여 활용합니다. ViT는 Transformer 블록들로 구성되며, 이들은 FFN, Skip Connection, Layer Normalization으로 구성됩니다. Self-Attention Layer에서는 query q, key k, 그리고 value v의 세 벡터가 그들의 Weight와 Linear Transformation된 다음, query와 key 간의 연관성(Attention-Score)을 계산하게 됩니다. 이 과정에 대한 수식은 잘 알고 계시리라 생각합니다. 이 때 앞서 말한 [CLS]는 실제로 이미지 분류를 위해 활용되는 토큰으로, 그말인 즉슨 해당 토큰은 이미지 전체를 잘 표현하는 정보를 내재하고 있습니다. 이 점이 핵심입니다.
Adaptive Important Token Selection via Outlier Detection
바로 위에서 [CLS] 토큰이 이미지 전체의 표현을 포함한다고 설명하였습니다. 이제, 저자가 Token Pruning을 위한 중요한 한 질문을 던집니다: “우리는 각 Visual Token의 중요성을 어떻게 판단할 수 있을까?”. 다른 말으로, 중요하지 않은 Visual Token을 안다면 그들을 지울 수 있을텐데 라는 말이죠. 저자는 이 [CLS] 토큰을 다른 이미지 토큰과의 Attention Score를 계산하면, 각 이미지 토큰들이 중요한지/하지 않은지를 알 수 있다고 판단합니다. 이를 보여주는 그림이 다음과 같습니다. 실제로 Attention Score를 비교해보니, 몇몇 토큰을 제외하고는 0에 수렴하는 중요하지 않은 (주로 배경) 토큰임을 알아내었습니다. 이러한 접근법은 이전 PuMer 리뷰에서 이미지 토큰과 텍스트 토큰 간의 Cross-Attention Score를 통해 입력 텍스트와 연관되지 않은 토큰을 구별해내는 방법과 유사하다고 볼 수 있습니다. 하지만 이번 LMM 기반에서는 텍스트와의 Cross-Attention은 LLM에서 수행되다 보니 그 정보를 활용할 수 없어, [CLS] 토큰의 정보를 활용했다고 생각하시면 됩니다.
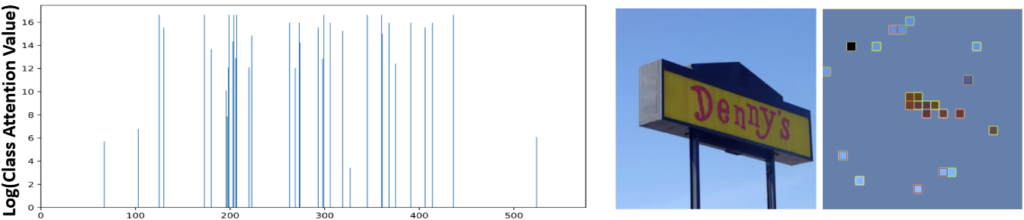
정량적으로 이들을 측정하고자, 사분범위 (IQR)을 활용합니다. 이는 이전 2020년도, “Outlier detection: Methods, models, and classification” 논문에서 소개된 방법으로, [CLS] 토큰과의 Attention Score를 Q1-Q4의 사분범위로 나눈 이후, IQR (Q3-Q1)에 대해 Minimum/Maximum fence (boundary)를 정의합니다. Minimum은 Q1-(1.5*IQR), Maximum은 Q3+(1.5*IQR)로 설정합니다. 이제 이 두 범위를 벗어난 Attention Score를 보이는 이미지 토큰을 Outlier로 정의하며, 이들은 Pruning합니다. 비교적 단순한, 통계학적인 접근 방식입니다. 대신, 이 방식의 장점은 이미지에 따라 Pruning의 비율을 사전에 정의해놓지 않으니 적응적으로 (Adaptive) 토큰의 수를 줄일 수 있다는 장점이 있습니다. 실제 위 그림을 보면, 비교적 단순한 이미지에서는 남은 토큰이 많지 않지만, 아래의 그림을 보면 이미지가 복잡한 (여기서 단순함과 복잡함은 이미지 내 정보 (특히 텍스트)로 정의함) 경우에는 토큰이 비교적 많이 남아있습니다. 뭐, 다른 한 편으로는 웬만하면 장면이 복잡한 경우가 더 많을텐데, 그 때는 비율을 정해놓은 방식에 비해 더 많은 수가 남아 효율면에서 아쉬울 수 있다는 점도 있습니다.

Token Supplement via Similar Key Clustering
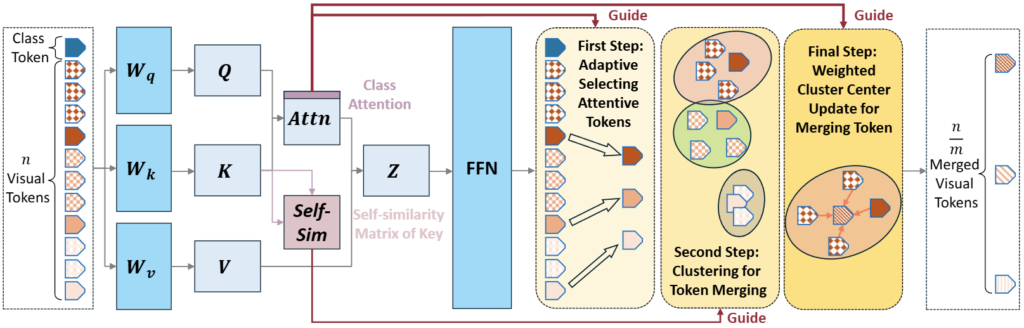
저자는 Pruning 이후, 남은 토큰에 대한 최적화 방식에 대해서도 소개하고 있습니다. 위 결과만 보면 Pruning된 토큰은 처음에는 그다지 필요하지 않은 것 처럼 보일 수 있지만, 그들 또한 LLM의 인지에 필요한 정보를 포함하고 있을 수 있습니다. 단지 비교적 정보량이 부족했을 뿐이죠. 이러한 사실은 특히 이미지 내 객체의 크기가 큰 경우, 많은 토큰이 줄어들면 무심코 모델의 능력을 줄이는 결과를 만들기도 합니다. 이를 극복하고자 저자는 Pruning 되지 않은, 남은 토큰들의 정보를 보완해주기 위한 Fusion 전략을 활용합니다. 이들은 비교적 단순합니다. [CLS] 토큰과 마찬가지로, 각 이미지 토큰들은 Key 벡터를 가지고 있으며 이들로부터 유사도를 측정할 수 있습니다. 이러한 방식은 이전의 Token Pruning 연구에서 활용되던 방식입니다.
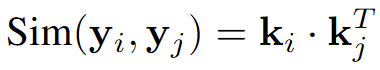
해당 유사도를 기반으로, 우리는 남은 토큰들을 Cluster Center로 하는 KNN을 수행할 수 있습니다. 해당 KNN 결과로 남은 토큰들은 다른 Pruning된 토큰들에 대해 가중 합으로 정보를 보완할 수 있습니다. 하지만, 우리가 최적화 관점에서만 바라보면 이 접근 방식은 Key 벡터 간의 Dot Product 연산을 요구한다는 점 (이는 추가적인 연산입니다)과, KNN 방식에서 남은 모든 토큰과의 거리 비교가 필요하다는 점에서 굉장히 비효율적입니다. 저자는 이에 대해 이후 Discussion 파트에서 본 방식은 현재의 Token Reduction 방식과는 조금 다르게 바라보아야 한다며, ViT의 Efficiency를 향상하는게 아닌 LMM의 Efficiency를 향상하기 위한 방식으로, ViT에서 요구되는 연산량이 조금 더 많아봤자, LLM에서 줄이는게 더 효율적일 것이라는 관점으로 접근한다고 설명합니다. 이들의 전체적인 파이프라인을 모사하는 아래의 그림과 알고리즘에서 확인할 수 있습니다.

PruMerge+: Bridging the Efficiency-Performance Gap
위 방식의 PruMerge는 이미지 토큰을 줄인다는 점에서 꽤나 많은 토큰을 줄일 수 있지만 (10배) 성능면에선 당연히 낮을 수 있습니다. 이를 보완하기 위한 방식을 소개하는데, 제 개인적인 생각으로 이 방식은 굉장히 속된말로 짜칩니다. 저자의 말을 빌리자면 “strikes an optimal balance”라고 하지만, 그 방식은 실제로는 이미지 공간 상으로 토큰을 균등히 몇 개 정도 더 뽑아 쓰는 방식입니다. 이 토큰들은 이미지 전반적으로 균일하게 뽑혀져 전체적인 표현력을 익히는 데에 도움이 되겠죠. 하지만, 이는 너무 단순한 방식입니다. Pruning의 주된 목적이 필요 없는 부분을 제거하자는 것인데, 이 방식은 도로 꽤나 배경 영역을 많이 포함시키는 결과로 귀결되기 때문입니다. 아마도 이는 아래의 제일 오른쪽 (중간은 PruMerge, 오른쪽은 PruMerge+)을 보시면 바로 눈치채실 수 있으리라 생각합니다.

Experiments
실험 측면에서도 아쉽습니다. 물론, 황유진 연구원님이 질문 주신 바와 같이 이 추후 논문을 읽어보았을 때 본 논문 (LLaVA-PruMerge)이 LMM에서 Token Reduction을 시도한 최초의 논문이기에 다른 방법론과의 비교군이 없음은 이해합니다 (해당 논문의 이름은 Less is More: A simple yet Effective Token Reduction Method for Efficient Multi-modal LLMs입니다). 다만, 보통 이런 표에서의 핵심은 성능과 효율의 Trade-off를 보여줌에 있는데, 성능표와 효율표를 따로 보여주다 보니 비교에 어려움을 겪습니다. 해당 PruMerge와 PruMerge+는 LLaVA-1.5를 기반으로 VQA 태스크의 많은 데이터 셋 (6종)에서 수행되었습니다. 우선 성능 표를 확인해봅시다.
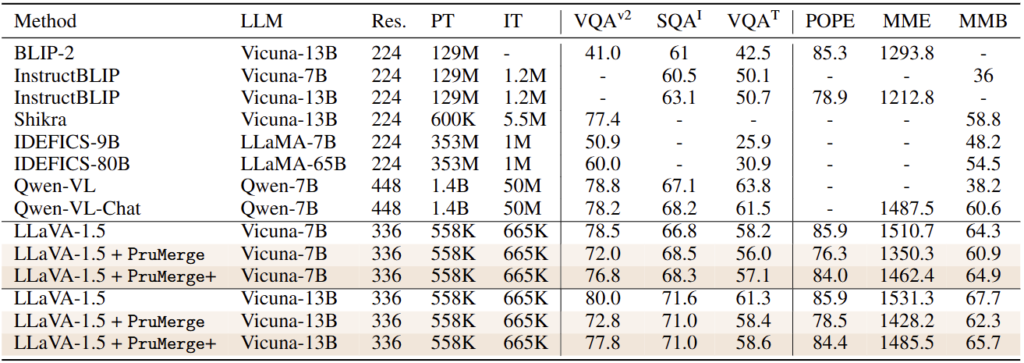
LLaVA-1.5면 아직까지도 SotA 급의, 현역 모델입니다. 비교군은 크게는 이전의 BLIP, Shikra, IDEFICS, Qwen이 벤치마킹 표로 있지만, 실제 이 방법의 비교는 LLaVA-1.5와 LLaVA-1.5 + PruMerge(PruMerge+)로 보아야할 것 입니다. LLaVA 자체가 이미 많은 벤치마킹에서 너무 우수한 성능을 보이고 있어서일까요, 사실 저는 PruMerge 때는 성능 하락이 Vicuda-7B(13B도 유사함) 기준에서 특정 벤치마크(POPE, VQAv2)에서는 너무 낮아지는 모습을 보여 놀랐습니다. 음, 그 이전의 PuMer 논문이 비교군이 될 순 없겠지만 (왜냐하면 그들은 LLM을 활용하지 않는 방식이므로), 그 당시에는 1% 내외의 성능 하락만을 보였기 때문입니다. 물론 PruMerge+는 더 많은 토큰을 활용하기에 성능이 웬만해선 오르는 모습을 보이기도 합니다. 그럼, 우리가 만약 PruMerge+를 쓴다고 가정하고, 이들에 대한 효율성이 궁금합니다.
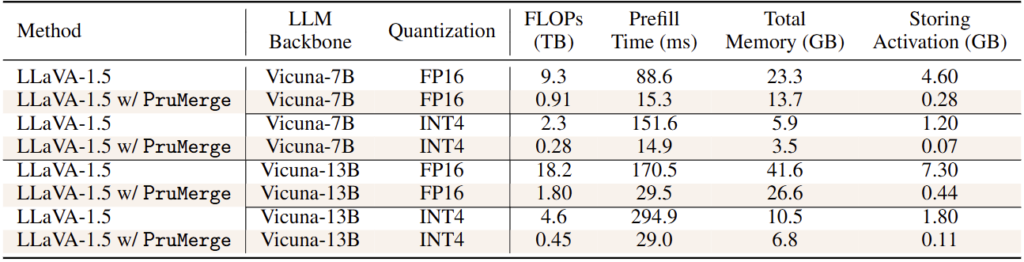
바로 이 점에서 크게 아쉽습니다. 왜 PruMerge+는 효율성 표에 추가하지 않았을까요? 아마도 뭐, 성능이 아쉬웠을 순 있습니다. 하지만 PruMerge는 성능면에서 어쩌면 너무 큰 공격을 받을 수도 있지 않을까요? 물론 FLOPS가 10배 이상 빨라지고 Prefill Time이 짧아지며 Memory 측면에서 효율성이 있음은 알겠습니다. 하지만 Trade-off를 고려하면 적어도 제 생각에선 PruMerge+가 그 방법론은 마음에 안들더라도 얘네와 비교했어야했을법한데 말이죠. 다음의 표도 마음에 안듭니다.
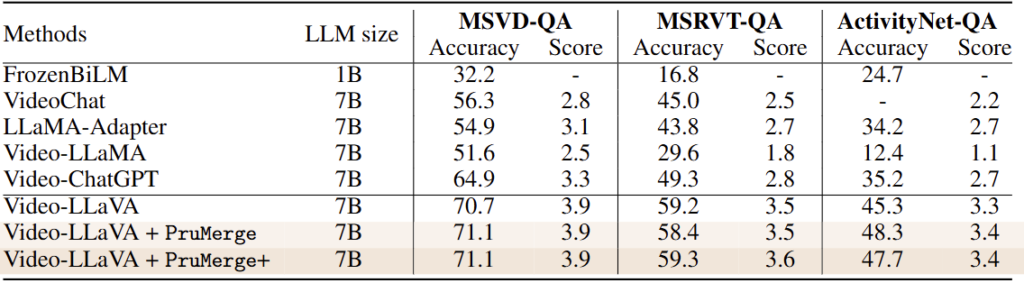
Introduction 초반부에 설명한 것과 같이, Video-LLaVA는 더 많은 토큰을 필요로 할테니 그렇다면 그 때의 Accuracy도 중요하겠죠 뭐. 어쩌면 저자는 오히려 Accuracy나 Score가 높아져 이 표를 들고왔을 순 있지만 이 논문의 핵심은 그럼에도 불구하고 Efficiency 비교가 빠져서는 안된다고 생각하였지만, Video-LLaVA에 대한 비교 실험에서 쏙 빼져 있습니다.
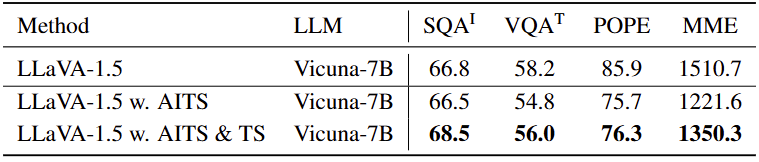
다른 Ablation은 큰 쓸모가 없다 생각하여 들고 온 AITS (Pruning)과 TS (Merging/Clustering) 방식에 대한 Ablation 하나만 보더라도, 성능적으로 TS의 도움을 받았음은 사실 중요하지 않습니다. AITS와 TS에 대해 각 방법이 추가되었을 때 얼마나 초기에는 FLOPs가 줄어들고, 다시 조금 더 올라 성능 향상 (약 2% 내외)을 보았을 때 ‘아~ TS를 붙이면 조금의 FLOPs가 늘어날 수는 있겠지만 그래도 성능이 저 만큼 오르면 납득되구나’로 귀결되어야 할텐데요. 사실 결과 시각화 자료도 하나 없어서 굉장히 아쉽네요. 그러니 즉 이번 논문에선 뭐 Introduction 부분은 괜찮은데, Method도 충분히 뭐 초기 연구이다 보니 마음엔 안들어도 납득하였습니다만, 제가 리뷰어라면 이 실험 부분에서 큰 실망을 하였을 것 같습니다. Efficiency를 보여주는 논문이 맞는가? 하는 의문이 너무 드는 논문이였네요. 하지만, 또 이런 논문 덕분에 다음 번의 연구 방향을 어느 정도 설정할 수 있어 한 편으로 좋기도 하였습니다. 이 후속 논문이 한 3-4가지 정도 있는데, 한 2개 정도를 뽑아 읽어본 후 확실히 예상 연구 방향과 Contribution을 정리하여 실험에 돌입하려 합니다. 재밌겠네요.